КЛАСС КЛАССЗ 66 55 89 77 4' КЛАССЗ ЖЛАСС
9 /
КЛАССЫ КЛАСС1
11 ' КЛАСС1 ' КЛАСС2 ' КЛАССЗ 3 ЖЛАССЫ КЛАССЫ1
12
VARIABLE X 2 ALLOT
14 '
15
95
О \ АЛГОРИТМЫ РАСПОЗНАВАНИЯ ОБРАЗОВ
. & ';.; . ' I.- - ' - ' : '; .■ ■
2' К ЛАСС1 ПРОТОТИП
3 'К ЛАСС 2П РОТОТИ П
4' К ЛАССЗ ПРОТОТИ П
5 ' ' ■ ■ ■ ■ • ■ ■ ■ ■ ■ ■: ■
6 4 X! 4 X 2+! \ X = (4, 4)
7
X ' КЛАССЫ1 КЛАССИФИКАЦИЯ
10
11
12
13 .
14
15
 Экраны 93, 94, 95. Определения слов ЖЛАСС и ЖЛАССЫ
Экраны 93, 94, 95. Определения слов ЖЛАСС и ЖЛАССЫ
260
Слово ПРОТОТИП, изображенное на экране 91, выбирает из
стека cfa слова-класса и вычисляет точку-прототип и wn+1 для нее,
а также запоминает эти значения в соответствующие поля данных
самого слова-класса. Слово D(X) является решающей функцией.
Оно выбирает указатель на точку, подлежащую классификации, а
также cfa класса, и возвращает в стек число, позволяющее судить
о степени принадлежности данной точки к классу..Чем больше чи-
сло, тем вероятнее принадлежность. Слово КЛАССЫ, показанное
на экране 92, определяет классы в области образов. По его pfa
располагается число классов, а затем по порядку адреса cfa каждо-
го класса (класс 0 на первом месте). Наконец, слово КЛАССИФИ-
КАЦИЯ выбирает указатель на точку данных X' и cfa области об-
разов, а возвращает число назначенных классов.
На экране 93 представлены два слова, позволяющие упростить
заполнение в словах КЛАСС и КЛАССЫ выделенной памяти дан-
ными. Их использование показано на экране 94, где класс 1
(КЛАСС1) определен четырьмя точками в области образов: (0, 2),
(1, 1), (2, 1) и (2, 2). Экран 95 иллюстрирует вычисление точки-
прототипа каждого класса и wn+1. Далее классифицируемая точка
помещается в X. На экране 95 X получает значение (4, 4). Нако-
нец, вызывается слово КЛАССИФИКАЦИЯ с параметрами X и
КЛАССЫ 1, где содержатся три класса. В результате мы имеем:
п+1
Класс Точка-прототип
0 (1, 1) 1
1 (4, 2) 10
2 (6, 7) 36
Слово КЛАССИФИКАЦИЯ относит точку (4, 4) к классу 1.
АЛГОРИТМЫ КЛАССИФ И КАЦИИ ОБРАЗО В
" Для классификатора, построенного с помощью критерия мини-
мального расстояния, по набору точек с заданной классификацией
вычисляются точки-прототипы. Затем могут быть классифицирова-
ны новые точки посредством решающих функций, построенных на
базе этих прототипов. Таким образом, по точке-прототипу строит-
ся вектор весов W, используемый для определения решающей
функции-гиперплоскости.
Теперь рассмотрим несколько алгоритмов автоматической
классификации образов. Методы кластеризации с заранее опре-
деленными классами лежат в основе неуправляемого ( unsupervise d )
обучения. Если же алгоритмы учатся правильно распознавать об-
разы с использованием обратной связи по завершении процесса
классификации, то такое обучение называется управляемым
( supervised ). В ЭС применяются оба вида обучения.
