
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Выражение функции распредел нормальной величины через функцию Лапласа. Вероятность попадания знач нормальной св в заданный интервал, правило 3 сигм. ⇐ ПредыдущаяСтр 5 из 5
Вычислим по формуле: Если Если Если Правило «3 сигм»: если св распределена нормально, то абсолютная величина ее отклонения от мат ожидания не превосходит утроенного среднего квадратичного отклонения. В этом и состоит сущность правила «трех сигм» или если св Х имеет нормальный закон распределения с параметрами
27.Неравенство Маркова. Теорема. Если св Х принимает только неотрицательные значения и имеет мат ожидание, то для любого положительного числа
28. Неравенство Чебышева. Теорема. Для любой св, имеющей мат ожидание и дисперсию, справедливо неравенство Ч. Пусть имеется некоторая св Х с M(X) и D(X). Каково не было бы положительное число
29. Закон больших чисел « в форме» теоремы Чебышева. Свойство устойчивости массовых случайных явлений известно человечеству с древности: конкретные особенности каждого конкретного случайного яв почти не сказываются на среднем результате массы таких явлений; случайное отклонение от среднего неизбежные в каждом отдельном явлении в массе взаимно погашаются, выравниваются – это устойчивость средних и представляет собой физическое содержание закона больших чисел. Под законом больших чисел в широком смысле понимается общий принцип, согласно которому, по формулировке А. Н. Колмогорова, совокупное действие большого числа случайных факторов приводит (при некоторых весьма общих условиях) к результату, почти не зависящему от случая. Другими словами, при большом числе св их средний результат перестает быть случайным и может быть предсказан с большой степенью определенности. Под законом больших чисел в узком смысле понимается ряд математических теорем, в каждой из которых для тех или иных условий устанавливается факт приближения средних характеристик большого числа испытаний к некоторым определенным постоянным.
30.Теорема Бернулли. Теорема Бернулли устанавливает связь между относительной частотой появления события и его вероятностью. При достаточно большом числе независимых испыт с вероятностью, близкой к единице, можно утверждать, что разность между относительной частой появления события в этих испытаниях его вероятностью в отдельном испытании по абсолютной величине окажется меньше сколь угодно малого числа, если вероятность наступления этого события в каждом испытании постоянна и равна. где q-вероят-ть неудачи q=1-p
31.Понятие о «центральная предельная теорема». Теорема Ляпунова. Пусть имеется последовательность св X1, X2…Xn, удовлетворяющих следующим условиям. Величины X1, X2…Xn независимы. Величины X1, X2…Xn обладают конечными абсолютными центральными моментами третьего порядка, т. е. M(|Xj-M(Xj)|3) удовлетворяет условию Тогда при n→∞ св Zn=
Для доказательства покажем, что характеристическая функция Zn при n→∞ стремится к exp(- M(Yj)=M( D(Yj)=D( 32.Понятие случайный процесс. Корреляционная функция случайного процесса. Случайным процессом X(t) называется процесс, значение которого при любом фиксированном t = t0 является случайной величиной X(t0). При изучении явлений окружающего мира мы часто сталкиваемся с процессами, течение которых заранее предсказать в точности невозможно. Эта неопределенность (непредсказуемость) вызвана влиянием случайных факторов, воздействующих на ход процесса. ФУНКЦИЯ КОРРЕЛЯЦИОННАЯ СЛУЧАЙНОГО ПРОЦЕССА X(t) есть Функция R(t,s) = E[X(t) - m(t)]·(X(s)-m(s)], где m(t) = EX(t) — математическое ожидание X(t). R(t,s) характеризует связь между отдельными точками t и s. Если имеются 2 случайных процесса Х(t) и Y(t) с Ф. к. с. п. Rx (t,s) и RY(t,s) и математическим ожиданием тX (t) и mY (t), to можно определить взаимную корреляционную функцию: rxy (t,s) = E{X(t) — тX (t)}{Y(s) — mY (s)}. По виду Ф. к. с. п. можно проверить модель случайного процесса и тип динамической системы, его генерирующей. Ф. к. с. п. используется в литологии, в частности, при изучении геол. смысла распределения пористости и выяснении специфики условий осадконакопления.
33. Стат совокуп. Ген и выбороч совокуп. Несмещенная, состоятельная и эф-ная оценка параметров. Предметом мат стат яв изучение случ событий и св по результатам наблюдений. Совокуп предметов или явлений, объединенных каким-либо общим признаком, наз стат совокуп. Результатом наблюдений над стат совокупностью яв стат данные – сведения о том, какие значения принял в итоге наблюдений интересующий нас признак (св X). Обработка стат данных методами мат стат приводит к установлению определенных закономерностей, присущих массовым явлениям. При этом точность стат выводов повышается с ростом числа наблюдений. Стат данные, как правило, представляют собой ряд знач 34.Основные числовые характер стат распределения. Выборочным средним Размахом вариации наз число R=xmax-xmin Модой вариац ряда наз вариант, имеющий наибольшую частоту. Медианой вариац ряда наз знач признака приходящееся на серед ряда.
