
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Методы автоматического рубрицирования, основанные на знаниях ⇐ ПредыдущаяСтр 2 из 2
В системах, реализующих данный подход, используются заранее сформированные базы знаний, в которых описываются языковые выражения, соответствующие той или иной рубрике, правила выбора между рубриками. Процесс создания подобных систем часто сравнивают с созданием экспертных систем для диагностики и классификации. Наибольшее распространение среди данных методов получили две модели представления знаний: модель семантической сети (см. [18]) и продукционная модель (см. [17]). В первом случае знания о предметной области описываются независимо от рубрикатора в специального вида тезаурусе, который связывается с одним или более рубрикаторами гибкой системой отношений. Под тезаурусом понимается иерархическая сеть понятий и отношений между ними. Тезаурус может быть разработан независимо от какой-либо системы рубрицирования. В нем могут быть накоплены разнообразные варианты представления в тексте понятий предметной области (дескрипторов). В качестве вариантов (синонимов или эквивалентов) дескрипторов в тезаурусе встречаются именные и глагольные группы, отдельные существительные, прилагательные или глаголы. Тезаурус может быть разработан в полуавтоматическом режиме. Например, сначала обрабатывается совокупность документов большого объема при помощи программ морфологического и синтаксического анализа с целью выделения терминоподобных групп слов. Затем выбранные группы слов исследуются экспертами и принимается решение относительно того: · может ли данная группа слов быть включена в тезаурус (в этом случае она становится термином); · является ли данный термин дескриптором или синонимом другого дескриптора; · как должны быть описаны отношения данного термина. Кроме того, в комплекс знаний могут также быть включены дополнительные базы данных, например: географическая база данных, содержащая описания географических объектов, база данных организаций, персоналий и т.д. Тезаурус и базы данных имеют одну структуру и состоят из следующих частей: 1. Дескрипторов, которые соответствуют понятиям или конкретным объектам. Обычно дескриптором является существительное или именная группа. 2. Каждый дескриптор имеет совокупность текстовых входов или синонимов. Текстовый вход может быть существительным, прилагательным или группой существительного. Одно слово может быть синонимом различных дескрипторов. Устранение смысловой неоднозначности производится во время автоматического обработки документа. 3. Отношения между дескрипторами внутри каждой базы данных, например: · более широкий термин (выше); · более узкий термин (ниже); · связанный термин (ассоциация); · целое для термина (часть); · часть для термина (целое). 4. Отношения между дескрипторами различных баз данных. В данном случае добавляется отношение – “равенство термина”, которое появляется, когда базы данных содержат дескрипторы, соответствующие одному понятию или объекту. Дескриптор D1 находится в дескрипторной среде дескриптора D, если между D1 и D существует дескрипторное отношение или существует транзитивная зависимость. Дескриптор D называют главным дескриптором среды. Иерархическая организованность тезауруса и наличие тезаурусных связей позволяет использовать понятия среды дескрипторов и главных дескриптор (опорных дескрипторов) среды для формирования дескрипторных кустов, и« пользуемых при автоматическом рубрицировании текстов в данной технологии. В целом же комплекс знаний представляет собой иерархическую сеть, полнота и целостность которой поддерживается и отслеживается экспертами. Существует два типа представления рубрик последовательностью опорных дескрипторов в виде булевских нормальных форм: · дизъюнкция опорных дескрипторов D, v D2 v... v Dn; · конъюнкция дизъюнкций опорных дескрипторов (D11 v D12 v…v D1n) & … & (Dm1 v Dm2 v … v Dmk). Для каждой рубрики рубрикатора может быть выбран свой тип представления! После того как для всех рубрик рубрикатора установлены связи