
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Ключевые аспекты организации уровня передачи данных. Сервисы, предоставляемые сетевому уровню. Формирование кадра.Стр 1 из 25Следующая ⇒
Ключевые аспекты организации уровня передачи данных. Сервисы, предоставляемые сетевому уровню. Формирование кадра. Ключевые аспекты организации уровня передачи данных. Уровень передачи данных должен выполнять ряд специфических функций. К ним относятся: • обеспечение строго очерченного служебного интерфейса для сетевого уровня; • обработка ошибок передачи данных; • управление потоком данных, исключающее затопление медленных прием- ников быстрыми передатчиками. Для этих целей канальный уровень берет пакеты, полученные с сетевого уровня, и вставляет их в специальные кадры для передачи. В каждом кадре содержится заголовок, поле данных и концевик. Управление кадрами — это основа деятельности уровня передачи данных. Сервисы, предоставляемые сетевому уровню Задача уровня передачи данных заключается в предоставлении сервисов сетевому уровню. Основным сервисом является передача данных от сетевого уровня передающей машины сетевому уровню принимающей машины. На передающей ма- шине работает некая сущность, или процесс, который передает биты с сетевого уровня на уровень передачи данных для передачи их по назначению. Работа уров- ня передачи данных заключается в передаче этих битов на принимающую маши- ну так, чтобы они могли быть переданы сетевому уровню принимающей машины, как показано на рис. 3.2, а. В действительности данные передаются по пути, пока- занному на рис. 3.2, б, однако проще представлять себе два уровня передачи дан- ных, связывающихся друг с другом при помощи протокола передачи данных. По этой причине на протяжении этой главы будет использоваться модель, изобра- женная на рис. 3.2, а.
Уровень передачи данных может предоставлять различные сервисы. Их на- бор может быть разным в разных системах. Обычно возможны следующие вари- анты. 1. Сервис без подтверждений, без установки соединения. 2. Сервис с подтверждениями, без установки соединения. 3. Сервис с подтверждениями, ориентированная на соединение.
A) Сервис без подтверждений и без установки соединения заключается в том, что передающая машина посылает независимые кадры принимающей машине, а принимающая машина не посылает подтверждений о приеме кадров. Никакие соединения заранее не устанавливаются и не разрываются после передачи кад- ров. B) Cервис с под-тверждениями, без установки соединения. При его использовании соединение так- же не устанавливается, но получение каждого кадра подтверждается. Таким об- разом, отправитель знает, дошел ли кадр до пункта назначения в целости. Если в течение установленного интервала времени подтверждения не поступает, кадр посылается снова. Такая служба полезна в случае использования каналов с боль- шой вероятностью ошибок, например, в беспроводных системах. C) При использовании ориентированного на соединение сервиса передача дан- ных состоит из трех различных фаз. В первой фазе устанавливается соединение, при этом обе стороны инициализируют переменные и счетчики, необходимые для слежения за тем, какие кадры уже приняты, а какие — еще нет. Во второй фазе передаются кадры данных. Наконец, в третьей фазе соединение разрывается и при этом освобождаются все переменные, буферы и прочие ресурсы, использо- вавшиеся во время соединения. Формирование кадра. Поскольку для отметки начала и конца кадра полагаться на временные параметры слишком рискованно, были разработаны другие методы. В данном разделе мы рассмотрим четыре метода маркировки границ кадров. 1. Подсчет количества символов. 2. Использование стартовых и стоповых символов, с символьным заполнением. 3. Использование стартовых и стоповых битов, с битовым заполнением. 4. Использование запрещенных сигналов физического уровня. Первый метод формирования кадров использует поле в заголовке для указания количества символов в кадре. Когда уровень передачи данных на принимающем компьютере видит количество символов, он узнает, сколько символов последует, и, таким образом, определит, где находится конец кадра. Эта техника проиллюстрирована на рис. 3.3, а для четырех кадров размером 5, 5, 8 и 8 символов соответственно. Второй метод формирования кадров решает проблему восстановления синхронизации после сбоя при помощи маркировки начала каждого кадра последовательностью ASCII символов DLE STX и конца кадра — символами DLE ETX. (DLE означает Data Link Escape — смена канала данных, код 16; STX, Start of TeXt — начало текста, код 2; ETX, End of TeXt — конец текста, код 3). При таком способе формирования кадра, если принимающий компьютер потеряет границу кадра, он должен всего лишь найти последовательность символов DLE ETX или DLE STX. Главный недостаток этого метода заключается в том, что он тесно связан с 8-битовыми символами в целом и с символами ASCII в частности. По мере развития сетей недостатки использования символьного кода в механизме формирования кадра становились все более очевидными, поэтому потребовалось создание новой техники, допускающей использование символов произвольного размера. Данная техника позволяет использовать кадры и наборы символов из любого количества битов. Каждый кадр начинается и завершается специальной последовательностью битов, 01111110, называемой флаговым байтом. Если в битовом потоке передаваемых данных встретится пять идущих подряд единиц, уровень передачи данных автоматически добавит к ним 0-й бит. Битовое заполнение аналогично символьному, при котором дублировался встречающийся в данных символ DLE. Когда принимающая сторона видит пять единиц подряд, за которыми следует ноль, она автоматически удаляет этот 0. Битовое заполнение, как и символьное, является абсолютно прозрачным для сетевого уровня обоих компьютеров. Если флаговая последовательность бит 01111110 встречается в данных пользователя, она передается в виде 011111010, но на сетевой уровень принимающего компьютера попадает опять в исходном виде 01111110. На рис. 3.5 приведен пример битового заполнения. Благодаря битовому заполнению границы между двумя кадрами могут быть безошибочно распознаны с помощью флаговой последовательности. Таким образом, если приемная сторона потеряет границы кадров, ей нужно всего лишь отыскать в полученном потоке битов флаговый байт, поскольку он встречается только на границах кадров и никогда в данных пользователя. Четвертый метод формирования кадров приемлем только в сетях, в которых физический носитель обладает некоторой избыточностью. Например, некоторые локальные сети кодируют один бит данных двумя физическими битами. Обычно бит 1 кодируется парой высокого и низкого сигналов, а бит 0 — наоборот, парой низкого и высокого сигналов. Комбинации сигналов высокий-высокий и низкий-низкий не используются для кодирования данных. В такой схеме каждый передаваемый бит данных содержит в середине переход, благодаря чему упрощается распознавание границ битов.
