
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Доверительный интервал для оценки мат.ожидания нормального распределения ⇐ ПредыдущаяСтр 5 из 5
Пусть CВ Х распределена нормально т. е. ген. с-ть – нормально распределенная CВ с переменными: В нашем случае: (Если отбор бесповторный, то мера точности D имеет вид: D=
31. Понятие корреляционной зависимости. Корреляционная таблица. Линейная корреляция Если изменение одной из случайных величин влечет изменение среднего другой случайной величины, то стат.зависимость называют корреляционной. Сами случайные величины, связанные коррреляционной зависимостью, оказываются коррелированными. Корреляционную зависимость Y от X можно описать с помощью уравнения вида: yx=f(x) (1) где yx - условное среднее величины Y, соответствующее значению x величины X, а f(x) некоторая функция. Уравнение (1) называется выборочным уравнением регрессии Y на X. Функцию f(x) называют выборочной регрессией Y на X, а ее график – выборочной линией регрессии Y на X. Совершенно аналогично выборочным уравнением регрессии X на Y является уравнение: xy=φ (y) Пусть величина Х в выборке принимает значения x1, x2,....xm, где количество различающихся между собой значений этой величины, причем в общем случае каждое из них в выборке может повторяться. Пусть величина Y в выборке принимает значения y1, y2,....yk, где k - количество различающихся между собой значений этой величины, причем в общем случае каждое из них в выборке также может повторяться. В этом случае данные заносят в таблицу с учетом частот встречаемости. Такую табл. с группированными данными называют корреляц-ой. Если две случайные величины Х и Y имеют в отношении друг друга линейные функции регрессии, то говорят, что величины Х и Y связаны линейной корреляционной зависимостью.
32. Метод наименьших квадратов для определения параметров линейной регрессии Выбрав вид функции регрессии, т.е. вид рассматриваемой модели зависимости Y от Х (или Х от У), напр/, линейную модель yx=a+bx, необходимо определить конкретные значения коэффиц. модели. При различных значениях а и b можно построить бесконечное число зависимостей вида yx=a+bx т.е на координатной плоскости имеется бесконечное количество прямых, нам же необходима такая зависимость, которая соответствует наблюдаемым значениям наилучшим образом. Таким образом, задача сводится к подбору наилучших коэффициентов. Линейную функцию a+bx ищем, исходя лишь из некоторого количества имеющихся наблюдений. Для нахождения функции с наилучшим соответствием наблюдаемым значениям используем метод наименьших квадратов. Обозначим: Yi - значение, вычисленное по уравнению Yi=a+bxi. yi - измеренное значение, ε i=yi-Yi - разность между измеренными и вычисленными по уравнению значениям, ε i=yi-a-bxi. В методе наименьших квадратов требуется, чтобы ε i, разность между измеренными yi и вычисленными по уравнению значениям Yi, была минимальной. Следовательно, находим коэффициенты а и b так, чтобы сумма квадратов отклонений наблюдаемых значений от значений на прямой линии регрессии оказалась наименьшей:
Исследуя на экстремум эту функцию аргументов а и с помощью производных, можно доказать, что функция принимает минимальное значение, если коэффициенты а и b являются решениями системы:
Если разделить обе части нормальных уравнений на n, то получим:
Учитывая, что Получим
При этом b называют коэффициентом регрессии; a называют свободным членом уравнения регрессии и вычисляют по формуле: Полученная прямая является оценкой для теоретической линии регрессии. Имеем:
Статистическая гипотеза. Основные понятия Статистической называют гипотезу о виде неизвестного распределения, или о параметрах известных распределений. Нулевой (основной) называют выдвинутую гипотезу Н0. Конкурирующей (альтернативной) называют гипотезу Н1, которая противоречит нулевой. Гипотезы относ-но параметров распределения наз. параметрическими. Гипотезы бывают простые и сложные. Простая – гипотеза, содержащая только одно предположение. Сложная – гипотеза, которая состоит из конечного или бесконечного числа простых гипотез. Стат. критерием (значимости) наз. СВ X, кот. является ф-цией выборки K=К(х1, х2, х3, …, хn) (статистической) и служит для проверки гипотезы, с ее помощью принимается решение о принятии или отвержении гипотезы Н0. Критическая область – совокупность значений критерия, при которых нулевую гипотезу отвергают. Область принятия гипотезы (область допустимых значений) – совок-ть значений критерия, при кот. гипотезу принимают. |
Последнее изменение этой страницы: 2017-03-14; Просмотров: 268; Нарушение авторского права страницы
 и
и 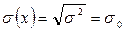 . Для нормальной СВ Х с переменными a и s имеет место ф-ла вер-ти отклонения нормальной СВ:
. Для нормальной СВ Х с переменными a и s имеет место ф-ла вер-ти отклонения нормальной СВ:  .
.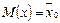 , e=D> 0, s(х)=
, e=D> 0, s(х)=  , СВ Х=
, СВ Х= 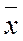 . Тогда получаем
. Тогда получаем  . Зададим доверительную вероятность g, тогда
. Зададим доверительную вероятность g, тогда 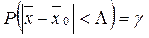 . Это вероятность того, что выборочная характеристика
. Это вероятность того, что выборочная характеристика  отличается от ген средней
отличается от ген средней  по абсолютной величине меньше чем на D, тогда имеем:
по абсолютной величине меньше чем на D, тогда имеем:  → ty=
→ ty= 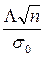 . Рассмотрим D=
. Рассмотрим D=  - точность оценки (предельная ошибка выборки). Получим интервал:
- точность оценки (предельная ошибка выборки). Получим интервал:  на этом интервале с надежностью(доверит вероятностью) g находится неизвестная вероятная средняя
на этом интервале с надежностью(доверит вероятностью) g находится неизвестная вероятная средняя 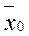 Примечание: если s0 неизвестна, ее заменяют приближенно исправленной стат дисперсией
Примечание: если s0 неизвестна, ее заменяют приближенно исправленной стат дисперсией 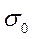 »S
»S )
)



 , отсюда
, отсюда 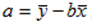 , подставляя значение a в первое уравнение, получим:
, подставляя значение a в первое уравнение, получим: 