с соответствующими опорными дескрипторами, автоматически определяются рубрик для всех дескрипторов тезауруса. Таким образом, для каждого дескриптора создается список соответствующих рубрик с указанием того, в какую из дизъюнкций рубрики входит данный дескриптор. Каждая рубрика в данной технологии фиксирует запрос пользователя, который описывается посредством дескрипторов тезауруса. При этом в тезаурусе находится куст дескрипторов, соответствующий данной рубрике, и устанавливается связь между рубрикой и наивысшим дескриптором (опорный дескриптор рубрики) в иерархии дескрипторного куста. Одной рубрике может соответствовать несколько опорных дескрипторов. Дальнейшее развитие данной технологии состоит в предоставлении пользователю возможности описывать рубрику на ЕЯ. Суть процесса рубрицирования в рамках данного подхода состоит в выделении из текста опорных дескрипторов и отношений между ними с последующим сопоставлением их с описаниями рубрик. Представленная технология автоматического рубрицирования текстов позволяет классифицировать различные типы текстовой информации, быстро настраиваться на различные рубрикаторы и типы документов. Но и имеет существенные ограничения в своем использовании, так как трудоемкость разработки тезауруса достаточно высока и требует больших временных затрат (от нескольких месяцев до нескольких лет), кроме того, формирование тезауруса производится в соответствии с той или иной предметной областью, что делает невозможным использование одного тезауруса при классификации текстов из различных предметных областей. Основу методов, использующих продукционную модель представления знаний, составляет выделение из текста концепций (или понятий), заранее описанных экспертом. Каждое понятие предметной области описываются экспертом при помощи особой конструкции - определения понятия, объединяющего в себе набор характерных для данного понятия слов и фраз. Определение понятия представляет собой выражение, записанное на специальном языке, позволяющем объединять эти слова и фразы при помощи стандартных булевых функций. В определении понятия при записи слов и фраз допускается использование символов-шаблонов (&, * и т.д.), что позволяет отказаться от процедуры морфологического анализа, используемой для нормализации лексики документа. Поскольку описание понятий производится экспертом вручную, то это не доставляет особых неудобств, зато позволяет значительно повысить производительность. В Дополнение к этим функциям в языке определения понятий может быть предусмотрена возможность введения контекстуальных ограничений, заключающаяся в указании порядка следования слов в тексте, расстояния между словами и т.д. Кроме того, фразам в определении понятия могут быть назначены экспертные веса, показывающие, насколько каждая из фраз характерна для данного понятия. Ниже приведен пример определения понятия золото:
(gold (& n (reserve! medal! Jewelry)))
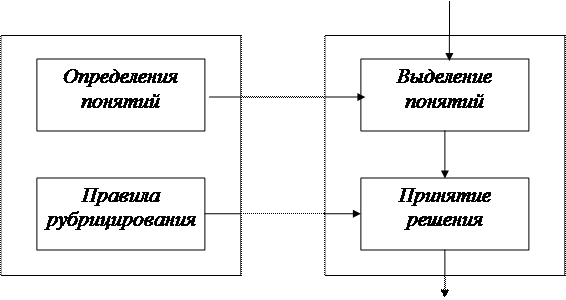
Процесс рубрицирования разбивается на два этапа. Первым из них является выделение понятий из текста, которое можно представить как процесс распознавания, основывающийся на использовании данных из базы определен Решение о наличии понятия в тексте принимается путем вычисления справедливости выражения, определяющего понятие, относительно данного текста. Если выражение справедливо, то считается, что понятие присутствует в тексте. Кроме того, если в определении понятия присутствуют экспертные веса, вычисляется вес или вероятность появления данного понятия в обрабатываемом тексте с учетом частоты встречаемости фраз в тексте сообщения. На втором этапе принимается решение о принадлежности текста конкретной рубрике. На его вход поступают выделенные на первом этапе из текста понятия, с возможными весами. Решение принимается на основе правил рубрицирования, которые, так же как и определения понятий, формулируются эк пертом заранее с использованием языка правил. Выражения, записанные на языке правил, схожи с конструкцией if-then алгоритмических языках программирования.