Обработка ошибок. Решив проблему маркировки начала и конца кадра, мы сталкиваемся с новой проблемой: как гарантировать доставку сетевому уровню принимающей машины всех кадров, и при этом в правильном порядке. Предположим, что отправитель просто посылает кадры, не заботясь о том, дошли ли они до адресата. Этого было бы достаточно для службы без подтверждений и без установления соединения, но не для ориентированной на соединение службы с подтверждениями. Обычно для гарантирования надежной доставки поставщику посылается информация о том, что происходит на другом конце линии. Протокол требует от получателя посылать обратно специальные управляющие кадры, содержащие позитивные или негативные подтверждения о полученных кадрах. Получив позитивное подтверждение, отправитель узнает, что посланный им кадр успешно получен на том конце линии. Негативное подтверждение, напротив, означает, что с кадром что-то случилось и его нужно передать снова. Кроме того, посланный кадр может из-за неисправности или помехи пропасть полностью. В данном случае принимающая сторона его просто не получит и, соответственно, никак не прореагирует, а отправитель может вечно ожидать положительного или отрицательного ответа и так ничего и не получить. Чтобы избежать зависаний сети в случае полной потери кадров, в уровне передачи данных используются таймеры. После посылки кадра включается таймер, отсчитывая интервал времени, достаточный для получения принимающим компьютером этого кадра, его обработки и посылки обратно подтверждения. В нормальной ситуации кадр правильно принимается, а подтверждение посылается назад и вручается отправителю, прежде чем истечет установленный интервал времени, после этого таймер отключается. Однако, если либо кадр, либо подтверждение теряется по пути, установленный интервал времени истечет и отправитель получит сообщение о возможной проблеме. Самым простым решением для отправителя будет послать кадр еще раз. Однако при этом возникает опасность получения одного и того же кадра несколько раз уровнем передачи данных принимающего компьютера и повторной передачи его сетевому уровню. Чтобы этого не случилось, необходимо пронумеровать отсылаемые кадры, так чтобы получатель мог отличить повторно переданные кадры от оригиналов. Управление потоком. Еще один важный аспект разработки уровня передачи данных (а также более высоких уровней) связан с вопросом, что делать, если отправитель постоянно желает передавать кадры быстрее, чем получатель способен их получать. Такая ситуация может возникнуть, если у передающей стороны оказывается более мощный (или менее загруженный) компьютер, чем у принимающей. Отправитель продолжает посылать кадры на высокой скорости до тех пор, пока получатель не окажется полностью ими завален. Даже при идеально работающей линии связи в определенный момент получатель просто не сможет продолжать обработку все прибывающих кадров и начнет их терять. Очевидно, что для предотвращения подобной ситуации следует что-то предпринять. Обычным решением в данном случае является использование управления потоком, ограничивающего скорость передатчика скоростью, с которой приемник может обрабатывать поток. Для такого ограничения необходим механизм обратной связи между получателем и отправителем, информирующий отправителя о способности или неспособности получателя продолжать принимать информацию. На сегодняшний день разработано много схем регулирования потока, но в большинстве из них используется один и тот же принцип. Протокол содержит четко определенные правила, определяющие, когда отправитель может посылать следующий кадр. Эти правила часто запрещают пересылку кадра до тех пор, пока получатель не даст разрешения, либо явно, либо неявно. Например, при установке соединения получатель может сказать: «Вы можете послать мне сейчас n кадров, но не посылайте следующие кадры, пока я не попрошу вас продолжать». В данной главе мы рассмотрим различные механизмы, основанные на этом принципе. Другие механизмы будут обсуждаться в последующих главах.
Корректирующее кодирование. Разработчики сетей создали две основные стратегии для борьбы с ошибками. Каждый метод основывается на добавлении к передаваемым данным некоторой избыточной информации. В одном случае этой информации должно быть достаточно, чтобы с большой вероятностью обнаружить наличие искаженных битов. В другом случае избыточной информации должно быть достаточно даже для того, чтобы восстановить поврежденный блок данных. Коды, применяемые в обоих случаях, называются помехоустойчивыми. Коды, позволяющие исправлять ошибки, называются корректирующими или кодами с исправлением ошибок. Чтобы понять, как могут обнаруживаться и исправляться ошибки, необходимо рассмотреть подробнее, что представляет собой ошибка. Обычно кадр состоит из m бит данных (то есть информационных) и r избыточных или контрольных битов. Пусть полная длина кадра равна n (то есть n = m + r). Набор из n бит, содержащий информационные и контрольные биты, часто называют n-битовым кодовым словом или кодовой комбинацией. Если рассмотреть два кодовых слова, например 10001001 и 10110001, можно определить число отличающихся в них соответствующих разрядов. В данном примере отличаются три бита. Для нахождения этого числа нужно сложить два кодовых слова по модулю 2 (операция «исключающее или») и сосчитать количество единиц в результате. Количество бит, которыми отличаются два кодовых слова, называется кодовым расстоянием или расстоянием между кодовыми комбинациями в смысле Хэмминга (Hamming) [129]. Смысл этого числа в том, что если два кодовых слова находятся на кодовом расстоянии d, то для преобразования одного кодового слова в другое понадобится d ошибок в одиночных битах. В большинстве приложений передачи данных все 2m возможных сообщений являются допустимыми, однако благодаря использованию контрольных битов не все 2n возможных кодовых слов используются. Зная алгоритм формирования контрольных разрядов, можно построить полный список всех допустимых кодовых слов и в этом списке найти такую пару кодовых слов, кодовое расстояние между которыми будет минимальным. Это расстояние называется минимальным кодовым расстоянием кода или расстоянием всего кода в смысле Хэмминга. В качестве простейшего примера кода с обнаружением ошибок рассмотрим код, в котором к данным добавляется один бит четности. Бит четности выбирается таким образом, чтобы количество единиц во всем кодовом слове было четным (или нечетным). Например, при посылке числа 10110101 с добавлением бита четности в конце оно становится равным 101101011, тогда как 10110001 преобразуется в 101100010. Код с единственным битом четности имеет кодовое расстояние, равное 2, так как любая однократная ошибка в любом разряде образует кодовое слово с неверной четностью. Такой код может использоваться для обнаружения однократных ошибок. В качестве простейшего примера корректирующего кода рассмотрим код, у которого есть всего четыре допустимые кодовые комбинации: 0000000000, 0000011111, 1111100000 и 1111111111. Этот код имеет расстояние, равное 5, что означает, что он может исправлять двойные ошибки. Если приемник получит кодовое слово 0000000111, он поймет, что оригинал должен быть равен 0000011111. Однако если тройная ошибка изменит 0000000000 в 0000000111, ошибка будет исправлена неверно. Попробуем создать