|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Форматный вывод данных (функции printf() и fprintf()).
Для вывода форматированных данных, как правило, применяются функции printf() и fprintf(). Первая записывает данные в поток stdout, а вторая — в указанный файл или поток. Аргументами функции printf() являются строка форматирования и список выводимых переменных. (В функции fprintf() первый аргумент — указатель файла.) Для каждой переменной из списка задание формата вывода осуществляется с помощью следующего синтаксиса: %[флаги][ширина][.точность][{h | l}]спецификатор В простейшем случае указывается только знак процента и спецификатор, например %f. Обязательное поле спецификатор указывает на способ интерпретации переменной: как символа, строки или числа (таблица 1). Необязательное поле флаги определяет дополнительные особенности вывода (таблица 2). Необязательное поле ширина задает минимальную ширину поля вывода. Если количество выводимых символов меньше указанного значения, поле дополняется слева или справа пробелами или нулями в зависимости от установленных флагов. Необязательное поле точность интерпретируется следующим образом: · при выводе чисел формата е, Е и f определяет количество цифр после десятичной точки (последняя цифра округляется); · при выводе чисел формата g и G определяет количество значащих цифр (по умолчанию 6); · при выводе целых чисел определяет минимальное количество цифр (если цифр недостаточно, число дополняется ведущими нулями); · при выводе строк определяет максимальное количество символов, лишние символы отбрасываются (по умолчанию строка выводится, пока не встретится символ \0). Поля ширина и точность могут быть заданы с помощью символа-заменителя *. В этом случае в списке переменных должны быть указаны их настоящие значения. Необязательные модификаторы h и l определяют размерность целочисленной переменной: h соответствует ключевому слову short, а l — long. Таблица 1. Спецификаторы типа переменной в функциях printf() и fprintf()
Таблица 2. Флаги в функциях printf() и fprintf()
Форматный ввод Форматирование вводимых данных в языке С можно осуществлять с помощью достаточно мощных функций scanf() и fscanf(), Различие между ними заключается в том, что последняя требует указания файла, из которого читаются данные. Функция scanf() принимает данные из стандартного входного потока stdin. Функция scanf(), как и ее «родственники» fscanf() и sscanf(), в качестве аргумента принимает такого же рода строку форматирования, что и функция printf(), осуществляющая вывод данных, хотя имеются и некоторые отличия. Для примера рассмотрим следующее выражение: scanf(" %2d%5s%4f", sivalue, psz, & fvalue); Данная функция считывает целое число, состоящее из двух цифр, строку из пяти символов и число с плавающей запятой, образованное не более чем четырьмя символами (2, 97, 12, 5 и т.п.). Все аргументы, перечисленные после строки форматирования, должны быть указателями, т.е. содержать адреса переменных. Другое выражение: scanf(" \" %[^А-Zа-z-] %*[-] %[^\" ]", ps1, ps2); Первым в строке форматирования стоит пробел. Он служит указанием пропустить все ведущие пробелы, символы табуляции и новой строки, пока не встретится двойная кавычка («). В строке форматирования этот символ защищен обратной косой чертой (\»), так как в противном случае он означал бы завершение самой строки. Таким образом, обратная косая черта является своего рода командой отмены специального назначения следующего за ней символа. Управляющая последовательность %[^A-Za-z-] говорит о том, что в строку рs1 нужно вводить все, кроме букв и символа дефиса (-). Квадратные скобки, в которых на первом месте стоит знак крышки (^), определяют диапазон символов, из которых не должна состоять вводимая строка. В данном случае в диапазон входят буквы от 'А' до 'Z' (дефис между ними означает «от и до») и от 'а' до 'z', а также сам дефис. Если убрать знак ^, то, наоборот, будут ожидаться только буквы и символы дефиса. В конец прочитанной строки добавляется символ \0. Если