|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Приклади формулювань задач при використанні методів
OLAP і Data Mining
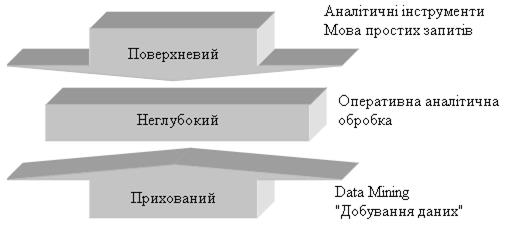
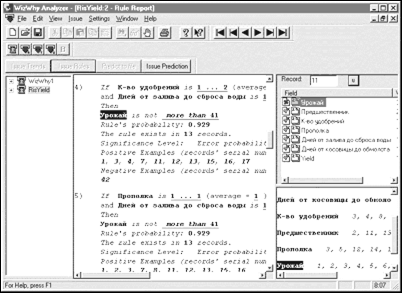
Важливе положення Data Mining − нетривіальність розшукуваних шаблонів. Це означає, що знайдені шаблони повинні відображати неочевидні, несподівані (unexpected) регулярності в даних, становлять так звані “приховані знання” (hidden knowledge). Суспільство дійшло розуміння, що “сирі” дані (raw data) містять глибинний пласт знань, при грамотній розкопці якого можуть бути знайдені справжні самородки (рис. 2.21). Рис. 2.21. Рівні знань, добування даних У цілому технологію Data Mining достатньо точно визначає Григорій Пятецький-Шапіро − один із засновників цього напряму: Data Mining − це процес виявлення в “сирих” даних раніше невідомих, нетривіальних; практично корисних і доступних інтерпретації знань, необхідних для ухвалення рішень в різних сферах людської діяльності. Сфера використання Data Mining нічим не обмежена − вона скрізь, де є які-небудь дані. Але в першу чергу методи Data Mining сьогодні, м'яко кажучи, заінтригували комерційні підприємства, що розгортають проекти на основі інформаційних СД (Data Warehousing). Досвід багатьох таких підприємств показує, що віддача від використовування Data Mining може досягати 1000%. Наприклад, відомі повідомлення про економічний ефект, що перевищив в 10-70 разів первинні витрати від 350 до 750 тис. дол. Відомі відомості про проект в 20 млн. дол., який окупився всього за 4 міс. Інший приклад − річна економія 700 тис. дол. за рахунок упровадження Data Mining в мережі універсамів у Великобританії. Data Mining представляють велику цінність для керівників і аналітиків в їх повсякденній діяльності. Ділові люди усвідомили, що за допомогою методів Data Mining вони можуть одержати відчутні переваги в конкурентній боротьбі. Стисло охарактеризуємо деякі можливі бізнес-додатки Data Mining. Роздрібна торгівля Підприємства роздрібної торгівлі на теперішній час збирають докладну інформацію про кожну окрему покупку, використовуючи кредитні картки з маркою магазина і комп'ютеризовані системи контролю. Ось типові задачі, які можна вирішувати за допомогою Data Mining у сфері роздрібної торгівлі: · аналізування “споживацького кошика” (схожості) призначено для виявлення товарів, які покупці прагнуть придбавати разом. Знання складу споживацького кошика необхідне для покращання реклами, вироблення стратегії створення запасів товарів і способів їх розкладки в торгових залах тощо; · дослідження тимчасових шаблонів допомагає торговим підприємствам ухвалювати рішення про створення товарних запасів і дає відповіді на питання типу “Якщо сьогодні покупець придбав відеокамеру, то через який час він найімовірніше купить нові батареї і плівку?”; · створення прогнозних моделей дає можливість торговим підприємствам взнавати характер потреб різних категорій клієнтів з певною поведінкою, наприклад, що купують товари відомих дизайнерів або відвідують розпродажі. Ці знання потрібні для розробки точно направлених, економічних заходів щодо просування товарів. Банківська справа Досягнення технології Data Mining використовуються в банківській справі для вирішення наступних поширених задач: · виявлення шахрайства з кредитними картками. Шляхом аналізу минулих транзакцій, які згодом виявилися шахрайськими, банк виявляє деякі стереотипи такого шахрайства; · сегментація клієнтів. Розбиваючи клієнтів на різні категорії, банки роблять свою маркетингову політику більш цілеспрямованою і результативною, пропонуючи різні види послуг різним групам клієнтів; · прогнозування змін клієнтури. Data Mining допомагає банкам будувати прогнозні моделі цінності своїх клієнтів і відповідним чином обслуговувати кожну категорію. Телекомунікації У галузі телекомунікацій методи Data Mining допомагають компаніям енергійніше просувати свої програми маркетингу і ціноутворення з метою утримання існуючих клієнтів і привертання нових. Серед типових заходів наголосимо на наступних: · аналізування записів про докладні характеристики викликів. Призначення такого аналізування − виявлення категорій клієнтів з схожими стереотипами користування їх послугами і розробка привабливих наборів цін і послуг; · виявлення лояльності клієнтів. Data Mining можна використовувати для визначення характеристик клієнтів, які, один раз скориставшися послугами даної компанії, з великою часткою ймовірності залишаться їй вірними. У результаті засоби, що виділяються на маркетинг, можна витрачати там, де віддача якнайбільше. Страхування Страхові компанії протягом ряду років накопичують великі обсяги даних. Тут обширне поле діяльності для методів Data Mining: · виявлення шахрайства. Страхові компанії можуть понизити рівень шахрайства, відшукуючи певні стереотипи в заявах про виплату страхового відшкодування, що характеризують взаємостосунки між юристами, лікарями і заявниками; · аналізування ризику. Шляхом виявлення поєднань чинників, пов'язаних із сплаченими заявами, страховики можуть зменшити свої втрати за зобов'язаннями. Data Mining може застосовуватися в безлічі інших галузей: · розвиток автомобільної промисловості. При збірці автомобілів виробники повинні враховувати вимоги кожного окремого клієнта, тому їм потрібні можливість прогнозування популярності певних характеристик і знання того, які характеристики звичайно замовляються разом; · політика гарантій. Виробникам потрібно передбачати число клієнтів, які подадуть гарантійні заявки, і середню вартість заявок; · заохочення клієнтів які часто літаючих. Авіакомпанії можуть знайти групу клієнтів, яких даними заохочувальними заходами можна спонукати літати частіше. Наприклад, одна авіакомпанія знайшла категорію клієнтів, які скоювали багато польотів на короткі відстані, не накопичуючи достатньо миль для вступу до їх клубів, тому вона таким чином змінила правила прийому в клуб, щоб заохочувати число польотів так само, як і милі. Медицина Відомо багато ЕС для постановки медичних діагнозів. Вони побудовані головним чином на основі правил, що описують поєднання різних симптомів різних захворювань. За допомогою таких правил визнають не тільки, на що хворий пацієнт, але і як потрібно його лікувати. Правила допомагають вибирати засоби медикаментозної дії, визначати лікування-протипоказання, орієнтуватися в лікувальних процедурах, створювати умови найефективнішого лікування, передбачати результати призначеного курсу лікування і т. ін. Технології Data Mining дозволяють знаходити в медичних даних шаблони, що становлять основу вказаних правил. Молекулярна генетика і генна інженерія Мабуть, найбільш гостро і, разом з тим, чітко задача виявлення закономірностей в експериментальних даних стоїть в молекулярній генетиці й генній інженерії. Тут вона формулюється як визначення так званих “маркерів”, під якими розуміють генетичні коди, контролюючі ті або інші фенотипічні ознаки живого організму. Такі коди можуть містити сотні, тисячі і більш зв'язаних елементів. На розвиток генетичних досліджень виділяються великі кошти. Останнім часом в даній галузі виник особливий інтерес до використання методів Data Mining. Відомо декілька крупних фірм, що спеціалізуються на використанні цих методів для розшифровки генома людини і рослин. Прикладна хімія Методи Data Mining знаходять широке застосування в прикладній хімії (органічної і неорганічної). Тут нерідко виникає питання про з'ясування особливостей хімічної будови тих або інших з'єднань, що визначають їх