
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
История развития компьютерных сетей передачи данных. Появление Internet .Стр 1 из 12Следующая ⇒
Появление World Wide Web (WWW), понятие гипертекстовой среды работы с документами. Всеми́рная паути́на— распределённая система, предоставляющая доступ к связанным между собой документам, расположенным на различных компьютерах, подключённых к Интернету. Для обозначения Всемирной паутины также используют слово веб и аббревиатуру WWW. Всемирную паутину образуют сотни миллионов веб-серверов. Большинство ресурсов Всемирной паутины основаны на технологии гипертекста. В компьютерной терминологии гипертекст — это текст, сформированный с помощью языка разметки с расчетом на использование гиперссылок. Гипертекстовые документы, размещаемые во Всемирной паутине, называются веб-страницами. Несколько веб-страниц, объединённых общей темой, дизайном, а также связанных между собой ссылками и обычно находящихся на одном и том же веб-сервере, называются веб-сайтом. Для загрузки и просмотра веб-страниц используются специальные программы — браузеры. Всемирная паутина вызвала настоящую революцию в информационных технологиях и взрыв в развитии Интернета. Изобретателями всемирной паутины считаются Тим Бернерс-Ли и, в меньшей степени, Роберт Кайо. Тим Бернерс-Ли является автором технологий HTTP, URI/URL и HTML. В 1980 году он работал в Европейском совете по ядерным исследованиям консультантом по программному обеспечению. Именно там, в Женеве (Швейцария), он для собственных нужд написал программу «Энквайр», которая использовала случайные ассоциации для хранения данных и заложила концептуальную основу для Всемирной паутины. В 1989 году Тим Бернерс-Ли предложил глобальный гипертекстовый проект, теперь известный как «Всемирная паутина». Проект подразумевал публикацию гипертекстовых документов, связанных между собой гиперссылками, что облегчило бы поиск и консолидацию информации для учёных Европейского совета по ядерным исследованиям. Для осуществления проекта Тимом Бернерсом-Ли (совместно с его помощниками) были изобретены идентификаторы URI, протокол HTTP и язык HTML. Это технологии, без которых уже нельзя себе представить современный Интернет. В период с 1991 по 1993 год Бернерс-Ли усовершенствовал технические спецификации этих стандартов и опубликовал их. В рамках проекта Бернерс-Ли написал первый в мире веб-сервер, называвшийся «httpd», и первый в мире гипертекстовыйвеб-браузер, называвшийся «WorldWideWeb». Первый в мире веб-сайт был размещён Бернерсом-Ли 6 августа1991 года. Ресурс определял понятие «Всемирной паутины», содержал инструкции по установке веб-сервера, использования браузера и т. п. Этот сайт также являлся первым в мире интернет-каталогом, потому что позже Тим Бернерс-Ли разместил и поддерживал там список ссылок на другие сайты. И всё же теоретические основы веба были заложены гораздо раньше Бернерса-Ли. Ещё в 1945 годуВанна́вер Буш разработал концепцию Memex — вспомогательных механических средств «расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации. Следующим значительным шагом на пути ко Всемирной паутине было создание гипертекста (термин введён Тедом Нельсоном в 1965 году). В опубликованном виде он впервые появился в 1965 годув докладе для описания документов (например, представляемых компьютером), которые выражают нелинейную структуру идей, в противоположность линейной структуре традиционных книг, фильмов и речи.