во входном потоке вслед за открывающей кавычкой первыми встретятся буква или дефис, выполнение функции scanf() завершится ошибкой и в переменные ps1 и рs2 ничего не будет записано, а сама строка останется в буфере потока. Чтение строки ps1 продолжается до тех пор, пока не встретится один из символов, указанных после знака ^. Вторая управляющая последовательность %*[-] говорит о том, что после чтения строки ps1 должна быть обнаружена группа из одного или нескольких дефисов, которые необходимо пропустить. Символ звездочки (*) указывает на то, что данные должны быть прочитаны, но не сохранены. Отметим два важных момента. Если после строки ps1 первой встретится буква, а не дефис, выполнение функции scanf() завершится ошибкой, в переменную ps2 ничего не будет записано, а сама строка останется в буфере потока. Если бы в первой управляющей последовательности символ дефиса не был отмечен как пропускаемый, функция scanf() работала бы неправильно, так как символ дефиса, являющийся «ограничителем» строки ps1, воспринимался бы как часть этой строки. В этом случае чтение было бы прекращено только после обнаружения буквы, а это, в свою очередь, привело бы к возникновению ошибки, описанной в первом пункте. Последняя управляющая последовательность %[^\»] указывает на то, что в строку ps2 нужно считывать все символы, кроме двойных кавычек, которые являются признаком завершения ввода. Для полной ясности приведем пример входной строки: " 65---ААА" Вот что будет получено в результате: *psl= 65, *ps2 = ааа. Все вышесказанное справедливо и в отношении функций fscanf() и sscanf(). Функция sscanf() работает точно так же, как и scanf(), но читает данные из указанного символьного массива, а не из потока stdin. В следующем примере показано, как с помощью функции sscanf() преобразовать строку цифр в целое число: sscanf(psz, " %d", & ivalue); Пример работы с форматным выводом /* #include < stdio.h> void main () { char с = 'А', psz[]= " Строка для экспериментов"; ivalue = 1234; /* 1 — вывод символа с */ /* 2 — вывод ASCII-кода символа с */ /* 3 — вывод символа с ASCII-кодом 90 */ /* 4 — вывод значения ivalue в восьмеричной системе */ /* 5 — вывод значения ivalue в шестнадцатеричной */ /* 6 — вывод значения ivalue в шестнадцатеричной */ /* 7 — вывод одного символа, минимальная ширина поля равна 5, */ /* 8 -- вывод одного символа, минимальная ширина поля равна 5, */ /* 9 — вывод строки, отображаются 24 символа */ /* 10 — вывод минимум 5-ти символов строки, отображаются 24 символа */ /* 11 — вывод минимум 38-ми символов строки, */ /*12 — вывод минимум 38-ми символов строки, */ /* 13 — вывод значения ivalue, по умолчанию отображаются 4 цифры */ /* 14 — вывод значения ivalueсо знаком */ /* 15 — вывод значения ivalueминимум из 3-х цифр, */ /* 16 — вывод значения ivalueминимум из 10-ти цифр, */ /* 17 — вывод значения ivalueминимум из 10-ти цифр, '*/ printf(" \n[%d]%-10d", ++iln, ivalue); /* 18 — вывод значения ivalue минимум из 10-ти цифр, */ /* выравнивание вправо с дополнением нулями */ /* 19 — вывод значения dPiс форматированием по умолчанию */ /* 20 — вывод значения dPi, минимальная ширина поля равна 20, */ /* 21 — вывод значения dPi, минимальная ширина поля равна 20, */ /* 22 — вывод значения dPi, минимальная ширина поля равна 20, */ /* 23 — вывод 19-ти символов строки, */ /* 24 — вывод первых двух символов строки */ /*'25 — вывод первых двух символов строки, минимальная ширина поля */ /* 26 — вывод первых двух символов строки, минимальная ширина поля */ /* 27 " - вывод первых шести символов строки, минимальная ширина поля */ /* 28 — вывод значения dPi, минимальная ширина поля */ /* 29 — вывод значения dPi, минимальная ширина поля */ /*' 30 — вывод, значения dPi, минимальная ширина поля */ /* 31 — вывод значения dPi, минимальная ширина поля */ /* 32 — вывод значения dPi, минимальная ширина поля */ Результат работы программы будет выглядеть следующим образом: [ 1] А [ 2] 65 [ 3] Z [ 4] 2322 [ 5] 4d2 [ 6] 4D2 [ 7] А [ 8] А [ 9] Строка для экспериментов [10] Строка для экспериментов [11] Строка для экспериментов [12]Строка для экспериментов [13]1234. [14] +1234 [15]1234 [16] 1234 [17]1234 [18] 0000001234 [19]3.141593 [20] 3.141593 [21]0000000000003.141593 [22] 3.141593 [23]Строка для эксперим [24] Ст [25] Ст [26] Ст [27] Строка [28]3.14159265 [29] 3.14 [30]3.1416 [31] 3.1416 [32] 3.14е+000 Порядок выполнения работы 1. Ознакомиться с теоретическими сведениями. 