
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Файловая система хранения данных. Объективные предпосылки применения. Недостатки. СУБД - хранение и интерпретация данных.Стр 1 из 10Следующая ⇒
Архитектура СУБД. Функции СУБД. Физическая модель данных, модель описания данных СУБД, даталогическая модель данных. Под архитектурой СУБД понимают совокупность основных характеристик компьютера и программных средств, обеспечивающих функционирование СУБД. В процессе научных исследований, посвященных тому, как именно должна быть устроена СУБД, предлагались различные способы реализации. Самым жизнеспособным из них оказалась предложенная американским комитетом по стандартизации ANSI (American National Standards Institute) трехуровневая система организации. 1. Уровень внешних моделей — Этот уровень определяет точку зрения на БД отдельных приложений. Каждое приложение видит и обрабатывает только те данные, которые необходимы именно этому приложению. Например, система распределения работ использует сведения о квалификации сотрудника, но ее не интересуют сведения об окладе, домашнем адресе и телефоне сотрудника, и наоборот, именно эти сведения используются в подсистеме отдела кадров. 2. Концептуальный уровень — центральное управляющее звено, здесь база данных представлена в наиболее общем виде, который объединяет данные, используемые всеми приложениями, работающими с данной базой данных. Фактически концептуальный уровень отражает обобщенную модель предметной области (объектов реального мира), для которой создавалась база данных. Как любая модель, концептуальная модель отражает только существенные, с точки зрения обработки, особенности объектов реального мира. 3. Физический уровень — собственно данные, расположенные в файлах или в страничных структурах, расположенных на внешних носителях информации. Внутренняя модель определяет размещение данных, методы доступа, технику индексирования. Эта архитектура позволяет обеспечить логическую (между уровнями 1 и 2) и физическую (между уровнями 2 и 3) независимость при работе с данными. Логическая независимость предполагает возможность изменения одного приложения без корректировки других приложений, работающих с этой же базой данных. Физическая независимость предполагает возможность переноса хранимой информации с одних носителей на другие при сохранении работоспособности всех приложений, работающих с данной базой данных. Это именно то, чего не хватало при использовании файловых систем. Основные функции системы управления базами данных. Непосредственное управление данными во внешней памяти Эта функция включает обеспечение необходимых структур внешней памяти как для хранения данных, непосредственно входящих в БД, так и для служебных целей, например, для ускорения доступа к данным в некоторых случаях (обычно для этого используются индексы). Управление буферами оперативной памяти СУБД обычно работают с БД значительного размера; по крайней мере, этот размер обычно существенно больше доступного объема оперативной памяти. Понятно, что если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Практически единственным способом реального увеличения этой скорости является буферизация данных в оперативной памяти. При этом, даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов. Управление транзакциями Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует изменения БД, произведенные этой транзакцией, во внешней памяти, либо ни одно из этих изменений никак не отражается на состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Приведем пример информационной системы с файлами СОТРУДНИКИ и ОТДЕЛЫ, единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника является объединение элементарных операций над файлами СОТРУДНИКИ и ОТДЕЛЫ в одну транзакцию. Таким образом, поддержание механизма транзакций является обязательным условием даже однопользовательских СУБД (если, конечно, такая система заслуживает названия СУБД). Но понятие транзакции гораздо более важно в многопользовательских СУБД. Поддержание механизма транзакций — необходимое условие даже однопользовательских СУБД. Но понятие транзакции гораздо важнее в многопользовательских СУБД. То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. Журнализация Одним из основных требований к СУБД является надежность хранения данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), и жесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть: аварийное завершение работы СУБД (по причине ошибки в программе или в результате некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции. Понятно, что в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежности хранения данных в БД требует избыточности хранения данных, причем та часть данных, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенным методом поддержания такой избыточной информации является ведение журнала изменений БД. Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая с особой тщательностью (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), иногда - минимальной внутренней операции модификации страницы внешней памяти; в некоторых системах одновременно используются оба подхода. Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, что если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя. Самая простая ситуация восстановления - индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции, путем выполнения обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу). Поддержка языков БД Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два языка
SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания, и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык запросов SQL (Structured Query Language). Данные не обладают определенной структурой, данные становятся информацией тогда, когда пользователь задает им определенную структуру, то есть осознает их смысловое содержание. Поэтому центральным понятием в области баз данных является понятие модели. Модель данных - это некоторая абстракция, которая, будучи приложенной к конкретным данным, позволяет пользователям и разработчикам трактовать их уже как информацию, то есть сведения, содержащие не только данные, но и взаимосвязь между ними. Принято выделять три группы моделей данных: инфологические, даталогические и физические. Инфологическая (семантическая) модель – это обобщённое, не привязанное к какой-либо ЭВМ и СУБД описание предметной области. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств объединяет частные представления о содержимом базы данных, полученные в результате опроса пользователей, и представления разработчиков о данных, которые могут потребоваться в будущих приложениях. Физическая модель данных (ФМД) – это модель данных, описанная с помощью средств конкретной СУБД. ФМД строится на базе даталогической путем добавления особенностей конкретной СУБД. К таким особенностям могут относиться поддерживаемые СУБД типы данных, соглашения о присвоении имен таблицам, атрибутам и т.д. Внешние модели (даталогические модели) никак не связаны с типом физической памяти, в которой будут храниться данные, и с методами доступа к этим данным. Внутренние модели (физические модели) наоборот определяют и оперируют размещением данных и их взаимосвязях на запоминающих устройствах. Физическая модель данных является полностью компьютерно-ориентированной, и конечные пользователи не имеют никакого представления о том, каким образом данные запоминаются и извлекаются или каким способом организуются индексы в таблицах для быстрого поиска или ссылочная целостность. Эти и множество других функций по методам доступа и поддержании баз данных на внешних носителях, а также способов поиска и доступа к данным в современных СУБД обеспечивается в основном ядром базы данных, что значительно облегчает задачу создания БД и их ведение. Под даталогической понимается модель, отражающая логические взаимосвязи между элементами данных безотносительно их содержания и физической организации. При этом даталогическая модель разрабатывается с учетом конкретной реализации СУБД, также с учетом специфики конкретной предметной области на основе ее инфологической модели. Даталогическая модель уже является компьютеро-ориентированной. С её помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Порядок проектирования БД. Анализ предметной области. Обобщенное неформальное описание создаваемой базы данных (инфологическая модель данных). Создание датологической модели данных посредством языка описания данных. Физическая модель данных (внутреннее описание данных в СУБД). Процесс проектирования БД представляет собой последовательность переходов от неформального словесного описания информационной структуры предметной области к формализованному описанию объектов предметной области в терминах некоторой модели. В общем случае можно выделить следующие этапы проектирования: 1. Системный анализ и словесное описание информационных объектов предметной области. 2. Проектирование инфологической модели предметной области — частично формализованное описание объектов предметной области в терминах некоторой семантической модели, например, в терминах ER-модели. 3. Даталогичеcкое или логическое проектирование БД, то есть описание БД в терминах принятой даталогической модели данных. 4. Физическое проектирование БД, то есть выбор эффективного размещения БД на внешних носителях для обеспечения наиболее эффективной работы приложения. С точки зрения проектирования БД в рамках системного анализа, необходимо осуществить первый этап, то есть провести подробное словесное описание объектов предметной области и реальных связей, которые присутствуют между описываемыми объектами. В общем случае существуют два подхода к выбору состава и структуры предметной области:
Системный анализ должен заканчиваться подробным описанием информации об объектах предметной области, которая требуется для решения конкретных задач и которая должна храниться в БД, формулировкой конкретных задач, которые будут решаться с использованием данной БД с кратким описанием алгоритмов их решения, описанием выходных документов, которые должны генерироваться в системе, описанием входных документов, которые служат основанием для заполнения данными БД. Инфологическая модель создается по результатам проведения исследований предметной области. Инфологическая модель представляет собой описание будущей базы данных, представленное с помощью естественного языка, формул, графиков, диаграмм, таблиц и других средств, понятных как разработчикам БД, так и обычным пользователям. Назначение такой модели состоит в адекватном описании процессов, информационных потоков, функций системы с помощью общедоступного и понятного языка, что делает возможным привлечение экспертов предметной области, консультантов, пользователей для обсуждения модели и внесения исправлений. Создание инфологической модели является естественным продолжением исследований предметной области, но в отличие от него является представлением БД с точки зрения проектировщика (разработчика). Наглядность представления такой модели позволяет экспертам предметной области оценить ее точность и внести исправления. От правильности модели зависит успех дальнейшей разработки. Важно отметить, что создаваемая на этом этапе модель полностью не зависит от физической реализации будущей системы. В случае с БД это означает, что совершенно не важно где физически будут храниться данные: на бумаге, в памяти компьютера и кто или что эти данные будет обрабатывать. В этом случае, когда структуры данных не зависят от их физической реализации, а моделируются исходя из их смыслового назначения, моделирование называется семантическим. Логическое (даталогическое) проектирование — создание схемы базы данных на основе конкретной модели данных. Цель даталогического проектирования – разработка логической структуры базы данных. Причем логическая структура базы данных, а также сама заполняемая данными база данных являются отображением реальной предметной области. Спроектировать логическую структуру базы данных означает определить все информационные единицы базы данных и связи между ними, задать их имена, типы и другие требуемые характеристики. Так как каждая система управления базами данных имеет собственные требования к назначению информационным единицам соответствующих характеристик, то даталогическое проектирование обязательно производится в среде конкретной СУБД. Таким образом, исходными данными для разработки даталогической модели являются:
Даталогическая модель включает в себя следующие основные компоненты:
Для каждой конкретной СУБД эти компоненты могут иметь уникальные особенности, поэтому цель пособия заключается в описании основных из них, наиболее общих для всех систем управления базами данных. Концептуальная и внутренняя схемы баз данных, получаемые на разных этапах проектирования, отображают один и тот же объект реального мира. В связи с этим преобразование концептуальной схемы во внутреннюю выполняется в соответствии с определенными правилами, регламентирующими, как из описания предметной области на уровне инфологической модели получить описание той же предметной области на даталогическом уровне. В результате даталогического моделирования в соответствии с реляционной моделью данных создается внутренняя схема. Для описания внутренней схемы базы данных используются операторы языка описания данных соответствующей СУБД. В современных реляционных СУБД наиболее распространенным ЯОД являются подмножества языка SQL (Structured Query Language). Для описания ограничений целостности используются соответствующие средства ЯОД и языка разработки приложений (SAL – SQL Application Language), поддерживаемые конкретной СУБД. Конечным результатом даталогического проектирования является описание логической структуры базы данных на ЯОД. Под физической организацией БД понимается совокупность методов и средств размещения данных во внешней памяти и созданная на их основе внутренняя (физическая) модель данных. Внутренняя модель является средством отображения логической модели данных в физическую среду хранения. В отличие от логических моделей физическая модель данных связана со способами организации данных на носителях, методами доступа к данным. Она указывает, каким образом записи размещаются в базе данных, как они упорядочиваются, как организуются связи, каким путем можно локализовать записи и осуществить их выборку. Внутренняя модель разрабатывается средствами СУБД. Очевидно, что любая логическая модель может быть отображена множеством внутренних моделей данных подобно тому, как один и тот же алгоритм может быть представлен множеством эквивалентных программ, составленных на одном или разных языках программирования. Одна из внутренних моделей будет оптимальной. В качестве критериев оптимальности используются минимальное время ответа системы, минимальный объем памяти, минимальные затраты на ведение баз данных и др. Основными средствами физического моделирования в БнД являются структура хранения данных, поисковые структуры и язык описания данных. В простейшем случае структуру хранения данных можно представить в виде структуры записи файла базы данных, включающей поля записи, порядок их размещения, типы и длины полей. Если структура хранения данных в основном предназначена для указания способа размещения записей и полей, то поисковые структуры определяют способ быстрого нахождения этих записей. Поэтому различают два принципа физической организации БД: организация на основе структуры хранения данных и организация, сочетающая структуру хранения данных с одной или несколькими поисковыми структурами. Конечным итогом разработки физической организации БД являются базы данных – файл базы данных и файлы поисковых структур. В ПК эти файлы могут быть последовательными или прямыми (имеется в виду последовательного или прямого доступа). Виды сущностей
Слабая сущность в контексте решаемой задачи не может существовать без сильной. Например, в вузе студент обязательно входит в группу, т.е. сущность студент не может существовать без сущности группа. Сущность деталь не может существовать без сущности изделие, а сущность сотрудник - без сущности отдел. Так как сущность соответствует некоторому классу однотипных объектов, то предполагается, что в системе существует множество экземпляров данной сущности. Экземпляр сущности - это конкретный представитель данной сущности. Объект, которому соответствует понятие сущности, имеет свой набор атрибутов — характеристик, определяющих свойства данного представителя класса. При этом набор атрибутов должен быть таким, чтобы можно было различать конкретные экземпляры сущности. Между сущностями могут быть установлены связи — бинарные ассоциации, показывающие, каким образом сущности соотносятся или взаимодействуют между собой. Связь может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). Она показывает, как связаны экземпляры сущностей между собой. Если связь устанавливается между двумя сущностями, то она определяет взаимосвязь между экземплярами одной и другой сущности. Связи делятся на три типа по множественности: один-к-одному (1:1), один-ко-многим (1:M), многие-ко-многим (M:M). Связь один-к-одному означает, что экземпляр одной сущности связан только с одним экземпляром другой сущности. Связь 1: M означает, что один экземпляр сущности, расположенный слева по связи, может быть связан с несколькими экземплярами сущности, расположенными справа по связи. Связь "один-к-одному" (1:1) означает, что один экземпляр одной сущности связан только с одним экземпляром другой сущности, а связь "многие-ко-многим" (M:M) означает, что один экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и наоборот, один экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Между двумя сущностями может быть задано сколько угодно связей с разными смысловыми нагрузками. Связь любого из этих типов может быть обязательной, если в данной связи должен участвовать каждый экземпляр сущности, необязательной — если не каждый экземпляр сущности должен участвовать в данной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны. Кроме того, в ER-модели допускается принцип категоризации сущностей. Это значит, что, как и в объектно-ориентированных языках программирования, вводится понятие подтипа сущности, то есть сущность может быть представлена в виде двух или более своих подтипов — сущностей, каждая из которых может иметь общие атрибуты и отношения и/или атрибуты и отношения, которые определяются однажды на верхнем уровне и наследуются на нижнем уровне. Все подтипы одной сущности рассматриваются как взаимоисключающие, и при разделении сущности на подтипы она должна быть представлена в виде полного набора взаимоисключающих подтипов. Если на уровне анализа не