|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Представлення в базах даних.⇐ ПредыдущаяСтр 13 из 13
ПРЕДСТАВЛЕННЯ Представлення – це шаблон, через який можна переглядати базу даних. Його можна також назвати віртуальним відношенням, яке не існує насправді, але яке динамічно відтворюється на підставі запиту до одній або декількох таблиць або до інших (або іншому) представлень. Представлення не зберігають яких-небудь даних. У словнику даних зберігається лише пропозиція SELECT тієї або іншого представлення. Синтаксис команди: CREATE VIEW <ім'я вистави> [(<ім'я стовпця> [,.n ]) [WITH {ENCRYPTION | SCHEMABINDING | VIEW_METADATA}] AS < команда SELECT> [WITH CHECK OPTION]; WITH CHECK OPTION – обмежує дію команд INSERT і UPDATE. При завданні цієї пропозиції вони дозволені лише в тому випадку, якщо вони створюють рядки, які потім видно у представленні. Представлення бувають простими і складними. Простими називаються представлення, що створені на підставі однієї таблиці і не містять функцій або умов угрупування. При створенні вистави SQL не здійснює контроль за типом змінних, тобто представлення буде створена без генерації повідомлення про помилку, але при спробі здійснити запит згенерує повідомлення про помилку. Раніше наголошувалося, що опція WITH CHECK OPTION може обмежити дію команд INSERT і UPDATE, проте існують і інші обмеження на використанні команд DML. Команда DELETE заборонена, якщо представлення містить: умова з'єднання групові функції або пропозиція GROUP BY пропозиція DISTINCT стовпець з властивістю IDENT I TY Команда UPDATE заборонена завжди, коли заборонена команда DELETE, а також у разі, коли стовпці містять вирази. Команда INSERT заборонена завжди, коли заборонена команда UPDATE, а також тоді, коли який-небудь стовпець таблиці NOT NULL не міститься у представлення. Після успішного завершення команди CREATE VIEW видається повідомлення View created (Представлення створена). Представлення використовуються для: обмеження доступу до бази даних; спрощення запитів; заховання схеми бази даних. У першому випадку можна не лише обмежити перегляд тих або інших даних, але і склавши обмеження тим або іншим способом, зробити неможливим виконання тієї або іншої комбінації операцій над базами даних (видалення, додавання, редагування). Привілеї в базах даних. Привілеї – це права користувача на проведення тих чи інших дій над певним об'єктом бази даних. Для введення елементів системи безпеки застосовується інструкція GRANT, за допомогою якої тим чи іншим користувачам надаються певні привілеї на використання тих чи інших об'єктів бази даних. В інструкції GRANT задається комбінація ідентифікатора користувача, об'єкта і привілеїв. Надані привілеї можна пізніше анулювати за допомогою інструкції REVOKE. Кожному користувачеві реляційної бази даних присвоюється ідентифікатор – коротке ім'я, що однозначно визначає користувача для СУБД. Ці ідентифікатори є основою системи безпеки. Кожна інструкція SQL виконується в СУБД від імені конкретного користувача. Від його ідентифікатора залежить, чи буде дозволено або заборонено виконання інструкції. У більшості комерційних реляційних СУБД код користувача створюється для кожного сеансу зв'язку з базою даних. В інтерактивному режимі сеанс починається, коли користувач запускає інтерактивну програму формування запитів, і продовжується до тих пір, поки користувач не вийде з програми. Пароль служить для підтвердження того, що користувач дійсно має право працювати під введеним ідентифікатором. Ідентифікатори і паролі застосовуються в більшості реляційних СУБД, однак спосіб, яким користувач вводить свій ідентифікатор та пароль, змінюється залежно від СУБД. Наприклад, коли СУБД Oracle працює з інтерактивним SQL-модулем, який називається SQLPLUS, необхідно ввести ім'я користувача і відповідний пароль у командному рядку: SQLPLUS ідентифікатор/пароль. У багатьох інших СУБД, включаючи Informix, у ролі ідентифікаторів користувачів використовуються імена користувачів, що реєструються в операційній системі мейнфрейму. У великих виробничих базах даних часто є групи користувачів зі схожими завданнями. У межах кожної групи всі користувачі працюють з однаковими даними і повинні мати ідентичні привілеї. Згідно стандарту ANSI/ISO, з групами користувачів можна вчинити одним з двох способів: 1. Кожному члену групи можна присвоїти один і той же код користувача. 