властивості. Особливо актуальна така задача при аналізуванні складних хімічних сполук, опис яких включає сотні і тисячі структурних елементів та їх зв'язків. Можна привести ще багато прикладів різних галузей знання, де методи Data Mining виконують провідну роль. Особливість цих сфер полягає в їх складній системній організації. Вони відносяться в основному до надкібернетичного рівня організації систем, закономірності якого не можуть бути достатньо точно описані мовою статистичних або інших аналітико-математичних моделей. Дані у наведених галузях неоднорідні, гетерогенні, нестаціонарні і часто відрізняються високою розмірністю. Виділяють п'ять стандартних типів закономірностей, які дозволяють виявляти методи Data Mining: асоціація, послідовність, класифікація, кластеризація і прогнозування. Асоціація має місце в тому випадку, якщо декілька подій взаємопов'язані. Наприклад, дослідження, проведене в супермаркеті, може показати, що 65% покупців кукурудзяні чіпси, беруть також і “кока-колу”, а за наявності знижки за такий комплект “колу” купують в 85% випадках. Маючи в розпорядженні відомості про подібну асоціацію, менеджерам легко оцінити, наскільки дієва знижка, надана на товари. Якщо існує ланцюжок пов'язаних в часі подій, то визначають послідовність. Так, після купівлі будинку в 45% випадків протягом місяця купується нова кухонна плита, а в межах двох тижнів 60% новоселів обзаводяться холодильником. За допомогою класифікації виявляються ознаки, що характеризують групу, до якої належить той або інший об'єкт. Це робиться з допомогою аналізування вже класифікованих об'єктів і формулювання деякого набору правил. Кластеризація відрізняється від класифікації тим, що самі групи наперед не задані. З допомогою кластеризації засоби Data Mining самостійно виділяють різні однорідні групи даних. Основою для всіляких систем прогнозування служить історична інформація, що зберігається в БД у вигляді тимчасових рядів. Якщо вдається побудувати чи знайти шаблони поведінки цільових показників, що адекватно відображають динаміку, є вірогідність, що з їх допомогою можна передбачити і поведінку системи в майбутньому. Дерева рішень є одним з найпопулярніших підходів до рішення задач Data Mining. Вони створюють ієрархічну структуру класифікованих правил типу “ЯКЩО... ТО...” (if-then), що має вид “дерева”. Для ухвалення рішення, до якого класу віднести деякий об'єкт або ситуацію, вимагається відповісти на питання, що стоять у вузлах цього “дерева”, починаючи з його коріння. Питання мають вигляд “значення параметра А більше x?”. Якщо відповідь позитивна, здійснюється перехід до правого вузла наступного рівня; якщо негативний − то до лівого вузла; потім знову слідує питання, пов'язане з відповідним вузлом. Популярність підходу пов'язана з наочністю і зрозумілістю. Але “дерева рішень” принципово не здатні знаходити “кращі” (якнайповніші та точніші) правила в даних. Вони реалізують наївний принцип послідовного перегляду ознак і “чіпляють” фактично осколки справжніх закономірностей, створюючи лише ілюзію логічного висновку. Разом з тим, більшість систем використовує саме цей метод. Найвідомішими є See5/С5.0 (RuleQuest, Австралія), Clementine (Integral Solutions, Великобританія), SIPINA (University Lyon, Франція), IDIS (Information Discovery, США), KnowledgeSeeker (ANGOSS, Канада). Вартість цих систем варіюється від 1 до 10 тис. дол. Рис. 2.22. Обробка банківської інформації системою KnowledgeSeeker Еволюційне програмування. Проілюструємо сучасний стан даного підходу на прикладі системи PolyAnalyst − вітчизняній розробці, що одержала сьогодні загальне визнання на ринку Data Mining. В даній системі гіпотези про вигляд залежності цільової змінної від інших змінних реалізується у вигляді програм деякою внутрішньою мовою програмування. Процес побудови програм будується як еволюція в світі програм (цим підхід трохи схожий на генетичні алгоритми). Коли система знаходить програму, що більш-менш задовільно виражає шукану залежність, вона починає вносити в неї невеликі модифікації і відбирає серед побудованих дочірніх програм ті, які підвищують точність. Таким чином, система “вирощує” декілька генетичних ліній програм, які конкурують між собою в точності виразу шуканої залежності. Спеціальний модуль системи PolyAnalyst перекладає знайдені залежності з внутрішньої мови системи на зрозумілу користувачу мову (математичні формули, таблиці й ін.). Інший напрям еволюційного програмування пов'язаний з пошуком залежності цільових змінних від інших у формі функцій якогось певного вигляду. Наприклад, в одному з найвдаліших алгоритмів цього типу − методі групового обліку аргументів (МГОА) залежність шукають у формі поліномів. В даний час з систем, що продаються в Росії, МГОА реалізований в системі NeuroShell компанії Ward Systems Group. Генетичні алгоритми . Data Mining не основна галузь використання генетичних алгоритмів. Їх потрібно розглядати, швидше, як могутній засіб вирішення різноманітних комбінаторних задач і задач оптимізації. Проте генетичні алгоритми увійшли зараз до стандартного інструментарію методів Data Mining, тому вони і включені в даний огляд. Перший крок при побудові генетичних алгоритмів − це кодування початкових логічних закономірностей в БД, які іменують хромосомами, а весь набір таких закономірностей – популяцією хромосом. Далі для реалізації концепції відбору вводиться спосіб зіставлення різних хромосом. Популяція обробляється з допомогою процедур репродукції, мінливості (мутацій), генетичної композиції. Ці процедури імітують біологічні процеси. Найважливіші серед них: випадкові мутації даних в індивідуальних хромосомах, переходи (кросинговер) і рекомбінація генетичного матеріалу, що міститься в індивідуальних батьківських хромосомах (аналогічно гетеросексуальній репродукції), і міграції генів. В ході роботи процедур на кожній стадії еволюції виходять популяції зі все більш досконалими індивідумами. Генетичні алгоритми зручні тим, що їх легко розпаралелювати. Наприклад, можна розбити покоління на декілька груп і працювати з кожною з них незалежно, обмінюючись час від часу декількома хромосомами. Існують також й інші методи розпаралелювання генетичних алгоритмів. Генетичні алгоритми мають ряд недоліків. Критерій відбору хромосом і використовувані процедури є евристичними і далеко не гарантують знаходження “кращого” рішення. Як і в реальному житті, еволюцію може “заклинити” на якій-небудь непродуктивній гілці. І, навпаки, можна привести приклади, як два неперспективних батьки, які будуть виключені з еволюції генетичним алгоритмом, виявляються здатними надати високоефективного нащадка. Це особливо стає помітно при вирішенні високорозмірних задач з складними внутрішніми зв'язками. Прикладом може служити система GeneHunter фірми Ward Systems Group. Алгоритми обмеженого перебору. Алгоритми обмеженого перебору були запропоновані в середині 60-х років XX ст. М.