Типы хостинга : • Виртуальный хостинг (множество веб-сайтов расположено на одном веб-сервере. Это самый экономичный вид хостинга, подходящий для небольших проектов.) • Виртуальный выделенный сервер (когда группа веб-сайтов находится на одном физическом веб-сервере, но для каждого из них создается собственный виртуальный сервер. Со всеми вытекающими — собственный IP-адрес, полный контроль и управление ресурсами машины и ее конфигурацией.) • Выделенный сервер (клиенту целиком предоставляется отдельная физическая машина (в противоположность виртуальному хостингу) • Колокация (услуга связи, состоящая в том, что провайдер размещает оборудование клиента на своей территории (обычно в датацентре) и подключает его к каналам связи с высокой пропускной способностью)
Веб-хостинг : • Бесплатный хостинг • По содержимому: Блог-платформа, Видео хостинг, Файлообменник, Вики-хостинг Функциональные службы в Интернет: E-mail, WWW,FTP, Archie • Электронная почта E-mail - служба электронного общения в режиме оффлайн. (предназначена для обмена почтовыми сообщениями между абонентами сети Internet. С помощью E-mail можно посылать и получать сообщения, отвечать на полученные письма, рассылать копии письма сразу нескольким получателям, переправлять полученное письмо по другому адресу и так далее.Для работы с электронной почтой используют почтовые клиенты (Outlook Express, Microsoft Outlook, The Bat) и почтовые Web-интерфейсы, расположенные на почтовых веб - серверах) • Распределенная система гипермедиа Word Wide Web (WWW) – ( это одна из служб Интернета, но она является его основой, это распределенная система гипермедиа (гипертекста), в которой документы, размещены на серверах Интернет и связаны друг с другом ссылками. Для просмотра Web-страниц используются прикладные программы - браузеры. К наиболее популярным обозревателям относятся: Internet Explorer, Mozilla Firefox, MyIE Web Browser, Opera и т.д. ) • Передача файлов – FTP (это служба или программа-клиент FTP, которая предназначена для пересылки файлов между компьютерами, работающими в сетях TCP/IP, при помощи прикладного протокола передачи файлов (File Transfer Protocol), который определяет правила передачи файлов с одного компьютера на другой. С помощью клиентской программы ftp можно просматривать содержимое директорий на удаленном компьютере и переходить из директории в директорию, выбирая требуемые файлы. Выбранные файлы можно скачать на свой ПК. Некоторые FTP серверы могут пересылать файлы по E-mail) • Archie (Это прикладная служба, которая помогает находить файлы, хранящиеся на анонимных FTP-серверах в Internet. Archie-серверы ведут списки файлов многих FTP серверов, постоянно обновляя их в своих базах данных. Так как поиск требуемого файла в FTP-серверах является сложной задачей, то для поиска нужного файла в FTP-серверах используют средство - Archie. Задача Archie - сканировать FTP-архивы на предмет наличия в них требуемых файлов)
Наличие экспертных оценок В Веб содержится огромное количество экспертных оценок, как явных, так и неявных, которые могут быть использованы для обучения и настройки методов поиска. Например, явная информация о тематической направленности ресурсов содержится в тематических каталогах -- как в глобальных типа Yahoo! или List.Ru, так и в небольших персональных подборках ссылок на ресурсы по определенной теме. Важным источником экспертных оценок в Веб являются гипертекстовые ссылки. Поскольку большинство ссылок создается вручную, то гипертекстовая ссылка часто отражает мнение создателя о цитируемом ресурсе. Пытаться характеризовать это мнение можно разными способами -- например, путем анализа текста ссылки или в ее окружении. Особенности структуры Естественной моделью представления Веб является ориентированный граф, в котором вершины соответствуют страницам, а ребра - соединяющим страницы гиперссылкам. В рамках этой модели задача анализа структуры связей между страницами -- это задача анализа структуры графа. Информацию о структуре графа Веб можно использовать при решении многих связанных с Веб задач: при теоретическом анализе поведения алгоритмов, использующих информацию о ссылках; для оптимизации вычислительной эффективности методов работы с графом - например, сжатие графа Веб; при исследовании развития Веб с социологической точки зрения и т.д. [26]. Отметим лишь некоторые известные свойства Веб, которые активно используются в методах информационного поиска:
Другой часто встречающийся вид подграфов -- полные двудольные подграфы Эти наблюдения очень важны для использующих структуру графа Веб алгоритмов, которые обсуждаются далее (см. раздел 4.1).
Очень важное наблюдение о том, что ``Веб -- это фрактал'', т.е. структура Веб обладает свойством самоподобия, был сделан в работе [106]. Другими словами, свойства структуры Веб также верны и для его ``характерных'' подграфов. Таким подграфом является относительно большое подмножество (от Этот факт позволяет надеяться, что алгоритмы, использующие информацию о структуре Веб, будут работать не только на том наборе данных, на котором они тестировались.
