|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Синтаксическим анализаторомСтр 1 из 5Следующая ⇒
Транслятором
Программа, которая переводит текст программы с языка высокого уровня на язык низкого уровня – машинный код, называется Компилятором
Программа, которая переводит текст программы с языка высокого уровня на язык команд некоторой абстрактной машины, программная реализация которой, как правило, входит в нее, называется интерпретатором.
Программа, которая преобразует входной символьный поток в последовательность более крупных единиц – лексем, называется Лексическим анализатором Сканером
Программа, которая переводит текст программы с языка высокого уровня на язык низкого уровня – машинный код, называется Компилятором
Программа, которая проверяет синтаксическую правильность входной цепочки (уже разбитой на лексемы) и строит её семантическое дерево, называется: Синтаксическим анализатором
Алфавитом называется: Любое конечное множество
Программа, которая переводит текст программы с языка высокого уровня на язык команд некоторой абстрактной машины, программная реализация которой, как правило, входит в нее, называется: Интерпретатором
A* это: Множество всех цепочек в алфавите A
Обращение цепочки a обозначается как aR. Итерация цепочки a n раз обозначается как an. Какие из перечисленных ниже тождеств являются истинными для двух произвольных цепочек символов a и b, а какие нет: |ab| = |a| + |b| = |ba| |aR| = |a| (a2b2)R = (bR)2(aR)2
Кто (или что) для любого языка программирования выступает в роли генератора цепочек языка? грамматика
Операцией, которая определяется свойствами: ea = ae = a, <a1,...,an> <b1,...,bm> = <a1,...,an,b1,...,bm>, где аi, bi – символы; e – пустая цепочка символов называется: Конкатенацией
Языком L над алфавитом A называется: Любое множество цепочек в алфавите A
Любое множество цепочек в алфавите A, называется языком
Операция над языками, которая определяется следующей формулой: LM = {ab | a ∈ L, b ∈ M}, L0 = e, Ln+1 =LnL, называется произведение
Если язык конечен или образуется из конечных языков с помощью операций объединения, произведения и итерации, он называется Регулярным
Отдельные конструкции в языках программирования являются регулярными языками. Как правило, это: Идентификаторы Числа
Грамматика I = L{L | D} , где L = {a,...,z}, D = {0,1,2,...,9} определяет множество: Идентификаторов
Какой язык порождается КС-грамматикой с правилами S aSb, S . { anbn | n 0}
Грамматика R = SNFP, где S = {+,-,e}, N = DD*, F = .N | e , P = eSN | e определяет множество: Чисел
Грамматика I = D{ D} , где D = {0,1,2,...,9} определяет множество: Целых чисел без знака
Пусть, множество всех языков над алфавитом A обозначено Langs(A). Выражение, построенное из конечных языков, принадлежащих Langs(A), и переменных с помощью операций объединения, произведения и итерации называется: Регулярным
Набор G = (N,T,P,S), где N – алфавит нетерминальных символов; T – алфавит терминальных символов, P – конечное множество правил (или продукций); правило имеет вид a → b, где a, b ∈ (T U N)*, причем a содержит хоть один нетерминальный символ; S – начальный нетерминальный символ, S ∈ N. называется: Грамматикой
По классификации Н. Хомского, грамматика с правилами вида a → b, где |a | <= |b |. относится к типу: 1
По классификации Н. Хомского, контекстно-свободной называется грамматика с правилами вида: A → a, где A ∈ VN, a ∈ V*
По классификации Н. Хомского, грамматика с правилами вида A → a, где A ∈ N, a ∈ V* относится к типу: 2 4. 3 По классификации Н. Хомского, грамматика с правилами вида A → UT | e, где A, U ∈ VN, T ∈ VT относится к типу: 3 Дерево следующего вида: корнем является нетерминальный символ; вершинами являются символы из V; если вершина A имеет непосредственных потомков X1, ..., Xn (или e), то в грамматике есть правило A → X1...Xn (или A → e). Порядок потомков совпадает с порядком символов в правиле, называется: деревом вывода КС-грамматика G такая, что у каждой цепочки языка L(G) имеется только одно дерево вывода, называется: Однозначной
Анализ, задачей которого является проверка, принадлежит ли произвольная заданная цепочка a ∈ T * языку L(G) для заданной грамматики G, называется: Синтаксическим
Грамматика G = (N,T,P,S) и автомат A = (Q,T,t,q0,F) называются соответствующими друг другу, если: N = Q, S = q0, X → aY ∈ P Ы (X,a) →Y ∈ t, X → e ∈ P Ы X ∈ F