М. Бонгардом для пошуку логічних закономірностей в даних. З тих пір вони продемонстрували свою ефективність при рішенні безліччі задач з самих різних сфер. Ці алгоритми обчислюють частоти комбінацій простих логічних подій в підгрупах даних. Приклади простих логічних подій: X = а; X < b; X >а; а < X < b і ін., де X − якийсь параметр; “a” і “b” − константи. Обмеженням служить довжина комбінації простих логічних подій (наприклад 3). На підставі аналізу обчислених частот робиться висновок про корисність тієї або іншої комбінації для встановлення асоціації в даних, для класифікації, прогнозування й ін. Найяскравішим сучасним представником наведеного підходу є система WizWhy підприємства WizSoft. Хоча автор системи Абрам Мейдан не розкриває специфіку алгоритму, встановленого в основу роботи WizWhy, за наслідками ретельного тестування системи були зроблені висновки про наявність тут обмеженого перебору. Автор WizWhy стверджує, що його система знаходить всі логічні if-then правила в даних. Насправді це, звичайно, не так. По-перше, максимальна довжина комбінації в if-then правила в системі WizWhy рівна 6, і, по-друге, з самого початку роботи алгоритму проводиться евристичний пошук простих логічних подій, на яких потім будується весь подальший аналіз. Зрозумівши ці особливості WizWhy, неважко було запропонувати просту тестову задачу, яку система не змогла взагалі вирішити. Інший момент − система видає рішення за прийнятний час тільки для порівняно невеликої розмірності даних. Проте, система WizWhy є на теперішній час одним з лідерів на ринку продуктів Data Mining. Це не позбавлено підстав. Система постійно демонструє вищі показники при рішенні практичних задач, ніж вся решта алгоритмів (рис. 2.23). Рис. 2.23. Система WizWhy, яка знайшла правила, що пояснюють врожайність деяких сільськогосподарських ділянок Системи для візуалізації багатовимірних даних . Тою чи іншою мірою засоби для графічного відображення даних підтримуються всіма системами Data Mining. Разом з тим, вельми значну частку ринку займають системи, що спеціалізуються винятково на цій функції. Прикладом тут може служити програма DataMiner 3D словацької фірми Dimension5 (5-е вимірювання). У аналогічних системах основна увага сконцентрована на доброзичливості призначеного для користувача інтерфейсу, що дозволяє асоціювати з аналізованими показниками різні параметри діаграми розсіювання об'єктів (записів) БД. До таких параметрів відносяться колір, форма, орієнтація щодо власної осі, розміри й інші властивості графічних елементів зображення. Крім того, системи візуалізації даних забезпечені зручними засобами для масштабування і обертання зображень. Вартість систем візуалізації може досягати декількох сотень доларів (рис. 2.24).
Рис. 2.24. Візуалізація даних системою DataMiner 3D Ринок систем Data Mining експоненціально розвивається. В цьому розвитку беруть участь практично всі найбільші корпорації. Зокрема, Microsoft безпосередньо керує великим сектором даного ринку (видає спеціальний журнал, проводить конференції, розробляє власний продукт). Системи Data Mining застосовуються по двох основних напрямках: 1) як масовий продукт для бізнес-додатків; 2) як інструменти для проведення унікальних досліджень (генетика, хімія, медицина й ін.). В даний час вартість масового продукту від $1000 до $10 000. Кількість інсталяцій масових продуктів, судячи за наявними відомостями, сьогодні досягає десятків тисяч. Лідери Data Mining пов'язують майбутнє цих систем з використанням їх як інтелектуальних додатків, вбудованих в корпоративні СД. Не зважаючи на велику кількість методів Data Mining, пріоритет поступово все більш зміщується у бік логічних алгоритмів пошуку в даних if-then правил. З їх допомогою вирішуються задачі прогнозування, класифікації, розпізнавання образів, сегментації БД, витягання з даних “прихованих” знань, інтерпретації даних, встановлення асоціацій в БД й ін. Результати таких алгоритмів ефективні та легко інтерпретуються. Разом з тим, основною проблемою логічних методів виявлення закономірностей є проблема перебору варіантів за прийнятний час. Відомі методи або штучно обмежують такий перебір (алгоритми КОРА, WizWhy), або будують дерева рішень (алгоритми CART, CHAID, ID3, See5, Sipina й ін.), що мають принципові обмеження ефективності пошуку if-then правил. Інші проблеми пов'язані з тим, що відомі методи пошуку логічних правил не підтримують функцію узагальнення знайдених правил і функцію пошуку оптимальної композиції таких правил. Вдале рішення вказаних проблем може скласти предмет нових конкурентних розробок. GRID -т ехнологія Технологія Грід (Grid) використовується для створення географічно розподіленої обчислювальної інфраструктури, об'єднуючої ресурси різних типів з колективним доступом до цих ресурсів в рамках віртуальних організацій, що складаються з підприємств і фахівців, які спільно використовують ці загальні ресурси. Термін Grid (сітка, грати) почав використовуватися з середини 90-х років і був вибраний за аналогією з мережами передачі та розподілу електроенергії (Power Grids). Розвиток і впровадження технології Грід мають стратегічний характер. У найближчій перспективі ця технологія дозволить створити принципово новий обчислювальний інструмент для розвитку високих технологій в різних сферах людської діяльності. Ідейною основою технології Грід є об'єднання ресурсів шляхом створення комп'ютерної інфраструктури нового типу, що забезпечує глобальну інтеграцію інформаційних і обчислювальних ресурсів на основі мережевих технологій і спеціального програмного забезпечення проміжного рівня (між базовим і прикладним ПЗ), а також набору стандартизованих служб для забезпечення надійного спільного доступу до географічно розподілених інформаційних і обчислювальних ресурсів: окремим комп'ютерам, кластерам, сховищам інформації й мережам. Поява технології Грід обумовлена наступними передумовами: · наявністю в багатьох організаціях обчислювальних ресурсів: суперкомп'ютерів або, що найчастіше зустрічається, організованих у вигляді кластерів ПК; · необхідністю рішення складних наукових, виробничих, інженерних і завдань бізнесу; · стрімким розвитком мережевого транспортного середовища і технологій високошвидкісної передачі даних. Застосування технології Грід може забезпечити новий якісний рівень, а іноді і реалізувати принципово новий підхід в обробці величезних обсягів експериментальних даних, забезпечити моделювання складних процесів, візуалізацію великих наборів даних, складні додатки бізнесу з великими обсягами обчислень. До теперішнього часу вже реалізовані і далі реалізуються безліч проектів по створенню Грід-систем. Велика частина цих проектів має експериментальний характер. Виходячи з результатів аналізу проектів можна зробити висновок про три напрямки розвитку технології Грід: обчислювальний Грід, Грід для інтенсивної обробки даних і семантичний Грід для операцій даними з різних БД. Метою першого напрямку є досягнення максимальної швидкості обчислень за рахунок глобального розподілу цих обчислень між комп'ютерами. Проект DEISA (www.desia.org) може служити прикладом цього напрямку, в якому робиться спроба об'єднання суперкомп'ютерних центрів. Метою другого напрямку є обробка величезних обсягів даних відносно нескладними програмами за принципом “одне завдання – один процесор”. Доставка даних для обробки і пересилання результатів в цьому випадку є достатньо складним завданням. Для цього напряму інфраструктура Грід є об'єднанням кластерів. Один з проектів, метою якого і є створення виробничої Грід-системи для обробки наукових даних, є проект EGEE (Enabling Grids for E-sciencE), виконуваний під егідою Європейського Союзу (www.eu-egee.org). Учасниками цього проекту є більше 90 наукових і освітніх установ зі всього світу. Побудова інфраструктури Грід в рамках проекту EGEE орієнтована, в першу чергу, на застосування в різних галузях наукової діяльності, у тому числі і для обробки даних у фізиці високих енергій учасниками експериментів, що проводяться на базі створюваного в Європейському центрі ядерних досліджень (CERN, www.cern.ch) прискорювача LHС. Проект EGEE тісно пов'язаний на даній