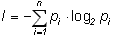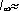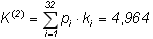|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Кодирование информации с использованием циклических и самосинхронизирующихся кодов
Цель – изучить принципы экономичного кодирования символьной информации. 1. научиться вычислять избыточность кодирования информации; 2. изучить способы построения неравномерных двоичных кодов с разделителями знака, слова; 3. изучить префиксные коды (условие Фано); 4. научиться использовать метод префиксного двоичного кодирования Хаффмана. Теоретическая часть Сообщение есть последовательность знаков алфавита. При их передаче возникает проблема распознавания знака: каким образом прочитать сообщение, т.е. по полученным сигналам установить исходную последовательность знаков первичного алфавита. В устной речи это достигается использованием различных фонем (основных звуков разного звучания), по которым мы и отличает знаки речи. В письменности это достигается различным начертанием букв и дальнейшим нашим анализом написанного. Появление конкретного знака (буквы) в конкретном месте сообщения - событие случайное. Следовательно, узнавание (отождествление) знака требует получения некоторой порции информации. Можно связать эту информацию с самим знаком и считать, что знак несет в себе (содержит) некоторое количество информации. Попробуем оценить это количество. Начнем с самого грубого приближения (будем называть его нулевым, что отражается индексом у получаемых величин) - предположим, что появление всех знаков (букв) алфавита в сообщении равновероятно. Тогда для английского алфавита ne=27 (с учетом пробела как самостоятельного знака); для русского алфавита nr=34. Из формулы Хартли находим:
Получается, что в нулевом приближении со знаком русского алфавита в среднем связано больше информации, чем со знаком английского. Например, в русской букве «а» информации больше, чем в «a» английской! С точки зрения техники это означает, что сообщения из равного количества символов будут иметь разную длину (и соответственно, время передачи) и большими они окажутся у сообщений на русском языке. В качестве следующего (первого) приближения, уточняющего исходное, попробуем учесть то обстоятельство, что относительная частота, т.е. вероятность появления различных букв в тексте (или сообщении) различна. Рассмотрим таблицу средних частот букв для русского алфавита, в который включен также знак «пробел» для разделения слов с учетом неразличимости букв «е» и «ë », а также «ь» и «ъ» (так принято в телеграфном кодировании), получим алфавит из 32 знаков со следующими вероятностями их появления в русских текстах:
Оценим информацию, связанной с выбором одного знака алфавита с учетом неравной вероятности их появления в сообщении (текстах). Если pi - вероятность (относительная частота) знака номер i данного алфавита из N знаков, то среднее количество информации, приходящейся на один знак, равно:
Это и есть знаменитая формула К.Шеннона, с работы которого «Математическая теория связи» (1948) принято начинать отсчет возраста информатики, как самостоятельной науки. Применение формулы Шеннона к алфавиту русского языка дает значение средней информации на знак I1(r) = 4, 36 бит, а для английского языка I1(e) = 4, 04 бит, для французского I1(l) = 3, 96 бит, для немецкого I1(d) = 4, 10 бит, для испанского I1(s) = 3, 98 бит. Как мы видим, и для русского, и для английского языков учет вероятностей появления букв в сообщениях приводит к уменьшению среднего информационного содержания буквы. Несовпадение значений средней информации для английского, французского и немецкого языков, основанных на одном алфавите, связано с тем, что частоты появления одинаковых букв в них различаются. В рассматриваемом приближении по умолчанию предполагается, что вероятность появления любого знака в любом месте сообщения остается одинаковой и не зависит от того, какие знаки или их сочетания предшествуют данному. Такие сообщения называются шенноновскими (или сообщениями без памяти). Сообщения, в которых вероятность появления каждого отдельного знака не меняется со временем, называются шенноновскими, а порождающий их отправитель - шенноновским источником. Если сообщение является шенноновским, то набор знаков (алфавит) и вероятности их появления в сообщении могут считаться известными заранее. В этом случае, с одной стороны, можно предложить оптимальные способы кодирования, уменьшающие суммарную длину сообщения при передаче по каналу связи. С другой стороны, интерпретация сообщения, представляющего собой последовательность сигналов, сводится к задаче распознавания знака, т.