удается выявить полный перечень подтипов, то вводится специальный подтип, называемый условно ПРОЧИЕ, который в дальнейшем может быть уточнен. В реальных системах бывает достаточно ввести подтипизацию на двух-трех уровнях. Реляционная модель. Отношение – Таблица. Кортеж – Строка (Запись). Атрибут – Столбец (Поле). Реляционная модель - совокупность данных, состоящая из набора двумерных таблиц. В теории множеств таблице соответствует термин отношение (relation), физическим представлением которого является таблица, отсюда и название модели – реляционная. Соответственно теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики, как теория множеств и логика первого порядка. В сравнении с иерархической и сетевой моделью данных, реляционная модель отличается более высоким уровнем абстракции данных. Реляционная модель является удобной и наиболее привычной формой представления данных, так в настоящее время эта модель является фактическим стандартом, на который ориентируются практически все современные коммерческие СУБД. На реляционной модели данных строятся реляционные базы данных[1]. В реляционной модели данных применяются разделы реляционной алгебры, откуда и была заимствована соответствующая терминология.В реляционной алгебре поименованный столбец отношения называется атрибутом, а множество всех возможных значений конкретного атрибута – доменом. Строки таблицы со значениями разных атрибутов называют кортежами. Атрибут, значение которого однозначно идентифицирует кортежи, называется ключевым (или просто ключом). Так ключевое поле – это такое поле, значения которого в данной таблице не повторяется. В отличие от иерархической и сетевой моделей данных в реляционной отсутствует понятие группового отношения. Для отражения ассоциаций между кортежами разных отношений используется дублирование их ключей. Сложный ключ выбирается в тех случаях, когда ни одно поле таблицы однозначно не определяет запись. Отношение является важнейшим понятием и представляет собой двумерную таблицу, содержащую некоторые данные. Пусть дана совокупность типов данных T1, T2, ..., Tn, называемых также доменами, не обязательно различных. Тогда n-арным отношением R, или отношением R степени n называют подмножество декартовa произведения множеств T1, T2, ..., Tn[1][2]. Отношение R состоит из заголовка (схемы) и тела. Заголовок представляет собой множество атрибутов (именованных вхождений домена в заголовок отношения), а тело — множество кортежей, соответствующих заголовку[2]. Более строго:
В изменчивой реляционной базе данных хранятся отношения, значения которых изменяются во времени. Переменной VARrназывается именованный контейнер, который может содержать любое допустимое значение Vr . Естественно, что при определении любой VARr требуется указывать соответствующий заголовок отношения Hr. 9. Информационные системы организаций. Прикладные БД - данные, необходимые для решения одной или нескольких прикладных задач. Предметные БД - данные, относящиеся к какой-либо предметной области (например, финансам, студентам и т.д.). Информационная система, решающая задачи оперативного управления предприятием, строится на основе базы данных, в которой фиксируется вся возможная информация о предприятии. Такая информационная система является инструментом для управления бизнесом и обычно называется корпоративной информационной системой. Информационная система оперативного управления включает в себя массу программных решений по автоматизации бизнес-процессов, имеющих место на конкретном предприятии. "Идеальная" информационная система управления предприятием должна автоматизировать все или, по крайней мере, большинство из видов деятельности предприятия. При этом автоматизация должна быть выполнена не ради автоматизации, а с учётом затрат на неё, и дать реальный эффект в результатах финансово-хозяйственной деятельности предприятия. В зависимости от предметной области информационные системы могут весьма значительно различаться по своим функциям, архитектуре, реализации. Однако можно выделить ряд свойств, которые являются общими. 1. Информационные системы предназначены для сбора, хранения и обработки информации, поэтому в основе любой из них лежит среда хранения и доступа к данным. 2. Информационные системы ориентированы на конечного пользователя, не обладающего высокой квалификацией в области вычислительной техники. Поэтому клиентские приложения информационной системы должны обладать простым, удобным, легко осваиваемым интерфейсом, который предоставляет конечному пользователю все необходимые для работы функции и в то же время не даёт ему возможность выполнять какие-либо лишние действия. На предприятии должна быть создана база данных, которая обеспечивает хранение информации и доступность её для всех составляющих системы управления. Наличие такой базы данных позволяет сформировать информацию для принятия решений Наличие постоянных и разовых пользователей в автоматизированных информационных системах, и, следовательно, наличие потока регламентированных и произвольных по содержанию запросов требуют разработки специальных подходов к определению границ ПО и проектированию состава элементов информационной модели. Поэтому информационные системы больших организаций содержат несколько десятков БД, нередко распределенных между несколькими взаимосвязанными ЭВМ различных подразделений [5, 17]. (Так в больших городах создается не одна, а несколько овощных баз, расположенных в разных районах.) Если бы в АИС существовал только поток регламентированных запросов и не ожидалось развитие системы, то можно было бы определить границы ПО и осуществить проектирование исходя из анализа содержания всей совокупности запросов пользователей – это так называемый подход к проектированию «от запросов пользователей» [17]. Базы данных, спроектированные по такому подходу, могут объединять все данные, необходимые для решения одной или нескольких прикладных задач, и обычно называются прикладными БД. Наличие потока произвольных по содержанию запросов и развитие автоматизированных информационных систем во времени не позволяют в полной мере использовать подход от запросов. В этом случае необходим подход, позволяющий выполнить прогноз смыслового содержания ожидаемой совокупности произвольных запросов. Таким является подход, называемый «от реального мира». С помощью экспертов определяются границы предметной области – состав объектов, их свойства и отношения с учетом развития системы, и затем проектируется модель. Этот подход базируется на предположении, что произвольные запросы пользователей соответствуют тематической направленности АИС. Такие БД объединяют данные, относящиеся к какой-либо предметной области [5] (например, финансам, обучению, торговле и т.