фазі розвитку з проектом LCG (LHC Computing Grid), який, по суті, і є його технологічною базою. Ведеться активна робота по розширенню інфраструктури Грід (RDIG, www.egee-rdig.ru). Не зважаючи на достатньо тісну взаємодію багатьох проектів, конкретні реалізації Грід-систем відрізняються одна від одної, хоча до теперішнього часу з достатньою визначеністю почала спостерігатися тенденція стандартизації більшості компонентів, що означає найважливіший етап формування технології Грід (архітектура, протоколи, сервіси й ін.). З найзагальніших позицій ця технологія характеризується простим набором критеріїв: · координація використання ресурсів за відсутності централізованого управління цими ресурсами; · використання стандартних, відкритих, універсальних протоколів і інтерфейсів; · забезпечення високоякісного обслуговування користувачів. Концепція Грід. Грід є технологією забезпечення гнучкого, безпечного і скоординованого загального доступу до ресурсів. При цьому термін “ресурс” розуміється в дуже широкому сенсі, тобто ресурсом може бути апаратура (жорсткі диски, процесори), а також системне і прикладне ПЗ (бібліотеки, додатки). У термінології Грід сукупність людей і організацій, вирішуючих спільно те або інше загальне завдання і що надають один одному свої ресурси, має назву віртуальна організація (ВО). Наприклад, віртуальною організацією може бути сукупність всіх, що беруть участь в якій-небудь науковій колаборації [фр. collaboration –співробітництво]. Віртуальні організації можуть розрізнятися за складом, масштабом, часом існування, родом діяльності, цілями, відносинам між учасниками (довірчі, не довірчі) і т.д. Склад віртуальних організацій може динамічно мінятися. Є два основних критерії, що виділяють Грід-системи серед інших систем, які забезпечують доступ до ресурсів, що розділяються: 1. Грід-система координує розрізнені ресурси. Ресурси не мають загального центру управління, а Грід-система займається координацією їх використання, наприклад балансуванням навантаження. Тому проста система управління ресурсами кластера не є системою Грід, оскільки здійснює централізоване керування всіма вузлами даного кластера, маючи до них повний доступ. Грід-системи мають лише обмежений доступ до ресурсів, залежних від політики того адміністративного домену (організації-власника), в якому цей ресурс знаходиться. 2. Грід-система будується на базі стандартних і відкритих протоколів, сервісів та інтерфейсів. Не маючи стандартних протоколів, неможливо легко і швидко підключати нові ресурси до Грід-системи, розробляти новий вигляд сервісів і т.д. Додамо ще декілька властивостей, якими звичайно володіють Грід-системи: · гарантії якості обслуговування; · гнучка і могутня підсистема безпеки: стійкість до атак зловмисників, забезпечення конфіденційності; · гнучкість, тобто можливість забезпечення доступу, що розділяється, потенційно до будь-яких видів ресурсів; · масштабованість: працездатність Грід-системи при значному збільшенні або зменшенні її складу; · можливість контролю над ресурсами: застосування локальних і глобальних політик і квот; · можливість одночасної, скоординованої роботи з декількома ресурсами. Хоча сама технологія Грід не прив'язана до певних ресурсів, найчастіше реалізація Грід-систем забезпечують роботу з наступними типами ресурсів: · обчислювальні ресурси – окремі комп'ютери, кластери; · ресурси зберігання даних – диски і дискові масиви, стрічки, системи масового зберігання даних; · мережеві ресурси; · програмне забезпечення – яке-небудь спеціалізоване ПЗ. Відзначимо різницю між технологією Грід і реалізаціями Грід-систем. Технологія Грід включає лише найбільш загальні та універсальні аспекти, однакові для будь-якої системи (архітектура, протоколи, інтерфейси, сервіси). Використовуючи цю технологію і наповнюючи її конкретним змістом, можна реалізувати ту або іншу Грід-систему, призначену для вирішення того або іншого класу прикладних задач. Не варто змішувати технологію Грід з технологією паралельних обчислень. В рамках конкретної Грід-системи, звичайно, можливо організувати паралельні обчислення з використанням існуючих технологій (PVM, MPI), оскільки Грід-систему можна розглядати як якийсь мета-комп'ютер, що має безліч обчислювальних вузлів. Проте технологія Грід не є технологією паралельних обчислень, в її завдання входить лише координація використання ресурсів. Архітектура Грід. Архітектура Грід визначає системні компоненти, цілі і функції цих компонентів і відображає способи їх взаємодії. Архітектура Грід є архітектурою взаємодіючих протоколів, сервісів і інтерфейсів, що визначають базові механізми, за допомогою яких користувачі встановлюють з'єднання з Грід-системою, спільно використовують обчислювальні ресурси для вирішення різного роду завдань. Архітектура протоколів Грід розділена на рівні (рис. 2.25), компоненти кожного з яких можуть використовувати можливості компонентів будь-якого з розташованих нижче рівнів. В цілому ця архітектура задає вимоги для основних компонентів технології (протоколів, сервісів, прикладних інтерфейсів і засобів розробки ПЗ), не надаючи строгий набір специфікацій, залишаючи можливість їх розвитку в рамках прийнятої концепції. Рис. 2.25. Рівні архітектури протоколів Грід та їх відповідність рівням архітектури протоколів Інтернет
Базовий рівень (Fabric Layer) описує служби, безпосередньо працюючи з ресурсами. Ресурс є одним з основних понять архітектури Грід. Ресурси можуть бути вельми різноманітними, проте, як вже відмічалося, можна виділити декілька основних типів (рис. 2.26): · обчислювальні ресурси; · ресурси зберігання даних; · інформаційні ресурси, каталоги; · мережеві ресурси. Обчислювальні ресурси надають користувачу Грід-системи процесорні потужності. Обчислювальними ресурсами можуть бути як кластери, так і окремі робочі станції. При всій різноманітності архітектури будь-яка обчислювальна система може розглядатися як потенційний обчислювальний ресурс Грід-системи. Необхідною умовою для цього є наявність спеціального ПЗ, так званого “проміжного рівня” (middleware), що реалізує стандартний зовнішній інтерфейс з ресурсом і що дозволяє зробити ресурс доступним для Грід-системи. Основною характеристикою обчислювального ресурсу є продуктивність. Ресурси пам'яті є простором для зберігання даних. Для доступу до ресурсів пам'яті також використовується ПЗ проміжного рівня, що реалізує уніфікований інтерфейс управління і передачі даних. Як і у обчислювальних ресурсів, фізична архітектура ресурсу пам'яті не принципова для Грід-системи, будь то жорсткий диск на робочій станції або система масового зберігання даних на сотні терабайт. Основною характеристикою ресурсу пам'яті є його обсяг. Інформаційні ресурси і каталоги є особливим видом ресурсів пам'яті. Вони служать для зберігання і надання метаданих й інформації про інші ресурси Грід-системи. Інформаційні ресурси дозволяють структуровано зберігати величезний обсяг інформації про поточний стан Грід-системи і ефективно виконувати завдання пошуку. Мережевий ресурс є сполучною ланкою між розподіленими ресурсами Грід-системи. Основною характеристикою мережевого ресурсу є швидкість передачі даних. Географічно розподілені системи на основі даної технології здатні об'єднувати тисячі ресурсів різного типа, незалежно від їх географічного положення. Рівень зв'язку. Рівень зв'язку (Connectivity Layer) визначає комунікаційні протоколи і протоколи аутентифікації. Комунікаційні протоколи забезпечують обмін даними між компонентами базового рівня. Протоколи