
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Статистические гипотезы о значениях коэффициентов
Выше в примере мы получили
или Если действительное значение Те же соображения относятся и к другому значению Такого рода утверждения называются статистическими гипотезами (statistical hypothesis). Проверяемая гипотеза называется исходная– «нулевая» (maintained, null) гипотеза и обозначается через
Такая гипотеза отвергается (отклоняется), если значение
Из (2.2.1) мы получаем, что
и гипотеза Тогда гипотеза При выборе произвольного доверительного уровня
или, вероятность ошибки 1-го рода будет равна Процедура установления истинности статистической гипотезы Выбор значения gопределяется значимостью для исследователя исходной гипотезы Статистический критерий, как правило, основывается на использовании статистики критерия, случайной величины с известным распределением, значения которой вычисляются на основе имеющихся статистических данных. В выше проведенных вычислениях критерий проверки гипотезы
где Гипотеза Таким образом, статистический критерий задается: a. статистической гипотезой Н0; b. уровнем значимости g; c. статистикой критерия; d. критическим множеством K. Для одного и того же уровня значимости, как будет показано в дальнейшем, могут быть определены разные критические множества, что позволяет исследователю выбрать множество K наиболее эффективным образом, т.е. выбирать наиболее мощный критерий. Пакеты прикладных программ для анализа данных (в том числе и Пакет анализа EXСEL, см. п.2.5 приложение 4)основное внимание придают проверке гипотезы
в условиях множественной линейной регрессии у=a0+a1х1 +a2х2 +…+amхm+e, где погрешность eявляется нормально распределенной случайной величиной с параметрами Данная гипотеза соответствует тому предположению, что Для рассматриваемого критерия a. b. по умолчанию обычно выбирается уровень значимости c. статистика критерия определяется следующим образом
если верна гипотеза
Которая называется t-статистика (t-statistic); d) критическое множество Kимеет вид
При этом, результаты регрессионного анализа содержат: · оценку · · отношение Также сообщается: · вероятность принятия случайной величиной, имеющей распределение Стьюдента при Если найденное P-значение не больше заданного уровня значимости Если полученное P-значение больше заданного уровня значимости Если уровень значимости Если гипотеза Если же гипотеза Впрочем, статистическая значимость (или незначимость) параметров модели зависит от выбранного уровня значимости Пример 2.2. Пусть в примере 2.1 с уровнями безработицы получаем
Тогда, при заданном уровне значимости Пример2.3. Исследуя зависимость спроса на куриные окорочка от цены, получили
Получили статистически значимый коэффициент при объясняющей переменной ЦЕНА при уровне Пример2.4. Регрессионный анализ спроса на свинину на душу населения Челябинска в зависимости от цены на свинину дает значения
В этом случае коэффициент при переменной ЦЕНА получился статистически незначимым при следующих уровнях значимости Популярное:
|
Последнее изменение этой страницы: 2016-05-30; Просмотров: 860; Нарушение авторского права страницы
 – доверительный интервал для параметра
– доверительный интервал для параметра  в следующем виде
в следующем виде (2.1)
(2.1)
 . Т.е. это довольно редкое событие, имеющее вероятность
. Т.е. это довольно редкое событие, имеющее вероятность  , что дает нам право сомневаться в том, что
, что дает нам право сомневаться в том, что  , не лежащемув указанном
, не лежащемув указанном  -доверительном интервале: утверждение, что
-доверительном интервале: утверждение, что  , является маловероятным.
, является маловероятным. следующим образом:
следующим образом: 
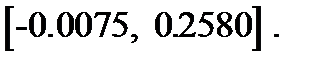

 .
. отвергается, при этом допускается «ошибка 1-го рода».
отвергается, при этом допускается «ошибка 1-го рода». , гипотеза
, гипотеза 
 , другими словами, гипотеза
, другими словами, гипотеза  .
. исследователь выбирает, если интуитивно склоняется к гипотезе
исследователь выбирает, если интуитивно склоняется к гипотезе  , исследователь не так сильно настаивает на гипотезе
, исследователь не так сильно настаивает на гипотезе  ,
,  и
и  определяются на основании данных наблюдений.
определяются на основании данных наблюдений. -статистики, по абсолютной величине превышающих значение
-статистики, по абсолютной величине превышающих значение 

 .
. -я объясняющая переменная не влияет на объясняемую переменную у, и ее можно исключить из модели.
-я объясняющая переменная не влияет на объясняемую переменную у, и ее можно исключить из модели. ;
;  равный
равный  ;
; 
 , то получаем статистику с распределением Стьюдента при
, то получаем статистику с распределением Стьюдента при 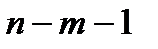 степенях свободы,
степенях свободы,  ~
~  ,
, 
 параметра
параметра  - графа Коэффициенты (Coefficient);
- графа Коэффициенты (Coefficient);  - знаменатель t-статистики – графа Стандартная ошибка (Std.Error);
- знаменатель t-статистики – графа Стандартная ошибка (Std.Error);  - графа t-статистика (t-statistic).
- графа t-статистика (t-statistic). степенях свободы, значения, большее по абсолютной величине наблюденного значения
степенях свободы, значения, большее по абсолютной величине наблюденного значения  – графа Р-значение (Р-value или Probability).
– графа Р-значение (Р-value или Probability). , то t-статистика
, то t-статистика  попадает в область непринятия гипотезы
попадает в область непринятия гипотезы  Тогда гипотеза
Тогда гипотеза  отвергается.
отвергается. , то t-статистика
, то t-статистика  не входит в область непринятия гипотезы
не входит в область непринятия гипотезы  , значит,
, значит,  Тогда гипотеза
Тогда гипотеза  принимается любое из этих двух решений.
принимается любое из этих двух решений. является статистически значимым (statistically significant); это значит, что присутствие объясняющей переменной
является статистически значимым (statistically significant); это значит, что присутствие объясняющей переменной  в модели существенно для объясняемой переменной.
в модели существенно для объясняемой переменной. . Следовательно, можно не включать эту переменную в модель регрессии.
. Следовательно, можно не включать эту переменную в модель регрессии. .
. и следующие данные:
и следующие данные:  получаем коэффициент при переменной СЗ статистически незначимым. Если взять
получаем коэффициент при переменной СЗ статистически незначимым. Если взять  , то
, то  -значение получается меньше уровня значимости, и тогда коэффициент при переменной СЗ получается статистически значимым.
-значение получается меньше уровня значимости, и тогда коэффициент при переменной СЗ получается статистически значимым. и следующие данные:
и следующие данные:  , так что ЦЕНА в данном примере получилась существенная объясняющая переменная.
, так что ЦЕНА в данном примере получилась существенная объясняющая переменная. и следующие значения параметров:
и следующие значения параметров:  .
.