|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Выполнение операций над списковыми структурами.
Цель задания: 1. Ознакомление с возможностями представления строк символов в виде списков. 2. Закрепление навыков выполнения операций над списками. Постановка задачи: Ввести с клавиатуры строку символов, формируя из ее элементов однонаправленный список. Обработать список согласно конкретному варианту. Распечатать результат.
Содержание отчета: 1. Постановка задачи. 2. Входная строка символов. 3. Текст программы. Выходная строка символов.
Образец выполнения работы. Лабораторная работа № 15. Выполнение операций над списковыми структурами. Цель задания: 1. Ознакомление с возможностями представления строк символов в виде списков. 2. Закрепление навыков выполнения операций над списками. Постановка задачи: Ввести с клавиатуры строку символов, формируя из ее элементов однонаправленный список. Обработать список согласно конкретному варианту. Распечатать результат.
Вариант задания: Поменять местами первый символ и символ, стоящий посередине строки; {Представление строк символов в виде списков}
Program T853; Uses CRT; Type PListHead=^TList; TList=Record Sym: Char; Next: PListHead; End; Var str1, str2: String; P: PListHead; {указатель нa голову списка}
Procedure InitString; Begin WriteLn('Введите строку символов'); ReadLn(str1); End;
{формируем из строки символов однонаправленный список} Procedure ConvertStringToList; Var i: integer; Head, P1, P2: PListHead; Label Exits; Begin
P: =nil; P1: =nil; P2: =nil;
{создаем и заполняем голову списка и следующий за ней элемент} Head^.Sym: =str1[1]; New(P1); P1^.Sym: =str1[2]; Head^.Next: =P1;
{создаем и заполняем остальные элементы} For i: =3 to 255 Do Begin If Ord(str1[i])=0 Then Goto Exits; New(P2); P2^.Sym: =str1[i]; P1^.Next: =P2; P1: =P2; End;
Exits: P2^.Next: =nil; P: =Head; End;
Procedure EditList; var i, i1, i2: integer; P1, P2, P3, PMiddle, PEnd: PListHead; Begin P1: =P; i1: =-1; i2: =0;
While P1^.Next< > nil Do Begin {находим общее количество элементов(i1)} PEnd: =P1; {PEnd - предпоследний элемент} P1: =P1^.Next; {P1 - последний элемент} inc(i1); End;
i2: =i1 div 2; {порядковый номер элемента в середине списка} P2: =P;
For i: =0 to i2 Do Begin PMiddle: =P2; {PMiddle - элемент, предшествующий середине списка} P2: =P2^.Next; {P2 - середина списка} End;
{перестановка ссылок} PMiddle^.Next: =P1; PEnd^.Next: =P2; P3: =P2^.Next; P2^.Next: =P1^.Next; P1^.Next: =P3;
End;
{*************** Процедура вывода на печать списка *********************} Procedure Result; var P1: PListHead; i: integer; Begin p1: =P; i: =1;
{ формирование выходной строки } Repeat str2[0]: =Chr(i); {устанавливаем новую длину строки} str2[i]: =P1^.Sym; {присваиваем значение элементу строки} inc(i); P1: =P1^.Next; Until P1=nil;
WriteLn(' _______ Результат работы программы ___________ '); WriteLn; WriteLn('Входная строка символов: ', str1); WriteLn('Выходная строка символов: ', str2); WriteLn; End;
Begin InitString; ConvertStringToList; EditList; Result; WriteLn('Press any key...'); Repeat Until KeyPressed; End. Результат работы программы:
Варианты заданий. 1) удалить два первые символа строки; 2) удалить последние три символа строки; 3) удалить все буквы К; 4) удвоить все символы *; 5) добавить в конец строки слово END; 6) поменять местами первый и последний символы строки; 7) поменять местами первый и второй символы строки; 8) поменять местами первый и предпоследний символы строки; 9) подсчитать в строке число букв А и В, и если букв А больше, чем букв В, то удалить в строке все символы В; 10) удалить все символы, равные первому символу строки; 11) подсчитать число символов в строке, и если число нечетное, то удалить символ, стоящий посередине строки; 12) поменять местами второй и предпоследний символы строки; 13) удалить два последние символа строки;
14) удалить все символы строки, повторяющиеся более двух раз; 15) устранить дублирование символов; 16) добавить в начало строки слово BEGIN; 17) увеличить количество символов на 5; 18) подсчитать число символов в строке, и если число четное, то добавить в конец строки один символ; 19) удалить все буквы Д; 20) добавить в конец строки символ, равный первому символу строки; 21) удалить из строки символы, порядковый номер которых кратен 3; 22) удалить из строки все символы с нечетным порядковым номером; 23) удалить из строки символы с четным порядковым номером; 24) удалить из строки символы, порядковый номер которых является простым числом; 25) поменять местами первый символ и символ, стоящий посередине строки;
Деревья. Как известно, рекурсию можно эффективно использовать для определения сложных структур. Распространенным примером применения рекурсии служат деревья. Дерево определяется следующим образом: дерево с базовым типом Т - это либо: 1) пустая структура, либо 2) элемент типа Т, с которым связано конечное число деревьев с базовым типом Т, называемых поддеревьями. Отсюда видно, что список есть дерево, в котором каждая вершина имеет не более одного поддерева, поэтому список называют вырожденным деревом. Существует несколько способов изображения структуры дерева. Структура, представленная в виде графа и явно отражающая разветвления, привела к появлению термина “дерево”.

