
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Достоинства и недостатки файловой организацииСтр 1 из 6Следующая ⇒
КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Файловые системы и базы данных» 1. Перечислите набор общих процедур управления ресурсами: Управление ресурсами в общем случае (вне зависимости от видов ресурсов) означает способность к выполнению над ними процедур планирования, распределения, поддержки и сохранения, экономного расходования, правильного потребления и интеграции (возможности использования в различных целях). 2. Какие еще составляющие, кроме среды хранения, можно выделить в системе управления ресурсом. Очевидно, что использование данных как ресурса предполагает: · представление самого понятия “данные”; · умение их собирать и анализировать; · определение природы и свойств данных, для чего необходимо знать, как и с какой целью они применяются, где находятся, откуда поступают и т.п.; таким образом, для управления данными необходимо иметь о них как можно больше сведений; · наличие среды хранения полученных сведений, которые могут надежно сохраняться только при наличии четких процедур накопления, планирования и ведения данных; · возможность после сбора и организации сведений получения доступа к ресурсу данных всюду, где нужна информация, требуемая для управления другими ресурсами, то есть интегрирование данных; · наличие администратора данных.
3. Дайте общее определение информационной системы. Использование средств вычислительной техники в автоматических или автоматизированных информационных системах. В самом широком смысле информационная система представляет собой программно-аппаратный комплекс, функции которого состоят в надежном хранении информации в памяти компьютера, выполнении специфических для данного приложения преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса. Обычно такие системы имеют дело с большими объемами информации, и эта информация имеет достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т. д. 4. Какие дополнительные требования к вычислительной технике предъявляют информационные потребности по сравнению с вычислительными задачами. для информационных систем, в которых потребность в текущих данных определяется конечным пользователем, наличие только магнитных лент и барабанов неудовлетворительно. Представьте себе покупателя билета, который, стоя у кассы, должен дождаться полной перемотки магнитной ленты. Одним из естественных требований к таким системам является удовлетворительная средняя скорость выполнения операций. 5.
Структура программы при файловой организации данных 6. Перечислите достоинства и недостатки файловой системы управления информационными массивами . КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «База данных как модель предметной области» 1. Дайте определение следующим базовым понятиям: данные, элемент данных, атрибут, объект, предметная область. Более точное определение, позволяющее сформулировать понятие модели предметной области, предполагает уточнение ряда других базовых понятий. Данные. Некоторый факт, на котором основан вывод или любая другая интеллектуальная деятельность. Первичными компонентами данных являются цифры и символы или их кодированное представление в виде строки двоичных битов. Элемент данных. Наименьшая семантически значимая поименованная единица данных, принимающая значение (фамилия, должность, цвет, зарплата). Объект. То, о чем хранятся данные (служащий, станок, материал). Атрибут. Характеристика (свойство) объекта. Заметим, что смысл объекта (данного) определяется только совокупностью его атрибутов, представленных соответствующими элементами данных. Предметная область. Совокупность объектов реального мира, рассматриваемого в рамках определенного контекста (теории, сферы деятельности, модели и т.п.). 2. Что определяет семантику объекта. Семантика. Присвоение данным некоторых свойств, после чего они становятся полезными как для людей (в смысле принятия решений), так и для программ или процедур (при определении обоснованности использования). В дальнейшем слово смысл будем использовать как синоним “семантики”. 3. Сформулируйте определение базы данных, исходя из понятия предметной области. полное и исчерпывающее описание предметной области в БД практически невозможно. но для решения возникающих в практической деятельности задач (проблем) полное информационное описание предметной области и не требуется. Поскольку любая решаемая задача связана с достижением некоторой цели, из предметной области всегда можно выделить лишь ограниченную совокупность (подмножество) взаимосвязанных объектов с определенными свойствами, поведение которой существенно для решения задачи. Ясно, что такие ограниченные подмножества связаны с каждой задачей, решаемой в рамках конкретной предметной области. Определение 2. БД – это структурная совокупность данных, отображающих свойства актуальных объектов внешнего мира (рассматриваемых с определенной точки зрения). Определение 3. База данных - это совокупность описаний объектов реального мира и связей между ними, актуальных для конкретной прикладной области. Другими словами, база данных - это некоторый набор данных, отображающий актуальные (необходимые для решения задач) данные и актуальные (значимые) связи. 4. Дайте определения понятиям: проблема, проблемная ситуация, цель, проблемная среда. Дадим еще несколько определений, уточняющих отдельные понятия, уже встречавшиеся ранее. Проблема. Объективно возникающий в деятельности человека вопрос или комплекс вопросов, решение которых представляет теоретический или практический интерес. Проблемная ситуация. Ситуация, которая не может быть разрешена имеющимися средствами. Цель. Некоторое состояние, к которому движется (или должна двигаться) совокупность взаимосвязанных объектов. Очевидно, что цель возникает при наличии проблемной ситуации. Замечание. Состояние совокупности взаимосвязанных объектов предметной области в каждый момент времени определяется совокупностью значений атрибутов объектов и характеристик связей. Изменились значения (характеристики связей) - изменилось состояние. Проблемная среда (область). Взаимосвязанная совокупность описаний решаемых задач в рамках определенной информационной системы. 5. Дайте общее определение понятию системы. Приведите основные свойства системы как объекта исследования . Система. Под системой будем понимать множество объектов и отношений (связей) между ними, выделенное из предметной области в соответствии с определенной целью в рамках определенного временного интервала. выделим следующие группы свойств, характеризующих систему как объект исследования: Статические свойства: · Целостность. Позволяет отделить систему от окружающей среды. · Открытость. Связь со средой. Наличие у системы входов (поступление информации из среды) и выходов (выдача результирующей информации в среду). · Внутренняя неоднородность. Позволяет выделить в системе ее составные части. · Структурированность. Наличие связей между частями системы. Динамические свойства: · Функциональность. Функции – это процессы, происходящие на выходах системы; результаты ее деятельности; продукция, ею производимая. · Стимулируемость. Подверженность системы воздействиям извне и изменение ее поведения под этими воздействиями. · Изменчивость со временем. Возможность изменения состава элементов, самих элементов, связей. · Устойчивость. Существование в изменяющейся среде. Сохранение работоспособности системы при изменениях в предметной области. Синтетические свойства: · Эмерджентность (emergence – внезапное появление). Появление свойств системы как целого, отсутствующих у отдельных частей системы. · Неразделимость на части. Следствие эмерджентности. Исчезновение некоторых свойств системы при выполнении операции ее декомпозиции. · Ингерентность (inherent – являющийся неотъемлемой частью чего-то). Согласованность с окружающей средой, совместимость с ней. · Целесообразность. Подчиненность определенной цели.
6. Дайте общее определение понятию модели. В чем отличительная особенность модели от других видов систем. Перечислите системные свойства модели. Основным способом изучения систем является построение ее модели. Существует множество определений модели. Учитывая сформулированное определение системы и перечень ее свойств, остановимся на следующем определении понятия модели [1]: Модель есть системное отображение оригинала. Выделим в этом определении два момента. 1. Отличительная особенность моделей от других систем состоит в их предназначении отображать моделируемый оригинал, т.е. содержать и представлять информацию об оригинале (системе). 2. Модель есть системное отображение оригинала => модель есть отображение: · целевое, · статическое или динамическое, · ингерентное, · проявляющаяся и развивающаяся в процессе его создания и практического использования, · конечное, упрощенное, приближенное, · абстрактное или реальное; абстрактность или реальность модели определяют ее тип. Абстрактные (искусственные) модели являются результатом мыслительной деятельности. Примеры: математические модели (функции, системы уравнений), литературные произведения. Реальные (естественные) модели. Для построения таких моделей используются материальные средства. Примеры: фотографии, макеты. выше приведена классификация моделей по типу. описании важной для дальнейшего рассмотрения структурной модели, применяемой при исследовании внутреннего устройства системы. Под формальной структурой понимается совокупность функциональных элементов и их отношений (связей), необходимых и достаточных для достижения системой заданных целей. Под связью (отношением) в общем случае будем понимать упорядоченную пару типов объектов. По типу отношений между элементами структуры подразделяются на: · · · · иерархические (древовидные) и неиерархические структуры. Важным классом неиерархических структур являются сетевые структуры (сети) – неиерархические структуры с направленными связями. Рассмотрим виды связей, актуальные для теории баз данных. Пусть даны два типа объектов А и В.
Один-к-одному (1:1). Обозначение
Говорят, что типы А и В находятся в отношении 1:1, если в каждый момент времени каждому экземпляру типа объектов А соответствует один и только один экземпляр типа объектов В. Очевидно, что А идентифицирует В (если определен экземпляр А, то определен и экземпляр В). В качестве примера можно рассмотреть связь объектов СЛУЖАЩИЙ и ЗАРПЛАТА Примера 2.
Один-ко-многим (1:М). Обозначение
Говорят, что типы А и В находятся в отношении 1:М, если в каждый момент времени каждому экземпляру из типа объектов А соответствует нуль, один или несколько экземпляров типа объектов В.
при таком виде связи А не идентифицирует В. В общем случае возможны четыре представления прямой и обратной связи: 1:1, 1:M, N:1, N:M. модель структуры системы – это перечень существенных связей между элементами системы. 7. Сформулируйте определение базы данных как модели предметной области. БД – это созданная и поддерживаемая в вычислительной среде статическая или динамическая модель предметной области, представленная управляемой совокупностью именованных данных, отображающей состояния объектов и их отношений во внешнюю память ЭВМ. Замечание . Как и всякая модель, БД отображает определенный взгляд на предметную область. Однако, выделенных компонент БД как модели предметной области недостаточно для разрешения проблемных ситуаций и достижения поставленных целей. Решение задач возможно только при наличии набора операций, которые могут обрабатывать содержимое БД (ее элементы). Таким образом, мы приходим к общему понятию модели данных, которая должна включать следующие компоненты: · допустимую организацию данных, · семантические ограничения целостности, · множество допустимых операций. Очевидно, что множество допустимых операций зависит от инструментария конкретной СУБД, в рамках которой реализуется модель предметной области. 8. Сформулируйте понятие модели данных. Какие составляющие должны быть определены в модели, чтобы ее можно было рассматривать как модель данных. Итак, модель данных можно определить как совокупность правил структурирования данных в базах данных, допустимых операций над ними и ограничений целостности, которым они должны удовлетворять. Замечание. В модели данных могут учитываться не все виды ограничений целостности, например, в ней нельзя учесть результаты некорректного выполнения коллективных запросов к информационному хранилищу. Обратим внимание на то, что понятие модели данных можно рассматривать в двух аспектах: · как инструментарий СУБД (средства описания данных и манипулирования ими), · как результат моделирования.
9. В чем отличие модели предметной области и поддерживаемой инструментарием СУБД определенной модели данных. Результирующую модель обычно называют моделью базы данных. Заметим при этом, что функции моделей в этих аспектах существенно различаются. В настоящее время термин модель базы данных считается устаревшим (хотя он в литературе и встречается), под моделью данных принято понимать инструментарий СУБД, а конечным результатом моделирования в рамках выбранной СУБД являются схемы базы данных разных уровней КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Понятие о банке данных» 1. Приведите схему общей структуры банка данных.
Общая структура банка данных
2. Приведите общую схему коллектива специалистов. Перечислите основные функции аналитиков, системных программистов, прикладных программистов.
Системные программисты занимаются созданием базового программного обеспечения. Генерируют операционную систему, в рамках которой предполагается функционирование СУБД, саму СУБД, необходимые компиляторы и обслуживающие утилиты. Аналитики, используя знания закономерностей определенной проблемной среды, строят ее математическую модель, привлекая необходимый математический инструментарий. Основная функция аналитика – представить задачу КП в форме некоторой формальной модели (“погрузить” задачу пользователя в математическую модель его проблемной области). Конечная цель аналитика – исходное представление задачи для прикладного программиста. Прикладной программист преобразует продукт деятельности аналитика в форму прикладной программы, предназначенной для реализации на ЭВМ. 3. Приведите схему уровней представления (абстракций) информационной системы. Схемы: · Схема концептуальная. Описание концептуальной модели предметной области средствами языка определения данными концептуального уровня архитектуры используемой СУБД. · Схема внешняя. Описание внешней модели предметной области средствами языка определения данными внешнего уровня архитектуры используемой СУБД. В одной системе баз данных СУБД может одновременно поддерживаться несколько внешних схем. · Схема внутренняя. Описание внутренней модели предметной области средствами языка определения хранимых данных выбранной СУБД. Иначе говоря, это описание организации базы данных в среде хранения данных используемой СУБД. В терминах перечисленных понятий рассмотрим схему одного из ранних (70-е – 80-е годы прошлого века) подходов в определении архитектуры информационной системы (рис. 7). На этой схеме выделены следующие уровни абстракции
Уровни представления информационной системы ЛПП (локальные пользовательские представления) - начальный уровень абстракции; соответствует представлениям о предметной области конечных пользователей на уровне руководителей подразделений (главный бухгалтер, начальник отдела кадров и т.п.). Инфологический (информационно-логический) – второй уровень. Представляет собой интеграцию ЛПП, соответствующую ”взгляду” на предметную область ее администратора (директора, президента фирмы, ректора вуза и т.п.). Администратор предметной области (не путать с администратором базы данных!) обозревает все множество информационных объектов, все возможные ассоциации между ними, в то время как каждый конечный пользователь просматривает лишь ограниченный фрагмент предметной области (бухгалтерия, цех, кадры и т.п.). 4. Дайте понятие инфологической модели. В чем отличие инфологической модели от концептуальной. Инфологическая модель предметной области - это описание структуры и поведения (динамики) предметной области в терминах, естественных и понятных пользователям разрабатываемой системы баз данных и учитывающих характер их информационных потребностей. Таким образом, ЛПП и инфологическое представление о предметной области определяет лишь информационные потребности разрабатываемой системы, отражает особенности предметной области, не затрагивая вопроса о способах отображения соответствующих данных в памяти ЭВМ. Инфологическая модель существует независимо от реализации системы, в частности, от выбора инструментария СУБД описание БД на концептуальном уровне задается на языке описания данных используемой СУБД в терминах и ограничениях, принятых в этой системе. Поскольку каждая СУБД поддерживает свою модель данных (свой инструментарий), описание единой инфологической модели предметной области в рамках разных СУБД приводит к разным (но, в идеале, эквивалентным) концептуальным схемам. Концептуальный уровень абстракции соответствует представлению о логической организации данных администратора базы данных. Этот уровень абстракции очень схож с инфологическим; его отличие состоит в привязке к средствам реализации, инструментарию СУБД, то есть модель предметной области разрабатываемой системы должна быть представлена в терминах (на языке описания данных) модели данных концептуального уровня (концептуальной модели) выбранной конкретной СУБД. Эту стадию называют логическим проектированием базы данных, а ее результатом является концептуальная схема базы данных. КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Вопросы проектирования баз данных» 1. Перечислите и охарактеризуйте основные этапы жизненного цикла информационной системы. Как и любая другая, информационная система проходит во времени свой определенный жизненный цикл. В зависимости от целей исследования, в жизненном цикле БД можно определить различные последовательности этапов. С точки зрения проектировщика и пользователя согласно [2] выделим две фазы жизненного цикла базы данных: · анализ и проектирование – начальный (“бумажный”) этап жизни БД, · реализация и эксплуатация системы. Анализ и проектирование. Этап выполняется посредством изучения предметной области и требований, предъявляемых к создаваемой БД. На “бумажной” стадии жизни системы производится выбор: · структур данных и стратегии их хранения в памяти ЭВМ, · технологии обслуживания БД и взаимодействия с ней конечных пользователей, · технических и стандартных программных средств, а также разработка оригинальных программных средств обслуживания системы. Реализация и эксплуатация. Сущность реализации заключается в материализации проекта, в перенесении его в память ЭВМ. На этой стадии разрабатывается и отлаживается программное обеспечение информационной системы, создается отладочный вариант БД, разрабатываются многочисленные приложения. На стадии реализации тестируется и корректируется технология обслуживания информационной системы. Эксплуатация начинается с наполнения системы реальной информацией. Эта стадия жизненного цикла охватывает весь комплекс действий по поддержанию функционирования информационной системы:стадия эксплуатации включает в себя разработку новых приложений, а также совершенствование и последующее развитие системы.