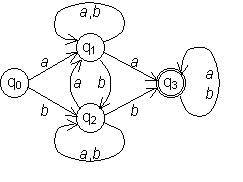
Конечный автомат представленный диаграммой:
позволяет распознавать: Числа
Конечный автомат представленный диаграммой:
позволяет распознавать: Идентификаторы
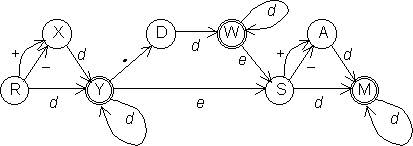
Недетерминированный автомат, изображенный на следующем рисунке,
имеет грамматику с правилами: q0 → aq1 | bq2, q1 → aq1 | aq3 | bq1 | bq2, q2 → aq1 | aq2 | bq2 | bq3, q3 → aq3 | bq3 | e
Для инфиксного выражения a+b*c-(d+e) правильной польской суффиксной записью будет: abc*de+-+
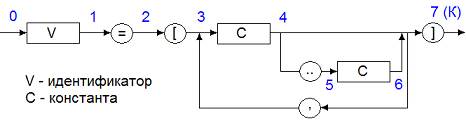
Какая синтаксическая конструкция описывается следующей диаграммой:
Объявление массива
Магазинные автоматы или автоматы с магазинной памятью – МП-автоматы, являются формальной моделью: Синтаксических анализаторов
Если существует вывод X → + X… , нетерминальный символ X называется: Леворекурсивным
Леворекурсивная грамматика Е → Е+Т | E-T | T после использования факторизации и итерации примет вид: Е →T{+T | -T}
Синтаксический анализ, при котором цепочка входных символов просматривается слева направо, а дерево строится сверху вниз, называется: Нисходящим
Синтаксический анализ, при котором цепочка входных символов просматривается слева направо, а дерево строится снизу вверх, называется: Восходящим
МП-автомат M= (Q,T,Z,P,q0,F,S), для которого выполнены следующие условия: o для каждой тройки (q,a,z), a ∈T , есть не более одного правила, o для каждой тройки (q,e,z) есть не более одного правила, o если есть правило для (q,a,z), то нет правила для (q,e,z), называется:
детерминированным Набор M = (Q,T,Z,P,q0,F,S), где Q – конечное множество состояний, T – конечный входной алфавит, Z – конечный магазинный алфавит, P ⊆ Qґ(T И e)ґZґQґZ* - конечное множество правил, q0∈Q – начальное состояние, F ⊆ Q – множество заключительных состояний, S∈Z – начальный магазинный символ, называется: МП-автоматом
МП-автомат M= (Q,T,Z,P,q0,F,S), для которого выполнены следующие условия: o для каждой тройки (q,a,z), a ∈T , есть не более одного правила, o для каждой тройки (q,e,z) есть не более одного правила, o если есть правило для (q,a,z), то нет правила для (q,e,z), называется:
Детерминированным
Для автомата M любая тройка вида (q,a,g), где o q∈Q, текущее состояние, o a ∈T * - непрочитанный остаток входной цепочки (читающая головка обозревает левый символ – текущий - или входная лента пуста), o g ∈ Z* - магазинная цепочка с вершиной слева (может быть пустой) называется: конфигурацией Метод нисходящего синтаксического анализа, который состоит в представлении каждого нетерминального символа A в виде процедуры (без параметров), распознающей в тексте цепочки языка L(A), причем тело такой процедуры строится на основе правил грамматики для A, получил название: Рекурсивного спуска
Синтаксический анализатор A = (N,T,P,S), соответствующий КС-грамматике G = (N,T,P,S), который, анализируя цепочку a ∈T *, пытается, читая a слева направо, построить её правый вывод (если он существует), называется: Восходящим
Пусть G = (N,T,P,S) - произвольная КС-грамматика и некоторая цепочка a ∈ V* имеет в G правый вывод S →* bXg → bdg = a , где X ∈ N, g ∈T *, X → d - правило грамматики, т.е. указанное вхождение d в bdg = a является основой a. Начало цепочки a, завершающееся основой, т.е. bd, называется: Активным префиксом
Множество AP(G) активных префиксов цепочек из V*, выводимых в G правым выводом является регулярным языком над алфавитом V и, следовательно, допускается: Конечным автоматом В программе на Ассемблере все символы, находящиеся справа от ; являются: Комментарием В программе на Ассемблере все символы, находящиеся справа от ; и до конца строки, являются: Комментарием
К какому типу по способу построения дерева вывода относится распознаватель на основе алгоритма «сдвиг-свертка»: восходящему К какому типу: восходящему или нисходящему относится распознаватель на основе алгоритма «сдвиг-свертка»: Восходящему
Грамматики, в которых для каждой упорядоченной пары символов полного алфавита устанавливается отношение, отражающее порядок их вхождения в основу называются: Оба символа
Правило вида A B, где A,B VN называется: Цепным
Если язык, заданный регулярной грамматикой, содержит пустую цепочку, то может ли он быть задан автоматной грамматикой? да Являются ли регулярными множествами следующие множества: Множество вещественных чисел; Множество всех возможных строковых констант в языке Pascal; Вещественные двоичные числа