2. Усім членам групи можна присвоїти різні ідентифікатори користувача. Ті дії, які користувач має право виконувати над об'єктом бази даних, називаються привілеями користувача по відношенню до даного об'єкту. У стандарті SQL для таблиць визначені чотири привілеї: 1. Привілей SELECT дозволяє отримувати дані з таблиці. 2. Привілей INSERT дозволяє додавати нові записи в таблицю. 3. Привілей DELETE дозволяє видаляти записи з таблиці. 4. Привілей UPDATE дозволяє модифікувати записи у таблиці або псевдотаблиці. Коли користувач створюєте таблицю за допомогою інструкції CREATE TABLE, він стаєте її власником і отримуєте всі привілеї для цієї таблиці (SELECT, INSERT, DELETE, UPDATE та інші привілеї, які є в СУБД). Інші користувачі спочатку не мають ніяких привілеїв на щойно створену таблицю. Щоб вони отримали доступ до таблиці, власник повинен явно надати їм відповідні привілеї за допомогою інструкції GRANT [5]. У багатьох комерційних СУБД крім привілеїв SELECT, INSERT, DELETE і UPDATE, встановлених стандартом SQL, по відношенню до таблиць можуть бути видані додаткові привілеї. Наприклад, в Oracle та Informix передбачені привілеї ALTER та INDEX. Маючи привілей ALTER для якої-небудь таблиці, користувач може за допомогою інструкції ALTER TABLE модифікувати структуру даної таблиці; маючи привілей INDEX, користувач може за допомогою інструкції CREATE INDEX створити індекс для таблиці За допомогою механізму прав на рівні таблиці можна управляти доступом різних користувачів на рівні таблиці цілком або на рівні полів у таблиці. Але іноді виникає ситуація, коли необхідно управляти доступом до окремих записів у таблиці. Наприклад, в деякій фірмі треба забезпечити такий доступ до інформації про співробітників, щоб кожен користувач міг бачити записи тільки про тих співробітників, які працюють в одному з ним відділі. Як вирішити це завдання? Якщо користуватися правами на рівні таблиць, то буде потрібно створювати стільки таблиць з однаковою структурою, скільки відділів у фірмі. Очевидно, це переобтяжить структуру бази даних, зробить її негнучкої і зробить важчою розробку прикладних програм. У SQL дана проблема може бути вирішена за допомогою VIEW – псевдотаблиці. Ієрархічна модель даних. Ієрархічна модель даних Деревоподібна (ієрархічна) структура, або дерево, - це зв'язний неорієнтований граф, що не містить циклів, тобто петель з замкнутих шляхів.
Як правило, при роботі з деревом виділяють яку-небудь конкретну верхівку (початок), визначають її як коріння дерева і розглядають особливо - в цю верхівку не заходить жодне ребро. В цьому випадку дерево стає орієнтованим. Орієнтація на кореневому дереві визначається або від коріння, або до коріння. Кореневе дерево можна визначити наступним чином: 1) є єдиний особливий вузол , який називається корінням, в який не заходить жодне ребро; 2) в всі інші вузли заходить тільки одне ребро, а виходить довільна (0, 1, 2,..., п) кількість ребер; 3) не існує циклів. В програмуванні використовується інше визначення дерева, яке дозволяє розглядати дерево як рекурсивну структуру. Рекурсивне дерево визначається як кінцева множина Т, яка складається з одного або більш вузлів, таких, що: 1) існує один спеціально виділений вузол, який називається корінням дерева; 2) інші вузли розбиті на m>0 неперетинаючихся підмножини T1,T2, …, Tm, кожна з яких в свою чергу є деревом. T1,T2, …, Tm, називаються піддеревами. З визначення слідує, що будь-який вузол дерева є корінням деякого піддерева, що міститься в повному дереві. Число піддерев вузла називають ступенем вузла. Вузол називається кінцевим, якщо він має нульову степінь. Інколи кінцеві вузли називають листками, а ребра -гілками . Кожний вузол, крім кореневого , зв'язаний з одним вузлом на більш високому рівні ієрархії і називається вихідним. Кожний вузол може бути зв'язаний з одним або декількома вузлами на більш низькому рівні і називається породженим. Якщо кожний вузол має однакову кількість гілок, причому процес включення нових гілок іде зверху вниз , а на кожному рівні дерева - зліва направо, то таке дерево називається збалансованим. Для збалансованих дерев фізична організація даних суттєво спрощується. До особливої категорії дерев відносять двійкове (бінарне) дерево. Це дерево має не більш як дві гілки, які виходять з одного вузла. Двійкові дерева можуть бути як збалансованими, так і незбалансованими. . Прикладом простого ієрархічного представлення може служити адміністративна структура вищого учбового закладу: університет - відділення - факультет - група (студентська).