2.
ПО-информация отображает объекты (процессы, явления, предметы) реального мира как составные части ПО (элементы ПО), их существенные свойства, а также взаимосвязи между этими элементами. Эта ПО-информация не связана ни с конкретными приложениями, ни с конкретным способом обработки, а описывает естественные концептуальные связи всех данных в БД. ПП-информация описывает данные и связи, используемые в приложениях. В общем случае в методологии построения инфологических моделей ПО-информация должна использоваться для построения первоначальной инфологической модели данных, а ПП-информация – для совершенствования последней с целью повышения эффективности обработки данных.
3. Приведите общую схему концептуального проектирования.
Пример объединения сущностей Общая структура процесса логического проектирования (включая этап инфологического проектирования) представлена схемой на рис.11. На основании этой схемы можно определить следующие основные этапы процесса концептуального проектирования.
4. Приведите общую схему процесса проектирования.
Проектирование реализации
Структура процесса концептуального проектирования
КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Реляционная модель данных» 1. Дайте определение базовым понятиям реляционной модели: домен, кортеж, отношение, схема отношения, схема базы данных. Домен. В самом общем виде домен определяется заданием некоторого базового типа данных, к которому относятся элементы домена, и способа определения принадлежности произвольного элемента типа данных домену. Отношением называется произвольное конечное подмножество декартова произведения одного или нескольких доменов. Тип данных. Понятие тип данных в реляционной модели данных полностью адекватно понятию типа данных в языках программирования. Обычно в современных реляционных БД допускается хранение символьных, числовых данных, битовых строк, а также специальных «темпоральных» данных (дата, время, временной интервал). Схема БД (в структурном смысле) - это набор именованных схем отношений. В целом реляционная база данных представляется набором взаимосвязанных отношений различного смыслового наполнения, а ее схема – списком имен отношений, ее образующих, и совокупностью схем каждого из этих отношений. схемы отношения, - мощность этого множества. Если все атрибуты одного отношения определены на разных доменах, резонно использовать для именования атрибутов имена соответствующих доменов (не забывая, конечно, о том, что это является всего лишь удобным способом именования и не устраняет различия между понятиями домена и атрибута). Кортеж, соответствующий данной схеме отношения, - это множество пар (имя атрибута, значение), которое содержит одно вхождение каждого имени атрибута, принадлежащего схеме отношения. Значение является допустимым значением домена данного атрибута (или типа данных, если понятие домена не поддерживается). Тем самым, степень, или «арность» кортежа, то есть число элементов в нем, совпадает с «арностью» соответствующей схемы отношения.
2. Каковы пользовательские представления понятиям схемы отношения и экземпляра отношения. схему отношения можно ассоциировать с пустой таблицей (то есть с ее заголовком), а экземпляр схемы – с заполненной таблицей, отображающей состояние отношения в текущий момент времени, причем строками заполненной таблицы являются кортежи отношения-экземпляра, а имена атрибутов именуют столбцы этой таблицы. Поэтому иногда говорят «столбец таблицы», имея в виду «атрибут отношения». Этой терминологии придерживаются в большинстве коммерческих реляционных СУБД
3. Перечислите свойства отношений. Фундаментальные свойства отношений (таблиц). Определенные таким образом таблицы обладают следующими свойствами: 1. Однородность столбцов. Для всех столбцов таблицы выполняется следующее требование: элементы столбца принимают значения на одном домене. 2. Отсутствие кортежей-дубликатов. В таблице нет двух одинаковых строк. Это свойство следует из определения отношения как множества кортежей. В классической теории множеств, по определению, каждое множество состоит из различных элементов. Именно из этого свойства вытекает необходимость наличия у каждого отношения первичного ключа. 3. Отсутствие упорядоченности кортежей. В операциях с такой таблицей ее строки и столбцы могут просматриваться в любом порядке и в любой последовательности безотносительно к их информационному содержанию и смыслу. Свойство отсутствия упорядоченности кортежей отношения также является следствием определения отношения-экземпляра как множества кортежей. Отсутствие требования к поддержанию порядка на множестве кортежей отношения дает дополнительную гибкость СУБД при хранении баз данных во внешней памяти и при выполнении запросов к базе данных. Это не противоречит тому, что при формулировании запроса к БД можно потребовать сортировки результирующей таблицы в соответствии со значениями некоторых столбцов. Такой результат - это вообще говоря, не отношение, а некоторый упорядоченный список кортежей. 4. Отсутствие упорядоченности атрибутов. Атрибуты отношений не упорядочены, поскольку по определению схема отношения есть множество пар (имя атрибута, имя домена). Для ссылки на значение атрибута в кортеже отношения всегда используется имя атрибута. Это свойство теоретически позволяет, например, модифицировать схемы существующих отношений не только путем добавления новых атрибутов, но и путем удаления существующих атрибутов. Однако в большинстве существующих систем такая возможность не допускается, и хотя упорядоченность набора атрибутов отношения явно не требуется, часто в качестве неявного порядка атрибутов используется их порядок в определении схемы отношения.
Рис.13. Базовые понятия реляционной модели и соотношения между ними
5. Атомарность значений атрибутов. Значения всех атрибутов являются атомарными. Это следует из определения домена как потенциального множества значений простого типа данных, т.е. среди значений домена не могут содержаться множества значений (в свою очередь являющиеся отношениями). Принято говорить, что в реляционных базах данных допускаются только нормализованные отношения
4. Сформулируйте понятие функциональной зависимости. Определите 1НФ, 2НФ и 3НФ представления реляционной модели. функциональная зависимость означает, что атрибут Aj отношения R функционально зависит от атрибута Ai того же отношения, если в каждый момент времени каждому значению атрибута Ai соответствует не более чем одно значение атрибута Aj, связанного с Ai в отношении R. Или еще проще: функциональная зависимость Aj от Ai означает, что если в любой момент времени известно значение Ai, то можно однозначно получить и значение Aj. Наличие тех или иных зависимостей между атрибутами в схеме определяет степень ее нормализации. С практической точки зрения, достаточно трех первых форм - следует учитывать время, необходимое системе для «соединения» таблиц при отображении их на экране. Поэтому мы ограничимся изучением процесса приведения отношений к первым трем формам. Этот процесс включает: · устранение повторяющихся групп (приведение к 1НФ) · удаление частично зависимых атрибутов (приведение к 2НФ) · удаление транзитивно зависимых атрибутов (приведение к 3НФ).
Первая нормальная форма Назовем простым атрибут, значения которого неделимы. Назовем сложным атрибут, значения которого можно представить конкатенацией нескольких значений других атрибутов. Пример. Пусть задано следующее отношение R1: R1
Очевидно, что в схеме R1 все атрибуты, кроме атрибута Дети, простые. Замечание . Здесь и далее жирным шрифтом в примерах схем отношений выделяются первичные ключи. Отношение называется нормализованным или приведенным к первой нормальной форме (1НФ), если все его атрибуты являются атомарными (простыми); другими словами, если на пересечении строки и столбца находится значение только одного элемента данных. Преобразование ненормализованной формы в 1НФ осуществляется, как правило, увеличением размера отношения и изменению его первичного ключа. После приведения к 1НФ отношение R1 принимает следующий вид: R2
Очевидно, что в нормализованном отношении R2 все неключевые атрибуты функционально зависят от ключа. Замечание . При определении первичного ключа в отношении R2 предполагается, что в семье нет детей с одинаковым именем, в противном случае в состав ключа необходимо было бы включить атрибут Возраст_ребенка (вероятность одинакового имени у близнецов при нормальных родителях равна нулю). Вторая нормальная форма Говорят, что неключевой атрибут функционально полно зависит от составного ключа, если он функционально зависит от ключа, но не находится в функциональной зависимости ни от какой части составного ключа. Очевидно, что в отношении R2 атрибуты ФИО, Оклад, Комната, Телефон не находятся в полной функциональной зависимости от ключа отношения, поскольку они функционально зависят от части ключа Таб_номер. Наличие неполной функциональной зависимости приводит к высокой степени дублирования информации в отношении, а следовательно, к необходимости при изменении значения атрибута, (например, Оклад) вносить изменения в большое количество записей. Более того, данные о сотрудниках, не имеющих детей, естественным образом в отношение включены быть не могут. Таким образом, для отношения, находящегося в 1НФ, могут потребоваться дальнейшие преобразования. Говорят, что отношение находится во второй нормальной форме (2НФ), если оно находится в 1НФ и все неключевые атрибуты функционально полно зависят от составного ключа. Замечание. Проблема функциональной полноты рассматривается только в контексте составного ключа. Если первичный ключ включает только один атрибут, очевидно, эта проблема снимается. Для искомого приведения 1НФ во 2НФ необходимо: 1) построить проекцию 1НФ, исключив атрибуты, которые не находятся в полной функциональной зависимости от составного ключа; 2) построить дополнительно одну или несколько проекций на часть составного ключа и атрибуты, функционально зависящие от этой части ключа. Для нашего примера отношение R2 должно быть преобразовано в два отношения R3 и R4, оба находящиеся во 2НФ: R3
R4
Третья нормальная форма Пусть X, Y, и Z – три атрибута некоторого отношения. При этом
но обратное соответствие отсутствует, то есть или Тогда говорят, что Z транзитивно зависит от X. Например, в отношении R4 транзитивной является зависимость Таб_номер → Комната → Телефон Хранение в одном отношении атрибутов, находящихся в транзитивной зависимости от ключа, порождает ряд неудобств. Действительно, номер телефона есть характеристика комнаты, поэтому сведения о телефоне будут многократно дублироваться в записях для всех сотрудников, располагающихся в оной комнате. Более того, изменение телефона в одной комнате приводит к корректировке многих записей БД. Другая проблема, связанная с возможным нарушением целостности БД, возникает в случае, когда комнату покидает единственный находящийся в ней сотрудник; очевидно, при этом, что всякая связь с этой комнатой теряется. Говорят, что отношение находится в третьей нормальной форме (3НФ), если оно находится во 2НФ и каждый неключевой атрибут нетранзитивно зависит от ключевого атрибута. Для преобразования 2НФ в 3НФ необходимо построить несколько проекций. Для нашего примера отношение R4 должно быть приведено к двум отношениям R5 и R6:
R5
R6
процессе приведения отношений в 2НФ и 3НФ число отношений в схеме БД увеличивается. Однако, всегда сохраняется возможность получить исходные отношения, используя операции соединения. С другой стороны, появление новых отношений порождает проблемы поддержания семантической целостности. Выше было отмечено, что на практике третья нормальная форма схем отношений является достаточной в большинстве случаев и приведением к третьей нормальной форме процесс проектирования реляционной базы данных обычно заканчивается. Дайте понятия целостности для сущностей и ссылок. Что такое внешний ключ. 5. В чем отличие в использовании аппарата реляционной алгебры и аппарата реляционного исчисления. структурной части модели фиксируется, что единственной структурой данных, используемой в реляционных БД, является нормализованное n-арное отношение. Целостная компонента была рассмотрена в предыдущем пункте. В манипуляционной составляющей реляционной модели определяются два базовых механизма манипулирования реляционными данными: 1. Основанная на теории множеств реляционная алгебра. 2. Базирующееся на математической логике (точнее, на исчислении предикатов первого порядка) реляционное исчисление. В свою очередь, обычно рассматриваются два вида реляционного исчисления - исчисление доменов и исчисление предикатов. Все эти механизмы обладают одним важным свойством: они замкнуты относительно понятия отношения. Это означает, что выражения реляционной алгебры и формулы реляционного исчисления определяются над отношениями реляционных БД и результатами вычислений также являются отношения. Как следствие, любое выражение или формула могут интерпретироваться как отношение, что позволяет использовать их в других выражениях или формулах. Как мы увидим, алгебра и исчисление обладают большой выразительной мощностью: очень сложные запросы к базе данных могут быть выражены с помощью одного выражения реляционной алгебры или одной формулы реляционного исчисления. По этой причине именно эти механизмы включены в реляционную модель данных. И еще одно важное замечание. Основные достоинства реляционной модели заключаются не только в простоте ее представления, но и в возможности «разрезать» и «склеивать» отношения, то есть в возможности манипулировать частями отношений, формируя новые отношения. Заметим, что схема отношения может рассматриваться как описание типа переменной с именем, совпадающим с именем отношения, а экземпляры отношения – как значения этой переменной. Другими словами, операндами операций манипулирования отношениями могут выступать переменные.