Интуитивно кажется естественным предположение о том, что ссылки со страниц в Веб в основном ведут на страницы близкой тематики. Эмпирическое подтверждение согласованности между тематической и пространственной (в смысле расстояний в графе Веб) локальностью было дано в работе [44]. Более формально эмпирически показана справедливость следующих предположений: Ссылки в большинстве случаев соединяют страницы с близким содержанием Текст ссылки и, возможно, вокруг нее описывает содержание страницы, на которую ведет ссылка. В работе [55] был предложен эффективный алгоритм выделения ``сообществ'' в Веб, т.е. множеств страниц близкой тематики, где с любой из страниц большая часть ссылок ведет на другие страницы этого же ``сообщества'', на основе анализа только гипертекстовой структуры сети. Этот результат важен, поскольку демонстрирует осмысленность структуры ссылок Веб, процесс создания которой централизовано не контролируется 2. Особенности информационного поиска в WEB по сравнению с информационно-справочными системами. Модель поведения типичного пользователя. Методы поиска, используемые в классических ИПС, разрабатывались и тестировались на относительно небольших и однородных коллекциях, таких как библиотечные каталоги или коллекции газетных статей. Веб как набор данных имеет ряд важных особенностей:
Отметим, что эти оценки касаются только той ``поверхностной'' части Веб, которая не скрыта за поисковыми формами, и доступ к которой не требует предварительной регистрации или авторизации. Другую, ``скрытую'' часть Веб (hidden web), поисковые системы обычно не рассматривают, а ведь к ней относится множество крупных баз данных, опубликованных в Интернет. Поэтому неудивительно, что оценка объема ``скрытого'' Веб в 500 раз больше, чем объем ``поверхностного'' Веб [17,84].
Около 30% информации в Веб составляют точные или приблизительные копии других документов [104].
В Веб изменяется и понятие ``типичного пользователя''. Отметим следующие отличия [72]:
Более того, типичные запросы очень коротки -- более 60% поисковых запросов в Веб состоят из 1-2 слов, что сильно отличается от 7-9 слов в классических ИПС [15,72].
Как следствие, меняется представление о критериях эффективности поиска. Например, традиционно популярный критерий полноты, т.е. процента обнаруженных релевантных документов, малополезен для оценки эффективности систем поиска для Веб [39]. 3. Архитектура поисковой системы для WEB. Понятия: хранилище документов, модуль индексирования, индекс, сетевой робот, поисковая машина, формат запроса.
Хранилище Хранилище содержит большое количество объектов данных (страниц Веб) и в этом смысле очень похоже на СУБД или файловую систему. Однако многие возможности этих систем в данном случае совершенно не нужны (например, транзакции или иерархия директорий), зато очень важны другие: масштабируемость, эффективная поддержка двух режимов доступа: произвольного -- для того, чтобы быстро найти конкретную страницу по ее идентификатору (например, для создания копии страницы из кэша ИПС), и потокового -- для того, чтобы вынуть значительную часть всей коллекции (например, для индексирования или анализа), эффективная поддержка обновлений, сборка ``мусора'' (устаревших страниц) [14]. Естественно, что для достижения необходимой масштабируемости Хранилище должно быть распределенным и должно храниться на множестве отдельных узлов. Эффективность реализации требуемых операций зависит от способов решения трех основных проблем:
Модуль индексирования Задачей этого модуля является построение необходимых структур данных, ускоряющих поиск - индексов. Кроме текстовых индексов, часто используются индексы, описывающие структуру графа Веб, а также прочие вспомогательные индексы (например, индекс для доступа к страницам по их длине или по количеству используемых графических изображений). Существует много подходов к индексированию текстовой информации -- например, инвертированные файлы, хэширование, файлы сигнатур, различные виды деревьев для многомерного индексирования и т.