2. Получить вариант задания у преподавателя. 3. Выполнить задание. 4. Продемонстрировать выполнение работы преподавателю. 5. Оформить отчет. 6. Защитить лабораторную работу. 4. Требования к оформлению отчета Отчет по лабораторной работе должен содержать следующие разделы: · титульный лист; · цель работы: · задание на лабораторную работу; технический отчет по заданию; · ответы на контрольные вопросы; · выводы по проделанной работе. Задание на работу 1. Написать программу –базу данных, в которой в файле хранится контактная информация на людей со следующими полями: Фамилия, Телефон, Город, Улица, Дом, Квартира. В качестве разделителя полей выступает символ табуляции. Предусмотреть возможность вывода всех записей на экран, сортировку по полям Фамилия и Телефон, ввод новых записей. 2. Написать программу –базу данных, в которой в файле хранится информация об автомобилях со следующими полями: Марка, Модель, ГосНомер, Пробег, Цвет, ГодВыпуска. В качестве разделителя полей выступает символ запятой. Предусмотреть возможность вывода всех записей на экран, ввод новых записей, поиск записи по полю ГосНомер, сортировка записей по полю Пробег. 3. Написать программу –базу данных, в которой в файле хранится информация о спортсменах-футболистах со следующими полями: Фамилия, Команда, ГодРождения, ЧислоЗабитыхГолов, Лига, ЧислоМатчей. В качестве разделителя полей выступает символ тире. Предусмотреть возможность вывода всех записей на экран, ввод новых записей, поиск записи по полю Фамилия, сортировка записей по полю ЧислоМатчей. 4. Написать программу – базу данных, в которой в файле хранится информация о собаках со следующими полями: Кличка, Клуб, ГодРождения, Порода, Хозяин, ЧислоМедалей. В качестве разделителя полей выступает символ точки. Предусмотреть возможность вывода всех записей на экран, ввод новых записей, поиск записи по полю Хозяин, сортировка записей по полю ЧислоМедалей. 5. Написать программу –базу данных, в которой в файле хранится информация о компьютерах со следующими полями: ИмяКомпьютера, СетевойАдрес, ДатаОбслуживания, Процессор, ОбъемПамяти, ЧислоПоломок. В качестве разделителя полей выступает символ подчеркивания. Предусмотреть возможность вывода всех записей на экран, ввод новых записей, поиск записи по полю СетевойАдрес, сортировка записей по полю ОбъемПамяти. 6. Написать программу –базу данных, в которой в файле хранится информация о пользователях сети со следующими полями: Фамилия, СетевойАдрес, ДатаПодключения, ОбъемТрафика, ДенегНаСчету, НомерСчета. В качестве разделителя полей выступает символ пробела. Предусмотреть возможность вывода всех записей на экран, ввод новых записей, поиск записи по полю НомерСчета, сортировка записей по полю СетевойАдрес. 6. Контрольные вопросы 1. Для чего используется поле флаги в форматной строке процедуры вывода? 2. Что задает поле ширина в форматной строке процедуры вывода? 3. Какую структуру имеет форматная строка процедур ввода/вывода? 4. Что задает поле точность в форматной строке процедуры вывода? 5. Для чего используется поле спецификатор в форматной строке процедуры вывода? 6. Как с помощью процедуры fprintf() осуществить вывод на экран.
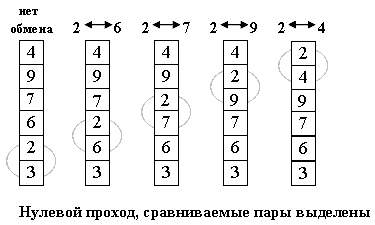
Лабораторная работа № 7. Цель работы Ознакомится с основными алгоритмами сортировки. Теоретические сведения Сортировка пузырьком Расположим массив сверху вниз, от нулевого элемента - к последнему. Идея метода: шаг сортировки состоит в проходе снизу вверх по массиву. По пути просматриваются пары соседних элементов. Если элементы некоторой пары находятся в неправильном порядке, то меняем их местами.
