|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
МНОЖЕСТВЕННЫЙ РЕГРЕССИОНЫЫЙ АНАЛИЗ ⇐ ПредыдущаяСтр 3 из 3
Цель практической работы Цель: освоение методики проведения регрессионного анализа.
1. Краткая теоретическая часть. Основные понятия, определения, формулы Множественная регрессия
Множественный регрессионный анализ является развитием парного регрессионного анализа применительно к случаям, когда зависимая переменная гипотетически связана с более чем одной независимой переменной. Большая часть анализа будет непосредственным расширением парной регрессионной модели, однако появляются две новые проблемы. Во-первых, при оценке влияния данной независимой переменной на зависимую переменную необходимо решить проблему разграничения ее воздействия и воздействий других независимых переменных. Во-вторых, возникает проблема спецификации модели. Часто предполагается, что несколько переменных могут оказывать влияние на зависимую переменную, с другой стороны, некоторые переменные могут не подходить для модели. Необходимо решить, какие из них следует включить в уравнение регрессии, а какие - исключить из него. В данной расчетной работе предполагается, что спецификация модели правильна. Для проведения регрессионного анализа из (к+1)-мерной, генеральной совокупности (Y, X1, X2,..., Xj,..., Xk) берется выборка объемом п и каждое 1-ое наблюдение (объект) характеризуется значениями переменных (ynxll> Xyt..., xlk), где х jj - значение j-ой переменной для i-ro наблюдения (i=l, 2,..„n), уj-. - значение результативного признака для i-ro наблюдения. Наиболее часто используемая множественная линейная модель регрессионного анализа имеет вид:
где ε i - случайные ошибки наблюдения, независимые между собой, имеют нулевую среднюю и дисперсию α 2. Отметим, что модель справедлива для всех i = 1, 2,.., n, линейна относительно неизвестных параметров 4 и аргументов. Как следует из модели коэффициент регрессии β 1 показывает, на какую величину в среднем изменится результативный признак Y, если переменную Xj увеличить на единицу измерения, т е. является нормативным коэффициентом. В матричной форме регрессионная модель имеет вид: Y=Хβ +ε (2) где Y - случайный вектор - столбец размерности (n x 1) наблюдаемых значений результативного признака (у1, у2,..., уп); X - матрица размерности [п* (к+1)] наблюдаемых значений аргументов. Элемент матрицы Xij рассматривается как неслучайная величина (i =l, 2,..., n; j-=0, l, 2,...k, Xot — I); β -вектор - столбец размерности [(k+l) х 1] неизвестных, подлежащих оценке параметров (коэффициентов регрессии) модели; ε -случайный- вектор - столбец размерности (n x 1) ошибок наблюдений (остатков). Компоненты вектора ε i независимы между собой, имеют нормальный закон распределения с нулевым математическим ожиданием и неизвестной дисперсией о2 На практике рекомендуется, чтобы n превышало к не менее, чем в три раза. В матричной модели единицы в первом столбце матрицы.призваны обеспечить наличие свободного члена в исходной модели. Здесь предполагается, что существует переменная хо, которая во всех наблюдениях принимает значения равные 1. Основная задача регрессионного анализа заключается в нахождении по выборке объемом n, оценки неизвестных коэффициентов регрессии β 0 … β k модели или вектора β . Так как, в регрессионном анализе xj рассматриваются как неслучайные величины, a Mε i =0, то уравнение регрессии имеет
