|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Документальные модели данных
Документальные модели данных применяются для представления слабоструктурированной информации, ориентированной в основном на свободные форматы документов, текстов на естественном языке (монографий, публикаций в периодике, текстов законодательных актов и т.п.). Модели, ориентированные на формат документа, связаны, прежде всего, с языками разметки документов. Стандартный обобщённый язык разметки документов SGML (Standard Generalized Markup Language) позволяет отделить аспекты содержания документов от аспектов его представления. Описание документов в этом языке не зависит от программно-аппаратной платформы, на которой осуществляется их обработка. На его основе разработаны программные системы управления документами, а также браузеры для просмотра размеченных документов. На основе языка SGML разработан язык гипертекстовой разметки HTML (Hyper Text Markup Language), применяемый для отображения статистических данных на Web-страницах. Этот язык определяет оформление элементов документа и имеет некий ограниченный набор инструкций – тегов, при помощи которых осуществляется процесс разметки. В качестве элемента гипертекстовой базы данных[2], описываемой HTML, используется текстовый файл, который может легко передаваться по сети с использованием протокола HTTP. Эта особенность, а также то, что HTML является открытым стандартом и огромное количество пользователей имеет возможность применять возможности этого языка для оформления своих документов, безусловно, повлияли на рост популярности HTML и сделали его сегодня главным механизмом представления информации в Интернете. Кроме HTML в настоящее время используется язык гипертекстовой разметки XML (Extensible Markup Language). Он используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. Сам по себе XML не содержит никаких тегов, предназначенных для разметки, он просто определяет порядок их создания. Тезаурусные модели основаны на принципе организации словарей и содержат определённые языковые конструкции и принципы их взаимодействия в заданной грамматике. Эти модели эффективно используются в системах-переводчиках, особенно многоязыковых переводчиках. Принцип хранения информации в этих системах подчиняется тезаурусным моделям. Дескрипторные модели – самые простые из документальных моделей, они широко использовались на ранних стадиях использования документальных баз данных. В этих моделях каждому документу соответствовал дескриптор – описатель. Этот дескриптор имел жёсткую структуру и описывал документ в соответствии с теми характеристиками, которые требуются для работы с документами в разрабатываемой документальной БД. Например, для БД, содержащей описание патентов, дескриптор содержал название области, к которой относился патент, номер патента, дату выдачи патента и ещё ряд ключевых параметров, которые заполнялись для каждого патента. Обработка информации в таких базах данных велась исключительно по дескрипторам, т.е. по тем параметрам, которые характеризовали патент, а не по самому тексту патента.
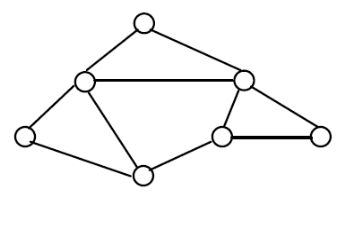
Фактографические модели Фактографические модели представлены в виде специальным образом организованных совокупностей формализованных записей данных. Основанные на таких моделях фактографические системы используются не только для реализации информационно-справочных функций (в отличие от документальных систем), но и для решения задач обработки данных. Под обработкой данных понимается специальный класс решаемых на ЭВМ задач, связанных с вводом, хранением, сортировкой, отбором и группировкой данных однородной структуры. Центральным функциональным звеном фактографических систем является СУБД. В БД функцию описания данных выполняет язык описания данных, а выполняемые над данными операции определяются языком манипулирования данными. Основные операции над данными. Операции над данными отражают динамические свойства модели данных. Как правило, можно выделить следующие основные виды операций: 1. Идентификация одного данного и нахождения его положения в БД; 2. Выборка (чтение) данного из БД; 3. Включение (запись) данного в БД; 4. Удаление данного из БД; 5. Модификация (изменение) данного в БД. Операции над данными должны соотноситься с ЯМД СУБД. Ограничения целостности. Логические ограничения, которые накладываются на данные, называются ограничениями целостности. Ограничения используются в моделях данных для поддержания целостности данных при функционировании системы, т.