аутентифікації, грунтуючись на комунікаційних протоколах, надають криптографічні механізми для ідентифікації й перевірки достовірності користувачів і ресурсів. Протоколи рівня зв'язку повинні забезпечувати надійне транспортування і маршрутизацію повідомлень, а також привласнення імен об'єктам мережі. Не зважаючи на існуючі альтернативи, зараз протоколи рівня зв'язку в Грід-системах припускають використання тільки стека протоколів TCP/IP, зокрема: на мережевому рівні – IP і ICMP, транспортному рівні – TCP, UDP; прикладному рівні – HTTP, FTP, DNS, RSVP. Враховуючи бурхливий розвиток мережевих технологій, в майбутньому рівень зв'язку, можливо, залежатиме і від інших протоколів. Для забезпечення надійного транспортування повідомлень в Грід-системі повинні використовуватися рішення, що передбачають гнучкий підхід до безпеки комунікацій (можливість контролю над рівнем захисту, обмеження делегування прав, підтримка надійних транспортних протоколів). В теперішній час ці рішення грунтуються як на існуючих стандартах безпеки, спочатку розроблених Інтернет (SSL, TLS), так і на нових розробках. Ресурсний рівень. Ресурсний рівень (Resource Layer) побудований над протоколами комунікації й аутентифікації рівня зв'язку архітектури Грід. Ресурсний рівень реалізує протоколи, що забезпечують виконання наступних функцій: · узгодження політик безпеки використання ресурсу; · процедура ініціації ресурсу; · моніторинг стану ресурсу; · контроль над ресурсом; · облік використання ресурсу. Протоколи цього рівня спираються на функції базового рівня для доступу і контролю над локальними ресурсами. На ресурсному рівні протоколи взаємодіють з ресурсами, використовуючи уніфікований інтерфейс і не розрізняючи архітектурні особливості конкретного ресурсу. Розрізняють два основних класи протоколів ресурсного рівня: 1. інформаційні протоколи, які одержують інформацію про структуру і стан ресурсу, наприклад про його конфігурацію, поточне завантаження, політику використання; 2. протоколи управління, використовувані для узгодження доступу до ресурсів, що розділяються, визначаючи вимоги і допустимі дії відносно до ресурсу (наприклад, підтримка резервування, можливість створення процесів, доступ до даних). Протоколи управління повинні перевіряти відповідність запрошуваних дій політиці розділення ресурсу, включаючи облік і можливу оплату. Вони можуть підтримувати функції моніторингу статусу і управління операціями. Список вимог до функціональності протоколів ресурсного рівня близький до списку для базового рівня архітектури Грід. Додалася лише вимога єдиної семантики для різних операцій з підтримкою системи сповіщення про помилки. Колективний рівень. Колективний рівень (Collective Layer) відповідає за глобальну інтеграцію різних наборів ресурсів, на відміну від ресурсного рівня, сфокусованого на роботі з окремо взятими ресурсами. У колективному рівні розрізняють загальні і специфічні (для додатків) протоколи. До загальних протоколів відносяться, в першу чергу, протоколи виявлення і виділення ресурсів, системи моніторингу і авторизації співтовариств. Специфічні протоколи створюються для різних додатків Грід (наприклад, протокол архівації розподілених даних або протоколи управління завданнями збереження стану і т.п.). Компоненти колективного рівня пропонують величезну різноманітність методів спільного використання ресурсів. Нижче приведені функції й сервіси, реалізовані в протоколах даного рівня: · сервіси каталогів дозволяють віртуальним організаціям виявляти вільні ресурси, виконувати запити по іменах і атрибутах ресурсів, таким як тип і завантаження; · сервіси спільного виділення, планування і розподілу ресурсів забезпечують виділення одного або більш ресурсів для певної мети, а також планування виконуваних на ресурсах завдань; · сервіси моніторингу і діагностики відстежують аварії, атаки і перевантаження; · сервіси дублювання (реплікації) даних координують використання ресурсів пам'яті в рамках віртуальних організацій, забезпечуючи підвищення швидкості доступу до даних відповідно до вибраних метрик, такими як час відповіді, надійність, вартість і т.п.; · сервіси управління робочим завантаженням застосовуються для опису і управління багатокроковими, асинхронними, багатокомпонентними завданнями; · служби авторизації співтовариств сприяють поліпшенню правил доступу до ресурсів, що розділяються, а також визначають можливості використання ресурсів співтовариства. Подібні служби дозволяють формувати політики доступу на основі інформації про ресурси, протоколи управління ресурсами і протоколи безпеки зв'язуючого рівня; · служби обліку і оплати забезпечують збір інформації про використання ресурсів для контролю звернень користувачів; · сервіси координації підтримують обмін інформацією в потенційно великому співтоваристві користувачів. Прикладний рівень. Прикладний рівень (Application Layer) описує призначені для користувача додатки, що працюють в середовищі віртуальної організації. Додатки функціонують, використовуючи сервіси, визначені на рівнях що пролягають нижче. На кожному з рівнів є певні протоколи, що забезпечують доступ до необхідних служб, а також прикладні програмні інтерфейси (Application Programming Interface – API), відповідні даним протоколам. Для полегшення роботи з прикладними програмними інтерфейсами користувачам надаються набори інструментальних засобів для розробки ПЗ (Software Development Kit – SDK). Набори інструментальних засобів високого рівня можуть забезпечувати функціональність з одночасним використанням декількох протоколів, а також комбінувати операції протоколів з додатковими викликами прикладних програмних інтерфейсів нижнього рівня. Варто звернути увагу, що додатки на практиці можуть викликатися через достатньо складні оболонки і бібліотеки. Ці оболонки самі можуть визначати протоколи, сервіси і прикладні програмні інтерфейси, проте подібні надбудови не відносяться до фундаментальних протоколів і сервісів, необхідним для побудови Грід-систем. Розподіл ресурсів в Грід. Ефективний розподіл ресурсів і їх координація є основними завданнями системи Грід, і для їх вирішення використовується планувальник (брокер ресурсів). Користуючись інформацією про стан Грід-системи, планувальника визначає найбільш відповідні ресурси для кожного конкретного завдання і резервує їх для її виконання. Під час виконання завдання може запросити у планувальника додаткові ресурси або звільнити надмірні. Після завершення завдання всі відведені для неї обчислювальні ресурси звільняються, а ресурси пам'яті можуть бути використані для зберігання результатів роботи. Важливою властивістю систем Грід є те, що користувачу не потрібно знати про фізичне розташування ресурсів, відведених його завданню. Вся робота по управлінню, перерозподілу і оптимізації використання ресурсів лягає на планувальник і виконується непомітно для користувача. Для користувача створюється ілюзія роботи в єдиному інформаційному просторі, що володіє величезними обчислювальними потужностями і обсягом пам'яті. Грід є найбільш складним інформаційним середовищем, коли-небудь створюваним людиною. Для системи такої складності дуже важлива проблема забезпечення надійного функціонування і відновлення при збоях. Людина не здатна встежити за станом тисяч різних ресурсів, що входять в Грід-систему, і з цієї причини завдання контролю над помилками покладається на систему моніторингу, яка стежить за станом окремих ресурсів. Дані про стан заносяться в інформаційні ресурси, звідки вони можуть бути прочитані планувальником та