
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Непрерывные и дискретные системы автоматического управленияСтр 1 из 26Следующая ⇒
Непрерывные и дискретные системы автоматического управления Структурную схему системы автоматического управления (САУ) можно представить в следующем виде (рис. 1):
Рис. 1. В состав устройства управления входят корректирующее и вычитающее устройства. В процессе разработки системы автоматического управления решаются две основные задачи: 1. Синтез корректирующего устройства, результатом которого является передаточная функция корректирующего устройства; 2. Техническая реализация корректирующего устройства. Рассмотрим вопросы технической реализации корректирующего устройства на примере пропорционального регулятора (рис. 2):
Рис. 2. Вариант 1. Реализация в виде электронной схемы (например, на основе операционного усилителя, рис. 3). В этом случае значение управляющего сигнала
Рис. 3. Вариант 2. Реализация на основе специализированной ЭВМ (рис. 4):
Рис. 4. В этом случае собственно корректирующее устройство реализуется программно в виде алгоритма расчета значения управляющего сигнала
Рис. 5. Алгоритм работы корректирующего устройства Весь управляющий цикл состоит из ввода исходных данных для расчета, собственно расчета и вывода полученного значения управляющей величины. Работа алгоритма может быть представлена на временной оси (рис. 6):
Рис. 6. Так как реализация алгоритма представляет собой набор операций, а каждая операция выполняется внутри ЭВМ за конечное время, процессы ввода, расчета и вывода также занимают конечное время. Следовательно, значение управляющей величины
Рис. 7. То же самое можно сказать и о сигналах, вводимых в ЭВМ (рис. 8). Эти сигналы определены внутри ЭВМ лишь в дискретные моменты времени (на фазе ввода
Рис. 8. Системы, сигналы в которых определены лишь в отдельные дискретные моменты времени, называются дискретными системами(Система, сигналы в которой определены лишь в отдельные дискретные моменты времени). Все системы, в состав которых входит ЭВМ, являются дискретными. Таким образом, все системы автоматического управления в зависимости от варианта технической реализации блока управления (корректирующего устройства) можно подразделить на непрерывные и дискретные.
Рис. 1. Рис. 2. Перерегулирования нет, уменьшая постоянную времени Т мы можем добиться уменьшения времени переходного процесса. Теперь рассмотрим вариант дискретной организации блока управления. Так как значения управляющего сигнала
Рис. 3. Рассмотрим произвольно взятый интервал времени (рис. 4)
Рис. 4. Можем записать следующие соотношения: Для рассматриваемого временного отрезка можем записать дифференциальное уравнение: Рассмотрим различные варианты: Вариант 1. Таблица 1
В этом случае будем иметь некое подобие апериодического процесса (рис. 5).
Рис. 5. Вариант 2. Таблица 2
В этом случае будем иметь колебательный сходящийся (устойчивый) процесс (рис. 6)
Рис. 6. Вариант 3. Таблица 3
В этом случае будем иметь колебательный расходящийся (неустойчивый) процесс (рис. 7)
Рис. 7. Таким образом, мы видим, что в цифровой системе устойчивость, точность и качество управления зависят от параметров системы, и прежде всего, от значения На основании этого можно сделать вывод, что при использовании линейных алгоритмов управления, цифровая система всегда хуже непрерывной системы с точки зрения процесса управления. Одна из причин такого положения заключается в том, что в дискретной системе сигнал обратной связи вводится в дискретные моменты времени, следовательно в течение интервала времени Таблица 4
Таблица 5
Существует также зависимость эффективности непрерывной и дискретной реализации блока управления от сложности реализуемого алгоритма (рис. 8).
Рис. 8. Из графика видно, что по мере усложнения алгоритма, эффективность непрерывной системы уменьшается, так как возрастает число включенных в нее электронных элементов, а следовательно, усложняется конструкция, увеличиваются масса, габариты, стоимость, уменьшается точность и общая надежность. Для дискретной же системы усложнение алгоритма приводит лишь к изменению программы, что не влияет ни на массу и габариты, ни на стоимость технической реализации, так как не меняется конструкция самого блока управления. Правда, при дальнейшем усложнении алгоритма наступает критический момент, когда эффективность дискретной системы резко падает. Это связано с чрезмерным усложнением программы, сложностью ее отладки и уменьшением общей надежности системы. Вывод: Дискретная система управления имеет два основных преимущества по сравнению с непрерывной системой: 1. Простота модернизации (изменения алгоритма); 2. Большая эффективность при использовании сложных (нелинейных, адаптивных) алгоритмов управления. Системы счисления Система счисления — способ представления количественных величин с помощью специальных знаков, например цифр. Наиболее распространены позиционные системы счисления. В позиционной системе счисления любое число может быть представлено в виде
В повседневной жизни мы используем десятичную систему счисления, для которой Пример 1
Максимальное число, которое может быть представлено
Система с основанием 2 ( Попробуем определить, какая система счисления (по какому основанию) наиболее эффективна с точки зрения представления данных. Итак, пусть мы имеем систему счисления с основанием
Для представления числа внутри ЭВМ необходимо определенное количество элементов. Оно может быть оценено по следующей формуле:
Будем оценивать эффективность различных систем счисления с точки зрения представления информации внутри ЭВМ в сравнении с двоичной системой счисления, то есть в качестве критерия эффективности будем использовать
Если показатель Таблица 1
Из таблицы видно, что система счисления по основанию 3 более эффективна, однако она не нашла применения по причине сложности реализации запоминающих устройств, которые должны были бы в этом случае состоять из запоминающих элементов, имеющих три состояния. Таким образом, двоичная система представляется наиболее эффективной для хранения информации внутри ЭВМ с учетом относительной простоты ее технической реализации. Большое распространение получила также шестнадцатеричная система счисления ( Таблица 2
При записи числа с использованием шестнадцатеричной системы счисления, на конце числа обычно ставится буква h, при записи в двоичной — буква b. например 1000 — число в десятичной системе счисления, 1000h — в шестнадцатеричной, 1000b — в двоичной. Рис. 1. Известны координаты точки в системе координат
Таким образом, задача преобразования координат сведена к выполнению элементарных арифметических операций (сложение, вычитание, умножение, деление). Пример 2. Пропорциональный регулятор (рис. 2).
Рис. 2.
В результате получим следующую схему интегрирования: Эта задача также сводится к простейшим арифметическим операциям. Рис. 3. Микропроцессор состоит из трех основных функциональных блоков: · Арифметическо-логическое устройство (АЛУ). Выполняет простейшие арифметические и логические операции над данными, представленными в двоичном коде, то есть занимается собственно обработкой данных. · Внутреннее запоминающее устройство (ВЗУ). Предназначено для временного хранения данных в процессе обработки. · Устройство управления микропроцессора управляет процессом обработки данных и самим микропроцессором. Рис. 1. В состав МПС входят следующие блоки: · Микропроцессор (МП) — выполняет обработку информации и управляет работой МПС. · Запоминающее устройство(ЗУ) — служит для хранения информации (прежде всего программы), а также других данных, используемых в процессе расчетов, или результатов расчетов. · Устройство ввода-вывода (УВВ) предназначено для организации обмена информацией между МПС и другими устройствами (датчиками, усилителями, устройствами ввода и т.п.). УВВ может отсутствовать в МПС, наличие ЗУ и микропроцессора является обязательным. Внешние линии связи предназначены для передачи информации за пределы микропроцессорной системы и приема информации от внешних устройств.
Понятие обмена данными Обмен данными (информацией) — передача данных от одного устройства к другому в МПС. Передача одной порции данных называется циклом обмена. Минимальной единицей информации является бит, соответствующий одному двоичному разряду. 8 бит (8 двоичных разрядов) образуют байт. 210 байт = 1 килобайт 220 байт = 1 мегабайт Машинное слово — объем данных, который может быть обработан микропроцессором как единое целое. Размер машинного слова соответствует разрядности микропроцессора, то есть для 8-ти разрядного МП машинное слово составляют 8 бит, для 16-ти разрядного — 16 бит и т.д.
Рис. 1.
Рис. 2. Существуют два основных способа передачи данных: параллельный и последовательный. При параллельном способе двоичное число передается одновременно по нескольким параллельно идущим линиям связи (проводникам). Количество линий связи равно количеству разрядов в передаваемом двоичном числе. При последовательном способе биты, составляющие двоичное число, передаются последовательно, один за одним, по одной линии связи (одному проводнику). К достоинствам параллельного способа передачи данных следует отнести высокую скорость (так как все биты передаются одновременно). Однако в параллельно идущих проводниках возникают перекрестные помехи, и при большой длине линии связи эти помехи становятся весьма ощутимыми. То есть, при передаче данных параллельным способом на большие расстояния высока вероятность искажения передаваемых данных. Поэтому этот способ применяется при передаче данных на небольшие расстояния (до нескольких метров). При последовательной передаче данных возможна передача на большие расстояния, так как проводник один и взаимовлияние отсутствует. Одну линию связи легче (и дешевле) продублировать — это тоже достоинство последовательного способа. Недостаток — меньшая, чем в параллельном способе, скорость передачи данных и более сложная конструкция аппаратных средств.
Управление обменом на примере параллельного способа обмена Управление обменом заключается в решении следующих задач: 1. Определение устройства, управляющего обменом; 2. Определение устройств, участвующих в обмене; 3. Определение направления обмена; 4. Определения момента начала и окончания обмена; 5. Контроль правильности передачи данных. В МПС обмен всегда происходит между двумя устройствами: ведущим(активным) и ведомым (пассивным), рис. 1.
Рис. 1. Обменом всегда управляет ведущее устройство. Ведущим устройством в микропроцессорной системе всегда является микропроцессор (за исключением обмена по методу прямого доступа в память). Таким образом, одним из устройств, участвующих в обмене, является МП. Другим устройством может быть ЗУ илиУВВ. Запоминающее устройство может быть представлено в виде набора регистров (ячеек), в которых хранится информация (рис. 2)
Рис. 2. Обмен происходит между МП и одной из ячеек ЗУ. Следовательно, МП должен иметь возможность указания, с какой именно ячейкой ЗУ он будет выполнять обмен. Для этого каждая ячейка ЗУ имеет уникальный номер, который называется адресом. Перед началом обмена МП указывает адрес ячейки ЗУ, с которой он будет обмениваться, определяя таким образом второго участника обмена Устройство ввода-вывода также может быть представлено в виде набора регистров, в которых может храниться информация. Каждый такой регистр называется портом и может быть соединен с каким-либо внешним устройством — таким образом осуществляется передача данных между МПС и внешними по отношению к ней устройствами (датчиками, исполнительными элементами).
Рис. 3. Каждый порт ввода-вывода также имеет уникальный номер, называемый адресом. При обмене с устройством ввода-вывода МП указывает адрес порта, с которым он будет производить обмен данными. Так как обмен информацией всегда осуществляется между двумя устройствами — ведущим и ведомым, информация может передаваться либо от ведомого к ведущему, либо наоборот. Передача данных от ведущего устройства к ведомому называется записью информации. Передача данных от ведомого к ведущему — чтением (рис. 4, рис. 5).
Рис. 4.
Рис. 5. Для указания направления передачи данных (запись или чтение) используются специальные управляющие сигналы (передаваемые по специальным управляющим линиям связи): "разрешение чтения" (RD)и "разрешение записи" (WR) (рис. 6).
Рис. 6. Горизонтальная черта над обозначением сигналов означает, что активным уровнем для данного сигнала является логический "0". То есть, если сигнал WR находится в состоянии логического нуля выполняется запись данных (передача от ведущего к ведомому). Если сигнал RD находится в состоянии логического нуля выполняется чтение данных (передача от ведомого к ведущему). Естественно, одновременно эти сигналы находится в состоянии логического "0" не могут. Таким образом, перед началом обмена, ведущее устройство, которое управляет обменом, переводит соответствующий сигнал в состояние логического "0", определяя таким образом направление обмена. Иногда вместо двух сигналов используется один (RD/WR). Значение логического "0", принимаемое этим сигналом, соответствует записи информации, логической "1" — чтению (рис. 7).
Рис. 7. Начало и окончание обмена могут определяться двумя способами. Способ 1. Для определения момента начала и окончания обмена используются сигналы, задающие направление обмена (RD и WR). Передний фронт сигнала соответствует моменту начала обмена, задний — моменту окончания обмена (рис. 8).
Рис. 8. Способ 2. Использование специального управляющего сигнала (рис. 9).
Рис. 9.
Методы обмена С точки зрения организации обмена между ведущим и ведомым устройствами существуют несколько методов обмена. Синхронный обмен. При синхронном обмене ведущее устройство не анализирует готовность ведомого устройства, предполагая, что ведомое устройство всегда готово к обмену. Такой метод обмена применим в случае, если ведомое и ведущее устройства обладают примерно одинаковым быстродействием. Асинхронный обмен. Если ведомое устройство имеет меньшее быстродействие, или оно бывает готово к обмену лишь в определенные моменты времени, необходимо перед началом обмена убедится в его готовности к обмену информацией с ведущим устройством. Принцип асинхронного обмена иллюстрируется рис. 1.
Рис. 1. Для проверки готовности используется специальная управляющая линия READY. Сигнал логической "1" на ней свидетельствует о готовности ведомого устройства. Ведущее устройство анализирует состояние линии перед началом обмена. Обмен по прерываниям. Недостаток асинхронного метода заключается в том, что если ведомое устройство в течение длительного времени не готово, ведущее "простаивает", теряя время в цикле проверки готовности. От такого недостатка можно было бы избавиться, если бы ведомое устройство имело возможность сообщать ведущему о своей готовности в произвольный момент времени и тем самым вынуждать его к началу обмена. По такому принципу работает обмен по прерываниям (рис. 2).