35.Выборочный метод. Точечное оценивание. Точечные оценки параметров ген совокуп Оценка параметра — определенная числовая характеристика, получ из выборки. Точечной наз стат оценку, кот определяется одним числом. В качестве точечных оценок параметров ген совокуп испол соответствующ выборочные характер. Теоретич обоснование возможности испол этих выборочных оценок для суждений о характеристиках и свойствах ген совокуп дают закон больших чисел и центральная предельная теорема Ляпунова. Несмещенной наз точечную оценку, мат ожидание кот = оцениваемому параметру при любом объеме выборки. Смещенной наз точечную оценку, мат ожид кот не равно оцениваемому параметру. Выборочная средняя яв точечной оценкой ген средней, т. е. Несмещенной оценкой ген средней (мат ожидания) служит выборочная средняя. Ген дисперсия имеет 2 точечные оценки: — выборочная дисперсия, кот исчисляется при n30; S^2 — исправленная выборочная дисперсия, кот исчисляется при n < 30. Причем в мат стат доказывается, что При больших объемах выборки и S^2практически совпадают. Смещенной оценкой ген дисперсии служит выбороч дисперсия. Ген среднее квадратическое отклонение также имеет 2 точечные оценки: — выборочное среднее квадратич отклон и S — исправленное выборочное среднее квадратическое отклон. испол для оценивания при n 30, a S для оценивания при п < 30; пpи этом Св-ва средней арифм:1.Сумма отклон индивид знач признака от его среднего знач = 0. 2. Если каждое индивид знач призн умнож или раздел на постоян число, то и средняя увелич или умен во столько же раз. 3. Если к каждому индивид знач признака прибавить или из каждого знач вычесть постоян число, то сред вел возрастет или умен на это же число. 4. Если веса средней взвешенной умножить или разделить на постоянное число, средняя вел не изменится. 5. Сумма квадр отклон индив знач признака от средней арифмет меньше, чем от любого другого числа. 36.Интервальные оценки параметров. Доверительный интервал Интервальной оценкой наз оценку, кот определяется двумя числами — концами интервала, кот с определенной вероятностью накрывает неизвестный параметр генеральной совокупности. Интервал, содержащий оцениваемый параметр ген совокуп, наз доверительным интервалом. Для его определения вычисляется предельная ошибка выборки, позволяющая установить предельные границы, в кот с заданной вероятностью (надежностью) должен находиться параметр ген совокуп. Предельная ошибка выборки равна t-кратному числу средних ошибок выборки. Коэффициент t позволяет установить, насколько надежно высказывание о том, что заданный интервал содержит параметр ген совокуп. Если выбирается коэффициент таким, что высказывание в 95% случаев окажется правильным и только в 5% — неправильным, то говорится, что: со статистической надежностью в 95% доверительный интервал выборочной статистики содержит параметр генеральной совокупности. Статистической надежности в 95% соответствует доверительная вероятность — 0,95. В 5% случаев утверждение «параметр принадлежит доверительному интервалу» будет неверным, т. е. 5% задает уровень значимости () или 0,05 вероятность ошибки. Обычно в статистике уровень значимости выбирают таким, чтобы он не превысил 5% (α < 0,05). Доверительная вероятность и уровень значимости дополняют друг друга до 1 (или 100%) и определяют надежность статистического высказывания. С помощью доверительного интервала можно оценить не только генеральную среднюю, но и другие неизвестные параметры генеральной совокупности.
37. Несмещенные оценки для генерального среднего и генеральной дисперсии. Расчет доверительного интервала и объема выборки (при повторном и бесповторном отборах). Несмещённая оценка в математической статистике — это точечная оценка, математическое ожидание которой равно оцениваемому параметру. Определение. Пусть Здесь параметр а – неслучайная величина, а интервал le является случайным, так как 38. Статистическая проверка гипотез. Нулевая и альтернативная гипотезы. Ошибки 1-го и 2-го рода при проверки гипотез. Уровень значимости, критическая область. Критерии согласия и его мощность. C татистической наз гипотезу о виде неизвестного распределения или о параметрах известных распределений. Примеры статистических гипотез: генеральная совокупность распределена по закону Пуассона; дисперсии двух нормальных распределений равны между собой. Нулевой (основной) наз выдвинутую гипотезу Альтернативной (конкурирующей) называют гипотезу, которая противоречит нулевой. Простой называют гипотезу, содержащую только одно предположение. Сложной называют гипотезу, состоящую из конечного или бесконечного числа простых гипотез. В итоге статистической проверки гипотезы в двух случаях может быть принято неправильное решение, т.е. могут быть допущены ошибки двух родов. Ошибка первого рода состоит в том, что будет отвергнута правильная гипотеза. Ошибка второго рода состоит в том, что будет принята неправильная гипотеза. Следует отметить, что последствия ошибок могут оказаться различными. Вероятность совершения ошибки первого рода называют уровнем значимости и обозначают
39. Проверка гипотезы о равенстве средних знач для нормал распред при известной и неизвест ген дисперсиях. Имеются 2 ген совокуп Х и У с известными дисперсиями 40. Критерий Пирсона. Критерием согласия наз критерий проверки гипотезы о предполагаемом законе неизвестного распределения. Наиболее часто используемым яв критерий согласия К.Пирсона («хи квадрат»). В качестве критерия проверки нулевой гипотезы примем св: Доказано, что при n®¥ закон распределения св (А) стремится к закону распределен
41. Критерий согласия Фишера – Снедекора и его примен для проверки гипотезы о равенстве дисперсий. F - критерий Фишера испол для сравнен дисперсий двух вариац рядов. Он выч по формуле:,
42.Критерий согласия Колмогорова. основан на определении максим расхождения между накопленными частотами и частостями эмпирических и теоретич распределений: 43. Однофакторный дисперсион анализ. испол в тех случаях, когда есть в распоряжении 3 или более независимые выборки, получ из одной ген совокуп путем изменения какого-либо независимого фактора, для кот по каким-либо причинам нет количественных измерений. Расчеты начинаются с расстановки всех данных по столбцам, относящимся к каждому из факторов соответственно. Следующим действием будет нахождение сумм значений по столбцам (то есть – градациям) и возведение их в квадрат. Фактически метод состоит в сопоставлении каждой из полученных и возведенных в квадрат сумм с суммой квадратов всех значений, получво всем эксперименте. 44. Двухфакторный дисперсионный анализ. Дисперсионный анализ, предложенный Р. Фишером, яв статистическим методом, предназначенным для выявления влияния ряда отдельных факторов на результаты экспериментов. Принципиальной разницы между многофакторным и однофакторным дисперсионным анализом нет. Кроме учета влияния на зависимую переменную каждого из факторов по отдельности, следует оценивать и их совместное действие. В этом смысле процедура многофакторного дисперсионного анализа несомненно более экономична, поскольку всего за один запуск решает сразу две задачи: оценивается влияние каждого из факторов и их взаимодействие. Сравнивая компоненты дисперсии друг с другом посредством F — критерия Фишера, можно определить, какая доля общей вариативности результативного признака обусловлена действием регулируемых факторов.