Рис. 1. Представление древовидной структуры в виде графа.
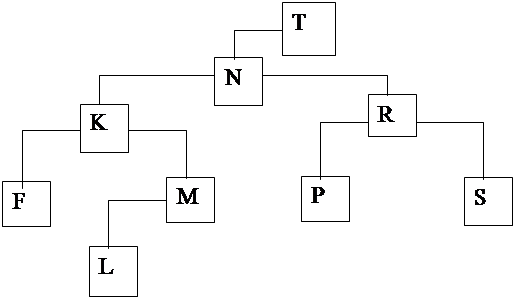
Элемент типа Т называется узлом дерева. Связи между узлами дерева называются ветвями. Дерево, являющееся частью другого дерева называется поддеревом. Самый верхний узел называется корнем ( на рис. 1 это узел А). Рассматривая пример дерева, приведенного на рисунке 1, можно также ввести понятие потомка и предка. Узел В, который находится непосредственно под узлом А, называется непосредственным потомком А. И наоборот, узел А является непосредственным предком узла В. Узел, не имеющий потомков называется терминальным узлом или листом. Узел, не являющийся листом, называется внутренним узлом. Число потомков внутреннего узла называется его степенью. Максимальная степень всех узлов есть степень дерева. Например степень дерева на рис. 1 равна 3. Упорядоченное дерево - это дерево, у которого ветви каждого узла упорядочены. Упорядоченные деревья степени 2 называются бинарными деревьями. Бинарное дерево - это упорядоченное дерево, в котором каждый узел связан не более, чем с двумя деревьями. Эти деревья называют левыми и правыми поддеревьями.
Идеально сбалансированное дерево Дерево называется идеально сбалансированным, если для каждого из узла количество узлов в левом и правом поддереве различается не более, чем на один. Что достичь максимальной высоты при данном числе узлов нужно располагать максимально возможное число узлов на всех уровнях, кроме самого нижнего. Это можно сделать очень просто, если распределить узлы поровну слева и справа от каждого узла. {построение идеально сбалансированного бинарного дерева для n -узлов} Procedure Tree (n: integer; Var p: point); Var r: point; Nl, nr: integer; Begin If n = 0 then {это лист} p: = nil Else begin Nl: = nd1v2; nr: = n – n1 – 1; {взять один узел в качестве корня} new ( r); read (r^. Data); tree (nl, left): {построить левое поддерево} tree (nr, left): {построить правое поддерево} {включить узел в дерево} p: = r end End; Обратите внимание, что узлы включаются в дерево при обратном ходе в порядке, обратном их формированию, т.е. снизу вверх (от листьев к корню). И все это достигается одим оператором р: = r.
Обход дерева Имеется много задач, которые можно выполнять на дереве; распространенная задача – выполнения заданной операции Р с каждым элементом дерева. Здесь Р рассматривается как параметр более общей задачи посещения всех узлов, или, как это обычно называют, обход дерева. При обходе дерева его узлы посещаются в определенном порядке и могут считаться расположенными линейно. Можно говорить о переходе к следующему узлу, имея ввиду некоторое упорядочение.