Рис. 7. Основная идея сортировки пузырьком После нулевого прохода по массиву «вверху» оказывается самый «легкий» элемент - отсюда аналогия с пузырьком. Следующий проход делается до второго сверху элемента, таким образом второй по величине элемент поднимается на правильную позицию.
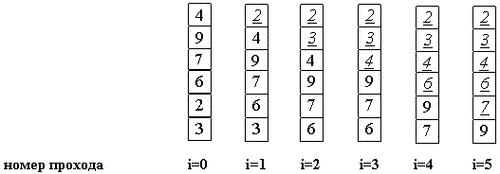
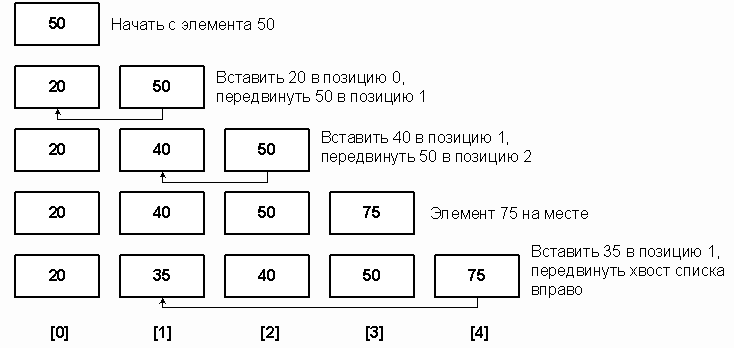
Рис. 8. Сортировка пузырьком по шагам Делаем проходы по все уменьшающейся нижней части массива до тех пор, пока в ней не останется только один элемент. На этом сортировка заканчивается, так как последовательность упорядочена по возрастанию. Среднее число сравнений и обменов имеют квадратичный порядок роста: O(n2), отсюда можно заключить, что алгоритм пузырька очень медленен и малоэффективен. Тем не менее, у него есть громадный плюс: он прост и его можно по-всякому улучшать. Чем мы сейчас и займемся. Во-первых, рассмотрим ситуацию, когда на каком-либо из проходов не произошло ни одного обмена. Это значит, что все пары расположены в правильном порядке, так что массив уже отсортирован. И продолжать процесс не имеет смысла. Итак, первое улучшение алгоритма заключается в запоминании, производился ли на данном проходе какой-либо обмен. Если нет - алгоритм заканчивает работу. Процесс улучшения можно продолжить, если запоминать не только сам факт обмена, но и индекс последнего обмена k. Действительно: все пары соседих элементов с индексами, меньшими k, уже расположены в нужном порядке. Дальнейшие проходы можно заканчивать на индексе k, вместо того чтобы двигаться до установленной заранее верхней границы i. Качественно другое улучшение алгоритма можно получить из следующего наблюдения. Хотя легкий пузырек снизу поднимется наверх за один проход, тяжелые пузырьки опускаются с минимальной скоростью: один шаг за итерацию. Так что массив 2 3 4 5 6 1 будет отсортирован за 1 проход, а сортировка последовательности 6 1 2 3 4 5 потребует 5 проходов. Чтобы избежать подобного эффекта, можно менять направление следующих один за другим проходов. Получившийся алгоритм иногда называют «шейкер-сортировкой». Насколько описанные изменения повлияли на эффективность метода? Среднее количество сравнений, хоть и уменьшилось, но остается O(n2), в то время как число обменов не поменялось вообще никак. Среднее(оно же худшее) количество операций остается квадратичным. Дополнительная память, очевидно, не требуется. Поведение усовершенствованного (но не начального) метода довольно естественное, почти отсортированный массив будет отсортирован намного быстрее случайного. Сортировка пузырьком устойчива, однако шейкер-сортировка утрачивает это качество. На практике метод пузырька, даже с улучшениями, работает, увы, слишком медленно. А потому - почти не применяется. Сортировка вставками Сортировка вставками похожа на процесс тасования карточек с именами. Регистратор заносит каждое имя на карточку, а затем упорядочивает карточки по алфавиту, вставляя карточку в верхнюю часть стопки в подходящее место. Опишем этот процесс на примере пятиэлементного списка A = 50, 20, 40, 75, 35 (рис. 9). В функцию InsertionSort передается массив A и длина списка n. Рассмотрим i-ый проход (1< i< n-1). Подсписок от A[0] до A[i-1] уже отсортирован по возрастанию. В качестве вставляемого (TARGET) выберем элемент A[i] и будем продвигать его к началу списка, сравнивая с элементами A[i-1], A[i-2] и т.д. Просмотр заканчивается на элементе A[j], который меньше или равен TARGET, или находится в начале списка (j = 0). По мере продвижения к началу списка каждый элемент сдвигается вправо (A[j] = A[j-1]). Когда подходящее место для A[i] будет найдено, этот элемент вставляется в точку j.