45.Модели и основные понятия корреляционного и регрес анализа . Корреляц анализ — это колич метод определения тесноты и направления взаимосвязи между выборочными переменными величинами. Регрессионный анализ — это количествен метод определения вида мат функции в причинно-следственной зависим между переменными величинами. Корреляц анализ – это совокуп методов обнаружения так называемой корреляц зависимости между св. Для двух св Х и Y корреляц анализ состоит из след этапов:1) построение корреляц поля и составление корреляц таблицы; 2) вычисление выборочного коэф корреляции; 3) проверка стат гипотезы о значимости корреляц связи. Зависимость между св X и Y наз стохастической, если с изменением одной их них (например Х) меняется закон распределения другой (Y). В теории вероятностей стохастическую зависимость Y от Х описывают условным мат ожиданием:
46.Линейная корреляц зависимость и прямые регрессии. Линейную корреляц зависимость между переменными X и Y выражают в виде линейного уравнения регрессии: Необходимо заменить параметры
47.Коэф корреляции и их свойства Коэф корреляции р для ген совокуп, как правило, неизвестен, поэтому он оценив по эксперимент данным, представляющим собой выборку объема n пар значений (Xi, Yi), полученную при совместном измерении двух признаков Х и Y. Коэф корреляции, определяемый по выборочным данным, наз выборочным коэф корреляции. Его принято обозначать символом r. Коэф корреляции — удобный показатель связи, получивший широкое применение в практике. К их основным свойствам необходимо отнести следующие: 1.Коэф корреляции способны характеризовать только линейные связи, кот выраж уравнением линейной функции. При наличии нелинейной зависимости между варьирующими признаками следует испол другие показат связи. 2.Значения коэф корреляции – это отвлеченные числа, лежащее в пределах от -1 до +1, т.е. -1 < r < 1. 3.При независимом варьировании признаков, когда связь между ними отсутствует, r= 0. 4.При положительной, или прямой, связи, когда с увеличением знач одного признака возрастают знач другого, коэф корреляции приобретает полож (+) знак и находится в пределах от 0 до +1, т.е. 0 < r < 1. 5.При отрицательной, или обратной, связи, когда с увеличением знач одного признака соответственно уменьшаются знач другого, коэф корреляции сопровождается отрицательным (–) знаком и находится в пределах от 0 до –1, т.е. -1 < r <0. 6.Чем сильнее связь между признаками, тем ближе величина коэф корреляции к |1|. Если r =+-1, то корреляционная связь переходит в функциональную, т.е. каждому знач признака Х будет соответствовать одно или несколько строго определенных знач признака Y. 7.Только по величине коэф корреляции нельзя судить о достоверности корреляц связи между признаками. Этот параметр зависит от числа степеней свободы k = n –2, где: n – число коррелируемых пар показат Х и Y. Чем больше n, тем выше достоверность связи при одном и том же значи коэфф корреляции. В практич деят, когда число коррелируемых пар признаков Х и Y невелико, то при оценке зависимости между показателями испол след градацию: 1) высок степень взаимосвязи – знач коэфф корреляции находится в пределах от 0,7 до 0,99; 2) средн степень взаимосвязи – знач коэф корреляции находится в пределах от 0,5 до 0,69; 3) слаб степень взаимосвязи – значения коэф корреляции находится от 0,2 до 0,49. 48. Понятие «нелинейная корреляция». Корреляция - систематическая и обусловленная связь между двумя рядами данных, односторонняя статистическая зависимость между СВ. Нелинейная корреляция - корреляция, при которой отношение степени изменения одной переменной к степени изменения другой переменной является изменяющейся величиной. Описывается нелинейной функцией. Нелинейная корреляция - корреляция, при кот отношение степени изменения одной переменной к степени изменения другой переменной является изменяющейся величиной. 49.Анализ соответствия регрес модели наблюденным данным. Регрессионный анализ - это метод установления аналитического выражения стохастической зависимости между исследуемыми признаками. Уравнение регрессии показывает, как в среднем изменяется Y при изменении любого из Xi, и имеет вид: Если независимая переменная одна - это простой регрессионный анализ. Если же их несколько, то такой анализ называется многофакторным. В ходе регрессионного анализа решаются 2 основные задачи: 1)построение уравнения регрессии, т.е. нахождение вида зависимости между результатным показателем и независимыми факторами x1, x2, ..., xn. 2) оценка значимости полученного уравнения, т.е. определение того, насколько выбранные факторные признаки объясняют вариацию признака Y. Применяется регрессионный анализ главным образом для планирования, а также для разработки нормативной базы. В отличие от корреляционного анализа, кот только отвечает на вопрос, существует ли связь между анализируемыми признаками, регрессионный анализ дает и ее формализованное выражение. Кроме того, если корреляционный анализ изучает любую взаимосвязь факторов, то регрессионный - одностороннюю зависимость, т.