п. Специфика Веб определяет свои особенности построения текстового индекса для ИПС. В дополнение к традиционным целям -- минимизации времени доступа и размера индекса -- здесь также важно минимизировать время создания индекса и обеспечивать возможность эффективного обновления. Один из возможных подходов -- распределенное построение инвертированных файлов на основе техники программных каналов. Идея состоит в параллельном выполнении трех процессов: загрузки документов в оперативную память, построения инвертированных списков по документам и их окончательной записи на жесткий диск. Поскольку эти процессы требуют разных аппаратных ресурсов, то такой подход позволяет сократить время создания индекса на 30-40%. Очень важной проблемой является создание индексов для хранения информации о структуре графа Веб. Для поддержки эффективного выполнения алгоритмов на графах необходимо применение специализированных методов индексирования. Например, в последней версии системы Connectivity Server для хранения информации о ссылке требуется менее 6 бит, что позволяет хранить графы в несколько сот миллионов страниц в оперативной памяти и, как следствие, обеспечивать эффективный доступ к этой информации. Поисковая машина Расширенные возможности поиска пользуются малым спросом у пользователей ИПС для Веб. Как следствие, за исключением предикатов, позволяющих наложить условия на входящие/исходящие ссылки, в языках запросов, применяемых в системах в Веб, нет существенных нововведений по сравнению с языками запросов классических ИПС. Однако простота запросов влечет их низкую селективность, и поэтому очень важной задачей является упорядочивание результатов так, чтобы первыми оказались те результаты, которые вероятнее всего интересны пользователю. Классические подходы к ранжированию опираются на меру схожести текста запроса и текста документа, но ``расплывчатые'' запросы пользователей и огромное количество документов значительно понижают эффективность таких подходов в контексте Веб. Новые подходы к задаче ранжирования результатов поиска обсуждаются в разделе 4. 4. Стратегии сканирования пространства WEB сетевыми роботами. Особенности сканирования скрытого Web. Стратегии сканирования Используемая сетевым роботом стратегия сканирования определяет множество посещенных им страниц. Например, возможные стратегии выбора следующей ссылки из множества уже известных, но еще не посещенных ссылок -- обход ``в глубину'', т.е. посещение последней обнаруженной ссылки, или обход в ``ширину'', т.е. посещение ссылок в порядке их обнаружения. Обобщенной задачей робота является максимизация ``качества'' построенного приближения
Сетевые роботы обычно сканируют только ``поверхностный'' Веб и не могут сканировать информацию, скрытую за поисковыми формами или требующую предварительной регистрации. Мы обсудим некоторые подходы к задаче сканирования ``скрытого'' Веб в разделе 3.3. Большинство сетевых роботов осуществляет сканирование сетевых ресурсов за счет перекачивания их содержимого на тот сервер, где они работают, тем самым создавая значительный сетевой трафик.
Как уже было сказано выше, фокусированное сканирование применяется для повышения общей ``полезности'' посещенных ресурсов. ``Полезность'' ресурса определяется той целью, которая поставлена роботу:
Отметим также, что наибольшее превосходство фокусированные стратегии сканирования демонстрируют при относительно небольшой продолжительности сканирования, т. е. до Сканирование ``скрытого'' Веб Робот, сканирующий ``скрытые'' ресурсы, должен уметь не только автоматически взаимодействовать с основанными на формах поисковыми интерфейсами, которые ориентированы на пользователя-человека, но также и подставлять осмысленные значения при заполнении этих форм. Фундаментальное отличие робота, сканирующего ``скрытую'' часть Веб, относится только к работе со страницами, которые содержат поисковые формы. Модель робота содержит 4 компонента:
5. Понятие релевантного и нерелевантного документа. Методы ранжирования результатов поиска. Модели PageRank, “голосования”, HITS. Ранжирование результатов Локальные методы В подходах этой группы для оценки качества страницы используется информация о ее локальном контексте и учитывается специфика текущего запроса. Наиболее известным подходом этого вида является HITS (Hyperlink-Induced Topic Search) [74]. В рамках модели HITS выделяются две разных роли документа -- ``первоисточника'' (authority) и ``посредника'' (hubs). Хороший ``первоисточник'' -- это документ, на который часто ссылаются в контексте некоторой тематики, а хороший ``посредник'' ссылается на много хороших ``первоисточников''. Алгоритм HITS состоит из двух шагов: выбор подмножества Веб на основе запроса и определение лучших ``авторитетов'' и ``посредников'' по результатам анализа этого подмножества [56]. Подмножество строится путем расширения множества найденных по запросу пользователя страниц за счет добавления всех страниц, связанных с ними путем, состоящим из одной (иногда двух) ссылок. Далее, для каждого документа рекурсивно вычисляется его значимость как ``авторитета''
