
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Московский государственный техническийСтр 1 из 3Следующая ⇒
Московский государственный технический университет им. Н.Э. Баумана
Просуков Е.А., Пащенко О.Б.
Работа с динамическими структурами данных
Часть 1
Ссылки, структуры, списки записей
Учебно-методическое пособие по курсу «Вычислительная техника и информационная технология»
(упрощенная версия для однонаправленных списков)
Аннотация. Методическое пособие посвящено динамическим структурам данных, которые широко используются в современной технологии программирования. В пособии при-ведены примеры, иллюстрирующие использование динамических средств языка Turbo Pascal 7.0 применительно к персональным компьютерам, а так же различные приёмы работы с динамической памятью. Примеры снабжены подробными комментариями. Предлагаемое методическое пособие требует от читателя знания основных конструкций языка Turbo Pascal 7.0. Пособие предназначено для студентов и преподавателей ВУЗов, обучающихся по специальностям, связанным с информационными технологиями, а также для широкого круга читателей, изучающих программирование на языке Turbo Pascal 7.0.
Введение Динамические структуры широко используются в задачах информационного поиска и трансляции языков программирования, что подчёркивает актуальность выбран-ной темы. Кроме того, динамические структуры и способы их использования всегда вызы-вали затруднения у студентов, изучающих программирование. В пособии изложен матери-ал, связанный с начальным изучением динамических структур данных, в частности по работе со связанными списками. Приведены многочисленные примеры с подробными комментариями, иллюстрирующими механизм распределения памяти. В первой главе даётся определение ссылочных переменных, приводятся простей-шие действия с указателями, а также показано динамическое распределение памяти в области «кучи». Во второй главе излагаются теоретические основы по списковым структурам, а также алгоритмические подходы по работе с ними. В третьей главе приведены конкретные приёмы программирования по работе со списком. В четвёртой главе предложены темы заданий для лабораторных работ. Содержание 1. Ссылки, динамические переменные и структуры. 1.1 Адресный тип-указатель, ссылочные переменные, простейшие действия с указателями. 1.2 Динамическое распределение памяти в области кучи, процедуры управления кучей, не связанные динамические данные. 1.3 Практические примеры работы с не связанными динамическими данными.
2.1 Разновидности связанных списков. 3.Приемы программирования при обработке связанных списков. 3.1 Создание и опустошение списка. 3.2 Вывод содержимого информационных полей списка. 3.3 Включение и исключение узлов. 3.3.1 Включение узла в список. 3.3.2 Исключение узла из списка. 4.Практикум по программированию с динамическими переменными на языке Turbo Pascal 7.0. 4.1 Темы заданий для лабораторных работ. Ссылки, динамические переменные и структуры. Таблица 1.2
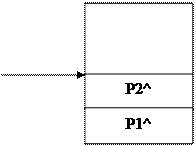
Пример анализа динамики выделения памяти в " куче": var P1, P2, P3, P4: real; P: Pointer; begin New (P1); New (P2); Mark (P); New (P3); New (P4); end. После выполнения процедур данной программы состояние " кучи" можно отобразить как показано на рис.1.3.
Рис.1.3 Процедура Mark(Р) фиксирует состояние " кучи" перед размещением динамической переменной Р3^, копируя значение текущего указателя " кучи" в указатель Р. Если дополнить в конце данную программу процедурой Release(Р), то куча будет выглядеть как показано на рис.1.4а.
 P2 P2
 P1 P1
Рис.1.4 а Рис.1.4 б При этом освобождается память, выделенная после обращения к процедуре Mark. Если же выполнить процедуру Release(HeapOrg), то " куча" будет очищена полностью, так как указатель HeapOrg содержит адрес начала кучи. В то же время, если вместо процедуры Release использовать в программе процедуру Dispose(Р3), то в середине " кучи" образуется свободное пространство (“дырка”), как показано на рис.1.4 б. Адреса и размеры свободных блоков, созданных при операциях Dispose и FrееМем, хранятся в списке свободных блоков, который увеличивается вниз, начиная со старших адресов памяти, в сегменте динамически распределяемой области. Каждый раз перед вы-делением памяти для динамической переменной, перед тем, как динамически распределя-емая область будет расширена, проверяется список свободных блоков. Если имеется блок соответствующего размера (то есть размер которого больше или равен требуемому раз-меру), то он используется. Процедура Rеlеаsе всегда очищает список свободных блоков. Таким образом, программа динамического распределения памяти " забывает" о незанятых блоках, которые могут существовать ниже указателя динамически распределяемой области. Если вы чере-дуете обращения к процедурам Маrk и Rеlеаsе с обращениями к процедурам Dispose и FrееМем, то нужно обеспечить отсутствие таких свободных блоков. Переменная FreeList модуля System указывает на первый свободный блок динами-чески распределяемой области памяти. Данный блок содержит указатель на следующий свободный блок и т.д. Последний свободный блок содержит указатель на вершину дина-мически распределяемой области (то есть адрес, заданный HeapPtr ). Если свободных блоков в списке свободных нет, то FreeList будет равно HeapPtr. Формат первых восьми байт свободного блока задается типом TFreeRec: type PFreeRec = ^TFreeRec; TFreeRec = record Next: PFreeRec; Size: Pointer; end; Поле Next указывает на следующий свободный блок, или на туже ячейку, что и HeapPtr, если блок является последним свободным блоком. В поле Size записан размер свободного блока. Значение в поле Size представляет собой не обычное 32-битовое зна-чение, а " нормализованное" значение-указатель с числом свободных параграфов (16-бай-товых блоков) в старшем слове и счетчиком свободных байт (от 0 до 15) в младшем слове. Следующая функция BlockSize преобразует значение поля Size в обычное значение типа Longint: function BlockSize(Size: Pointer): Longint; type PtrRec = record Lo, Hi: Word end; begin BlockSize: = Longint(PtrRec(Size)).Hi)*16+PtrRec(Size).Lo end; В начале свободного блока всегда имеется место для TFreePtr, в обеспечение этого подсистема управления динамически распределяемой областью памяти округляет размер каждого блока, выделенного подпрограммами New и GetMem до 8-ми байтовой границы. Таким образом, 8 байт выделяется для блоков размером 1-8 байт, 16 байт - для блоков раз-мером 9-16 и т.