е. связь, показывающую, каким образом изменение факторных признаков влияет на признак результативный. Регрессионный анализ - один из наиболее разработанных методов математической статистики. Строго говоря, для реализации регрессионного анализа необходимо выполнение ряда специальных требований (в частности, xl,x2,...,xn; y должны быть независимыми, нормально распределенными случайными величинами с постоянными дисперсиями). В реальной жизни строгое соответствие требованиям регрессионного и корреляционного анализа встречается очень редко, однако оба эти метода весьма распространены в экономических исследованиях. Зависимости в экономике могут быть не только прямыми, но и обратными и нелинейными. Регрессионная модель может быть построена при наличии любой зависимости, однако в многофакторном анализе используют только линейные модели вида: Построение уравнения регрессии осуществляется, как правило, методом наименьших квадратов, суть которого состоит в минимизации суммы квадратов отклонений фактических значений результатного признака от его расчетных значений, т.е.: где т - число наблюдений; j = a + b1x1j + b2x2j+ ... + bnхnj - расчетное значение результатного фактора. Коэффициенты регрессии рекомендуется определять с помощью аналитических пакетов для персонального компьютера или специального финансового калькулятора. В наиболее простом случае коэффициенты регрессии однофакторного линейного уравнения регрессии вида y = а + bх можно найти по формулам.
|
Последнее изменение этой страницы: 2019-05-08; Просмотров: 225; Нарушение авторского права страницы
 при различных значениях
при различных значениях  .
. , то
, то 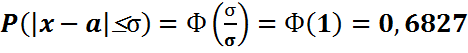
 , то
, то 
 , то
, то 

 , то практически достоверно, что ее значения заключены в интервале (
, то практически достоверно, что ее значения заключены в интервале (  ).
).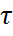 , верно неравенство, т.е. вероятность того, что св Х примет какое-нибудь значение превосходящее положительное значение
, верно неравенство, т.е. вероятность того, что св Х примет какое-нибудь значение превосходящее положительное значение  :
: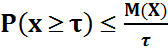 ИЛИ
ИЛИ 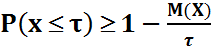
 , вероятность того, что величина Х отклонится от своего мат ожидания не меньше чем на
, вероятность того, что величина Х отклонится от своего мат ожидания не меньше чем на 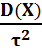 :
:  ИЛИ
ИЛИ 
 Формула Бернули. Испыт Х1,Х2,…,Хn наз независимым, если исход каждого испыт не зависит от исходов всех предыдущих испыт. П-р: бросание монеты, игральной кости, выборочный контроль кач-ва прод-ции. В схеме Бернулли рассматр-ся серия состоящая из n независимых испытаний Х1,Х2,…,Хn, причем каждое из этих испытаний имеет лишь 2 исхода: а)событие А наступило-успех, б)событие А не наступило-неудача. Причем вер-ть успеха при одном испытании Р(А)=р(0≤р≤1) постоянна и не зависит от номера испытания. Числа n и p наз-ся параметрами схемы Бернулли. В рамках схемы Бернулли у заданного числа m(0≤m≤n) опр-ть вер-тьPn(m) того, что событие А в данной серии из n числа испытаний наступит точно m раз и имеет место формула Бернулли Pn(m)=C*pmqn-m
Формула Бернули. Испыт Х1,Х2,…,Хn наз независимым, если исход каждого испыт не зависит от исходов всех предыдущих испыт. П-р: бросание монеты, игральной кости, выборочный контроль кач-ва прод-ции. В схеме Бернулли рассматр-ся серия состоящая из n независимых испытаний Х1,Х2,…,Хn, причем каждое из этих испытаний имеет лишь 2 исхода: а)событие А наступило-успех, б)событие А не наступило-неудача. Причем вер-ть успеха при одном испытании Р(А)=р(0≤р≤1) постоянна и не зависит от номера испытания. Числа n и p наз-ся параметрами схемы Бернулли. В рамках схемы Бернулли у заданного числа m(0≤m≤n) опр-ть вер-тьPn(m) того, что событие А в данной серии из n числа испытаний наступит точно m раз и имеет место формула Бернулли Pn(m)=C*pmqn-m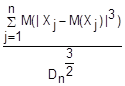 →0 при n→∞. Dn=D(
→0 при n→∞. Dn=D(  j) Тогда при n→∞ св Zn=
j) Тогда при n→∞ св Zn= 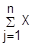 j имеет нормальный закон распределения. Теорема Ляпунова для одинаково распределенных св. Пусть имеется последовательность св X1, X2…Xn, обладающих след свойствами: Величины X1, X2…Xn независимы. Величины X1, X2…Xn одинаково распределены. Величины X1, X2…Xn имеют конечное и одинаковое мат ожидание M(Xj)=
j имеет нормальный закон распределения. Теорема Ляпунова для одинаково распределенных св. Пусть имеется последовательность св X1, X2…Xn, обладающих след свойствами: Величины X1, X2…Xn независимы. Величины X1, X2…Xn одинаково распределены. Величины X1, X2…Xn имеют конечное и одинаковое мат ожидание M(Xj)= 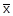 Величины X1, X2…Xn имеют конечную и одинаковую дисперсию D(Xj)=σ2
Величины X1, X2…Xn имеют конечную и одинаковую дисперсию D(Xj)=σ2 имеет нормальный закон распределения, причем M(Zn)=0 и D(Zn)=1. Доказательство.