Однако в некоторых ситуациях последнее предположение оказывается неверным, и, как следствие, доминирующее сообщество относится к другой тематике. Так, например, по запросу ``jaguar'' доминирующее сообщество посвящено городу ``Цинциннати'', местная газета которого уделяет много внимания давнему сопернику их футбольной команды - команде ``Jaguars''. Теоретический анализ стабильности метода вычисления HITS по отношению к небольшим изменениям в графе показал, что стабильность сильно зависит от разницы между наибольшими собственными числами матрицы В основе одного из расширений модели HITS лежит предположение, что ссылка Для вычисления рангов необходимо задать количество факторов Глобальные методы Подходы этой группы оценивают качество страницы, используя только информацию о Веб, и получаемые оценки не зависят от текущего запроса. Типичным примером является индекс цитирования, т.е. количество ссылок на данную страницу, аналог которого давно используется в библиометрическом анализе. Наиболее известным расширением индекса цитирования в Веб является PageRank, который определяет важность страницы
где d -- это некоторый параметр (обычно порядка 0.85), а В основе PageRank лежит модель случайного пользователя, который, начав с какой-то страницы, переходит на новые страницы по ссылкам с текущих и никогда не нажимает кнопку ``Вернуться'', а когда ему надоедает (что происходит с вероятностью Формально, модель PageRank не учитывает динамику развития Веб и анализирует граф с некоторой статической структурой. Однако теоретический анализ стабильности PageRank относительно изменений в графе показал устойчивость получаемых рангов по отношению к изменениям, касающимся ресурсов с невысоким рангом [96]. Этот результат очень важен, поскольку на практике PageRank всегда вычисляется на основе некоторого приблизительного представления о содержимом Веб. Еще одна интересная модель -- модель ``голосования'' (voting model), в которой ранг ресурса определяется на основе оценок качества от некоторого множества экспертов и структуры графа Веб [86]. Отметим, что здесь в качестве экспертов могут быть использованы разнообразные источники информации -- тематические каталоги, поведение других пользователей, явная метаинформация на странице, и т.п. Формально, эта модель расширяет PageRank, но отсутствие результатов апробирования не позволяет оценить практическую полезность этого расширения.
6. Архитектуры Информационно-поисковых систем(ИПС): распределенные, метапоисковые . Вариации архитектуры ИПС Описанная в разделе 2 архитектура ИПС для Веб не является единственно возможной. Мы остановимся на нескольких альтернативных вариантах, поскольку принципиальные изменения архитектуры часто вызывают появление новых исследовательских проблем. Распределенные ИПС Естественной попыткой решить проблему масштабируемости ИПС является использование распределенной архитектуры. Этот подход активно исследовался как в контексте классических ИПС [15], так и в контексте поисковых систем Веб [99]. В рамках такой архитектуры поиск производится по виртуально единому индексу, который физически распределен по ряду серверов. Эффективная система должна выполнять запросы, не производя поиск во всех частях индекса, стараясь искать только там, где действительно содержится ответ. В распределенной ИПС для Веб пополнение и поддержка разных частей индекса может выполняться разными роботами, и то, насколько они будут эффективны, также зависит от принципов разбиения индекса [10]. Интересным примером является исследовательская система OASIS (http://www.oasis-europe.org), в которой индекс разбивается на тематические части [99]. Такой подход не только позволяет использовать фокусированные стратегии сканирования для обнаружения новых документов (см. раздел 3.1), но также и лучше контролировать качество информации по отдельным тематикам, например, привлекая экспертов по этим темам. Возможно дальнейшее повышение автономности системы. Так, например, для поиска в разных частях индекса могут использоваться разные алгоритмы (например, тематический тезаурус). При этом, поскольку оценки близости запросу пользователя становятся не сравнимы, возникает проблема слияния результатов [58]. Важными также являются вопросы, связанные с интероперабельностью компонент распределенной системы [1].
