
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Синтаксический анализ как распознающая процедура
После того, как построена грамматика, порождающая язык для описания рассматриваемого образа, необходимо построить устройство, распознающее объекты представленные цепочками, порождёнными этой грамматикой. Прямой подход к решению этой задачи состоит в создании отдельной грамматики для каждого класса объектов. Распознающее устройство для данной грамматики будет выделять только те объекты, которые принадлежат соответствующему этой грамматике классу. Например, для m классов объектов C 1, C 2, …, Cm можно построить m соответствующих грамматик G 1, G 2, …, Gm, таких, что цепочки, порождённые грамматикой Gi, будут представлять объекты из класса Ci. [4] Тогда для произвольного объекта, описываемого цепочкой x, проблема распознавания сводится к вопросу: верно ли, что x
Процесс, приводящий к ответу на этот вопрос для одной заданной грамматики, обычно называют «синтаксическим анализом» или «грамматическим разбором». Этот процесс, кроме ответа на вопрос - «да» или «нет», может также давать дерево вывода, т.е. информацию о структуре соответствующего объекта. Блок-схема распознающего алгоритма приведена на рисунке 9.
Будем считать, что если объекты представляются единственным образом, то среди ответов на вопросы «верно ли, что x Простой способ распознавания состоит в сопоставлении входной цепочки с прототипом или эталоном каждого класса. Эталонная цепочка задаётся в терминах непроизводных элементов. Сопоставление непроизводных элементов может осуществляться параллельно или последовательно. Цепочка x относится к тому классу, из которого взята эталонная цепочка, наилучшим образом согласующаяся с x. В этом случае требуется либо точное совпадение x с эталоном, либо выполнение подходящего критерия согласования. Конечно, не менее важен и выбор эталонных цепочек [4]. Этот подход, хотя и выглядит менее гибким, может быть реализован быстродействующей программой. Однако в действительности иерархическая структурная информация используется недостаточно, и этот подход полезен только тогда, можно определить соответствующие эталонные цепочки и имеющий смысл критерий согласования. Если грамматика Gi регулярна, то можно построить детерминированный конечный автомат для распознавания цепочек, порождённых Gi. Если Gi - бесконтекстная или программная грамматика, то обычно требуется недетерминированный автомат. В процессе распознавания используется, вообще говоря, некоторая недетерминированная процедура. Задача синтаксического анализа может быть поставлена следующим образом: для заданного предложения x и грамматики G построить треугольник
S x
и попытаться заполнить его внутреннюю часть деревом вывода x, правильным для грамматики G [4]. Если попытка успешна, то x Грамматический разбор сверху вниз. Синтаксический анализ сверху вниз начинается с символа S, обозначающего всё предложение, и состоит из последовательных пробных подстановок правил, которые порождают подходящие для этого предложения вспомогательные символы. Чистый синтаксический анализ сверху вниз - полностью целенаправленный процесс. Главной целью является вывод из S данного предложения x. Делается предположение, что анализируемая цепочка действительно есть предложение в языке данной грамматики G. Поэтому первый шаг - выяснить, можно ли свести цепочку к правой части некоторого правила подстановки S → X 1 X 2 … XN. (2.33)
Это выясняется следующим образом. Применение данного правила подстановки в случае, когда X 1 - основной символ, возможно, если цепочка начинается с этого символа. Если же X 1 - вспомогательный символ, ставится подзадача: определить, можно ли какое-либо начало цепочки свести к X 1. Если это оказывается возможным, таким же образом проверяется X 2, затем X 3 и т.д. Если для некоторого Xi не удаётся найти подходящего места в выводе цепочки, то надо попробовать применить другое правило подстановки. Точно также решаются подзадачи для всех A При анализе слева направо и сверху вниз иногда вызывает затруднение повторение слева вспомогательного символа: правила подстановки вида A 1 → A 1 α могут приводить к бесконечным петлям при анализе. Это происходит, когда сведение части цепочки к символу A 1 ставится как подзадача, и первым шагом в её решении оказывается решение той же задачи, т.