|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Средства структурного анализа
До разработки инструментария структурного системного анализа не было возможности показать лежащие в основе проекта логические функции и потребности системы, поскольку аналитик очень быстро утопал в деталях текущей или предполагаемой реализации проекта. Сейчас для целей моделирования систем вообще, и структурного анализа в частности, используются три группы средств, отображающих: · функции, которые система должна выполнять; · процессы, обеспечивающие выполнение указанных функций; · данные, используемые при выполнении функций, и отношения между этими данными. Среди всего многообразия средств решения указанных задач в методологиях структурного анализа наиболее часто и эффективно применяемыми являются: · FDD (Functional Decomposition Diagrams) - диаграммы функциональной декомпозиции; · DFD (Data Flow Diagrams) - диаграммы потоков данных; · ERD (Entity-Relationship Diagrams) - диаграммы "сущность-связь" Все они содержат графические и текстовые средства моделирования: первые - для удобства демонстрации основных компонентов модели и их связей, вторые - для обеспечения точного определения компонентов и связей. При помощи этих средств строятся как логические модели исходной и реорганизованной систем управления, так и логическая модель автоматизированной системы управления - подробное описание того, что и как должна делать система, освобожденное, насколько это возможно, от рассмотрения путей реализации. 33. ПОСТРОЕНИЕ ИЕРАРХИЧЕСКИХ ДИАГРАММ ПРОЦЕССА УПРАВЛЕНИЯ. Иерархические диаграммы. Для отображения позиций и взаимоотношений в графическом формате сверху вниз можно использовать структуру обычной организационной диаграммы. Одним из таких способов обобщенного представления областей ответственности являются иерархические структуры работ (ИСР), основное назначение которых заключается в разбиении результатов поставки проекта на пакеты работ. Организационная структура (ОС) внешне похожа на ИСР, но организована она не по результатам поставки проекта, а в соответствии с имеющейся структурой подразделений организации (отделов, групп или команд). Под каждым отделом указан список операций проекта или пакета работ. Таким образом, можно увидеть всю ответственность в проекте для данного функционального отдела (например, отдела информационных технологий или отдела закупок) в одном месте рядом с названием отдела. Иерархическая структура ресурсов (ИСР) — это другая разновидность иерархической диаграммы. Она используется для разбиения проекта по типам ресурсов. Например, ИСР может отобразить всех сварщиков и сварочное оборудование, используемое при строительстве судна, несмотря на то что они разбросаны по различным ответвлениям ОС или ИСР. ИСР может быть полезна при контроле стоимости проекта и может быть организована согласно бухгалтерской системе, действующей в организации. ИСР может содержать и иные категории ресурсов, чем человеческие ресурсы. Матричные диаграммы. Матрица ответственности (МО) используется для отображения связей между выполняемыми работами и членами команды проекта. В крупных проектах матрицы ответственности могут быть использованы на разных уровнях. Например, матрица ответственности высокого уровня может определять, какая группа или подразделение команды проекта отвечает за какой компонент в ИСР, в то время как матрицы ответственности более низких уровней используется внутри группы для распределения ролей, ответственности и уровней полномочий в конкретных операциях. Матричный формат, иногда также называемый табличным форматом, позволяет увидеть все операции, назначенные к выполнению определенному человеку, или отобразить всех людей, принимающих участие в выполнении определенной операции. На рис. 9-5 изображена матрица ответственности, называемая диаграммой RACI. Такое название она носит потому, что аббревиатура RACI составлена из первых букв названий документально зафиксированных ролей: Ответственный, Подотчетный, Проконсультироваться и Информировать (Responsible, Accountable, Consult, and Inform). На примере диаграммы в левой колонке указана выполняемая работа на уровне операций, но при помощи матрицы ответственности можно отобразить на разных уровнях. Имена могут обозначать как конкретных исполнителей, так и группы.
О = Ответственный П = Подотчетен К = Консультации И ~ Информирование Рисунок 9-5. Матрица ответственности (МО) в формате RACI Текстовые форматы. Для описания распределения ответственности, при котором нужны подробные описания, используются текстовые форматы. Обычно в таких документах в краткой форме содержится следующая информация: обязанности, полномочия и квалификация. Такие документы называют по-разному, например "описание позиции" или "форма роль- обязанности-полномочия". Из таких описаний и форм получаются прекрасные шаблоны для будущих проектов, особенно если в процессе исполнения проекта обновление информации происходит за счет накопленных знаний. Другие разделы плана управления проектом. Перечень и описание некоторых обязанностей, относящихся к управлению проектом, находится в других разделах плана управления проектом. Например, в реестре рисков перечислены лица, ответственные за риски, в плане управления коммуникациями содержится список членов команды, ответственных за операции по коммуникациям, а в плане управления качеством перечислены лица, ответственные за выполнение операций по обеспечению качества и контроля качества. 34. ТИПЫ СВЯЗЕЙ МЕЖДУ ОБЪЕКТАМИ И ФУНКЦИЯМИ. Одним из важных моментов при проектировании ИС с помощью методологии SADT является точная согласованность типов связей между функциями. Различают по крайней мере семь типов связывания:
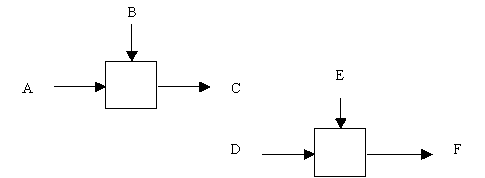
Ниже каждый тип связи кратко определен и проиллюстрирован с помощью типичного примера из SADT. (0) Тип случайной связности: наименее желательный. Случайная связность возникает, когда конкретная связь между функциями мала или полностью отсутствует. Это относится к ситуации, когда имена данных на SADT-дугах в одной диаграмме имеют малую связь друг с другом. Крайний вариант этого случая показан на рисунке 2.8.
Рис. 2.8. Случайная связность (1) Тип логической связности. Логическое связывание происходит тогда, когда данные и функции собираются вместе вследствие того, что они попадают в общий класс или набор элементов, но необходимых функциональных отношений между ними не обнаруживается. (2) Тип временной связности. Связанные по времени элементы возникают вследствие того, что они представляют функции, связанные во времени, когда данные используются одновременно или функции включаются параллельно, а не последовательно. (3) Тип процедурной связности. Процедурно-связанные элементы появляются сгруппированными вместе вследствие того, что они выполняются в течение одной и той же части цикла или процесса. Пример процедурно-связанной диаграммы приведен на рисунке 2.9.
Рис. 2.9. Процедурная связность (4) Тип коммуникационной связности. Диаграммы демонстрируют коммуникационные связи, когда блоки группируются вследствие того, что они используют одни и те же входные данные и/или производят одни и те же выходные данные (рисунок 2.10). (5) Тип последовательной связности. На диаграммах, имеющих последовательные связи, выход одной функции служит входными данными для следующей функции. Связь между элементами на диаграмме является более тесной, чем на рассмотренных выше уровнях связок, поскольку моделируются причинно-следственные зависимости (рисунок 2.11). (6) Тип функциональной связности. Диаграмма отражает полную функциональную связность, при наличии полной зависимости одной функции от другой. Диаграмма, которая является чисто функциональной, не содержит чужеродных элементов, относящихся к последовательному или более слабому типу связности. Одним из способов определения функционально-связанных диаграмм является рассмотрение двух блоков, связанных через управляющие дуги, как показано на рисунке 2.12.
Рис. 2.10. Коммуникационная связность
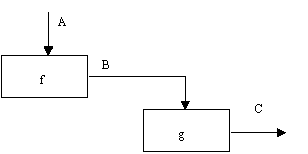
Рис. 2.11. Последовательная связность В математических терминах необходимое условие для простейшего типа функциональной связности, показанной на рисунке 2.12, имеет следующий вид: C = g(B) = g(f(A))Ниже в таблице представлены все типы связей, рассмотренные выше. Важно отметить, что уровни 4-6 устанавливают типы связностей, которые разработчики считают важнейшими для получения диаграмм хорошего качества.
Рис. 2.12. Функциональная связность
35. ИСПОЛЬЗОВАНИЕ ВНЕШНИХ СВЯЗЕЙ ПРИ ПРОЕКТИРОВАНИИ. Вне́шний ключ (англ. foreign key), или связь, — понятие теории реляционных баз данных, относящееся к ограничениям целостности базы данных. Неформально выражаясь, внешний ключ представляет собой подмножество атрибутов некоторой переменной отношения R2, значения которых должны совпадать со значениями некоторого потенциального ключа некоторой переменной отношения R1. Формальное определение. Пусть R1 и R2 — две переменные отношения, не обязательно различные. Внешним ключом FK в R2 является подмножество атрибутов переменной R2 такое, что выполняются следующие требования: 1. В переменной отношения R1 имеется потенциальный ключ CK такой, что FK и CK совпадают с точностью до переименования атрибутов (то есть переименованием некоторого подмножества атрибутов FK можно получить такое подмножество атрибутов FK’, что FK’ и CK совпадают как по именами, так и по типам атрибутов). 2. В любой момент времени каждое значение FK в текущем значении R2 идентично значению CK в некотором кортеже в текущем значении R1. Иными словами, в каждый момент времени множество всех значений FK в R2 является (нестрогим) подмножеством значений CK в R1. При этом для данного конкретного внешнего ключа FK → CK отношение R1, содержащее потенциальный ключ, называют главным, целевым, или родительским отношением, а отношение R2, содержащее внешний ключ, называют подчинённым, или дочерним отношением. Поддержка внешних ключей также называется соблюдением ссылочной целостности. Реляционные СУБД поддерживают автоматический контроль ссылочной целостности. 36. СОСТАВ ЛОГИЧЕСКОЙ И ФИЗИЧЕСКОЙ МОДЕЛИ RATIONALROSE. Rational Rose - CASE-средство фирмы Rational Software Corporation (США) - предназначено для автоматизации этапов анализа и проектирования ПО, а также для генерации кодов на различных языках и выпуска проектной документации [21]. Rational Rose использует синтез-методологию объектно-ориентированного анализа и проектирования, основанную на подходах трех ведущих специалистов в данной области: Буча, Рамбо и Джекобсона. Разработанная ими универсальная нотация для моделирования объектов (UML - Unified Modeling Language) претендует на роль стандарта в области объектно-ориентированного анализа и проектирования. Конкретный вариант Rational Rose определяется языком, на котором генерируются коды программ (C++, Smalltalk, PowerBuilder, Ada, SQLWindows и ObjectPro). Основной вариант - Rational Rose/C++ - позволяет разрабатывать проектную документацию в виде диаграмм и спецификаций, а также генерировать программные коды на С++. Кроме того, Rational Rose содержит средства реинжиниринга программ, обеспечивающие повторное использование программных компонент в новых проектах. Структура и функции В основе работы Rational Rose лежит построение различного рода диаграмм и спецификаций, определяющих логическую и физическую структуры модели, ее статические и динамические аспекты. В их число входят диаграммы классов, состояний, сценариев, модулей, процессов [21]. В составе Rational Rose можно выделить 6 основных структурных компонент: репозиторий, графический интерфейс пользователя, средства просмотра проекта (browser), средства контроля проекта, средства сбора статистики и генератор документов. К ним добавляются генератор кодов (индивидуальный для каждого языка) и анализатор для С++, обеспечивающий реинжиниринг - восстановление модели проекта по исходным текстам программ. Репозиторий представляет собой объектно-ориентированную базу данных. Средства просмотра обеспечивают "навигацию" по проекту, в том числе, перемещение по иерархиям классов и подсистем, переключение от одного вида диаграмм к другому и т. д. Средства контроля и сбора статистики дают возможность находить и устранять ошибки по мере развития проекта, а не после завершения его описания. Генератор отчетов формирует тексты выходных документов на основе содержащейся в репозитории информации. Средства автоматической генерации кодов программ на языке С++, используя информацию, содержащуюся в логической и физической моделях проекта, формируют файлы заголовков и файлы описаний классов и объектов. Создаваемый таким образом скелет программы может быть уточнен путем прямого программирования на языке С++. Анализатор кодов С++ реализован в виде отдельного программного модуля. Его назначение состоит в том, чтобы создавать модули проектов в форме Rational Rose на основе информации, содержащейся в определяемых пользователем исходных текстах на С++. В процессе работы анализатор осуществляет контроль правильности исходных текстов и диагностику ошибок. Модель, полученная в результате его работы, может целиком или фрагментарно использоваться в различных проектах. Анализатор обладает широкими возможностями настройки по входу и выходу. Например, можно определить типы исходных файлов, базовый компилятор, задать, какая информация должна быть включена в формируемую модель и какие элементы выходной модели следует выводить на экран. Таким образом, Rational Rose/С++ обеспечивает возможность повторного использования программных компонент. В результате разработки проекта с помощью CASE-средства Rational Rose формируются следующие документы: · диаграммы классов; · диаграммы состояний; · диаграммы сценариев; · диаграммы модулей; · диаграммы процессов; · спецификации классов, объектов, атрибутов и операций · заготовки текстов программ; · модель разрабатываемой программной системы. Последний из перечисленных документов является текстовым файлом, содержащим всю необходимую информацию о проекте (в том числе необходимую для получения всех диаграмм и спецификаций). Тексты программ являются заготовками для последующей работы программистов. Они формируются в рабочем каталоге в виде файлов типов .h (заголовки, содержащие описания классов) и .cpp (заготовки программ для методов). Система включает в программные файлы собственные комментарии, которые начинаются с последовательности символов //##. Состав информации, включаемой в программные файлы, определяется либо по умолчанию, либо по усмотрению пользователя. В дальнейшем эти исходные тексты развиваются программистами в полноценные программы. Взаимодействие с другими средствами и организация групповой работы Rational Rose интегрируется со средством PVCS для организации групповой работы и управления проектом и со средством SoDA - для документирования проектов. Интеграция Rational Rose и SoDA обеспечивается средствами SoDA. Для организации групповой работы в Rational Rose возможно разбиение модели на управляемые подмодели. Каждая из них независимо сохраняется на диске или загружается в модель. В качестве подмодели может выступать категория классов или подсистема. Для управляемой подмодели предусмотрены операции: · загрузка подмодели в память; · выгрузка подмодели из памяти; · сохранение подмодели на диске в виде отдельного файла; · установка защиты от модификации; · замена подмодели в памяти на новую. Наиболее эффективно групповая работа организуется при интеграции Rational Rose со специальными средствами управления конфигурацией и контроля версий (PVCS). В этом случае защита от модификации устанавливается на все управляемые подмодели, кроме тех, которые выделены конкретному разработчику. В этом случае признак защиты от записи устанавливается для файлов, которые содержат подмодели, поэтому при считывании "чужих" подмоделей защита их от модификации сохраняется и случайные воздействия окажутся невозможными. Среда функционирования Rational Rose функционирует на различных платформах: IBM PC (в среде Windows), Sun SPARC stations (UNIX, Solaris, SunOS), Hewlett-Packard (HP UX), IBM RS/6000 (AIX). Для работы системы необходимо выполнение следующих требований: · Платформа Windows - процессор 80386SX или выше (рекомендуется 80486), память8Mб (рекомендуется 12Mб), пространство на диске 8Mб + 1-3Mб для одной модели. · Платформа UNIX - память 32+(16*число пользователей)Mб, пространство на диске 30Mб + 20 при инсталляции + 1-3Mб для одной модели. Совместимость по версиям обеспечивается на уровне моделей. 37. СОЗДАНИЕ МОДЕЛИ КЛАССОВ И СВЯЗИ С ДРУГИМИ КЛАССАМИ И ОБЪЕКТАМИ. истема управления содержимым (CMS) обязана предоставить гибкие всеохватывающие функциональные возможности для управления содержимым сайта, облегчить работу администратора-конфигуратора и способствовать созданию удобного в использовании сайта. Содержимым сайта можно назвать новости, размещенные на нём, а также статьи, комментарии, фотографии. Содержимым также являются целые структуры информации: новостные ленты, каталоги, форумы, блоги. Обобщенно: содержимое – это данные, размещенные на сайте. CMS может просто передавать данные по запросу клиентскому приложению, например сетевой программе, flash-клипу или AJAX-приложению. Но чаще всего, CMS предоставляет клиенту уже подготовленные для отображения данные в HTML формате. В этом случаи, для обеспечения доступности, легкости восприятия и удобства пользования содержимым, выполняется стилизация и объединение его с элементами оформления (темы, шаблоны), навигации (меню, ссылки) и управления (формы и ссылки тоже), и всем этим тоже нужно управлять. Идея
Объекты, классы и связи данных – это информация, которую нужно уметь создавать, хранить, использовать, изменять и удалять. В нашем распоряжении реляционная база данных для хранения информации. Действия же совершаемые с информацией – часть логики функционирования CMS, которая в большей части будет реализована модулем данных Data. Речь идет о создаваемой CMS Boolive. Предыдущая статья про архитектуру CMS. Фактически модуль данных будет осуществлять объектно-реляционную проекцию (ORM) – предоставлять объектно-ориентрованный доступ к базе данных. При этом сущности объектной модели (классы, связи, объекты) будут определяться в базе данных, а не программно, что позволит, не программируя, создавать новые классы данных – новые типы содержимого. Чтобы не путаться с объектами и классами языка программирования, применяются термины «объект данных» и «класс данных» Для хранения однотипных объектов в реляционной базе данных в принципе достаточно одной таблицы, поля которой будут соответствовать атрибутам объекта. Но объекты могут иметь связи на другие объекты и чаще только их и имеют. Вместо того, чтобы в таблице объектов создавать поля (внешние ключи) для связи с другими объектами, лучше создать отдельную таблицу для связей – это, кстати, позволит хранить дополнительные сведения о связях, в частности, именование и их тип. Связь образует свойство у объекта, владеющего связью. Свойством называется совокупность связи и объекта, на который установлена связь. Атрибуты и свойства объектов определяются классом. Фактически же атрибуты определяются таблицей – её полями. Определение свойств у объектов можно реализовать наличием связей между соответствующими классами. Сами классы тоже нужно хранить, поэтому для них тоже нужно создать таблицу. По имени класса будет определяться таблица с его объектами. Каждая сущность (класс, объект и связь) должна иметь идентификатор – уникальное целое число, уникальное среди всех сущностей. То есть не должно быть, например, класса и объекта с одинаковым идентификатором. Уникальность идентификатора среди разнотипных сущностей позволяет, в частности, хранить связи классов в таблице вместе со связями объектов. Термин «сущность» подразумевает и объект, и класс, и связь. Одно из основных понятий объектной модели – наследование классов. Наследование тоже нужно представить в реляционном виде и это достаточно легко сделать, определив целочисленное поле в таблице классов для хранения идентификатора наследуемого класса (внешний ключ), и оперировать этой информацией для слияния соответствующих таблиц объектов при запросах. Если класс «B» наследует класс «A», то атрибуты объектов класса «B» будут храниться в таблице «А» и «Б». Классы являются объектами! Пока без объяснений. Так как класс – это объект, а у любого объекта имеется класс, значит и у класса есть класс, определяющий атрибуты для него, в частности имя и идентификатор наследуемого класса. Связи тоже являются объектами, соответственно и они имеют свой класс. Таким образом, всё является объектами, но чтобы не путаться с назначениями разнотипных объектов, в целях обобщения будет применяться термин «сущность». Реализация
Создаем второй класс с названием «class». Пока создание класса сводится к созданию таблицы. Создаем таблицу с именем «class» и полями «id», «sys_name», «extend», «final». Поле «id» используется для связи «один к одному» с таблицей сущностей, поле «id» используется логикой системы для слияния записей при реализации наследования. «sys_name» – это системное имя класса, совпадающее с именем таблицы, в которой будут храниться объекты соответствующего класса. «extend» – идентификатор наследуемого класса. «final» – признак возможности наследования класса (если 0). CREATE TABLE class ( `id` int(10) unsigned NOT NULL, `sys_name` VARCHAR(255) NOT NULL, `extend` int(10) unsigned NOT NULL default '1', `final` tinyint(1) unsigned NOT NULL default '0', PRIMARY KEY (`id`), UNIQUE `index_sys_name` (`sys_name`) );
Сейчас понять картину взаимосвязей будет непросто – это как случай с курицей и яйцом, типа, что было первым? В данном случае даже ошибочно рассказывать появление двух сущностей (классов) последовательно, так как они должны появиться одновременно и не могут существовать друг без друга. Созданы две таблицы – как бы созданы два класса, но именно как бы, так таблицы пусты – сущностей нет. Первая сущность – это базовый класс «id» называемый «сущность». От того, что сущность эта является классом, ассоциируемая с ней запись должна быть как в таблице «id» так и в таблице «class». Идентификатор первой сущности равен 1. Обратите внимание на системное имя класса – оно совпадает с именем таблицы «id». Вторая сущность тоже является классом, поэтому запись тоже и в таблице «id» и в таблице «class». Системное имя второго класса «class» совпадает с именем таблицы созданной для классов. Второй класс наследует первый – это определено в поле «extend». Второй класс запрещено наследовать.
Создадим теперь класс для связей. Класс-связь определяет атрибуты специфичные для связей: · «sys_name» – системное имя связи; · «define» – идентификатор связи, определяющей данную связь; · «kind» – признак вида связи: «использовать» или «состоять»; · «size» – признак мощности связи: «много» или «один»; · «is_define» – признак, что связь определяет связь между объектами; · «is_mandat» – признак, что связь обязательно должна быть у объекта; · «primary» – идентификатор сущности владельца связи; · «secondary» – идентификатор сущности, с которым выполняется связь. CREATE TABLE `link` ( `id` int(10) unsigned NOT NULL, `define` int(10) unsigned NOT NULL default '0', `sys_name` varchar(255) NOT NULL, `kind` tinyint(1) unsigned NOT NULL default '0', `size` tinyint(1) unsigned NOT NULL default '1', `is_mandat` tinyint(1) unsigned NOT NULL default '1', `is_define` tinyint(1) unsigned NOT NULL default '1', `primary` int(10) unsigned NOT NULL, `secondary` int(10) unsigned NOT NULL, PRIMARY KEY (`id`), KEY `index_define` (`define`), KEY `index_sys_name` (`sys_name`), KEY `index_primary` (`primary`), KEY `index_secondary` (`secondary`) );
Связи имеют двойное назначение, используемое логикой модуля Data. Первое назначение – непосредственная связь между объектами для реализации свойств, второе назначение – определение этих свойств классом. Класс, установкой связи с другим классом, определяет свойства для своих объектов. Но если рассматривать класс как объект, то он тоже может иметь свойства. Значит простым наличием связи между классами нельзя определить, что эта связь описывает свойство у объектов. Поэтому у связи имеются атрибуты «define» и «is_define». По атрибуту «define» можно найти связь между классами, определяющею данную связь. Атрибут «is_define» является признаком, принимающим значение 0, если это обычная связь между объектами и 1, если эта связь описывает свойство и применяется классом. Связи бывают двух видов: «использовать» (агрегация, ассоциация) или «состоять» (композиция, быть частью). Вид определяется атрибутом «kind». Объекты, связанные с другим объектом связью вида «состоять» и являющиеся подчиненными, будут зависеть от объекта-владельца связи. Зависимость сводится к тому, что удаляя главный объект, будут автоматически удаляться все подчиненные объекты связанные связью вида «состоять». Есть другие особенности, например объект не может «быть частью» более чем для одного объекта. Если бы не были бы оптимизированы связи объекта с классом и связь наследования у классов, то в общем счете было бы четыре вида связи. Вдобавок к описанным были бы связи вида «являться» и «наследует». Следующий важный атрибут связи – «size» (мощность), принимающий значение «много» или «один». Например, у статьи может быть несколько комментариев, что будет определяться множественным свойством. Этот атрибут используется связью класса, описывающей свойства для объектов. На самом деле статья будет иметь ровно столько связей, сколько комментариев должно быть с ней связано, но эти связи будут иметь одинаковые значения атрибутов, отличие только в идентификаторе и объекте (комментарии), с которым выполняется связывание. Ниже в таблице приведены примеры свойств объекта статьи (в скобках указана мощность связей). Атрибуты, кроме идентификатора, у статьи отсутствуют. Статья:
Атрибуты «primary» и «secondary» осуществляют уже непосредственную связь между сущностями по их идентификаторам – являются внешними ключами для связывания таблиц объектов. Само связывание выполняется логикой модуля Data.
|
Последнее изменение этой страницы: 2019-03-31; Просмотров: 604; Нарушение авторского права страницы