іншими сервісами, що дозволяє мати достовірну інформацію про стан ресурсів, що постійно оновлюються. У Грід-системах використовується складна система виявлення і класифікації помилок. Якщо помилка відбулася з вини завдання, то завдання буде зупинене, а відповідна діагностика направлена її власнику (користувачу). Якщо причиною збою послужив ресурс, то планувальник проведе перерозподіл ресурсів для даного завдання і перезапустить її. Збої ресурсів є не єдиною причиною відмов в Грід-системах. Через величезну кількість завдань і постійно змінну складну конфігурацію системи важливо своєчасно визначати переобтяжені і вільні ресурси, проводячи перерозподіл навантаження між ними. Переобтяжений мережевий ресурс може стати причиною відмови значної кількості інших ресурсів. Планувальник, використовуючи систему моніторингу, постійно стежить за станом ресурсів і автоматично вживає необхідні заходи для запобігання перевантаженням і простою ресурсів. У розподіленому середовищі, якою є Грід-система, життєво важливою властивістю є відсутність так званої “єдиної точки збою”. Це означає, що відмова будь-якого ресурсу не повинна приводи до збою в роботі всієї системи. Саме тому планувальник, система моніторингу й інші сервіси Грід-системи розподілені й продубльовані. Не зважаючи на всю складність, архітектура Грід розроблялася з метою забезпечення максимальної якості сервісу для користувачів. У Грід-системах використовуються сучасні технології передачі даних, забезпечення безпеки і відмовостійкості. Інструментальні засоби Грід ( Globus Toolkit). У цьому розділі буде розглянутий набір інструментальних засобів, використовуваних при реалізації проектів Грід і розроблених в рамках проекту Глобус (Globus Project). Ці інструментальні засоби утворюють набір програмних засобів Globus Toolkit і дозволяють побудувати повнофункціональну Грід-систему. Засоби Globus Toolkit є сукупністю програмних компонентів, що реалізують необхідні частини архітектури. Globus Toolkit складається з наступних основних компонентів: · GRAM (Globus Resource Allocation Manager) відповідальний за створення процесів. Цей компонент Globus Toolkit встановлюється на обчислювальному вузлі Грід-системи (вузлом може бути як робоча станція, так і обчислювальний кластер). Призначені для користувача додатки формують запити до GRAM спеціальною мовою RSL (Resource Specification Language); · MDS (Monitoring and Discovery Service) забезпечує способи представлення інформації про Грід-систему. Ця інформація може бути найрізноманітнішою і містити, наприклад, дані про конфігурацію або стан як всієї системи, так і окремих її ресурсів (тип ресурсу, доступний дисковий простір, кількість процесорів, обсяг пам'яті, продуктивність q ін.). Вся інформація логічно організована у вигляді “дерева”, і доступ до неї здійснюється за стандартним протоколом LDAP (Lightweight Directory Access Protocol); · GSI (Globus Security Infrastructure) забезпечує захист, що включає шифрування даних, а також аутентифікацію (перевірка достовірності, при якій встановлюється, що користувач або ресурс дійсно є тим, за кого себе видає) і авторизацію (процедура перевірки, при якій встановлюється, що аутентифікований користувач або ресурс дійсно має право доступу, що зажадалися) з використанням цифрових сертифікатів Х.509; · GASS (Global Access to Secondary Storage) надає можливість зберігання масивів даних в розподіленому оточенні і доступу до цих даних. Визначає різні стратегії розміщення даних; · Бібліотеки globus _ io і Nexus використовуються як прикладними програмами, так і компонентами Globus Toolkit для мережевої взаємодії вузлів в гетерогенному середовищі. Далі детальніше розглянуті деякі з цих компонентів. Варто зазначити, що Globus Toolkit не містить брокера ресурсів, залишаючи завдання його реалізації розробникам, що створюють системи Грід на його основі. Управління ресурсами. Архітектура засобів управління ресурсами (Globus Resource Management Architecture – GRMA) має багаторівневу структуру (рис. 2.27). Запити призначених для користувача додатків виражаються на RSL і передаються брокеру ресурсів, який відповідає за високорівневу координацію користування ресурсами (балансування завантаження) в певному домені. На основі переданого призначеним для користувача додаткам запиту і політики (права доступу, обмеження використання ресурсів) відповідального адміністративного домена брокер ресурсів ухвалює рішення про те, на яких обчислювальних вузлах виконуватиметься завдання, який відсоток обчислювальної потужності вузла вона може використовувати й ін. При виборі обчислювального вузла брокер ресурсів повинен визначити, які вузли доступні у теперішній момент, їх завантаження, продуктивність та інші параметри, вказані в RSL-запиті; вибрати найбільш оптимальний варіант (це може опинитися один обчислювальний вузол або декілька); згенерувати новий RSL-запит (ground RSL) і передати його високорівневому менеджеру ресурсів (co-allocator). Цей запит міститиме вже конкретніші дані, такі, як імена конкретних вузлів, необхідна кількість пам'яті й ін. Основні функції високорівневого менеджера ресурсів: колективне виділення ресурсів; додавання/видалення ресурсів до раніше виділених; отримання інформації про стан завдань; передача початкових параметрів завданням.
Рис. 2.27. Архітектура засобів управління ресурсами Високорівневий менеджер ресурсів проводить декомпозицію запитів ground RSL на безліч простіших RSL-запитів і передає ці запити GRAM. Далі, за відсутності повідомлень про помилки від GRAM, завдання користувача запускається на виконання. У разі, якщо один з GRAM повертає помилку, завдання або знімається з виконання, або спроба запуску проводиться повторно. Менеджер GRAM надає верхнім рівням універсальний API для управління ресурсами вузла Грід. Сам GRAM взаємодіє з локальними засобами управління ресурсами вузла. Вузлом може бути, наприклад, робоча станція або обчислювальний кластер. Організація доступу до ресурсів. GRAM – достатньо низькорівневий компонент Globus Toolkit, що є інтерфейсом між високорівневим менеджером ресурсів і локальною системою управління ресурсами вузла. В даний час цей інтерфейс може взаємодіяти з наступними локальними системами управління ресурсами: · PBS (Portable Batch System) – система управління ресурсами і завантаженням кластерів. Може працювати на великому числі різних платформ: Linux, FreeBSD, NetBSD, Digital Unix Tru64, HP-UX, AIX, IRIX, Solaris. В теперішній час існує вільна і наділена ширшими можливостями реалізація PBS, звана Torque; · LSF (Load Sharing Facility) – система, аналогічна PBS. Розроблена компанією Platform Computing. Також здатна працювати на безлічі платформ; · NQE (Network Queuing Environment) – продукт компанії Cray Research, використовуваний найчастіше як менеджер ресурсів на суперкомп'ютерах, кластерах і системах Cray, хоча може працювати і на інших платформах; · LoadLeveler – продукт компанії IBM, керівник балансом завантаження крупних кластерів. Використовується в основному на кластерах IBM; · Condor – вільно доступний менеджер ресурсів, розроблений в основному студентами різних університетів Європи і США. Аналогічний вищепереліченим. Працює на різних платформах UNIX і Windows NT; · Easy-LL – сумісна розробка IBM і Cornell Theory Center, призначена для управління крупним кластером IBM в цьому центрі. По суті є об'єднанням LoadLeveler і продукту EASY лабораторії Argonne National Lab; · fork – простий стандартний засіб запуску процесів в UNIX. Структура GRAM представлена на рис. 2.28.