6. Опишите набор традиционных операций над множествами как операций реляционной алгебры.
S UNION P будет содержать сведения о поставщиках, проживающих в Томске, либо поставляющих товар «Труба»:
2. Пересечение. Пересечением двух совместимых по типу отношений S и P (S INTERSECT P) называется отношение с тем же заголовком, что и у исходных отношений, и с телом, состоящим из множества кортежей, принадлежащих одновременно обоим отношениям. Результирующее отношение в условиях Примера 1. включает сведения о поставщиках из Томска, поставляющих товар «Труба»:
3. Вычитание. Вычитанием двух совместимых по типу отношений S и P (S MINUS P) называется отношение с тем же заголовком, что и у исходных отношений, и с телом, состоящим из множества кортежей, принадлежащих отношению S и не принадлежащих отношению P. Результирующее отношение в условиях Примера 1. включает сведения о поставщиках из Томска, не поставляющих товар «Труба»:
Очевидно, что отношение (P MINUS S) содержит сведения о поставщиках товара «Труба», не проживающих в Томске.
4. Декартово произведение. Декартово произведение двух не имеющих общих имен отношений S и P (S TIMES P) определяется как отношение с заголовком, который представляет собой сцепление исходных заголовков, и телом, состоящим из множества всех кортежей таких, что каждый кортеж получается конкатенацией некоторого кортежа отношения S с некоторым кортежем отношения P. Очевидно, что количество кортежей результирующего отношения равно произведению количества кортежей отношений S и P. Пример 2. Пусть отношения S (поставщики) и P (товары) имеют вид:
S
P
В результирующем отношении (S TIMES P) фиксируется тот факт, что каждый из поставщиков поставляет все товары:
7. Опишите набор специальных операций реляционной алгебры. S JOIN P называется отношение с заголовком {X, Y, Z} и телом, содержащим множество всех кортежей {X:x, Y:y, Z:z} таких, для которых в отношении S значение атрибута X равно x, атрибута Y равно y, а в отношении P значение атрибута Y равно y, а атрибута Z равно z. 5. Деление. Пусть заголовки отношений S (делимое) и P (делитель) имеют вид{X1, X2, …, Xm, Y1, Y2, … , Yn}и {Y1, Y2, … , Yn},соответственно, причем атрибуты {Y1, Y2, … , Yn}в обоих отношениях представлены одинаковыми именами и определены на одних и тех же доменах. Будем рассматривать выражения{X1, X2, …, Xm} и {Y1, Y2, … , Yn}как два составных атрибута {X} и {Y}. Тогда результатом деления отношения S на отношение P, обозначаемое как S DEVIDEBY P, называется отношение с заголовком {X} и телом, содержащим множество всех кортежей{X:x} таких, что для каждого xЄX существует множество кортежей {X:x, Y:y} отношения S таких, у которых множество составляющих {Y:y} включает все кортежи {Y:y} отношения P. Или нестрого: результат содержит такие X-значения из отношения S, для которых соответствующие Y-значения включают все Y-значения из отношения P. Запросы к базе данных, включающей отношения S, P, и SP, могут быть реализованы следующими цепочками операций реляционной алгебры. Запрос 1. Получить имена поставщиков, поставляющих деталь «Колено» (((SP JOIN P) WHERE Назв _ дет = « Колено ») JOIN S) [ Фио ] Запрос 2. Получить имена поставщиков, поставляющих все детали. ((( SP [Ном_пост, Ном_дет]) DEVIDEBY ( P [Ном_дет])) JOIN S ) [Фио] Запрос 3. Получить имена поставщиков, которые не поставляют деталь «Кран». ( S [Ном_пост,Фио] MINUS ((( SP JOIN P ) WHERE Назв_дет=«Кран») JOIN S ) [Ном_пост,ФИО]) [Фио] Учитывая, что каждый экземпляр схемы отношения можно представить как значение некоторой переменной, выполнение этого запроса может быть реализовано следующей иллюстративной программой:
T 1 = S [Ном_пост, Фио]; T2 = SP JOIN P; T3 = T2 WHERE Назв _ дет = « Кран »; T4 = T3 JOIN S; T5 = T4[ Ном _ пост , Фио ]; T6= T1 MINUS T5; T7 = T6[ Фио ]. Замечание. Если посмотреть на общий обзор реляционных операций, то видно, что домены атрибутов результирующего отношения однозначно определяются доменами отношений-результатов. Однако с именами атрибутов результата не всегда бывает все так просто. Например, представим себе, что у отношений-операндов операции прямого произведения имеются одноименные атрибуты с одинаковыми доменами. Каким должен был бы быть заголовок результирующего отношения? Поскольку заголовок - это множество, в нем не должны содержаться одинаковые элементы. Но и потерять атрибут в результате недопустимо. А это значит, что в этом случае вообще невозможно корректно выполнить операцию прямого произведения. Аналогичные проблемы могут возникать и в случаях других двуместных операций. Для их разрешения в состав операций реляционной алгебры вводится операция переименования. Ее следует применять в любом случае, когда возникает конфликт именования атрибутов в отношениях-операндах одной реляционной операции. Тогда к одному из операндов сначала применяется операция переименования, а затем основная операция выполняется уже безо всяких проблем.
10.Перечислите достоинства и недостатки реляционных систем. К числу наибольших достоинств реляционного подхода можно отнести: · наличие небольшого набора абстракций, которые позволяют сравнительно просто моделировать большую часть распространенных предметных областей и допускают точные формальные определения, оставаясь интуитивно понятными; · наличие простого и в то же время мощного математического аппарата, опирающегося главным образом на теорию множеств и математическую логику и обеспечивающего теоретический базис реляционного подхода к организации баз данных; · возможность ненавигационного манипулирования данными без необходимости знания конкретной физической организации баз данных во внешней памяти. Среди основных недостатков реляционной модели в настоящее время выделяют: · слабая система типов данных; этим системам присуща некоторая ограниченность (прямое следствие простоты) при использовании в так называемых нетрадиционных областях применения (наиболее распространенными примерами являются системы автоматизации проектирования), в которых требуются предельно сложные структуры данных, · невозможность адекватного отражения семантики предметной области; другими словами, возможности представления знаний о семантической специфике предметной области в реляционных системах очень ограничены, · сложности интеграции в новые технологические среды, которые основаны главным образом на объектных моделях. Современные исследования в области постреляционных систем главным образом посвящены именно устранению этих недостатков (см. раздел 8.). КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Навигационные модели данных» 1. Сформулируйте основные понятия иерархической модели. Перечислите ее основные. Основные понятия. Основным типом логической структуры, поддерживаемой иерархическими СУБД, является иерархическая (древовидная) структура (или просто иерархия). Иерархическая структура определяется на соответствующих типах записей согласно схеме базы данных (дереву определений, типу дерева). В этом дереве типы записей являются узлами, а дуги представляют иерархические связи («исходный-порожденный», «род-вид», «элемент-класс» и т.п.) между узлами дерева различных уровней. Тип дерева состоит из одного «корневого» типа записи и упорядоченного набора (из нуля или более) типов поддеревьев (каждое из которых является некоторым типом дерева). Тип дерева в целом представляет собой иерархически организованный набор типов записей. Содержимое иерархической БД представляется упорядоченным набором нескольких экземпляров типа дерева. В общем случае иерархия должна удовлетворять следующим условиям: 1. Одно дерево может иметь только один корень (исходный узел). 2. Узел должен иметь один или несколько атрибутов, описывающих семантику объекта. 3. У родительского узла может быть несколько потомков. 4. Потомок может быть связан только с одним родительским узлом. 5. Порожденные узлы могут быть добавлены как в горизонтальном, так и в вертикальном направлениях. Ограничения, например, на глубину иерархии, могут накладываться только требованиями конкретной иерархической СУБД. Если разность уровней двух связанных узлов равна единице, связь является непосредственной; кроме того, любые две вершины дерева, принадлежащие одной его ветви, транзитивно связаны друг с другом. 2. Каково представление концептуального и внешнего уровней иерархической модели. Концептуальная модель. Совокупность взаимосвязанных ФБД образует концептуальную иерархическую модель данных. Очевидно, что в простейшем случае дереву определений («бумажной» модели) соответствует одна ФБД. Каждая ФБД на физическом уровне реализуется отдельным набором физических записей. Для каждой ФБД на языке описания данных должно присутствовать как описание ее логической структуры, так и структуры хранения. Внешняя модель. При работе с иерархической моделью внешняя представляет собой совокупность поддеревьев для физических баз данных, с которыми работает данное приложение. Каждое поддерево внешней модели в обязательном порядке должно содержать корневой тип сегмента соответствующей ФБД концептуальной модели. Представление внешней модели часто называют логической базой данных и определяется она совокупностью блоков связи данного приложения с ФБД, входящими в состав концептуальной схемы иерархической базы данных. 3. Опишите принципы организации физического хранения записей в иерархической модели. Принципы организации физического хранения записей. Набор всех экземпляров записей, подчиненных одному экземпляру корневой записи, называется физической записью. Порядок хранения экземпляров типов записей в физической записи зависит от особенностей реализации, определяющих способ отображения логических деревьев в физические структуры файлов конкретной СУБД. Наиболее простой способ состоит в линеаризации дерева; при этом экземпляры типов записей хранятся последовательно в порядке обхода дерева сверху вниз слева направо. Пример. Физическая запись, хранящая экземпляры R1 и R2 при линеаризации, будет выглядеть следующим образом: 4.
Ясно, что при этом в общем случае физические записи будут иметь различную длину, причем длина некоторых из них может оказаться недопустимо большой (как с точки зрения занимаемых ресурсов памяти, так и времени поиска нужной информации). Поэтому в иерархических СУБД широко используется аппарат разделения графа, представляющего дерево определений, на подграфы (поддеревья), хранящиеся (реализуемые) отдельно, но в целом (в совокупности) представляющие единую логическую структуру – дерево определений. Такое расчленение обычно соответствует делению предметной области на фрагменты, каждый из которых описывается своим подграфом дерева определений.
Рис. 15. Упрощенный вид дерева определений ПО «Университет» В данном дереве можно выделить такие фрагменты, как например, Деканат, Ректорат, Кадры, Финансы и т.п. Каждый из фрагментов предметной области представляется отдельной физической базой данных (ФБД). 4. Сформулируйте основные понятия сетевой модели. Основные понятия. Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь в точности одного предка; в сетевой структуре данных потомок может иметь любое число предков. С точки зрения теории графов сетевой модели соответствует произвольный граф (возможно, имеющий циклы и петли). Например,
Стандарт сетевой модели впервые был определен в 1975г. организацией CODASYL (Conference of Data System Languages), которая определила базовые понятия модели и формальный язык ее описания. Базовыми объектами модели являются: · элемент данных, · агрегат данных, · запись, · набор данных. Элемент данных – минимальная информационная единица, доступная с помощью СУБД. Агрегат данных – соответствует следующему после элемента данных уровню обобщения. Например, агрегат с именем Адрес может быть представлен в виде
Запись - в общем случае совокупность элементов данных и/или агрегатов, моделирующая некоторый класс объектов реального мира. Набор – двухуровневый граф, связывающий отношением 1:M два типа записей.
Набор фактически отображает иерархическую связь между двумя типами записей - родительским типом записи (предком), называемым владельцем набора, и дочерним типом записи (потомком) – членом набора. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для любых двух типов записей может быть задано любое количество наборов, которые их связывают. Наличие подобных возможностей позволяет промоделировать отношение M:N между двумя объектами реального мира, что выгодно отличает сетевую модель от иерархической. Пример. На рис.16. представлены два набора, связывающие сущности «Преподаватель» и «Группа».
Рис.16. Наборы данных, связывающие сущности «Преподаватель» и «Группа» Пусть связь между экземплярами типов записей в наборах представляется содержимым таблицы1. Экземпляров набора «Ведет занятия у» – 3 (по количеству преподавателей), а экземпляров набора «Занимается у» – 4 (по количеству групп). Таблица 1.
Учитывая первоначальные рекомендации CODASYL и результаты последующих соглашений, можно сформулировать следующие основные свойства и ограничения, присущие набору: 1. Набор – это поименованная совокупность связанных записей. 2. В каждом экземпляре набора имеется только один экземпляр записи-владельца. 3. Тип набора представляет логическую взаимосвязь 1:M между владельцем и членом 4.