Метапоисковая система -- это система, которая предоставляет единый доступ к нескольким другим поисковым системам, т.е. обслуживает запросы пользователей за счет опрашивания других поисковых систем, которые полностью независимы и не предоставляют никакой специальной информации о содержимом своих индексов или используемых методах поиска [4,81,92,113]. Такие системы популярны в силу ряда причин:
При создании метапоисковой системы необходимо решать проблемы, похожие на возникающие при создании распределенных систем. Но полная автономность составляющих ИПС вносит свою специфику. Так, языки запросов, используемые в разных ИПС, зачастую сильно отличаются, и поэтому необходим либо сильно упрощенный язык поиска для метапоисковой системы, либо такой подход к интеграции гетерогенных ИПС, который решает задачу по переформулировке запросов. Отметим, модель ADMIRE, которая способна адаптироваться к изменениям в поисковых интерфейсах и к появлению новых ИПС [69]. Непростой задачей является и выбор ИПС, которые будут обрабатывать запрос. Этот шаг напрямую влияет как на вычислительную, так и на качественную эффективность поиска [48,91]. Проблема осложняется отсутствием информации о множестве проиндексированных ИПС документов. Одним из возможных подходов является сбор этой информации в процессе работы. Например, система SavvySearch на основе своего опыта обслуживания запросов учится предсказывать полезность конкретных ИПС по используемым в запросе ключевым словам [68]. В случае поиска по специализированным ИПС полезным может оказаться их предварительная автоматическая классификация на основе тестовых запросов [70]. XML как основа построения семантического информационного пространства в WWW сети.
Язык XML привлек к себе уже достаточно много внимания со стороны разработчиков и пользователей Интернет. Сегодня количество приверженцев этой новой технологии возрастает также стремительно, как и число сообщений об очередных взятых ею преградах на пути к всеобщему признанию. Несмотря на то, что XML очень молод (международная организация W3C утвердила спецификацию "ExtensibleMarkupLanguage(XML) 1.0 в начале февраля 1998 г уже сегодня появляются новые языки, созданные на основе XML, возникают многочисленные Web-сервера, использующие эту технологию для организации хранящейся на них информации. XML (ExtensibleMarkupLanguage) - это язык разметки, описывающий целый класс объектов данных, называемых XML- документами. Этот язык используется в качестве средства для описания грамматики других языков и контроля за правильностью составления документов. Язык разметки XML
5. Структура XML документа. Пролог и корневой элемент. Комментарии. Специальные символы. Пример XML файла. XML (англ. eXtensible Markup Language) расширяемый язык разметки Описание XML-документа представляет собой простой текст, который можно набрать в любом текстовом редакторе, например, редактор Notepad, входящем в состав Microsoft Windows. Еще лучше воспользоваться редактором, в котором предусмотрена возможность анализа исходных кодов, например, текстовым редактором Microsoft Visual Studio, рассчитанным на работу с Microsoft Visual C++, Microsoft Visual InterDev, Microsoft Visual J++ и другими приложениями Visual Studio.
Анатомия XML-документа
XML- документ подобный что набранному вами, состоит из двух основных частей: пролога и элемента Документ (его также называют корневым элементом),как показано на рисунке на следующей странице.
В данном примере документа пролог состоит из трех строк:
<?xml version="1.0"?> <!-- Имя файла : Inventory.xml -->
Первая строка представляет собой объявление XML, указывающее на то, что это XML-документ и содержащее номер версии. Объявление XML не является обязательным, хотя спецификация требует его включения. Если вы включаете XML-объявление, оно должно находиться в начале документа.
