|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Логическая и физическая организация данных в ЭВМ
Под организацией данных понимают совокупность методов и средств представления информации в ЭВМ. Различают логическую и физическую (машинную) организации данных. Физическая организация (структура) данных отражает способы представления данных в памяти ЭВМ и методы доступа к ним. При решении данных задач рассматриваются память и представление в ней значений (ячейки, разряды ячеек, их адреса и взаимное расположение значений). Проблемы физической организации данных выделяются в самостоятельную область исследований – структуру памяти, в которой анализируются параметры технических средств (объем памяти, скорость выборки данных, способы адресации и т.п.) и возникают основные задачи по организации обмена данными между оперативной и внешней памятью ЭВМ, защите памяти, ее распределению, способам адресации и т.д. Физическое представление обычно скрыто от «внешнего наблюдателя» (например, пользователя некоторого алгоритмического языка) и может существенно различаться в разных программных системах. Логическая организация данных является абстрактным способом представления данных, не связанным с физической средой их размещения. Для простоты манипуляции с информацией в ЭВМ она для пользователей (людей, программ, устройств) представляется в абстрактном виде как логическая структура. Спроектировать логическую структуру организации данных означает определить все информационные единицы и связи между ними, задать их имена, типы данных и при необходимости их количественные характеристики. Единица поименованных данных (объект) – элемент данных (поле). Он является наименьшей (неделимой) единицей информации, имеющей смысловое значение. Например, элементом данных является число или совокупность слов (символов). Логическая организация данных в ЭВМ позволяет обеспечить запись, хранение и вызов любой требующейся для обработки информации, не вдаваясь в детальные особенности ее расположения на физических носителях. В общем случае между логической и соответствующей ей физической структурами существует различие, степень которого зависит от самой структуры и особенностей той физической среды, в которой она должна быть отражена. Например с точки зрения пользователя алгоритмического языка двумерный массив – это прямоугольная таблица, содержащая определенное число строк столбцов. Но в машинной памяти этот массив, как правило, представлен линейной последовательностью ячеек, в каждой из которых хранится значение одного элемента массива, причем элементы массива в памяти ЭВМ упорядочены по столбцам или строкам. Это означает, что в памяти в начале линейной последовательности ячеек, хранящих массив, располагаются элементы первого столбца (строки) логической структуры массива, за ним – элементы второго столбца (строки) и т.д. Вследствие различия между логической и соответствующей ей физической структурами в вычислительных системах должны существовать процедуры, осуществляющие отображение логической структуры в физическую и, наоборот, физической структуры в логическую. Эти процедуры обеспечивают доступ к физическим структурам и выполнение над ними различных операций, причем каждая операция может рассматриваться применительно к логической или физической структуре данных. Расмотрим в качестве примера наиболее распространенные в программных системах структуры данных: массивы, списки и древовидные структуры. Массив – упорядоченная совокупность однотипных элементов, адресуемых с помощью некоторого индекса. Массив может быть одномерным и многомерным. Одномерный массив (вектор) – одна из простейших структур данных, имеющаяся во всех алгоритмических языках. Элементы вектора находятся друг с другом в единственно возможном отношении – отношении непосредственного следования, что позволяет пронумеровать их последовательными целыми числами, называемыми индексами элементов. Одномерный массив (вектор) – одна из простейших структур данных, имеющаяся во всех алгоритмических языках. Элементы ветора находятся друг с другом в единственно возможном отношении – отношении непосредственного следования, что позволяет пронумеровать их последовательными целыми числами, называемыми индексами элементов. Логическая структура вектора полностью определяется числом и типом элементов вектора. При описании логической структуры вектора ему обычно присваивается имя (идентификатор), указываются минимальное и максимальное значение индекса и, возможно, размер памяти для каждого из элементов. Важнейшая операция над вектором – доступ к заданному элементу. Как только реализован доступ к элементу, над ним может быть выполнена любая операция, имеющая смысл для того типа данных, которому соответствует элемент. На логическом уровне доступ к элементу вектора осуществляется путем его идентификации, для чего достаточно указать имя вектора и значение индекса соответствующего элемента. Физическая структура вектора представляется в машинной памяти последовательностью одинаковых по длине участков памяти (ячеек), каждый из которых предназначен для хранения одного элемента массива. Физической структуре может быть поставлен в соответствие дескриптор, или заголовок, который содержит общие сведения о физической структуре (имя вектора, адрес в памяти его первого элемента (первой ячейки памяти), нижняя и верхняя границы индекса, тип элемента и т.