Рис. 2. В момент, когда ведомое устройство готово к обмену, оно посылает ведущему специальный сигнал — "запрос на прерывание". Ведущее (микропроцессор) прерывает выполнение основной программы и начинает выполнение специальной подпрограммы обработки прерывания. Подпрограмма обработки прерывания и выполняет собственно обмен. По окончании выполнения подпрограммы, ведущее устройство возвращается к выполнению основной программы. Использование обмена по прерываниям позволяет ведомому устройству самому выступать инициатором обмена. При этом пока ведомое не готово, ведущее устройство может заниматься своими делами, не тратя время на периодическую проверку сигнала готовности. Таким образом, применение обмена по прерываниям целесообразно в тех случаях, когда быстродействие ведущего и ведомого устройств сильно различаются или если обмен с ведомым устройством может происходить в случайные моменты времени.
Рис. 1. Часто для передачи адреса и данных используют одни и те же линии связи, передавая по ним сначала адрес, потом данные с разделением во времени. Такое конструктивное решение получило название мультиплексированная шина адреса-данных (рис. 2).
Рис. 2. Для определения момента времени, в который происходит передача адреса, служит сигнал "строб адреса" — на время передачи адреса по мультиплексированной шине он переводится в состояние логической "1". С учетом всего вышеизложенного, временная диаграмма синхронного параллельного обмена (при использовании мультиплексированной шины адреса-данных) будет выглядеть следующим образом (рис. 3).
Рис. 3.
Рис. 1. Это означает, что на передачу одного бита информации отводится интервал времени В последовательном обмене всегда участвуют два устройства: приемник и передатчик (рис. 2).
Рис. 2. Данные передаются от передатчика (он формирует на линии напряжение) к приемнику (он анализирует напряжение на линии). Таким образом, участники обмена всегда определены заранее путем соответствующего подключения линии связи. Различают три основных разновидности последовательного обмена: 1. Симплексный обмен. Данные передаются только в одном направлении. 2. Полудуплексный обмен. Данные могут передаваться в обоих направлениях, но не одновременно (поочередно). 3. Дуплексный (полнодуплексный) обмен — данные могут передаваться одновременно в обоих направлениях. Существуют два основных способа управления последовательным обменом: синхронный и асинхронный. При синхронном последовательном обмене, по линии связи передаются только данные в формате, представленном на рис. 1. Порция данных, передаваемая передатчиком за один прием, называется символом. Как правило, символ содержит от 5 до 8 бит информации. При последовательном синхронном обмене информация о моменте начала передачи поступает в передатчик и приемник одновременно от некоего внешнего источника (рис. 3)
Рис. 3. Приемник и передатчик одновременно (синхронно) начинают работать. После начала передачи данные передаются непрерывно. Момент окончания передачи не оговаривается. Недостатком синхронного способа обмена является возможность рассинхронизации приемника и передатчика. Как следует из рис. 1, каждый бит передается в течение времени Выходом из положения могла бы стать передача по второй линии связи тактовых импульсов передатчика приемнику. Однако такой способ не дает ощутимых результатов при передаче на значительные расстояния, так как в линии передачи синхроимпульсов возникают искажения, приводящие опять же к рассинхронизации. Таким образом, синхронная последовательная передача имеет ряд недостатков: 1. Сложность синхронизации начала и окончания передачи. 2. Постепенная рассинхронизация приемника и передатчика. Асинхронный метод последовательного обмена был разработан с целью устранения указанных недостатков. При асинхронном обмене информация передается кадрами, каждый кадр состоит из информационных бит, образующих символ, и служебных бит, определяющих момент начала и окончания передачи символа (рис. 4)
Рис. 4. При отсутствии передачи, на линии поддерживается состояние логической "1". Стартовый бит всегда имеет значение логического "0". Таким образом, переход линии из состояния "1" в состояние "0" (передача стартового бита) является признаком начала передачи данных. По началу стартового бита производится синхронизация приемника и передатчика, таким образом, при асинхронном последовательном обмене синхронизация приемника и передатчика происходит в начале передачи каждого кадра. Стоп-бит всегда имеет значения логической "1". Он как бы возвращает линию в состояние отсутствия передачи. Длительность передачи стопового бита может быть По сравнению с синхронным методом, асинхронный имеет меньшую скорость передачи данных, так как кроме собственно информационных приходится передавать еще и служебные биты.
Рис. 1. Собственно алгоритм обнаружения ошибок выглядит следующим образом: Действия передатчика 1. Бит паритета устанавливается в "0" 2. Подсчитывается количество единиц во всех информационных битах 3. Значение бита паритета устанавливается таким, чтобы полученная сумма плюс бит паритета была четной Действия приемника 1. Подсчитывается количество единиц во всех принятых информационных битах полюс бит паритета. 2. Если полученная сумма является четной, данные приняты без искажений, в противном случае имела место ошибка. Достоинством данного метода является его простота. Недостатком — то, что он может определить состояние ошибки, только если искажению подверглось нечетное количество бит. При искажении, например, двух бит в символе, данный метод не выявит ошибки. Тем не менее, он получил очень широкое распространение и реализован на аппаратном уровне в большинстве современных асинхронных приемопередатчиков. Метод контроля четности может быть использован также и при параллельной передаче данных, если это необходимо. В этом случае необходимо использовать дополнительную линию связи для передачи бита паритета.
Рис. 1. Пакет состоит из отдельных символов, а символ состоит из определенного числа бит. В начале пакета находятся стартовые символы, которые имеют фиксированное значение. Они определяют момент начала передачи пакета и позволяют выполнить синхронизацию приемника с передатчиком аналогично варианту асинхронной передачи. Далее идут информационные символы, в которых отсутствуют служебные биты. Далее — контрольные символы, содержащие информацию, позволяющую проверить правильность передачи информационных символов. Стоп-символы имеют также фиксированное значение и прием последнего стоп-символа определяет момент окончания передачи пакета. При таком способе с одной стороны отсутствуют служебные биты в каждом символе (т.е. сохраняется высокая скорость передачи данных), с другой стороны существует возможность синхронизации передатчика и приемника. Данный способ является своеобразным "гибридом" синхронной и асинхронной передачи.
Рис. 1. Следовательно, необходима процедура согласования между двумя парами "приемник-передатчик" для определения права на занятие линии связи и недопущения одновременного занятия линии двумя передатчиками. Для решения этой задачи используются два дополнительных управляющих сигнала: RTS (Request To Send — запрос на передачу данных) и CTS (Clear To Send — разрешение передачи данных). Устройство, желающее начать передачу данных, устанавливает активным сигнал RTS. Второе устройство, если оно освободило линию и готово к приему, устанавливает в ответ сигнал CTS. Таким образом, в полудуплексном обмене передача может начаться только при получении активного сигнала CTS от устройства, находящегося на другом конце линии.
Управление потоком данных При передаче данных по последовательному каналу возможна ситуация, когда быстродействие приемника меньше, чем быстродействие передатчика. При этом возможна ситуация, когда передаваемые по каналу связи данные не могут быть своевременно приняты приемником, что грозит потерей данных. В таком случае возникает необходимость приостановки передачи данных передатчиком по сигналу от приемника. Решение данной задачи получило название управление потоком данных. Управление потоком предполагает посылку приемником уведомления о невозможности приема данных. Существуют два варианта управления потоком -- аппаратное и программное. Аппаратное управление потоком (RTS/CTS, Hardware Flow Control) использует два дополнительных управляющих сигнала: RTS и CTS. Сигнал CTS (от приемника к передатчику) позволяет приостановить передачу данных, если приемник не готов к их приему. Передатчик "выпускает" очередной байт только при наличии активного сигнала на линии CTS. Байт, который уже начал передаваться, задержат сигналом CTS невозможно. Аппаратный протокол обеспечивает самую быструю реакцию передатчика на состояние приемника (рис. 1).
Рис. 1. Если аппаратный протокол не используется, на стороне передатчика необходимо обеспечить постоянную подачу на вход CTS активного сигнала, в противном случае передатчик будет "молчать". Программное управление потоком (XON/XOFF, Software Flow Control) предполагает наличие двунаправленного канала передачи данных. Работает протокол следующим образом: если устройство, принимающее данные, обнаруживает причины, по которым оно не может их дальше принимать, оно по обратному последовательному каналу посылает байт-символ XOFF (13h). Противоположное устройство (передатчик), приняв этот символ, приостанавливает передачу. Когда принимающее устройство снова становится готово к приему данных, оно посылает символ XON (11h), приняв который передатчик возобновляет передачу. Время реакции передатчика на изменение состояния приемника, по сравнению с аппаратным протоколом, увеличивается, по крайней мере, на время передачи символа (XON или XOFF). Следовательно, данные без потерь могут приниматься только приемником, имеющим дополнительный буфер принимаемых данных и сигнализирующим о неготовности заблаговременно. Преимущество программного протокола заключается в отсутствии необходимости передачи управляющих сигналов (уменьшение количества проводов в кабеле). Недостатком, кроме требования наличия буфера и большого времени реакции, является сложность реализации полудуплексного режима обмена.
Рис. 1. Недостаток такого способа заключается в том, что если передается длинная последовательность нулей, сложно детектировать обрыв линии, так как картина в обоих случаях будет одинаковой — отсутствие напряжения на линии. Способ 2. Код NRZ (Not Return no Zero, однополярный код) (рис. 2).
Рис. 2. Недостаток такого способа — при большой длине линии за счет ее активного сопротивления, Способ 3. Двуполярный код (рис. 3).
Рис. 3. Двуполярный код лишен вышеупомянутого недостатка, присущего однополярному коду, но более сложен в технической реализации. Способ 4. Код "Манчестер II" В коде "Манчестер II" синхросигнал передается вместе с данными (рис. 4).
Рис. 4. Код "Манчестер II" формируется на основе сихросигнала, задающего период и информационного сигнала в коде NRZ. Передача "0" или "1" кодируется направлением изменения напряжения. Таким образом, сигнал в коде "Манчестер II" всегда содержит информацию о периоде следования синхроимпульсов. Принцип технической реализация передачи с использованием кода "Манчестер II" иллюстрируется рис. 5
Рис. 5. На стороне передатчика синхросигнал выделяется и используется для получения данных из сигнала в коде NRZ. При этом устраняется возможность рассинхронизации приемника и передатчика за счет того, что приемник использует синхроимпульсы, формируемые тактовым генератором передатчика. Недостатком данного способа является сложность его технической реализации. Способ используется в тех случаях, когда необходимо обеспечить высокую надежность передачи информации. Часто применяется при передаче данных с датчиков.
Рис. 1. Аппаратные средства включают в себя: микропроцессор, запоминающее устройство, устройства ввода вывода, вспомогательные устройства и линии связи между ними. Программные средства включают систему команд микропроцессора, а также средства для разработки программ, по которым работает микропроцессорная система (в том числе трансляторы). Аппаратные средства Архитектура микропроцессора — описание устройства микросхемы в виде крупных структурных единиц (блоков). Интерфейс микропроцессора — описание выводов микросхем и правил изменения сигналов на них. Микропроцессорный комплект — набор микросхем, совместимых друг с другом с точки зрения интерфейса. Совместимость с точки зрения интерфейса предполагает логическую и физическую совместимость. Логическая совместимость — совместимость с точки зрения состава и назначения выводов. Например, на рис. 2 представлены две логически совместимые микросхемы — они имеют одинаковые выводы для управления обменом.
Рис. 2. На рис. 3 представлен пример двух микросхем, интерфейсы которых логически несовместимы
Рис. 3. Под физической совместимостью интерфейсов понимается одинаковость их электрических параметров (уровни напряжений, способ кодирования логических "0" и "1"). Изучение аппаратных средств МПС предполагает изучение архитектуры и интерфейса входящих отдельных устройств, таких как МП, ЗУ, УВВ и вспомогательные устройства. Программные средства Работа программных средств строится по следующей схеме (рис. 4)
Рис. 4. При написании программы на языке высокого уровня, транслятор осушествляет ее перевод в команды микропроцессора. При этом перевод не всегда бывает оптимальным с точки зрения размера получаемого набора команд и быстродействия (времени выполнения программы). Это происходит вследствие того, что транслятор переводит выражения языка высокого уровня в команды микропроцессора по неким общим правилам без учета специфики конкретных участков программы, и программист не может воздействовать на процесс этого перевода. В некоторых случаях неоптимальность трансляции играет отрицательную роль (например, если важен размер результирующего машинного кода или его время его выполнения процессором). В этих случаях для составления исходной программы используется язык "Ассемблер", в котором каждый оператор соответствует одной строго определенной команде микропроцессора. Поскольку каждый микропроцессор имеет свою собственную систему команд, язык "Ассемблер" индивидуален для каждого МП. Так как "Ассемблер" тоже является языком программирования, программа написанная на нем также должна быть преобразована в команды микропроцессора с помощью транслятора. Но так как каждый оператор "Ассемблера" всегда преобразуется в одну определенную команду МП, программист, составляя программу на языке "Ассемблер", имеет возможность непосредственно определять результирующий набор команд, в который в конечном итоге будет преобразована программа. Однако программирование на "Ассемблере" является весьма трудоемкой задачей. Поэтому часто применяют комбинированный способ разработки программ: программа пишется на языке программирования высокого уровня (C, Pascal, Basic), а определенные части, для которых важна скорость выполнения, пишутся на языке "Ассемблер". Изучение программных средств МПС предполагает изучение системы команд МП (на примере какого-либо конкретного микропроцессора, так как системы команд разных МП различны). Изучение системы команд МП также удобно вести с использованием "Ассемблера", так как каждый оператор этого языка соответствует определенной команде МП.
Рис. 1. Устройство управления управляет работой микропроцессора, обменом с внешними устройствами и обработкой информации. В состав устройства управления входит уже известный нам дешифратор команд. Аккумулятор предназначен для временного хранения операндов или результатов операции. Если один из операндов хранится в аккумуляторе, операция выполняется максимально быстро. Аккумулятор представляет собой регистр, разрядность которого совпадает с разрядностью микропроцессора. Регистры общего назначения — набор регистров, предназначенных для временного хранения операндов, результатов операций или других данных. Вообще операнды, используемые в команде, могут храниться либо в одном из внутренних регистров микропроцессора, либо в запоминающем устройстве. Естественно, обращение к операндам, находящимся в ЗУ занимает больше времени. Поэтому часто используемые данные, результаты операций, используемые как операнды для последующих операций, хранятся во внутренних регистрах микропроцессора — аккумуляторе или регистрах общего назначения. Количество регистров общего назначение различно у разных МП. Способ задания местоположения операндов в команде называется методом адресации. Существуют следующие основные методы адресации: · Непосредственная адресация — значение операнда указывается в самой команде (в виде числа); · Прямая адресация — в команде указывается адрес ячейки ЗУ, в которой находится операнд; · Неявная адресация — местоположение операнда явно не указывается, но из описания операции известно, где он находится. · Регистровая адресация — операнд находится в одном из регистров общего назначения микропроцессора или в аккумуляторе. В команде указывается имя (номер, идентификатор) этого регистра. Регистр признаков (регистр "флагов") — регистр, каждый бит которого ("флаг") имеет собственное значение и содержит информацию об определенном событии, произошедшем или не произошедшем в процессе выполнения предыдущей команды. Наиболее важными "флагами" являются "флаг" нуля (ZF) и "флаг" знака (NF). "Флаг" нуля равен единице, если в результате предыдущей команды был получен ноль (нулевой результат). "Флаг" знака равен единице, если в результате выполнения предыдущей команды было получено отрицательное число. Эти "флаги" могут быть использованы для организации сравнения чисел. Например, необходимо проверить условие Счетчик команд хранит адрес следующей выполняемой команды. После загрузки очередной команды содержимое счетчика команд увеличивается таким образом, чтобы он опять указывал на следующую команду. При этом предполагается, что в ЗУ команды программы лежат последовательно друг за другом. Если же порядок выполнения команд изменяется (например, при вызове подпрограммы), адрес очередной команды заносится в счетчик команд с помощью специальной команды ветвления. При выполнении программы часто возникает такая специфическая ситуация, как вызов подпрограммы. При переходе к подпрограмме в счетчик команд записывается новое значение, соответствующее адресу первой команды подпрограммы. После окончания выполнения подпрограммы, должно быть продолжено выполнение основной программы. Таким образом, перед вызовом подпрограммы необходимо запомнить адрес следующей команды основной программы ("адрес возврата"), для того, чтобы загрузить его в счетчик команд ("восстановить счетчик команд") по окончании выполнения подпрограммы. При этом нужно учитывать, что вызовы подпрограмм могут быть "вложенными" (из первой вызывается вторая, из второй третья и так далее). Для сохранения адресов возвратов из подпрограмм используется специально организованное запоминающее устройство, называемой стеком. Стек организован по принципу "последним вошел — первым вышел". Схема работы стека при помещении в него информации представлена на рис. 2.
Рис. 2. Стек представляет собой набор ячеек (регистров), но запись нового числа ( Извлечение данных из стека происходит в обратном порядке (рис. 3). Извлечено может быть только число, находящееся в вершине стека. При его извлечении, находящиеся в стеке данные "продвигаются" вверх и следующее число занимает место в вершине стека и может быть извлечено из него.
Рис. 3. Стек может быть организован аппаратно или программно-аппаратно. Аппаратный стек — это специальным образом организованная группа регистров. При помещении данных в вершину стека, его содержимое физически "продвигается" путем перезаписи информации между регистрами. Работа аппаратного стека контролируется специальным блоком управления. Недостаток такого стека – аппаратная сложность и ограниченность объема данных, которые могут быть сохранены. В случае программно-аппаратного стека в качестве стека используется специально выделенная область основного запоминающего устройства. Одна из ячеек этой области является вершиной стека и ее адрес хранится в специальном регистре микропроцессора, называемом "указатель стека". Именно такой вариант является наиболее распространенным и представлен на рис. 1 При записи данных в стек, уже находящиеся там данные никуда не перемещаются, а "перемещается" вершина стека (путем изменения значения указателя стека), (см. рис. 4). Запись данных всегда происходит в ячейку, являющуюся в данный момент вершиной стека, адрес которой хранится в указателе стека.
Рис. 4. При извлечении данных из стека указатель перемещается в обратном направлении (рис. 5). Чтение данных всегда происходит из ячейки, являющейся вершиной стека.
Рис. 5. Недостаток программно-аппаратного стека — большее, чем в случае просто аппаратного стека, время, необходимое для записи/извлечения данных. Объясняется это необходимостью обращения к основному ЗУ при каждой операции со стеком. Достоинства — простота аппаратной реализации и отсутствие жестких ограничений на размер стека (фактически его размер ограничен только размером основного ЗУ). Использование стека для хранения адресов возвратов из подпрограмм позволяет получать адреса возврата в порядке, обратном их помещению. И таким образом обеспечить корректный возврат из подпрограмм даже в случае вложенных вызовов. В большинстве современных процессоров основной стек, доступный программам, имеет программно-аппаратную реализацию. Соответственно, МП имеет в своем составе регистр-указатель стека. Аппаратный стек применяется в специализированных процессорах Таким образом, мы рассмотрели обобщенную архитектуру микропроцессора, включающую в себя АЛУ, УУ с ДШК, аккумулятор, РОН, счетчик команд, регистр флагов и указатель стека.
Рис. 1. Каждая шина состоит из нескольких проводников (линий связи), идущих параллельно. Разрядность шины данных определяется разрядностью микропроцессора. Разрядность шины адреса определяется разрядностью адреса, используемого в данном микропроцессоре, и может отличаться от разрядности шины данных. Количество же линий в шине управления зависит от микропроцессора и способа организации в нем обмена с другими устройствами, входящими в состав МПС. Обобщенный интерфейс микропроцессора представлен на рис. 2.
Рис. 2. Он включает шину данных (в данном случае для примера — 16-ти разрядную), 16-разрядную шину адреса и шину управления, в которую входят сигналы, предназначенные для управления обменом в параллельном формате. Для реализации асинхронного обмена предусмотрен сигнал проверки готовности READY, с помощью которого ведомое устройство сообщает микропроцессору о своей готовности к обмену. Часто с целью уменьшения количества выводов микропроцессора, для передачи адреса и данных используют одни и те же линии. При этом передача адреса и данных происходит в разные моменты времени (разделение во времени). Такой способ организации шины получил название мультиплексированная шина адреса-данных (рис. 3)
Рис. 3. Сигнал ALE, входящий в состав шины управления, показывает, в какой момент времени по мультиплексированной шина передается адрес (рис. 4).
Рис. 4. На рисунке представлена временная диаграмма цикла асинхронного обмена (на примере операции чтения из внешнего устройства). Как видно, обмен начинается с выставления адреса на шине адреса. Сигнал ALE показывает, что по мультиплексированной шине передается адрес. Затем устанавливается направление обмена с помощью сигнала RD, и сигнал начала обмена DEN переходит в активное состояние. Далее происходит анализ готовности ведомого устройства. Если устройство не готово (сигнал READY=0), микропроцессор переходит в состояние ожидания. После активизации сигнала готовности происходит собственно ввод данных, предоставленных по шине данных ведомым устройством. Для организации обмена по прерываниям в интерфейсе микропроцессора должны быть предусмотрены специальные управляющие сигналы (они входят в состав шины управления), (см. рис. 5).
Рис. 5. Сигнал INT — запрос на прерывание от внешнего устройства. Сигнал INTA — подтверждение прерывания (микропроцессор этим сигналом сообщает внешнему устройству, что он готов обработать запрос). Сигнал NMI — запрос немаскируемого прерывания, аналогичен сигналу INT. Немаскируемое прерывание обрабатывается микропроцессором всегда, в то время как обработка обычных прерываний (по входу INT) может быть запрещена (с помощью специальной команды) на время выполнения критических участков программы. Ко входу запроса немаскируемого прерывания обычно подключаются сигналы, информирующие МП о событиях, имеющих жизненно важное значение для работы МПС (например, сигнал о понижении напряжения питания — микропроцессор должен принять немедленные меры для сохранения данных). Временная диаграмма изменения сигналов запроса/подтверждения прерывания приведена на рис. 6.
Рис. 6. Временной разрыв между активизацией сигналов INT и INTA вызван необходимостью завершения текущей команды микропроцессором. В дополнении к указанным сигналам, на микропроцессор обязательно подаются тактовые импульсы от тактового генератора, которые позволяют синхронизировать работу всех узлов процессора (рис. 7).
Рис. 7. Для подачи импульсов служит вход CLK микропроцессора.
Рис. 1. Действие по обработке информации называется операцией, например:
В качестве примера описания операции в виде последовательности простейших действий рассмотрим сложение двоичных чисел на примере одного разряда двоичного числа (рис. 2)
Рис. 2. Представим операцию в следующем виде (рис. 3)
Рис. 3. Здесь Рассматриваемая операция может быть представлена таблицей: Таблица 1
Таким образом, операция сложения одного двоичного разряда сводится к поиску по указанной таблице выходных значений Команда — указание микропроцессору выполнить некоторое действие. Команда должна включать информацию об операндах и описание самой операции, которую необходимо выполнить. Структура команды получила название "формат команды" (рис. 4).
Рис. 4. Так как описание операции может быть достаточно громоздким, нецелесообразно иметь его непосредственно в составе команды. Учитывая, что каждый микропроцессор способен выполнить ограниченное количество операций, каждой операции может быть присвоен числовой код — код операции (КОП). В самой команде при этом можно указывать только этот код, который будет характеризовать операцию (рис. 5).
Рис. 5. В составе микропроцессора необходимо иметь блок, который по коду операции будет определять собственно ее описание — последовательность элементарных действий, которые должны быть выполнены. Такой блок называется дешифратором команд и входит в состав устройства управления микропроцессора (рис. 6).
Рис. 6. Дешифратор команд можно представить в виде таблицы из двух столбцов, в одном из них — код операции, в другом – ее описание. Получив очередную команду, блок управления обращается к дешифратору команд, передает ему код операции и получает описание операции в виде последовательности элементарных действий, которые затем выполняются. Вся совокупность команд, которая может выполняться микропроцессором, называется системой команд. В систему команд входит ограниченное число команд. Естественно, все они должны быть представлены в дешифраторе команд — микропроцессор не может выполнить команду, код которой неизвестен дешифратору. Таким образом, преобразование, представленное на рис. 1 представляет собой преобразование программы, написанной на языке программирования, в последовательность команд микропроцессора. Оно называется трансляцией и выполняется специальной программой — транслятором. Трансляторы подразделяются на компиляторы (преобразуют сразу всю программу) и интерпретаторы (выполняют построчное преобразование и исполнение программы).
Рис. 1. Матрица ячеек состоит из вышеупомянутых регистров — ячеек, каждый из которых состоит из триггеров. При поступлении адреса, дешифратор адреса "активизирует" одну из ячеек. В зависимости от направления передачи информации (чтение или запись) выбранная ячейка подключается к входному или выходному буферу. Буферы представляют собой электронные усилители. Естественно, в случае ПЗУ входной буфер отсутствует. Блок управления управляет работой микросхемы, к нему подключены уже знакомые нам сигналы управления обменом RD и WR. Сигнал CS называется "сигналом выбора микросхемы", он необходим для выборочного обращения к отдельной микросхеме при наличии нескольких микросхем в составе ЗУ. Микросхема воспринимает сигналы на входах адреса, данных и управления только если сигнал CS находится в активном состоянии. Если сигнал CS неактивен, все входы и выходы микросхемы переводятся в высокоомное состояние, что эквивалентно отключению их от линий связи. Временная диаграмма чтения из ЗУ представлена на рис. 2.
Рис. 2. Желая прочитать данные из ячейки ЗУ, микропроцессор устанавливает на шине адреса адрес этой ячейки, активизирует управляющий сигналы RD и CS. После перехода в активное состояние сигнала RD микросхема ЗУ выдает данные, хранившиеся в выбранной ячейке ЗУ на шину данных через выходной буфер. Временная диаграмма записи в ЗУ представлена на рис. 3.
Рис. 3. Для выполнения записи данных в определенную ячейку ЗУ, МП устанавливает ее адрес на шине адреса и выдает сами данные на шину данных. После этого он активизирует сигналы WR и CS. После перехода сигнала WR в активное состояние, информация, установленная МП на шине данных, через входной буфер вводится в микросхему ЗУ и записывается в ячейку с указанным адресом. Рис. 1. Параллельный программируемый интерфейс Буфер шины данных — усилитель, предназначенный для подключения к шине данных МПС. Устройство управления управляет работой параллельного порта. К устройству управления подходят управляющие сигналы RD, WR, CS. Порт представляет собой регистр и усилитель, обеспечивающий подключение к разрядам регистра внешних линий связи. При работе порта в режиме вывода данных, информация, содержащаяся в регистре, выдается на линии порта в виде соответствующих напряжений. При работе порта в режиме ввода данных, внешнее устройство устанавливает на линиях порта напряжения, соответствующие передаваемым данным, при этом в регистре порта устанавливаются значения, соответствующие этим напряжениям, т.е. передаваемые данные. Регистр управления содержит данные, определяющие режим работы параллельного интерфейса (например, направление передачи данных через порт — ввод или вывод). Настройка интерфейса на требуемый режим работы (программирование) осуществляется путем записи соответствующего значения в регистр управления. Эта запись выполняется микропроцессором перед началом работы с УВВ. Адресные линии (A0, A1) необходимы для выбора внутреннего регистра, в который будет происходить запись (чтение) информации при выполнении цикла обмена с МП. В представленном на рисунке примере имеются только два внутренних регистра — сам порт и регистр управления. Часто в одной микросхеме помещают несколько портов. Временная диаграмма записи данных а параллельный порт представлена на рис. 2.
Рис. 2. Микропроцессор устанавливает соответствующее значение адреса на шине адреса и данные на шине данных. После активизации сигнала разрешения записи WR данные с шины данных записываются в регистр-порт и выдаются на внешние линии связи (выходы порта). На этих выходах данные будут существовать до тех пор, пока новые данные не будут записаны в порт. Временная диаграмма чтения данных из порта представлена на рис. 3.
Рис. 3. Микропроцессор устанавливает соответствующее значение адреса на шине. После активизации сигнала разрешения чтения RD данные из регистра-порта (соответствующие напряжениям на входах порта) поступают на шину данных. Внешнее устройство, разумеется, должно установить данные на линиях порта до начала указанной процедуры чтения. Запись данных в регистр управления (программирование интерфейса) происходит аналогично записи данных в регистр – порта (рис. 2), при этом на шине адреса устанавливается адрес, соответствующие регистру управления, а данные на линиях порта, естественно, не изменяются.
Рис. 1. Последовательный программируемый интерфейс Такое устройство называется последовательным программируемым интерфейсом (последовательным портом). Часто применяют также аббревиатуру УАПП — универсальный асинхронный приемопередатчик. Приемник осуществляет прием информации в последовательном формате с линии (вход RxD). Данные из последовательного формата преобразуются в параллельный и формируется символ. Принятый символ помещается во входной буфер и может быть прочитан микропроцессором. Если новый символ будет принят приемником до того, как предыдущий будет прочитан, предыдущий символ теряется, новый записывается на его место во входной буфер. Передатчик осуществляет передачу данных в линию (выход TxD), преобразуя данные в параллельном формате (записанные процессором) в данные в последовательном формате. Символ (байт) для передачи предварительно записывается процессором в выходной буфер. Передача начинается немедленно после записи. На входы CLK приемника и передатчика подаются тактовые сигналы для формирования последовательных данных в линии. Период тактового сигнала определяет интервал времени для передачи одного бита данных по последовательной линии. Таким образом, частота тактового сигнала определяет скорость передачи данных по последовательной линии. Тактовые сигналы формируются внешним генератором прямоугольных импульсов. Регистр управления используется для настройки порта на заданный режим работы (программирования). В данном случае настраиваются такие параметры, как тип передачи (синхронная или асинхронная), для асинхронной передачи — количество стоповых бит, наличие или отсутствие контроля четности и т.п. Регистр состояния содержит информацию о наступлении некоторых событий в процессе передачи или приема данных (начало и окончание передачи или приема, ошибка кадра или четности при приеме данных, потеря данных во входном буфере вследствие перезаписи данных и т.п.). Блок управления управляет работой последовательного порта. В дополнении к уже известным нам управляющим сигналам, обеспечивающим обмен данными между УВВ и МП, он имеет выход запроса на прерывание INT. Это связано с тем, что приход данных по последовательной линии происходит в произвольный момент времени. Поэтому целесообразно использовать обмен по прерываниям для инициирования чтения данных микропроцессором из входного буфера после того, как очередной байт данных принят с линии. Этот же механизм может быть использован и при передаче данных. Так как передача данных в последовательном формате занимает определенное время, целесообразно использовать запрос на прерывание по окончании передачи очередного байта для того, чтобы микропроцессор мог загрузить следующий байт в выходной буфер. Временные диаграммы обмена данными между последовательным портом и микропроцессором при чтении и записи данных аналогичны соответствущим временным диаграммам для параллельного программируемого интерфейса. После записи в выходной буфер данные сразу же начинают передаваться передатчиком. Чтение же данных производится после того, как они приняты с линии. Факт приема данных с линии можно определить, опрашивая циклически регистр состояния (асинхронный обмен с проверкой готовности) или используя запрос на прерывание от последовательного порта.
Рис. 1. Внешнее устройство по специальной линии посылает микропроцессору сигнал запроса на прерывание. Микропроцессор реагирует на него и переходит к подпрограмме обработки этого прерывания. Предположим, что в системе имеется несколько устройств, использующих обмен по прерываниям. Логично, что в этом случае каждое их них будет посылать запрос на прерывание по своей отдельной линии, чтобы микропроцессор мог определить, какое же устройство запрашивает обмен. Однако такое решение имеет два серьезных недостатка: 1. Количество выводов МП ограничено, следовательно, количество входов запросов на прерывание также будет ограничено, следовательно, у системы будет жесткое ограничение на количество устройств, могущих участвовать в обмене по прерываниям с МП. 2. Если два или более устройства одновременно запросят обмен по прерываниям, возникает конфликтная ситуация, так как одновременно может быть выполнен только один запрос. Для устранения указанных недостатков применяется программируемый контроллер прерываний, который включается в систему между МП и устройствами, запрашивающими прерывания так, как показано на рис. 2.
Рис. 2. Внешние устройства подключаются к контроллеру прерываний, а он в свою очередь — к микропроцессору. Контроллер прерываний решает три основные задачи: 1. Передача в МП сигналов запросов на прерывание, поступивших от внешних устройств. 2. Информирование МП о том, какое именно устройство запросило прерывание (МП должен это знать для перехода на выполнение соответствующей подпрограммы обработки прерывания, а сам он это определить не может, так как все запросы приходят к нему по одной линии INT). 3. Разрешение конфликтных ситуаций, когда два или более устройства одновременно выдают запрос на прерывание. В этом случае контроллер должен выбрать из них какое-то одно в соответствии с теми приоритетами, которые назначены каждому устройству при настройке (программировании) контроллера. Первым будет обработан запрос от устройства, имеющего максимальный приоритет среди всех запросивших. Обобщенная архитектура программируемого контроллера прерываний представлена на рис. 3.
Рис. 3. Буфер шины данных, обеспечивает подключение к контроллера прерываний к шине данных. Подключение к ШД необходимо для: · программирования (начальной настройки) контроллера перед началом работы; · передачи контроллером МП номера устройства, запросившего прерывание. Блок управления управляет работой контроллера, обеспечивая обмен данными между ним и МП (на этапе программирования контроллера), формирование сигнала INT и передачу в МП номера устройства, запросившего обмен. Регистр управления содержит информацию о режиме работы контроллера. Информация в него заносится микропроцессором на этапе программирования (настройки) контроллера. К программируемым (настраиваемым) параметрам относятся, в частности, номера устройств для каждой линии запроса, приоритеты, схемы изменения приоритетов, наличие контроллеров следующего уровня и т.п. Регистр запросов фиксирует запросы, приходящие от внешних устройств. К линиям IRQ подключаются ВУ, по ним передаются запросы на прерывание. Регистр маскирования предназначен для "маскирования" (запрещения обработки) запросов на прерывание для определенного входа (входов). Регистр маскирования содержит по одному биту на каждый вход запроса от внешнего устройства. Если значение бита равно "1", обработка прерывания по данному входу разрешена, если "0" — запрещена. Значение в регистр маскирования записывается МП на этапе программирования контроллера. Контроллер прерываний в общем случае может поддерживать разные схемы приоритетов. Схема жестких приоритетов. Каждому устройству (входу IRQ) назначается фиксированный приоритет, который не меняется во время работы контроллера. Недостаток такой схемы — если устройство с высоким приоритетом будет интенсивно выдавать запросы, запросы от устройств с более низким приоритетом подолгу не будут обрабатываться. Схема используется в том случае, если в системе явно присутствует устройство, которому необходимо обеспечить первоочередное обслуживание в обработке прерываний. Схема циклически изменяющихся приоритетов. Приоритеты изменяются по следующей схеме: устройство, запрос от которого был обработан последним, получает наименьший приоритет. Таким образом, устройство, которое дольше всех не обслуживалось, имеет максимальный приоритет. При этой схеме, в среднем, каждое устройство имеет равные шансы быть обслуженным. Такая схема используется в случае, если все устройства являются равноправными. Кроме передачи сигнала запроса, контроллер должен сообщить микропроцессору номер устройства. Номер выдается контроллером на шину данных после получения от МП сигнала подтверждения прерывания INTA (рис. 4).
Рис. 4. На рис. 4 приведена временная диаграмма работы контроллера прерываний по обслуживанию запроса от устройства. Устройство выдает запрос на обмен по прерыванию на линию IRQ. Контроллер "передает" запрос в МП по линии INT (перед этим решается, если необходимо, задача приоритетов, проверяется, не запрещена ли обработка прерывания через регистр маскирования). Спустя некоторое время (разрыв на временной диаграмме) микропроцессор активизирует сигнал INTA, сообщая таким образом, что он готов начать процедуру обмена по прерываниям. В ответ на это контроллер выдает на шину данных номер устройства, запросившего прерывание. Микропроцессор загружает этот номер с шины данных и переходит к выполнению соответствующей подпрограммы обработки прерывания. Адрес подпрограммы МП определяет по номеру устройства с помощью специальной таблицы (таблицы векторов прерываний), в которой каждому номеру устройства соответствует определенный адрес подпрограммы. Некоторые контроллеры вместо номера устройства выдают в МП непосредственно адрес подпрограммы обработки прерывания. Разрыв на временной диаграмме вызван тем, что после получения сигнала запроса, МП может не сразу перейти к обработке прерывания. Как минимум, он должен завершить выполнение текущей команды. Кроме того, обработка прерываний в МП может быть временно запрещена — в этом случае сигнал INTA будет активизирован после того, как обработка прерываний снова будет разрешена. Количество входов для подключения внешних устройств в любом контроллере прерываний ограничено и может возникнуть ситуация, когда необходимо подключить большее количество устройств, чем имеется входов у контроллера. В этом случае используется каскадирование контроллеров прерываний. Второй контроллер подключается к первому как одно из внешних устройств — выход INT второго контроллера (контроллера второго уровня) подключается к одному из входов IRQ первого контроллера (контроллера первого уровня). При этом первому контроллеру на этапе программирования указывается, что к одному из его входов подключено не простое устройство, а другой КП.
Программируемый таймер Программируемый таймер представляет собой многофункциональный генератор, способный формировать импульсы переменой длительности или последовательность импульсов с заданным интервалом следования. Обобщенная архитектура программируемого таймера представлена на рис. 1.
Рис. 1. Основным элементом архитектуры таймера является счетчик. Счетчик содержит счетный регистр, в который на этапе программирования (настройки) таймера заносится некоторое начальное значение. На вход CLK счетчика подаются счетные импульсы с тактового генератора. При поступлении каждого импульса значение счетчика уменьшается на 1. При достижении счетным регистром значения "0" наступает счетное событие, смысл которого зависит от режима работы счетчика. Режим 1. Генерация одиночного импульса через заданный промежуток времени. Временная диаграмма работы таймера в этом режиме представлена на рис. 2.
Рис. 2. Представим себе, что в счетный регистр записано значение "4". Как только значение записано, начинается счет, то есть при поступлении каждого импульса на вход CLK значение счетного регистра уменьшается на 1. При достижении значением счетного регистра "0" происходит формирование одиночного импульса, длительность которого равна одному периоду сигнала CLK. В таймере может быть предусмотрен режим автоинициализации, когда после окончания счета в счетный регистр опять заносится первоначальное значение (в нашем примере — "4") и процесс повторяется. В этом случае мы будем иметь на выходе OUT последовательность импульсов, период следования которых определяется начальным значением, заносимым в счетный регистр: Режим 2. Формирование импульса заданной длительности (рис. 3).
Рис. 3. После записи начального значения в регистр, начинается счет. Одновременно выход OUT переводится в состояние логической "1" — начинается формирование импульса на нем. При поступлении каждого импульса на вход CLK значение счетного регистра уменьшается на 1. При достижении значением счетного регистра "0" выход OUT переводится в состояние логического "0", что соответствует окончанию импульса. Таким образом, длительность импульса на выходе OUT определяется начальным значением, заносимым в счетный регистр:
Буферный регистр Буферные регистры используются для организации запоминающих буферов, адресных защелок, портов ввода-вывода, мультиплексоров и т.п. Условное графическое обозначение и архитектура восьмиразрядного буферного регистра представлены на рис. 1.
Рис. 1. Буферный регистр состоит из собственно регистра, предназначенного для хранения информации и состоящего из триггеров, выходного усилителя, имеющего выходы с тремя состояниями и устройства управления. Назначение выводов: · DI7-DI0 — линии входных данных; · DO7-DO0 — линии выходных данных; · STB — стробирующий сигнал; · OE — разрешение передачи данных. При сигнале высокого уровня на входе STB состояние входных линий DI7-DI0 передается на выходные линии DO7-DO0, то есть буферный регистр работает как импульсный усилитель с единичным коэффициентом усиления. При переходе сигнала STB от высокого уровня к низкому происходит запоминание (защелкивание) информации в регистре. После этого, пока STB находится в состоянии логического нуля, буферный регистр не воспринимает информацию, поступающую на входные линии DI7-DI0, а на выходных линиях DO7-DO0 продолжают находиться данные, запомненные по заднему фронту сигнала STB. Сигнал OE управляет выходными буферами. При OE=1 выходы DO7-DO0 переводятся в Z-состояние, что эквивалентно "отключению" буферного регистра от следующей за ним электрической схемы.
Шинный формирователь Шинные формирователи применяют как буферные устройства шины данных в микропроцессорных системах. На рис. 1 представлено условное графическое обозначение восьмиразрядного шинного формирователя:
Рис. 1. Шинный формирователь представляет собой импульсный многоканальный усилитель с единичным коэффициентом усиления. Он имеет две группы выводов A0-A7 и B0-B7. В зависимости от значения сигнала T, передача данных производится от выводов A0-A7 к выводам B0-B7 (при T=1) или от выводов B0-B7 к выводам A0-A7 (при T=0). Сигнал OE, как и в случае буферного регистра, переводит выходы микросхемы в Z–состояние. Таким образом, помимо усиления сигнала, шинный формирователь дает возможность "отключения" одной части электрической схемы передачи данных от другой.
Рис. 1. Однако корректное использование математической модели цифровой системы невозможно, если неизвестно точное соответствие частей модели структурным единицам и блокам МПС. Обобщенная структурная схема МПС представлена на рис. 2.
Рис. 2. На первый взгляд, соответствие структурной схемы (рис. 2) и математической модели (рис. 1) не просматривается. Попробуем его найти. Рассмотрим частный случай цифровой САУ — цифровой электропривод (рис. 3):
Рис. 3. Как видно, САУ состоит из микропроцессорной системы (микропроцессор, запоминающее устройство и 3-х УВВ) и непрерывной неизменяемой части (усилитель мощности, исполнительный двигатель, редуктор, нагрузка и датчик обратной связи). Выделим в этой системе четыре элемента: 1. Канал обратной связи (УВВ 1, ДОС и линии связи); 2. Канал управляющих сигналов (УВВ 2 и линии связи); 3. Канал входных сигналов (УВВ 3 и линии связи); 4. Цифровой фильтр (микропроцессор и запоминающее устройство). Таким образом, МПСУ состоит из цифрового фильтра, трех каналов связи и непрерывной неизменяемой части. Почему микропроцессор и запоминающее устройство названы цифровым фильтром? В технике принято называть фильтром любое устройство, если при прохождении через него синусоидального сигнала амплитуда этого сигнала меняется. Любое корректирующее устройство представляет собой фильтр. В запоминающем устройстве хранится программа, реализующая алгоритм управления, а следовательно – осуществляющая фильтрацию сигналов, проходящих через МПС. Эта фильтрация называется цифровой, поскольку микропроцессор выполняет команды за конечное время и работает с дискретными величинами. Имеет место квантование по времени и по уровню. Следовательно, микропроцессор работает как цифровой фильтр. Рассмотрим более подробно структуру трех перечисленных каналов связи и попытаемся получить их математическое описание. Канал обратных связей (КОС) Согласно схеме, приведенной на рис. 3. КОС имеет следующую структуру (рис. 4):
Рис. 4. Здесь Д— датчик обратной связи. Датчик может быть непрерывным и дискретным. Рассмотрим эти два варианта отдельно. КОС с непрерывным датчиком В этом случае датчик может быть представлен в виде усилительного звена с некоторым коэффициентом усиления, которое путем структурных преобразований может быть перенесено в прямую цепь контура САУ. В результате структура КОС оказывается следующей (рис. 5):
Рис. 5. Здесь Блок-схема алгоритма управления для цифровой системы имеет вид (рис. 6):
Рис. 6. Так как каждый шаг алгоритма состоит из набора команд микропроцессора и выполняется за конечное время, ввод сигнала
Рис. 7. Здесь Следует обратить внимание, что физически импульсного элемента не существует. Присутствие его в математической модели лишь отражает факт квантования сигнала по времени. Физически это квантование осуществляет сам микропроцессор, выполняя ввод данных в дискретные моменты времени. КОС с дискретным датчиком В дискретном датчике преобразование непрерывного сигнала в дискретный и соответствующее квантование по уровню происходит внутри самого датчика, сигнал на его выходе представляется уже в цифровом виде. Поэтому мы можем рассматривать дискретный датчик как АЦП, понимая под АЦП здесь любое устройство, осуществляющее квантование по уровню. Следовательно, в случае дискретного датчика КОС также описывается схемой, представленной на рис. 7. АЦП и его характеристики Обычно АЦП рассматривают как статический элемент, то есть предполагают, что запаздывание сигналов, проходящих через него, очень мало. Однако в высокоскоростных системах приходится учитывать конечность времени преобразования в АЦП непрерывного сигнала в соответствующий цифровой код. Реальный АЦП имеет следующую характеристику (рис. 8):
Рис. 8. То есть он является нелинейным элементом. Горизонтальный размер ступеньки на характеристике называется ценой младшего разряда АЦП ( Наличие нелинейного элемента в цепи обратной связи будет приводить к возникновению автоколебаний, амплитуда которых сравнима с ценой младшего разряда АЦП. Однако колебания могут демпфироваться силами трения в опорах, которые играют роль нелинейного элемента с зоной нечувствительности. На практике, для того, чтобы уйти от эффекта автоколебаний, увеличивают разрядность АЦП на 2-3 разряда по сравнению с той, которая необходима для обеспечения требуемой точности системы. В расчетах часто используется линеаризованную статическую характеристику АЦП, представляя его усилительным звеном с коэффициентом усиления Подобная линеаризация оправдана при условии большого количества разрядов АЦП и малого значения Канал входных сигналов Если сигнал g подается на вход МПСУ в непрерывном (аналоговом) виде, структура канала входных сигналов (КВС) такая же, как и КОС (рис. 7). Если же входной сигнал передается от другой МПС (ЭВМ), на первый взгляд он является сразу квантованным по уровню, и АЦП в канале не нужен. Но, принимая во внимание, что по своей физической сути сигнал Таким образом, КВС описывается следующей схемой (рис. 9):
Рис. 9. Здесь Канал управляющих сигналов На входе этого канала (КУС) всегда находится сигнал, квантованный по уровню. На вход усилителя мощности необходимо подавать непрерывный сигнал. Следовательно, сигнал должен быть преобразован из квантованного по уровню в непрерывный. Для этого используется цифро-аналоговый преобразователь (ЦАП). Под ЦАП будем понимать любое устройство, преобразующее квантованный по уровню сигнал в непрерывный. Кроме этого, выдача сигнала происходит в дискретные моменты времени в соответствии с алгоритмом работы МПС (см. рис. 10).
Рис. 10. Выдача сигнала на усилитель мощности в дискретные моменты времени может привести к появлению высокочастотных колебаний в приводе. Следовательно, выдаваемый сигнал должен присутствовать на выходе и в промежутках между выдачами рассчитанного значения. Для этой цели используется экстраполятор — устройство, преобразующее сигналы, дискретные по времени, в непрерывные. Наиболее часто применяются в МПС экстраполяторы нулевого порядка, заполняющие интервал
Рис. 11. Экстраполятор нулевого порядка технически может быть реализован в виде регистра, хранящего последнее рассчитанное значение. Таким образом, канал управляющих сигналов может быть описан следующей структурной схемой:
Рис. 12. Здесь ЦАП и его характеристики Цифро-аналоговый преобразователь имеет нелинейную характеристику, аналогичную АЦП (рис. 8). Все рассуждения, проводившиеся для АЦП относительно возможности возникновения автоколебания и выборе цены младшего разряда, справедливы и для ЦАП. При расчетах он также условно представляется линейным элементом (усилительным звеном) с коэффициентом усиления Математическая модель МПСУ Теперь, когда мы нашли описания всех каналов связи, представим их на единой структурной схеме, взяв за основу структурную схему МПСУ (рис. 13).
Рис. 13. Операция вычисления ошибки реально выполняется микропроцессором (цифровым фильтром) в соответствии с алгоритмом управления. На приведенной выше схеме она вынесена за пределы ЦФ исключительно для удобства моделирования МПС (физически представленный на схеме сумматор не существует). АЦП 1 и АЦП 2 имеют разрядности Рассмотрим теперь работу во времени импульсных элементов в каналах ОС и ВС. Времена их срабатывания соответствуют моментам ввода сигнала С учетом приведенных рассуждений, схема рис. 13 может быть преобразована к следующему виду (рис. 14):
Рис. 14. Представим АЦП в виде усилительного звена с коэффициентом усиления
Рис. 15. Если пренебречь известным эффектом реализации линейных корректирующих устройств в МПС, когда дискретная реализация дает заведомо худшие показатели качества СУ, можно заменить ЦФ неким непрерывным корректирующим устройством, присоединенным к непрерывной части системы. С учетом того, что экстраполятор — то же самое, что и формирователь импульса, получим из рис. 15 следующую модель (рис. 16):
Рис. 16. Таким образом, мы пришли к классической математической модели дискретной САУ (рис. 1). Еще раз повторим тем допущения, которые были сделаны при нахождении математической модели МПСУ: 1. Разрядности АЦП в каналах ОС и ВС одинаковы. 2. Пренебрегаем нелинейностью характеристик ЦАП и АЦП, заменяя их линейными усилительными звеньями. 3. Ввод данных в микропроцессор происходит намного быстрее, чем расчет управляющего сигнала, поэтому срабатывание импульсных элементов в каналах ОС и ВС можно считать одновременным. 4. В цифровом фильтре реализованы линейные алгоритмы управления.
Рис. 1. Задача разработки аппаратных средств МПС сводится, таким образом, к разработке цифрового фильтра и каналов связи. Разработка самого цифрового фильтра, как правило, не вызывает особых сложностей. По сути, она сводится к выбору микропроцессора, наиболее подходящего по условиям конкретной задачи по таким параметрам как тактовая частота (быстродействие), разрядность (точность), стоимость и т.д. Разработка же каналов связи проводится индивидуально для каждой микропроцессорной системы с учетом специфики объекта управления, используемых датчиков обратной связи и задающих устройств. Таким образом, при разработке аппаратных средств МПС основной и наиболее трудоемкой задачей является разработка каналов связи. Учитывая это, дальнейшее изложение будет посвящено, прежде всего, разработке каналов связи микропроцессорной системы. Часто вместо термина "канал" используется термин УСО (устройство сопряжения с объектом).
Классификация УСО УСО могут быть классифицированы по нескольким признакам: По характеру преобразования сигнала 1. Преобразование из непрерывной в дискретную форму (пример — ввод сигнала с непрерывного датчика обратной связи, например потенциометра, с использованием АЦП). 2. Преобразование из дискретной в непрерывную форму (например, при передаче управляющего сигнала в усилитель мощности). 3. Преобразование из дискретной в дискретную форму (пример — ввод данных с импульсного датчика скорости). Задачи проектирования УСО В дальнейшем под УСО мы будем понимать не только отдельно взятый канал, но и объединенные конструктивно в один блок все каналы МПС
Рис. 1. Таким образом, УСО представляет собой "связующее звено" между цифровым фильтром (микропроцессором) и объектом управления. Задача разработки УСО распадается на три подзадачи: 1. Разработка соединения УСО с микропроцессором (с магистралью микропроцессора). 2. Разработка собственно УСО (устройства, обеспечивающие передачу данных и преобразование сигналов). 3. Разработка соединения УСО с объектом управления. Рис. 1. Из временной диаграммы видно, что адрес и данные передаются в разные моменты времени по одним и тем же линиям A/D. Однако вспомогательные микросхемы, используемые в УСО, а также запоминающее устройство требуют присутствия адресной информации на своих входах в течение всего цикла обмена. К тому же они имеют различные входы для адреса и данных. Следовательно, необходимо выполнить "разделение" мультиплексированной шины адреса/данных на шину адреса (на которой адрес будет присутствовать в течение всего цикла обмена) и шину данных. Очевидно, этим должна заниматься специально разработанная схема, называемая схемой демультиплексирования (рис. 2).
Рис. 2. Попытаемся понять, что должна делать схема демультиплексирования. С одной стороны, она должна "разделить" адрес и данные. То есть в момент, когда по мультиплексированной шине адреса-данных передается адрес (ALE=1), она должна быть соединена с шиной адреса, в момент передачи данных (DEN=0) — с шиной данных. Таким образом, схема демультиплексирования должна выполнять роль своеобразного "переключателя", подключающего мультиплексированную шину адреса-данных микропроцессора к шине адреса или шине данных. С другой стороны, адрес должен находиться на шине адреса в течение всего цикла обмена. Следовательно, он должен быть где-то "запомнен", например, в буферном регистре. На рис. 3 представлена обобщенная функциональная схема схемы демультиплексирования.
Рис. 3. Буферный регистр обеспечивает "формирование" шины адреса, запоминая (защелкивая) адрес по сигналу ALE. Шинный формирователь обеспечивает "формирование" шины данных, выполняя функции усилителя с возможностью отключения шины данных от микропроцессора на время передачи адреса. Рассмотрим функционирование схемы демультиплексирования более подробно. Обратимся к рис. 1. В такте 1 цикла обмена происходит выдача адреса на мультиплексированную шину адреса-данных, что сопровождается стробирующим сигналом "разрешение защелкивания адреса" ALE. Сигнал ALE подается на вход STB буферного регистра, адрес поступает с мультиплексированной шины адреса-данных на входы буферного регистра (рис. 4).
Рис. 4. Поскольку сигнал DEN все это время находится в неактивном состоянии (логической единицы), выходы шинного формирователя находятся в Z–состоянии и адрес не может пройти на шину данных. По заднему фронту сигнала ALE (в конце 1-го такта) происходит запоминание адреса в буферном регистре. В такте 3 цикла обмена (см. рис. 1) происходит собственно передача данных, то есть мультиплексированная шина адреса-данных должна быть "соединена" с шиной данных. Это происходит за счет того, что сигнал DEN, находящийся в этот момент в состоянии логического нуля, подается на вход OE шинного формирователя и "отпирает" его — шинный формирователь работает в режиме усилителя, направление передачи данных определяется сигналом DT/R, идущим от микропроцессора (рис. 5).
Рис. 5. Обратите внимание, что все это время на шине адреса продолжает находиться адрес, "защелкнутый" в буферном регистре. Так как сигнал, подаваемый на вход буферного регистра, находится в состоянии логического нуля, передающиеся по мультиплексированной шины адреса-данных данные не поступают в буферный регистр и не "портят" находящуюся там адресную информацию. Построенная по такому принципу схема демультиплексирования обеспечивает решение поставленной задачи: "разделение" адреса и данных и обеспечения наличия адреса на шине адреса в течение всего цикла обмена. Наличие разделенных шин адреса и данных позволяет выполнять подключение к ним устройств, входящих в УСО.
Рис. 1. Здесь представлены два микропроцессора, которые могут через магистраль обращаться к общими ЗУ и УВВ. Очевидно, для ЗУ и УВВ, представленных на рисунке, существует два ведущих устройства — микропроцессор 1 и микропроцессор 2. Естественно, микропроцессоры используют общие ресурсы не одновременно, а по очереди, поэтому в конкретном цикле обмена ведущим устройством является один из них. В общем случае количество микропроцессоров может быть больше двух. Такая схема может применяться в разных случаях, например, если нужно осуществить обмен данными между двумя микропроцессорами через общее ЗУ, или иметь доступ из нескольких МПС к одному УВВ, через которое подключен какой-либо датчик. На рис. 1 представляет упрощенное представление системы с несколькими микропроцессорами. В реальности, системы будет выглядеть следующим образом (рис. 2):
Рис. 2. У каждого микропроцессора имеются свои персональные ЗУ и УВВ, находящиеся целиком и полностью в его распоряжении. Вместе с микропроцессором они образуют микропроцессорную систему. В то же время, каждый микропроцессор имеет доступ к общим ресурсам — ЗУ и УВВ. Магистрали (шины), соединяющие все эти устройства, имеют свою классификацию (рис. 3):
Рис. 3. Магистраль, выходящая из микропроцессора называется локальной шиной микропроцессора. Она является мультиплексированной (в большинстве случаев). Магистраль, соединяющая микропроцессор с УВВ и ЗУ, находящимися в его персональном распоряжении, называется резидентной шиной. Магистраль, соединяющая микропроцессор с общими ЗУ и УВВ носит название системной шины. Резидентная и системная шины не мультиплексированы. Очевидно, для подключения УСО к микропроцессору в данном случае мы должны использовать специальную схему — схему шинного интерфейса (СШИ). Она должна располагаться в месте соединения всех трех шин (см. рис. 3). СШИ должна решать следующие задачи: 1. Демультиплексирование локальной ШАД; 2. Хранение адреса в течение всего цикла обмена; 3. Подключение микропроцессора (локальной шины) к системной или резидентной шине, в зависимости от того, по какой шине будет происходить обмен. Отдельно должен решаться вопрос о порядке подключении к системной шине (СШ). Очевидно, что к общим ресурсам (ЗУ, УВВ) в некий момент времени может иметь доступ только один микропроцессор. Следовательно, должна существовать возможность проверки занятости СШ. Также необходимо предусмотреть механизм для разрешения конфликтных ситуаций, например, когда два или более микропроцессора одновременно попытаются получить доступ к общим ресурсам. Все эти вопросы будут рассмотрены нами позже, пока же сосредоточимся на создании СШИ, решающей сформулированные выше три задачи. Очевидно, что СШИ должно быть две — одна будет обеспечивать подключение к СШ, другая — к РШ. Естественно, в каждом цикле обмена работать будет либо одна, либо другая СШИ (рис. 4):
Рис. 4. Рассмотрим более детально саму схему шинного интерфейса (рис. 5):
Рис. 5. Если посмотреть на сформулированные ранее три задачи, которые должна решать СШИ, мы можем увидеть, что две первые из них совпадают с задачами, которые решала рассмотренная в предыдущем разделе схема демультиплексирования. Следовательно, она может быть положена в основу СШИ. Остается третья задача: обеспечение подключения/отключения от локальной шины (в соответствии с сигналом, передаваемым по специальной линии "Разрешение подключения к шине"). На выходе СШИ мы имеем три шины: адреса, данных и управления. Задача отключения шины данных фактически уже решена в схеме демультиплексирования: при неактивном сигнале DEN шина данных отключена от локальной шины. Отключение шины адреса также может быть выполнено в рамках известной нам схемы демультиплексирования путем подачи сигнала "Разрешение подключения к шине" на вход OE буферного регистра. Для отключения шины управления используется специальное устройство, называемое контроллером шины (рис. 6). Контроллер шины Контроллер шины предназначен для решения задач управления шинным интерфейсом.
Рис. 6. Контроллер шины (КШ) состоит из следующих блоков: · Дешифратор состояний. На вход дешифратора состояний с микропроцессора приходит информация о состоянии микропроцессора в виде двоичного кода, передаваемого по специальным линиям. Обрабатывая эту информацию, дешифратор определяет, будет ли микропроцессор выполнять цикл обмена, если да — будет ли это обмен с ЗУ или УВВ, обмен по чтению или записи. · Устройство управления — правляет работой КШ. На него подаются тактовые импульсы (по входу CLK) — для синхронизации с микропроцессором. Вход AEN — вход разрешения подключения к шине. · Генератор командных сигналов — формирует сигналы шины управления в соответствии с информацией о типе цикла обмена при условии, что подключение к шине разрешено сигналом AEN. · Генератор управляющих сигналов — формирует сигналы управления схемой демультиплексирования (буферным регистром и шинным формирователем) при условии, что подключение к шине разрешено сигналом AEN. Контроллер шины позволяет выполнять подключение/отключение шины управления в зависимости от сигнала разрешения AEN. А вся схема шинного интерфейса будет выглядеть следующим образом (рис. 7):
Рис. 7. Здесь мы видим уже знакомую нам схему демультиплексирования, которая в данном случае управляется контроллером шины. Он же решает задачу "подключения/отключения" шины управления. Схема шинного интерфейса "открывается", то есть подключает микропроцессор к соответствующей шине, с помощью сигнала "Разрешение подключения к шине". Этот сигнал подается на контроллер шины, заставляя его "подключить" микропроцессор к шине управления и сформировать сигналы, управляющие буферным регистром и шинным формирователем. Этот же сигнал подается на буферный регистр для "отключения" его от шины данных в случае, когда схема шинного интерфейса находится в "закрытом" состоянии. Как же формируется сигнал "Разрешение подключения к шине"? Если посмотреть на рис. 4 мы увидим, что у нас имеется две СШИ — одна для подключения к системной шине, другая для подключения к резидентной шине. Обе схемы имеют вход "Разрешение подключения к шине". Следовательно, должно быть некое устройство, которое в каждом цикле обмена определяло бы, будет ли вестись обмен по системной или резидентной шине. Определить это можно на основании адреса ведомого устройства. Поэтому для решения рассматриваемой задачи используется дешифратор адреса (рис. 8):
Рис. 8. На вход дешифратора адреса подается адрес устройства, с которым будет происходить обмен. Не углубляясь в нюансы технической реализации дешифратора адреса, мы можем представить его в виде некоей таблицы из двух столбцов. В первом — все значения адресов, с которыми возможен обмен, во втором — для каждого адреса признак: к системной или резидентной шине он относится. Получив значение адреса и определив его принадлежность, дешифратор активизирует одну из линии "Разрешение подключения к шине" (на схеме обозначена AEN), "отпирая" таким образом одну из СШИ. Обратите внимание, что между дешифратором и СШИ системной шины на пути сигнала AEN находится некое устройство, задачей которого является определение возможности подключения к системной шине (она может быть занята другой МПС). Об этом устройстве мы поговорим немного позже. Рис. 9. Использование логической микросхемы "ИЛИ" с инверсными входами (на ее выходе будет "1" только если на одном или на обоих входах "0") позволяет формировать активное значение сигнала READY только в том случае, если хотя бы один из сигналов AEN (для системной или резидентной шины) активен (на нем присутствует сигнал логического "0"). Арбитр шины Вернемся к рис. 9. Устройство, обозначенное на этом рисунке знаком вопроса и определяющее возможность подключения к системной шине, называется арбитром шины (АШ). Каждая МПС, подключенная к системной шине имеет в своем составе арбитр шин. Таким образом, количество арбитров шин (АШ) равно количеству МПС (микропроцессоров) в многопроцессорной системе. Образно выражаясь, АШ является "представителем" МПС по вопросам доступа к системной шине. Получив от микропроцессора информацию о желании использовать системную шину (СШ), АШ "вступает в переговоры" с другими АШ и в результате определяет момент времени, когда ему (его микропроцессору) будет разрешено использование СШ. (рис. 10)
Рис. 10. Все АШ соединены между собой посредством специальных линий связи, по которым осуществляется взаимодействие между ними в процессе решения вопросов о возможности и порядке доступа к СШ. Рассмотрим АШ более подробно (рис. 11):
Рис. 11. От микропроцессора к АШ по специальным линиям приходит информация о состоянии микропроцессора (аналогично КШ, рассмотренному ранее). От дешифратора адреса поступает сигнал о том, что в данном цикле обмен будет вестись по СШ (сигнал SYSB). Когда разрешение на занятие шины получено, АШ "открывает" СШИ уже известным нам сигналом AEN. Общая схема соединения АШ с микропроцессором и СШИ приведена на рис. 12.
Рис. 12. В общем случае АШ решает следующие задачи: · Проверка занятости СШ. Так как обмен по СШ в каждый конкретный момент времени может вести только один микропроцессор, подключение микропроцессора к СШ возможно только в том случае, если она в данный момент не используется другим микропроцессором. Таким образом, АШ должен проверить свободность СШ, если она свободна – разрешить "своему" микропроцессору ее использовать, если занята – дождаться ее освобождения. · Задача разрешения конфликтов (задача арбитража). В случае, если одновременно два или более АШ претендуют на занятие СШ, среди них должен быть выбран какой-то один и ему предоставлено право работы с СШ, а остальные переведены в режим ожидания освобождения шины Рассмотрим первую задачу. Для определения занятости СШ используется специальная сигнальная линия BUSY, к которой параллельно подключаются все АШ (рис. 13):
Рис. 13. Получив от микропроцессора и дешифратора адреса информацию о необходимости использования СШ, АШ проверяет ее занятость, анализируя состояние линии BUSY. Наличие логической "1" говорит о том, что СШ свободна, наличие "0" — о том, что СШ занята. Если СШ занята, АШ ожидает ее освобождения, "прослушивая" линию BUSY. Если СШ свободна, АШ сам выдает на линию BUSY сигнал логического "0", сообщая таким образом остальным АШ о том, что шина им занята. По окончании использования шины АШ, "захвативший" шину, переводит сигнал BUSY в неактивное состояние (логической "1"), сообщая другим АШ об освобождении СШ. Решение второй задачи основано на использовании понятия "приоритет". Каждому АШ назначается некий приоритет и при одновременном запросе СШ доступ получает АШ с более высоким приоритетом. Рассмотрим две основные схемы, используемые для решения этой задачи: схему последовательного и параллельного арбитража. Последовательный арбитраж Схема включения АШ при использовании последовательного арбитража приведена на рис. 14.
Рис. 14. Каждый арбитр имеет вход BPRN — разрешение занятия шины. Если на этом входе присутствует активный сигнал (в данном случае это сигнал логического "0"), АШ разрешается занять СШ. Посмотрим на рис. 14. У самого левого АШ вход BPRN соединен с "землей" — это эквивалентно подаче на него логического "0". То есть самый левый АШ всегда имеет право занять СШ — он имеет наивысший приоритет. Но возможна ситуация, когда АШ не нуждается в использовании СШ (его микропроцессор не выполняет в данный момент циклов обмена по СШ). В этом случае данный АШ может "передать" свое право на занятие СШ следующему АШ. Внутри АШ расположен воображаемый логический ключ (рис. 15), который в этом случае "замыкается", соединяя вход BPRN с выходом BPRO.
Рис. 15. Выход BPRO соединен со входом BPRN следующего АШ и разрешение на занятие СШ передается ему за счет подачи уровня "0" на вход BPRN. Второй АШ может начать использование СШ (если его микропроцессору это нужно), а может "передать" право использования СШ дальше. Очевидно, что самый правый АШ имеет наименьший приоритет и получит право работы с СШ только в том случае, если все предыдущие АШ "отказались" ее использовать. Достоинства последовательного арбитража: простота реализации — не нужно никаких дополнительных устройств, достаточно лишь соединить в определенной последовательности выходы и входы АШ. Недостатки последовательного арбитража: · Каждый АШ имеет жестко заданный приоритет. Следовательно, если АШ с высоким приоритетом будут интенсивно использовать СШ, АШ с низким приоритетом может долго не получать доступа к ней. · "Передача" разрешения от одного АШ к другому ("замыкание" внутреннего "логического ключа") занимает некоторое время. Следовательно, при большом количестве АШ, включенных в цепь последовательного арбитража, "разрешение" на занятие шины к последнему АШ поступит со значительной задержкой. С другой стороны, протокол обмена по системной шине ограничивает время, отведенное на решение задачи арбитража. Следовательно, количество АШ, которые могут быть включены в цепь последовательного арбитража, ограничено. Параллельный арбитраж Схема включения АШ при использовании параллельного арбитража приведена на рис. 16.
Рис. 16. При необходимости получения доступа к шине АШ устанавливает активный уровень на линии BREQ — сигнал запроса на занятие шины. Эти сигналы от всех АШ поступают в специальное устройство — контроллер арбитража, которое в соответствии с заложенными в него приоритетами выбирает один из АШ и разрешает ему работать с СШ, устанавливая в активное состояние сигнал BPRN для этого АШ. Внутри контроллера арбитража каждому АШ может быть назначен жесткий приоритет, либо может использоваться система циклически меняющихся приоритетов, когда АШ, последним использовавший СШ, получает наинизший приоритет, а тот, который дольше всего не обращался к СШ — наивысший. Достоинства данной схемы: · Не ограничено количество АШ (так как задача арбитража решается одновременно для всех АШ). · При использовании циклического изменения приоритетов внутри контроллера арбитража удается избавиться от ситуации, когда активно использующий СШ арбитр с высоким приоритетом "не дает работать" арбитрам с меньшим приоритетом. Недостаток (по сравнению со схемой последовательного арбитража) — большая сложность, так как используется дополнительное устройство — контроллер арбитража. Рис. 17. В момент времени (1) информация о состоянии микропроцессора сигнализирует о начале цикла обмена, в момент времени (2) сигнал SYSB переходит в активное состояние. АШ выдает сигнал запроса системной шины BREQ (3). После этого АШ ожидает наступления следующих условий: перехода сигнала BUSY в состояние логической "1" (говорит об освобождении СШ) и перехода сигнала BPRN в активное состояние логического "0" (означает, что занятие шины разрешено именно этому АШ). Наступление этих двух условий (моменты времени (4) и (5)) означает, что АШ может занять СШ. Он переводит сигнал BUSY в состояние логического "0" (момент (6)), сообщая тем самым другим АШ о занятии шины, и переводит в активное состояние сигнал AEN, "отпирая" схему шинного интерфейса и сигнализируя микропроцессору о возможности продолжения обмена (момент времени (7)). Рис. 18. АШ переводит в неактивное состояние сигналы BREQ, AEN и устанавливает на линии BUSY сигнал логической "1", показывая другим арбитрам, что он освободил СШ. Сигнал блокировки шины Если в процессе обмена по СШ сигнал BPRN на входе АШ переходит в неактивное состояние, СШ немедленно (по завершении текущего цикла обмена) освобождается, и использовавший ее микропроцессор вынужден ждать, пока ему снова будет предоставлен доступ к системной шине. Однако существуют операции ввода-вывода, которые нежелательно прерывать до их полного завершения. Например, при вводе данных с 20-разрядного цифрового датчика положения нужно произвести два цикла обмена, так как за один цикл может быть введено только одно машинное слово (16 разрядов для 16-разрядного микропроцессора). Если доступ к датчику осуществляется по СШ и после первогого цикла доступ к СШ будет прерван, только часть данных окажется введенной. И микропроцессор должен будет ожидать неопределенное время для ввода оставшейся порции данных и продолжения вычислений. Такой ситуации можно избежать, если иметь возможность запретить АШ освобождать СШ при выполнении "критических" операции ввода-вывода. Для этого служит специальная управляющая линия блокировки шины LOCK (рис. 19):
Рис. 19. Установка активного состояния линии LOCK на выходе микропроцессора производится программно с помощью специального префикса блокировки шины LOCK, например: LOCK IN AL, 0001Таким образом, при составлении программы имеется возможность защиты "критических" операции ввода-вывода от прерывания, вызванного отказом в доступе к СШ.
Рис. 1. УСО параллельно подключаются к шине данных. Использование шины адреса позволяет указать, с каким из них будет выполняться обмен. Шина управления также подключена ко всем УСО и состоит из двух управляющих сигналов — разрешения записи в УВВ IOW и разрешения чтения из УВВ IOR. Рис. 2. Так как при асинхронном обмене предполагается возможность проверки готовности ведомого устройства к обмену, к шине управления добавляется сигнал проверки готовности READY. Он может быть общим (как на приведенной схеме) и соединятся с соответствующим входом МП, либо возможен вариант, когда сигнал готовности каждого устройства анализируется индивидуально, например, путем соединения их со входами одного из регистров параллельного порта ввода-вывода и анализа значений отдельных бит в этом регистре. Рис. 3. Обмен по прерываниям (рис. 3) предполагает, что УСО само инициирует обмен с помощью специального сигнала запроса прерывания. Сигналы от каждого УСО подаются на контроллер прерываний (КП), который обеспечивает передачу в МП сигнала запроса и номера устройства, запросившего обмен. Рис. 4. Предположим, нам нужно ввести некоторые данные из внешнего устройства (например, с датчика) через УВВ и поместить их в ЗУ. При классической организации МПС это можно сделать, только считав данные из УВВ в МП, а затем записав их из МП в ЗУ. Если объем данных велик, МП тратит значительное время на "техническую" работу по пересылке данных. Кроме этого, пересылка через МП является медленной, так как для передачи каждого машинного слова или байта необходимо выполнение двух циклов обмена. Значительно эффективней была бы прямая передача данных из УВВ в ЗУ (или обратно) без участия МП. Для этого необходимо специальное устройство, которое взяло бы на себя роль "ведущего" вместо МП в процессе такой передачи – контроллер прямого доступа в память (контроллер ПДП). Контроллер ПДП должен выполнять все действия МП по управлению обменом, а самому МП предоставить возможность заниматься обработкой информации.
Рис. 5. На рис. 5 представлена структурная схема МПС, в которой внешнее устройство (через УВВ) может обмениваться с ЗУ в режиме прямого доступа в память под управлением контроллера ПДП. Рассмотрим принцип ее функционирования в режиме ПДП. 1. УВВ (внешнее устройство) инициирует начало процедуры обмена с использованием ПДП, устанавливая активный сигнал на линии DREQ. 2. Контроллер ПДП, получив сигнал от внешнего устройства, с помощью сигнала HRQ запрашивает у МП разрешение на использование системных шин. 3. МП выдает разрешение на занятие системных шин, устанавливая сигнал HLDA в активное состояние. При этом МП "отключается" от системных шин, переводя свои соответствующие выводы в Z-состояние. Разрешение на занятие системных шин может быть выдано микропроцессором не сразу, так как он должен завершить текущий цикл обмена. Выдача разрешения задерживается также в том случае, если исполняемая команда защищена префиксом блокировки шины LOCK. 4. Контроллер ПДП по линии DACK сообщает внешнему устройству о начале обмена. С этого момента он принимает на себя обязанности ведущего устройства, управляющего обменом. 5. Контроллер ПДП выдает на шину адреса адрес ячейки ЗУ, с которой будет производиться обмен информацией. 6. Контроллер ПДП формирует на шине управления управляющие сигналы IOR и MEMW (при передаче данных из ВУ в ЗУ) или IOW и MEMR (при передаче данных из ЗУ в ВУ). В этот момент происходит собственно передача данных. 7. По окончании передачи контроллер переводит в неактивное состояние сигнал DACK , сообщая внешнему устройству об окончании обмена, и сигнал HOLD, информируя МП о завершении использования системных шин. С этого момента функции ведущего устройства снова возвращаются к МП. Пункты 5 и 6 составляют собственно цикл обмена в режиме ПДП. Этот цикл может быть одиночным ("одиночная передача") или повторяющимся определенное число раз ("блочная передача"). Возможен также вариант "передача по требованию", когда циклы передачи повторяются до тех пор, пока внешнее устройство удерживает активный уровень сигнала на линии DREQ. Рис. 6. Контроллер ПДП состоит из следующих основных блоков: · Буфер шины данных — обеспечивает подключение к шине данных, необходимое на этапе программирования контроллера. · Устройство управления — выполняет управление работой контроллера, содержит регистры, содержание которых задается на этапе программирования и определяет режим работы контроллера. · Каналы ПДП. Обычно контроллер ПДП имеет несколько каналов, к каждому из которых может быть подключено ВУ по линии запроса обмена DACK. При поступлении одновременно нескольких запросов на обмен, предпочтение отдается устройству, подключенному к каналу с наивысшим приоритетом. Приоритеты каналов задаются в процессе программирования, они могут быть жесткими или гибкими (изменятся в процессе работы, например по циклической схеме — канал, обслуженный последним, получает низший приоритет). К устройству управления подходят: · Шина адреса — используется для выдачи контроллером адреса ячейки ЗУ при работе в режиме ПДП и для выбора одного из внутренних регистров контроллера при записи информации в режиме программирования. · Сигналы шины управления — MEMR, MEMW, IOR, IOW — используются для формирования сигналов управления на шине управления в режиме ПДП. Сигналы IOR, IOW используются также при занесении информации в контроллер в режиме программирования. · Сигналы взаимодействия с МП — HRQ и HLDA. Рис. 1. Так как ввод любых данных в МПС осуществляется по шине данных (ШД), мы должны соединить выходные линии датчика с шиной данных. Но соединить их напрямую мы не можем, так как в этом случае информация, передаваемая датчиком, будет находиться на шине данных постоянно. И обмен с другими устройствами будет невозможен. Следовательно, датчик необходимо соединить с ШД с помощью устройства, которое бы подключало датчик к ШД только на время цикла ввода информации с него. Для этой цели может быть использован рассмотренный нами ранее буферный регистр (БР) (рис. 2).
Рис. 2. В данном случае БР играет роль усилителя с возможностью отключения от шины данных. Следовательно, на вход STB должен быть подан сигнал логической "1", обеспечивающий работу БР в режиме усилителя. Вход OE будет использоваться для подключения БР (и датчика) к ШД в цикле чтения. БР должен подключаться к ШД при следующих условиях: · Выполняется цикл обмена по чтению из внешнего устройства (управляющая линия IOR в активном состоянии — логического "0"). · Цикл обмена выполняется именно с данным датчиком. Так как любое внешнее устройство, подключенное к МПС, должно иметь уникальный адрес, необходимо проанализировать адресную информацию (сигналы на линиях адреса). И если установленный на шине адрес соответствует адресу рассматриваемого ВУ (датчика), БР должен быть подключен к шине данных. Для анализа адресной информации используется дешифратор (рис. 3).
Рис. 3. В приведенной схеме УСО используется дешифратор с двумя входами, на которые подаются сигналы двух младших адресных линий. Следовательно, линия CS будет активизирована при передаче адреса, у которого младшие разряды будут иметь значение "00" (старшие разряды адреса в данной схеме не анализируются и могут иметь любые значения). Использование логического элемента "ИЛИ" позволяет формировать сигнал OE на входе буферного регистра только если оба сигнала — CS и IOR находятся в активном состоянии — логического "0". Таким образом, схема УСО, представленная на рис. 3 позволяет решить поставленную задачу — подключение цифрового датчика к шине данных только на время выполнения обмена с ним (с установкой соответствующего ему адреса на шине адреса). Временная диаграмма изменения сигналов в УСО представлена на рис. 4.
Рис. 4. Из временной диаграммы видно, что данные на шине данных появляются только после установки на шине адреса соответствующего адреса и активизации сигнала IOR Задача подключения цифрового датчика может быть решена также с использованием программируемого параллельного интерфейса (ППИ, параллельного порта). Схема УСО для этого случая представлена на рис. 5.
Рис. 5. Схема во многом аналогична предыдущей. Так как ППИ имеет в своем составе несколько портов ввода-вывода, при вводе данных через него необходимо указать, с каким конкретно портом идет работа (т.е. к какому порту подключено интересующее нас устройство — в данном случае цифровой датчик). Для этого используются входы А0, А1, которые соединены непосредственно с двумя младшими линиями шины адреса. Следовательно, два младших разряда адреса в данном случае определяют номер нужного порта внутри ППИ. Два следующих разряда адреса (А2, А3) используются для выбора конкретной микросхемы ППИ — через дешифратор они соединены со входом CS ППИ. Параллельный интерфейс будет подключен к ШД только если на вход CS подан активный сигнал логического "0", а это произойдет только при А2=А3=0. Таким образом, если предположить, что датчик подключен к порту A ППИ, для выбора которого необходимо А1=А2=0, то для чтения данных с датчика через ППИ на шине адреса должно быть установлено значение "0000" — четыре младшие разряда нулевые. Значения старших разрядов не имеют значения, так как никак не используются в данной схеме. Временная диаграмма изменения сигналов в УСО рис. 5. представлена на рис. 6.
Рис. 6. Рассмотрим теперь ситуацию, когда разрядность данных, получаемых с датчика, больше 8. Так как порты ввода-вывода и буферные регистры обычно являются восьмиразрядными, для ввода данных большей разрядности необходимо использовать несколько портов (буферных регистров). Например, при вводе данных с 16-разрядного датчика положения, в схеме на рис. 5 линии восьми младших разрядов должны быть подключены к одному порту ППИ (например, порту А), линии восьми старших разрядов — к другому (например, порту В). Ввод данных с датчика будет осуществляться в два приема — сначала считывание младшего байта из порта А, затем старшего — из порта В. В соответствии со схемой подключения на рис. 5. порт А ППИ имеет адрес 0000h, порт В — 0001h. В таком случае ввод данных осуществляется следующей последовательностью команд МП Intel 8086: IN AL, 0000h ; ввод младшего байта MOV BL, AL ; сохранение младшего байта IN AL, 0001h ; ввод старшего байта MOV BH, AL ; сохранение старшего байтаЗначение, введенное с датчика, помещается в результате в регистр BX. Рассмотрим процесс ввода во временной области. Для ввода данных в данном случае необходимо выполнить два цикла обмена. Каждый цикл занимает определенное время (несколько тактов синхронизации процессора). Между циклами имеется некоторый промежуток за счет выполнения команды сохранения введенного значения в регистре BL. Таким образом, между моментами ввода в МП младшего и старшего байтов существует интервал времени
Рис. 7. В течение этого интервала времени, значение, поступающее с датчика, может измениться. Например, в момент ввода младшего байта имелось значение 00FFh (младший байт — FFh, старший байт — 00h). Ввели младший байт (FFh). Затем, в течение интервала
Рис. 8. Младшие и старшие восемь линий, идущие с датчика, подключены через соответствующие буферные регистры к портам А и В ППИ. Буферные регистры работают в режиме усилителей с возможностью фиксации данных по заднему срезу сигнала STB. Для формирования строба на линии STB используется линия 0 порта С ППИ. При установке младшего разряда порта С в "1" сигнал на линии STB переходит из "0" в "1" (начало строба), при сбросе младшего разряда порта С в "0" сигнал на линии STB переходит из "1" в "0" (окончание строба). Процесс иллюстрирует рис. 9.
Рис. 9. В момент времени Так как адрес порта С ППИ при указанной на рис. 8. схеме подключения равен 0002h, начало строба формируется командами MOV AL, 0001h OUT 0002h, ALОкончание строба — командами MOV AL, 0000h OUT 0002h, ALТак как фиксация данных в БР происходит по заднему фронту сигнала STB, установка и сброс должны быть произведены перед процедурой ввода данных. При этом длительность импульса ( В результате, фрагмент программы, выполняющей ввод данных с 16-разрядного цифрового датчика, будет выглядеть следующим образом: MOV AL, 0001h ; OUT 0002h, AL ;Установка сигнала STB MOV AL, 0000h ; OUT 0002h, AL ;Сброс сигнала STB- фиксация данных IN AL, 0000h ;ввод младшего байта MOV BL, AL ;сохранение младшего байта IN AL, 0001h ;ввод старшего байта MOV BH, AL ;сохранение старшего байтаПри вводе данных без преобразования (в цифровом виде) необходимо обращать внимание на формат представления вводимых данных. Как известно, данные внутри МПС представлены в двоичном дополнительном коде. Вводимые данные могут быть представлены в прямом двоичном коде, прямом коде со смещением и т.п. В этом случае процесс ввода должен предусматривать преобразование данных в двоичный дополнительный код. Преобразование может быть выполнено как аппаратно (с помощью специальных преобразователей) так и программно.
Непрерывные и дискретные системы автоматического управления Структурную схему системы автоматического управления (САУ) можно представить в следующем виде (рис. 1):
Рис. 1. В состав устройства управления входят корректирующее и вычитающее устройства. В процессе разработки системы автоматического управления решаются две основные задачи: 1. Синтез корректирующего устройства, результатом которого является передаточная функция корректирующего устройства; 2. Техническая реализация корректирующего устройства. Рассмотрим вопросы технической реализации корректирующего устройства на примере пропорционального регулятора (рис. 2):
Рис. 2. Вариант 1. Реализация в виде электронной схемы (например, на основе операционного усилителя, рис. 3). В этом случае значение управляющего сигнала
Рис. 3. Вариант 2. Реализация на основе специализированной ЭВМ (рис. 4):
Рис. 4. В этом случае собственно корректирующее устройство реализуется программно в виде алгоритма расчета значения управляющего сигнала
Рис. 5. Алгоритм работы корректирующего устройства Весь управляющий цикл состоит из ввода исходных данных для расчета, собственно расчета и вывода полученного значения управляющей величины. Работа алгоритма может быть представлена на временной оси (рис. 6):
Рис. 6. Так как реализация алгоритма представляет собой набор операций, а каждая операция выполняется внутри ЭВМ за конечное время, процессы ввода, расчета и вывода также занимают конечное время. Следовательно, значение управляющей величины
Рис. 7. То же самое можно сказать и о сигналах, вводимых в ЭВМ (рис. 8). Эти сигналы определены внутри ЭВМ лишь в дискретные моменты времени (на фазе ввода
Рис. 8. Системы, сигналы в которых определены лишь в отдельные дискретные моменты времени, называются дискретными системами(Система, сигналы в которой определены лишь в отдельные дискретные моменты времени). Все системы, в состав которых входит ЭВМ, являются дискретными. Таким образом, все системы автоматического управления в зависимости от варианта технической реализации блока управления (корректирующего устройства) можно подразделить на непрерывные и дискретные.
|
Последнее изменение этой страницы: 2019-05-08; Просмотров: 616; Нарушение авторского права страницы


 может быть измерено в любой момент времени и с любой точностью. Системы, сигналы в которых существуют (могут быть измерены) в любой произвольный момент времени называются непрерывными системами.
может быть измерено в любой момент времени и с любой точностью. Системы, сигналы в которых существуют (могут быть измерены) в любой произвольный момент времени называются непрерывными системами.

 и
и  . Блок-схема такого алгоритма выглядит следующим образом (рис. 5):
. Блок-схема такого алгоритма выглядит следующим образом (рис. 5):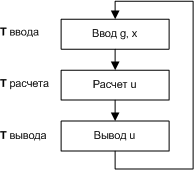

 :
: 
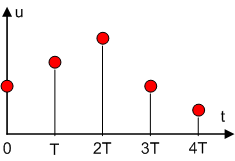

 (рис. 3)
(рис. 3)

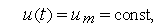


 , тогда
, тогда  .
.
 , рассматривая момент времени
, рассматривая момент времени  :
:
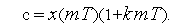

 :
:
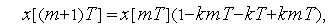

 ,будем иметь:
,будем иметь:
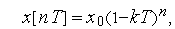
 определяется начальными условиями.
определяется начальными условиями. , например
, например  :
:





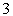
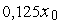

 , например
, например 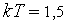 :
:


 , например
, например  :
: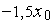
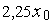

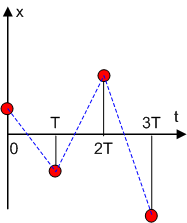
 система может стать неустойчивой, чем больше значение этой величины, тем хуже вид переходного процесса. Существуют ограничения на значение
система может стать неустойчивой, чем больше значение этой величины, тем хуже вид переходного процесса. Существуют ограничения на значение  . Если же предположить, что фиксирован коэффициент усиления
. Если же предположить, что фиксирован коэффициент усиления 

 — представляемая количественная величина (число),
— представляемая количественная величина (число),  — знак, используемый для его представления и занимающий
— знак, используемый для его представления и занимающий  -тую позицию,
-тую позицию,  — основание системы счисления,
— основание системы счисления,  .
.

 . Так, напрмер, с помощью одного разряда в десятичной системе счисления можно представить числа от 0 до 9 (
. Так, напрмер, с помощью одного разряда в десятичной системе счисления можно представить числа от 0 до 9 (  ), с помощью двух разрядов — от 0 до 99 (
), с помощью двух разрядов — от 0 до 99 (  ) и т.д.
) и т.д. ) называется двоичной системой счисления. Один разряд двоичной системы счисления может иметь лишь два значения: 0 или 1. Число, представленное в двоичной системе счисления, называется двоичным числом.
) называется двоичной системой счисления. Один разряд двоичной системы счисления может иметь лишь два значения: 0 или 1. Число, представленное в двоичной системе счисления, называется двоичным числом. , мы можем определить, какое количество разрядов необходимо для представления заданного
, мы можем определить, какое количество разрядов необходимо для представления заданного 



 будет меньше 1, то соответствующая система счисления более эффективна, чем двоичная (см. табл. 1).
будет меньше 1, то соответствующая система счисления более эффективна, чем двоичная (см. табл. 1). ). Для представления числовых величин в ней используются цифры от 0 до 9 и шесть первых заглавных букв латинского алфавита (A, B, C, D, E, F). Шестнадцатиричная система позволяет представлять числа более компактно, нежели двоичная. В то же время, перевод из двоичной системы в шестнадцатеричную намного проще, чем в десятичную. Таким образом, шестнадцатеричная система используется для более компактной записи двоичных чисел (см. табл. 2).
). Для представления числовых величин в ней используются цифры от 0 до 9 и шесть первых заглавных букв латинского алфавита (A, B, C, D, E, F). Шестнадцатиричная система позволяет представлять числа более компактно, нежели двоичная. В то же время, перевод из двоичной системы в шестнадцатеричную намного проще, чем в десятичную. Таким образом, шестнадцатеричная система используется для более компактной записи двоичных чисел (см. табл. 2).
 . Необходимо определить координаты точки в система координат
. Необходимо определить координаты точки в система координат  , повернутой на угол
, повернутой на угол 
 :
:












 — шаг интегрирования.
— шаг интегрирования.









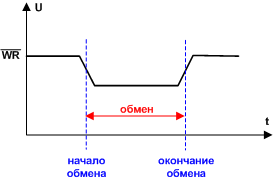





 . Логическая "1" в простейшем случае кодируется напряжением
. Логическая "1" в простейшем случае кодируется напряжением  , логический "0" — отсутствием напряжения. В процессе передачи одного бита линия на время переводится в соответствующее состояние. По истечении периода
, логический "0" — отсутствием напряжения. В процессе передачи одного бита линия на время переводится в соответствующее состояние. По истечении периода 


 или
или  (часто говорят "один", "полтора" или "два стоп-бита"). Несмотря на то, что кадр состоит всего из 10 бит, в процессе его передачи может возникнуть рассинхронизация (по причинам, описанным выше). При очень большой разнице
(часто говорят "один", "полтора" или "два стоп-бита"). Несмотря на то, что кадр состоит всего из 10 бит, в процессе его передачи может возникнуть рассинхронизация (по причинам, описанным выше). При очень большой разнице  приемника и передатчика, потеря бита может произойти даже на 10 битах. Во избежание этого, длительность стопового бита увеличивают, так как он обязательно должен быть обнаружен после последнего информационного бита. Увеличение длительности стопового бита позволяет также "защитить" стартовый бит следующего кадра от потери. Если приемник не обнаруживает стоп-бит, фиксируется "ошибка кадра" и весь кадр считается принятым с искажением.
приемника и передатчика, потеря бита может произойти даже на 10 битах. Во избежание этого, длительность стопового бита увеличивают, так как он обязательно должен быть обнаружен после последнего информационного бита. Увеличение длительности стопового бита позволяет также "защитить" стартовый бит следующего кадра от потери. Если приемник не обнаруживает стоп-бит, фиксируется "ошибка кадра" и весь кадр считается принятым с искажением.

 уменьшаются, приближаясь друг к другу. В результате могут возникать ошибки при детектировании "0" и "1" приемником.
уменьшаются, приближаясь друг к другу. В результате могут возникать ошибки при детектировании "0" и "1" приемником.





 . Для этого достаточно провести вычитание
. Для этого достаточно провести вычитание  и проанализировать "флаг" нуля: если ZF=1, значит результат вычитания был нулевым и величины
и проанализировать "флаг" нуля: если ZF=1, значит результат вычитания был нулевым и величины  и
и  равны. Если ZF=0 — не равны. Аналогично, если после операции вычитания "флаг" знака установился в 1, это говорит о том, что был получен отрицательный результат, то есть значение
равны. Если ZF=0 — не равны. Аналогично, если после операции вычитания "флаг" знака установился в 1, это говорит о том, что был получен отрицательный результат, то есть значение 
 ) и последующих чисел происходит аналогично.
) и последующих чисел происходит аналогично.





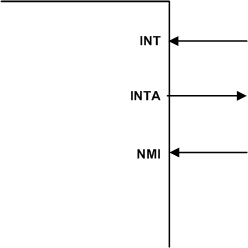


 — операция возведения в квадрат (
— операция возведения в квадрат ( 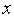 — операнд,
— операнд,  — результат операции);
— результат операции); — операция дифференцирования (
— операция дифференцирования (  — оператор).
— оператор).

 и
и  — значения соответствующего разряда в первом и втором слагаемом,
— значения соответствующего разряда в первом и втором слагаемом,  — перенос из младшего разряда,
— перенос из младшего разряда,  — значение соответствующего разряда суммы,
— значение соответствующего разряда суммы,  — значение переноса в старший разряд.
— значение переноса в старший разряд.











 .
.






 — данные, передаваемые по шине данных и представленные в числовом виде. Из-за ограниченности разрядной сетки число
— данные, передаваемые по шине данных и представленные в числовом виде. Из-за ограниченности разрядной сетки число 

 — сигнал, квантованный по уровню,
— сигнал, квантованный по уровню, 
 ). Чем меньше цена младшего разряда, тем большее число разрядов двоичного числа необходимо для представления преобразованного значения при одном и том же диапазоне его изменения. На практике цена младшего разряда выбирается исходя из максимально допустимой ошибки (они должны быть примерно равны):
). Чем меньше цена младшего разряда, тем большее число разрядов двоичного числа необходимо для представления преобразованного значения при одном и том же диапазоне его изменения. На практике цена младшего разряда выбирается исходя из максимально допустимой ошибки (они должны быть примерно равны):  .
. .
. – непрерывная величина (мы рассматриваем цифровой привод), можно сказать, что квантование по уровню все равно имело место (было выполнено в ЭВМ верхнего уровня), а, следовательно, математическая модель КВС должна содержать АЦП (хотя физически — как отдельного устройства — его нет).
– непрерывная величина (мы рассматриваем цифровой привод), можно сказать, что квантование по уровню все равно имело место (было выполнено в ЭВМ верхнего уровня), а, следовательно, математическая модель КВС должна содержать АЦП (хотя физически — как отдельного устройства — его нет).
 — входной сигнал, квантованный по уровню,
— входной сигнал, квантованный по уровню,  — входной сигнал, квантованный по уровню и времени.
— входной сигнал, квантованный по уровню и времени.
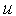 — сигнал, квантованный по времени и уровню,
— сигнал, квантованный по времени и уровню, 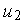 — сигнал, квантованный по времени,
— сигнал, квантованный по времени,  — непрерывный сигнал на выходе канала.
— непрерывный сигнал на выходе канала.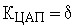 .
.
 и
и  соответственно. На практике, как правило, их разрядности совпадают, так как в противном случае при вычислении ошибки неизбежно будет возникать погрешность. Поэтому мы тоже можем допустить, что разрядности АЦП 1 и АЦП 2 совпадают.
соответственно. На практике, как правило, их разрядности совпадают, так как в противном случае при вычислении ошибки неизбежно будет возникать погрешность. Поэтому мы тоже можем допустить, что разрядности АЦП 1 и АЦП 2 совпадают.
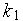 , ЦАП — в виде усилительного звена с коэффициентом усиления
, ЦАП — в виде усилительного звена с коэффициентом усиления  . Тогда при условии, что в ЦФ реализуются линейные алгоритмы коррекции, схема рис. 14 может быть представлена в следующем виде (рис. 15):
. Тогда при условии, что в ЦФ реализуются линейные алгоритмы коррекции, схема рис. 14 может быть представлена в следующем виде (рис. 15):







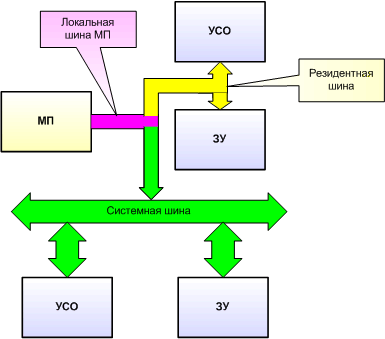









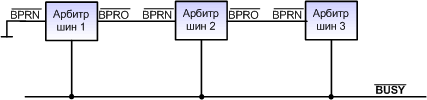











 происходит фиксация значений в буферных регистрах.
происходит фиксация значений в буферных регистрах. на рис. 9) должна быть достаточной для завершения всех переходных процессов в БР. Длительность строба может быть рассчитана по известной тактовой частоте МП и известному количеству тактов на выполнение каждой команды. При необходимости между командами установки и сброса строба может быть введена программная задержка.
на рис. 9) должна быть достаточной для завершения всех переходных процессов в БР. Длительность строба может быть рассчитана по известной тактовой частоте МП и известному количеству тактов на выполнение каждой команды. При необходимости между командами установки и сброса строба может быть введена программная задержка.