Какой язык порождается представленной ниже грамматикой: G1({".",+,-,0 ,1 , 2, 3, 4, 5, 6, 7, 8, 9},{<число>,<часть>,<цифра>,<осн.>},Р1,<число>) Р1: <число> —> +<осн.> | -<осн.> | <осн.> <осн.> —> <часть>.<часть> | <часть>. | <часть> <часть> -> <цифра> | <часть><цифра> <цифра> -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Вещественные числа
Какой язык порождается представленной ниже грамматикой: G1({".",0,1, 2, 3, 4, 5, 6, 7, 8, 9},{<число>,<часть>,<цифра>,<осн.>},Р1,<число>) Р1: <число> —><осн.> <осн.> —> <часть>.<часть> | <часть>. | <часть> <часть> -> <цифра> | <часть><цифра> <цифра> -> 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9
Вещественные двоичные числа
Какой язык порождается представленной ниже грамматикой: G5({".",+,-,0,1},{<знак>,<число>,<часть>,<осн.>},Р5,<число>) Р5: <число> —> <часть>. | <осн.>0 | <осн.>1 | <часть>0 | <часть>1 <осн.> —> <часть>. | <осн.>0 | <осн.>1 <часть> -+ 0 | 1 | <знак>0 | <знак>1 | <часть>0 | <часть>1 <знак> -> + | -
Вещественные двоичные числа
Является ли представленная ниже грамматика автоматной: G3({".",+,-,0,1},{<число>,<часть>,<осн.>},Р3,<число>) РЗ: <число> -> +<осн.> | -<осн.> | <осн.> <осн.> -> 0 | 1 | 0.<часть> | 1.<часть> | 0<осн.> | 1<осн.> <часть> -> 0 | 1 | 0<часть> | 1<часть> Нет
Является ли представленная ниже грамматика автоматной: G4({".",+,-,0,1},{<знак>,<число>,<часть>,<осн.>},Р4,<число>) Р4: <число> -> <знак>0 | <знак>1 | <часть>. | <число>0 | <число>1 <часть> —> <знак>0 | <знак>1 | <часть>0 | <часть>1 <знак> -> l| + | - Нет
К чему может привести левая рекурсия при работе нисходящего распознавателя? Зацикливанию
Для моделирования работы какого (восходящего или нисходящего) распознавателя представляет сложность левая рекурсия? Нисходящего
Можно ли полностью устранить рекурсию из правил грамматики, записанных в расширенной форме Бэкуса—Наура? да
Справедливы ли следующие утверждения?: Любой язык программирования является контекстно-свободным языком; Синтаксис любого языка программирования может быть описан с помощью контекстно-свободной грамматики;
Справедливо ли следующее утверждение: любой язык программирования является контекстно-свободным языком? да
Справедливо ли следующее утверждение: синтаксис любого языка программирования может быть описан с помощью контекстно-свободной грамматики? да
Справедливо ли следующее утверждение: любой язык программирования является контекстно-зависимым языком? Нет
Справедливо ли следующее утверждение: семантика любого языка программирования может быть описана с помощью контекстно-свободной грамматики? Нет
Какие из перечисленных ниже тождеств являются истинными для двух произвольных цепочек символов a и b (обращение цепочки a обозначается как aR): |ab| = |a| + |b| = |ba| |aR | = |a| (a²b²)R = (bR) ² (aR) ²
Является ли представленное ниже тождество истинным для двух произвольных цепочек символов a и b (обращение цепочки a обозначается как aR): |ab| = |a| + |b| = |ba| Да Является ли представленное ниже тождество истинным для двух произвольных цепочек символов a и b (обращение цепочки a обозначается как aR): ab = ba Нет
Является ли представленное ниже тождество истинным для двух произвольных цепочек символов a и b (обращение цепочки a обозначается как aR): |aR | = |a| Да
Является ли представленное ниже тождество истинным для двух произвольных цепочек символов a и b (обращение цепочки a обозначается как aR): (a²b²)R = (bRaR) ² Нет
Является ли представленное ниже тождество истинным для двух произвольных цепочек символов a и b (обращение цепочки a обозначается как aR): (a²b²)R = (bR) ² (aR) ² да
К какому типу относится язык десятичных чисел с фиксированной точкой? Регулярному
Поездом называется произвольная последовательность локомотивов и вагонов, начинающаяся с локомотива. Ниже представлена грамматика для понятия <поезд> в расширенной форме Бэкуса—Наура, считая, что понятия <локомотив> и <вагон> являются терминальными символами:
<Поезд> → < локомотив >{<вагон>}
Какие из перечисленных составов порождаются данной грамматикой: Нет
Верно ли утверждение: Число процедур для алгоритма рекурсивного спуска равно числу символов в полном алфавите грамматики? Нет