п.). Многомерный массив. Логическая структура многомерного массива может быть представлена прямоугольной матрицей, в которой любой ее элемент может быть однозначно идентифицирован указанием пары индексов, при этом первый задает номер строки, а второй – номер столбца, на пересечении которых расположен элемент. На физическом уровне к элементу массива доступ осуществляется с помощью функции адресации, которая при известном начальном адресе массива в машинной памяти преобразует номера строки и столбца в адрес соответствующего элемента массива. В частности, если k – число элементов в каждой строке, то адрес элемента i- й строки и j – го столбца ADDR(Aij) при упорядочении элементов массива в памяти по строкам можно вычислить по формуле ADDR(Aij) = ADDR(A11) = [k(i-1)] + (j-1), где ADDR(A11) – адрес ячейки, содержащей первый элемент массива A11 для примера на рис. 5.19 а представлена логическая структура двумерного массива в виде прямоугольной матрицы с четырьмя строками и тремя столбцами, а на рис. 5.19б – его представление в памяти при упорядочении элементов массива по строкам. В данном примере адрес элемента третьей строки второго столбца может быть найден по формуле ADDR(A32) = ADDR(A11) + [3(3 – 1)] + (2 – 1) = ADDR(A11) + 7
а)
б) Рис. 5.19. Логическая структура двумерного массива 4х3 (а) и его представление в памяти с упорядочением элементов массива по строкам (б). В общем случае можно определить массив произвольной конечной размерности, в котором каждый элемент однозначно определяется конечной упорядоченной последовательностью индексов. Для массива общего вида преобразование логической структуры в физическую структуру выполняется путем процесса линеаризации, в ходе которого многомерная логическая структура массива отображается в одномерную физическую структуру, представляющую собой линейно упорядоченную последовательность элементов массива. В отличие от массивов, размер и форма которых постоянна, списки относятся к динамическим структурам, размер и форма которых могут изменяться. Списки могут быть непрерывными (последовательными) и связанными. Непрерывным (последовательным) списком называют список, у которого упорядоченность элементов задается неявно путем последовательного расположения его элементов как в логической структуре, так и в памяти машины. Одним из недостатков данной структуры является то, что при добавлении новых элементов может оказаться недостаточным объем памяти, отведенный под список, и возникает необходимость перемещения всего списка в другой блок непрерывной памяти, достаточный для размещения расширенного списка. Данного недостатка лишены связанные списки, позволяющие хранить отдельные элемента списка в различных местах памяти. У связанных списков упорядоченность элементов задается с помощью указателей, располагаемых в элементах и дающих возможность для каждого элемента списка определить следующий элемент. Таким образом элементы могут быть разбросаны по множеству незначительных по размеру блоков памяти, объединенных в единый список указателями. (рис. 5.20).
Рис. 5.20. Логическая структура односвязанного списка Частью логической структуры связанного списка является указатель начала списка, для которого отводится отдельная ячейка памяти, предназначенная для хранения адреса этого элемента. Конец связанного списка отмечается специальным нулевым указателем (NIL). Среди непрерывных (последовательных) списков широко используются стек и очередь. Стек - последовательный список с непрерывной длиной, включение и исключение элементов из которого выполняются только с одной стороны списка. Стек является структурой типа LIFO (Last – IN – First – Out – «последний пришел – первым вышел»): последний вставленный в список элемент первым удаляется из списка. Логическая структура стека представлена на рис. 5.21. Операции доступа к стеку (включение элементов и исключение элементов) осуществляются с вершины стека, причем в каждый момент для исключения доступен элемент N, находящийся на вершине стека. Вершина стека адресуется с помощью специального указателя. Для включения нового элемента в стек указатель сначала перемещается «вверх» на длину ячейки, а затем по значению указателя в стек помещается информация о новом элементе. При исключении элемента из стека сначала прочитывается информация об исключенном элементе по значению указателя, а затем указатель смещается «вниз» на одну ячейку.
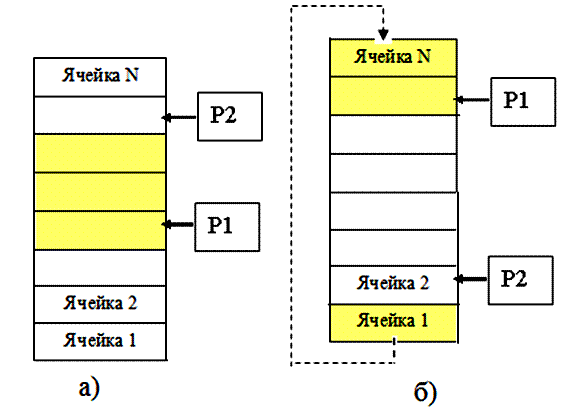
Рис. 5.21. Логическая структура стека Кроме включения и исключения элементов, над стеком производятся операции очистка стека и проверка объема стека (т.е. проверка числа элементов в стеке). Для хранения стека в памяти машины резервируется сплошная область памяти, достаточно большая, чтобы в ней мог разместиться стек при его расширении и сокращении. Физическая структура стека дополняется обычно дескриптором, в котором кроме указателя содержатся имя стека, границы физической структуры в памяти, а также описание элемента. Очередь – последовательный список переменной длины, включение элементов в который происходит с одной стороны, а исключение элементов с другой стороны списка. Очередь функционирует по принципу FIFI (First – In – First–Out – «первым пришел – первым вышел»). Та сторона очереди, с которой осуществляется добавление элементов, называется хвостом или концом очереди, другая – головой. Для индикации хвоста и головы организуются два указателя. На рис. 5.22а приведена схема простейшей очереди. Идентификаторы Р1 и Р2 – указатели, причем Р1 – указатель головного элемента очереди, а Р2 адресует первую свободную ячейку, следующую за хвостовым элементом.