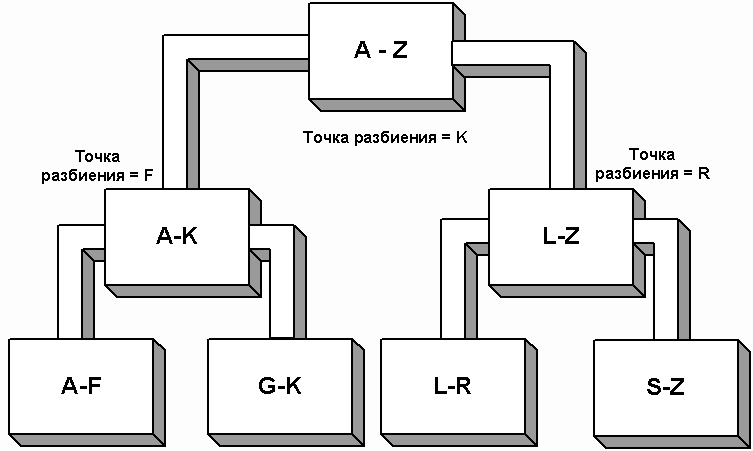
Рис. 9. Выполнение сортировки вставками Сортировка вставками требует фиксированного числа проходов. На n-1 проходах вставляются элементы от A[1] до A[n-1]. На i-ом проходе вставки производятся в подсписок A[0]–A[i] и требуют в среднем i/2 сравнений. Общее число сравнений равно 1/2 + 2/2 + 3/2 +... + (n-2)/2 + (n-1)/2 = n(n-1)/4 В отличие от других методов, сортировка вставками не использует обмены. Сложность алгоритма измеряется числом сравнений и равна O(n2). Наилучший случай – когда исходный список уже отсортирован. Тогда на i-ом проходе вставка производится в точке A[i], а общее число сравнений равно n-1, т.е. сложность составляет O(n). Наихудший случай возникает, когда список отсортирован по убыванию. Тогда каждая вставка происходит в точке A[0] и требует i сравнений. Общее число сравнений равно n(n-1)/2, т.е. сложность составляет O(n2). В принципе, алгоритм сортировки вставками можно значительно ускорить. Для этого следует не сдвигать элементы по одному, как это продемонстрировано в приведенном выше примере, а находить нужный элемент с помощью бинарного поиска, описанного в предыдущем номере (то есть, в цикле разбивая список на две равные части, пока в списке не останется один-два элемента), а для сдвижки использовать функции копирования памяти. Такой подход дает довольно высокую производительность на небольших массивах. Основным узким местом в данном случае является само копирование памяти. Пока объем копируемых данных (около половины размера массива) соизмерим с размером кэша процессора 1 уровня, производительность этого метода довольно высока. Но из-за множественных непроизводительных повторов копирования, этот способ менее предпочтителен, чем метод «быстрой» сортировки, описанный в следующем разделе. Этот же метод можно рекомендовать в случае относительно статичного массива, в который изредка производится вставка одного-двух элементов. Быстрая» сортировка Итак, мы рассмотрели алгоритм сортировки массива, имеющий сложность порядка O(n2). Алгоритмы, использующие деревья (турнирная сортировка, сортировка посредством поискового дерева), обеспечивают значительно лучшую производительность O(n log2n). Несмотря на то, что они требуют копирования массива в дерево и обратно, эти затраты покрываются за счет большей эффективности самой сортировки. Широко используемый метод пирамидальной сортировки также обрабатывает массив «на месте» и имеет эффективность O(n log2n). Однако «быстрая» сортировка, которую изобрел К.Хоар, для большинства приложений превосходит пирамидальную сортировку и является самой быстрой из известных до сих пор. Как и для большинства алгоритмов сортировки, методика «быстрой» сортировки взята из повседневного опыта. Чтобы отсортировать большую стопку алфавитных карточек по именам, можно разбить ее на две меньшие стопки относительно какой-нибудь буквы, например K. Все имена, меньшие или равные K, идут в одну стопку, а остальные – в другую.