код, состоящий из m информационных и r контрольных битов, способный исправлять одиночные ошибки. Каждому из 2m допустимых сообщений будет соответствовать n недопустимых кодовых слов, отстоящих от сообщения на расстояние 1. Их можно получить инвертированием каждого из n битов n-битового кодового слова. Таким образом, каждому из 2m допустимых сообщений должны соответствовать n + 1 кодовых комбинаций. Поскольку общее количество возможных кодовых комбинаций равно 2n, получается, что (n + 1)2m Ј 2m. Так как n = m + r, это требование может быть преобразовано к виду: (m + r + 1) Ј 2r. При заданном m данная формула описывает нижний предел для требуемого количества контрольных битов для возможности исправления одиночных ошибок. Этот теоретический предел может быть достигнут на практике с помощью метода Хэмминга Коды с обнаружением ошибок. Коды, исправляющие ошибки, иногда используются при передаче данных, например в случае симплексного канала, в котором нельзя запросить повторную передачу. Однако чаще более эффективным оказывается обнаружение ошибки с последующей повторной передачей. Например, рассмотрим канал с изолированными ошибками, возникающими с вероятностью 10–6 на бит. Пусть блок данных состоит из 1000 бит. Для создания кода, корректирующего однократные ошибки, потребуется 10 дополнительных битов на блок. Для мегабита данных это составит 10 000 проверочных битов. Чтобы просто обнаруживать одиночную 1-битовую ошибку, достаточно одного бита четности на блок. На каждые 1000 блоков придется переслать повторно в среднем еще один блок. Таким образом, суммарные накладные расходы такого метода составят всего 2001 бит на мегабит данных против 10 000 битов, необходимых для кода Хэмминга. Если к блоку добавлять всего один бит четности, то в случае пакета ошибок вероятность обнаружения ошибки будет всего лишь 0,5, что абсолютно неприемлемо. Этот недостаток может быть исправлен, если рассматривать каждый посылаемый блок как прямоугольную матрицу n бит шириной и k бит высотой. Бит четности должен вычисляться отдельно для каждого столбца и добавляться к матрице в виде последнего ряда. Затем матрица передается по рядам. Приемник проверяет все биты четности. Если хотя бы один из них неверен, он запрашивает повторную отсылку всего блока. Такой метод позволяет обнаружить одиночный пакет ошибок длиной не более n, так как в этом случае будет изменено не более одного бита в каждом столбце. Однако пакет ошибок длиной n + 1 не будет обнаружен, если будут инвертированы первый и последний биты, а все остальные биты останутся неизменными. (Пакет ошибок не предполагает, что все биты неверны, предполагается только, что, по меньшей мере, первый и последний биты инвертированы.) Если блок подвергнется при передаче длинному пакету ошибок или нескольким одиночным ошибкам, вероятность того, что четность любого из n столбцов будет верной (или неверной), равна 0,5, поэтому вероятность необнаружения ошибки будет равна 2–n. Хотя приведенная выше схема может в некоторых случаях быть приемлемой, тем не менее на практике широко используется другой метод: полиномиальный код, также известный как CRC (Cyclical Redundancy Code — циклический избыточный код). В основе полиномиальных кодов лежит представление битовых строк в виде многочленов с коэффициентами, равными 0 или 1. Кадр из k бит рассматривается как список коэффициентов многочлена степени k – 1, состоящего из k членов от xk – 1 до x0. Старший (самый левый) бит кадра соответствует коэффициенту при xk – 1, следующий бит — коэффициенту при xk – 2 и т. д. Например, число 110001 состоит из 6 бит и, следовательно, представляется в виде многочлена пятой степени с коэффициентами 1, 1, 0, 0, 0 и 1: x5 + x4 + 1. С данными многочленами осуществляются арифметические действия по модулю 2 в соответствии с алгебраической теорией поля. При этом вычитание не отличается от сложения, перенос в следующий или предыдущий разряд не производится.
Протоколы скользящего окна. Сущность всех протоколов скользящего окна заключается в том, что в любой момент времени отправителем поддерживается набор последовательных номеров, соответствующих кадрам, которые ему разрешено посылать. Про такие кадры говорят, что они попадают в посылающее окно. Аналогично получатель поддерживает принимающее окно, соответствующее набору кадров, которые ему позволяется принять. Окно получателя и окно отправителя не обязаны иметь одинаковые нижний и верхний пределы или даже быть одного размера. В некоторых протоколах их размер фиксируется, однако в других они могут увеличиваться или уменьшаться по мере передачи или приема кадров. Хотя данные протоколы предоставляют уровню передачи данных большую свободу в вопросе, касающемся порядка передачи и приема кадров, требование доставки пакетов сетевому уровню принимающей машины в том же прядке, в котором они были получены от сетевого уровня передающей машины, сохраняется. Также сохраняется аналогичное требование к физическому уровню, касающееся сохранения порядка доставки кадров. То есть физический уровень должен функционировать подобно проводу. Последовательные номера в окне отправителя представляют кадры, которые уже отправлены, но на которые еще не получены подтверждения. Получаемому от сетевого уровня пакету дается наибольший последовательный номер, и верхний край окна увеличивается на единицу. Когда поступает подтверждение, на единицу поднимается нижний край окна. Таким образом, окно постоянно содержит список неподтвержденных кадров. Поскольку кадры, находящиеся в окне отправителя, могут быть потеряны или повреждены во время их передачи, отправитель должен хранить все эти кадры в памяти на случай возможной повторной передачи. Таким образом, если максимальный размер кадра равен n, отправителю требуется n буферов для хранения неподтвержденных кадров. Если окно достигает максимального размера, уровень передачи данных должен отключить сетевой уровень до тех пор, пока не освободится буфер. Окно принимающего уровня передачи данных соответствует кадрам, которые он может принять. Любой кадр, не попадающий в окно, игнорируется без каких-либо комментариев. Когда прибывает кадр с последовательным номером, соответствующим нижнему краю окна, он передается сетевому уровню, формируется подтверждение, и окно сдвигается на одну позицию. В отличие от окна отправителя окно получателя всегда сохраняет свой изначальный размер. Окно размером, равным 1, означает, что уровень передачи данных может принимать кадры только в установленном порядке, однако при больших размерах окна это не так. Сетевому уровню, напротив, данные всегда предоставляются в строгом порядке, независимо от размера окна уровня передачи данных. Протокол с возвратом на n. До сих пор мы молчаливо подразумевали, что время, необходимое на распространение кадра от отправителя до получателя, и время, необходимое на распространение подтверждения от получателя до отправителя, пренебрежимо мало. Иногда это предположение является совершенно неверным. В таких ситуациях большое время прохождения кадров по сети может значительно снижать эффективность использования пропускной способности канала. В качестве примера рассмотрим спутниковый канал связи с пропускной способностью 50 кбит/с и временем, требуемым для прохождения сигнала в оба конца, равным 500 мс. Попытаемся использовать протокол 4 для пересылки