е. выявлению, какой именно знак находится в данном месте сообщения. А такая задача, как мы уже убедились в предыдущем параграфе, может быть решена серией парных выборов. При этом количество информации, содержащееся в знаке, служит мерой затрат по его выявлению. Последующие (второе и далее) приближения при оценке значения информации, приходящейся на знак алфавита, строятся путем учета корреляций, т.е. связей между буквами в словах. Дело в том, что в словах буквы появляются не в любых сочетаниях; это понижает неопределенность угадывания следующей буквы после нескольких, например, в русском языке нет слов, в которых встречается сочетание щц или фъ. И напротив, после некоторых сочетаний можно с большей определенностью, чем чистый случай, судить о появлении следующей буквы, например, после распространенного сочетания пр- всегда следует гласная буква, а их в русском языке 10 и, следовательно, вероятность угадывания следующей буквы 1/10, а не 1/33. В связи с этим примем следующее определение: Сообщения (а также источники, их порождающие), в которых существуют статистические связи (корреляции) между знаками или их сочетаниями, называются сообщениями (источниками) с памятью или марковскими сообщениями (источниками). Учет в английских словах двухбуквенных сочетаний понижает среднюю информацию на знак до значения I2(e)=3, 32 бит, учет трехбуквенных - до I3(e)=3, 10 бит. Шеннон сумел приблизительно оценить; I5(e) Последовательность I0, I1, I2… является убывающей в любом языке. Экстраполируя ее на учет бесконечного числа корреляций, можно оценить предельную информацию на знак в данном языке
Избыточность является мерой бесполезно совершаемых альтернативных выборов при чтении текста. Эта величина показывает, какую долю лишней информации содержат тексты данного языка; лишней в том отношении, что она определяется структурой самого языка и, следовательно, может быть восстановлена без явного указания в буквенном виде. Исследования Шеннона для английского языка дали значение Символы некоторого первичного алфавита (например, русского) кодируются комбинациями символов двоичного алфавита (т.е. 0 и 1), причем, длина кодов и, соответственно, длительность передачи отдельного кода, могут различаться. Длительности элементарных сигналов при этом одинаковы ( Очевидно, возможны различные варианты двоичного кодирования, однако, не все они будут пригодны для практического использования - важно, чтобы закодированное сообщение могло быть однозначно декодировано, т.е. чтобы в последовательности 0 и 1, которая представляет собой многобуквенное кодированное сообщение, всегда можно было бы различить обозначения отдельных букв. Проще всего этого достичь, если коды будут разграничены разделителем - некоторой постоянной комбинацией двоичных знаков. Условимся, что разделителем отдельных кодов букв будет последовательность 00 (признак конца знака), а разделителем слов - 000 (признак конца слова - пробел). Довольно очевидными оказываются следующие правила построения кодов: · код признака конца знака может быть включен в код буквы, поскольку не существует отдельно (т.е. кода всех букв будут заканчиваться 00); · коды букв не должны содержать двух и более нулей подряд в середине (иначе они будут восприниматься как конец знака); · код буквы (кроме пробела) всегда должен начинаться с 1; · разделителю слов (000) всегда предшествует признак конца знака; при этом реализуется последовательность 00000 (т.е. если в конце кода встречается комбинация …000или …0000, они не воспринимаются как разделитель слов); следовательно, коды букв могут оканчиваться на 0 или 00 (до признака конца знака). Длительность передачи каждого отдельного кода ti, очевидно, может быть найдена следующим образом: ti = ki •