5. В сетевых моделях допускаются записи-члены, не участвующие в наборах. Это соответствует порожденным узлам дерева, не имеющим исходных. 6. Между двумя типами записей можно определить любое количество наборов, то есть, между ними могут быть определены любые типы отношений. 7. Экземпляр набора существует после заполнения записи-владельца. На формирование типов связи не накладываются особые ограничения; возможны, например, ситуации: · Тип записи потомка в одном типе связи может быть типом записи предка в другом типе связи (как в иерархии). · Данный тип записи может быть типом записи предка в любом числе типов связи. · Данный тип записи может быть типом записи потомка в любом числе типов связи. · Предок и потомок могут быть одного типа записи. 5. Каково представление концептуального и внешнего уровней сетевой модели. Концептуальная модель. Таким образом, сетевая БД состоит из набора записей и набора связей между ними, на концептуальном уровне образующих некоторый граф, а если говорить более точно, из набора экземпляров каждого типа из заданного в схеме БД набора типов записи и набора экземпляров каждого типа из заданного набора типов связи. Внешняя модель. При сетевой организации данных внешняя модель поддерживается путем описания соответствующей части общего связного графа. 6. Достоинства и недостатки навигационных моделей. Особенности: · Навигационные модели активно использовались в течение многих лет, дольше, чем какая-либо из реляционных СУБД. На самом деле некоторые из ранних систем используются даже в наше время, накоплены громадные базы данных, и одной из актуальных проблем информационных систем является использование их совместно с современными системами. · Все ранние системы не основывались на каких-либо абстрактных моделях. Понятие модели данных фактически вошло в обиход специалистов в области БД только вместе с реляционным подходом. Абстрактные представления ранних систем появились позже на основе анализа и выявления общих признаков у конкретных систем. · В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путем создания соответствующих прикладных программ с собственным интерфейсом. · Навигационная природа ранних систем и доступ к данным на уровне записей заставляли производить всю оптимизацию доступа к БД самого пользователя, без какой-либо поддержки системы. · После появления реляционных систем большинство ранних систем было оснащено «реляционными» интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме. Достоинства: · Иерархическая модель естественным образом реализует отображение 1:N между исходным и порожденными типами записей. Это отображение полностью функционально, так как дерево не может содержать порожденный узел без исходного. · Большая выразительность сетевой модели, достигаемая, прежде всего, возможностью установления между сущностями отношений любого типа. · Развитые средства управления данными во внешней памяти на низком уровне. · Возможность построения вручную эффективных прикладных систем. · Возможность экономии памяти за счет разделения подобъектов (в сетевых системах). Недостатки: · Для представления отображения типа M:N в иерархических системах необходимо дублирование деревьев. Пример. Связь
должна быть реализована двумя схемами:
(а) (б) Пусть загрузочная база данных по схеме (а) включает экземпляры:
Тогда загрузочная база данных по схеме (б) должна включать экземпляры:
Очевидно, что расплатой за необходимость такой реализации отношений M:N выступает высокая степень дублирования данных в базе. · Моделью слишком сложно пользоваться. Фактически необходимы знания о физической организации. · Прикладные системы зависят от физической организации. Их логика перегружена деталями организации доступа к БД. · Разработчик приложения должен детально знать логическую структуру БД, поскольку ему необходимо осуществлять навигацию среди различных экземпляров наборов и типов записей, то есть, программист должен представлять текущее состояние в экземплярах наборов при «продвижении» по БД. · Проблемой поддержки иерархической модели является невозможность хранения в базе данных порожденных узлов без соответствующих исходных. Следует заметить, что в процессе проектирования такая ситуация встречается достаточно часто (например, когда о родительском узле нет достоверной информации). В этом случае необходимо ввести пустой исходный узел. Наличие пустых узлов создает дополнительные трудности при проектировании некоторых приложений. · Определенная сложность операций включения информации о новых объектах в иерархическую базу данных и удаления устаревшей (проблема сохранения целостности базы данных: при удалении узла в общем случае удаляется целое поддерево, что может привести к потере информации). В более общей формулировке: возможность потери независимости данных при реорганизации БД (разрушение целостности БД). Произвольность структуры сети приводит к принципиальным сложностям в реализации такой модели, поскольку в ней отсутствуют ограничения на способы соединения типов записей в схеме БД. КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Система управления базой данных» 1. Перечислите основные функции СУБД. Как уже было отмечено, традиционных возможностей файловых систем оказывается недостаточно для построения даже простых информационных систем (см. п.1.2.). Было выявлено несколько потребностей, которые не покрываются возможностями систем управления файлами: · поддержание логически согласованного набора файлов; · обеспечение языка манипулирования данными; восстановление информации после разного рода сбоев; · реально параллельная работа нескольких пользователей. Можно считать, что система управления данными, обладающая перечисленными свойствами, является системой управления базами данных (СУБД). Таким образом, СУБД играет центральную роль в функционировании автоматизированного банка данных. В общем случае СУБД – это набор программных средств, выполняющих следующие основные функции: 1. Обеспечение пользователей языковыми средствами определения и манипулирования данными. 2. Обеспечение поддержки моделей данных пользователей, то есть средств определения логического представления данных, относящихся к некоторому приложению. Таким образом, здесь под термином модель данных понимаются средства определения именно логического представления данных. 3. Обеспечение защиты данных. 4. Обеспечение целостности данных. Вопрос о сохранении целостности данных имеет несколько аспектов, например: · проверка корректности данных связана с выполнением для новых данных, заносимых в БД, условий, связанных с ограничениями на их значения, например, год рождения служащего не может датироваться 18.. годом, · неправильное управление общими данными при коллективном доступе. 5. Управление транзакциями. Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует изменения БД, произведенные искомой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается в состоянии БД. 6. Непосредственное управление данными во внешней памяти. 7. Управление буферами оперативной памяти. 8. Обеспечение независимости данных. СУБД должна поддерживать неизменное представление базы данных на одном уровне архитектуры системы независимо от изменения представлений базы данных на других архитектурных уровнях. 9. Обеспечение универсальности. СУБД должна обладать мощными средствами поддержки концептуальной модели данных для отображения пользовательских логических представлений. Другими словами, должна быть способна поддерживать разные модели данных на единой логической и физической основе. 10.Обеспечение совместимости и развития. СУБД должна сохранять работоспособность при развитии программного и аппаратного обеспечения. 11.Обеспечение безизбыточности данных. БД должна представлять собой единую совокупность интегрированных данных с минимальной степенью их дублирования. 12.Поддержка как централизованных, так и распределенных по информационно-вычислительной сети БД. 2. Определите понятие транзакции. Назначение и суть механизма журнализации. Поддержка целостности. Понятие транзакции необходимо для поддержания логической целостности БД. Если вспомнить пример информационной системы отдела кадров с файлами СОТРУДНИКИ и ОТДЕЛЫ (см. п.5.2.), то единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника будет объединение элементарных операций над файлами СОТРУДНИКИ и ОТДЕЛЫ в одну транзакцию. Таким образом, поддержание механизма транзакций - обязательное условие даже однопользовательских СУБД. Но понятие транзакции гораздо существеннее во многопользовательских СУБД. При коллективном режиме возможно параллельное использование общих физических данных. Это требует поддержки согласованности одних и тех же данных при работе различных пользователей. Типичные примеры рассогласования при неправильном управлении одновременными модификациями – продажа большего числа товаров, чем имеется на складе, продажа нескольких билетов на одно место. Другими словами, суть сохранения целостности БД – ее адекватность текущему состоянию предметной области. То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый пользователь может в принципе ощущать себя единственным пользователем СУБД. Защита данных может рассматриваться с нескольких точек зрения, например: · защита для обеспечения секретности связана с разрешением использования тех или иных данных, хранящихся в системе, только пользователям, имеющим на это право, · защита от несанкционированного доступа, как правило, разрешает неограниченный доступ к данным из БД по чтению (выборке), но запрещает обновление и запись новых данных в “чужие” для данного пользователя разделы БД, · защита от разрушения БД при сбоях оборудования предполагает наличие процедур копирования и восстановления (функция журнализации). Журнализация. Одно из основных требований к СУБД - надежное хранение данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: · так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), · и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: · аварийное завершение работы СУБД (из-за ошибки в программе или некоторого аппаратного сбоя), · аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции. В любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежного хранения данных в БД требует избыточности хранения данных, причем та их часть, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенный метод поддержания такой избыточной информации - ведение журнала изменений БД. Журнал - это особая часть БД, недоступная пользователям СУБД, в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД фиксируются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), а порой запись соответствует минимальной внутренней операции модификации страницы внешней памяти. В некоторых системах одновременно используются оба подхода. Во всех случаях придерживаются стратегии «упреждающей» записи в журнал протокола. Кратко, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Самая простая ситуация восстановления - индивидуальный откат транзакции. Физически журнал обычно представляет собой чисто последовательный файл с записями переменного размера, которые можно просматривать в прямом или обратном порядке. Операции обмена производятся стандартными порциями (страницами) с использованием буфера оперативной памяти (см. пп.7.2.1. и 7.3.). Структура (и тем более, смысл) журнальных записей известна только компонентам СУБД, ответственным за журнализацию и восстановление. Поскольку содержимое журнала является критичным при восстановлении базы данных после сбоев, к ведению файла журнала предъявляются особые требования по части надежности. В частности, обычно стремятся поддерживать две идентичные копии журнала на разных устройствах внешней памяти. Очевидно, что в многопользовательском режиме работы вопросы журнализации занимают одно из центральных мест при функционировании СУБД. Управление данными во внешней памяти. Эта функция включает обеспечение необходимых структур внешней памяти (индексов) как для хранения непосредственных данных, входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным (см. пп. 7.2.3. - 7.2.7.). Управление буферизацией. СУБД обычно работают с БД значительного размера; по крайней мере, этот размер обычно существенно превышает доступный объем оперативной памяти. Понятно, если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Единственным же способом реального увеличения этой скорости является буферизация данных в оперативной памяти. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов. При управлении буферами основной памяти приходится разрабатывать и применять согласованные алгоритмы буферизации, журнализации и синхронизации. 3. Какие основные аспекты сохранения целостности учитываются при функционировании СУБД Обеспечение целостности данных. Вопрос о сохранении целостности данных имеет несколько аспектов, например: проверка корректности данных связана с выполнением для новых данных, заносимых в БД, условий, связанных с ограничениями на их значения, например, год рождения служащего не может датироваться 18.. годом, неправильное управление общими данными при коллективном доступе. 4. Какие основные аспекты защиты данных должны учитываться при функционировании СУБД. Защита данных может рассматриваться с нескольких точек зрения, например: · защита для обеспечения секретности связана с разрешением использования тех или иных данных, хранящихся в системе, только пользователям, имеющим на это право, · защита от несанкционированного доступа, как правило, разрешает неограниченный доступ к данным из БД по чтению (выборке), но запрещает обновление и запись новых данных в “чужие” для данного пользователя разделы БД, · защита от разрушения БД при сбоях оборудования предполагает наличие процедур копирования и восстановления (функция журнализации). 5. Сформулируйте понятия логической и физической независимости данных. Независимость данных. Важнейшими аспектами независимости данных являются: Логическая независимость данных. Способность механизмов СУБД поддерживать изменения логического представления данных таким образом, чтобы при этом было возможно сохранить неизменными пользовательские представления данных. В терминологии архитектурной модели ANSI/X3/SPARC это означает возможность вариации концептуальной схемы базы данных без необходимости изменений внешних схем. Физическая независимость данных. Способность механизмов СУБД поддерживать изменения физического представления данных таким образом, чтобы при этом было возможно сохранить неизменным логическое их представление. В терминологии архитектурной модели ANSI/X3/SPARC это означает возможность вариации внутренней схемы базы данных без необходимости изменений концептуальной схемы. 6. Приведите обобщенную схему СУБД. Обобщенную структуру СУБД можно представить схемой на рис. 18. Упрощенно основные этапы реализации СУБД запроса приложения представлены на рис.19. 1. Прикладная программа выдает СУБД запрос на доступ к БД. 2. СУБД анализирует запрос и определяет типы необходимых логических записей, содержащих запрашиваемые данные. 3. СУБД определяет хранимые записи, которые нужно предоставить прикладной программе. 4. СУБД выдает ОС команды поиска и обработки хранимых записей. 5.
Обобщенная структура СУБД
6. СУБД выделяет логические записи, которые необходимо передать приложению. 7. СУБД передает выделенные данные из системных буферов в рабочую область прикладной программы, предварительно преобразовав их в формат, указанный в запросе. 8. СУБД передает прикладной программе информацию о результатах обработки запроса. 9.
Рис.19. Схема реализации запроса к СУБД Замечание. Понятия концептуальной и внешней схем для навигационных моделей достаточно очевидны. Для реляционной модели внешнюю схему можно ассоциировать со схемой отношения, являющегося результатом выполнения запроса. понятие концептуальной схемы как результата реализации соответствующей модели инструментарием СУБД заменяется понятием даталогической (логической) схемы базы данных как взаимосвязанного набора схем отношений, формирующих базу. Замечание. Для эффективной работы с внешн памятью СУБД может взять управление на себя, минуя систему управления файлами ОС 7. Приведите упрощенную схему функционирования СУБД.
Рис.20 Взаимодействие компонентов информационной системы КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Основы физического проектирования» 2.Сформулируйте основные понятия физического уровня: хранимая запись, формат хранимой записи, метод доступа, механизм поиска Хранимая запись. Под хранимой записью будем понимать запись какого-либо типа, хранимую во внешней памяти. Очевидно, по аналогии с логическими записями, можно говорить о типе хранимой записи и экземпляре хранимой записи некоторого типа. Метод доступа определим как совокупность технических и программных средств, обеспечивающих возможность хранения и выборки данных (представленных хранимыми записями), расположенных во внешней памяти. В формировании метода доступа важны два компонента: · структура памяти, · механизм поиска. По структуре различают два типа внешней памяти: · память с последовательным доступом (например, магнитные ленты), · память с прямым доступом (например, дисковая память). Механизм поиска задается алгоритмом, определяющим специфический путь доступа, который возможен в рамках конкретной структуры памяти, и количество шагов вдоль этого пути для нахождения искомых данных (хранимых записей). Очевидно, что выбор метода доступа регулируется соображениями эффективности работы с БД (по использованию ресурсов - памяти и времени). Как правило, современные СУБД используют несколько методов доступа к хранимым записям. 1. Сформулируйте основные задачи этапа физического проектирования. Таким образом, в общем случае процесс проектирования физической БД (физическое проектирование) – это процесс создания по заданной логической структуре ее эффективной физической реализации, исходя из информационных требований конечных пользователей. Выделим в процессе физического проектирования следующие задачи: · определение методов доступа, · распределение и управление внешней памятью.
2. Классификация методов доступа
3. Опишите способы последовательной организации. Проблема синонимов при реализации Хеш-функции отношения 1:1 между значениями ключей и номерами участков размер справочника участков становиться неприемлемо большим, а величина самих участков неприемлемо малой=>к нерациональному расходу памяти. Реальным выходом из этой ситуации является принятие соглашения, при котором в общем случае Хеш-функции осуществляет отображение типа 1:M; однако в этом случае фиксируется эффект возникновения синонимов, когда записи с различными значениями ключей направляются для хранения в один участок, что приводит, в конечном счете, к различной степени загруженности участков. И, если при использовании связанной последовательной организации блоков внутри участков (именно такая организация представлена на рис.26.) наличие синонимов приводит, в основном, только к различию во времени поиска в пределах отдельных участков, то при использовании физически последовательной организации могут возникнуть дополнительные проблемы, связанные с необходимостью введения области переполнения (рис.27.). Очевидно, что возникновение слишком большого количества цепочек переполнения ведет к потере главное преимущества хэширования - доступа к записи практически всегда за одно обращение. Переход на использование новой хэш-функции (со значением свертки большего размера) требует перестройки всех участков основного файла, что в случае баз данных являются абсолютно неприемлемым. Поэтому обычно вводят промежуточные таблицы-справочники, содержащие значения ключей и адреса записей, а сами записи хранятся отдельно. Тогда при переполнении справочника требуется только его переделка, что вызывает меньше накладных расходов. Замечание. Конечно, структура самой области переполнения может быть связанной последовательной или физически последовательной.