имеет нормальный закон распределения, причем M(Zn)=0 и D(Zn)=1. Доказательство. (u)=exp(-
(u)=exp(- 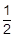 u2)
u2) u2). Введем св Yj=
u2). Введем св Yj= 
 )=
)=  M(Xj-
M(Xj- 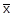 )=
)= 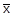 ))=
))=  (
( 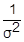 D(Xj-
D(Xj-  )=
)= 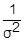 (D(Xj)-D(
(D(Xj)-D(  ))=
))= 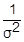 (σ2-0)=1 – т. е. Yj нормированы.
(σ2-0)=1 – т. е. Yj нормированы.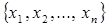 некоторой св. Обработка этого ряда значений представляет собой первый этап исследован св. Первая задача мат стат – указать способы сбора и группировки стат данных, полученных в результ наблюдений или в рез специально поставленных экспериментов. Второй задачей мат стат яв разработка методов анализа стат данных в зависимости от целей исследован. К этой задаче относятся: оценка неизвестной вероят событ; оценка неизвестной функции распределения; оценка параметров распределения, вид кот известен; оценка зависимости св от одной или нескольких св и т.п.; проверка стат гипотез о виде неизвестного распределения или о величине параметров распределения, вид кот известен. В современной мат стат есть много общего с наукой о принятии решен в условиях неопределенности, так как она разрабатывает способы определения числа необходимых испытан до начала исследован (планиров эксперимента), в процессе исследован (последовательный анализ) и решает многие другие аналогичные задачи. Типичными задачами мат стат яв: 1) определение закона распределения св по стат данным; 2) проверка правдоподобия гипотез; 3) нахождение неизвестных параметров распределения. При решен задач вероятность случ событ полагать примерно равной относительной частоте, а мат ожидание св приблизительно равно выборочному среднему. Ген совокуп наз совокуп объектов, из кот производится выборка. Совокуп всех возможных наблюдений, проводимых в одинаковых условиях над некоторой св наз ген совокуп. Ген совокуп может содержать конечное или бесконечное число элементов. Выборочной совокуп или случ выборкой наз совокуп случ отобранных объектов. Число N -элементов – объем ген совокуп, n -элементов – объем выборочной совокуп. При составлении выборки можно поступать двумя способами: после того как объект отобран и исследован, его можно возвратить или не возвращать в ген совокуп. В связи с этим выборки подразделяются на повторные (отобранный объект перед отбором след возвращается в ген совокуп) и бесповторные (отобранный объект в ген совокуп не возвращается). Для того чтобы по данным выборки можно было достаточно уверенно судить об интересующем признаке ген совокуп, необходимо, чтобы объекты выборки правильно его представляли. Выборка должна правильно представлять пропорции ген совокуп, т.е. выборка должна быть репрезентатив (представительной). В силу закона больших чисел можно утверждать, что выборка будет репрезентатив, если ее осуществить случ: каждый объект выборки отобран случ из ген совокуп, если все объекты имеют одинаковую вероятность попасть в выборку. Если объем выборки достаточно велик, а выборка составляет лишь незначительную часть совокуп, то различие между повтор и бесповтор выборкой стирается. На практике применяются различные способы отбора, кот можно подразделить на 2 вида: 1) Отбор, не требующий расчленения ген совокуп на части. Сюда относятся а) простой случ бесповтор отбор и б) простой случ повтор отбор; 2) Отбор, при кот ген совокуп разбивается на части. Сюда относятся а) типический отбор, б) механический отбор и в) серийный отбор. Простым случ наз отбор, при кот объекты извлек по одному из ген совокуп. Типическим наз отбор, при кот объекты отбираются не из всей ген совокуп, а из каждой ее “типической” части. Механическим наз отбор, при кот ген совокуп механически делится на столько групп, сколько объектов должно войти в выборку, а из каждой группы выбирается один объект. Серийным наз отбор, при кот объекты отбирают из ген совокуп не по одному, а “сериями”, кот подвергаются сплошному обследованию. На практике часто применяют комбинированный отбор, при кот сочетаются указанные выше способы. Определение. Оценка
некоторой св. Обработка этого ряда значений представляет собой первый этап исследован св. Первая задача мат стат – указать способы сбора и группировки стат данных, полученных в результ наблюдений или в рез специально поставленных экспериментов. Второй задачей мат стат яв разработка методов анализа стат данных в зависимости от целей исследован. К этой задаче относятся: оценка неизвестной вероят событ; оценка неизвестной функции распределения; оценка параметров распределения, вид кот известен; оценка зависимости св от одной или нескольких св и т.п.; проверка стат гипотез о виде неизвестного распределения или о величине параметров распределения, вид кот известен. В современной мат стат есть много общего с наукой о принятии решен в условиях неопределенности, так как она разрабатывает способы определения числа необходимых испытан до начала исследован (планиров эксперимента), в процессе исследован (последовательный анализ) и решает многие другие аналогичные задачи. Типичными задачами мат стат яв: 1) определение закона распределения св по стат данным; 2) проверка правдоподобия гипотез; 3) нахождение неизвестных параметров распределения. При решен задач вероятность случ событ полагать примерно равной относительной частоте, а мат ожидание св приблизительно равно выборочному среднему. Ген совокуп наз совокуп объектов, из кот производится выборка. Совокуп всех возможных наблюдений, проводимых в одинаковых условиях над некоторой св наз ген совокуп. Ген совокуп может содержать конечное или бесконечное число элементов. Выборочной совокуп или случ выборкой наз совокуп случ отобранных объектов. Число N -элементов – объем ген совокуп, n -элементов – объем выборочной совокуп. При составлении выборки можно поступать двумя способами: после того как объект отобран и исследован, его можно возвратить или не возвращать в ген совокуп. В связи с этим выборки подразделяются на повторные (отобранный объект перед отбором след возвращается в ген совокуп) и бесповторные (отобранный объект в ген совокуп не возвращается). Для того чтобы по данным выборки можно было достаточно уверенно судить об интересующем признаке ген совокуп, необходимо, чтобы объекты выборки правильно его представляли. Выборка должна правильно представлять пропорции ген совокуп, т.