Верно ли утверждение: Структура процедуры рекурсивного спуска соответствует структуре правой части правил для данного нетерминала? да Верно ли утверждение: Фигурным скобкам в правой части правил грамматики для нетерминала в процедуре рекурсивного спуска соответствует цикл? да Верно ли утверждение: Нетерминальному символу в правой части правил грамматики в процедуре рекурсивного спуска соответствует вызов процедуры? да
Верно ли утверждение: Терминальному символу в правой части правил грамматики в процедуре рекурсивного спуска соответствует вызов процедуры? Нет
Верно ли утверждение: Терминальному символу в правой части правил грамматики соответствует в процедуре рекурсивного спуска его сопоставление с очередным символом входной строки? да Верно ли утверждение: Нетерминальному символу в правой части правил соответствует в процедуре рекурсивного спуска его сопоставление с очередным символом входной строки? Нет Верно ли утверждение: Алгоритм рекурсивного спуска зацикливается, если в грамматике есть хотя бы один леворекурсивный символ? да
Верно ли утверждение: Для использования алгоритма рекурсивного спуска необходимо, чтобы в грамматике был хотя бы один леворекурсивный символ? Нет
Верно ли утверждение: Алгоритм рекурсивного спуска ориентирован на анализ языков LR(k) грамматик? Нет
Верно ли утверждение: Алгоритм рекурсивного спуска ориентирован на анализ языков LL(1) грамматик? да
Верно ли утверждение: Для использования алгоритма рекурсивного спуска необходимо, чтобы грамматика была представлена в виде списковой структуры? Нет Верно ли утверждение: При использовании алгоритма рекурсивного спуска дерево вывода в явном виде не строится? да Верно ли утверждение: При использовании алгоритма рекурсивного спуска дерево вывода строится в явном виде? Нет Из скольких процедур будет состоять синтаксический анализатор, построенный на основе использования алгоритма рекурсивного спуска для следующей грамматики арифметического выражения:
Е → ТЕ' ; Е'→ (+T|-T) Е' | ε ; T → FT' ; T' → (*F|/F)T' | ε ; F → (E) | I ?
5
Верно ли утверждение: следующая грамматика арифметического выражения:
Е → ТЕ' ; Е'→ (+T|-T) Е' | ε ; T → FT' ; T' → (*F|/F)T' | ε ; F → (E) | I
не содержит цепных правил?
да
Верно ли утверждение: следующая грамматика арифметического выражения:
Е → ТЕ' ; Е'→ (+T|-T) Е' | ε ; T → FT' ; T' → (*F|/F)T' | ε ; F → (E) | I
содержит два цепных правила?
Нет
Верно ли утверждение: для следующей грамматики арифметического выражения:
Е → ТЕ' ; Е'→ (+T|-T) Е' | ε ; T → FT' ; T' → (*F|/F)T' | ε ; F → (E) | I
может быть использован алгоритм рекурсивного спуска без возвратов?
да
Верно ли утверждение: для следующей грамматики арифметического выражения:
Е → ТЕ' ; Е'→ (+T|-T) Е' | ε ; T → FT' ; T' → (*F|/F)T' | ε ; F → (E) | I
не может быть использован алгоритм рекурсивного спуска без возвратов? Нет
Верно ли утверждение: Для выполнения синтаксического анализа с использованием алгоритма рекурсивного спуска необходимо вызвать процедуру, соответствующую начальному символу грамматики? да Верно ли утверждение: Для выполнения синтаксического анализа с использованием алгоритма рекурсивного спуска необходимо последовательно вызвать все процедуры, соответствующие нетерминальным символам грамматики? Нет
Анализатор, который представляет собой программу, содержащую процедуры для каждого нетерминального символа, называется: Предиктивным
Анализатор, который представляет собой программу, содержащую процедуры для каждого нетерминального символа, называется: Предиктивным Предсказывающим
Предиктивный анализатор состоит из процедур для … символов: Нетерминальных
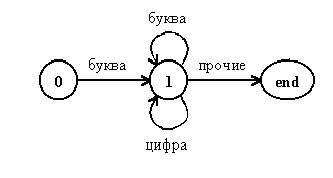
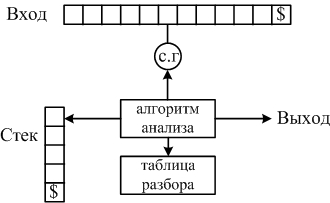
Синтаксический анализатор, изображённый на рисунке, называется:
Нерекурсивным
Верно ли утверждение: Нерекурсивный предиктивный синтаксический анализатор можно построить с помощью неявного использования стека. Нет
Нерекурсивный предиктивный синтаксический анализатор можно построить с помощью … использования стека. Явного
Проблема предиктивного анализа заключается в определении … Продукции
При построении предиктивного синтаксического анализатора используются функции: FIRST FOLLOW Множество терминальных цепочек, выводимых из FIRST( k, α)
Множество укороченных до k символов терминальных цепочек, которые могут следовать непосредственно за FOLLOW(k, A)
Имеется грамматика: Е → ТЕ'; Е'→ +ТЕ'|ε; Т → FT'; T'→ *FT'| ε; F → (E)| I. Укажите множество FIRST(E): FIRST(E) = FIRST(T) = FIRST(F) = {‘(‘, I}.