5. Опишите метод доступа с полным индексом и индексно-последовательный метод доступа. Сравните эти методы. В чем достоинства и недостатки каждого из них. Доступ с полным (плотным) индексом (или индексно-произвольный метод) представляет собой такую организацию файла, при которой для каждого экземпляра записи в файле предусмотрен соответствующий элемент индекса (рис. 28.). Этот элемент включает значение ключа записи и указатель на блок, содержащий искомую запись. Обычно для ускорения поиска в индексе его элементы упорядочиваются. Достоинством данного метода доступа является произвольное расположение записей данных в основном файле, что обеспечивает их физическую независимость при хранении.
Рис.28. Схема организации метода доступа с плотным индексом Основной недостаток проявляется в тех случаях, когда: 1. Выдается оперетор выборки всех или большинства записей, и при этом требуется упорядочивание полученных данных. 2. Сложность процесса обновления основного файла, особенно при добавлении в него новых записей (требуется перестройка индекса). Доступ с неплотным индексом (индексно-последовательный метод доступа) строится на основе физически упорядоченного по возрастанию значения ключей последовательного файла и совокупности пронумерованных индексных элементов (индексе), каждый из которых содержит ключ подобно записям основного файла; элементы в индексе упорядочиваются по возрастанию значений ключей. Значение ключа в индексном элементе представляет наибольший (или наименьший) из значений ключей записей, входящих в блок основного файла с номером, совпадающим с номером индексного элемента. Структура индексно-последовательного файла представлена на рис.29.Алгоритм поиска при данной организации файла очевиден и включает два этапа: Поиск в индексе элемента, указывающего на блок, в котором должна находиться искомая запись, используя максимальное (или минимальное) значение ключей записей, размещенных в блоках основного файла.Последовательный просмотр записей найденного блока.
Рис.29. Схема организации индексно-последовательного файла
Таким образом, к записям индексно-последовательного файла с помощью индекса осуществляется прямой доступ к блоку (странице), включающему требуемую запись, и последовательный доступ в соответствии с упорядоченностью записей по этому ключу индексирования. Использование индексно-последовательной организации наиболее эффективно, когда модификация исходного файла не предполагает его расширения. В противном случае, как праавило, необходимо введение области переполнения, существование которой принципиально ломает простоту алгоритм поиска, присущую индексно-последоватльному методу доступа Основной единицей хранения и манипулирования данными при бесфайловой организации является страница памяти (или блок данных) - часть пространства памяти среды хранения базы данных, организованного таким образом, что оно состоит из последовательности таких частей (страниц), имеющих одинаковую длину. Страница является единицей обмена с внешней памятью. Размер страницы фиксирован для базы данных и устанавливается при ее (базы) создании. Страницы памяти имеют уникальные идентификаторы, в качестве которых обычно используются их последовательные номера. Содержимое страницы памяти может быть прочитано в буфер обмена или записано во внешнюю память из буфера за одно обращение к устройству внешней памяти. В некоторых системах страницы памяти могут иметь внутреннюю организацию, например, могут обладать индексом, обеспечивающим прямой доступ к содержащимся на странице хранимым записям. Страницы с простейшей организацией, предусматривающей последовательное размещение в них записей, в некоторых методах доступа называются блоками записей. КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Особенности объектно-ориентированных СУБД» 1. Перечислите побудительные мотивы к началу исследований по созданию ООСУБД. В середине 70-х годов XX века начали рождаться новые идеи, которые привели впоследствии к формированию объектного подхода в технологиях баз данных. 1. Объектный подход в программировании в значительной мере побудил интерес к воплощению объектной парадигмы в технологиях баз данных, поскольку возникла необходимость в обеспечении эффективной среды хранения объектных данных для поддержки многочисленных прикладных программных систем, реализованных средствами объектных языков. Эту функцию было естественно возложить на СУБД, основанные на объектных моделях данных, и обладающие интерфейсами прикладного программирования (API) для объектных языков. Объектно-ориентированная СУБД (ООСУБД) — средство, которое обеспечивает запись объектов в базу данных «как есть». Данное обстоятельство стало решающим аргументом в пользу разработки технологии ООСУБД как средства для переноса семантики объектов и процессов реального мира в сферу информационных систем, то есть переноса объектов реального мира в виртуальный мир. 2. Исследования по созданию ООСУБД связаны со сложившимся пониманием неэффективности использования реляционных систем в целом ряде приложений. Многие из таких приложений нуждаются в более богатых по сравнению с предоставляемыми реляционными СУБД средствами моделирования предметной области (с более развитыми системами типов данных, возможностями структурирования данных, обеспечивающих во многих случаях более естественное отображение семантики предметной области в базах данных). Дело в том, что одним из основных положений реляционной модели данных является требование нормализации отношений: поля кортежей могут содержать лишь атомарные значения, то есть, по существу, требование примитивности структур данных, лежащих в основе реляционной модели. Для традиционных приложений реляционных СУБД (РСУБД) - банковских систем, систем резервирования (билетов, посадочных мест и т.д.) - это вовсе не ограничение, а даже преимущество, позволяющее проектировать экономные по памяти БД с предельно простой и понятной структурой. Запросы с соединениями в таких системах сравнительно редки, для динамической поддержки целостности используются соответствующие средства SQL. Заметим, что плоские нормализованные отношения универсальны и теоретически достаточны для представления данных любой предметной области. Однако такой подход является весьма неестественным при управлении наборами данных или данными, которые необходимо описать с большей степенью детализации. Допустим, в столбце Адрес таблицы СЛУЖАЩИЙ может быть указан полный домашний адрес, причем различные приложения могут обрабатывать различные компоненты адресов. Однако РСУБД будет трактовать данные столбца Адрес как единое целое (строку символов), не замечая компонентные элементы данных; поэтому либо каждому приложению придется распаковывать содержимое поля, либо, что более соответствует духу реляционной модели, для каждой компоненты адреса будет выделен отдельный столбец. Еще большие проблемы возникают при использовании РСУБД в прикладных системах, основанных на знаниях – системах автоматизированного проектирования (САПР), системах искусственного интеллекта и т.п., которые обычно оперируют с объектами сложной структуры. Для формирования (воссоздания) цельного объекта из плоских таблиц РСУБД приходится выполнять запросы, почти всегда требующие соединения отношений. Поэтому попытки использования РСУБД в соответствии с требованиями таких нетрадиционных приложений приводят к появлению в базе данных сотен и тысяч таблиц, над которыми постоянно выполняются дорогостоящие операции соединения, необходимые для воссоздания сложных структур данных, присущих предметной области. Другими словами, в руки проектировщиков даются настолько же мощные и гибкие средства структуризации данных, как те, которые были присущи иерархическим и сетевым системам баз данных. 3. Проблема, название которой можно перевести как импеданс (или расхождение) моделей. Она выражается в том, что модель данных, используемая в приложении, отличается от модели данных базы данных. Это различие, в свою очередь, приводит к двум проблемам в приложениях, в результате которых и возникает расхождение: · Программист, разрабатывающий приложение, должен оперировать двумя различными языками программирования, с различным синтаксисом, семантикой и типами систем, а именно, прикладным языком программирования (например, Си++) и языком манипулирования базами данных (то есть, SQL). Логика приложения реализуется средствами прикладного языка, в то время как SQL используется для создания и манипулирования данными в базе. · При извлечении данных из реляционной базы, они должны быть переведены из представления, в котором они там хранились, в представление, соответствующее представлению данных в памяти, характерному для данного приложения. Аналогично, все обновления данных должны быть переданы базе данных при помощи другого предложения SQL, то есть требуется еще одно преобразование из представления, используемого в приложении, в представление базы данных. Весь обмен данными между базой данных и приложением приводит к ненужной дополнительной обработке, которой можно было бы избежать, будь модели данных приложения и базы данных одинаковыми. 2. Каковы особенности объектной модели данных. В связи с объектной парадигмой был предложен новый подход, при котором модель данных рассматривается как система типов. Такой подход обеспечивает естественные возможности интеграции баз данных и языков программирования. Ориентируясь на современное понимание типа данных как носителя свойств, определяющих и состояние экземпляров типа, и их поведение, можно дать следующее определение понятия модели данных (ср. с определением этого понятия, приведенным в п. 2.4.): Модель данных – это система типов данных, типов связей между ними и допустимых видов ограничений целостности, которые могут быть для них определены. Стандарт на ООСУБД выработан консорциумом Object Database Management Group (ODMG), состоящим в основном их производителей таких СУБД. В соответствии со стандартом ODMG, объектная модель данных характеризуется следующими свойствами. · Базовыми примитивами являются объекты и литералы. Каждый объект имеет уникальный идентификатор, литерал не имеет идентификатора. · Объекты и литералы различаются по типу. Все элементы одного типа имеют одинаковый диапазон изменения состояния (множество свойств) и одинаковое поведение (множество определенных операций). Объект, на который можно установить ссылку, называется экземпляром; он хранит определенный набор данных. · Состояние объекта определяется набором значений множества свойств. Этими свойствами могут быть атрибуты объекта или связи между объектом и одним или несколькими другими объектами. · Поведение объекта определяется набором операций, которые могут быть выполнены над объектом или самим объектом. Операции могут иметь список входных и выходных параметров строго определенного типа. Каждая операция может также возвращать типизированный результат. · База данных хранит объекты, позволяя совместно использовать их различным пользователям и приложениям. База данных основана на схеме данных, определяемой языком определения данных, и содержит экземпляры типов, определенных схемой. Каждый тип имеет внешнюю спецификацию и одну или несколько реализаций. Спецификация определяет внешние характеристики типа: пользователю для работы с объектом предоставляется набор операций и набор атрибутов объекта, при помощи которых можно работать с реальными экземплярами. Реализация определяет внутреннее содержание объектов, например операции. Тип также является объектом. ООСУБД обслуживает множество баз данных, каждая из которых содержит определенное множество типов. В базах данных могут содержаться объекты соответствующего типа из этого множества. Тип имеет набор свойств, а объект характеризуется состоянием в зависимости от значения каждого свойства. Операции, определяющие поведение типа, едины для всех объектов одного типа. Свойство едино для всего типа, а все объекты типа также имеют одинаковый набор свойств. Значение свойства относится к конкретному объекту. Таким образом, одним из принципиальных отличий объектных баз данных от реляционных является возможность создания и использования новых типов данных. Основные элементы ООСУБД представлены на рис.36., а применение базовых понятий объектной модели в ООСУБД на рис.37.
Рис.36. Основные элементы ООСУБД
Замечание 1. Очевидно родство понятия класса объектно-ориентированной парадигмы программирования и понятия типа объектно-ориентированной технологии баз данных. Замечание 2. Напомним, что термин объект в РСУБД обозначает либо тип объектов, либо экземпляр типа объектов. В ООСУБД и тип, и экземпляр типа являются объектами. Стандартный механизм объектно-ориентированного программирования — наследование, реализуется в ООСУБД путем поддержки иерархии супертипов (родительских типов) и подтипов (типов-потомков). Как правило, в ООСУБД для объектов, которые предполагается хранить в базе (постоянные объекты), требуется, чтобы их предком был конкретный базовый тип, определяющий все основные операции взаимодействия с сервером баз данных. Поэтому для создания своего типа необходимо унаследовать свойства любого имеющегося типа, наиболее подходящего по своему поведению и состоянию к типу, который требуется получить, расширить недостающие операции и атрибуты и переопределить, по необходимости, уже имеющиеся.
3. Каковы достоинства и недостатки ООСУБД. возникло ощущение, что объектно-ориентированные СУБД вытеснят реляционные и в силу согласованности с объектно-ориентированной парадигмой программирования, и в силу возможности навигации по указателям (ссылкам), что позволяет на новом уровне реализовать лучшие изобразительные средства иерархических и сетевых моделей. из-за ряда причин ООСУБД так и не смогли оказать значительного влияния на положение дел в области технологии баз данных: 1. Отсутствие в ООСУБД базовых средства, к которым пользователи систем баз данных привыкли. Чтобы ООСУБД смогли оказать значительное влияние на рынок баз данных, требовалось учесть привычку разработчиков к использованию средств РСУБД и огромный объем прикладного программного обеспечения, использующего реляционные базы данных. Для этого необходимо было: · превратить ООСУБД в системы баз данных, обладающих достаточной совместимостью с РСУБД, чтобы обеспечить сосуществование имеющихся и создающихся новых продуктов, · унифицировать модели данных РСУБД и ООСУБД, · унифицировать архитектуры РСУБД и ООСУБД. 2. Чтобы стать полноценными СУБД, ООСУБД должны поддерживать весь спектр соответствующих средств: · стандартная алгебра, средства обеспечения и оптимизации запросов, · управление транзакциями, · поддержка ограничений целостности, · организация безопасности, · и т.д. 3. Наличие в ООСУБД основных базовых средства, которые пользователи хотели бы видеть; · широкие возможности настройки производительности, присущие РСУБД, · поддержка сложных объектов, · поддержка динамических изменений определений классов, · полная интеграция с объектно-ориентированными системами программирования. Значительные сложности учета перечисленных факторов привел к тому, что рынок ООСУБД в настоящее время, по существу, исчез. Основные трудности объектно-ориентированного моделирования данных проистекают из того, что не существует развитого математического аппарата, на который могла бы опираться общая объектно-ориентированная модель данных. Замечание. Некоторые авторы утверждают, что общая объектно-ориентированная модель данных в классическом смысле и не может быть определена по причине непригодности классического понятия модели данных к парадигме объектной ориентированности. КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Вопросы распределенных баз данных» 1. Перечислите модели доступа и основные стратегии распределения данных, их достоинства и недостатки. · Централизация. Единая копия БД располагается в одном узле. Преимущества: - простота поддержки целостности, - простота обеспечения защиты, - простота реализации, - минимальная степень дублирования данных. Недостатки: - ограниченный объем внешней памяти, - ограничения на надежность, определяемые надежностью работы узла, - возможное значительное (а часто и недопустимое) время отклика на запрос при большом сетевом трафике (ограниченный доступ).