е. СУБД должна обеспечивать непротиворечивость данных заданными ограничениями при переводе БД из одного состояния в другое. Использование ограничений связано также с адекватностью отражения предметной области с помощью данных, хранимых в БД. Например, «год рождения» не может быть больше «года поступления в институт». Выбор модели данных. v Возможность прямого моделирования. v Сложность и трудоемкость написания определенных данных и программирования для манипулирования структурами данных. v Сложность модели для изучения пользователем. v Простота, т.е. модель должна иметь минимальное число типов базисных структур и правил композиции. v Наглядность представления структуры данных. Хранимые в БД данные описываются различными моделями представления данных. К классическим (традиционным) моделям относятся: сетевая, иерархическая, реляционная. Сетевая и иерархическая модель являются историческими предшественниками реляционной. Все ранние (дореляционные) системы не основывались на каких-либо абстрактных моделях, понятие модели данных фактически появилось в лексиконе специалистов в области БД только вместе с реляционным подходом (в 1970-е гг.). В ранних системах доступ к БД производился на уровне записей. Пользователи этих систем осуществляли явную навигацию в БД, используя языки программирования, расширенные функциями СУБД. Интерактивный доступ к БД поддерживался только путём создания соответствующих прикладных программ с собственным интерфейсом. После появления реляционных систем большинство ранних систем было оснащено «реляционными» интерфейсами. Однако в большинстве случаев это не сделало их по-настоящему реляционными системами, поскольку оставалась возможность манипулировать данными в естественном для них режиме. СУБД, основанные на сетевой и иерархической моделях, используются и в настоящее время. Иерархические модели Иерархическая модель данных была создана в 1960-х гг. как отражение потребностей практики. Иерархическая модель состоит из упорядоченного набора экземпляров типа дерево. Тип «дерево» является составным (рис.11). Он может включать в себя подтипы («поддеревья»), также являющиеся типом «дерево». Тип «дерево» состоит из вершины («корневого» типа) и упорядоченного набора из нуля или более типов «поддеревьев». Каждый из элементарных типов, включённых в тип «дерево», является простым или составным типом «запись». Простая «запись» состоит из одного типа, например, символьного, а составная «запись» объединяет некоторую совокупность различных типов, например числовые и символьные. Корневой тип имеет подчинённые типы и сам не является подтипом (подчинённым типом). Подтип является потомком по отношению к предку (родителю).
Рисунок 11 – Иерархический граф
В примере Группа является предком для Староста и Студенты, а Староста и Студенты – потомки Группа (рис. 12).
Рисунок 12 – Пример структуры типа «дерево»
Между типами записи поддерживаются связи. Тип «дерево» в целом представляет собой иерархически организованный набор типов «запись». База данных представляет совокупность таких деревьев. Потомки одного и того же типа являются близнецами. В иерархической модели предусмотрены навигационные операции по структуре базы данных и операции манипулирования данными. Например, могут быть следующие операции: − найти указанное «дерево» БД (например, Группу 21 ИТ); − перейти от одного дерева к другому; − перейти от одной записи к другой внутри дерева (например, к следующей записи типа Студенты); − перейти от одной записи к другой в порядке обхода иерархии; − вставить новую запись в указанную позицию; − удалить текущую запись. Между предками и потомками автоматически поддерживается целостность ссылок. Основное правило: никакой потомок не может существовать без своего родителя, у некоторых родителей не может быть потомков. Иерархическая модель данных активно использовалась во многих СУБД до появления реляционных систем.
Рисунок 13 – Пример хранения данных в базе данных
«Живучесть» иерархических моделей обусловлена тем, что многие структуры данных естественным образом иерархичны (например, в области биологии: виды, классы, группы и т.д.). Сетевые модели Концепция сетевой модели данных была сформулирована в конце 1960-х гг. в Предложениях группы CODASYL, и с тех пор на неё ссылаются как на модель CODASYL DTBG. Сети представляют естественный способ представления отношений между объектами. Они широко применяются в математике, физике, социологии и других областях знаний. Сетевой подход к организации данных является расширением иерархического. В иерархических структурах запись-потомок должна иметь одного предка; в сетевой структуре данных потомок может иметь любое число предков.