Вторая строка пролога состоит из пробела. С целью улучшения внешнего вида документа вы можете вставлять любое количество пустых строк между элементами пролога. При обработке они будут игнорироваться.
Третья строка пролога представляет собой комментарий. Добавление комментариев в XML-документ не обязательно, но позволяет сделать его более понятным. Номер версии в XML-объявлении в начале пролога документа может быть заключен как в одинарные, так и в двойные кавычки. Строки в кавычках в XML-разметке носят название литерал. Таким образом, обе приведенные ниже записи являются допустимыми: <?xml version='1.0'?> <?xml version="1.0"?> Комментарий начинается с символов <!-- и заканчивается символами -->. Между этими двумя группами символов вы можете поместить любой текст (за исключением --); XML-процессор проигнорирует его. Пролог может также содержать следующие необязательные компоненты:
· объявление типа документа, определяющее тип и структуру документа. Объявление типа документа должно следовать после XML-объявления; · одну или несколько инструкций по обработке, содержащих информацию о порядке проходов при обработке приложения XML-процессором. (Например,инструкцию по обработке для связывания таблицы стиля с XML-документом).
специальные символы (<,>,&,",' и т.д.) пример файла: (помимо картиночки) <?xml version="1.0" encoding="WINDOWS-1251"?> 6. XML процессор. Использование инструкций по обработке. Директивы анализатора. Примеры
XML-процессор — это программный модуль, считывающий XML-документ и обеспечивающий доступ к его содержимому. Он также предоставляет этот доступ другим программным модулям, или приложениям, которые манипулируют и отображают содержимое документа. Если вы отображаете XML-документ в Internet Explorer 5, браузер включает в себя как XML-процессор, так и приложение. (Если для отображения XML-документа вы используете HTML и сценарий (скрипт-код), то при этом самостоятельно создаете часть приложения.) Обратите внимание, что термин приложение в данном случае отличен от термина, применяемого для обозначения XML-приложения (или словаря) как целевого набора элементов и структуры документа, которые используются для описания документов определенного типа. В XML-документы могут быть включены не относящиеся к содержимому документа инструкции, несущие информацию для приложения, которое будет этот документ обрабатывать. Инструкции по обработке имеют вид: <?приложение содержимое?> Инструкция по обработке всегда заключается в угловые скобки со знаками вопроса. Первая часть инструкции, приложение, определяет программу или систему, которой предназначена вторая часть, ее содержимое. Примером инструкции по обработке может послужить следующая запись: <?serv cache-document?> В данном случае целевое приложение имеет имя 'serv', а сама инструкция может быть интерпретирована как указание серверу на то, что документ нужно сохранить в кэше. Естественно, инструкции по обработке имеют смысл только для тех приложений, которым они адресуются.
Инструкции, предназначенные для анализаторов языка, описываются в XML документе при помощи специальных тэгов - <? и ?>;. Программа клиента использует эти инструкции для управления процессом разбора документа. Наиболее часто инструкции используются при определении типа документа (например, <? Xml version=”1.0”?>) или создании пространства имен. 7. Правила создания XML документа. Необходимое программное обеспечение для работы с XML документом Конструкции языка
Содержимое XML- документа представляет собой набор элементов, секций CDATA, директив анализатора, комментариев, спецсимволов, текстовых данных. Рассмотрим каждый из них подробней.
Элементы данных
Элемент - это структурная единица XML- документа. Заключая слово rose в в тэги <flower> </flower> , мы определяем непустой элемент, называемый <flower>, содержимым которого является rose. В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, - т.е. практически любые части XML- документа.