Рис.47. Методы доступа в распределенных базах данных
· Распределение. Различают два способа распределения данных с целью их приближения к месту использования и сокращения тем самым сетевого трафика - репликация и фрагментация. Репликация (тиражирование, дублирование). Технология, которая предусматривает поддержку полных копий базы данных или некоторых ее фрагментов в нескольких узлах сети. Полная репликация. Все данные дублируются в каждом узле. Частичная репликация. Некоторые, часто используемые на удаленных узлах, данные могут дублироваться в соответствующих узлах. Преимущества: - максимальный уровень надежности, - минимизация времени отклика при выборке данных (повышение степени доступности). Недостатки: - необходимость синхронизации при модификации БД. Фрагментация (расщепление, разделение). Технология, предусматривающая разбиение полной базы данных каким-либо методом на непересекающиеся составные части (фрагменты), хранимые в разных узлах сети. В свою очередь расщепление может быть вертикальным - выделение подмножества полей (атрибутов), и горизонтальным - выделение подмножества записей (кортежей). Преимущества: - максимальная внешняя память (суммарная для всех узлов сети), - минимальное время отклика на локальный запрос, - большая степень распараллеливания, - высокая степень доступности и надежности. Недостатки: - высокая стоимость связи в запросах, касающихся многих «чужих» локальных БД. Замечание. Ключевым фактором, влияющим на доступность и надежность БД, является локализация ссылок, то есть расположение запрашиваемых данных, исходя из удовлетворения запросов пользователей. Если БД распределена по сети так, что данные, расположенные в узле, запрашиваются почти исключительно пользователями этого узла, говорят, что существует высокая степень локализации ссылок. Очевидно, что надежность и доступность БД снижаются при понижении степени локализации ссылок. Возможным подходом к распределению данных может быть и применение смешанной стратегии - сочетанию репликации и фрагментации. Пример стратегий распределения Пусть схема распределенной по трем узлам БД состоит из трех отношений: СЛУЖАЩИЕ(слж#, фио, отд#, зарпл, рук) ОТДЕЛ(подраздел#, отд#) РАЗМЕЩЕНИЕ(подраздел#, город)
В Узел#1 находится головное учреждение и хранятся полные копии всех отношений (СЛУЖАЩИЕ, ОТДЕЛ, РАЗМЕЩЕНИЕ). В Узел#2 обрабатываются данные о зарплатах и налогах. Для этого нужны только атрибуты слж#, фио, зарпл из отношения СЛУЖАЩИЕ. В Узел#3 хранятся полные данные о служащих, зарабатывающих меньше 50000 руб. в год; об остальных служащих хранятся только сведения о номере отдела, в котором служащий работает, и руководителе отдела. Построим в Узел#2 отношение СЛЖ1(слж#, фио, зарпл) как проекцию: СЛЖ1 = СЛУЖАЩИЕ[слж#, фио, зарпл] Построим в Узел#3 отношения СЛЖ2(слж#, фио,отд#,зарпл,рук ) и СЛЖ3(слж#, фио,отд#,рук ), используя операции селекции (выборки) и проекции: СЛЖ2 = СЛУЖАЩИЕ WHERE зарпл < 50000 СЛЖ3 = СЛУЖАЩИЕ WHERE зарпл ≥ 50000[слж#, фио, отд#, рук] Таким образом, в Узел#1 хранятся полные кортежи, в Узел#2 - вертикальный фрагмент (расщепление по вертикали), в Узел#3 - горизонтальный и смешанный фрагменты отношения СЛУЖАЩИЕ. Замечание. Правильное восстановление полных кортежей отношения СЛУЖАЩИЕ по кортежам отношений СЛЖ1, СЛЖ2 и СЛЖ3 осуществляется с использованием значений ключевого атрибута слж#.
2. Перечислите проблемы распределенных баз данных. · Логическая прозрачность. Необходимость наличия единой концептуальной схемы распределенной по сети БД, другими словами, необходимость наличия общей модели данных распределенной системы. Принцип логической прозрачности позволяет пользователю формировать запросы ко всем данным распределенной БД так, как если бы он работал с централизованной базой. · Прозрачность размещения. Выполнение данного принципа позволяет пользователю при формировании запроса не указывать местоположение узлов, откуда необходимо получить данные для удовлетворения запроса. Очевидно, что реализация прозрачности размещения требует наличия схемы, определяющей местонахождение данных в сети. · Прозрачность преобразования. Распределенные БД могут быть однородными или неоднородными в смысле использования аппаратных и программных (СУБД) средств. Проблема неоднородности аппаратной, но однородности программной решается сравнительно просто. Если же в узлах сети используются разные СУБД, необходимы средства преобразования структур данных и языков. · Управление словарями. Для обеспечения всех видов прозрачности в распределенной БД нужны программы, управляющие многочисленными справочниками и словарями. · Координация процессов. Методы выполнения запросов в распределенных БД отличаются от аналогичных методов централизованных СУБД, поскольку отдельные части запроса нужно выполнять на месте расположения соответствующих данных и передавать частичные результаты на другие узлы, при этом должна быть обеспечена координация всех процессов. · Непротиворечивость данных. Необходим сложный механизм управления одновременной обработкой, который, в частности, должен обеспечивать синхронизацию при обновлениях информации, что гарантирует непротиворечивость данных. · Развитая методика репликации и расщепления данных. Выполнение запросов в распределенных базах данных . Поскольку данные распределены, а также могут быть расщеплены, запросы, составленные пользователем, который рассматривает данные целиком, должны быть приведены к виду, учитывающему разделение и расщепление данных. Таким образом, требуется декомпозиция запроса, так как программа, реализующая запрос, не может быть выполнена полностью в одном узле. Кроме того, поскольку для завершения выполнения программы необходимо перемещать целые отношения (файлы) или результаты промежуточных вычислений, необходимо оптимизировать: · саму программу, · методику выполнения программы (запроса) с учетом необходимых перемещений данных. 3. Перечислите свойства транзакций. Варианты завершения транзакции. Транзакция - это разовый прогон программы, реализующей запрос (другими словами, такая единица работы), при котором БД остается в состоянии целостности до и после выполнения транзакции. Замечание. В процессе выполнения транзакции целостность БД может нарушаться. два варианта завершения транзакции. Вариант 1. Все операции транзакции выполнены успешно и в процессе выполнения не произошло никаких сбоев программного или аппаратного обеспечения. В этом случае транзакция фиксируется, то есть, производится запись во внешнюю память изменений в БД, которые были сделаны в процессе выполнения транзакции. Замечание. До тех пор, пока транзакция не зафиксирована, допустимо аннулирование этих изменений путем восстановления БД в то состояние, в котором она была на момент начала выполнения транзакции. Вариант 2. Если в процессе выполнения транзакции возникла ситуация, которая делает невозможным ее нормальное завершение, БД должна быть возвращена в исходное состояние, то есть, должен быть произведен откат. Таким образом, откат транзакции - это совокупность действий, обеспечивающих аннулирование всех изменений данных в БД, которые были сделаны операторами SQL в теле незавершенной транзакции. Согласно стандартным соглашениям, транзакция завершается одним из 4-х возможны путей: 1) выполнение оператора COMMIT - фиксация успешного завершения транзакции; 2) успешное завершение программы, в которой было инициировано выполнение транзакции; 3) выполнение оператора ROLLBACK - реализация отката; 4) аварийное завершение программы, в которой было инициировано выполнение транзакции. Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается некоторая системная структура, называемая журналом транзакций. Однако, назначение журнала транзакций гораздо шире. Он предназначен для обеспечения надежного хранения данных в БД. Возможны следующие ситуации, при которых требуется произвести восстановление состояние БД. 1) Индивидуальный откат транзакции: a) стандартная ситуация отката и явное аварийное завершение транзакции по оператору ROLLBACK; b) аварийное завершение работы прикладной программы, которое логически эквивалентно выполнению оператора ROLLBACK, но физически имеет иной механизм выполнения; c) принудительный откат транзакции в случае взаимной блокировки при параллельном выполнении транзакций; в подобном случае для выхода из тупика данная транзакция может быть выбрана в качестве «жертвы». 2) Восстановление после внезапной потери содержимого оперативной памяти (мягкий сбой): a) при аварийном выключении питания; b) неустранимый сбой процессора и, таким образом, потеря данных, находящихся в оперативной памяти. 3) Восстановление после поломки основного внешнего носителя БД (жесткий сбой). Свойства транзакций Существуют различные модели транзакций, которые могут быть классифицированы на основании различных свойств, включающих: · структуру транзакции, · параллельность внутри транзакции, · продолжительность и т.п. Стандартно выделяют 4 классических свойства транзакций: Атомарность (Atomicity) - транзакция должна быть выполнена в целом или не выполнена вовсе. Согласованность (Consistency) - гарантирует, что по мере выполнения транзакции данные переходят из одного согласованного состояния в другое, то есть транзакция не разрушает взаимной согласованности данных. Изолированность (Isolation) - конкурирующие за доступ к БД транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно. Долговечность (Durability) - если транзакция завершена успешно, то те изменения в данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах (даже в случае последующих ошибок). Традиционные (плоские) транзакции, обладающие всеми стандартными свойствами, иногда называют ACID-транзакциями. 4. Сформулируйте понятие расписания. Приведите примеры рассогласования. В связи с управлением одновременной работой СУБД по выполнению запросов от разных пользователей, рассматриваются понятия транзакции и расписания. Транзакция - это разовый прогон программы, реализующей запрос (другими словами, такая единица работы), при котором БД остается в состоянии целостности до и после выполнения транзакции. Замечание. В процессе выполнения транзакции целостность БД может нарушаться. Расписанием совокупности транзакций будем называть порядок, в котором выполняются элементарные шаги этих транзакций. Очевидно, что расписание при одновременной работе представляет порядок выполнения транзакций во времени. Примеры расписаний. Введем следующие обозначения: Т - транзакция, R- A - элементарный шаг транзакции, представляющий чтение значения поля А, W-A - элементарный шаг транзакции, представляющий запись значения в поле А. Расписание 1. Т1 : R-A T1 : W-A T2 : R-A T2 : W-A Нарушения целостности (рассогласования) БД возникнуть не может, так как транзакции Т1 и Т2 выполняются последовательно. Расписание 2. Т1 : R-A T2 : R-A T1 : W-A T2 : W-A Модификация транзакции Т1 затирается транзакцией Т2, следовательно, она теряется. Расписание 3. Т1 : W-A T2 : W-A T1 : отменить Потеря модификации транзакции Т2, поскольку после ее окончания следует сигнал отмены модификации. Расписание 4. Т1 : W-A T2 : R-A T1 : прервать Ситуация известна под названием «неправильное считывание», поскольку выбранное транзакцией Т2 значение впоследствии из БД удаляется. Расписание 5 Т2: R-A T1: W-A T2 : R-A Две выборки дадут различные значения. Пример рассогласования БД. Пусть транзакции Т1 и Т2 имеют вид: R-A A=A+1 W-A Шаги выполнения транзакций приведены в следующей таблице
Очевидно, что целостность БД нарушена, поскольку нельзя было допустить чтение и модификацию поля А транзакцией Т2 до того, пока транзакция Т1 свое выполнение не закончит, то есть до записи модифицированного транзакцией Т1 значения в поле А. Согласованные состояния БД обеспечивают последовательные или приводимые к последовательным расписания. Расписание называется последовательным, если все транзакции выполняются строго друг за другом. Расписание называется приводимым к последовательному, если результат применения этого расписания к БД эквивалентен результату последовательного расписания. Для выявления расписаний, приводимых к последовательным и благодаря этому сохраняющих согласованное состояние БД, можно использовать метод, основанный на построении графа зависимостей. В графе зависимостей транзакциям соответствуют узлы, а направленная дуга графа, связывающая узлы Ti и Tj , обозначает, что вход транзакции Tj зависит от выхода транзакции Ti , то есть Tj использует значение поля, определенное Ti. Если граф зависимостей содержит циклы, то это означает, что соответствующее расписание не приводится к последовательному.