кадров размером в 1000 бит через спутник. В момент времени t = 0 отправитель начинает посылать первый кадр. В момент времени t = 20 мс кадр полностью послан. В момент времени t = 270 мс получатель принял кадр полностью и отправил обратно подтверждение. И только через 520 мс после начала передачи кадра подтверждение получено отправителем. В данном случае еще предполагается, что приемник не тратит времени на обработку принятого кадра, при этом подтверждение такое короткое, что временем его передачи и приема можно пренебречь. Тем не менее из 520 мс передатчик работал только 20 мс, а 500 мс ожидал подтверждения. Таким образом, использовалось лишь 4 % от пропускной способности канала. Очевидно, что сочетание большого времени прохождения сигнала, высокой пропускной способности и коротких кадров совершенно неприемлемо с точки зрения эффективности. Описанная выше проблема является следствием правила, требовавшего отправителю дожидаться подтверждения, прежде чем посылать следующий кадр. Смягчив это требование, можно значительно повысить эффективность. Решение проблемы заключается в разрешении отправителю послать не один кадр, а несколько, например w, прежде чем остановиться и перейти в режим ожидания подтверждений. Можно подобрать число w так, чтобы отправитель мог безостановочно посылать кадры. В приведенном выше примере w должно быть равно, по меньшей мере, 26. Отправитель начинает, как и ранее, с передачи кадра 0. К тому моменту, когда он закончит отправку 26 кадров в момент времени t = 520 мс, как раз прибудет подтверждение кадра 0. Затем подтверждения станут прибывать каждые 20 мс, таким образом, отправитель будет получать разрешения на передачу следующего кадра как раз вовремя. В любой момент времени у отправителя будет не более 26 неподтвержденных кадров, и, следовательно, достаточно будет окна размером 26. Такая техника называется конвейерной обработкой. Если пропускная способность канала равна b бит/с, размер кадра равен l бит, то время передачи одного кадра составит l/b с. Пусть время прохождения сигнала по каналу в оба конца равно R секунд. В протоколе с ожиданием линия занята в течение l/b с и свободна в течение R с, что дает коэффициент эффективности использования линии равный l/(l + bR). При l < bR эффективность использования линии будет менее 50 %. Конвейерный режим может использоваться для загрузки избежания простаивания линии, если время прохождения сигнала значительно по сравнению со временем самой передачи. Если же задержка распространения сигнала мала, дополнительное усложнение протокола не является оправданным. При конвейерном режиме передачи кадров по ненадежному каналу возникает ряд серьезных проблем. Во-первых, что произойдет, если повредится или потеряется кадр в середине длинного потока? Большое количество последующих кадров прибудет к получателю прежде, чем отправитель обнаружит, что произошла ошибка. Когда поврежденный кадр приходит получателю, он, конечно, должен быть отвергнут, однако что должен делать получатель со всеми правильными последующими кадрами? Как уже упоминалось, получающий уровень передачи данных обязан передавать пакеты сетевому уровню, соблюдая строгий порядок.
Модели конечных автоматов Ключевой концепцией, используемой в моделях протоколов, является модель конечных автоматов. Данный метод рассматривает состояния, в которых находится протокольная машина (то есть отправитель или получатель) в каждый момент времени. Состояние протокольной машины включает в себя значения всех ее переменных, в том числе и программные счетчики. В большинстве случаев многие состояния можно объединить для анализа в группы. Например, рассматривая получателя в протоколе 3, мы можем выделить из всех его возможных состояний два самых важных: ожидание кадра 0 и ожидание кадра 1. Все остальные состояния могут рассматриваться как временные, промежуточные между этими двумя. Обычно выбираются состояния, соответствующие ожидаемым событиям (это соответствует вызову процедуры wait (event) в наших примерах протоколов). Состояние протокольной машины полностью определяется состоянием ее переменных. Количество состояний равно 2n, где n — количество битов, необходимых для описания всех переменных, вместе взятых. Состояние всей системы представляет собой комбинацию всех состояний двух протокольных машин и состояний канала. Состояние канала определяется его содержимым. При использовании протокола 3 у канала может быть четыре возможных состояния: кадр 0 или кадр 1, перемещающийся от отправителя к получателю, кадр подтверждения, двигающийся в противоположном направлении, или пустой канал. Если отправитель и получатель могут находиться в двух различных состояниях, то вся система будет иметь 16 различных состояний. Следует сказать несколько слов о состоянии канала. Концепция кадра, находящегося в канале, конечно, является абстракцией. Имеется в виду, что кадр частично передан, частично принят, но еще не обработан получателем. Кадр остается «в канале» до тех пор, пока протокольная машина не выполнит процедуру from_physical_layer и не обработает его. Каждое состояние может быть соединено с другими состояниями несколькими (0 или больше) переходами. Переходы всегда соответствуют каким-либо событиям. Для протокольной машины переход происходит, когда прибывает новый кадр, истекает время ожидания какого-либо таймера, происходит прерывание и т. д. Для канала обычными событиями являются следующие: помещение протокольной машиной в канал нового кадра, доставка кадра протокольной машине или потеря кадра вследствие всплеска шума. Имея полное описание протокольной машины и характеристик канала, можно нарисовать направленный граф, изображающий все состояния в виде узлов, а переходы — в виде направленных дуг. Одно особое состояние обозначается как начальное. Оно соответствует состоянию системы в момент ее запуска или состоянию, близкому к нему. Из начального состояния можно попасть во многие (вероятно, даже во все) другие состояния с помощью серии переходов. Применяя хорошо известные методы теории графов (например, вычисляя транзитивное замыкание графа), можно определить, какие из состояний достижимы, а какие нет. Такой метод называется анализом достижимости (Lin и др., 1987). Данный анализ может быть полезен для определения правильности протокола. Формально модель протокола машины конечных состояний можно рассматривать как набор их четырех множеств (S, М, I, Т), где S — множество состояний, в которых могут находиться процессы и канал; M — множество кадров, передающихся по каналу; I — множество начальных состояний процессов; Т — множество переходов между состояниями. В начальный момент времени все процессы находятся в исходном состоянии. Затем начинают происходить события — например, появляются кадры, которые нужно передать по каналу, или срабатывает таймер. Каждое событие может переключить один из процессов или канал в новое состояние. Тщательно нумеруя все возможные предшественники каждого состояния, можно построить дерево достижимости и проанализировать протокол. Полносвязная. Каждая пара узлов соединена между собой отдельным каналом. Наиболее дорогая кабельная система. При этом достигается максимальная производительность, надежность, скорость передачи. Используется, например, при соединении ATC телефонной сети, для построения сети передачи общего пользования.