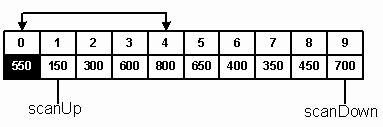
Рис. 10. Выполнение «быстрой» сортировки Затем каждая стопка снова делится на две. Например, на рис. 10 точками разбиения являются буквы F и R. Процесс разбиения на все меньшие и меньшие стопки продолжается. В алгоритме «быстрой» сортировки применяется метод разбиения с определением центрального элемента. Так как мы не можем позволить себе удовольствие разбрасывать стопки по всему столу, как при сортировке алфавитных карточек, элементы разбиваются на группы внутри массива. Рассмотрим алгоритм «быстрой» сортировки на примере, а затем обсудим технические детали. Пусть дан массив, состоящий из 10 целых чисел: A = 800, 150, 300, 600, 550, 650, 400, 350, 450, 700 Массив имеет нижнюю границу, равную 0 (low), и верхнюю границу, равную 9 (high). Его середина приходится на 4 элемент (mid). Первым центральным элементом является A[mid] = 550. Таким образом, все элементы массива A разбиваются на два подсписка: Sl и Sh. Меньший из них (Sl) будет содержать элементы, меньшие или равные центральному. Подсписок Sh будет содержать элементы большие, чем центральный. Поскольку заранее известно, что центральный элемент в конечном итоге будет последним в подсписке Sl, мы временно передвигаем его в начало массива, меняя местами с A[0] (A[low]). Это позволяет сканировать подсписок A[1]--A[9] с помощью двух индексов: scanUp и scanDown. Начальное значение scanUp соответствует индексу 1 (low+1). Эта переменная адресует элементы подсписка Sl. Переменная scanDown адресует элементы подсписка Sh и имеет начальное значение 9 (high). Целью прохода является определение элементов для каждого подсписка.
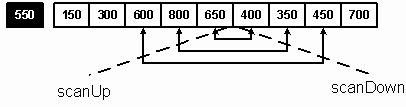
Рис. 11. Выполнение «прохода» быстрой сортировки Оригинальность «быстрой» сортировки заключается во взаимодействии двух индексов в процессе сканирования списка. Индекс scanUp перемещается вверх по списку, а scanDown – вниз. Мы продвигаем scanUp вперед и ищем элемент A[scanUp] больший, чем центральный. В этом месте сканирование останавливается, и мы готовимся переместить найденный элемент в верхний подсписок. Перед тем, как это перемещение произойдет, мы продвигаем индекс scanDown вниз по списку и находим элемент, меньший или равный центральному. Таким образом, у нас есть два элемента, которые находятся не в тех подсписках, и их можно менять местами. Swap (A[scanUp], A[scanDown]); // менять местами партнеров Этот процесс продолжается до тех пор, пока scanUp и scanDown не зайдут друг за друга (scanUp = 6, scanDown = 5). В этот момент scanDown оказывается в подсписке, элементы которого меньше или равны центральному. Мы попали в точку разбиения двух списков и указали окончательную позицию для центрального элемента. В нашем примере поменялись местами числа 600 и 450, 800 и 350, 650 и 400 (см. рис. 12).
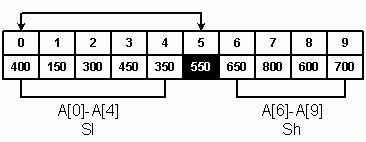
Рис. 12. Обмен элементами при выполнении Затем происходит обмен значениями центрального элемента A[0] с A[scanDown]: Swap(A[0], A[scanDown]); В результате у нас появляются два подсписка A[0] – A[5] и A[6] – A[9], причем все элементы первого подсписка меньше элементов второго, и последний элемент первого подсписка является его наибольшим элементом. Таким образом, можно считать, что после проделанных операций подсписки разделены элементом А[5] = 550. Если теперь отсортировать каждый подсписок по отдельности, то у нас получится полностью отсортированный массив. Заметьте, что по сути оба этих подсписка являются такими же массивами, как и исходный, поэтому к ним можно применить тот же самый алгоритм. Применение того же алгоритма к частям массива называется рекурсивной фазой. Одним и тем же методом обрабатываются два подсписка: Sl(A[0] – A[4]) и Sh(A[6] – A[9]). Элемент А[5] обрабатывать не надо, так как он уже находится на своем месте.