Т1 : W-A
T2 : W-A T2 : W-B Пример 2. Расписание , приводимое к последовательному
Т1 : W-A
T1 : W-В T2 : W-B
Пример 3. Расписание , не приводимое к последовательному
Т1 : W-A
T2 : W-В T1 : W-B 5. Управление блокированием. Перечислите основные методы синхронизации распределенных обновлений. В распределенных базах данных в общем случае одновременно выполняются несколько транзакций; при этом могут использоваться одни и те же данные, возможно, продублированные в разных узлах. При чтении для получения нужной информации достаточно одной копии, если СУБД обеспечивает непротиворечивость всех копий. При обновлениях (записи в БД) для сохранения непротиворечивости все копии должны быть своевременно модифицированы. Очевидно, что обновления нужно производить в соответствии с последовательными протоколами. Если учитывать одновременное выполнение транзакций над многочисленными копиями, последовательность обновлений требует развитых средств синхронизации, которая прежде всего предполагает монопольное владение поля транзакцией до полного окончания использования этого поля. Монопольное использование значения поля в процессе работы СУБД можно обеспечить с помощью блокировки (захвата). При этом предполагается, что любая транзакция представима в виде последовательности ЗАХВАТ - ДЕЙСТВИЕ - ОСВОБОЖДЕНИЕ Управление блокированием - это функциональный элемент СУБД, который назначает и регистрирует блокирование, а также играет роль арбитра между несколькими запросами на блокировку одного элемента. Очевидно, что блокировка действует как примитивная синхронизация выполнения транзакций. То есть, если транзакция пытается блокировать (ЗАХВАТ) что-то уже заблокированное, она должна ждать, пока блокировка не будет снята (ОСВОБОЖДЕИЕ) транзакцией, установившей блокировку. Итак, всякая транзакция в конце концов должна разблокировать все, что она ранее заблокировала. Таким образом, в распределенных БД необходимо обеспечить передачу следующих сообщений о блокировках: 1) послать запросы на блокировку во все узлы, 2) получить подтверждение о реализации блокирования (при поступлении запроса на блокировку прежде всего проверяется, не заблокирован ли элемент данных другой транзакцией; если элемент не заблокирован, он блокируется), 3) после завершения операции (чтения или обновления) требуется посылка запросов на снятие блокировки во все узлы, где хранится информация. при работе с блокировками транзакции чтения достаточно блокировать одну копию данных, находящуюся в соответствующем узле сети, а транзакция обновления должна блокировать все копии данных, находящихся в разных узлах сети. При этом, вообще говоря, транзакция может прочитать элемент данных из любой копии, содержащей этот элемент, даже если она блокирована по чтению другой транзакцией. Однако обновить элемент транзакция может только в том случае, если блокированы по записи все копии, содержащие этот элемент данных, именно этой транзакцией. Блокировка по чтению (возможность чтения) будет обеспечена до тех пор, пока другая транзакция не установит блокировку по записи. Для одного и того же элемента данных не могут одновременно существовать блокировки по чтению и записи. Таким образом, блокировка по чтению необходима, в общем случае, только для того, чтобы до завершения чтения никакая транзакция не могла модифицировать этот элемент данных. Метод 1. Использование графа предшествования . В графе предшествования узлам соответствуют транзакции, а ребрам - сведения о блокировках и освобождениях данных. Направленное ребро выходит из узла, который снимает блокировку элемента данных (Освободить), и ведет к узлу, который эти данные блокирует (Захватить). Наличие циклов в таком графе означает существование тупиковых ситуаций, когда ни одна транзакция не закончена, и все они находятся в состоянии ожидания разблокирования элементов данных, необходимых для продолжения их выполнения. Пример. Пусть имеется следующая последовательность запросов и действий транзакций, представленная на рис.49. (А, В, С - элементы данных):тупик (цикл) возникает, если для двух различных элементов данных необходимо исполнение двух транзакций в разном порядке. порядок, в котором различные транзакции блокируют элемент данных, должен соответствовать приводимому к последовательному расписанию. В схеме с основным узлом установка и снятие блокировок для всех транзакций происходят для основного узла. Когда поступает запрос на блокировку, проверяется, не заблокирован ли элемент данных, находящийся в основном узле, другой транзакцией. Если элемент не заблокирован, он блокируется. При синхронизации распределенных обновлений заблокировать можно не один основной узел, а несколько узлов. В узле находится свой локальный граф предшествования, в котором связь с остальной частью сети представлена специальной вершиной В этой схеме возможна глобальная тупиковая ситуация, хотя ни один из локальных графов не содержит циклов. Для обнаружения подобной ситуации узлы связывают свои локальные графы попарно через специальные внешние вершины до тех пор, пока не будет обнаружена тупиковая ситуация.При синхронизации распределенных обновлений на основе блокировок в центральном узле может находиться общий граф предшествования. В этом случае все узлы посылают запросы на установку и снятие блокировок в центральный узел. Расписание и соответствующий граф предшествования Метод 2. Временные метки . При использовании временных меток исключается возможность возникновения тупиковых ситуаций. Каждой транзакции при входе в сеть присваивается уникальная метка, например, показание часов глобальной сети, дополненное идентификатором сети. Каждый элемент в БД имеет временные метки последних выполненных над ним транзакций чтения (метка чтения) и обновления (метка записи). Если транзакция Т1 запрашивает операцию, которая вступает в конфликт с операцией, уже выполняемой в соответствии с более поздней по времени транзакцией Т2, Т1 запускается вновь. Конфликт между Т1 и Т2 возникает: Случай 1. Если операция транзакции Т1 есть операция чтения, но объект уже записан транзакцией Т2. Анализ ситуации: 1) объект прочитан транзакцией Т2, то есть своего состояния не изменил, и конфликт не возникает; 2) конфликт может возникнуть, поскольку объект записан транзакцией Т2, но транзакция Т1 не знает, что объект изменен и может быть настроена на обработку объекта, находящегося в состоянии до его изменения транзакцией Т2. Случай 2. Если операция транзакции Т1 есть операция записи, но объект уже был записан или прочитан транзакцией Т2. Анализ ситуации: Конфликт может возникнуть в любом случае, поскольку транзакция Т2 не знает, что состояние объекта изменено транзакцией Т1. Если транзакция перезапускается, ей присваивается новая временная метка. Замечание. Хотя тупиковые ситуации исключаются, могут возникать избыточные отказы и перезапуски, например, последовательность действий RT2 WT1 RT2 может быть абсолютно корректной, но приводит к рестарту транзакции Т1 (случай 2). Метод 3. Системы с голосованием . Каждому узлу дана возможность «голосовать» в пользу обновления. Известны два подхода. Подход 1. Запрос на обновление выполняется, если за проведение обновления проголосовали все узлы. Подход 2. Запрос на обновление выполняется, если за проведение обновления проголосовало большинство узлов. Замечание. Считается, что ни один узел не может одновременно голосовать за выполнение двух конфликтных транзакций. При наличии запроса на обновление узел может выдать один из следующих сигналов: 1) проведение обновления, 2) отклонение обновления, 3) возможна тупиковая ситуация, 4) узел воздерживается от голосования по данному запросу.
КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Файловые системы и базы данных» 1. Перечислите набор общих процедур управления ресурсами: Управление ресурсами в общем случае (вне зависимости от видов ресурсов) означает способность к выполнению над ними процедур планирования, распределения, поддержки и сохранения, экономного расходования, правильного потребления и интеграции (возможности использования в различных целях). 2. Какие еще составляющие, кроме среды хранения, можно выделить в системе управления ресурсом. Очевидно, что использование данных как ресурса предполагает: · представление самого понятия “данные”; · умение их собирать и анализировать; · определение природы и свойств данных, для чего необходимо знать, как и с какой целью они применяются, где находятся, откуда поступают и т.п.; таким образом, для управления данными необходимо иметь о них как можно больше сведений; · наличие среды хранения полученных сведений, которые могут надежно сохраняться только при наличии четких процедур накопления, планирования и ведения данных; · возможность после сбора и организации сведений получения доступа к ресурсу данных всюду, где нужна информация, требуемая для управления другими ресурсами, то есть интегрирование данных; · наличие администратора данных.
3. Дайте общее определение информационной системы. Использование средств вычислительной техники в автоматических или автоматизированных информационных системах. В самом широком смысле информационная система представляет собой программно-аппаратный комплекс, функции которого состоят в надежном хранении информации в памяти компьютера, выполнении специфических для данного приложения преобразований информации и/или вычислений, предоставлении пользователям удобного и легко осваиваемого интерфейса. Обычно такие системы имеют дело с большими объемами информации, и эта информация имеет достаточно сложную структуру. Классическими примерами информационных систем являются банковские системы, системы резервирования авиационных или железнодорожных билетов, мест в гостиницах и т. д. 4. Какие дополнительные требования к вычислительной технике предъявляют информационные потребности по сравнению с вычислительными задачами. для информационных систем, в которых потребность в текущих данных определяется конечным пользователем, наличие только магнитных лент и барабанов неудовлетворительно. Представьте себе покупателя билета, который, стоя у кассы, должен дождаться полной перемотки магнитной ленты. Одним из естественных требований к таким системам является удовлетворительная средняя скорость выполнения операций. 5.
Структура программы при файловой организации данных 6. Перечислите достоинства и недостатки файловой системы управления информационными массивами . Достоинства и недостатки файловой организации Достоинства: · Файловые системы обычно обеспечивают хранение слабо структурированной информации, оставляя дальнейшую структуризацию обрабатывающим программам. В некоторых случаях использования файлов это даже хорошо, потому что при разработке любой новой прикладной системы, опираясь на простые, стандартные и сравнительно дешевые средства файловой системы, можно реализовать те структуры хранения, которые наиболее естественно соответствуют специфике соответствующей прикладной области. · Файловая организация позволяет достигнуть высокой скорости обработки. Недостатки: · Узкая специализация как обрабатывающих программ, так и файловых данных, что служит причиной большой избыточности, так как одни и те же элементы данных хранятся в разных программных системах. · Возможность наличия противоречивости данных, когда для выполнения одних и тех же операций над однотипными данными, хранящихся в разных файлах, требуются разные программы. · Частое нарушение целостности данных, когда логически идентичные элементы данных в разных частных файлах имеют разные типы значений (например, Real и Integer), что может привести к расхождению в отчетах, полученных с помощью ЭВМ.
7. Какова структура программы при использовании технологии баз данных.
8. В чем основное функциональное отличие использования файловой системы управления информационными массивами и технологии баз данных. использование файловых систем для удовлетворения сложных интегрированных запросов, требующих обработки большого количества разнотипных данных, за приемлемое время практически невозможно. Совокупность предназначенных для машинной обработки интегрированных данных, служащая для удовлетворения нужд многих пользователей
9. Сформулируйте общее понятие о базе данных, как о хранилище информации. Перечислите основные преимущества в использовании баз данных. под базой данных понимается некоторая унифицированная совокупность данных, совместно используемая персоналом/населением группы, предприятия, региона, страны, мира... Задача базы данных состоит в хранении всех представляющих интерес данных в одном или нескольких местах, причем таким способом, который заведомо исключает ненужную избыточность. В хорошо спроектированной базе данных избыточность данных исключается, и вероятность сохранения противоречивых данных минимизируется. Таким образом, создание баз данных преследует две основные цели: понизить избыточность данных и повысить их надежность. Наиболее широко БД используются в управленческой деятельности благодаря следующим свойствам: · Скорость. Возможный доступ к информации за требуемое время. · Полная доступность. Вся информация, содержащаяся в БД, доступна для использования (с учетом, конечно, необходимости засекречивания и защиты). · Гибкость. Легко вносимые изменения и дополнения в БД позволяют получать ответы на вопросы, которые ранее оставались без ответа. · Целостность. Уменьшилась степень дублирования данных и ликвидирована их противоречивость; упорядочился процесс обновления и восстановления БД после сбоев; появилась возможность управления параллельного общения с БД нескольких прикладных программ. 10. Какие два ключевых момента следует отметить при переходе к технологии баз данных. В связи с концепцией баз данных еще раз подчеркнем два ключевых момента: 1. Информация уже не скрыта в сочетании “файл-программа”; она хранится явным образом в БД. БД ориентирована на интегрированные запросы, а не на одну задачу. 2. Возможность выделения по запросу из всех данных, хранящихся в БД, только необходимых и в требуемой форме (структуре и форматах). КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «База данных как модель предметной области» 1. Дайте определение следующим базовым понятиям: данные, элемент данных, атрибут, объект, предметная область. Более точное определение, позволяющее сформулировать понятие модели предметной области, предполагает уточнение ряда других базовых понятий. Данные. Некоторый факт, на котором основан вывод или любая другая интеллектуальная деятельность. Первичными компонентами данных являются цифры и символы или их кодированное представление в виде строки двоичных битов. Элемент данных. Наименьшая семантически значимая поименованная единица данных, принимающая значение (фамилия, должность, цвет, зарплата). Объект. То, о чем хранятся данные (служащий, станок, материал). Атрибут. Характеристика (свойство) объекта. Заметим, что смысл объекта (данного) определяется только совокупностью его атрибутов, представленных соответствующими элементами данных. Предметная область. Совокупность объектов реального мира, рассматриваемого в рамках определенного контекста (теории, сферы деятельности, модели и т.п.). 2. Что определяет семантику объекта. Семантика. Присвоение данным некоторых свойств, после чего они становятся полезными как для людей (в смысле принятия решений), так и для программ или процедур (при определении обоснованности использования). В дальнейшем слово смысл будем использовать как синоним “семантики”. 3. Сформулируйте определение базы данных, исходя из понятия предметной области. полное и исчерпывающее описание предметной области в БД практически невозможно. но для решения возникающих в практической деятельности задач (проблем) полное информационное описание предметной области и не требуется. Поскольку любая решаемая задача связана с достижением некоторой цели, из предметной области всегда можно выделить лишь ограниченную совокупность (подмножество) взаимосвязанных объектов с определенными свойствами, поведение которой существенно для решения задачи. Ясно, что такие ограниченные подмножества связаны с каждой задачей, решаемой в рамках конкретной предметной области. Определение 2. БД – это структурная совокупность данных, отображающих свойства актуальных объектов внешнего мира (рассматриваемых с определенной точки зрения). Определение 3. База данных - это совокупность описаний объектов реального мира и связей между ними, актуальных для конкретной прикладной области. Другими словами, база данных - это некоторый набор данных, отображающий актуальные (необходимые для решения задач) данные и актуальные (значимые) связи. 4. Дайте определения понятиям: проблема, проблемная ситуация, цель, проблемная среда. Дадим еще несколько определений, уточняющих отдельные понятия, уже встречавшиеся ранее. Проблема. Объективно возникающий в деятельности человека вопрос или комплекс вопросов, решение которых представляет теоретический или практический интерес. Проблемная ситуация. Ситуация, которая не может быть разрешена имеющимися средствами. Цель. Некоторое состояние, к которому движется (или должна двигаться) совокупность взаимосвязанных объектов. Очевидно, что цель возникает при наличии проблемной ситуации. Замечание. Состояние совокупности взаимосвязанных объектов предметной области в каждый момент времени определяется совокупностью значений атрибутов объектов и характеристик связей. Изменились значения (характеристики связей) - изменилось состояние. Проблемная среда (область). Взаимосвязанная совокупность описаний решаемых задач в рамках определенной информационной системы. 5. Дайте общее определение понятию системы. Приведите основные свойства системы как объекта исследования . Система. Под системой будем понимать множество объектов и отношений (связей) между ними, выделенное из предметной области в соответствии с определенной целью в рамках определенного временного интервала. выделим следующие группы свойств, характеризующих систему как объект исследования: Статические свойства: · Целостность. Позволяет отделить систему от окружающей среды. · Открытость. Связь со средой. Наличие у системы входов (поступление информации из среды) и выходов (выдача результирующей информации в среду). · Внутренняя неоднородность. Позволяет выделить в системе ее составные части. · Структурированность. Наличие связей между частями системы. Динамические свойства: · Функциональность. Функции – это процессы, происходящие на выходах системы; результаты ее деятельности; продукция, ею производимая. · Стимулируемость. Подверженность системы воздействиям извне и изменение ее поведения под этими воздействиями. · Изменчивость со временем. Возможность изменения состава элементов, самих элементов, связей. · Устойчивость. Существование в изменяющейся среде. Сохранение работоспособности системы при изменениях в предметной области. Синтетические свойства: · Эмерджентность (emergence – внезапное появление). Появление свойств системы как целого, отсутствующих у отдельных частей системы. · Неразделимость на части. Следствие эмерджентности. Исчезновение некоторых свойств системы при выполнении операции ее декомпозиции. · Ингерентность (inherent – являющийся неотъемлемой частью чего-то). Согласованность с окружающей средой, совместимость с ней. · Целесообразность. Подчиненность определенной цели.