261
Рис. 11.9. Пороговый алгоритм классификации
На рис. 11.9 показан простой алгоритм кластеризации, извест-
ный как пороговый алгоритм ( threshold algoritm ). Критерием для
отнесения образа к какому-либо классу здесь служит пороговое
расстояние Т. Если образ находится в пределах расстояния Т от
некоторого прототипа, то он будет отнесен к данному кластеру.
Если* же рассматриваемый образ находится от любого прототипа
дальше, чем на расстояние Т, он становится новым прототипом.
Первоначально точка-прототип определяется произвольно. Ею мо-
жет быть первый образ Xj. Затем вычисляется расстояние от сле-
дующего образа до Zj (и до любого другого прототипа, если он име-
ется). Отнесение данного образа к тому или иному классу
основывается на сравнении его расстояния до прототипа с Т.
Пороговый алгоритм прост, но он не свободен от недостатков.
Во-первых, существенное влияние на выбор прототипа оказывает
порядок рассмотрения образов. Положение можно улучшить, если
задать приблизительные значения прототипов. Во-вторых, выбор Т
влияет на разрешающую способность кластеризации. На рис.
11.10А представлено изменение числа кластеров с изменением Т.
" Нормальное" значение Т должно находиться в том интервале, где
данная зависимость линейна (между Tj и Т2). В этом диапазоне
алгоритм сравнительно не чувствителен к Т и обеспечивает опти-
мальную кластеризацию. На рис.11.10В показана область образов
применительно к нашей ситуации. Два кластера А и В будут четко
разделены любым значением Т между Tj и Т2. В том случае, ког-
да А и В перекрываются, ни одно из значений Т не разделит их.
Они действительно линейно неразделимы и здесь требуется приме-
нение статистических классификаторов.
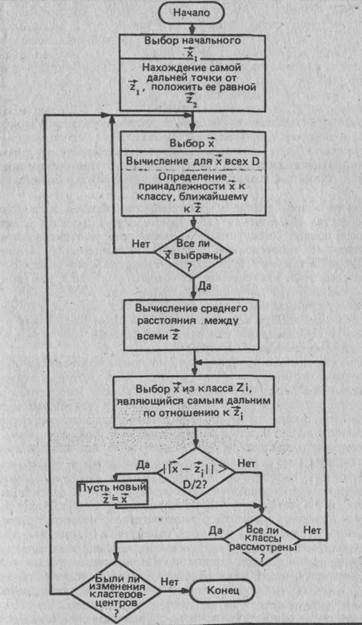
Алгоритм, построенный по критерию максимального расстоя-
ния, обладает лучшими качествами. Как показано на рис. 11.11,
он использует ту же меру длины, что и рассмотренный выше алго-
ритм. Здесь пороговое значение не фиксируется, а переопределяет-
ся после классификации всех образов, после чего осуществляется
переклассификация. В целях коррекции Т образец, наиболее уда-
ленный от своего прототипа, сравнивается с другими по среднему
расстоянию между прототипами. Если это расстояние превышает
среднее на половину среднего расстояния, то создается новый про-
тотип. Аналогичным образом происходит сравнение самых дальних
точек для каждого прототипа. При образбвании новых прототипов
осуществляется повторная классификация.
Алгоритм, построенный по принципу максимального расстоя-
ния, имеет преимущество перед алгоритмом с пороговым значени-
ем, поскольку предусматривает коррекцию Т. Однако он чувстви-
телен к порядку рассмотрения образов и к ложным образам (поме-
хи в передаче данных), так как самая дальняя точка вероятнее
всего окажется шумовой. Поскольку для нахождения максимально-
го расстояния вычисляется расстояние от каждой точки до ее
прототипа, при большом числе образов на это уходит очень много
262
263

Рис. 11.10. Изменение числа кластеров с изменением Т между Tj и Т2
линейно (А), так как в этом интервале кластеры А и В разделены (В)
времени. Если в качестве нового прототипа выбрать самую отда-
ленную точку, то отдельный кластер может быть ошибочно слит
с ближайшим к нему кластером, потому что на первых порах рас-
стояние между кластерами велико. Наконец, алгоритм не будет
функционировать при определенном распределении образов, на-
пример в том случае, когда классифицируемая точка находится по-
середине между двумя прототипами с равным числом точек.
Чувствительность алгоритма к порядку расположения образов
можно уменьшить. Имеет смысл сначала изучить распределение
образов и сделать предварительный выбор центров кластеров.
264
Рис. 11.11. Алгоритм классификации по критерию расстояния
265
Алгоритм усреднения п о К ( K - means algorithm ) осуществляет вы-
бор из (или ему задается) К прототипов. С помощью классифика-
тора, построенного по критерию минимального расстояния, он от-
носит каждую из оставшихся точек к одному из К заданных клас-
теров, после чего для каждого кластера вычисляется новый прото-
тип с учетом вновь приписанных образов (путем нахождения сред-
ней точки, как мы это выполняли ранее). Классификация повторя-
ется до тех пор, пока распределение образов по классам не завер-
шится. Алгоритм усреднения по К практически перераспределяет
- прототипы по К заданным прототипам. Сам он выбирает исходные
прототипы произвольным образом и поэтому остается чувствите-
льным к порядку расположения образов. Если же аппроксимация
К прототипов будет проведена до функционирования алгоритма, то
он уже не может считаться " автоматическим" при выборе прототц-
пов, как алгоритм, созданный по принципу максимального рассто-^
яния.
Более общий подход к кластеризации образов должен вклю-
чать средства объединения кластеров, которые срослись (с исполь-
зованием правил " отмирания" ), а также средства генерации новых
кластеров (с применением правил " порождения" ). Поскольку
образцы представляют собой данные измерений в некоторой облас-
ти (или свойства, извлеченные из исходных данных), для описания
этой области могут привлекаться правила из базы знаний, чтобы
решения, принимаемые при классификации, были бы уже частич-
но доказанными. При таком подходе сочетание численных и сим-
вольных преобразований позволило бы системе обучаться непос-
редственно на данных, получаемых с датчиков.
Так как процесс обучения требует новой информации об обла-
сти, желательно иметь компьютер (или робот), который снимал бы
эти данные непосредственно с датчиков, вместо того, чтобы вруч-
ную преобразовывать их в форму правил. В настоящее время в
большинстве систем представления знаний принята соответствую-
щая техника представления данных для обучения, которая являет-
ся сенсорным расширением систем построения баз знаний и поста-
вляет системе новую информацию вместо неэффективного челове-
ко-машинного интерфейса. С применением роботов происходит
объединение познавательных способностей систем, основанных на
знаниях, и искусственных сенсомоторных систем, что ведет к сок-
ращению такого интерфейса. Предполагается, что в будущем вза-
имодействие человека с системами управления базами знаний дол-
жно осуществляться через органы восприятия роботов, причем ро-
боты могут быть как автономными, так и управляемыми челове-
ком. Общение с ними будет подобно обычному человеческому об-
щению, а способов общения станет гораздо больше, чем предостав-
ляет нам сейчас клавиатура, дисплей и световое перо.
В одном из ранних проектов по обучающим системам был раз-
работан алгоритм управляемого обучения - так называемый алго-
266
ритм восприятия ( perceptron a lgoritm ). В результате обучения по
такому алгоритму создается вектор точных весов для классифи-
кации линейно разделимых кластеров. После обучения на образах
известной классификации (обучающем множестве - training set )
этот алгоритм может осуществлять классификацию образов из не-
известных классов (рис. 11.12). Данный метод легко расширить для
классификации по нескольким классам.
Обучающее множество состоит из N образов в каждом из двух
классов. Решающая функция для образов, принадлежащих классу
1, получает положительные числа:
Хи* W> 0, i = 1, 2........... N
а для образов из класса 2 - отрицательные:
X2i * W< О, i = 1, 2, ..., N
или:
- X2 i * W > 0, i = 1, 2,
Заменив -X2j на X2i, мы добились того, .что функция d(X)
будет одинаково применяться к образам обоих классов. Алгоритм
восприятия выбирает образ и определяет для него значение реша-
ющей функции. Если это значение положительно, образ классифи-
цирован правильно, и корректировка W не требуется. В противном
случае происходит корректировка W. Процедура повторяется до
тех пор, пока все образы не будут правильно классифицированы по
заданному вектору весов.
При отрицательном значении d(X) W увеличивается на вели-
чину с*Х, где с - положительное приращение коррекции. К-й шаг
процедуры коррекции выглядит следующим образом:
- w(k + 1)=w(k), если\у(к)*х> 0
W(k + 1) = W(k) + сХ, если W(k) * X < = О
В результате коррекции W улучшается, поскольку значение функ-
ции теперь равно:
d(X) = W(k + 1) * X = (W(k) + СХ) * X =
= W(k) * X + СХ * X
Полученное новое значение d(X) должно превышать предыдущее
значение, так как оно составляет лишь первое слагаемое текущего
значения - W(k) * X. Текущее значение превышает предыдущее
на величину второго слагаемого сХ ♦ X, значение которого должно
быть положительным, поскольку и с, и X ♦ X положительны (X не
равен 0).
267
2 6 8
Рис. 11.12. Алгоритм восприятия
Рассмотрим выполнение приведенного алгоритма на примере
обучающего множества, состоящего из двух образов в каждом
классе в двумерном пространстве:
класс 1: X, = [3 1] т, Х 2 = [1 2] т
класс 2: -Х 3 = [1 -2] т, -Х 4 = [2 -1] т
На рис. 11.13 показаны состояние обучающего множества и ре-
зультат коррекции W на различных тагах выполнения алгоритма
при заданных значениях с = 1 и W(0) =0. Результирующий вектор
весов [4 -1]т перпендикулярен прямой, разделяющей два класса.
X увеличивается на константный терм xn+i (аналогично и W), как
описано в разд. " Свойства гиперплоскости. Поскольку d(Xj) = 0,
W подлежит изменению, в результате чего получается
[3 1 1]т:
W(1) = W(0) + 1 * Xj = [-0 О 0]т + [3 1 1]т = [3 1 1)т
| Шаг
| Класс
| W
| X
| d(X)
| Изменением
|
| 0
| 1
| (0, 0, 0)
| (3, 1, 1)
| 0
| да
|
| 1
| 1
| (3 1 1)
| (1, 2, 1)
| 6
| нет
|
| 2
| 2
| (3, 1, 1)
| (1, -2.-1)
| 0
| да
|
| 3
| 2
| (4, -1, 0)
| (2, -1, -1)
| 9
| нет
|
| 4
| 1
| (4, -1, 0)
| (3, 1, 1)
| 11
| нет
|
| 5
| 1
| (4, -1, 0)
| (1, 2, 1)
| 2
| нет
|
| 6
| 2
| (4, -1, 0)
| (1.-2, -1)
| 6
| нет
|
Рис. 11.13. Пример выполнения алгоритма восприятия при начальном
значении W = 0 и четырех образах в двумерном пространстве при
с=1 1
Далее:
d(x2) = w * х2 = [3 11][1 2 1]т = 6
Результат положителен, W остается без изменений, или
W(2)=W(1). Выполнение процедуры продолжается, как показано
на рис. 11.11.
Что заставляет алгоритм восприятия выполняться? Из изло-
женного выше мы знаем, что W перпендикулярен поверхности
решения решающей функции d(X) = 0. Для заданного образа X
вектор W ориентирован в том же самом общем направлении, если
W ♦ X > 0. Угол между ними составляет меньше 90 градусов, пото-
269
му что скалярное произведение двух векторов равно:
W * X = |W| * |Х| * COS А
где А - угол между W и X.
Так как норма векторов всегда неотрицательна, знак скаляр-
ного произведения определяется ориентацией векторов. Следовате-
льно, решающая функция является мерой степени направленности
W и X в одну и ту же сторону. Алгоритм восприятия ищет такой
вектор W, который указывает в том же направлении, что и векто-
ры образов (образы класса 2 отрицательны). При добавлении с*Х к
W последний еще более ориентируется в направлении X. В ре-
зультате коррекции W * X всегда улучшается. За счет добавления
образов Х( к W тот выравнивается по отношению к Xj. Средняя ве-
личина вычисляется следующим образом:
М = (X, +X2+...+Xn)/N
В процессе выполнения алгоритма W приближается к М. По
существу, это классификация на основе критерия минимального |
расстояния. Различие состоит лишь в том, что W не вычисляется
по набору образов известной классификации, а обучается на
данном наборе.
Можно оптимизировать коррекцию W путем дифференциро-
ванного подбора с, что и было сделано выше. Процесс будет схо-
диться гораздо быстрее, если мы вместо произвольной фиксации
значения с, равного единице, присвоим с значение, необходимое
для правильной классификации после коррекции весов. На первом
шаге выполнения для заданного образца значение d(X) положите-
льно. Определим оптимальное значение с на этом шаге, где
W(k+l)*X > 0, или
W(k + 1) * X = (W(k) + CW) * X > О
Разрешим это неравенство относительно с:
-W(k) * Х/Х * X = -W(k) * Х/|Х|2
Так как X * X > 0 и W(k)* X < 0 (классификация была неудач-
ной), имеем: -W(k)* X < = 0. Присваивая с найденное значение,
называемое абсолютным приращением коррекции ( absolute - c orrec -
tion increment ), получаем алгоритм восприятия с абсолютным
приращением коррекции ( absolute - correction perceptron algorithm ).
Несмотря на то что в алгоритмах восприятия, функционирую-
щих с несколькими классами, может быть заложен любой из трех
мультикатегорийных классификаторов, все-таки классификатор ти-
па 3 допускает применение этого алгоритма в более общей форме.
Для образа из класса i, если d; не больше d: (i не равен j), вектор
270
весов для dj увеличивается, а для d: уменьшается. Остальные век-
хоры весов не претерпевают изменений.
Итак, мы рассмотрели область распознавания образов, причем
довольно кратко, поскольку многие методы аналогичны методам,
применяемым в ИИ с той лишь разницей, что в ИИ они основаны
на символьных преобразованиях, а здесь на числовых. Нужно от-
метить, что мы не затронули такую важную тему РО, как стати-
стическое распознавание образов, хотя в реальных программах
требуется именно этот подход. Детерминированная классифика-
ция является тем базисом, без которого невозможно уяснить ста-
тистические методы.
УПРАЖНЕНИЯ
1. Расширьте набор слов Форта, предназначенных для выполнения
классификации (экраны 90 - 95), с тем, чтобы векторы имели произвольную длину,
в том числе и максимальную N. Такой более универсальный набор слов смог бы
классифицировать образы в любом пространстве вплоть до N-мерного.
4 2. Напишите программу, реализующую пороговый алгоритм. Создайте нес-
колько опытных образов и проверьте на них работу вашей программы.
3. Определите функцию NC(T), значение которой - число центров кластеров -
определялось бы как функция от порогового значения Т порогового алгоритма из
упр. 2. Постройте график Nc.
4. Напишите программу алгоритма, созданного по принципу максимального
расстояния, и испытайте ее на нескольких выбранных образах.
5. Напишите программу алгоритма усреднения по К и испытайте ее на вы-
бранных образах. Пусть эта программа выберет прототипы случайным образом, а
затем инициирует аппроксимацию кластерных центров по данным прототипам.
Зафиксируйте различие в выполнении для двух отдельных случаев.
6. Напишите обучаемую программу восприятия для двух классов с образами в
двумерном пространстве. Напечатайте табличное значение W и X, а также d(X)
не каждом шаге при:
а) с-1,
б) с - абсолютному приращению коррекции.
Приложение А
ИСХОДНЫЕ ТЕКСТЫ ПРОГРАММ
 В настоящем приложении в полном объеме приводятся исходные тексты прог-
В настоящем приложении в полном объеме приводятся исходные тексты прог-
рамм, реализующих интерпретатор Пролога, который был описан и гл.7, 6 и 9.
Наберите содержимое приведенных ниже экранов, руководствуясь имеющимся у* j
вас описанием стандарта Форт-83.
Если вы работаете на IBM PC в среде F83, созданной Перри и Лэксеном
(поставляется как часть программного обеспечения на дискете), придерживайтесь
правил инициализации Пролог-интерпретатора:
1. Скопируйте содержимое исходной дискеты на другую дискету или на
жесткий диск.
2. Словом FORTH инициируйте Форт-систему.
3. Сделайте доступными блоки интерпретатора Пролога, введя текст:
OPEN PROLOG.BLK
Помните, что все литеры должны быть прописными.
4. Убедитесь в работоспособности Форт-системы, для чего выполните
следующие действия:
а) распечатайте последовательность блоков с помощью слова SHOW, например, так:
37 74 SHOW
б) выведите любой блок словом LIST:
37 LIST
в) используя слово WORDS, просмотрите список доступных слов Форта;
г) словом SEE выполните декомпиляцию любого слова:
SEE LIST
5. Загрузка Пролог-интерпретатора осуществляется программой, приведенной
на экрана 38:
37 LOAD
272
После окончания зафузки на экране дисплея появятся сообщения типа "...isn't
unique" - Это нормальное завершение, так как при зафузке были переопределены
некоторые базовые слова Форта. В частности, теперь слово LIST входит в состав
Пролога'. Для выдачи же блока следует обращаться к слову XLIST:
37 XLIST
6. После зафузки последнего экрана (экран 72) будут созданы списки (рас-
печатайте экран 72 командой 72 XLIST). Просмотреть их можно с помощью следу-
ющих команд: .
СП1 @ ВЫДАТЬ
СП2 @ ВЫДАТЬ
СПЗ О ВЫДАТЬ
7. Для проверки функции ЧТСП зафузите блок 50:
50 LOAD
11 @ ВЫДАТЬ
12 @ ВЫДАТЬ
13 @ ВЫДАТЬ
8. Зафузите базу знаний и проверьте ее работоспособность:
70 LOAD
ЦЕЛИ @ ВЫДАТЬ
ПРЕДЛОЖЕНИЯ @ ВЫДАТЬ
СЛЕД
9. Повторите те же действия с экраном 71:
71 LOAD
ЦЕЛИ @ ВЫДАТЬ
ПРЕДЛОЖЕНИЯ @ ВЫДАТЬ
СЛЕД
Для лучшего уяснения приведенных ниже профамм прочитайте главы с 6-й
по 10-ю.
Примечание. Для сохранения в любой момент времени состояние памяти
выполните команду SAVE-SYSTEM из стандарта Форт-83, указав имя файла:
SAVE-SYSTEM ANIMAL.COM
Файлы с расширением.СОМ аналогичны командам DOS, т.е. выполняются
без зафузки.
 ' В данном переводе книги возможность конфликта между именами слов
' В данном переводе книги возможность конфликта между именами слов
Форта и Пролога исключена - все слова, не входящие в стандартное ядро Форта, в
том числе и слова, реализующие Пролог, приведены в русской транскрипции. В
частности, слово Пролога LIST при переводе получило имя СПИСОК. -
П р им.п ерев.
273
Экр # 37 C: P RO L O G.BLK
0 \ ЗАГРУЗКА ПРОЛОГА