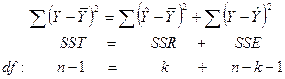|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Многомерная регрессионная модель
В простой регрессии зависимая переменная обозначалась символом Y, а независимая – X. В многомерном регрессионном анализе для обозначения независимых переменных используются символы Х с индексами, зависимая переменная по-прежнему обозначается через Y. Если начальное множество независимых переменных определено, взаимосвязь между Y и множеством переменных может быть выражена в форме многомерной регрессионной модели. В многомерной регрессионной модели математическое ожидание зависимой величины является линейной функцией всех объясняющих ее переменных.
Это выражение является многомерной регрессионной функцией генеральной совокупности. Так же, как и в случае простой линейной регрессии, мы не можем непосредственно рассматривать регрессионную функцию совокупности, поскольку наблюдаемые значения Y отклоняются от своего среднего значения. Каждая комбинация значений всех переменных X определяет математическое ожидание для части генеральной совокупности откликов Y. Предполагается, что в каждой такой части значения Y являются нормально распределенными величинами с одним и тем же стандартным отклонением При многомерной регрессии данные для каждого случая включают значение зависимой переменной Y и значение каждой независимой переменной. Зависимая переменная Y – это случайная величина, которая связана с независимыми переменными следующим соотношением.
где Для заданного набора данных оценки коэффициентов регрессии можно найти с помощью метода наименьших квадратов. Соответствующая функция регрессии будет иметь вид:
Остатки Оценки метода наименьших квадратов минимизируют сумму квадратов ошибок среди всех возможных значений
Интерпретация коэффициентов регрессии Значение Таким образом, частный или чистый коэффициент регрессии измеряет среднее изменение зависимой переменной при единичном изменении соответствующей независимой переменной и постоянных значениях других независимых переменных.
Статистический анализ модели многомерной регрессии Разложение дисперсии Статистический анализ модели многомерной регрессии проводится аналогично анализу простой линейной регрессии. Стандартные пакеты статистических программ позволяют изучить оценки по методу наименьших квадратов для параметров модели, оценки их стандартных ошибок, а также значение t-статистики, используемой для проверки значимости отдельных слагаемых регрессионной модели, и величину F-статистики, служащей для проверки значимости регрессионной зависимости. Вычисление указанных значений вручную при многомерном регрессионном анализе крайне непрактично - подобные вычисления следует проводить только с помощью компьютера.
является прогнозом, вычисленным по найденному уравнению регрессии. Форма разбиения суммы квадратов и соответствующие степени свободы здесь следующие:
Общая вариация зависимой переменной, SST, состоит из двух компонент: SSR, вариации, объясненной независимыми переменными через функцию регрессии, и SSE, необъясненной вариации. Информация из уравнения может быть получена в таблице анализа дисперсии ANOVA.
Популярное: |
Последнее изменение этой страницы: 2016-05-03; Просмотров: 637; Нарушение авторского права страницы

 .
.
 - это компонента ошибки, соответствующая отклонению значений зависимой переменной от истинного соотношения. Это ненаблюдаемая случайная величина, в которой проявляется влияние на зависимую переменную других, неучтенных факторов. Предполагается, что ошибки независимы и имеют нормальное распределение с математическим ожиданием 0 и неизвестной дисперсией
- это компонента ошибки, соответствующая отклонению значений зависимой переменной от истинного соотношения. Это ненаблюдаемая случайная величина, в которой проявляется влияние на зависимую переменную других, неучтенных факторов. Предполагается, что ошибки независимы и имеют нормальное распределение с математическим ожиданием 0 и неизвестной дисперсией 
 являются оценками компоненты ошибки и подобны остаткам в случае простой линейной регрессии. Вычисления по методу многомерного регрессионного анализа обычно проводят с помощью пакетов компьютерных программ, таких как Excel или Minitab.
являются оценками компоненты ошибки и подобны остаткам в случае простой линейной регрессии. Вычисления по методу многомерного регрессионного анализа обычно проводят с помощью пакетов компьютерных программ, таких как Excel или Minitab. :
: 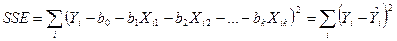
 - это свободный член в функции Y. Теперь его следует интерпретировать как значение Y при значениях всех Х, равных нулю. Коэффициенты
- это свободный член в функции Y. Теперь его следует интерпретировать как значение Y при значениях всех Х, равных нулю. Коэффициенты  называются частными или чистыми коэффициентами регрессии. Каждый из них измеряет среднее изменение величины Y при единичном изменении соответствующей независимой переменной. Однако поскольку совместное влияние всех независимых переменных на величину Y измеряется регрессионной функцией в целом, частный или чистый эффект одной переменной должен измеряться отдельно от влияния других переменных. Поэтому говорят, что коэффициент
называются частными или чистыми коэффициентами регрессии. Каждый из них измеряет среднее изменение величины Y при единичном изменении соответствующей независимой переменной. Однако поскольку совместное влияние всех независимых переменных на величину Y измеряется регрессионной функцией в целом, частный или чистый эффект одной переменной должен измеряться отдельно от влияния других переменных. Поэтому говорят, что коэффициент 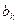 измеряет среднее изменение величины Y при единичном изменении переменной
измеряет среднее изменение величины Y при единичном изменении переменной 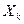 и постоянных значениях других независимых переменных.
и постоянных значениях других независимых переменных.