Имеется грамматика: Е → ТЕ'; Е'→ +ТЕ'|ε; Т → FT'; T'→ *FT'| ε; F → (E)| I. Укажите множество FIRST(Е'): FIRST(Е') = {+,ε};
Имеется грамматика: Е → ТЕ'; Е'→ +ТЕ'|ε; Т → FT'; T'→ *FT'| ε; F → (E)| I. Укажите множество FOLLOW(F): FOLLOW(F) = {+,*,’)’,$};
Верно ли утверждение: LL(1)-грамматика не может содержать для любого нетерминального символа Да
Верно ли утверждение: Грамматика вида: Е → ТЕ'; Е'→ +ТЕ'|ε; Т → FT'; T'→ *FT'| ε; F → (E)| I. является LL(1)-грамматикой. Да
Если цепочка {b}
Если цепочка FIRST(1, B)
Результатом работы восходящих распознавателей является … вывод Правосторонний
Восходящий синтаксический анализ дерево разбора для входной строки строит: Снизу вверх
Основные понятия, связанные с восходящим анализом: Редукция Основа
Свёртка исходной строки в начальный символ грамматики путём выполнения последовательностей редукций, соответствует: Восходящему анализу
Восходящий распознаватель по алгоритму «сдвиг-свёртка» строится на основе … автомата: Магазинного
Основными операциями восходящего синтаксического анализатора, являются: Перенос Свёртка
В восходящем синтаксическом анализаторе основа всегда находится … На вершине стека
В восходящем синтаксическом анализаторе основа всегда находится … На вершине стека
Префиксы правосентенциальных форм, которые встречаются в стеке восходящего анализатора, называются: Активными
КС-грамматика без λ-правил, в которой правые части всех правил не содержат смежных нетерминальных символов, называется: Операторной Верно ли утверждение: Грамматика вида:
является операторной Нет
Верно ли утверждение: В грамматике простого предшествования не могут присутствовать цепные правила? Да Верно ли утверждение: Класс LL-грамматик является более широким, чем класс LR-грамматик. Нет Верно ли утверждение: Для каждого КС языка, заданного LR-грамматикой может быть построена LL-грамматика, задающая тот же язык. Нет Верно ли утверждение: Для каждого КС языка, заданного LL-грамматикой может быть построена LR-грамматика, задающая тот же язык. Да LR-грамматика для любого Однозначной Верно ли утверждение: В грамматике простого предшествования могут присутствовать цепные правила? Нет Верно ли утверждение: В грамматике операторного предшествования могут присутствовать цепные правила? Да Верно ли утверждение: В грамматике простого и операторного предшествования не могут присутствовать λ - правила? Да Распознаватель для грамматик предшествования строится на основе алгоритма: «Сдвиг-свёртка»
КС-грамматика G(VN,VT,P,S), V=VT o для каждой упорядоченной пары терминальных символов выполняется не более чем одно из трёх отношений предшествования; o различные порождающие правила имеют разные правые части, λ – правила отсутствуют; называется грамматикой … Простого предшествования
Всякая грамматика простого предшествования является … Однозначной
Верно ли утверждение: Всякая грамматика простого предшествования является однозначной? Да
Верно ли утверждение: Всякая грамматика операторного предшествования является однозначной? Нет
Верно ли утверждение: Всякая грамматика операторного предшествования задаёт детерминированный КС-язык? Да
Детерминированный КС-язык задаёт грамматика … предшествования: Операторного
Отношения операторного предшествования проверяются в процессе разбора только между … символами: Терминальными
Размер матрицы для грамматики операторного предшествования всегда будет …, чем размер матрицы эквивалентной ей грамматики простого предшествования: Меньше
Верно ли утверждение: Размер матрицы для грамматики операторного предшествования всегда будет больше, чем размер матрицы эквивалентной ей грамматики простого предшествования: Нет
а “забирает приоритет у” b:
Оператор * имеет более высокий приоритет, чем оператор +. При получении выражения вида E+E*E+E основой является: E*E
в выражении
На рисунке представлена модель … -анализатора:
LR-анализатора
В LR-анализаторе функция Завершается.