е. сведение части цепочки к A 1. Проблема повторения слева иногда решается путём какого-либо преобразования грамматики или изменения порядка разбора. Большую роль здесь также может сыграть порядок, в котором проверяются различные правые части правил подстановки при одной и той же левой части. Если только одна правая часть содержит повторение слева, то она должна проверяться в последнюю очередь. Однако такая последовательность действий может вступать в противоречие с другими условиями на порядок проверки, например, с требованием, что кратчайшая правая часть проверяется последней. Грамматический разбор снизу вверх. В отличие от метода разбора сверху вниз, где символ предложения S развёртывается в заданное предложение при помощи последовательных правил подстановки, при разборе снизу вверх применяют инверсии правил подстановки с тем, чтобы свернуть предложение до начального символа грамматики. Другими словами, в цепочке отыскиваются подцепочки, совпадающие с правыми частями правил подстановки, затем они заменяются на соответствующие левые части. Легко видеть, что при грамматическом разборе снизу вверх не существует проблемы повторений слева. В общем случае используются два различных метода для обхода тупиков, возникающих при грамматическом разборе. Первый метод - возвращение к тому моменту, с которого можно начать другой вариант синтаксического анализа. Этот метод требует восстановления цепочки в прежней форме или уничтожения некоторых связей, появившихся в дереве вывода. Второй метод заключается в параллельном выполнении всех возможных грамматических разборов предложения. Некоторые из этих вариантов разбора отбрасываются, поскольку их не удаётся закончить. На практике, однако, многие алгоритмы анализа можно усовершенствовать настолько, что при определённых ограничениях на вид грамматики ни возвращения, ни параллельное выполнение разборов не нужны. Сравнение различных методов синтаксического анализа трудно по следующим причинам. Во-первых, эффективность разбора зависит от вида грамматики: для одних грамматик предложения быстрее разбираются методом снизу вверх, а для других - методом сверху вниз. Во-вторых, если оказалось, что какой-либо метод синтаксического анализа не эффективен для некоторой грамматики, то можно построить её изменённый вариант, для которого этот метод эффективен. Большинство алгоритмов, дающих все грамматические разборы, основано на методе разбора сверху вниз. Однако алгоритмы узкого назначения для грамматик специального вида основано на методе снизу вверх. Алгоритмы синтаксического анализа, работающие по методу сверху вниз, применимы к более широкому классу грамматик, но менее эффективны. Показано, что для любой грамматики существует эквивалентная ей грамматика, такая, что для неё разбор предложения методом сверху вниз проводится ненамного медленнее, чем разбор снизу вверх для исходной грамматики. LR ( k )-грамматики. При грамматическом разборе слева направо и снизу вверх обычно на каждом шаге есть несколько подцепочек, которые можно заменить вспомогательными символами. Поэтому часто приходится перебирать большое количество вариантов. Для некоторых классов грамматик процесс перебора осуществим при помощи простой и детерминированной процедуры [4]. Один из таких классов называется классом LR ( k )-грамматик. Запись LR ( k ) означает, что при грамматическом разборе слева направо и снизу вверх достаточен просмотр цепочки вперёд на k символов. Неформально будем относить бесконтекстную грамматику G = ( VN, VT, P, S ) к LR ( k )-грамматикам, если для любой выводимой цепочки s верно следующее: s единственным способом записывается в виде β γ δ , так что существует единственный правый вывод S * Формально грамматика G относится к классу LR ( k )-грамматик, если для каждой цепочки α β x 1 x 2 (где α, β Если на предпоследнем шаге вывода получена цепочка α Ax 1 x 2 так, что
и есть некоторая другая цепочка α β x 1 x 3, такая, что
то γ = α , A = B и x = x 1 x 3. Другими словами, в правом выводе двух цепочек, у которых совпадают k символов правее места последней подстановки, в цепочках, полученных на предпоследнем шаге этого вывода, должны также совпадать k символов правее места последней подстановки. Важные свойства LR ( k )-грамматик. 1) Каждая LR ( k )-грамматика однозначна. 2) Каждый язык, порождаемый LR ( k )-грамматикой, допускается детерминированным магазинным автоматом. Такой язык называется детерминированным бесконтекстным языком. ) Каждый язык, допускаемый некоторым детерминированным магазинным автоматом, порождается LR (1)-грамматикой. Таким образом, язык принадлежит классу LR (1) тогда и только тогда, когда он принадлежит классу LR ( k ) для некоторого k. ) Если язык L 1 допускается некоторым детерминированным магазинным автоматом, то существует такая LR (0)-грамматика G, что L ( G ) = L 1 $. |