Пошук даних у ієрархічній структурі виконується завжди по одній із гілок, починаючи з кореневого елемента, тобто повинний бути зазначений повний шлях руху по гілкам. Так, для пошуку і вибірки одного або декількох екземплярів запису типу СТУДЕНТ необхідно вказати кореневий елемент ФАКУЛЬТЕТ і елементи КУРС, ГРУПА. У операційній системі для пошуку файла використовується такий же принцип - вказуються послідовно ім'я диска, ім'я каталогу, ім'я підкаталогів, ім'я файла.
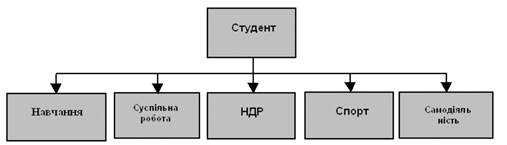
На рисунку приведений приклад типу набору, представленого у виді діаграми Бахмана. Діаграму назвали по імені вченого, який вперше їх застосував для опису відношень між даними при розробці СУБД IDS. На такій діаграмі кожний прямокутник представляє собою тип запису, а стрілка - відношення "один до багатьох" між типами запису.. У прикладі тип запису СТУДЕНТ є записом-власником, а типи записів НАВЧАННЯ, СУСПІЛЬНА РАБОТА, НДР, СПОРТ і САМОДІЯЛЬНІСТЬ -записами - членами. Тип набору названий ім'ям СУОНСС по перших літерах імен усіх типів запису, що беруть участь у наборі (наборові можна було надати і будь-яке інше ім'я). У цілому приведений тип набору призначений для того, щоб відобразити зв'язок між загальними даними про студента, що знаходяться в типі запису СТУДЕНТ, і даними, що характеризують різні сторони діяльності студента у вузі. При традиційному підході всі ці данні можна було б помістити в один загальний запис. Оскільки не кожний студент бере участь, наприклад, у спорті або самодіяльності, то прийшлося б вибрати запис з змінною довжиною або запис із фіксованою довжиною, причому в останньому випадку частина пам'яті витрачалася б даремно. Ієрархічна структура усуває виникаючі при цьому складнощі, тому що в будь-якому екземплярі типу набору з записом-власником можна асоціювати стільки записів-членів, скільки необхідно для конкретного екземпляра. Повна схема бази даних формується в загальному випадку з множини різних типів набору і типів запису. Ієрархічна деревоподібна структура, що орієнтована від коріння, задовольняє наступним умовам: 1) ієрархія завжди починається з кореневого вузла; 2) на першому рівні може знаходитися тільки один вузол- кореневий; 3) на нижніх рівнях знаходяться породжені (залежні) вузли; 4) кожний породжений вузол, який знаходиться на рівні і , зв'язаний тільки з одним вхідним вузлом , який знаходиться на рівні (і-1) ієрархії дерева; 5) кожний вхідний вузол може мати один або декілька породжених вузлів, які називаються подібними; 6) доступ до кожного породженого вузла виконується через йому відповідний вхідний вузол; 7) існує єдиний ієрархічний шлях доступу до будь-якого вузла, починаючи від кореневого вузла дерева. Прикладами типових операторів маніпулювання ієрархічно- організованими даними можуть бути наступні: · Знайти задане дерево БД ; · Перейти від одного дерева до іншого; · Перейти від одного запису до іншого в середині дерева ; · Перейти від одного запису до іншого в порядку обходу ієрархії; · Уставити новий запис у зазначену позицію; · Видалити поточний запис. Перевагами деревовидної моделі є наявність функціональних систем керування базами даних , які підтримують дану модель , простота сприйняття користувачами принципу ієрархії, забезпечення деякого рівня незалежності даних, простота оцінки операційних характеристик системи завдяки апріорно заданим взаємозв'язкам. До недоліків ієрархічних структур відносять : - надлишковість зберігання інформації, так як ієрархічні структури не підтримують взаємозв'язки Б:Б; - строгу ієрархічну