Верно ли утверждение: LR-анализатор может обнаруживать синтаксические ошибки сразу же, как только это становится возможным при сканировании входного потока Да
Грамматика, для которой мы можем построить таблицу синтаксического анализа, называется … - грамматикой. LR
Верно ли утверждение: Любая грамматика, содержащая λ - правила, не может быть LR(0) – грамматикой: Да
Количество шагов алгоритма функционирования распознавателя LR(k)-грамматики при росте длины входной цепочки символов растёт …: Линейно
Распознаватель для LR(k)-грамматики является … Линейным
Верно ли утверждение: Класс языков, заданных LR(1)-грамматиками, полностью совпадает с классом детерминированных КС-языков. Да
Управляющая таблица для LR(0)-грамматики строится на основании понятия: “левых контекстов”
Грамматика, для разбора которой LR-анализатору требуется просмотр до k символов входного потока на каждом шаге, называется: LR(k)-грамматикой
Верно ли утверждение: LR-грамматики могут описывать больше языков, чем LL-грамматики: Да
Соответствие методов построения таблицы LR-анализа для грамматики и мощностей для них: а) LALR 1) наиболее мощный б) SLR 2) занимает промежуточное положение в) канонический LR 3) наименее мощный а) –2); б) –3); в) –1)
Работа распознавателя для LR(k)-грамматик основана на использовании алгоритма …: Сдвиг-свёртка
Верно ли утверждение: Всякий детерминированный КС-язык может быть задан SLR(1)-грамматикой: Нет
Верно ли утверждение: Любой детерминированный КС-язык может быть задан LALR(1)-грамматикой: Да
LR(0) – пункт грамматики G – продукция G с точкой в некоторой позиции правой части. Продукция 1. 2. 3. 4. Какой из пунктов определяет, что во входном потоке есть входная строка, порождённая X, ожидаем получить из входного потока строку, порождаемую YZ. 2
LR(0) – пункт грамматики G – продукция G с точкой в некоторой позиции правой части. Продукция 1. 2. 3. 4. Какой из пунктов определяет, что во входном потоке мы ожидаем встретить строку, порождаемую XYZ 1
Любая LL-грамматика и любая LR-грамматика являются …: Однозначными
Верно ли утверждение: Каждая неоднозначная грамматика может быть LR-грамматикой: Нет Грамматика, описывающая арифметические выражения с операторами * и +: E → E+E | E*E | (E) | I является: Неоднозначной
Верно ли утверждение: Грамматика: E → E+T | T; T → T*F | F; F → (E) | I является однозначной Да
Правила, определяющие зависимости между атрибутами, которые представляются графом, называются Семантическими
Дерево разбора, показывающее значения атрибутов в каждом узле, называется: Аннотированным
Атрибуты, значения которых в узле дерева разбора определяются атрибутами родительского и/или дочерних по отношению к родительскому узлов, называются: Наследуемыми
Зависимости между наследуемыми и синтезируемыми атрибутами в узлах дерева разбора показываются с помощью направленного графа, называемого графом … Зависимости
Верно ли утверждение: Значение синтезируемого атрибута в узле вычисляется по значениям атрибутов в дочерних по отношению к данному узлах Да
Дерево разбора в сжатом виде, удобном для представления языковых конструкций, называется: Синтаксическим
Граф, у которого узел представляет общее подвыражение, имеющее более чем одного “родителя”, называется Дагом
Синтаксически управляемые определения, в которых применяются исключительно синтезируемые атрибуты – это: S-атрибутные определения
Верно ли утверждение: Транслятор для S-атрибутного определения может быть реализован с помощью генератора LR-анализаторов типа Yacc. Да
Верно ли утверждение: L-атрибутные определения включают все синтаксически управляемые определения, основанные на LL(1)-грамматиках. Да
Если каждый наследуемый атрибут символа o атрибутов символов o наследуемых атрибутов А, то синтаксически управляемое определение является L-атрибутным
Схема, представляющая собой контекстно-свободную грамматику, в которой атрибуты, связанные с символами грамматики, и семантические действия заключены в фигурные скобки ( { } ) и вставлены в правые части продукции, называется: Схемой трансляции
Программа, предназначенная для построения синтаксического анализатора КС-языка: YACC
Проверка, выполняемая компилятором, называется: Статической
Проверка, выполняемая целевой программой, называется: Динамической
Если компилятор языка может гарантировать, что скомпилированная программа будет выполняться без ошибок, связанных с типами, то такой язык называется: Строго типизированным
Верно ли утверждение: Два выражения типа структурно эквивалентны тогда и только тогда, когда они идентичны. Да Если два выражения либо представляют собой один и тот же базовый тип, либо сформированы путём одного и того же конструктора, то эти выражения: Структурно эквивалентны
С точки зрения … эквивалентности имя каждого типа представляет собственный тип, отличный от типа с другим именем. Именной
Верно ли утверждение:
С точки зрения структурной эквивалентности все пять переменных имеют один и тот же тип. Да
Преобразование одного типа в другой, когда оно выполняется компилятором автоматически, называется: Неявным
Преобразование, для задания которого программист должен специально что-то написать, называется: Явным
Верно ли утверждение: Явные преобразования с точки зрения программы проверки типов выглядят как применение функции. Да
Символ, имеющий различные значения в зависимости от своего контекста, называется: Перегруженным
Верно ли утверждение: В математике перегруженным символом является + Да
Перегрузка, при которой значение перегруженного символа определяется однозначно, называется: Разрешимой
Функции, которые могут быть выполнены с аргументами “различного типа” называются: Полиморфными
Процедуры, возвращающие значения, называются Функциями
Аргументы, передаваемые вызываемой процедуре, называются Фактическими