Рисунок 14 – Сетевой граф
Сетевая БД состоит из набора записей и набора связей между этими записями. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи С с типом записи предка P и типом записи потомка PT должны выполняться следующие два условия: 1) каждый экземпляр типа P является предком только в одном экземпляре C; 2) каждый экземпляр PT является потомком не более чем в одном экземпляре С. На формирование типов связи не накладываются особые ограничения, т.е. возможны, например, следующие ситуации: − тип записи потомка в одном типе связи может быть типом записи предка в другом типе связи (как в иерархии); − данный тип записи P может быть типом записи предка в любом числе типов связи; − данный тип записи P может быть типом записи потомка в любом числе типов связи; − может существовать любое число типов связи с одним и тем же типом записи предка и одним и тем же типом записи потомка; и если L1 и L2 – два типа связи с одним и тем же типом записи предка P и одним и тем же типом записи потомка C, то правила, по которым образуется родство, в разных связях могут различаться; − типы записи X и Y могут быть предком и потомком в одной связи и потомком и предком – в другой; − предок и потомок могут быть одного типа записи.
Рисунок 15– Пример сетевой схемы
Примерный набор операций для манипулирования данными может быть следующим: − найти конкретную запись в наборе однотипных записей; − перейти от предка к первому потомку по некоторой связи; − перейти к следующему потомку в некоторой связи; − перейти от потомка к предку по некоторой связи; − создать новую запись; − удалить запись; − изменить запись; − включить в связь; − исключить из связи; − переставить в другую связь и т.д. В принципе поддержание целостности связей не требуется, но иногда требуют целостности по ссылкам (как в иерархической модели). Системы на основе сетевой модели не получили широкого распространения на практике. Реляционные модели Реляционный подход формировался в 1970-е гг. Публикация известной статьи Э. Ф. Кодда о реляционной модели данных (в июне 1970 г.) стимулировала целый ряд математических исследований, направленных на изучение свойств реляционных баз данных, впоследствии приведших к созданию теории реляционных баз данных. В своих работах Э. Ф. Кодд описал математические основы реляционной модели. Основная идея Кодда состояла в том, чтобы применить концепцию математических отношений к моделированию данных. Отношение – это таблица из строк и столбцов. Наиболее важные характеристики реляционной модели заключаются в следующем: − Описание данных производится в соответствии с их естественной структурой, т.е. не требуется добавления дополнительных структур для машинного представления. − Обеспечивается независимость данных от их физического представления, от связей между данными и от соображений реализации. − Модель обеспечивает строгую математическую основу для интерпретации выводимости, избыточности и непротиворечивости отношений.
Рисунок 16 – Пример табличной организации данных
В это же время компания IBM начала разработку нескольких исследовательских проектов и программных продуктов-прототипов, нацеленных на создание реляционных СУБД. Благодаря успешному созданию исследовательских прототипов, реляционная теория стала активно продвигаться на практике. В 1980-х гг. было создано большое количество коммерческих реляционных продуктов – от компаний IBM, Oracle Corp., Ingres Corp. и других поставщиков. В настоящее время реляционные СУБД доминируют на рынке инструментальных средств разработки систем баз данных. Реляционные системы продолжают совершенствоваться и их внутренняя природа значительно меняется. В связи с распространением объектного подхода в 1990-е гг. появились объектно-реляционные модели. Расширяется и сфера применения реляционных систем. Примером развития реляционной модели является постреляционная модель. Классическая реляционная модель предполагает неделимость данных, постреляционная модель снимает ограничение неделимости данных, допускает многозначные поля, состоящие из множества значений. Физические модели Физическая организация данных оказывает основное влияние на эксплуатационные характеристики базы данных. Разработчики пытаются создать наиболее производительные физические модели данных, предлагая пользователям тот или иной инструментарий для поднастройки модели под конкретную СУБД. Физическая модель данных оперирует категориями, касающимися организации внешней памяти и структур хранения, используемых в данной операционной среде. В настоящий момент в качестве физических моделей используются различные методы размещения данных, основанные на файловых структурах: это организация файлов прямого и последовательного доступа, индексных файлов и инвертированных файлов, файлов, использующих различные методы хеширования, взаимосвязанных файлов. Кроме того, современные СУБД широко используют страничную организацию данных. Физические модели данных, основанные на страничной организации, являются наиболее перспективными.
|
Последнее изменение этой страницы: 2019-10-24; Просмотров: 1665; Нарушение авторского права страницы