Рис. 13. Разбиение массива на части при Тот же алгоритм применяется для каждого подсписка, разбивая эти подсписки на меньшие части, пока в подсписке не останется одного элемента или пока подсписок не опустеет. Этот рекурсивный алгоритм разделяет список A[low]--A[high] по центральному элементу, который выбирается из середины списка mid = (high + low) / 2; pivot = A[mid]; После обмена местами центрального элемента с A[low], задаются начальные значения индексам scanUp = low + 1 и scanDown = high, указывающим на начало и конец списка, соответственно. Алгоритм управляет этими двумя индексами. Сначала scanUp продвигается вверх по списку, пока не превысит значение scanDown или пока не встретится элемент больший, чем центральный. while (scanUp < = scanDown & & A[scanUp] < = pivot) scanUp++; После позиционирования scanUp индекс scanDown продвигается вниз по списку, пока не встретится элемент, меньший или равный центральному. while (pivot < A[scanDown]) scanDown--; По окончании этого цикла (и при условии что scanUp < scanDown) оба индекса адресуют два элемента, находящихся не в тех подсписках. Эти элементы меняются местами. Swap(A[scanUp], A[scanDown]); Обмен элементов прекращается, когда scanDown становится меньше, чем scanUp. В этот момент scanDown указывает начало левого подсписка, который содержит меньшие или равные центральному элементы. Индекс scanDown становится центральным. Взять центральный элемент из A[low]: Swap(A[low], A[scanDown]); Для обработки подсписков используется рекурсия. После обнаружения точки разбиения мы рекурсивно вызываем QuickSort с параметрами low, mid-1 и mid+1, high. Условие останова возникает, когда в подсписке остается менее двух элементов, так как одноэлементный или пустой массив упорядочивать не нужно. Общий анализ эффективности «быстрой» сортировки достаточно труден. Будет лучше показать ее вычислительную сложность, подсчитав число сравнений при некоторых идеальных допущениях. Допустим, что n – степень двойки, n = 2k (k = log2n), а центральный элемент располагается точно посередине каждого списка и разбивает его на два подсписка примерно одинаковой длины. При первом сканировании производится n-1 сравнений. В результате создаются два подсписка размером n/2. На следующей фазе обработка каждого подсписка требует примерно n/2 сравнений. Общее число сравнений на этой фазе равно 2(n/2) = n. На следующей фазе обрабатываются четыре подсписка, что требует 4(n/4) сравнений, и т.д. В конце концов процесс разбиения прекращается после k проходов, когда получившиеся подсписки содержат по одному элементу. Общее число сравнений приблизительно равно n + 2(n/2) + 4(n/4) +... + n(n/n) = n + n +... + n = n * k = n * log2n Для списка общего вида вычислительная сложность «быстрой» сортировки равна O(n log2 n). Идеальный случай, который мы только что рассмотрели, фактически возникает тогда, когда массив уже отсортирован по возрастанию. Тогда центральный элемент попадает точно в середину каждого подсписка. Если массив отсортирован по убыванию, то на первом проходе центральный элемент обнаруживается на середине списка и меняется местами с каждым элементом как в первом, так и во втором подсписке. Результирующий список почти отсортирован, алгоритм имеет сложность порядка O(n log2n).