Идентификаторы в определении процедуры, имеющие специальный характер, называются: Формальными
Каждое выполнение процедуры, называется ее … Активацией
“Время …” активации процедуры означает последовательность шагов в процессе выполнения программы. Жизни
Верно ли утверждение: Если a и b – активации процедуры, то их времена жизни либо не перекрываются, либо вложены. Да
Если новая активация процедуры может начаться до того, как завершилась её же более ранняя активация, то процедура называется … Рекурсивной
Дерево, для которого выполняются условия:
называется деревом … Активации
Для отслеживания работающих активаций процедур используется … управления Стек
Синтаксическая конструкция, связывающая информацию с именем, называется: Объявлением
В приведённом фрагменте программы var i : integer ; объявление … Явное
Если вхождение имени в процедуре находится в области видимости объявления, расположенного внутри процедуры, то оно называется Локальным
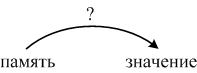
Среда
Какой термин означает функцию, отображающую местоположение в памяти в хранящееся там значение:
Состояние
Информация, необходимая для однократного выполнения процедуры, поддерживается с помощью непрерывного блока памяти, называемого … Кадром Записью активации
Для всех объектов данных в процессе компиляции используется … распределение памяти: Статическое
Верно ли утверждение: При статическом распределении памяти связь имён с местоположениями в памяти в процессе работы не изменяется и всякий раз при активации процедур их имена связываются с одними и теми же адресами памяти. Да
Верно ли утверждение: При стековом распределении памяти локальные переменные при каждом вызове связываются с новой областью памяти. Да
При стековом распределении памяти значения локальных переменных по окончании активации: Уничтожаются
Верно ли утверждение: При стековом распределении памяти значения локальных переменных по окончании активации сохраняются Нет
Метод передачи параметров, при котором происходит вычисление фактических параметров и полученные r-значения передаются вызываемой процедуре, называется: По значению
Верно ли утверждение: При передаче параметров по значению операции над формальными параметрами не влияют на значения в записи активации вызывающей программы. Да
Метод передачи параметров, при котором вызывающая процедура передаёт вызываемой указатель на адрес памяти каждого фактического параметра, называется: По ссылке
Верно ли утверждение: При вызове процедур и функций число и типы фактических параметров должны быть согласованы с числом и типами формальных параметров. Да
Для отслеживания области видимости и информации о связях имён компилятор использует: Таблицу символов
Для отслеживания области видимости и информации о связях имён компилятор использует таблицу … Символов
Для работы с таблицей символов используются: Хеш-таблицы
Выделенная программой память, к которой невозможно обратиться, называется Мусором
Последовательность инструкций вида x := y op z, где x,y,z – имена, константы или временные переменные, генерируемые компилятором; op – некоторый оператор, называется: Трёхадресным кодом
Реализация трёхадресных инструкций может быть представлена: Четвёрками Тройками Косвенными тройками
Верно ли утверждение: Любой язык программирования является контекстно-свободным: Нет
Все реальные языки программирования являются: Контекстно-зависимыми
Верно ли утверждение: Синтаксис любого языка программирования может быть описан с помощью контекстно-свободной грамматики: Нет
Верно ли утверждение: Полный разбор исходной программы компилятор может выполнить в рамках КС-языков с помощью КС-грамматик и МП-автоматов. Нет
Все реально существующие компиляторы выполняют анализ исходной программы в этапы: Синтаксический анализ Семантический анализ
Верно ли утверждение: Семантический анализ входной программы может быть произведён только после завершения её синтаксического анализа. Да
Распределение памяти выполняется … семантического анализа текста исходной программы. После
По способам распределения область памяти бывает: Статической Динамической
По роли области памяти в результирующей программе она бывает: Глобальной Локальной
Область памяти, которая выделяется один раз при инициализации результирующей программы и действует всё время выполнения результирующей программы, называется: Глобальной
Область памяти, которая выделяется в начале выполнения некоторого фрагмента результирующей программы и может быть освобождена по завершении выполнения данного фрагмента, называется … Локальной
Область памяти, размер которой известен на этапе компиляции, называется: Статической
Область памяти, размер которой на этапе компиляции программы не известен, называется: Динамической
Верно ли утверждение: Для динамической области памяти компилятор не может непосредственно выделить адрес – для неё он порождает фрагмент кода, который отвечает за распределение памяти. Да
Область данных, доступных для обработки в этой процедуре, называется: Дисплеем памяти
Адрес машинной команды, следующей за командой обращения к процедуре или функции – это: Адрес возврата
Адрес машинной команды, следующей за командой обращения к процедуре или функции – это адрес … Возврата
Верно ли утверждение: Адрес возврата никак не обрабатывается в процедуре или функции, но должен быть сохранён на всё время её выполнения Да
Получает на вход промежуточное представление исходной программы и выводит эквивалентную целевую программу – …
Генератор кода
Выходом генератора кода является … Целевая программа
Последовательность смежных инструкций, в которые поток управления входит в их начале и покидает в конце без останова программы, называется … Базовым блоком
Два базовых блока, вычисляющие одинаковые наборы выражений, называются эквивалентными