е. выборка должна быть репрезентатив (представительной). В силу закона больших чисел можно утверждать, что выборка будет репрезентатив, если ее осуществить случ: каждый объект выборки отобран случ из ген совокуп, если все объекты имеют одинаковую вероятность попасть в выборку. Если объем выборки достаточно велик, а выборка составляет лишь незначительную часть совокуп, то различие между повтор и бесповтор выборкой стирается. На практике применяются различные способы отбора, кот можно подразделить на 2 вида: 1) Отбор, не требующий расчленения ген совокуп на части. Сюда относятся а) простой случ бесповтор отбор и б) простой случ повтор отбор; 2) Отбор, при кот ген совокуп разбивается на части. Сюда относятся а) типический отбор, б) механический отбор и в) серийный отбор. Простым случ наз отбор, при кот объекты извлек по одному из ген совокуп. Типическим наз отбор, при кот объекты отбираются не из всей ген совокуп, а из каждой ее “типической” части. Механическим наз отбор, при кот ген совокуп механически делится на столько групп, сколько объектов должно войти в выборку, а из каждой группы выбирается один объект. Серийным наз отбор, при кот объекты отбирают из ген совокуп не по одному, а “сериями”, кот подвергаются сплошному обследованию. На практике часто применяют комбинированный отбор, при кот сочетаются указанные выше способы. Определение. Оценка 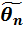 параметра
параметра  называется несмещенной, если ее мат ожидание = оцениваемому параметру, т.е.
называется несмещенной, если ее мат ожидание = оцениваемому параметру, т.е. 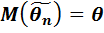 . В противном случае оценка наз смещенной. Требование несмещенности гарантирует отсутствие систематических ошибок при оценивании. Определение. Оценка
. В противном случае оценка наз смещенной. Требование несмещенности гарантирует отсутствие систематических ошибок при оценивании. Определение. Оценка 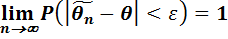 . Состоятельной наз статистическая оценка, кот при n®¥ стремится по вероятности к оцениваемому параметру. Практический смысл имеют только состоятельные оценки. Определение. Несмещенная оценка
. Состоятельной наз статистическая оценка, кот при n®¥ стремится по вероятности к оцениваемому параметру. Практический смысл имеют только состоятельные оценки. Определение. Несмещенная оценка  наз эффективной, если она имеет наимен дисперсию среди всех возможных несмещенных оценок параметра
наз эффективной, если она имеет наимен дисперсию среди всех возможных несмещенных оценок параметра  наз среднее арифметическое всех значений выборки:
наз среднее арифметическое всех значений выборки:  i ni Выборочной дисперсией D наз среднее арифметическое квадратов отклонений значений выборки от выборочной средней
i ni Выборочной дисперсией D наз среднее арифметическое квадратов отклонений значений выборки от выборочной средней  )2ni
)2ni 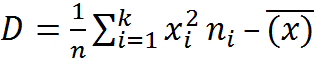 2 Выборочное среднее квадратическое отклонение выборки определяется формулой:
2 Выборочное среднее квадратическое отклонение выборки определяется формулой: 
 — выборка из распределения, зависящего от параметра
— выборка из распределения, зависящего от параметра  . Тогда оценка
. Тогда оценка  называется несмещённой, если
называется несмещённой, если 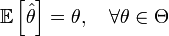 . В противном случае оценка называется смещённой, и случайная величина
. В противном случае оценка называется смещённой, и случайная величина  называется её смеще́нием. Примеры Выборочное среднее
называется её смеще́нием. Примеры Выборочное среднее  является несмещённой оценкой математического ожидания
является несмещённой оценкой математического ожидания 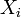 , так как если
, так как если  , то
, то  . Пусть независимые случайные величины
. Пусть независимые случайные величины 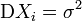 . Построим оценки
. Построим оценки  — выборочная дисперсия, и
— выборочная дисперсия, и 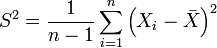 — исправленная выборочная дисперсия. Тогда
— исправленная выборочная дисперсия. Тогда 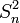 является смещённой, а
является смещённой, а 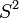 несмещённой оценками параметра
несмещённой оценками параметра 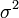 . Смещенность
. Смещенность  Представим это выражение в виде
Представим это выражение в виде  Это значит, что с вероятностью b точное значение параметра а находится в интервале le
Это значит, что с вероятностью b точное значение параметра а находится в интервале le 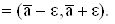
 le
le 
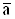 - случайная величина. Поэтому вероятность b лучше толковать, как вероятность того, что случайный интервал le накроет точку а. Интервал le называют доверительным интервалом, а вероятность b - доверительной вероятностью (надежностью).