Рис. 2.28. Структура GRAM Щоб на даному обчислювальному вузлі можна було віддалено запускати на виконання програми, на ньому повинен виконуватися спеціальний процес, названий Gatekeeper. Gatekeeper працює в привілейованому режимі й виконує наступні функції: · проводить взаємну аутентифікацію з клієнтом; · аналізує RSL-запит; · відображає клієнтський запит на обліковий запис деякого локального користувача; · запускає від імені локального користувача спеціальний процес, званий Job Manager, і передає йому список потрібних ресурсів. Після того як Gatekeeper виконає свою роботу, Job Manager запускає завдання (процес або декілька процесів) і проводить його подальший моніторинг, повідомляючи клієнта про помилки й інші події. Gatekeeper запускає тільки один Job Manager для кожного користувача, який управляє всіма завданнями даного користувача. Коли завдань більше не залишається, Job Manager завершує роботу. Інформаційний сервіс. Всі перелічені компоненти, включаючи призначені для користувача додатки, можуть використовувати інформаційний сервіс (Information Service) для отримання всієї необхідної інформації про стан Грід-системи. У Globus Toolkit роль інформаційного сервісу грає MDS. Цей компонент відповідає за збір і надання конфігураційної інформації, інформації про стан Грід-системи та її підсистем, а також забезпечує універсальний інтерфейс отримання необхідної інформації. MDS має децентралізовану, легкомасштабовану структуру і працює як із статичними, так і з динамічно змінними даними, необхідними призначеним для користувача додаткам і різним сервісам Грід-системи. MDS складається з трьох основних компонентів: 1) IP (Information Provider) – є джерелом інформації про конкретний ресурс або частину ресурсу; 2) GRIS (Grid Resource Information Service) – надає інформацію про вузол Грід-системи, який може бути як обчислювальним вузлом, так і яким-небудь іншим ресурсом. GRIS опитує індивідуальні IP і об'єднує одержану від них інформацію в рамках єдиної інформаційної схеми; 3) GIIS (Grid Index Information Service) – об'єднує інформацію з різних GRIS або інших GIIS. Для зменшення часу реакції на запит і зниження мережевого трафіку GIIS кеширує дані. GIIS верхнього рівня містить всю інформація про стан даної системи Грід. Безпека. Інфраструктура безпеки Грід (Grid Security Infrastructure – GSI) забезпечує безпечну роботу в незахищених мережах загального доступу (Інтернет), надаючи такі сервіси, як аутентифікація, конфіденційність передачі інформації і єдиний вхід в Грід-систему. Під єдиним входом мається на увазі, що користувачу потрібно лише один раз пройти процедуру аутентифікації, а далі система сама потурбується про те, щоб аутентифікувати його на всіх ресурсах, якими він збирається скористатися. GSI заснована на надійній і широко використовуваній інфраструктурі криптографії з відкритим ключем (Public Key Infrastructure – PKI). Як ідентифікатори користувачів і ресурсів в GSI використовуються цифрові сертифікати X.509. В роботі з сертифікатами X.509 і в процедурі видачі/отримання сертифікатів задіяні три сторони: 1) центр Сертифікації (Certificate Authority – CA) – спеціальна організація, що володіє повноваженнями видавати (підписувати) цифрові сертифікати. Різні CA звичайно взаємонезалежні. Відносини між CA і його клієнтами регулюються спеціальним документом; 2) передплатник – людина або ресурс, який користується сертифікаційними послугами CA. CA включає в сертифікат дані, надані передплатником (ім'я, організація й ін.) і ставить на ньому свій цифровий підпис; 3) користувач – людина або ресурс, що покладається на інформацію з сертифіката при отриманні його від передплатника. Користувачі можуть приймати або відкидати сертифікати, підписані якої-небудь CA. У Globus Toolkit використовуються два типу сертифікатів X.509: 1) Сертифікат користувача (User Certificate) – цей сертифікат повинен мати кожен користувач, що працює з Грід-системою. Сертифікат користувача містить інформацію про ім'я користувача; організацію, до якої він належить; і центр сертифікації, що видав даний сертифікат; 2) Сертифікат вузла (Host Certificate) – цей сертифікат повинен мати кожен вузол (ресурс) Грід-системи. Сертифікат вузла аналогічний сертифікату користувача, але в ньому замість імені користувача указується доменне ім'я конкретного обчислювального вузла. Подальший розвиток інструментальних засобів. Globus Toolkit набув широкого поширення, оскільки був першим повноцінним набором інструментальних засобів для розробок у сфері технології Грід і став стандартом де-факто. Проте навіть найбільш поширена друга версія Globus Toolkit не була позбавлена недоліків, основним з яких була відсутність уніфікованих засобів розробки додатків, здатних взаємодіяти між собою і надавати один одному різні послуги (сервіси). Для вирішення цієї проблеми на Global Grid Forum (GGF) була запропонована відкрита архітектура сервісів Грід (Open Grid Services Architecture – OGSA). Стандарт OGSA визначає основний набір послуг, які надають Грід-системи, і описує їх архітектуру. У термінології OGSA ці послуги називають “можливостями”. Прикладами таких можливостей є запуск додатків, доступ до даних й ін. У OGSA Грід-система розглядається як набір незалежних одна від одної послуг, які можуть використовуватися незалежно або спільно для побудови необхідної інфраструктури. Стандарт OGSA пропонує конструювати Грід-системи за принципом сервіс-орієнтованої архітектури. Рівні архітектури OGSA представлені на рис. 2.29:
Рис. 2.29. Трьохрівневе представлення Грід в OGSA · нижній рівень представлений ресурсами, які можуть входити в Грід-систему; · середній рівень є послугами. На цьому рівні здійснюється узагальнення (віртуалізація) ресурсів. Користувачу надаються високорівневі послуги з певними інтерфейсами. Строга специфікація цього рівня і є основним завданням OGSA; · верхній рівень представляє додатки, що використовують послуги для виконання тих або інших завдань. Цей рівень в OGSA не специфікований. OGSA спирається на сімейство технологій веб-сервісів (Web-services), які з'явилися відносно недавно і зараз дуже бурхливо розвиваються. Архітектура OGSA зосереджується на визначенні послуг у вигляді набору взаємодіючих сервісів. Програмне забезпечення LCG. Для побудови повністю функціональної Грід-системи необхідне ПЗ проміжного рівня, побудоване на базі існуючих інструментальних засобів і надаюче високорівневі сервіси завданням і користувачам. Прикладом такого ПЗ може стати ПЗ LCG (LHC Computing Grid), розроблене в Європейському центрі ядерних досліджень (CERN). Спочатку метою проекту LCG була розробка повністю функціонуючої Грід-системи на базі Globus Toolkit для обробки даних у фізиці високих енергій. З часом сфера застосування LCG розширилася, і в даний час це – один з найпоширеніших пакетів, що швидко розвиваються. Пакет LCG складається з декількох частин, званих “елементами”. Кожен елемент є самостійним набором програм (одні й ті ж програми можуть входити в декілька елементів), що реалізують деякий сервіс, і призначений для установки на комп'ютер під управлінням ОС Scientific Linux. Основні елементи LCG та їх призначення: · CE (Computing Element) – набір програм, призначений для установки на вузол обчислювального кластера, що управляє. Даний елемент надає універсальний інтерфейс до системи управління ресурсами кластера і дозволяє запускати на кластері обчислювальні завдання; · SE (Storage Element) – набір програм, призначений для установки на вузол зберігання даних. Даний елемент надає універсальний інтерфейс до системи зберігання даних і дозволяє управляти даними (файлами) в Грід-системі; · WN (Worker Node) – набір програм, призначений для установки на кожен