(if test: (or [auctralian-dollar-concept] (and [dollar-concept] [auctralian-concept] (not [us-dollar-concept] ) (not [us-dollar-concept] ) ... )) action: (asssign-auctralian-dollar-category) )
Язык правил позволяет основывать решения на комбинации понятий, пс. явившихся в тексте. Кроме того, он позволяет учесть вероятность появления, а также положение каждого понятия в тексте. Существует также возможное учета длины сообщения. Совокупность определений понятий и правил рубрицирования составляв базу правил, (см. рис. 4.3) Разработка базы правил представляет собой очень трудоемкий процесс, требующий привлечения высоко квалифицированных специалистов как в предметной < ласта, так и в области инженерии знаний. Суть этого процесса заключается в с более большего массива отрубрицированных документов, в ходе которого для: дои из рубрик выявляются статистические закономерности, основанные на частоте. встречаемости слов и фраз, а также совместной частоте встречаемости отдельных 1 них. Полученные данные затем используются экспертами при выявлении характерных слов и фраз для описания понятий и формирования правил рубрицирования.
Рис. 4.3. Процесс рубрицирования
Преимуществами данного подхода являются высокое качество рубрицирования и высокое быстродействие на тех текстовых потоках, для которых они проектировались. Основными недостатками подобных систем являются, как и в предыдущем случае: · высокая трудоемкость и значительные затраты, необходимые для разработки системы; · жесткая привязка баз знаний и алгоритмов к предметной области, конкретному рубрикатору, а также размеру и формату рубрицируемых текстов. Большинство же систем автоматического рубрицирования текстов требуют более быстрого и дешевого построения. 4.4.3.2. Методы, основанные на обучении по примерам Системы автоматического рубрицирования, основанные на обучении по примерам, рассматривают в качестве понятий, которым нужно обучиться, рубрики. Машинное обучение производится на основе примеров текстов, которые были заранее отрубрицированы экспертом вручную. Можно выделить статистические и нейросетевые методы рубрицирования. Идея статистического рубрицирования состоит в определении степени соответствия терминологического портрета документа и терминологического портрета рубрик на основе статистических характеристик субъектов сравнения. Под терминологическим портретом документа понимают совокупность наиболее важных терминов, содержащихся в тексте документа. В качестве показателя важности термина в документе чаще всего используется частота его встречаемости. Под терминологическим портретом рубрики понимается на наиболее характерных для этой рубрики терминов с их весами (в работах статистическим моделям рубрицирования под терминологическим портретом рубрики часто понимается множество ее характеристических терминов и частоты их встречаемости в рубрике). Таким образом, семантика рубрики задается однозначно только ее терминологическим портретом. Отметим, что терминологический портрет можно рассматривать как частный случай тезауруса, имеющего более простую модель и допускающего его автоматическое построение и корректировку. Формирование терминологических портретов каждой рубрики произвол экспертом не вручную, а с помощью одной из технологий обучения рубрикатора. При этом роль эксперта сводится к формированию для каждой рубрики обучающей выборки - совокупности максимально коротких фрагментов текст содержащих полное и минимально избыточное лингвистическое наполнение одной обучаемой рубрики. Выделение характеристических терминов для рубрики производится автоматически, на основе их весов, которые могут быть получены в процессе анализа обучающей выборки. Например,
W tr = log Nr / df tr,
где Nr - количество документов в обучающей выборке, принадлежали рубрике r, df tr-количество документов в обучающей выборке, принадлежащий рубрике r и содержащих термин t. Список характеристических терминов рубрики упорядочен по убыванию весов терминов в ней. Таким образом, единую модель для всех рубрик одного рубрикатора можно представить в виде двухмерной матрицы весов {wtk}. Рубрицирование выполняется по некоторому решающему правилу, учитывающему как важность терминов в документе, так и их веса для рубрик. Например, можно считать, что документ принадлежит рубрике r, если