- случайная величина. Поэтому вероятность b лучше толковать, как вероятность того, что случайный интервал le накроет точку а. Интервал le называют доверительным интервалом, а вероятность b - доверительной вероятностью (надежностью). . Чаще всего уровень значимости принимают равным 0,05 или 0,01. Если, например, принят уровень значимости 0,05, то это означает, что в пяти случаях из ста имеется риск допустить ошибку первого рода (отвергнуть правильную гипотезу).
. Чаще всего уровень значимости принимают равным 0,05 или 0,01. Если, например, принят уровень значимости 0,05, то это означает, что в пяти случаях из ста имеется риск допустить ошибку первого рода (отвергнуть правильную гипотезу).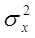 и
и  . Необходимо проверит гипотезу H0 о равенстве ген средних, т.е. H0:
. Необходимо проверит гипотезу H0 о равенстве ген средних, т.е. H0: 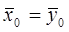 . Для проверки этой гипотезы взяты 2 независимые выборки объемами
. Для проверки этой гипотезы взяты 2 независимые выборки объемами  и
и  , по кот найдены средние арифмет
, по кот найдены средние арифмет 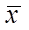 и
и  . В качестве критерия принимаем нормированную разность между
. В качестве критерия принимаем нормированную разность между  и
и 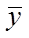 :
: 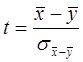 . Поскольку
. Поскольку  , то критерий при известных ген дисперсиях будет равен:
, то критерий при известных ген дисперсиях будет равен:  При выполнении гипотезы H0 критерий t при больших объемах выборок или при малых, при условии, что ген совокуп X и Y подчиняются нормал закону, так же будет подчиняться нормал закону N(0.1) с нулевым мат ожиданием и единичной дисперсией. Поэтому, например, при конкурирующей гипотезе
При выполнении гипотезы H0 критерий t при больших объемах выборок или при малых, при условии, что ген совокуп X и Y подчиняются нормал закону, так же будет подчиняться нормал закону N(0.1) с нулевым мат ожиданием и единичной дисперсией. Поэтому, например, при конкурирующей гипотезе  , выбирают двухстороннюю критическую область. Критическое знач критерия tkp выбираем из условия:
, выбирают двухстороннюю критическую область. Критическое знач критерия tkp выбираем из условия: 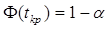 . Если фактически наблюдаемое значение критерия t по абсолютному значению больше критического tkp, определенного на уровне значимости a, т.е.
. Если фактически наблюдаемое значение критерия t по абсолютному значению больше критического tkp, определенного на уровне значимости a, т.е.  , то гипотеза H0 отвергается. Если
, то гипотеза H0 отвергается. Если  , то делаем вывод, что нулевая гипотеза H0 не противоречит имеющимся наблюдениям. При неизвестных ген дисперсиях
, то делаем вывод, что нулевая гипотеза H0 не противоречит имеющимся наблюдениям. При неизвестных ген дисперсиях  и
и  , но они равны, т.е.
, но они равны, т.е.  , то в качестве неизвестной величины
, то в качестве неизвестной величины 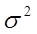 можно взять ее оценку – «исправленную» выборочную дисперсию:
можно взять ее оценку – «исправленную» выборочную дисперсию:  или
или 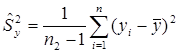 . Однако лучшей оценкой дисперсии разности независимых выборочных средних
. Однако лучшей оценкой дисперсии разности независимых выборочных средних  будет дисперсия смешанной совокупности
будет дисперсия смешанной совокупности  :
: 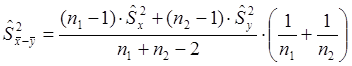 . В этом случае критерий вычисляем по выражению:
. В этом случае критерий вычисляем по выражению:  .Доказано, что в случае критерий t имеет распределение Стьюдента с
.Доказано, что в случае критерий t имеет распределение Стьюдента с 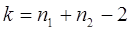 степенями свободы. Поэтому критическое знач критерия t
степенями свободы. Поэтому критическое знач критерия t  находится в зависимости от типа критической области по функции
находится в зависимости от типа критической области по функции  распределения Стьюдента, т.е.
распределения Стьюдента, т.е.  . При этом сохраняется тоже правило принятия гипотезы: гипотеза H0 отвергается на уровне значимости a, если
. При этом сохраняется тоже правило принятия гипотезы: гипотеза H0 отвергается на уровне значимости a, если  и принимается, если
и принимается, если 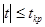 , т.е. с надежностью
, т.е. с надежностью 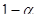 можно считать расхождение средних значений незначимым.
можно считать расхождение средних значений незначимым. .Для того, чтобы при заданном уровне значимости проверить нулевую гипотезу H0: ген совокуп распределена нормально, необходимо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия
.Для того, чтобы при заданном уровне значимости проверить нулевую гипотезу H0: ген совокуп распределена нормально, необходимо сначала вычислить теоретические частоты, а затем наблюдаемое значение критерия  и по таблице критических точек распределения
и по таблице критических точек распределения  , по заданному уровню значимости a и числу степеней свободы k=n–3 найти критическую точку
, по заданному уровню значимости a и числу степеней свободы k=n–3 найти критическую точку  . Если
. Если  – нет оснований отвергать нулевую гипотезу. В противном случае нулевую гипотезу отвергают, считая, что генеральная совокупность не распределена по нормальному закону.