6. Дайте общее определение понятию модели. В чем отличительная особенность модели от других видов систем. Перечислите системные свойства модели. Основным способом изучения систем является построение ее модели. Существует множество определений модели. Учитывая сформулированное определение системы и перечень ее свойств, остановимся на следующем определении понятия модели [1]: Модель есть системное отображение оригинала. Выделим в этом определении два момента. 1. Отличительная особенность моделей от других систем состоит в их предназначении отображать моделируемый оригинал, т.е. содержать и представлять информацию об оригинале (системе). 2. Модель есть системное отображение оригинала => модель есть отображение: · целевое, · статическое или динамическое, · ингерентное, · проявляющаяся и развивающаяся в процессе его создания и практического использования, · конечное, упрощенное, приближенное, · абстрактное или реальное; абстрактность или реальность модели определяют ее тип. Абстрактные (искусственные) модели являются результатом мыслительной деятельности. Примеры: математические модели (функции, системы уравнений), литературные произведения. Реальные (естественные) модели. Для построения таких моделей используются материальные средства. Примеры: фотографии, макеты. выше приведена классификация моделей по типу. описании важной для дальнейшего рассмотрения структурной модели, применяемой при исследовании внутреннего устройства системы. Под формальной структурой понимается совокупность функциональных элементов и их отношений (связей), необходимых и достаточных для достижения системой заданных целей. Под связью (отношением) в общем случае будем понимать упорядоченную пару типов объектов. По типу отношений между элементами структуры подразделяются на: · · · · иерархические (древовидные) и неиерархические структуры. Важным классом неиерархических структур являются сетевые структуры (сети) – неиерархические структуры с направленными связями. Рассмотрим виды связей, актуальные для теории баз данных. Пусть даны два типа объектов А и В.
Один-к-одному (1:1). Обозначение
Говорят, что типы А и В находятся в отношении 1:1, если в каждый момент времени каждому экземпляру типа объектов А соответствует один и только один экземпляр типа объектов В. Очевидно, что А идентифицирует В (если определен экземпляр А, то определен и экземпляр В). В качестве примера можно рассмотреть связь объектов СЛУЖАЩИЙ и ЗАРПЛАТА Примера 2.
Один-ко-многим (1:М). Обозначение
Говорят, что типы А и В находятся в отношении 1:М, если в каждый момент времени каждому экземпляру из типа объектов А соответствует нуль, один или несколько экземпляров типа объектов В.
при таком виде связи А не идентифицирует В. В общем случае возможны четыре представления прямой и обратной связи: 1:1, 1:M, N:1, N:M. модель структуры системы – это перечень существенных связей между элементами системы. 7. Сформулируйте определение базы данных как модели предметной области. БД – это созданная и поддерживаемая в вычислительной среде статическая или динамическая модель предметной области, представленная управляемой совокупностью именованных данных, отображающей состояния объектов и их отношений во внешнюю память ЭВМ. Замечание . Как и всякая модель, БД отображает определенный взгляд на предметную область. Однако, выделенных компонент БД как модели предметной области недостаточно для разрешения проблемных ситуаций и достижения поставленных целей. Решение задач возможно только при наличии набора операций, которые могут обрабатывать содержимое БД (ее элементы). Таким образом, мы приходим к общему понятию модели данных, которая должна включать следующие компоненты: · допустимую организацию данных, · семантические ограничения целостности, · множество допустимых операций. Очевидно, что множество допустимых операций зависит от инструментария конкретной СУБД, в рамках которой реализуется модель предметной области. 8. Сформулируйте понятие модели данных. Какие составляющие должны быть определены в модели, чтобы ее можно было рассматривать как модель данных. Итак, модель данных можно определить как совокупность правил структурирования данных в базах данных, допустимых операций над ними и ограничений целостности, которым они должны удовлетворять. Замечание. В модели данных могут учитываться не все виды ограничений целостности, например, в ней нельзя учесть результаты некорректного выполнения коллективных запросов к информационному хранилищу. Обратим внимание на то, что понятие модели данных можно рассматривать в двух аспектах: · как инструментарий СУБД (средства описания данных и манипулирования ими), · как результат моделирования.
9. В чем отличие модели предметной области и поддерживаемой инструментарием СУБД определенной модели данных. Результирующую модель обычно называют моделью базы данных. Заметим при этом, что функции моделей в этих аспектах существенно различаются. В настоящее время термин модель базы данных считается устаревшим (хотя он в литературе и встречается), под моделью данных принято понимать инструментарий СУБД, а конечным результатом моделирования в рамках выбранной СУБД являются схемы базы данных разных уровней КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Понятие о банке данных» 1. Приведите схему общей структуры банка данных.
Общая структура банка данных
2. Приведите общую схему коллектива специалистов. Перечислите основные функции аналитиков, системных программистов, прикладных программистов.
Системные программисты занимаются созданием базового программного обеспечения. Генерируют операционную систему, в рамках которой предполагается функционирование СУБД, саму СУБД, необходимые компиляторы и обслуживающие утилиты. Аналитики, используя знания закономерностей определенной проблемной среды, строят ее математическую модель, привлекая необходимый математический инструментарий. Основная функция аналитика – представить задачу КП в форме некоторой формальной модели (“погрузить” задачу пользователя в математическую модель его проблемной области). Конечная цель аналитика – исходное представление задачи для прикладного программиста. Прикладной программист преобразует продукт деятельности аналитика в форму прикладной программы, предназначенной для реализации на ЭВМ. 3. Приведите схему уровней представления (абстракций) информационной системы. Схемы: · Схема концептуальная. Описание концептуальной модели предметной области средствами языка определения данными концептуального уровня архитектуры используемой СУБД. · Схема внешняя. Описание внешней модели предметной области средствами языка определения данными внешнего уровня архитектуры используемой СУБД. В одной системе баз данных СУБД может одновременно поддерживаться несколько внешних схем. · Схема внутренняя. Описание внутренней модели предметной области средствами языка определения хранимых данных выбранной СУБД. Иначе говоря, это описание организации базы данных в среде хранения данных используемой СУБД. В терминах перечисленных понятий рассмотрим схему одного из ранних (70-е – 80-е годы прошлого века) подходов в определении архитектуры информационной системы (рис. 7). На этой схеме выделены следующие уровни абстракции
Уровни представления информационной системы ЛПП (локальные пользовательские представления) - начальный уровень абстракции; соответствует представлениям о предметной области конечных пользователей на уровне руководителей подразделений (главный бухгалтер, начальник отдела кадров и т.п.). Инфологический (информационно-логический) – второй уровень. Представляет собой интеграцию ЛПП, соответствующую ”взгляду” на предметную область ее администратора (директора, президента фирмы, ректора вуза и т.п.). Администратор предметной области (не путать с администратором базы данных!) обозревает все множество информационных объектов, все возможные ассоциации между ними, в то время как каждый конечный пользователь просматривает лишь ограниченный фрагмент предметной области (бухгалтерия, цех, кадры и т.п.). 4. Дайте понятие инфологической модели. В чем отличие инфологической модели от концептуальной. Инфологическая модель предметной области - это описание структуры и поведения (динамики) предметной области в терминах, естественных и понятных пользователям разрабатываемой системы баз данных и учитывающих характер их информационных потребностей. Таким образом, ЛПП и инфологическое представление о предметной области определяет лишь информационные потребности разрабатываемой системы, отражает особенности предметной области, не затрагивая вопроса о способах отображения соответствующих данных в памяти ЭВМ. Инфологическая модель существует независимо от реализации системы, в частности, от выбора инструментария СУБД описание БД на концептуальном уровне задается на языке описания данных используемой СУБД в терминах и ограничениях, принятых в этой системе. Поскольку каждая СУБД поддерживает свою модель данных (свой инструментарий), описание единой инфологической модели предметной области в рамках разных СУБД приводит к разным (но, в идеале, эквивалентным) концептуальным схемам. Концептуальный уровень абстракции соответствует представлению о логической организации данных администратора базы данных. Этот уровень абстракции очень схож с инфологическим; его отличие состоит в привязке к средствам реализации, инструментарию СУБД, то есть модель предметной области разрабатываемой системы должна быть представлена в терминах (на языке описания данных) модели данных концептуального уровня (концептуальной модели) выбранной конкретной СУБД. Эту стадию называют логическим проектированием базы данных, а ее результатом является концептуальная схема базы данных. КОНТРОЛЬНЫЕ ВОПРОСЫ ПО РАЗДЕЛУ «Вопросы проектирования баз данных» 1. Перечислите и охарактеризуйте основные этапы жизненного цикла информационной системы. Как и любая другая, информационная система проходит во времени свой определенный жизненный цикл. В зависимости от целей исследования, в жизненном цикле БД можно определить различные последовательности этапов. С точки зрения проектировщика и пользователя согласно [2] выделим две фазы жизненного цикла базы данных: · анализ и проектирование – начальный (“бумажный”) этап жизни БД, · реализация и эксплуатация системы. Анализ и проектирование. Этап выполняется посредством изучения предметной области и требований, предъявляемых к создаваемой БД. На “бумажной” стадии жизни системы производится выбор: · структур данных и стратегии их хранения в памяти ЭВМ, · технологии обслуживания БД и взаимодействия с ней конечных пользователей, · технических и стандартных программных средств, а также разработка оригинальных программных средств обслуживания системы. Реализация и эксплуатация. Сущность реализации заключается в материализации проекта, в перенесении его в память ЭВМ. На этой стадии разрабатывается и отлаживается программное обеспечение информационной системы, создается отладочный вариант БД, разрабатываются многочисленные приложения. На стадии реализации тестируется и корректируется технология обслуживания информационной системы. Эксплуатация начинается с наполнения системы реальной информацией. Эта стадия жизненного цикла охватывает весь комплекс действий по поддержанию функционирования информационной системы:стадия эксплуатации включает в себя разработку новых приложений, а также совершенствование и последующее развитие системы.
2.
ПО-информация отображает объекты (процессы, явления, предметы) реального мира как составные части ПО (элементы ПО), их существенные свойства, а также взаимосвязи между этими элементами. Эта ПО-информация не связана ни с конкретными приложениями, ни с конкретным способом обработки, а описывает естественные концептуальные связи всех данных в БД. ПП-информация описывает данные и связи, используемые в приложениях. В общем случае в методологии построения инфологических моделей ПО-информация должна использоваться для построения первоначальной инфологической модели данных, а ПП-информация – для совершенствования последней с целью повышения эффективности обработки данных.
3. Приведите общую схему концептуального проектирования.
Пример объединения сущностей Общая структура процесса логического проектирования (включая этап инфологического проектирования) представлена схемой на рис.11. На основании этой схемы можно определить следующие основные этапы процесса концептуального проектирования.
4. Приведите общую схему процесса проектирования.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-03-31; Просмотров: 1826; Нарушение авторского права страницы
 Какова структура программы при использовании файловой системы управления информационными массивами.
Какова структура программы при использовании файловой системы управления информационными массивами.
 структуры с направленными и ненаправленными связями,
структуры с направленными и ненаправленными связями,
 структуры с односторонними и двусторонними связями,
структуры с односторонними и двусторонними связями,

 структуры с равноправными и неравноправными связями,
структуры с равноправными и неравноправными связями, Различают следующие основные виды связей между этими объектами:
Различают следующие основные виды связей между этими объектами: 

 СУБД (система управления базой данных) – сложная программная система накопления данных в БД и последующего манипулирования ими в интересах конечных пользователей. Каждой прикладной программе (ПП) или конечному пользователю СУБД возвращает только те данные из БД, которые необходимы для удовлетворения пришедшего запроса, причем в требуемой форме.
СУБД (система управления базой данных) – сложная программная система накопления данных в БД и последующего манипулирования ими в интересах конечных пользователей. Каждой прикладной программе (ПП) или конечному пользователю СУБД возвращает только те данные из БД, которые необходимы для удовлетворения пришедшего запроса, причем в требуемой форме.

 Приведите общую схему инфологического проектирования. Дайте понятие ПО- и ПП-информации и поясните смысл их использовании для процесса проектирования.
Приведите общую схему инфологического проектирования. Дайте понятие ПО- и ПП-информации и поясните смысл их использовании для процесса проектирования.

 На этапе логического проектирования разрабатывается логическая структура БД, соответствующая логической модели ПО. Решение этой задачи существенно зависит от модели данных, поддерживаемой выбранной СУБД. Результатом выполнения этого этапа являются схемы БД концептуального и внешнего уровней архитектуры, составленные на языках определения данных, поддерживаемых данной СУБД.
На этапе логического проектирования разрабатывается логическая структура БД, соответствующая логической модели ПО. Решение этой задачи существенно зависит от модели данных, поддерживаемой выбранной СУБД. Результатом выполнения этого этапа являются схемы БД концептуального и внешнего уровней архитектуры, составленные на языках определения данных, поддерживаемых данной СУБД.



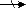 X.
X.
 Пример. Дерево определений, представляющее структуру университета (до определенного уровня)
Пример. Дерево определений, представляющее структуру университета (до определенного уровня)



 Существенное различие между сетевой и иерархической моделями данных состоит в том, что в сетевой модели каждая запись может участвовать в любом количестве наборов:
Существенное различие между сетевой и иерархической моделями данных состоит в том, что в сетевой модели каждая запись может участвовать в любом количестве наборов:


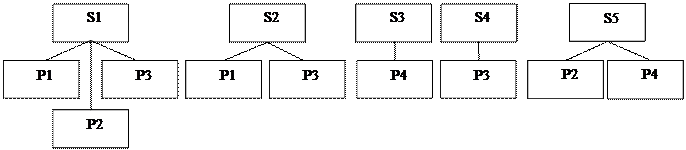
 ОС интерпретирует команды СУБД, взаимодействует с внешним запоминающим устройством, обнаруживая в БД требуемые записи. Отобранные записи передаются в системные буферы
ОС интерпретирует команды СУБД, взаимодействует с внешним запоминающим устройством, обнаруживая в БД требуемые записи. Отобранные записи передаются в системные буферы При успешном завершении СУБД обработки запроса приложение использует полученные данные для дальнейшей работы, в противном случае запрос должен быть повторен.
При успешном завершении СУБД обработки запроса приложение использует полученные данные для дальнейшей работы, в противном случае запрос должен быть повторен.
 Приведите общую классификацию методов доступа.
Приведите общую классификацию методов доступа.





 Пример 1. Расписание последовательное
Пример 1. Расписание последовательное T1 : W-B
T1 : W-B
 T2 : W-А
T2 : W-А
 T2 : W-А
T2 : W-А