п.) и называются предметными БД (соотносящимся с предметами организации, а не с ее информационными приложениями). Подход «от реального мира» предпочтительно использовать в качестве основного, подход «от запросов пользователей» – для уточнения границ предметной области. Наибольшее применение он должен получать в период использования АИС, когда при работе накапливается достаточно информации о содержании произвольных запросов и необходимо выполнить коррекцию границ ПО и состава элементов информационной модели. Предметные БД позволяют обеспечить поддержку любых текущих и будущих приложений, поскольку набор их элементов данных включает в себя наборы элементов данных прикладных БД. Вследствие этого предметные БД создают основу для обработки неформализованных, изменяющихся и неизвестных запросов и приложений (приложений, для которых невозможно заранее определить требования к данным). Такая гибкость и приспосабливаемость позволяет создавать на основе предметных БД достаточно стабильные информационные системы, т.е. системы, в которых большинство изменений можно осуществить без вынужденного переписывания старых приложений. Основывая же проектирование БД на текущих и предвидимых приложениях, можно существенно ускорить создание высокоэффективной информационной системы, т.е. системы, структура которой учитывает наиболее часто встречающиеся пути доступа к данным. Поэтому прикладное проектирование до сих пор привлекает некоторых разработчиков. Однако по мере роста числа приложений таких информационных систем быстро увеличивается число прикладных БД, резко возрастает уровень дублирования данных и повышается стоимость их ведения. Таким образом, каждый из рассмотренных подходов к проектированию воздействует на результаты проектирования качественно по-разному. Первая нормальная форма Отношение находится в первой нормальной форме (1НФ), если все атрибуты отношения являются простыми (требование атомарности атрибутов в реляционной модели), т.е. не имеют компонентов. Иными словами, домен атрибута должен состоять из неделимых значений и не может включать в себя множество значений из более элементарных доменов. Так, например, дата не может считаться простым атрибутом. В большинстве случаев выполнить это требование достаточно просто. Каждый простой атрибут должен иметь свою колонку в таблице. Однако это часто приводит к дублированию данных в отношении. Таким образом, процедура приведения отношения к 1НФ состоит в вынесении неатомарных атрибутов в отдельное подчиненное отношение, т.е. в выполнении двух проекций. Вторая нормальная форма Отношение находится во второй нормальной форме (2НФ), если оно находится в 1НФ, и все неключевые атрибуты отношения функционально полно зависят от составного ключа отношения. Иными словами, 2НФ требует, чтобы отношение не содержало частичных ФЗ. атрибут отношения ключевым, если он является элементом какого-либо ключа отношения. В противном случае атрибут будет считаться неключевым атрибутом. Таким образом, процедура приведения отношения ко 2НФ состоит в выполнении двух проекций: проекции без атрибутов частичной ФЗ и проекции на часть составного ключа и те атрибуты, которые от него зависят. Третья нормальная форма Отношение находится в третьей нормальной форме (3НФ), если оно находится во 2НФ, и все неключевые атрибуты отношения зависят только от первичного ключа. Иными словами, 3НФ требует, чтобы отношение не содержало транзитивных ФЗ неключевых атрибутов от ключа. Таким образом, процедура приведения отношения к 3НФ состоит в выполнении двух проекций: проекции по правой части транзитивнойФЗ и проекции по левой части транзитивной ФЗ. Запрос извлечения данных. Простейший запрос. Структура запроса. Пример запроса. Запрос - команда которую вы даете вашей программе базы данных, и которая сообщает ей чтобы она вывела определенную информацию из таблиц в память. Эта информация обычно посылается непосредственно на экран компьютера или терминала, которым вы пользуетесь, хотя, в большинстве случаев, ее можно также послать принтеру, сохранить в файле (как объект в памяти компьютера), или представить как вводную информацию для другой команды или процесса. Вы можете создать запрос на выборку с помощью мастера или конструктора запросов. Некоторые элементы недоступны в мастере, однако их можно добавить позже из конструктора. Хотя это разные способы, основные этапы аналогичны. Для выборки информации из таблиц базы данных используется SQL-инструкций SELECT (выбрать) языка SQL. Простейший оператор SELECT выглядит: SELECT * FROM …; Он осуществляет выборку всех записей из объекта БД табличного типа с именем PC. При этом столбцы и строки результирующего набора не упорядочены. Чтобы упорядочить поля результирующего набора, их следует перечислить через запятую в нужном порядке после слова SELECT Структуру SQL-инструкций можно разделить на две основные части (рис.1). Первая часть включает название (команду) SQL-инструкции, предикат (необязательный элемент) и аргументы инструкции, которыми являются перечисляемые через запятую имена полей или нескольких таблиц. Вторая часть состоит из одного или нескольких предложений, аргументы которых могут задавать источники данных (имена таблиц, операции над таблицами), способы, условия и режимы выполнения команды (предикаты сравнения, логические и математические выражения по значениям полей таблиц). Любой SQL-запрос должен заканчиваться символом «;» (точка с запятой). Выборка данных осуществляется с помощью оператора SELECT, который является самым часто используемым оператором языка SQL. Синтаксис оператора SELECT имеет следующий вид: SELECT [ALL/DISTINCT] <список атрибутов> /* FROM <список таблиц> [WHERE <условие выборки>] [ORDER BY <список атрибутов>] [GROUP BY <список атрибутов>] [HAVING <условие>] [UNION <выражение с оператором SELECT>] SELECT snum, sname, sity, comm FROM Salespeople; 14. Реляционные операторы =, >, >=, <, <=, <>. Реляционный оператор - математический символ который указывает на определенный тип сравнения между двум значениями. Вы уже видели как используются равенства, такие как 2 + 3 = 5 или city = "London". Но также имеются другие реляционные операторы. Предположим что вы хотите видеть всех Продавцов с их комиссионными выше определенного значения. Вы можете использовать тип сравнения "больше чем" - (>). Реляционные операторы которыми располагает SQL : = Равный к > Больше чем < Меньше чем >= Больше чем или равно <= Меньше чем или равно < > Не равно Эти операторы имеют стандартные значения для числовых значений. Для значения символа, их определение зависит от формата преобразования, ASCII или EBCDIC, который вы используете. SQL сравнивает символьные значения в терминах основных номеров как определено в формате преобразования. Даже значение символа, такого как "1", который представляет номер, не обязательно равняется номеру который он представляет. Вы можете использовать реляционные операторы чтобы установить алфавитный порядок - например, "a" < "n" где средство a первое в алфавитном порядке - но все это ограничивается с помощью параметра преобразования формата. Выборкой (ограничением, селекцией) на отношении с условием В простейшем случае условие Булевы операторы AND , OR , NOT . Пример использования в запросе. основные Булевы операторы также распознаются в SQL. Выражения Буля — являются или верными, или неверными, подобно предикатам. Булевы операторы связывают одно или более верных/неверных значений и производят единственное верное/или/неверное значение. Стандартными операторами Буля, распознаваемыми в SQL, являются: AND, OR, и NOT. Существуют другие, более сложные, операторы Буля (типа "исключенный или"), но они могут быть сформированы из этих трех простых операторов — AND, OR, NOT. Как вы можете понять, Булева верная/неверная логика — основана на цифровой компьютерной операции; и фактически, весь SQL (или любой другой язык) может быть сведен до уровня Булевой логики. Операторы Буля и как они работают: AND берет два Буля (в форме A AND B) как аргументы и оценивает их по отношению к истине, верны ли они оба. OR берет два Буля (в форме A OR B) как аргументы и оценивает на правильность, верен ли один из них. NOT берет одиночный Булев (в форме NOT A) как аргументы и заменяет его значение с неверного на верное или верное на неверное. Связывая предикаты с операторами Буля, вы можете значительно увеличить их возможности. Предположим вы хотите видеть всех заказчиков в San Jose которые имеют оценку (рейтинг) выше 200: SELECT * FROM Customers WHERE city = 'San Jose' AND rating > 200; Функции в SQL. Агрегатные, финансовые, текстовые, математические. Пример использования функции в запросе. Пример запроса. В SQL добавлены дополнительные функции, которые позволяют вычислять обобщенные групповые значения. Для применения агрегатных функций предполагается предварительная операция группировки. В чем состоит суть операции группировки? При группировке все множество кортежей отношения разбивается на группы, в которых собираются кортежи, имеющие одинаковые значения атрибутов, которые заданы в списке группировки.
SELECT SUM(SAL) FROM EMPLOYEE; SQL поддерживает полный набор арифметических операций и математических функций для построения арифметических выражений над колонками базы данных ( +, -, *, /, ABS, LN, SQRT и т.д.). Набор встроенных функций может изменяться в зависимости от версии СУБД одного производителя и также в СУБД различных производителей. Арифметические выражения необходимы для получения данных, которые непосредственно не сохраняются в колонках таблиц базы данных, но значения которых необходимы пользователю. Допустим, что вам необходим список служащих, показывающий выплату, которую получил каждый служащий с учетом премий и штрафов. SELECT ENAME, SAL, COMM, FINE, SAL + COMM - FINE FROM EMPLOYEE ORDER BY DEPNO; SQL предоставляет вам широкий набор функций для манипулирования со строковыми данными (LENGTH Возвращает длину строки, INSTR Устанавливает первый символ каждого слова в строке на заглавный, а остальные символы каждого слова - на прописные и другие). Можно использовать функцию INITCAP, чтобы при получении списка имен служащих фамилии всегда начинались с заглавной буквы, а все остальные были прописными. SELECT INITCAP(ENAME) FROM EMPLOYEE ORDER BY DEPNO;
17. Агрегатные функции : COUNT (* | <val>) – количество значений ; SUM (<val>) – сумма ; AVG (<val>) – среднее ; MAX (<val>) – максимальное ; MIN (<val>) – минимальное . Пример использования в запросе. Агрегатные функции в SQL позволяют выбирать обобщающую информацию из группы строк и проводить систематизацию данных. Использование функций агрегирования позволяет вам находить суммарные значения колонок и разброс данных в колонке. Функция SQL SUM возвращает сумму значений столбца таблицы базы данных. Она может применяться только к столбцам, значениями которых являются числа. Функция SQL MIN также действует в отношении столбцов, значениями которых являются числа и возвращает минимальное среди всех значений столбца. Эта функция имеет синтаксис аналогичный синтаксису функции SUM. SELECT MIN(Salary) FROM Staff WHERE DEPT=42 Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда требуется определить максимальное значение среди всех значений столбца. SELECT MAX(Salary) FROM Staff WHERE DEPT=42 Указанное в отношении синтаксиса для предыдущих описанных функций верно и в отношении функции SQL AVG. Эта функция возвращает среднее значение среди всех значений столбца. SELECT AVG(Years) FROM Staff WHERE DEPT=42 Функция SQL COUNT возвращает количество записей таблицы базы данных. Если в запросе указать SELECT COUNT(ИМЯ_СТОЛБЦА) ..., то результатом будет количество записей без учёта тех записей, в которых значением столбца является NULL (неопределённое). Если использовать в качестве аргумента звёздочку и начать запрос SELECT COUNT(*) ..., то результатом будет количество всех записей (строк) таблицы. SELECT COUNT(Comm) FROM Staff Математические функции . Перечень функций. Пример использования в запросе.