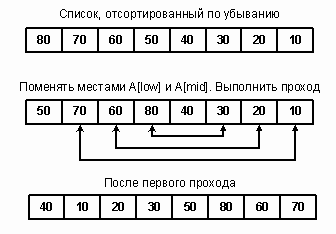
Рис. 14. Состояние массива после первого прохода «быстрой» сортировки. Наихудшим сценарием для «быстрой» сортировки будет тот, при котором центральный элемент все время попадает в одноэлементный подсписок, а все прочие элементы остаются во втором подсписке. Это происходит тогда, когда центральным всегда является наименьший элемент. Рассмотрим последовательность 3, 8, 1, 5, 9. На первом проходе производится n сравнений, а больший подсписок содержит n-1 элементов. На следующем проходе этот подсписок требует n-1 сравнений и дает подсписок из n-2 элементов и т.д. Общее число сравнений равно: n + n-1 + n-2 +... + 2 = n(n+1)/2 – 1 Сложность худшего случая равна O(n2), т.е. не лучше, чем для сортировок вставками и выбором. Однако этот случай является патологическим и маловероятен на практике. В общем, средняя производительность «быстрой» сортировки выше, чем у всех рассмотренных нами сортировок. Алгоритм QuickSort выбирается за основу в большинстве универсальных сортирующих утилит. Если вы не можете смириться с производительностью наихудшего случая, используйте пирамидальную сортировку – более устойчивый алгоритм, сложность которого равна O(n log2n) и зависит только от размера списка. Порядок выполнения работы 6. Ознакомиться с теоретическими сведениями. 7. Получить вариант задания у преподавателя. 8. Выполнить задание. 9. Продемонстрировать выполнение работы преподавателю. 10. Оформить отчет. 11. Защитить лабораторную работу. 7. 4. Требования к оформлению отчета Отчет по лабораторной работе должен содержать следующие разделы: · титульный лист; · цель работы: · задание на лабораторную работу; · ход работы; · ответы на контрольные вопросы; · выводы по проделанной работе. Задание на работу 1. Реализовать сортировку пузырьком для одномерного массива. 2. Реализовать сортировку вставками для одномерного массива. 3. Реализовать «быструю» сортировку для одномерного массива. 4. Реализовать сортировку пузырьком для двумерного массива. 5. Реализовать сортировку вставками для двумерного массива. 6. Реализовать «быструю» сортировку для двумерного массива. 9. 6. Контрольные вопросы · В чем заключается идея сортировки пузырьком? · В чем заключается идея сортировки вставками? · В чем заключается идея «быстрой» сортировки? · Какая из предложенных в работе сортировок эффективнее? Почему?
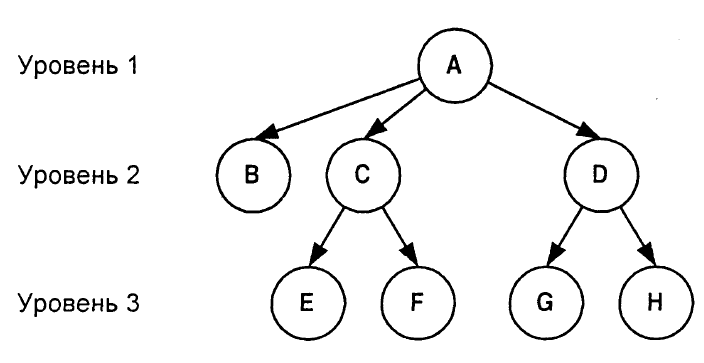
Лабораторная работа № 8. Цель работы Ознакомится с представлением данных в виде деревьев. Изучить основные алгоритмы обхода деревьев. Теоретические сведения Элементы могут образовывать и более сложную структуру, чем линейный список. Часто данные, подлежащие обработке, образуют иерархическую структуру, подобную изображенной на рис. 15, которую необходимо отобразить в памяти компьютера и, соответственно, описать в структурах данных. Каждый элемент такой структуры может содержать ссылки на элементы более низкого уровня иерархии, а может быть, и на объект, находящийся на более высоком уровне иерархии.
Рис. 15. Структура дерева Если абстрагироваться от конкретного содержания объектов, то получится математический объект, называемый деревом (точнее, корневым деревом). Корневым деревом называется множество элементов, в котором выделен один элемент, называемый корнем дерева, а все остальные элементы разбиты на несколько непересекающихся подмножеств, называемых поддеревьями исходного дерева, каждое из которых, в свою очередь, есть дерево. При представлении в памяти компьютера элементы дерева (узлы) связывают между собой таким образом, чтобы каждый узел (который согласно определению обязательно является корнем некоторого дерева или поддерева) был связан с корнями своих поддеревьев. Наиболее распространенными способами представления дерева являются следующие три (или их комбинации). Популярное:
|
Последнее изменение этой страницы: 2016-05-03; Просмотров: 1416; Нарушение авторского права страницы