Σ tf t w tr > kr, t где tft- частота встречаемости термина t в документе, kr - пороговое значение для рубрики r. Значение левой части указанного выражения может использоваться в качестве количественной оценки релевантности документов рубрикам. Пороговые значения для каждой из рубрик определяются таким образом, чтобы при применении решающего правила ко всей обучающей выборке к данной рубрике было отнесено максимальное количество релевантных и минимальное количество не релевантных ей текстов. Вычисление может производиться как при помощи различных математических методов, так и эмпирическим путем. К достоинствам такого подхода относятся: · простота определения семантики рубрики, что дает возможность организовать автоматическое обучение рубрик; · универсальность подхода, заключающаяся в том, что таким способом может быть определена семантика очень широкого класса рубрик из любой предметной области; · наличие аппарата количественной оценки релевантности документов рубрикам; · высокое быстродействие. Главным недостатком данной группы методов является более низкое по сравнению с методами, основанными на знаниях, качество рубрицирования. Основой нейросетевых методов рубрицирования текстов является использование нейронной сети (НС) в качестве обучаемого классификатора. Считается, что в наличии имеется подборка примеров текстов, каждый из которых помечен как релевантный или нерелевантный определенной рубрике. Задача НС, обученной на этих примерах, состоит в определении степени релевантности любого нового текста данной рубрике. Данный подход предполагает, что семантика рубрики однозначно задается примерами принадлежащих ей текстов. Поскольку НС оперирует векторами, для представления текста используется одна из векторных моделей, например [19]:
(t1,..., tD): ti =
di - лексическая единица из словаря; T - текст, рассматриваемый как неупорядоченное множество лексических единиц;
Поскольку обучающая выборка состоит из примеров с заранее известной принадлежностью текстов рубрикам, то имеет смысл использовать НС, в которых реализована парадигма обучения с учителем. Так, в [19] предлагается использовать вероятностную нейросеть (ВНС). НС имеет В входов и 2 выхода, один из которых отражает вероятность принадлежности предъявляемого текста к классу релевантных запросу текстов (Ррел), другой - к классу нерелевантных. На практике имеет смысл использовать лишь первый, поскольку сумма значений на выходах равна 1. Схематично описываемый процесс представлен на рис. 4.4 и рис. 4.5.
Рис. 4.5. Определение вероятности релевантности текста рубрике Словарь рубрики могут составлять как простые, так и составные термины. Его формирование производится так же, как и в статистических методах, с лишь разницей, что веса терминов в дальнейшем не используются. По качеству рубрицирования нейросетевые методы рубрицирования занимают среднее положение между статистическими методами и методами, основанными на знаниях. К основным недостаткам нейронных сетей чаще всего относят два факта: 1. Экспертам непонятно, как нейронная сеть работает. 2. На обучение сети требуется очень много времени. Однако, ВНС выгодно отличается тем, что имеет: 1. строгое математическое обоснование (по сути ВНС представляет собой оптимальный по Байесу классификатор); 2. огромное (в тысячи раз большее) по сравнению с другими нейросетевыми парадигмами быстродействие. Кроме того, характер решаемой задачи позволяет существенно оптимизировать ВНС, а также устранить зависимость объема вычислений от мощности словаря [19]. Этот факт позволяет полностью отказаться от усечения словаря, опасного тем, что в ходе его могут быть отброшены существенные для классификации термины. В целом, выбор данной нейросетевой парадигмы позволяет свести к минимуму указанные недостатки.
4.5. Поиск текстовой информации Популярное:
|
Последнее изменение этой страницы: 2017-03-11; Просмотров: 635; Нарушение авторского права страницы

 V di T
V di T
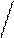
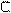

 0 di T, i=1, D, a v=1/√ N
0 di T, i=1, D, a v=1/√ N
 N - количество di Т.
N - количество di Т.