Рис. 2
Существует три принципа упорядочения, которые естественно вытекают из структуры дерева Рис 2. Сверху вниз: R, A, B (посетить корень, обойти левое поддерево, обойти правое поддерево). Слева направо: А, R, В (обойти левое поддерево, посетить корень, обойти правое поддерево). Снизу вверх: А, В, R (обойти левое поддерево, обойти правое поддерево, посетить корень). Обходя дерево на рис.1 и выписывая символы, находящиеся в узлах в том порядке, в котором они встречаются мы получим следующие последовательности: сверху вниз - +а*bc/d+ab слева направа a+b*c-d/a+b снизу вверх abc*dab+/- {обход дерева сверху вниз} Procedure Preorder (r: point); Begin If r< > nil then Begin P ( r ); {посетить узел r} Preorder (r^. Left); {обойти левое поддерево} Preorder (r^.Right); {обойти правое поддерево} End End;
{обход дерева слева направо} Procedure Inorder (r: point) Begin If r< > nil then Begin Inorder (r^. Left); {обойти левое поддерево} P( r ); {посетить узел} Inorder (r^. Right); {обойти правое поддерево} End End.
{обход дерева снизу вверх} Procedure Postorder (r: point) Begin If r< > nil then Begin Postorder (r^. Left); {обойти левое поддерево} Postorder(r^.Right); {обойти правое поддерево} P( r ); {посетить узел} End End. Теперь напишем процедуру которая печатает дерево, обходя его слева направо. Для этого надо просто заменить операцию Р процедурой печати. Для наиболее наглядной печати потребуем, чтобы дерево печаталось с соответствующим сдвигом, выделяющим каждый уровень узлов. {печать дерева обходя его слева направо} {вначале печатается левое поддерево, затем узел, который выделяется предшествующими l пробелами, затем правое поддерево} Procedure PrintTree (r: point; l: integer); Var i: integer; Begin If r< > nil then Begin PrintTree (r^.left, l+1); For i: =1 to l do write (‘ ‘); Writeln (r^. Data); PrintTree (r^. Right, l+1) End; End. Дерево поиска Бинарные деревья часто используются для представления множества данных, элементы которого ищутся по уникальному ключю. Если дерево организовано таким образом, что для каждого узла Р все ключи в левом поддереве меньше ключа Р, а ключи в правом поддереве больше ключа Р, то это дерево называется деревом поиска. В дереве поиска можно найти место каждого ключа, двигаясь от корня и переходя на левое или правое поддерево каждого узла в зависимости от его ключа. {инициализация дерева} Procedure IniTree (Var p: pointer; k: char); Begin New(p); p^.data: =k; p^.left: =nil; p^.right: =nil; End.
{добавить узел слева} Procedure Inleft (Var p: pointer; k: char); Var r: point; Begin New(r); p^.data: = k; r^.left: = nil; r^.right: = nil; p^.left: = r; End.
{добавить узел справа} Procedure Inright (Var p: pointer; k: char); Var r: point; Begin New(r); p^.data: = k; r^.left: = nil; r^.right: = nil; p^.right: = r; End. Для построения дерева поиска используем следующий алгоритм.Первый элемент помещаем в корень (инициализируем дерево). Далее поступаем следующим образом. Если добавленный в дерево элемент имеет ключ в больший, чем ключ узла, то, если узел не лист, обходим его справа. Если добавленный элемент имеет ключ не больший чем ключ узла, то, если узел не лист, обходим его слева. Если дошли до узла, то добавляем элемент соответственно справа или слева.
{включить элемент в дерево} Procedure Tree (Var p: pointer; k: char); Var ok: boolean; Begin Ok: false; While not ok do Begin If k> p^.data then {посмотреть направо} If p^.right < > nil {правый узел не лист} Then p: = p^. Right. {обход справа} Else begin {правый узел – лист и надо добавить к нему элемент} InRight (p, k); {и конец}; оk: = true; end; else {посмотреть налево} if p^. Left < > nil {левый узел не лист} then p: =p^.left {обход слева} else begin{левый узел –лист и надо добавить к нему элемент} Inleft(p, k); {и конец} ok: =true end end {цикла while}
end.
Поиск дерева с включением Хорошим примером использования дерева поиска является задача построения частотного словаря. В этой задаче задана последовательность слов и нужно установить число появлений каждого слова. Начиная с пустого дерева каждое слово ищется в дереве. Если оно найдено увеличивается счетчик его появлений, если нет в дерево добавляется новое слово с начальным значением счетчика, равным единице. Будем называть эту задачу поиском по дереву с включением. Процедура поиска включения запишется следующим образом. {поиск по дереву с включением} Procedure Search (Var p: point; x: integer); Begin If p = nil then {новое слово} Begin {оно добавляется в дерево} New (p), p^. Left: = nil; p^. Right: = nil; P^. Key: = x; p^. Count: = 1; End; Else if x> p^. Key then {слово ищется в правом поддереве} Search (p^. Right. x) Else if x< p^. Key then {слово ищется в левом поддереве} Search (p^. left. x) Else {слово найдено и его счетчик увеличивается на 1} P^. Count: = p^. Count + 1 End; Удаление из дерева Переходим к задаче, обратной включению, а именно удалению. Необходимо построить алгоритм для удаления узла с ключем х из дерева с упорядоченными ключами (дерево поиска). Удаление узла довольно просто если он является листом или имеет одного потомка. Например, если требуется удалить узел с ключем М надо просто заменить правую ссылку узла К на указатель на L. Трудность заключается в удалении узла с двумя потомками, поскольку мы не можем указать одним указателем на два направления.