– нет оснований отвергать нулевую гипотезу. В противном случае нулевую гипотезу отвергают, считая, что генеральная совокупность не распределена по нормальному закону. с
с  степенями свободы независимо от того, какому закону распределения подчинена ген совокуп. Поэтому сам критерий наз критерием согласия
степенями свободы независимо от того, какому закону распределения подчинена ген совокуп. Поэтому сам критерий наз критерием согласия  .
.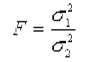 где -
где - 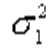 большая дисперсия,
большая дисперсия, 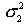 - меньшая дисперсия. Если вычисленное значение критерия F больше критического для определенного уровня значимости и соответствующих чисел степеней свободы для числителя и знаменателя, то дисперсии считаются различными. Число степеней свободы числителя определяется по формуле:,
- меньшая дисперсия. Если вычисленное значение критерия F больше критического для определенного уровня значимости и соответствующих чисел степеней свободы для числителя и знаменателя, то дисперсии считаются различными. Число степеней свободы числителя определяется по формуле:,  где
где  - число вариант для большей дисперсии. Число степеней свободы знаменателя определ по формуле:
- число вариант для большей дисперсии. Число степеней свободы знаменателя определ по формуле:  где
где 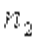 - число вариант для меньшей дисперсии.
- число вариант для меньшей дисперсии. или,
или, 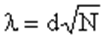 , где D и d – соответственно максимальная разность между накоплен частотами
, где D и d – соответственно максимальная разность между накоплен частотами  и накопленными частостями
и накопленными частостями  эмпирического и теоретич рядов распределений; N – число единиц совокуп. Рассчитав значение, по таблице Р(l) определяют вероятность, с кот можно утверждать, что отклонения эмпирических частот от теоретических случайны. Вероятность Р(l) может изменяться от 0 до 1. При Р(l)=1 происходит полное совпадение частот, Р(l)=0 – полное расхождение. Если l принимает знач до 0,3, то Р(l)=1. Основное условие испол критерия Колмогорова – достаточно большое число наблюд.
эмпирического и теоретич рядов распределений; N – число единиц совокуп. Рассчитав значение, по таблице Р(l) определяют вероятность, с кот можно утверждать, что отклонения эмпирических частот от теоретических случайны. Вероятность Р(l) может изменяться от 0 до 1. При Р(l)=1 происходит полное совпадение частот, Р(l)=0 – полное расхождение. Если l принимает знач до 0,3, то Р(l)=1. Основное условие испол критерия Колмогорова – достаточно большое число наблюд. кот, как видно из записи, яв функцией от независимой переменной х , имеющей смысл возможного значения св Х.
кот, как видно из записи, яв функцией от независимой переменной х , имеющей смысл возможного значения св Х. или
или  , неизвестные параметры кот находим методом наименьших квадратов. Например, для
, неизвестные параметры кот находим методом наименьших квадратов. Например, для  находим минимум
находим минимум  на основании необходимого условия экстремума функции двух переменных
на основании необходимого условия экстремума функции двух переменных 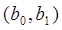 приравнивая нулю ее частные производные, т.е.
приравнивая нулю ее частные производные, т.е.  После преобразований получ систему нормал уравнений для определения параметров линейной регрессии:
После преобразований получ систему нормал уравнений для определения параметров линейной регрессии:  где соответствующие средние определ по формулам:
где соответствующие средние определ по формулам:  Подставляя знач
Подставляя знач 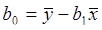 в уравнение регрессии
в уравнение регрессии  получаем:
получаем: 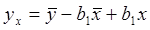 или
или  , где коэф b1 получил название коэф регрессии Y по X и обозначение byx. Этот коэф показывает на сколько единиц в среднем изменяется переменная Y при увелич переменной X на одну единицу. Решая систему нормал уравнений, найдем byx:
, где коэф b1 получил название коэф регрессии Y по X и обозначение byx. Этот коэф показывает на сколько единиц в среднем изменяется переменная Y при увелич переменной X на одну единицу. Решая систему нормал уравнений, найдем byx:  , где
, где 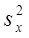 - выбороч диспер перемен
- выбороч диспер перемен 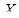 :
:  ,
,  - выбороч корреляц момент или выбороч ковариация:
- выбороч корреляц момент или выбороч ковариация:  ,
, 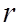 - выбороч коэф коррел:
- выбороч коэф коррел: 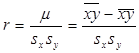 . Уравнение регрессии Y по X окончательно выглядит следующим образом:
. Уравнение регрессии Y по X окончательно выглядит следующим образом: 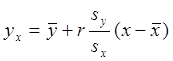 . Рассуждая аналогично находят уравнение регрессии X по Y:
. Рассуждая аналогично находят уравнение регрессии X по Y: 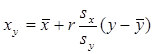 . Сравнение уравнения регрессии, полученные методом наименьших квадратов, с уравнением регрессии двумерной случайной величины с нормальным законом распределения показывает их идентичность. Поэтому для оценки линейного уравнения регрессии ген совокуп X и Y по выборке в формулах
. Сравнение уравнения регрессии, полученные методом наименьших квадратов, с уравнением регрессии двумерной случайной величины с нормальным законом распределения показывает их идентичность. Поэтому для оценки линейного уравнения регрессии ген совокуп X и Y по выборке в формулах 

 ,
, 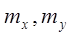 и K их состоятельными выборочными оценками – соответственно
и K их состоятельными выборочными оценками – соответственно  .
.