Сети Петри. Сети Петри – инструмент исследования систем. В настоящее время сети Петри применяются в основном в моделировании. Во многих областях исследований явление изучается не непосредственно, а косвенно, через модель. Модель – это представление, как правило, в математических терминах того, что считается наиболее характерным в изучаемом объекте или системе. Манипулируя моделью системы, можно получить новые знания о ней, избегая опасности, дороговизну или неудобства анализа самой реальной системы. Обычно модели имеют математическую основу. Развитие теории сетей Петри проводилось по двум направлениям. Формальная теория сетей Петри занимается разработкой основных средств, методов и понятий, необходимых для применения сетей Петри. Прикладная теория сетей Петри связана главным образом с применением сетей Петри к моделированию систем, их анализу и получающимся в результате этого глубоким проникновением в моделируемые системы. Моделирование в сетях Петри осуществляется на событийном уровне. Определяются, какие действия происходят в системе, какие состояние предшествовали этим действиям и какие состояния примет система после выполнения действия. Выполнения событийной модели в сетях Петри описывает поведение системы. Анализ результатов выполнения может сказать о том, в каких состояниях пребывала или не пребывала система, какие состояния в принципе не достижимы. Однако, такой анализ не дает числовых характеристик, определяющих состояние системы. Развитие теории сетей Петри привело к появлению, так называемых, “цветных” сетей Петри. Понятие цветности в них тесно связано с понятиями переменных, типов данных, условий и других конструкций, более приближенных к языкам программирования. Несмотря на некоторые сходства между цветными сетями Петри и программами, они еще не применялись в качестве языка программирования. Не смотря на описанные выше достоинства сетей Петри, неудобства применения сетей Петри в качестве языка программирования заключены в процессе их выполнения в вычислительной системе. В сетях Петри нет строго понятия процесса, который можно было бы выполнять на указанном процессоре. Нет также однозначной последовательности исполнения сети Петри, так как исходная теория представляет нам язык для описания параллельных процессов. Наилучшими возможностями описания параллельных систем обладают сети Петри. Они не менее мощные, чем PVM, MPI, SDL и другие, но чтобы их выполнять на процессорах необходимо сделать из описания параллельного распределенное. Сеть первого рода - это цветная сеть Петри, описанная на языке предписаний.
Сеть второго рода - это сеть, представленная в виде иерархической композиции объектов.
к началу документа Теория сетей Петри. Теория сетей Петри является хорошо известным и популярным формализмом, предназначенным для работы с параллельными и асинхронными системами. Основанная в начале 60-х годов немецким математиком К.А.Петри, в настоящее время она содержит большое количество моделей, методов и средств анализа, имеющих обширное количество приложений практически во всех отраслях вычислительной техники и даже вне ее. Данный раздел содержит систему понятий, определений и обозначений, которые непосредственно потребуются в последствии. к началу документа Простые сети Петри. Сеть Петри из трех элементов: множество мест Определение: Простая сеть Петри Простой сетью Петри называется набор 1. 2. 3. (а) (б) Условия в пункте 3 говорят, что для каждого перехода Определение: Входное и выходное мультимножества мест и переходов Пусть задана сеть 1. Если для некоторого перехода 2. Будем говорить, что Расширим функции
Сети Петри имеют удобную графическую форму представления в виде графа, в котором места изображаются кружками, а переходы прямоугольниками. Места и переходы, причем место
Пример. Пример сети В качестве простого примера расссмотрим сеть 1. 2. 3. В графической форме сеть представлена на Рис.1. Сеть имеет четыре места и три перехода. Отношение
Рис. 1: Пример графа сети Петри Само по себе понятие сети имеет статическую природу. Для задания динамических характеристик используется понятие маркировки сети Определение: Маркированная сеть Петри Маркированной сетью Петри называется набор 1. 2. Пример. Пример маркированной сети. На Рис.2 приведен пример маркированной сети. В начальной маркировке место
Рис. 2: Пример маркированной сети Петри Сети Петри были разработаны и используются для моделирования параллельных и асинхронных систем. При моделировании в сетях Петри места символизируют какое-либо состояние системы, а переход символизируют какие-то действия, происходящие в системе. Система, находясь в каком-то состоянии, может порождать определенные действия, и наоборот, выполнение какого-то действия переводит систему из одного состояния в другое. Текущее состояние системы определяет маркировка сети Петри, т.е. расположение меток (токенов) в местах сети. Выполнение действия в системе, в сетях Петри определяется как срабатывание переходов. Срабатывание переходов порождает новую маркировку, т.е. порождает новое размещение меток (токенов) в сети. Определим функционирование маркированных сетей, основанное на срабатывании отдельных переходов. Определение: Правило срабатывания переходов Пусть 1. Переход 2. Переход Иными словами, переход считается возбужденным при некоторой маркировке, если в каждом его входном месте имеется количество меток не менее кратности соответствующих дуг. Возбужденный переход может сработать, причем при срабатывании из каждого его входного места изымается, а в каждое входное добавляется некоторое количество меток, равное кратности соответствующих дуг. Если одновременно возбуждено несколько переходов, сработать может любой из них или любая их комбинация. Например, пусть в сети на рисунке 2 сработают переходы
Рис. 3: Новая сеть с маркировкой
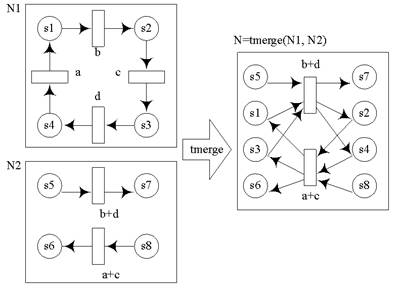
Композициональный подход к построению сетей Петри предполагает возможность построения более сложных сетей из менее сложных составляющих. Для этого вводятся точки доступа, которые позволяют объединять простые сети путём синхронизации событий и состояний (переходов и мест). Определение: Определение T-точки доступа. Пусть задана сеть 1. 2. 3. Определение: Определение S-точки доступа Пусть задана сеть 1. 2. Введённые понятия точек доступа предоставляют возможность ввести две основные операции над сетями Петри для построения композициональных сетей: 1. Операция слияния переходов - позволяет порождать и описывать синхронизацию параллельных процессов (tmerge); 2. Операция слияния мест - позволяет применять к сетям операции последовательной композиции, выбора, итерации и другие (smerge).
Рис. 4: Пример операции слияния переходов Рис. 5: Пример операции слияния мест Приведённые операции имеют следующий смысл: При слиянии мест - определяется набор состояний в сети, которые идентифицируются, как состояние сети, определённое именем s-точки доступа. Слияние различных сетей производится так, что если в одной сети достигнуто описанное состояние, то в другой сети это состояние также получается достигнутым; При слиянии переходов – определяется алфавит событий, видимых из t-точки доступа. Каждый переход в сети помечается либо невидимым событием, либо комбинацией событий из алфавита точки доступа. Слияние по переходам производится так, что если при срабатывании одной сети возникает некоторая комбинация событий, то эта же комбинация событий происходит во второй сети. к началу документа Цветные сети Петри. Расширение простых сетей в цветные заключается в добавлении информации к элементам сети, основываясь на которой, при определённых условиях, можно преобразовать цветные сети в простые ([8]). 1. Токены вместо простого обозначения содержимого места преобразуются в объект, который может содержать в себе один или более параметров, каждый из которых может принимать дискретный набор значений. В соответствии с этим токены различаются по типам параметров (переменных). Чтобы отличать токены различных типов их можно окрашивать в различные цвета (поэтому сети называют цветными)
2. К местам добавляется информация о типах токенов, которые могут находится в данном месте.