Рис. 3 Например, если просто удалить узел с ключем N, то левый указатель узла с ключем Т должен указывать одновременно на К и R что не возможно. В этом случае удаляемый узел нужно заменить на другой узел из дерева. Возникает вопрос, каким же узлом его заменить? Этот узел должен обладать двумя свойствами: во-первых, он должен иметь не более одного потомка; во-вторых, для сохранения упорядоченности ключей, он должен иметь ключ либо не меньший, чем любой ключ левого поддерева удаляемого узла, либо не больший, чем любой ключ правого поддерева удаляемого узла. Таким свойствам обладают два узла, самый правый узел левого поддерева удаляемого узла и самый левый узел его правого поддерева. Любым из этих узлов им можно заменить удаляемый узел. Например, на рис.3 это узлы М и Р. Необходимо различать три случая: 1. Узла с ключем, равным х, нет. 2. Узел с ключем, равным х, имеет не более одного потомка. 3. Узел с ключем, равным х, имеет двух потомков
{удаление из дерева} Procedure Delete (Var p: point; x: char); Var q: point; Procedure Del (Var r: point); {процедура удаляет узел имеющий двух потомков, заменяя его на самый правый узел левого поддерева} Begin If r^. Right < > nil then {обойти дерево справа} Del (r^. Right) Else {дошли до самого правого узла} Begin {заменить этим узлом удаляемый} q^. Data: = r^. Data; q: = r; r: = r^. Left; end; End; {del} Begin {delete} If p< > nil then {искать удаляемый узел} If x< p^. Data then {искать удаляемый узел} Delete (p^. Left, x) Else if x> p^. Data {искать в правом поддереве} Delete (p^. Right, x) Else {узел найден, надо его удалить} Begin {сохранить ссылку на удаленный узел} q: = p; if q^. Right = nil then {узел имеет не более одного потомка (слева) и ссылку на узел надо заменить ссылкой на этого потомка} p: = q^. Left else if q^. Left = nil thent {узел имеет не более одного потомка (справа) и ссылку на узел надо заменить ссылкой на этого потомка} p: = p^. Right else {узел имеет двух потомков} del ( q^. Left); dispose (q); End. Вспомогательная рекурсивная процедура del вызывается только в случае, когда удаляемый узел имеет двух потомков. Она “спускается вдоль” самой правой ветви левого поддерева удаляемого узла q^ (при вызове процедуры ей передается в качестве параметра указатель на левое поддерево) и, затем, заменяет существенную информацию (в нашем случае ключ data) в q^ соответствующим значением самого правого узла r^ этого левого поддерева, после чего от r^ можно освободиться. Процедура disposi (q) освобождает память занимаемую удаляемую узлом. Если узел требуется удалить только из дерева, но оставить в памяти процедура disposi не выполняется, а переменную q надо объявить глобальной.
Стеки, очереди.