впорядоченість , яка ускладнює процедури включення та вилучення записів; - вилучення вихідних вузлів призводить до вилучення відповідних їм породжених , що вимагає особливої обережності; - ускладнюється доступ до даних , які лежать на більш низьких рівнях ієрархії, так як кореневий вузол завжди є головним, а доступ до любого породженого вузла може здійснюватись через вихідний. В ієрархічні базі даних проблеми, пов'язані з операціями включення нових записів і вилучення старих, а також проблеми часткового дублювання інформації виникають в результаті того, що відношення БАГАТО-ДО-БАГАТЬОХ безпосередньо не підтримується, що і є основним недоліком ієрархічних моделей. Мережева модель даних. Більш широкі можливості для користувача забезпечує мережна модельбази даних, яка є узагальненням ієрархічної моделі і дозволяє відображативідношення між типами записів виду "багато до багатьох". У мережній моделікожний тип запису може бути членом більш ніж одного типу набору. Врезультаті можна сформувати модель бази даних із довільними зв'язками міжрізними типами запису. Крім того, окремі типи записів можна не включати ні всякі типи набору, що забезпечує додаткові можливості для ряду задач обробки даних в СКБД. Відзначимо, що СКБД, в основі якої використовується мережна модель бази даних, називається СУБД мережного типу. У 1971 році був опублікований офіційний стандарт мережних баз даних, який відомий як модель CODASYL. Розділення мережних структур на два типи (складні та прості) необхідно хоча б тому, що структури, побудовані з використанням зв'язку БАГАТО-ДО- БАГАТЬОХ, вимагають для їх реалізації використання більш складних методів. Крім того, деякі системи керування базами даних можуть підтримувати прості мережні структури, але не можуть підтримувати складні. Наприклад, СКБД DMS, DBMS, СЕКТОР дозволяють описувати прості мережні структури. Реалізація складних мережних структур можлива і в цих системах керування базами даних шляхом приведення до більш простого вигляду. Любу мережну структуру можливо привести до більш простого вигляду, якщо ввести надлишковість. Якщо надлишковість, яка при цьому виникає, є допустимою, то такий шлях дозволяє підтримувати мережні структури даних СКБД, які орієнтовані на ієрархічну організацію даних. Прикладами типових операторів маніпулювання мережними даними можуть бути наступні: · Знайти конкретний запис у наборі однотипних записів ; · Перейти від предка до першого нащадка по деякому зв'язку ; · Перейти до наступного нащадка в деякому зв'язку ; · Перейти від нащадка до предка по деякому зв'язку ; · Створити новий запис; · Знищити запис; · Модифікувати запис; · Включити в зв'язок; · Виключити зі зв'язку; · Переставити в інший зв'язок і т.д. До переваг мережних структур слід віднести наявність СКБД, які успішно реалізують таку організацію, а також простоту реалізації зв'язків "багато до багатьом", які часто зустрічаються в реальному світі. Недолік таких структур полягає в складності по відношенню до ієрархічних структур. Прикладному програмісту часто необхідно знати логічну структуру бази даних. При реорганізації бази даних не виключається в ряді випадків втрата незалежності даних. Представлення даних ієрархічними та мережними структурами, в загальному випадку, перешкоджає внесенню багатьох змін, пов'язаних з розширенням бази даних. Це може призвести до порушення логічного представлення даних, схем, підсхем, а, отже, до зміни в прикладних програмах. |
Последнее изменение этой страницы: 2019-04-19; Просмотров: 293; Нарушение авторского права страницы