SELECT ABS(-10) as module FROM table; SELECT ACOS(.5) as arcosine FROM table; Использование нескольких таблиц в запросе. Пример запроса. в предложении FROM допускается указание нескольких таблиц. Простое перечисление таблиц практически не используется, поскольку оно соответствует реляционной операции декартова произведения. Т.е. в результирующем наборе каждая запись из одной таблицы будет сочетаться с каждой записью в другой. Например, для таблиц
Результат запроса
Поэтому перечисление таблиц, как правило, используется совместно с условием соединения записей из разных таблиц, указываемым в предложении WHERE. Для приведенных выше таблиц таким условием может быть совпадение значений, скажем, в полях a и c:
т.е. соединяются только те строки таблиц, у которых в указанных полях находятся равные значения (эквисоединение). Естественно, могут быть использованы любые условия, хотя эквисоединение используется чаще всего, поскольку эта операция воссоздает некую сущность, декомпозированную на две других в результате процедуры нормализации. <имя таблицы>.<имя поля> В тех случаях, когда это не вызывает неоднозначности, использование данной нотации не является обязательным. Сортировка данных в запросе Order By. Пример запроса. Для выполнения сортировки в строку запроса нужно добавить команду ORDER BY. После этой команды указывается поле, по которому производится сортировка. По умолчанию, команда ORDER BY выполняет сортировку по возрастанию. Чтобы управлять направлением сортировки вручную, после имени столбца указывается ключевое слово ASC (по возрастанию) или DESC (по убыванию). SQL допускает сортировку сразу по нескольким полям. Для этого после команды ORDER BY необходимые поля указываются через запятую. Порядок в результате запроса будет настраиваться в той же очередности, в которой указаны поля сортировки. Сортировка строк чаще всего проводится вместе с условием на выборку данных. Команда ORDER BY ставится после условия выборки WHERE. SELECT * FROM mytable ORDER BY column1 ASC, column2 DESC, column3 ASC INNER JOIN Возвращаются все записи из таблиц table_01 и table_02, связанные посредством primary/foreign ключей, и соответствующие условию WHERE для таблицы table_01. Если в какой-либо из таблиц отсутствует запись, соответствующая соседней, то в выдачу такая пара включена не будет. Иными словами, выдадутся только те записи, которые есть и в первой, и во второй таблице. То есть выборка идет фактически по связи (ключу), выдадутся только те записи, которые связаны между собой. «Одинокие» записи, для которых нет пары в связи, выданы не будут. SELECT * FROM table_01 INNER JOIN table_02 ON table_01.primary_key = table_02.foreign_key WHERE table_01.column_01 = ‘value’ LEFT JOIN Возвращаются все данные из «левой» таблицы, даже если не найдено соответствий в «правой» таблице («левая» таблица в SQL-запросе стоит левее знака равно, «правая» — правее, то есть обычная логика правой и левой руки). Иными словами, если мы присоединяем к «левой» таблице «правую», то выберутся все записи в соответствии с условиями WHERE для левой таблицы. Если в «правой» таблице не было соответствий по ключам, они будут возвращены как NULL. Таким образом, здесь главной выступает «левая» таблица, и относительно нее идет выдача. В условии ON «левая» таблица прописывается первой по порядку (table_01), а «правая» – второй (table_02): SELECT * FROM table_01 LEFT JOIN table_02 ON table_01.primary_key = table_02.foreign_key WHERE table_01.column_01 = ‘value’ RIGHT JOIN Возвращаются все данные из «правой» таблицы, даже если не найдено соответствий в «левой» таблице. То есть примерно также, как и в LEFT JOIN, только NULL вернется для полей «левой» таблицы. Грубо говоря, эта выборка ставит во главу угла правую «таблицу», относительно нее идет выдача. Обратите внимание на WHERE в следующем примере, условие выборки затрагивает «правую» таблицу: SELECT * FROM table_01 RIGHT JOIN table_02 ON table_01.primary_key = table_02.foreign_key WHERE table_02.column_01 = ‘value’ 22. SQL INSERT. Структура запроса, пример запроса. Оператор INSERT вставляет новые записи в таблицу. При этом значения столбцов могут представлять собой литеральные константы, либо являться результатом выполнения подзапроса. В первом случае для вставки каждой строки используется отдельный оператор INSERT; во втором случае будет вставлено столько строк, сколько возвращается подзапросом. Синтаксис оператора следующий: INSERT INTO Пример 1 INSERT INTO dept VALUES (50, «ПРОДУКЦИЯ», «САН-ФРАНЦИСКО»); INSERT INTO Customers (city, cname, cnum) VALUES (‘London’, ‘Hoffman’, 2001); INSERT INTO Пример 2 INSERT INTO bonus SELECT ename, job, sal, comm FROM emp WHERE comm > 0.25 * sal; Утверждение INSERT с фразой VALUES добавляет одиночную строку к таблице. Эта строка содержит значения, определенные фразой VALUES. Файловая система хранения данных. Объективные предпосылки применения. Недостатки. СУБД - хранение и интерпретация данных. Однако с появлением магнитных дисков началась история систем управления данными во внешней памяти. До этого каждая прикладная программа, которой требовалось хранить данные во внешней памяти, сама определяла расположение каждой порции данных на магнитной ленте или барабане и выполняла обмены между оперативной памятью и устройствами внешней памяти с помощью программно-аппаратных средств низкого уровня (машинных команд или вызовов соответствующих программ операционной системы). Такой режим работы не позволяет или очень затрудняет поддержание на одном внешнем носителе нескольких архивов долговременно хранимой информации. Кроме того, каждой прикладной программе приходилось решать проблемы именования частей данных и структуризации данных во внешней памяти. Поэтому важным шагом в развитии информационных систем явился переход к использованию централизованных систем управления файлами. Фа́йловая систе́ма — порядок, определяющий способ организации, хранения и именования данных на носителях информации в компьютерах, а также в другом электронном оборудовании: цифровых фотоаппаратах, мобильных телефонах и т. п. Файловая система определяет формат содержимого и способ физического хранения информации, которую принято группировать в виде файлов. Конкретная файловая система определяет размер имен файлов (и каталогов), максимальный возможный размер файла и раздела, набор атрибутов файла. Когда прикладная программа обращается к файлу, она не имеет никакого представления о том, каким образом расположена информация в конкретном файле, так же, как и о том, на каком физическом типе носителя он записан. Всё, что знает программа — это имя файла, его размер и атрибуты. Эти данные она получает от драйвера файловой системы. Именно файловая система устанавливает, где и как будет записан файл на физическом носителе (например, жёстком диске). Однако файловая система не обязательно напрямую связана с физическим носителем информации. Существуют виртуальные файловые системы, а также сетевые файловые системы, которые являются лишь способом доступа к файлам, находящимся на удалённом компьютере. С точки зрения прикладной программы файл — это именованная область внешней памяти, в которую можно записывать и из которой можно считывать данные. Пользователи видят файл как линейную последовательность записей и могут выполнить над ним ряд стандартных операций:
Недостатки: В разных файловых системах эти операции могли несколько отличаться, но общий смысл их был именно таким. Главное, что следует отметить, это то, что структура записи файла была известна только программе, которая с ним работала, система управления файлами не знала ее. И поэтому для того, чтобы извлечь некоторую информацию из файла, необходимо было точно знать структуру записи файла с точностью до бита. Каждая программа, работающая с файлом, должна была иметь у себя внутри структуру данных, соответствующую структуре этого файла. Поэтому при изменении структуры файла требовалось изменять структуру программы, а это требовало новой компиляции, то есть процесса перевода программы в исполняемые машинные коды. Такая ситуация характеризовалась как зависимость программ от данных. Изменение структуры файла, которое было необходимо для одной программы, требовало исправления и перекомпиляции и дополнительной отладки всех остальных программ, работающих с этим же файлом. Далее, поскольку файловые системы являются общим хранилищем файлов, принадлежащих, вообще говоря, разным пользователям, системы управления файлами должны обеспечивать авторизацию доступа к файлам. В общем виде подход состоит в том, что по отношению к каждому зарегистрированному пользователю данной вычислительной системы для каждого существующего файла указываются действия, которые разрешены или запрещены данному пользователю. В большинстве современных систем управления файлами применяется подход к защите файлов, впервые реализованный в ОС UNIX. В этой ОС каждому зарегистрированному пользователю соответствует пара целочисленных идентификаторов: идентификатор группы, к которой относится этот пользователь, и его собственный идентификатор в группе. При каждом файле хранится полный идентификатор пользователя, который создал этот файл, и фиксируется, какие действия с файлом может производить его создатель, какие действия с файлом доступны для других пользователей той же группы и что могут делать с файлом пользователи других групп. Администрирование режимом доступа к файлу в основном выполняется его создателем-владельцем. Для множества файлов, отражающих информационную модель одной предметной области, такой децентрализованный принцип управления доступом вызывал дополнительные трудности. И отсутствие централизованных методов управления доступом к информации послужило еще одной причиной разработки СУБД. Следующей причиной стала необходимость обеспечения эффективной параллельной работы многих пользователей с одними и теми же файлами. В общем случае системы управления файлами обеспечивали режим многопользовательского доступа. Если операционная система поддерживает многопользовательский режим, вполне реальна ситуация, когда два или более пользователя одновременно пытаются работать с одним и тем же файлом. Если все пользователи собираются только читать файл, ничего страшного не произойдет. Но если хотя бы один из них будет изменять файл, для корректной работы этих пользователей требуется взаимная синхронизация их действий по отношению к файлу. При подобном способе организации одновременная работа нескольких пользователей, связанная с модификацией данных в файле, либо вообще не реализовывалась, либо была очень замедлена. Эти недостатки послужили тем толчком, который заставил разработчиков информационных систем предложить новый подход к управлению информацией. Этот подход был реализован в рамках новых программных систем, названных впоследствии Системами Управления Базами Данных (СУБД), а сами хранилища информации, которые работали под управлением данных систем, назывались базами или банками данных (БД и БнД). Отличительной чертой баз данных следует считать то, что данные хранятся совместно с их описанием, а в прикладных программах описание данных не содержится. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-06-09; Просмотров: 1271; Нарушение авторского права страницы
 называется отношение с тем же заголовком, что и у отношения
называется отношение с тем же заголовком, что и у отношения 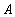 , и телом, состоящем из кортежей, значения атрибутов которых при подстановке в условие
, и телом, состоящем из кортежей, значения атрибутов которых при подстановке в условие  , где
, где  - один из операторов сравнения (
- один из операторов сравнения (  и т.д.), а
и т.д.), а  и
и  - атрибуты отношения
- атрибуты отношения 