Стек - это линейный список с определенной дисциплиной обслуживания, которая заключается в том, что элементы списка всегда включаются, выбираются и удаляются с одного конца, называемого вершиной стека. Доступ к элементам здесь происходит по принципу “ последним пришел - первым ушел”(LIFO - last in first out), т. е. последний включенный в стек элемент первым из него удаляется. Стеки моделируются на основе линейного списка. Включение элемента вершины стека называется операцией проталкивания в стек, а удаление элемента из вершины стека называется операцией выталкивания из стека. Для работы со стеками необходимо иметь один основной указатель на вершину стека (Тор) и один дополнительный временный указатель (Р), который используется для выделения и освобождения памяти элементов стека. Создание стека: Исходное состояние Тon: = nil 2. Выделение памяти под первый элемент стека и внесение в него информации New (P) P^. Inf: = S P^. Link: = nil Установка вершины стека Тор на созданый элемент Тор: = Р Добавление элемента стека: 1. Выделение памяти под новый элемент New (P) 2. Внесение значения в информационное поле нового элемента и установка связи между ним и старой вершиной стека Тор P^. Inf: = Val (Val=10) P^. Link: = Top. Помещение вершины стека Тор на новый элемент Тор: = Р Удаление элемента стека Извлечение информации из информационного поля вершины стека Тор в переменную Val и установка на вершину стека вспомогательного указателя Р. Val: = Top^. Inf; P: = Top; Перемещение указателя вершины стека Тор на следующий элемент и освобождение памяти, занимаемой «старой» вершиной стека Тор: - Р^. Lin K; Pispose (P) В качестве примера приведем программу создания и удаления стека из десяти элементов: Pvogram Stack; Uses Crt Tupe TP tr = ^Telem; Telem = record Inf: Real; Link: TPtr End; Var Top: TPfr; Value: Real; Value: Byte; Procedure Push (Val: Real) Var P: TPfr; Begin New (P); P^.Inf: = Val; P^.Link: = Top Top: = P End; Procedure Top (Var Val: Real); Var P: TPtr; Begin Val: = Top^. Inf; P: = Top; Top: = P^. Link; Pispose (P) End; Begin ClrSer; {начальные установки указателей} Тор: = nil {создание стека из десяти элементов} for i: = 1 to 10 do Push (i); {удаление стека с распечаткой значений его элементов} whise Top < > nil do begin Pop (Value); Writeln (‘Value= ‘, Value = 5: 2) End; End. Очередь - это линейный список, в котором элементы включаются с одного конца, называемого хвостом, а выбираются и удаляются с другого конца, называемого вершиной. Дисциплина обслуживания очереди- “первым пришел - первым вышел” (FIFO - first in first out), т. е. первый включенный в очередь элемент первым из нее и удаляется. Очередь – это частный случай линейного односвязующего списка для которого разрешены только два действия: добавление элемента в конец очереди и удаление элемента из начала очереди. Для создания очереди и работы с ней необходимо иметь как минимум два указателя: на начало очереди (возьмем идентификатор Beg Q) на конец очереди (возьмем идентификатор End Q) Кроме того, для освобождения памяти удаляемых элементов требуется дополнительный временный указатель (Р). Создание очереди: Исходное состояние: Beg Q: = nil Eng Q: = nil Выделение памяти под первый элемент New (P) Занесение информации в первый элемент очереди Beg Q: = P Eng Q: = P Добавление элемента очереди Выделение памяти под новый элемент и занесение в него информации: New (P) P^, Inf: = 5 P^, Link: = hil Установка связи между последним элементом очереди и новым, а также перемещение указателя конца очереди End Q на новый элемент End^. Link: = P End Q: = P Удаление элемента очереди Извлечение информации из удаляемого элемента в переменную Val и установка на него вспомогательного указателя Р Val: = Beg Q^. Inf P: = Beg Q Перестановка указателя начала очередт Beg Q на следующий элемент используя значение поля Link, которое хранится в первом элементе. После этого освобождается память начального элемента очереди, используя дополнительный указатель P: Beg Q: = P^. Link Dispose (P) В качестве примера приведем программу создания и удаления очереди из десяти элементов: Prodrsm Queue; Uses Crt; Type TPtr = ^Telem; TFlem = record Inf: Real; Link: Tptr End; Var Beg Q, End Q: TP tr; Value: Real; i: Byte; Procedure AddEl (Val: Real) {создает первый и дабавляет очередной элемент в конец очереди} Var P: TPtr Begin New (P); P^. Inf: = Val; P^. Link: = nil; If End Q = n: l; {если создается первый элемент очереди} Then Beg Q: = P {если создается очередной элемент очереди} Else Eng Q^. Link: = P; End Q: = P; End; Procedure bet Del E1 (vav Val: Real) {извлечение информации из начального элемента очереди с последующим освобождением его памяти} Var P: TPtr; Begin Val: = Reg Q^. Inf; P: = Beg Q; Beg Q: = P^. Link If Beg Q = nil {если удаляется последний элемент очереди} Then Eng Q: = nil;
Dispose (P); End;
Begin ClrScr; {начальные установки указателей} Beg Q: = nil; Eng Q: = nil; {создание очереди из 10 элементов} for I: = 1 to 10 to Add E1 (i) {удаление очереди с распечаткой значений её элементов} while. Beg Q < > nil do begin Get Del E1 (Value); Writeln (‘Value=’, Value: 5: 2) End; End.
Образец выполнения работы. Лабораторная работа № 16. Популярное:
|
Последнее изменение этой страницы: 2016-03-15; Просмотров: 1267; Нарушение авторского права страницы