д. Сначала это кажется непроизводительной тратой памяти. Это в самом деле так, если бы каждый блок был размером 1 байт, но обычно блоки имеют больший размер, поэтому относительный размер неиспользуемого пространства меньше. Восьми-байтовый коэффициент раздробленности обеспечивает то, что при большом числе случайного выделения и освобождения блоков относительно небольшого размера не приводит к сильной фрагментации динамически распределяемой области. 1.3 Практические примеры работы с несвязанными динамическими данными. Пример 1. Определение адреса переменных и создание адреса. Требуется определить адрес переменных i и x и создать ссылку (организовать адрес) на место в памяти, где располагается переменная i. Program Segment; Uses crt; Var x: string; i: integer; k: ^integer; p, p1: pointer; k2: ^string; addr_p, addr_p1, addr_k2: longint; begin x: =’Вeatles’; i: =66; clrscr; p: =addr(i); p1: =@(x); {функция addr(i) или операция взятия адреса @(i) служит для ‘привязывания’ динамических переменных к статическим. Иначе говоря, выдает значение типа Pointer, т.е. ссылку на начало объекта (переменной i ) в памяти} k: =ptr(seg(p^), ofs(p^)); { seg(p^) -выдает адрес сегмента, в котором хранится объект (переменная i ); ofs(p^) -смещение в сегменте, в котором хранится объект (переменная i ); ptr -функция, противоположная addr, организует ссылку на место в памяти, определяемое сегментом и смещением (создает адрес).} р1: =addr(p1^); { addr(p1^), @p1^, seg(p1^), ofs(p1^) – возврат содержимого ссылки.} k2: =p1; {работа с адресами, адреса равны и указывают на один и тот же объект (переменную i )} addr_p: =longInt(p); {приведение адреса (ссылки) к данному целому типу, к десятичной системе счисления} addr_p1: =longInt(p1); addr_k2: =longInt(k2); writeln(‘p=’, addr_p, ’p1=’, addr_p1, ’k2=’, addr_k2); {распечатаем адреса переменной i (ссылка р) и переменной х (ссылка р1 и к2) в десятичной системе счисления} writeln(‘Адрес переменной х: сегмент’, seg(p), ’смещение’, ofs(p)); {распечатаем адрес переменной х еще раз, используя функции ofs(p): word и seg(p): word} writeln(k2^, ’ ‘, k^); {распечатаем значения самих переменных} readkey; end. {результат, выданный на печать} р=434110802 р1=434110546 к2=434110546 Адрес переменной х: сегмент 6624 смещениe 348 beatles 66 В интегрированной среде программирования Турбо Паскаль 7.0 в окне параметров Watch можно увидеть адреса переменных i и х в шестнадцатиричной системе счисления (рис.1.5).
p: Ptr($19E0, $152) p1: Ptr($19E0, $52) k2: Ptr($19E0, $52)
рис.1.5 Пример 2: Организация динамических структур, открывающих доступ к большей оперативной памяти. Требуется организовать динамическую структуру данных типа двумерный массив, работающую с базовым типом real и размером более 64килобайт оперативной памяти. Схематично структурная организация такого массива в оперативной памяти представлена на рис.1.6.
- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - -
сегмент данных. Статический массив из 298 ссылок d: ptr298
Рис.1.6 Program BIG_KUCHA; Uses crt; Type Str298=array[1..298] of real; {тип строки матрицы} Str298_ptr=^str298; {ссылка на строку матрицы} Ptr298=array[1..298] of str298_ptr; {статический массив из 298 ссылок на динамические массивы по 298 элементов типа real} var d: ptr298; i, j, k: integer; begin for i: =1 to 298 do new(d[i]); {выделение памяти в куче под вещественные строки} for i: =1 to 298 do for j: =1 to 298 do d[i]^[j]: =random*1000; {заполнение массива строк} writeln(d[1]^[1]: 6: 4, d[298]^[298]: 6: 4); for i: =1 to 298 do dispose(d[i]); {освобождение памяти в " кучe", занятой строками} readKey; end. Таким образом оперативная память, выделенная в результате такой организации, составляет: 298*298*6 байт=532824 байта=520 килобайт. Пример 3. Анализ состояния кучи. Требуется определить ресурсы памяти перед размещением динамических переменных [2]. Program Test; Type Dim=array[1..5000] of LongInt; Var p: ^Dim; {ссылка на базовый тип-массив} Psize: LongInt; Const sl=sizeof(LongInt); {размер одного элемента массива} Begin Writeln(‘В куче свободно’, MemAvail, ’байт’); {функция MemAvail выдает полный объем свободного пространства} psize: =sl*(MaxAvail div sl); {функция MaxAvail возвращает длину в байтах самого длинного свободного блока} if sizeof(Dim)> Psize then begin writeln(‘Массив р^ не может быть размещен целиком’); GetMem(p, Psize); {отводим сколько есть Psize байт} Writeln(‘Размещено’, Psize div sl, ’элементов’); End Else begin New(p); {массив размещен, места достаточно} Psize: =sizeof(Dim); {объем массива p^} End; FreeMem(p, Psize); {освобождение массива} End. Begin Null: = L.Count=0; end ; function Length(L: List): Longint; Begin Length: = L.Count; end ; Незначительные изменения способа связывания узлов списка, заключающиеся в том, что поле Следующий последнего узла содержит ссылку на первый узел списка, а поле Предыдущий первого узла содержит ссылку на последний узел списка, дают важ-ную разновидность связанных списков - циклические или кольцевые списки. Узлы кольцевого списка объявляются точно так же, как узлы линейного списка. В кольцевых списках эффективно реализуются некоторые важные операции, такие, как " очистка" списка и " расщепление" списка на подсписки. Создание пустого списка. Под пустым списком следует понимать служебную структуру данных типа запись, содержащую поля указателей на начало и конец линейного списка, а также поле-счетчик узлов этого списка. При этом поля указателей еще не содержат конкретный адрес узла начала и узла конца списка, а лишь проинициализированы безадресным значением nil. В свою очередь поле-счетчик содержит значение 0. type List= record head: PtrNode; { указатель начала списка } tail: PtrNode; { указатель конца списка } count: integer; end; Графически это можно представить как показано на рис.3.1.