3. К дугам, исходящим из мест, добавляется информация о типах токенов, которые могут участвовать в возбуждении переходов, инцидентных этим дугам.
4. К переходам может быть добавлена информация с предикатом возбуждения перехода, в зависимости от переменных, содержащихся в токенах. ( 5. К дугам, исходящим из переходов, добавляется информация о типах токенов, исходящих из перехода и о преобразовании переменных.
6. К начальной маркировке сети добавляется информация о значении переменных, содержащихся в токенах. В графическом представлении информацию, которую можно однозначно достроить из сопутствующей информации, можно пропускать. Приведем пример цветной сети Петри (Рис. 6)
Рис. 6: Пример цветной сети Петри (очередь) На первый взгляд кажется, что представление цветной сети выглядит так, что каждая из дуг, выходящая из перехода, содержит некоторое действие. В действительности же, при преобразовании цветной сети в простую, все действия переходят в структуру сети. Это достигается разбиением мест и переходов на количество равное декартову произведению множества всех значений всех типов данных, соответствующих этим местам и переходам. При этом все переменные в сети получаются уже заданными и вместо дуг цветной сети рисуются дуги, соединяющие места и переходы, согласно своим “цветным” описаниям. В описании цветных сетей нет принципиального ограничения на используемые переменные. Тем не менее, преобразование цветной сети в простую возможно только тогда, когда все переменные имеют дискретный спектр значений. Примеры протоколов передачи данных. HDLC – высокоуровневый протокол управления каналом. Примеры протоколов передачи данных В следующих разделах мы рассмотрим некоторые широко используемые протоколы передачи данных. Первый из них, классический бит-ориентированный протокол HDLC, часто употреблялся во многих сетях. Второй, РРР, — это протокол уровня передачи данных, используемый при подключении к Интернету домашних компьютеров. Синхронная ALOHA Синхронная ALOHA разделяет время передачи на временные отрезки (слоты), и каждая станция может начать передачу только в начале слота.
Рис. 1.5. Критическое время при использовании протокола "синхронная ALOHA" Станция, пропустившая этот момент, должна ждать, пока не начнется следующий слот. Это означает, что станция, начавшая передачу в начале слота, закончит без конфликта свой кадр. Конечно, при этом все равно возможно состязание. Конфликт возникает, если две станции пытаются начать передачу в начале слота. Однако критическое время уменьшается в два раза. Это повышает пропускную способность общего ресурса передающей среды до 36,5%.
Протоколы множественного доступа с контролем несущей (CSMA/CD) Лучший результат, какой мы можем получить для системы ALOHA это 1/е. Это не удивительно, так как там станция не обращает внимание на то, что делают другие. В локальных сетях есть возможность определить, что делают другие станции и только после этого решать, что делать. Протоколы, которые реализую именно эту идею - определить есть ли передача и действовать соответствующе, называются протоколами с обнаружением несущей CSMA (Carrier Sense Multiply Access). Согласно протоколу, который мы сейчас рассмотрим, станция прежде чем что-либо передавать определяет состояние канала. Если канал занят, то она ждет. Как только канал освободился она пытается начать передачу. Если при этом произошла коллизия, она ожидает случайный интервал времени и все начинает с начала. Этот протокол называется CSMA настойчивым протоколом первого уровня или 1-настойчивым CSMA протоколом, потому что он начинает передачу с вероятностью 1 как только обнаруживает, что канал свободен. Здесь существенной является задержка распространения сигнала. Чем она больше, тем больше будет коллизий, так как две готовые к передачи станции обнаружат что они обе в режиме передачи только по истечении времени задержки. Тем не менее этот протокол более эффективен, чем любая из ALOHA, так как учитывают что происходит на канале прежде, чем начать действовать. Другой вариант CSMA - не настойчивый CSMA протокол. Основное отличие его от предыдущего в том, что готовая к передаче станция не опрашивает постоянно канал, в ожидании когда он освободиться, а делает это через случайные отрезки времени. Это несколько увеличивает задержку при передаче, но общая эффективность возрастает. И ,наконец, CSMA настойчивый протокол уровня р. Он применяется к слотированным каналам. Когда станция готова к передаче она опрашивает канал, если он свободен, то она с вероятностью р передает свой кадр и с вероятностью q=1-p ждет следующего слота. Так она действует пока не передаст кадр. Если произошла коллизия вовремя передачи, она ожидает случайный интервал времени и опрашивает канал опять. Если при опросе канала он оказался занят, станция ждет начала следующего слота и весь алгоритм повторяется. Протоколы множественного доступа с контролем несущей с определением Настойчивые и ненастойчивые CSMA протоколы несомненно есть улучшение ALOHA, т.к. они начинают передачу только проверив состояние канала. Другим улучшением, которое можно сделать, - станции должны уметь определять коллизии как можно раньше, а не по окончании отправки кадра. Это экономит время и пропускную способность канала. Такой протокол, известный как CSMA/CD(Carrier Sense Multiply Access with Collision Detection), широко используется в локальных сетях.