Последнее изменение этой страницы: 2020-02-16; Просмотров: 174; Нарушение авторского права страницы
 L ( Gi ) для i = 1, …, m? (2.32)
L ( Gi ) для i = 1, …, m? (2.32)
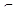 L ( Gi ) для i = 1, …, m? » может быть один только один положительный ответ, а все остальные - отрицательными. При ответе «x
L ( Gi ) для i = 1, …, m? » может быть один только один положительный ответ, а все остальные - отрицательными. При ответе «x  L ( G ), в противном случае x
L ( G ), в противном случае x  L ( G ). В принципе не важно, как мы пытаемся заполнить треугольник. Это можно делать, начиная с корня дерева (грамматический разбор сверху вниз) или снизу к вершине (разбор снизу вверх). Оба способа называются разборами слева направо, так как там, где это возможно, символы в предложении обрабатываются слева направо. Какой бы способ не использовался, отдельные шаги состоят из попыток найти правило подстановки, подходящее для рассматриваемого участка предложения. Тот факт, что приходится делать пробные попытки, которые впоследствии оказываются ошибочными, делает синтаксический анализ, вообще говоря, неэффективной процедурой. Правило подстановки выбирается только в том случае, если оно удовлетворяет некоторым априорным тестам. Например, выбираются только такие правила подстановки, которые подходят только для данного участка цепочки. Априорные тесты могут быть и более сложными. Правило подстановки может отбрасываться из-за того, что его применение приводит к большему количеству основных символов, чем содержится в исходной цепочке, либо к появлению основного символа, которого в цепочке нет. Быстрота синтаксического анализа зависит от того, насколько удаётся избежать ошибочных проб, которые и приводят к лишним затратам времени. Если порядок выбора шагов и априорные тесты таковы, что на каждом шаге применимо только одно правило подстановки, метод синтаксического анализа не может быть существенно улучшен (при условии, что проверка априорных тестов не слишком длинна). Однако если на каждом шаге есть несколько возможностей, то общее число возможных грамматических разборов растёт экспоненциально. Поэтому выбор априорных тестов и порядок действий становятся чрезвычайно важными [4].
L ( G ). В принципе не важно, как мы пытаемся заполнить треугольник. Это можно делать, начиная с корня дерева (грамматический разбор сверху вниз) или снизу к вершине (разбор снизу вверх). Оба способа называются разборами слева направо, так как там, где это возможно, символы в предложении обрабатываются слева направо. Какой бы способ не использовался, отдельные шаги состоят из попыток найти правило подстановки, подходящее для рассматриваемого участка предложения. Тот факт, что приходится делать пробные попытки, которые впоследствии оказываются ошибочными, делает синтаксический анализ, вообще говоря, неэффективной процедурой. Правило подстановки выбирается только в том случае, если оно удовлетворяет некоторым априорным тестам. Например, выбираются только такие правила подстановки, которые подходят только для данного участка цепочки. Априорные тесты могут быть и более сложными. Правило подстановки может отбрасываться из-за того, что его применение приводит к большему количеству основных символов, чем содержится в исходной цепочке, либо к появлению основного символа, которого в цепочке нет. Быстрота синтаксического анализа зависит от того, насколько удаётся избежать ошибочных проб, которые и приводят к лишним затратам времени. Если порядок выбора шагов и априорные тесты таковы, что на каждом шаге применимо только одно правило подстановки, метод синтаксического анализа не может быть существенно улучшен (при условии, что проверка априорных тестов не слишком длинна). Однако если на каждом шаге есть несколько возможностей, то общее число возможных грамматических разборов растёт экспоненциально. Поэтому выбор априорных тестов и порядок действий становятся чрезвычайно важными [4].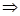 β A δ
β A δ  VN.
VN.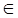 V *, и x 1, x 2
V *, и x 1, x 2  α β x 1 x 2, выполняется следующее условие.
α β x 1 x 2, выполняется следующее условие. , (2.34)
, (2.34) , (2.35)
, (2.35)