Рис.3.1 Как следует из раздела 2, каждый узел однонаправленного линейного списка содержит один указатель на следующий узел. В последнем узле списка указатель на следующий узел содержит значение nil. Для реализации этих целей используем следующие структурные построения данных: type PtrStud=^student; student= record { информационная запись } name: string [20]; age: integer; group: string [10] end; PtrNode=^node; node= record info: student; next: PtrNode; и на последующие узлы списка } end; List= record head: PtrNode; tail: PtrNode; count: integer; end; Proc= procedure(x: ptrnode); Для построения списка следует выполнить итерационную процедуру связывания структурированных узлов, посредством инициализации поля next: var current: ptrnode; {указатель на текущий узел} listfile: file of student; list0: list; file_name: string; procedure create_list; begin reset(listfile); {1} new(current); {выделена память под первый узел списка} read(listfile, current^.info); {чтение из файла информации по первому студенту в узел 1} list0.count: =1; list0.head: =current; {указатель начала списка поставлен на текущий первый узел} while not eof(listfile) do begin {3} new(current^.next); {выделить память для следующего узла по адресу, записанному в поле next текущего узла} read(listfile, current^.next^.info); inc(list0.count); {5} current: =current^.next; {сделать следующий(второй) узел текущим (перемещаем указатель current на следующий узел)} end; list0.tail: =current; {указатель конца списка ставим на последний узел} current^.next: =nil; {поле next последнего узла списка принимает значение nil} close(listfile); readln; end;
На рис.3.2 графически интерпретированы действия операторов программы.
 {3} {3}
 {5} {5}
Рис.3.2 Процедуру построения списка следует дополнить процедурой инициали-зации указателей начала и конца списка и счетчика узлов. procedure init_list; begin list0.head: =nil; list0.tail: =nil; list0.count: =0; end; Московский государственный технический университет им. Н.Э. Баумана
Просуков Е.А., Пащенко О.Б.
Популярное:
|
Последнее изменение этой страницы: 2016-05-03; Просмотров: 554; Нарушение авторского права страницы
 Москва 2002
Москва 2002





 Watch
Watch


 1-ая строка из 298 ячеек по 6 байт
1-ая строка из 298 ячеек по 6 байт



 3-ья …
3-ья …
 оверлейный буфер
оверлейный буфер




 nil nil
nil nil