Протоколы без столкновений Хотя в протоколе CSMA/CD столкновения не могут происходить после того, как станция захватывает канал, они могут случаться в период конкуренции. Эти столкновения снижают производительность системы, особенно при большой длине кабеля (то есть при больших т) и коротких кадрах. Метод CSMA/CD оказывается не универсальным. В описываемых далее протоколах предполагается наличие /V станций, у каждой из которых есть постоянный уникальный адрес в пределах от 0 до /V- 1. То, что некоторые станции могут часть времени оставаться пассивными, роли не играет. Также предполагается, что задержка распространения сигнала пренебрежимо мала. Главный вопрос сохраняется: какой станции будет предоставлен канал после передачи данного кадра? Основной метод битовой карты В первом протоколе без столкновений, который мы рассмотрим, называющемся основным методом битовой карты, каждый период конкуренции состоит ровно из /V временных интервалов. Если у станции 0 есть кадр для передачи, она передает единичный бит во время 0-го интервала. Другим станциям не разрешается передача в это время. Во время интервала 1 станция 1 также сообщает, есть ли у нее кадр для передачи, передавая бит 1 или 0. В результате к окончанию интервала N все Дистанций знают, кто хочет передавать. В этот момент они начинают передачу в соответствии со своим порядком номеров (рис. 4.6). Поскольку все знают, чья очередь передавать, столкновений нет. После того как последняя станция передает свой кадр, что все станции отслеживают, прослушивая линию, начинается новый период подачи заявок из N интервалов. Если станция переходит в состояние готовности (получает кадр для передачи) сразу после того, как она отказалась от передачи, это значит, что ей не повезло и она должна ждать следующего цикла. Протоколы, в которых намерение передавать объявляется всем перед самой передачей, называются протоколами с резервированием. Двоичный обратный отсчет Недостатком базового протокола бит-карты являются накладные расходы в 1 бит на станцию. Используя двоичный адрес станции, можно улучшить эффективность канала. Станция, желающая занять канал, объявляет свой адрес в виде битовой строки, начиная со старшего бита. Предполагается, что все адреса станций имеют одинаковую длину. Биты адреса в каждой позиции логически складываются (логическое ИJI И). Мы будем называть этот протокол протоколом с двоичным обратным отсчетом. Он используется в сети Datakit (Fraser, 1987). Неявно предполагается, что задержки распространения сигнала пренебрежимо малы, поэтому станции слышат утверждаемые номера практически мгновенно. Во избежание конфликтов следует применить правило арбитража: как только станция с 0 в старшем бите адреса видит, что в суммарном адресе этот 0 заменился единицей, она сдается и вдет следующего цикла. Например, если станции 0010, 0100, 1001 и 1010 конкурируют за канал, то в первом битовом интервале они передают биты 0, 0, 1 и 1 соответственно. В этом случае суммарный первый бит адреса будет равен 1. Следовательно, станции с номерами 0010 и 0100 считаются проигравшими, а станции 1001 и 1010 продолжают борьбу. Следующий бит у обеих оставшихся станций равен 0 — таким образом, обе продолжают. Третий бит равен 1, поэтому станция 1001 сдается. Победителем оказывается станция 1010, так как ее адрес наибольший. Выиграв торги, она может начать передачу кадра, после чего начнется новый цикл торгов. Схема протокола показана на рис. 4.7. Данный метод предполагает, что приоритет станции напрямую зависит от ее номера. В некоторых случаях такое жесткое правило может играть положительную, в некоторых — отрицательную роль. Двоичный обратный отсчет является примером простого, элегантного и эффективного протокола, который еще предстоит открыть заново разработчикам будущих сетей. Хочется надеяться, что когда-нибудь он займет свою нишу в сетевых технологиях.
Вопросы проектирования сетевого уровня. Метод коммутации пакетов с ожиданием.
Система работает следующим образом. Хост, у которого есть пакет для передачи, посылает его либо на ближайший маршрутизатор своей ЛВС, либо по двухточечному соединению оператору связи. Там пакет хранится до тех пор, пока не будет принят целиком, включая верифицируемую контрольную сумму. Затем он передается по цепочке маршрутизаторов, которая в итоге приводит к пункту назначения. Такой механизм называется коммутацией пакетов с ожиданием, и мы уже рассматривали его в предыдущих главах.
Способы объединения сетей На физическом уровне сети объединяются повторителями или концентраторами, которые просто переносят бит из одной сети в другую такую же сеть, преобразовывают сигналы при сопряжении различных физических сред.. Мосты и коммутаторы работают на уровне передачи данных. Они могут принимать кадры, анализировать их МАС-адреса, направлять их в другие сети, осуществляя по ходу минимальные преобразования протоколов, например из Ethernet в FDDI или в 802.11. На сетевом уровне маршрутизаторы соединяют две сети. Если сетевые уровни у них разные, маршрутизатор может обеспечить перевод пакета из одного формата в другой. Маршрутизатор может поддерживать несколько протоколов, тогда он называется мультипротокольным маршрутизатором. На транспортном уровне существуют транспортные шлюзы, предоставляющие интерфейсы для соединений своего уровня. Транспортный шлюз позволяет, к примеру, передавать пакеты из сети ТСР в сеть SNA (протоколы транспортного уровня у них различаются), склеивая одно соединение с другим. На прикладном уровне шлюзы занимаются преобразованием семантики сообщений. Например, шлюзы между электронной почтой Интернета (RFC 822) и электронной почтой Х.400 должны анализировать содержимое сообщений и изменять различные поля электронного конверта. Сокеты Беркли Теперь рассмотрим другой набор транспортных примитивов — примитивы сокетов (иногда называемых гнездами), используемые в операционной системе Berkeley UNIX для протокола T CP (Transmission Control Protocol — протокол управления передачей). Они приведены в табл. 6.2. Модель сокетов во многом подобна рассмотренной ранее модели транспортных примитивов, но обладает большей гибкостью и предоставляет больше возможностей. Модули TPDU, соответствующие этой модели, будут рассматриваться далее в этой главе, когда мы будем изучать TCP. Первые четыре примитива списка выполняются серверами в таком же порядке. Примитив SOCKET создает новый сокет и выделяет для него место в таблице транспортной сущности. Параметры вызова указывают используемый формат адресов, тип требуемой услуги (например, надежный байтовый поток) и протокол. В случае успеха примитив SOCKET возвращает обычный описатель файла, используемого при вызове следующих примитивов, подобно тому, как возвращает описатель файла процедура OPEN
У только что созданного сокета нет сетевых адресов. Они назначаются с по- мощью примитива BIND. После того как сервер привязывает адрес к сокету, с ним могут связаться удаленные клиенты. Вызов SOCKET не создает адрес напрямую, так как некоторые процессы придают адресам большое значение (например, они использовали один и тот же адрес годами, и этот адрес всем известен), тогда как другим процессам это не важно. Следом идет вызов LISTEN, который выделяет место для очереди входящих звонков на случай, если несколько клиентов попытаются соединиться одновременно. В отличие от примитива LISTEN в нашем первом примере, примитив LISTEN гнездовой модели не является блокирующим вызовом. Чтобы заблокировать ожидание входящих соединений, сервер выполняет примитив ACCEPT. Получив TPDU-модуль с запросом соединения, транспортная сущность создает новый сокет с теми же свойствами, что и у исходного сокета, и возвращает описатель файла для него. При этом сервер может разветвить процесс или поток, чтобы обработать соединение для нового сокета и вернуться к ожиданию следующего соединения для оригинального сокета. Теперь посмотрим на этот процесс со стороны клиента. В этом случае также сначала с помощью примитива SOCKET должен быть создан сокет, но примитив BIND здесь не требуется, так как используемый адрес не имеет значения для сервера. Примитив CONNECT блокирует вызывающего и инициирует активный процесс соединения. Когда этот процесс завершается (то есть когда соответствующий TPDU-модуль, посланный сервером, получен), процесс клиента разблокируется и соединение считается установленным. После этого обе стороны могут использовать примитивы SEND и RECV для передачи и получения данных по полнодуплексному соединению. Могут также применяться стандартные UNIX-вызовы READ и WRITE, если нет нужды в использовании специальных свойств SEND и RECV. В модели сокетов используется симметричный разрыв соединения. Соединение разрывается, когда обе стороны выполняют примитив CLOSE.