обчислювальний вузол кластера. Даний елемент надає стандартні функції й бібліотеки LCG завданням, що виконуються на даному обчислювальному вузлі; · UI (User Interface) – набір програм, що реалізують призначений для користувача інтерфейс Грід-системи (інтерфейс командного рядка). У цей елемент входять стандартні команди управління завданнями і даними; · RB (Resource Broker) – набір програм, що реалізують систему управління завантаженням (брокер ресурсів). Це найбільш складний (і об'ємний) елемент LCG, що надає всі необхідні функції для скоординованого автоматичного управління завданнями в Грід-системі; · PX (Proxy) – набір програм, що реалізують сервіс автоматичного оновлення сертифікатів (myproxy); · LFC (Local File Catalog) – набір програм, що реалізують файловий каталог Грід-системи. Файловий каталог необхідний для зберігання даних про копії (репліках) файлів, а також для пошуку ресурсів, що містять необхідні дані; · BDII (Infornation Index) – набір програм, що реалізують інформаційний індекс Грід-системи. Інформаційний індекс містить всю інформацію про поточний стан ресурсів, що одержується з інформаційних сервісів, і необхідний для пошуку ресурсів; · MON (Monitor) – набір програм для моніторингу обчислювального кластера. Даний елемент збирає і зберігає в БД інформацію про стан і використання ресурсів кластера; · VOMS (VO Management Service) – набір програм, що реалізують каталог віртуальних організацій. Даний каталог необхідний для управління доступом користувачів до ресурсів Грід-системи на основі членства у віртуальних організаціях. На один комп'ютер можлива установка відразу декількох елементів LCG, якщо це дозволяють його потужності (обсяг пам'яті й продуктивність). Мінімальна кількість вузлів, необхідних для розгортання повного набору ПЗ LCG, дорівнює трьом. Варто помітити, що установка всіх сервісів на один вузол хоч і можлива технічно, але не рекомендується. Брокер ресурсів, з міркувань безпеки, необхідно розташовувати на окремому вузлі. Обчислювальні вузли також варто виділити окремо, оскільки навантаження, що створюється на них працюючими завданнями, приведе до дефіциту ресурсів для решти сервісів. Вся решта елементів може бути встановлена спільно. В основу LCG покладено розробки, виконані в рамках Європейського проекту EDG (European DataGrid) кілька років тому. Зараз проект LCG активно розвивається і стоїть на порозі переходу до нової, більш функціональної інфраструктури ПЗ, що носить назву gLite. Даний перехід має на увазі поступову заміну застарілих програм новими із збереженням сумісності. Важливо відзначити, що все ПЗ, що розробляється в рамках проекту LCG, може вільно використовуватися. На основі цього ПЗ можливо створення національних і регіональних Грід-систем для ефективного розподілу локальних ресурсів. LCG є технологічною базою для інфраструктури, реалізованої в рамках проекту EGEE. Користувач в Грід. Система входу користувача в Грід-систему достатньо складна. Це визначено багатьма чинниками, але головною проблемою є рішення питань безпеки (загрози вторгнень і атак зловмисників). Аутентифікація і авторизація користувачів є шляхами для вирішення цієї проблеми. Аутентифікаційні рішення для середовищ віртуальних організацій повинні володіти наступними властивостями: · єдиний вхід. Користувач повинен реєструватися і аутентифікуватися тільки один раз на початку сеансу роботи, дістаючи доступ до всіх дозволених ресурсів базового рівня архітектури Грід; · делегування прав. Користувач повинен мати можливість запуску програм від свого імені. Таким чином, програми дістають доступ до всіх ресурсів, на яких авторизований користувач. Призначені для користувача програми можуть, у разі потреби, делегувати частину своїх прав іншим програмам; · довірче відношення до користувача. Якщо користувач виконує одночасно роботу з ресурсами декількох постачальників, то при конфігурації захищеного середовища користувача система безпеки не повинна вимагати взаємодії постачальників ресурсів один з одним. Для входу в Грід-систему користувач повинен: 1) бути легальним користувачем обчислювальних ресурсів в своїй організації; 2) мати персональний цифровий сертифікат, підписаний центром сертифікації; 3) бути зареєстрованим хоч би в одній віртуальній організації. Отримання цифрового сертифіката є важливим і необхідним кроком для отримання доступу до Грід-системи. Цифровий сертифікат аналогічний паспорту і однозначно ідентифікує користувача. Для отримання цифрового сертифіката користувачу необхідно звернутися в Центр сертифікації. Докладну інструкцію по отриманню цифрового сертифіката можна одержати безпосередньо в Центрі сертифікації, а тут вкажемо лише основні кроки при виконанні цієї інструкції: · створення на комп'ютері користувача (на призначеному для користувача інтерфейсі) двох файлів – закритого ключа і запиту на сертифікат; · відсилання запиту на сертифікат в Центр сертифікації; · отримання з Центру сертифікації підписаного відкритого ключа (потрібна перевірка особи користувача). Закритий ключ не варто посилати в Центр сертифікації, а необхідно зберігати в захищеному місці. Не зважаючи на те, що закритий ключ додатково захищений паролем, про всі випадки втрати або можливого несанкціонованого доступу до закритого ключа необхідно негайно повідомляти в Центр сертифікації. Після отримання цифрового сертифіката користувачу необхідно зареєструватися у віртуальній організації. Залежно від сфери діяльності користувача це може бути міжнародна, національна або локальна віртуальна організація. Правила реєстрації у віртуальній організації необхідно дізнатися у відповідному Центрі реєстрації (не плутати з Центром сертифікації). Можливо реєстрація одного і того ж користувача (сертифіката) в декількох віртуальних організаціях. Доступ до Грід-системи може бути проведений з будь-якої точки (обчислювальної системи, термінала), в якій встановлений призначений для користувача інтерфейс системи Грід. Веб-інтерфейси Грід. Прикладом веб-інтерфейсу до Грід-системи може служити GENIUS, розроблений в Італійському інституті INFN (grid-demo.ct.infn.it). Основними цілями при створенні веб-інтерфейсу GENIUS: · ознайомлення користувача з технологією Грід; · надання доступу до сервісів Грід-системи через Інтернет; · простий і зручний графічний інтерфейс; · ефективний моніторинг поточного стану Грід-системи. Веб-інтерфейс GENIUS дозволяє виконувати всі основні операції по управлінню завданнями і даними в Грід-системі, причому всі ці дії користувач може проводити прямо з браузера. В теперішній час GENIUS активно використовується в рамках проекту GILDA (Grid Infn Laboratory for Dissemination Activities), що є віртуальною лабораторією для демонстрації можливостей технології Грід. Проект GILDA складається з декількох частин: · GILDA Testbed – набір сайтів зі встановленим ПЗ LCG; · Grid Demonatrator – веб-інтерфейс GENIUS, що дозволяє працювати з певним набором додатків; · GILDA CA – центр сертифікації, що видає 14-денні сертифікати для роботи з GILDA; · GILDA VO – віртуальна організація, об'єднуюча всіх користувачів GILDA; · Grid Tutor – веб-інтерфейс GENIUS, використовуваний для демонстрації можливостей технології Грід; · Monitoring System – система моніторингу для GILDA Testbed. Призначені для користувача веб-інтерфейси до Грід-систем є вельми перспективним напрямом, оскільки можуть бути легко адаптовані під конкретне завдання або наочну сферу і не вимагають навиків роботи з командним рядком unix. Авторизація користувачів на таких інтерфейсах проводиться також за допомогою завантажених в браузер цифрових сертифікатів.
|
Последнее изменение этой страницы: 2019-04-11; Просмотров: 297; Нарушение авторского права страницы