Теперь можно найти среднюю длину кода K(2) для данного способа кодирования:
Поскольку для русского языка в указывалось среднее количество информации на один знак I1(r) =4, 356 бит, избыточность данного кода, согласно, составляет:
это означает, что при данном способе кодирования будет передаваться приблизительно на 12% больше информации, чем содержит исходное сообщение. Аналогичные вычисления для английского языка дают значение K(2) = 4, 716, что при I1(e) =4, 036 бит приводят к избыточности кода Q(e) = 0, 144. Рассмотрев один из вариантов двоичного неравномерного кодирования, попробуем найти ответы на следующие вопросы: возможно ли такое кодирование без использования разделителя знаков? Существует ли наиболее оптимальный способ неравномерного двоичного кодирования? Суть первой проблемы состоит в нахождении такого варианта кодирования сообщения, при котором последующее выделение из него каждого отдельного знака (т.е. декодирование) оказывается однозначным без специальных указателей разделения знаков. Наиболее простыми и употребимыми кодами такого типа являются так называемыепрефиксные коды, которые удовлетворяют следующему условию (условию Фано): Неравномерный код может быть однозначно декодирован, если никакой из кодов не совпадает с началом (префиксом 1) какого-либо иного более длинного кода. Например, если имеется код 110, то уже не могут использоваться коды 1, 11, 1101, 110101 и пр. Если условие Фано выполняется, то при прочтении (расшифровке) закодированного сообщения путем сопоставления со списком кодов всегда можно точно указать, где заканчивается один код и начинается другой. Пример 3.1 Пусть имеется следующая таблица префиксных кодов:
Требуется декодировать сообщение: 00100010000111010101110000110 Декодирование производится циклическим повторением следующих действий: 1. отрезать от текущего сообщения крайний левый символ, присоединить к рабочему кодовому слову; 2. сравнить рабочее кодовое слово с кодовой таблицей; если совпадения нет, перейти к (1); 3. декодировать рабочее кодовое слово, очистить его; 4. проверить, имеются ли еще знаки в сообщении; если «да», перейти к (1). Применение данного алгоритма дает:
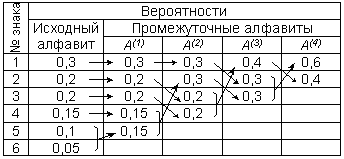
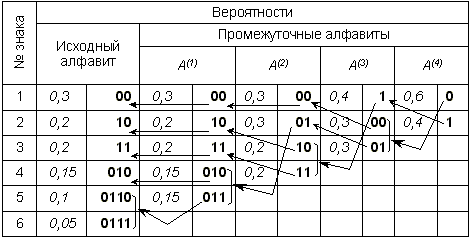
Доведя процедуру до конца, получим сообщение: «мама мыла раму». Таким образом, использование префиксного кодирования позволяет делать сообщение более коротким, поскольку нет необходимости передавать разделители знаков. Однако, условие Фано не устанавливает способа формирования префиксного кода и, в частности, наилучшего из возможных. Способ оптимального префиксного двоичного кодирования был предложен Д.Хаффманом. Пример 3.2. Построение кодов Хаффмана мы рассмотрим на следующем примере: пусть имеется первичный алфавит A, состоящий из шести знаков a1 …a6 с вероятностями появления в сообщении, соответственно, 0, 3; 0, 2; 0, 2; 0, 15; 0, 1; 0, 05. Создадим новый вспомогательный алфавит A1, объединив два знака с наименьшими вероятностями (a5и a6) и заменив их одним знаком (например, a(1)); вероятность нового знака будет равна сумме вероятностей тех, что в него вошли, т.е. 0, 15; остальные знаки исходного алфавита включим в новый без изменений; общее число знаков в новом алфавите, очевидно, будет на 1 меньше, чем в исходном. Аналогичным образом продолжим создавать новые алфавиты, пока в последнем не останется два знака; ясно, что число таких шагов будет равно N - 2, где N - число знаков исходного алфавита (в нашем случае N = 6, следовательно, необходимо построить 4вспомогательных алфавита). В промежуточных алфавитах каждый раз будем переупорядочивать знаки по убыванию вероятностей. Всю процедуру построения представим в виде таблицы:
Теперь в обратном направлении поведем процедуру кодирования. Двум знакам последнего алфавита присвоим коды 0 и 1 (которому какой - роли не играет; условимся, что верхний знак будет иметь код 0, а нижний - 1). В нашем примере знак a1(4) алфавита A(4), имеющий вероятность 0, 6, получит код 0, а a2(4) с вероятностью 0, 4 - код 1. В алфавитеA(3) знак a1(3) с вероятностью 0, 4 сохранит свой код (1); коды знаков a2(3) и a3(3), объединенных знаком a1(4) с вероятностью 0, 6, будут уже двузначным: их первой цифрой станет код связанного с ними знака (т.е. 0), а вторая цифра - как условились - у верхнего 0, у нижнего - 1; таким образом, a2(3) будет иметь код 00, а a3(3) - код 01. Полностью процедура кодирования представлена в следующей таблице:
Из самой процедуры построения кодов легко видеть, что они удовлетворяют условию Фано и, следовательно, не требуют разделителя. Средняя длина кода при этом оказывается:
Для сравнения можно найти I1(A); - она оказывается равной 2, 409, что соответствует избыточности кода Q = 0, 0169, т.е. менее 2%. Код Хаффмана важен в теоретическом отношении, поскольку можно доказать, что он является самым экономичным из всех возможных, т.е. ни для какого метода алфавитного кодирования длина кода не может оказаться меньше, чем код Хаффмана. Применение описанного метода для букв русского алфавита дает следующие коды (для удобства сопоставления они приведены в формате Таблицы 3.2): Таблица 3.3
Средняя длина кода оказывается равной K(2) = 4, 395; избыточность кода Q(r) = 0, 00887, т.е. менее 1%. Таким образом, можно заключить, что существует метод построения оптимального неравномерного алфавитного кода. Не следует думать, что он представляет число теоретический интерес. Метод Хаффмана и его модификация - метод адаптивного кодирования (динамическое кодирование Хаффмана) - нашли широчайшее применение в программах-архиваторах, программах резервного копирования файлов и дисков, в системах сжатия информации в модемах и факсах. Практическая часть 1. В чем смысл первой теоремы Шеннона для кодирования? 2. Первичный алфавит содержит 6 знаков с вероятностями: «пробел» - 0, 3; «*» - 0, 2; «+» - 0, 2; «%» - 0, 15; «#» - 0, 1 и «! » - 0, 05. Предложите вариант неравномерного алфавитного двоичного кода с разделителем знаков, а также постройте код Хаффмана; сравните их избыточности. 3. С помощью электронных таблиц проверьте правильность данных о средней длине кода K(2) для примеров 3.1 и 3.2 неравномерного алфавитного кодирования. 4. Для алфавита, описанного в задаче 3, постройте вариант минимального кода Бодо. 5. Проверьте данные об избыточность кода Бодо для русского и английских языков. Почему избыточность кода для русского языка меньше? 6. Почему в 1 байте содержится 8 бит? 7. Оцените, какое количество книг объемом 200 страниц может поместиться: o на дискете 1, 44 Мб; o в ОЗУ компьютера 32 Мб? o на оптическом CD-диске емкостью 650 Мб? o на жестком магнитном диске винчестера емкостью 8, 4 Гб? 8. Почему в компьютерных устройствах используется байтовое кодирование? 9. Что такое «лексикографический порядок кодов»? Чем он удобен? 10. Для цифр придумайте вариант байтового кодирования. Реализуйте процедуру кодирования программно (ввод - последовательность цифр; вывод - последовательность двоичных кодов в соответствии с разработанной кодовой таблицей). 11. Код Морзе для цифр следующий:
Считая алфавит цифр самостоятельным, а появление различных цифр равновероятным, найдите избыточность кода Морзе для цифрового алфавита. 12. В лексиконе «людоедки» Эллочки Щукиной из романа Ильфа и Петрова «12 стульев» было 17 словосочетаний («Хо-хо! », «Ого! », «Блеск! », «Шутишь, парниша», «У вас вся спина белая» и пр.). o Определите длину кода при равномерном словесном кодировании. o Предложите вариант равномерного кодирования данного словарного запаса. 13. Ответьте на контрольные вопросы, напишите отчёт по проделанной работе. Контрольные вопросы: 1. Что такое сообщение? 2. Что показывает формула Хартли? 3. Формула Шеннона. Что она даёт? 4. Код Хаффмана. Практическая работа №6 |
Последнее изменение этой страницы: 2017-03-15; Просмотров: 682; Нарушение авторского права страницы