Разрыв соединения.
Разорвать соединение проще, чем установить. Тем не менее, здесь также имеются подводные камни. Существует два стиля разрыва соединения: асимметричный и симметричный. Асимметричный разрыв с вязи соответствует принципу работы телефонной системы: когда одна из сторон вешает трубку, связь прерывается. При симметричном разрыве соединение рассматривается в виде двух отдельных однонаправленных связей, и требуется раздельное завершение каждого соединения. На рисунке показаны четыре сценария разъединения, использующих «тройное рукопожатие». Хотя этот протокол и не безошибочен, обычно он работает успешно. На рис а, показан нормальный случай, в котором один из пользователей посылает запрос разъединения DR (DISCONNECTION REQUEST), чтобы инициировать разрыв соединения. Когда он прибывает, получатель посылает обратно также запрос разъединения DR и включает таймер на случай, если запрос потеряется. Когда запрос прибывает, первый отправитель посылает в ответ на него TPDU-модуль с подтверждением АСК и разрывает соединение. Наконец, когда прибывает АСК, получатель также разрывает соединение. Разрыв соединения означает, что транспортная сущность удаляет информацию об этом соединении из своей таблицы открытых соединений и сигнализирует о разрыве соединения владельцу соединения (пользователю транспортной службы). Эта процедура отличается от использования пользователем примитива DISCONNECT. Если последний TPDU-модуль с подтверждением теряется (рис. б), ситуацию спасает таймер. Когда время истекает, соединение разрывается в любом случае. Теперь рассмотрим случай потери второго запроса разъединения DR. Пользователь, инициировавший разъединение, не получит ожидаемого ответа, у него истечет время ожидания, и он начнет все сначала. На рис. в показано, как это происходит в случае, если все последующие запросы и подтверждения успешно доходят до адресатов. Последний сценарий (рис. г) аналогичен предыдущему — с той лишь разницей, что в этом случае предполагается, что все повторные попытки передать запрос разъединения DR также терпят неудачу, поскольку все TPDU-модули теряются. После N повторных попыток отправитель наконец сдается и разрывает соединение. Тем временем у получателя также истекает время, и он тоже разрывает соединение.
Ключевые аспекты организации уровня передачи данных. Сервисы, предоставляемые сетевому уровню. Формирование кадра. |
Последнее изменение этой страницы: 2019-05-08; Просмотров: 619; Нарушение авторского права страницы



 , множество переходов
, множество переходов  и отношение инцидентности
и отношение инцидентности  .
.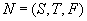 , где
, где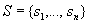 - множество мест;
- множество мест; - множество переходов таких, что
- множество переходов таких, что  .
. - отношение инцидентности такое, что
- отношение инцидентности такое, что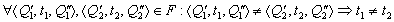 ;
;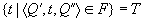
 существует единственный элемент
существует единственный элемент 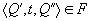 , задающий для него входное мультимножество мест
, задающий для него входное мультимножество мест  и выходное мультимножество
и выходное мультимножество 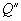 . Дадим определение входному и выходному мультимножеству.
. Дадим определение входному и выходному мультимножеству. .
. имеем
имеем  ;
; .
.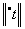 - входные, а
- входные, а  - выходные места перехода
- выходные места перехода  . Далее будем говорить, что место
. Далее будем говорить, что место  инцидентно переходу
инцидентно переходу  или
или  .
.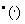 и
и  на мультимножества переходов. Пусть
на мультимножества переходов. Пусть  есть мультимножество переходов такое, что
есть мультимножество переходов такое, что  . Тогда положим
. Тогда положим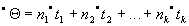
 .
. и
и  для некоторого натурального числа
для некоторого натурального числа  . Здесь число
. Здесь число  называется кратностью дуги, которое графически изображается рядом с дугой. Дуги, имеющие единичную кратность, будут обозначаться без приписывания единицы.
называется кратностью дуги, которое графически изображается рядом с дугой. Дуги, имеющие единичную кратность, будут обозначаться без приписывания единицы.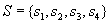 ;
; ;
;
 задает четыре дуги: из
задает четыре дуги: из  в
в 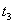 и из
и из  с кратностями 2, из
с кратностями 2, из 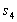 в
в  и
и  . Для места
. Для места  и
и 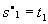 .
.
 , т.е. функции
, т.е. функции  , сопоставляющей каждому месту целое число. Графически маркировка изображается в виде точек, называемых метками (tokens), и располагающихся в кружках, соответствующих местам сети. Отсутствие меток в некотором месте говорит о нулевой маркировке этого места.
, сопоставляющей каждому месту целое число. Графически маркировка изображается в виде точек, называемых метками (tokens), и располагающихся в кружках, соответствующих местам сети. Отсутствие меток в некотором месте говорит о нулевой маркировке этого места. , где
, где - сеть;
- сеть;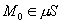 - начальная маркировка.
- начальная маркировка. - одну метку, а места
- одну метку, а места  .
.
 маркированная сеть.
маркированная сеть. считается возбужденным при маркировке
считается возбужденным при маркировке  , если
, если  ;
;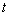 , возбужденный при маркировке
, возбужденный при маркировке  , может сработать, приведя к новой маркировке
, может сработать, приведя к новой маркировке  , которая вычисляется по правилу:
, которая вычисляется по правилу:  . Срабатывание перехода обозначается как
. Срабатывание перехода обозначается как 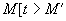 .
. и
и 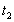 . Получим сеть представленную на рисунке 3.
. Получим сеть представленную на рисунке 3.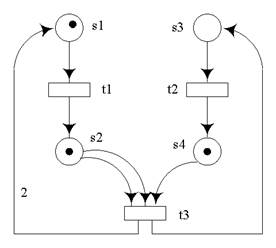
 . Т-точкой доступа называется набор
. Т-точкой доступа называется набор  , где
, где - имя (идентификатор) t-точки доступа;
- имя (идентификатор) t-точки доступа; - пометочная функция, где
- пометочная функция, где  . Запись
. Запись  обозначает множество всех конечных и непустых мультимножеств, определённых на множестве
обозначает множество всех конечных и непустых мультимножеств, определённых на множестве 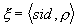 , где
, где - имя (идентификатор) s-точки доступа;
- имя (идентификатор) s-точки доступа; - множество такое, что
- множество такое, что 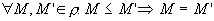 .
.



 and
and  )
)