Рис. 5.22. Схема простейшей очереди (а) и кольцевой очереди (б) Основные операции над очередью – включение элемента и исключение элемента. При включении новый элемент заносится в ячейку, адресуемую указателем Р2, после чего этот указатель должен быть «передвинут» к следующей (пустой) ячейке. При исключении из очереди извлекается элемент, адресуемый указателем Р1, после этого указатель Р1 перемещается к следующей ячейке. Возможны и другие операции над очередью, например проверка текущей длины и очистка. Очередь выделяет ограниченную область памяти, а включение каждого нового элемента в очередь осущетсвляется путем помещения его в память после предыдущего и соответствующей переустановки указателя конца очереди, поэтому в процессе включения элементов неизбежно наступит состояние переполнения очереди (когда указательР2 выйдет за пределы отведенной для очереди области памяти). Данный недостаток можно устранить, если после достижения указателем последней ячейки очереди перевести этот указатель на первую ячейку. Организованная таким образом очередь называется кольцевой. Пример схемы кольцевой очереди приведен на рис. 5.22б, на котором занятые ячейки закрашены. Пунктирная стрелка обозначает факт продолжения или «зацикливания» очереди. Древовидные структуры (деревья) являются частным случаем многосвязанных списков. Деревом называют сетевую структуру, характеризуемую следующими свойствами: - существует единственный элемент (узел), называемый корнем, на который не ссылается никакой другой элемент; - начиная с корня и следуя по определенной цепочке указателей, содержащих ся в элементах, можно осуществить доступ к любому элеиенту структуры; - на каждый элемент, кроме корня, имеется единственная ссылка, т. е. каждый элемент адресуется единственным указателем. Обычно дерево представляется в машинной памяти в форме многосвязанного списка, причем в каждом элементе списка отводятся следующие поля: поле данных, поле степени исхода (число дочерних вершин) и поля указателей, число которых равно степени исхода. На рис. 5.23а дан пример дерева и представление этого дерева в виде многосвязанного списка (рис.5.23б). корень дерева адресуется указателем Р. Обозначения A, B, C, D, E, F и G, записанные в первом поле каждого элемента списка, представляют собой данные о соответствующих узлах дерева.
Рис. 5.23. Пример дерева (а) и представления в виде связанного списка (б) В некоторых случаях, например в случае постоянства или редкой изменчивости структуры дерева, может использоваться и последовательное представление деревьев в памяти. Важный частный случай дерева – бинарное дерево. Бинарным деревом называется дерево, в котором каждая вершина имеет не больше двух дочерних вершин. Иными словами, в бинарном дереве степень исхода для каждого узла не превышает 2. Любое дерево может быть преобразовано в эквивалентное ему бинарное дерево, которое проще исходного дерева с точки зрения изучения, представления в памяти и обработки. Упрощение машинного представления бинарного дерева вытекает из того, что каждый элемент связного списка, соответствующего бинарному дереву, должен содержать не больше двух указателей, адресующих другие элементы списка.
Рис. 5.24. Этапы преобразования дерева, представленного на рис. 5.23а, в эквивалентное бинарное дерево Преобразование произвольного дерева с упорядоченными узлами в бинарное дерево сводится к следующим действиям. Сначала в каждом узле исходного дерева вычеркиваем все ветви, кроме самой левой ветви, которая соответствует ссылке на старшего «потомка». После этого в получившейся графе соединяем горизонтальными ветвями узлы одного уровня, имеющие общую родительскую вершину. В получившемся таким образом дереве корень левого поддерева является самым старшим потомком узла исходного дерева, а корень правого поддерева –следующим по старшенству. Результат преобразования дерева, показанного на рис. 5.23а, в бинарное дерево представлен на рис. 5.24, а на рис. 5.25 – его организация в виде связанного списка, где Р – указатель корневой вершины, NIL – пустой указатель.
Рис. 5.25. Организация бинарного дерева, представленного на рис. 5.24, в виде связанного списка Переход от произвольного дерева к эквивалентному бинарному не только облегчает анализ логической структуры, но также упрощает машинное представление, т.е. физическую структуру дерева. При представлении бинарного дерева в машинной памяти в виде связного списка каждый элемент списка содержит всего три поля, в одном из которых хранятся данные, соответствующие элементу, а в двух оставшихся полях – указатели старшего (левого) и младшего (правого) «потомков». Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 2700; Нарушение авторского права страницы