Запись, при которой операция записывается перед своими операндами, называется: Префиксной
Запись, при которой операция записывается между своими операндами, называется: Инфиксной
Верно ли утверждение: Запись арифметических выражений является примером инфиксной записи Да
Запись математических функций и функций в языках программирования является Префиксной
При исключении из дерева синтаксического разбора цепочки нетерминальных символов и узлов, не несущих смысловой нагрузки при генерации кода, получится дерево … Операций
Верно ли утверждение: Результирующее дерево операций всегда имеет одну и ту же структуру, зависящую только от семантики входного языка Да
Дерево, которое всегда имеет одну и ту же структуру, зависящую только от семантики входного языка, называется: Деревом операций
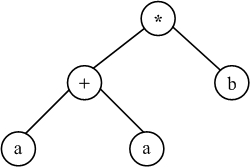
Дерево, представленное диаграммой:
называется: Деревом операций
Запись операций, предложенная польским математиком Я. Лукашевичем, это: Польская запись
В польской записи знаки операций записываются: За операндами
Верно ли утверждение: Польская запись не требует учитывать приоритет операций и в ней не употребляются скобки Да
Верно ли утверждение: Выражения в форме обратной польской записи всегда поддаются оптимизации Нет
Основной метод порождения кода результирующей программы на основании результатов синтаксического анализа – это: Н. Хомским
Важной составной частью генерации хорошего целевого кода является эффективное использование: Регистров
Верно ли утверждение: СУ-перевод является наиболее эффективным методом порождения результирующего кода Нет
Результирующая программа строится не вся сразу, а поэтапно, поэтому необходима … Оптимизация
Результирующая программа строится не вся сразу, а поэтапно, поэтому необходима (необходим): Оптимизация
Верно ли утверждение: Оптимизация – это обязательный этап компиляции Нет
Обработка, связанная с переупорядочиванием и изменением операций в компилируемой программе с целью получения более эффективной результирующей объектной программы, называется … Оптимизацией
Выполняемая по порядку последовательность операций, имеющая один вход и один выход, называется … Линейным участком
Верно ли утверждение: Линейные участки встречаются в любой программе Да
Транслятором
Программа, которая переводит текст программы с языка высокого уровня на язык низкого уровня – машинный код, называется Компилятором
Программа, которая переводит текст программы с языка высокого уровня на язык команд некоторой абстрактной машины, программная реализация которой, как правило, входит в нее, называется интерпретатором.
Программа, которая преобразует входной символьный поток в последовательность более крупных единиц – лексем, называется Лексическим анализатором Сканером
Программа, которая переводит текст программы с языка высокого уровня на язык низкого уровня – машинный код, называется Компилятором
Программа, которая проверяет синтаксическую правильность входной цепочки (уже разбитой на лексемы) и строит её семантическое дерево, называется: Синтаксическим анализатором
Алфавитом называется: Любое конечное множество
Программа, которая переводит текст программы с языка высокого уровня на язык команд некоторой абстрактной машины, программная реализация которой, как правило, входит в нее, называется: Интерпретатором
A* это: |
Последнее изменение этой страницы: 2019-05-08; Просмотров: 594; Нарушение авторского права страницы
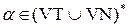 , укороченных до k символов, это:
, укороченных до k символов, это: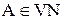 в цепочках вывода, это:
в цепочках вывода, это: 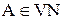 двух правил, начинающихся с одного и того же терминального символа.
двух правил, начинающихся с одного и того же терминального символа.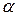 для множества FIRST(1, α) начинается с терминального символа b
для множества FIRST(1, α) начинается с терминального символа b 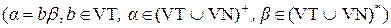 , то FIRST(1, α) = … :
, то FIRST(1, α) = … :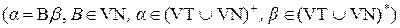 , то FIRST(1, α) = … :
, то FIRST(1, α) = … :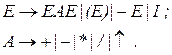
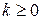 является …
является …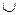 VN, для которой выполняются следующие условия:
VN, для которой выполняются следующие условия: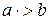
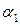 и
и 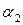 – операторы левоассоциативны и имеют равный приоритет
– операторы левоассоциативны и имеют равный приоритет 
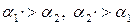
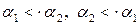
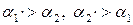 ;
;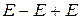 основой является
основой является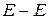
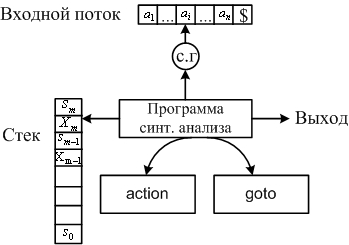
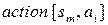 =“допуск”
=“допуск” 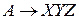 даёт четыре пункта:
даёт четыре пункта: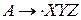
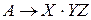
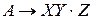
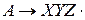
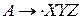
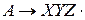
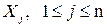 , из правой части продукции
, из правой части продукции 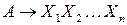 зависит только от
зависит только от , расположенных в продукции слева от
, расположенных в продукции слева от 
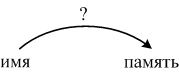 Какой термин означает функцию, отображающую имя в местоположение в памяти:
Какой термин означает функцию, отображающую имя в местоположение в памяти: