
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Кодер и декодер кода Бергера
Функциональная схема кодера приведена на рис. 4.18. В состав кодирующего устройства входят: входной регистр DD1, предназначенный для хранения преобразуемых сообщений, счетчик DD5 для подсчета числа единиц в исходном сообщении и преобразователь DD2параллельного кода в последовательный.
Исходная кодовая комбинация, представляющая, как правило, двоичный неизбыточный код, через мультиплексор DD2 поступает на выход и одновременно через схему И DD4на вход счетчика DD5, который в данном случае подсчитывает число единиц в передаваемом сообщении. После прохождения информационных k символов спадом пятого тактового импульса триггер DD3 устанавливается в 0, схема И DD4 закрывается и контрольные символы из счетчика DD5 через мультиплексор DD2 поступают в линию связи. Процесс кодирования кодовой комбинации G(x) = 11010 в виде состояния элементов кодера показан на схеме рис. 4.18. Декодирование сводится к определению числа единиц в информационной части, т.е. к формированию контрольных символов из пришедших на приемную сторону информационных символов, с последующим сравнением этой последовательности контрольных символов с контрольными символами, поступившими из линии связи. В случае их совпадения, что говорит об отсутствии ошибок, информационные символы поступают потребителю. Схема декодера приведена на рис. 4.19.
Кодовая комбинация в коде Бергера записывается в регистр DD4. На первых пяти тактах счетчиком DD3 подсчитывается число единиц в информационных символах. После этого сумматорами по модулю 2 DD5.1…DD5.3 складываются две последовательности контрольных символов, записанных в регистре DD4и зафиксированных счетчиком DD3. При полном их совпадении что говорит об отсутствии ошибок, на выходе ИЛИ–НЕ DD6 появляется 1, которая открывает элементы И DD7…DD11, и информационные символы поступают потребителю. В случае несоответствия двух последовательностей контрольных символов на выходе формирователя DD12 появляется 1, которая сбрасывает приемный регистр DD4 в исходное положение, а сигнал, равный 0, на выходе DD6запрещает выдачу информационных символов потребителю. Процесс декодирования кодовой комбинации
4.9. Кодирующее и декодирующее устройства
Как следует из подразд. 2.3.1, алгоритм кодирования и декодирования определяется составом образующей и проверочной матриц. Схема кодера, использующего алгоритм, полученный по выражениям: (2.12)

Сумматорами по модулю два DD2, DD3, DD4 формируются контрольные символы r1, r2 и r3 в соответствии с выражениями (2.12)…(2.14). Преобразователем параллельного кода в последовательный DD5 сначала в линию связи выдвигаются информационные символы k1, k2, k3, k4, а затем контрольные r1, r2, r3. На этом процесс кодирования данной комбинации заканчивается, и кодер ожидает поступления в регистр DD1 следующего кодового сообщения. Порядок формирования комбинации F(x) показан на схеме в виде состояния элементов кодера для сообщения G(x) = 1100. Декодирование заключается в определении синдрома по выражениям (2.17):
Если синдром будет нулевого порядка, то ошибок нет, в противном случае синдром должен указать номер искаженного разряда.
Кодовая комбинация из линии связи записывается в регистр DD1 и поступает на входы определителя синдрома, собранного на элементах DD2, DD3, DD4. На сумматоре по модулю 2 DD2 осуществляется вычисление S1, на
4.10. Кодирующее и декодирующее устройство Принцип построения кодирующего устройства не зависит от числа информационных разрядов передаваемого кода. Поэтому рассмотрим схему кодирующего устройства (рис. 4.22) для числа информационных символов k = 4, контрольных символов r = 4 и d = 4, хотя она без принципиальных изменений может быть использована для кодирования любого числа k за счет увеличения числа сумматоров по модулю 2 и числа входов отдельных элементов. Кодер состоит из входного регистра DD1, куда записываются комбинации, подлежащие кодированию; формирователя контрольных символов на элементах DD2…DD5 и преобразователя параллельного кода в последовательный на мультиплексоре DD6. В соответствии с методикой формирования контрольных символов, изложенной в подразд.2.3.2, можно записать, что Порядок кодирования комбинации G(x)= k4k3k2k1 = 1011 показан на рис. 4.22 в виде состояния элементов. В результате в линию связи поступит кодовая комбинация F(x) = 01100110 с классическим порядком следования контрольных и информационных символов.
Декодирование заключается в нахождении ошибок, их исправлении и выводе полезной информации потребителю. Схема декодера для кода (8, 4), позволяющего исправлять одиночные и обнаруживать двойные ошибки, приведена на рис. 4.23. Декодер состоит из входного регистра DD1, определителя синдрома S1S2S3 на элементах DD2…DD4, определителя общей проверки на четность SS на элементе DD15, дешифратора синдрома S1S2S3 на элементе DD5, дешифратора двойной ошибки на элементе И DD6, устройства коррекции ошибок на элементах " исключающее ИЛИ" DD7…DD10 и устройства вывода на элементах И DD11…DD14. Входы определителя синдрома DD2…DD4 подключаются в соответствии с принятым алгоритмом кодирования. Для кода (8, 4) сумматор по модулю 2 DD2 осуществляет проверку
В данном дешифраторе DD5 показаны прямые выходы, соответствующие информационным символам, и инверсный выход При всех других соотношениях Si и SS, указанных в подразд. 2.3.2, на выходе И DD6 будет сигнал, равный 1. Процесс декодирования кодовой комбинации
4.11. Технические средства умножения и деления многочлена на многочлен
Устройства для умножения и деления многочлена на многочлен составляют основу кодирующих и декодирующих устройств циклических кодов. Эти устройства строятся на базе регистров сдвига с обратными связями и сумматоров с приведением коэффициентов по модулю 2. Такие регистры также называют многотактными линейными переключательными схемами и линейными кодовыми фильтрами Хаффмана. Основные правила построения схем умножителей и делителей: 1) число ячеек регистра равно старшей степени многочлена, на который происходит умножение или деление. Ячейка регистра для старшей степени многочлена отсутствует, но всегда присутствует ячейка 2) число сумматоров на единицу меньше числа ненулевых членов многочлена, на который производится умножение или деление, или на единицу меньше его веса; 3) при делении отбрасывается сумматор, соответствующий старшему члену многочлена, а при умножении – младшему; 4) сумматоры устанавливают перед ячейками регистра, соответствующими ненулевым членами многочлена тех же степеней; 5) при умножении множимое подается одновременно на вход и на все сумматоры; 6) при делении делимое подается только на первый сумматор, а частное – на выход и на все сумматоры; 7) множимое или делимое поступает на вход начиная со старшего разряда. Функциональная схема делителя на многочлен P(x)=x4+x3+1 приведена на рис. 4.23. Разделим на этот многочлен (делитель) многочлен G(x)=x7+x5+x4+x3+x1+1 (делимое). Результат деления представлен в виде табл. 4.2, где стрелками показаны направления процессов между элементами.
В тактах 3 и 4 ячейки регистра продолжают заполняться, но на выход пока поступают только сигналы 0. Вследствие того что с ячейки DD6 сигнал 1 через сумматор DD1 поступает в ячейку DD2 одновременно с 1 делимого, в ней записывается 0 (такт 4). В этом же такте на выходе появляется 1 и через сумматор DD5 происходит запись 1 в ячейку DD6 (обратная связь с ячейки DD6 на ячейку DD2регистраи на ту же ячейку DD6 показана косыми стрелками влево и вниз). В такте 6, хотя на вход поступает 0 делимого, по обратной связи с ячейки DD6 в ячейку DD2 записывается 1. Однако из–за той же обратной связи в ячейке DD6 происходит запись 0, так как сумматор DD5 не пропустил два сигнала 1. Заполнение ячеек регистра в такте 7 происходит без обратной связи, которая вновь сказывается в такте 8. Частное читается сверху вниз. Остатки от деления начинают записываться в ячейки регистра начиная с такта 5. Последний остаток R(x) = 1110 записан в такте 8.
В такте 1 единица старшего разряда записывается одновременно в ячейки DD1, DD5 и поступает на выход. В такте 2 на выход проходит сигнал 1 с ячейки DD5, а с ячейки DD1 единица переходит в ячейку DD2. В такте 3 сигнал 1 записывается с ячейки DD1 и DD5 и проходит на выход, а сигнал 1 с ячейки DD2 переходит в ячейку DD3. В такте 4 сигнал 1 записывается только в ячейку DD1, но на выход он не проходит и не записывается в ячейку DD5. Этому препятствуют сигналы 1 с ячеек DD3 и DD5. Начиная с такта 9 информация в регистр не поступает и регистр очищается, т.е. информация, записанная в такте 8, такт за тактом подается на выход. Результат умножения F(x) = 111011010011 читается сверху вниз.
4.12. Кодер и декодер циклического кода
Как указывалось в подразд.2.3.3, образование циклического кода состоит из двух операция: умножение комбинации обычного двоичного кода G(x) на одночлен X r и последующего деления этого произведения на выбранный образующий многочлен P(x). Полученные в остатке от деления контрольные символы приписываются к кодируемой комбинации (2.29). Таким образом, кодирующее устройство должно совмещать функции умножения и деления.
В состав его входит r–разрядный регистр сдвига (DD11, DD13, DD14), который совместно с сумматорами по модулю 2 DD10, DD12 осуществляет деление на полином P(x), два ключа DA1, DA2, входной регистр DD5, для записи G(x), коммутатор входных сообщений (DD1…DD4, DD6) и триггер управления DD9. Схема работает следующим образом. В начале работы ключ DA2 замкнут сигналом 1 с инверсного выхода триггера DD9. Информационная последовательность под действием управляющих сигналов с распределителя импульсов DD6 через схемы И DD1…DD4начиная со старшего разряда поступает на выход и входной сумматор DD10. В процессе ее прохождения за k тактов в ячейках регистров сдвига DD11, DD13, DD14 накапливается r проверочных разрядов. После 4–го такта ключ DA2 закрывается, а ключ DA1 открывается. Записанные в ячейках регистра r = 3 проверочных разрядов тремя тактами поступают на выход кодирующего устройства.
Декодирование комбинаций циклического кода можно проводить различными методами, существуют методы (см. подразд. 2.3.3), основанные на использовании рекуррентных соотношений, на мажоритарном принципе, на вычислении остатка от деления принятой комбинации на образующий многочлен кода и др. Целесообразность применения каждого из них зависит от конкретных характеристик используемого кода. Рассмотрим сначала устройства декодирования, в которых для обнаружения и исправления ошибок производится деление произвольного многочлена F*(x), соответствующего принятой комбинации, на образующий многочлен кода P(x). В этом случае при декодировании могут использоваться те же регистры сдвига, что и при кодировании.
Принимаемая последовательность записывается в ячейки буферного регистра DD1 на первых четырех тактах и одновременно поступает в декодирующий регистр на 1–7–м тактах. Таким образом, в регистре DD1 оказываются лишь информационные разряды. На 8–м такте после приема последнего разряда кодовой комбинации, открываются схемы И DD8…DD11. Если комбинация принята без ошибок, то в ячейках декодирующего регистра будут записаны нули, а на выходе схем ИЛИ–НЕ появится 1, которая дает разрешение на вывод информационных разрядов к1…к4 через схемы И DD8…DD11 потребителю. Наличие же в тех или иных ячейках декодирующего регистра единиц свидетельствует об ошибках в принимаемой информации. На выходе схемы ИЛИ–НЕ DD7 в таком случае появляется сигнал 0, который запрещает вывод информации из буферного регистра.
Проиллюстрируем принцип построения декодеров для исправления ошибок на примере кода (7, 4) с образующим полиномом P(x) = x3+x+1. Минимальное кодовое расстояние d min = 3, следовательно, код способен исправлять однократные ошибки. Укажем, что дешифратор синдрома должен быть настроен на комбинацию 001. Схема декодера показана на рис. 4.28.
Пусть по каналу связи была передана комбинация F(x) = 1001110, которая под действием помех приняла вид На 7–м такте в ячейках декодирующего регистра завершается формирование комбинации синдрома. Комбинация 100 отлична от нуля, что свидетельствует о наличии ошибки. Далее в буферный и декодирующий регистры подается еще k = 4 тактов, которые, во–первых, выдвигают информационные разряды через выходной сумматор DD8 на выход декодера, а во–вторых, переформируют информацию в ячейках декодирующего регистра. Как видно из табл. 4.5, на 9–м такте в ячейках декодирующего регистра сформирована комбинация 001, на 10–м такте эта комбинация поступает на вход дешифратора синдрома, на выходе которого возникает сигнал 1. В этот же момент на выходной сумматор поступает искаженный 3–й разряд, который, проходя через сумматор, меняет знак на обратный. Исправленная комбинация имеет вид 1001.
На рис. 4.29 представлена функциональная схема мажоритарного декодирования кода (7, 3) (см. пример 2.17). В процессе заполнения регистра декодируемой кодовой комбинации ключ SWT находится в положении 1. После заполнения регистра сдвига на выходах сумматоров формируются результаты проверок относительно разряда а0 (2.48):
|
Последнее изменение этой страницы: 2017-03-15; Просмотров: 684; Нарушение авторского права страницы


 показан на схеме в виде состояния элементов. Элементами DD5.1…DD5.3 зафиксировано несовпадение двух последовательностей, в результате чего комбинация бракуется.
показан на схеме в виде состояния элементов. Элементами DD5.1…DD5.3 зафиксировано несовпадение двух последовательностей, в результате чего комбинация бракуется. , (2.13)
, (2.13)  , (2.14)
, (2.14) 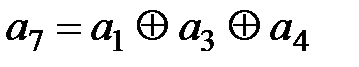 , приведена на рис. 4.20.
, приведена на рис. 4.20.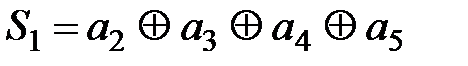 ,
, 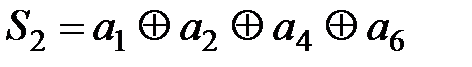 ,
,  .
.
 на выходах соответствующего элемента И DD5…DD8 появится единичный сигнал, который при прохождении информационного символа через выходной сумматор по модулю 2 DD9…DD12 изменит его на противоположный. Процесс декодирования кодовой комбинации
на выходах соответствующего элемента И DD5…DD8 появится единичный сигнал, который при прохождении информационного символа через выходной сумматор по модулю 2 DD9…DD12 изменит его на противоположный. Процесс декодирования кодовой комбинации 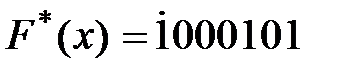 показан на схеме в виде состояния отдельных элементов. В данном случае зафиксировано искажение символа k2, который скорректирован выходным сумматором по модулю 2 DD10 c 0 на 1.
показан на схеме в виде состояния отдельных элементов. В данном случае зафиксировано искажение символа k2, который скорректирован выходным сумматором по модулю 2 DD10 c 0 на 1. ,
,  ,
,  ,
, 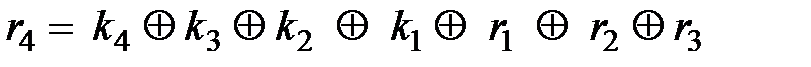 . Согласно этим выражениям осуществляем подключение входов сумматоров по модулю 2 к информационным шинам k1…k4. Порядок подачи информационных и контрольных символов на вход мультиплексора, а следовательно, и очередность их передачи в линию связи может быть различна: сначала информационные, а потом контрольные или наоборот, или классический вариант – на местах, кратных 2i, где i = 0, 1, 2 … r, контрольные, а на остальных – информационные.
. Согласно этим выражениям осуществляем подключение входов сумматоров по модулю 2 к информационным шинам k1…k4. Порядок подачи информационных и контрольных символов на вход мультиплексора, а следовательно, и очередность их передачи в линию связи может быть различна: сначала информационные, а потом контрольные или наоборот, или классический вариант – на местах, кратных 2i, где i = 0, 1, 2 … r, контрольные, а на остальных – информационные.
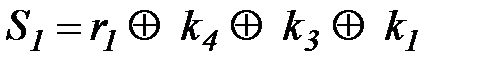 , сумматор DD3 —
, сумматор DD3 —  , сумматор DD4 –
, сумматор DD4 –  . Общая проверка на четность принятой кодовой комбинации производится сумматором DD15–
. Общая проверка на четность принятой кодовой комбинации производится сумматором DD15–  . Дешифратор синдрома представляет обычный дешифратор двоичного кода 4–2–1 в десятичный.
. Дешифратор синдрома представляет обычный дешифратор двоичного кода 4–2–1 в десятичный.
 , на котором нулевой сигнал появляется только в случае, когда S1= 0, S2= 0, S3= 0; выходы, соответствующие контрольным символам, не показаны, так как их коррекция не производится. На выходе дешифратора двойной ошибки, элементе 2И–НЕ DD6, сигнал 0 (запрета) появляется только в том случае, когда на инверсном выходе DD15 будет 1 и на выходе
, на котором нулевой сигнал появляется только в случае, когда S1= 0, S2= 0, S3= 0; выходы, соответствующие контрольным символам, не показаны, так как их коррекция не производится. На выходе дешифратора двойной ошибки, элементе 2И–НЕ DD6, сигнал 0 (запрета) появляется только в том случае, когда на инверсном выходе DD15 будет 1 и на выходе 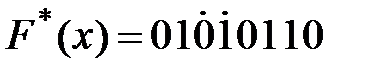 показан на схеме в виде состояния элементов. В данном случае на выходе схемы И DD6 будет 0, а следовательно, схемы И DD11…DD14 будут закрыты, информация потребителю не поступит и будет включен индикатор HLR, свидетельствующий о двойной ошибке.
показан на схеме в виде состояния элементов. В данном случае на выходе схемы И DD6 будет 0, а следовательно, схемы И DD11…DD14 будут закрыты, информация потребителю не поступит и будет включен индикатор HLR, свидетельствующий о двойной ошибке.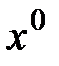 ;
; 







 . Процесс исправления ошибки представлен в табл. 4.5.
. Процесс исправления ошибки представлен в табл. 4.5.
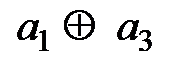 (DD8),
(DD8),  (DD9) и
(DD9) и  (DD10); а0 поступает непосредственно в схему, где происходит подсчет чисел 1 и 0, т.е. в мажоритарный элемент
(DD10); а0 поступает непосредственно в схему, где происходит подсчет чисел 1 и 0, т.е. в мажоритарный элемент 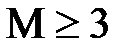 , который выносит решение о значении разряда а0. Далее ключ SWT переводится во второе положение, подается еще один тактовый импульс в регистр, комбинация сдвигается на один разряд вправо, создаются условия (2.49) по проверке разряда а1 и мажоритарный элемент выносит решение о значении разряда а1 и т.д. вплоть до декодирования разряда а6. Таким образом, декодирование кодовой комбинации осуществляется за 2n тактов: в течение первых n тактов заполняется регистр DD1…DD7, а в течение последующих определяется значение каждого из n разрядов. Вывод информации потребителю осуществляется с выхода мажоритарного элемента через схему И DD12.
, который выносит решение о значении разряда а0. Далее ключ SWT переводится во второе положение, подается еще один тактовый импульс в регистр, комбинация сдвигается на один разряд вправо, создаются условия (2.49) по проверке разряда а1 и мажоритарный элемент выносит решение о значении разряда а1 и т.д. вплоть до декодирования разряда а6. Таким образом, декодирование кодовой комбинации осуществляется за 2n тактов: в течение первых n тактов заполняется регистр DD1…DD7, а в течение последующих определяется значение каждого из n разрядов. Вывод информации потребителю осуществляется с выхода мажоритарного элемента через схему И DD12.