для всех i= 1, 2,..., n, или в матричной форме: Y=Xβ (4) где Y - вектор-столбец с элементами y1,..., yi,..., yn. Для оценки вектора β наиболее часто используют метод наименьших квадратов (МНК), согласно которому в качестве оценки принимают вектор b, который минимизирует сумму квадратов отклонения наблюдаемых значений yi от модельных значений yi, т. е. квадратичную форму:
Дифференцируя, с учетом и квадратичную форму Q по β 0, …β к и приравнивая производные нулю, получим систему нормальных уравнений:
решая которую и получаем вектор опенок b, где b-(bo, bl, bk) Согласно методу наименьших квадратов, вектор оценок коэффициентов регрессии получается по формуле:
XT - транспонированная матрица Х; (XrХ)-1 - матрица, обратная матрице ХТX Зная вектор оценок коэффициентов регрессии b, найдем оценку у, уравнения регрессии: уi = bo + b1.Xi1 +b2Xi21+...+bkXjk, Или в матричном виде: у ~ Xβ, где y=(Yl, Y2...YN) Оценка ковариационной матрицы коэффициентов регрессии вектора b определяется из выражения:
где
Учитывая, что на главной диагонали ковариационной матрицы находятся дисперсии коэффициентов рецессии, имеем:
Качество оценки: коэффициент R2
Цель регрессионного анализа состоит в объяснении поведения зависимой переменной у. В любой данной выборке у оказывается сравнительно низким в одних наблюдениях и сравнительно высоким в других. Разброс значений у в любой выборке можно суммарно описать с помощью выборочной дисперсии Var(y). После построения уравнения регрессии можно разбить значение уi в каждом наблюдении на две составляющих - у\ и еi:
Величина уi = расчетное значение у в наблюдении i.Остаток еi есть расхождение между фактическим и спрогнозированным значениями величины у. Используя (25), разложим дисперсию у: Var(y) = Var(y + ё) = Var(y) + Var(e) + 2Cov(y, e) (10) Так как Cov(yi, e) должна быть равна нулю, получим: Var(y) = Var(y) + Var(e) (11) Согласно (27), коэффициент детерминации
что равносильно
Максимальное значение коэффициента R2 равно единице. Это происходит в том случае, когда линия регрессии точно соответствует всем наблюдениям, так что y’t=yt для всех i и все остатки равны нулю. Тогда Var(y) = Var(y), Var(e)=0 и R2=l/ Если в выборке отсутствует видимая связь между у и x, то коэффициент R2 будет близок к нулю. При прочих равных условиях желательно, чтобы коэффициент R2 был как можно больше. Недостатком коэффициента детерминации R2 является увеличение его значения при добавлении в модель дополнительных регрессоров. Если взять число регрессоров равным числу наблюдений можно добиться того, что R2 =1, но это не будет означать наличие содержательной (имеющей экономический смысл) зависимости Y от регрессоров. Попыткой устранить эффект, связанный с ростом R2 при возрастании числа регрессоров, является коррекция R2 на число регрессоров. Скорректированным R2 называется
В определённой степени использование скорректированного коэффициента детерминации более корректно для сравнения регрессий при изменении количества регрессоров. Проверка значимости модели Значимость уравнения регрессии, т. е. гипотеза Но: β =0 (β o=β i-...β k=0), проверяется по F-критерию, наблюдаемое значение которого определяется по формуле:
где
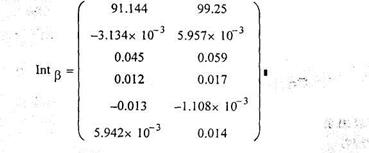
По таблице F-распределения для заданных α, vi-К+1, v2=n-k-1) находят Fкp. Если Fнабл> Fкр, то уравнение является значимым, т. е. хотя бы один из коэффициентов регрессии отличен от нуля. Проверка значимости отдельных коэффициентов регрессии. Для проверки значимости отдельных коэффициентов регрессии, т.е. гипотез Но: β j=0, где j=l, 2,...k, используют t-критерий и вычисляют tнабл(bj)= bj/Sbj. По таблице t-распределения для заданного а и v= n-k-1 находят tkp. Гипотеза Но отвергается с вероятностью а, если tнабд> tkp. Из этого следует, что соответствующей коэффициент регрессии β j значим, т. е. β j≠ 0. Интегральная оценка с доверительной вероятностью у для параметра β j имеет вид:
где ta находят по таблице t – распределение при вероятности а=1-у и числе степеней свободы v=n-K-1. Точечная и интервальная оценки для уравнения регрессии в точке. Зная вектор оценок коэффициентов регрессии b, можно найти оценку у по полученному уравнению регрессии в некоторой точке Х0:
Или в матричном виде: у=Хβ, где у=(У1, У2, …УN) Интервальная оценка для уравнения регрессии у в точке определяемой вектором начальных условий
Интервал оценки предсказания уn+1 с уровнем значимости α определяется как:
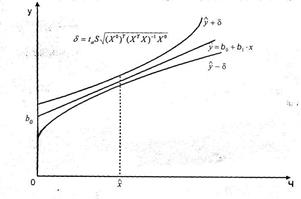
Где taопределяется по таблице t-распределения при v=n-k-1 По мере удаления вектора начальных условий х0от вектора средних х. ширина доверительного интервала при заданном у будет увеличиваться (рис. 1), где х = (1, х1, … хк)
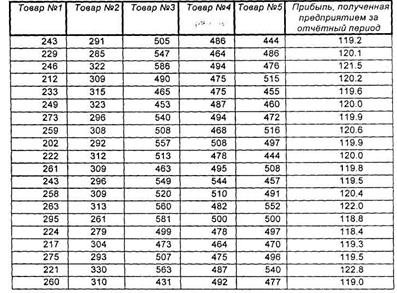
Рисунок 1 – Точечная и интервальная оценки уравнения регрессии Экспериментальная часть Пример Предприятие выпускает 5 видов товаров. Данные об их производстве и прибыль, полученная предприятием, за последние 20 недель приведены в таблице. К каким выводам можно прийти, используя компонентный и регрессионный анализ, по представленной информации?
Таблица 1.
Для решения данной задачи воспользуемся электронным документом regression.med (для работы которого необходимы regression1.med и regression2.med) составленным в математическом процессоре Mathcad 7.) В качестве регрессионной модели возьмем линейную модель вида У=β 0+β 1*х1*β 2х2+ …+β к*хк (21) Тогда в матричном виде исходные данные примут вид
Коэффициенты регрессии и их стандартные ошибки определим по следующим формулам:
Следовательно, аналитически модель можно представит как
Сумма квадратов остатков (необъясненная дисперсия)
Объясненная дисперсия
Полная дисперсия
То есть объясненная дисперсия составляет почти 100% от полной, что свидетельствует о хорошем соответствии модели реальной ситуации. Коэффициенты детерминации (простой и скорректированный)
Высокое значение коэффициентов детерминации свидетельствует о высоком качестве полученной модели. Проверка значимости уравнения регрессии и оценка доверительных интервалов для ее параметров. Проверим значимость модели, используя F-статистику. Для этого выдвинем статистическую гипотезу о равенстве всех коэффициентов регрессии нулю. Н0: все коэффициенты регрессии равны 0, т.е. уравнение модели незначимо. В качестве альтернативной гипотезы предположим, что все коэффициенты регрессии не равны 0. Н1: существует хотя бы один коэффициент регрессии, значение которого не равно 0, т.е. уравнение модели значимо.
F = 17? 963
Ftab=2, 901 Так как F> Ftab, то справедливо утверждать, что гипотеза Н0 отвергается в пользу альтернативной, т.е. полученная модель значима. •' Проверим значимость коэффициентов регрессии, используя статистику Стьюдента. Для этого выдвинем k статистических гипотез о равенстве каждого коэффициента регрессии нулю. Альтернативными гипотезами будут неравенство каждого коэффициента нулю (коэффициент значим).
Результаты проверки гипотез приведены в матричном виде/ Следовательно, все коэффициенты регрессии (кроме коэффициента bi) являются значимыми. Так как гипотеза о равенстве коэффициента β 1 нулю принимается, то справедливо полагать, что значение Y не зависит от значения X*. Доверительные интервалы для β i представим в виде матрицы, в первом столбце которой укажем нижние границы интервалов для каждого Ь» а во втором - верхние.
Предсказание значения Y по полученной модели в заданной точке X= (1 250 300 500 490 475) В точке х значение, рассчитанное по модели, примет вид У=119.518 Границы доверительного интервала предсказанного значения Уmin=119, 494 Ymax=119, 543
Так как полученная модель обладает высоким качеством, то не удивительно, что доверительный интервал предсказываемых значений оказался малым. Вывод: Использование регрессионного анализа привело к получению модели, очень хорошо описывающей взаимосвязь, между производством товаров и прибылью предприятия. Анализ коэффициентов регрессии показал, что товар №2 является наиболее прибыльным, а товар №4 - убыточным. Если предприятие произведёт 250 ед. товара №1, 300 ед. товара №2, 500 ед. - №3, 490 ед. - №4 и 475 ед. =№5, то, исходя из предсказания по модели, средняя прибыль составит с вероятностью 95% около 119, 494-119.543 ден. ед.
Адание на расчетную работу 1. Проиллюстрировать понятие регрессионного анализа. 2. Рассчитать по полученным данным коэффициенты линейной множественной регрессии, определить их стандартные отклонения. 3. Оцените качество построенной модели: разделите полную дисперсию зависимого параметра Y на объясненную и необъяснённую составляющие, определите коэффициент детерминации, сделайте выводы о качестве полученной модели. 4. Определите значимость коэффициентов регрессии, используя статистику Стьюдента. 5. Проверьте значимость модели, используя статистику Фишера. 6. По полученной модели определите с доверительной вероятностью 95% интервал возможных значений Y при заданных значениях независимых параметров X. При выполнении работы рекомендуется использовать пакеты прикладных программ Mathcad и Excel
Содержание отчета Отчет должен содержать: 1. Титульный лист; 2. Задание; 3. Постановку задачи; 4. Результаты выполнения задания; 5. Выводы с экономической трактовкой.
5.Контрольные вопросы 1. Каким методом можно рассчитать коэффициенты производственной функции Кобба-Дугласа? 2. Описать факторы, обуславливающие точность коэффициентов множественной регрессии. 3. Записать формулы для расчета стандартных ошибок и построения доверительных интервалов. 4. Дать определение понятию «мультиколлинеарность». 5. Рассказать о методах уменьшение негативных последствий муяьтикодл инеарности.
|
Последнее изменение этой страницы: 2017-04-13; Просмотров: 880; Нарушение авторского права страницы
 (1)
(1) (3)
(3) (5)
(5)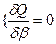 для i=0, 1, …k (6)
для i=0, 1, …k (6)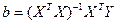
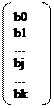 b=
b=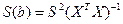
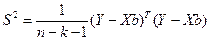 (7)
(7)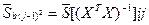 (8)
(8)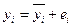 (9)
(9)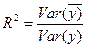 (12)
(12)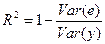 (13)
(13)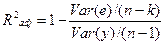 (14)
(14) (15)
(15)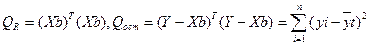 (16)
(16)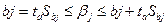 (17)
(17)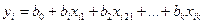 (18)
(18)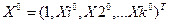 , равна:
, равна: 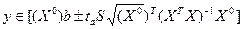 (19)
(19) (20)
(20)

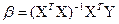 (22)
(22)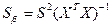 (23)
(23)
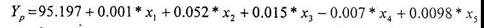
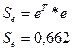 (24)
(24)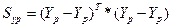 (25)
(25)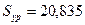
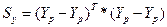 (26)
(26)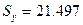
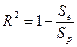 (27)
(27)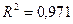
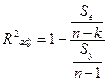 (28)
(28)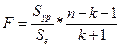 (29)
(29)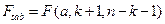 (30)
(30)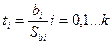 (31)
(31)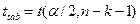 (32)
(32)
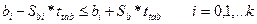 (33)
(33)