Любой непустой элемент должен состоять из начального, конечного тэгов и данных, между ними заключенных. Например, следующие фрагменты будут являться элементами:
<flower>rose</flower> <city>Novosibirsk</city>
,а эти - нет:
<rose> <flower> rose
Набором всех элементов, содержащихся в документе, задается его структура и определяются все иерархическое соотношения. Плоская модель данных превращается с использованием элементов в сложную иерархическую систему со множеством возможных связей между элементами. Например, опишем месторасположение Новосибирских университетов (указываем, что Новосибирский Университет расположен в городе Новосибирске, который, в свою очередь, находится в России), используя для этого вложенность элементов XML :
<country id="Russia"> <cities-list> <city> <title>Новосибирск</title> <state>Siberia</state> <universities-list> <university id="2"> <title>Новосибирский Государственный Технический Университет</title> <noprivate/> <address URL="www.nstu.ru"/> <description>очень хороший институт</description> </university> <university id="2"> <title>Новосибирский Государственный Университет</title> <noprivate/> <address URL="www.nsu.ru"/> <description>тоже не плохой</description> </university> </universities-list> </city> </cities-list> </country>
Производя в последствии поиск в этом документе, программа клиента будет опираться на информацию, заложенную в его структуру - используя элементы документа. Т.е. если, например, требуется найти нужный университет в нужном городе, используя приведенный фрагмент документа, то необходимо будет просмотреть содержимое конкретного элемента <university>, находящегося внутри конкретного элемента <city>. Поиск при этом, естественно, будет гораздо более эффективен, чем нахождение нужной последовательности по всему документу.
В XML документе, как правило, определяется хотя бы один элемент, называемый корневым и с него программы-анализаторы начинают просмотр документа. В приведенном примере этим элементом является <country>
В некоторых случаях тэги могут изменять и уточнять семантику тех или иных фрагментов документа, по разному определяя одну и ту же информацию и тем самым предоставляя приложению-анализатору этого документа сведения о контексте использования описываемых данных. Например, прочитав фрагмент <city>Holliwood</city> мы можем догадаться, что речь в этой части документа идет о городе, а вот во фрагменте <restaurant>Holliwood</restaurant> - о забегаловке.
Объявление типов элементов
В валидном XML-документе вы должны полностью объявить тип каждого элемента, который вы используете в документе, в объявлении типа элемента внутри DTD. Объявление типа элемента указывает на типы элементов, которые содержит документ, порядок следования элементов, а также описание содержимого элементов.
Объявление типа элемента имеет следующую обобщенную форму:
<!ELEMENT Имя опись_содержимого>
Здесь Имя есть имя объявляемого типа элемента. Опись одержимого - это описание содержимого, которое определяет, что может содержать элемент.
Ниже приведено объявление типа элемента с именем TITLE, для содержимого которого могут использоваться только символьные данные (дочерние элементы не допускаются):
<!ELEMENT TITLE (#PCDATA)>
А вот объявление для типа элемента с именем GENERAL, содержимое которого может быть любым:
<!ELEMENT GENERAL ANY>
В качестве последнего примера рассмотрим законченный XML-документ с двумя типами элементов. Объявление типа элемента COLLECTION указывает, что он может содержать один или несколько элементов CD, a объявление типа элемента CD указывает, что он может содержать только символьные данные. Заметим, что документ соответствует этим объявлениям, и, следовательно, является валидным:
<?xml version="1.0"?> <!DOCTYPE COLLECTION [ <!ELEMENT COLLECTION (CD)+> <!ELEMENTCD(#PCDATA)> <!-- Вы также можете включать комментарии в DTD. --> ] > <COLLECTION> <CD>Mozart Violin Concertos 1,2, and 3</CD> <CD>Telemann Trumpet Concertos</CD> <CD>Handel Concetti Grossi Op. 3</CD> </COLLECTION>
Вы можете объявить определенный тип элемента в данном документе только один раз.
Задание содержимого элемента
Если элемент имеет содержимое, он может непосредственно содержать только определенные дочерние элементы, но не символьные данные. В тексте документа вы можете разделять дочерние элементы пробелами, чтобы улучшить восприятие документа, но процессор будет игнорировать символы пробела и не передаст их приложению.
Рассмотрим следующий пример XML-документа, описывающий одну книгу:
<?xmlversion="1.0"?> <!DOCTYPE BOOK [ <!ELEMENT BOOK (TITLE, AUTHOR)> <!ELEMENT TITLE (#PCDATA}> <!ELEMENT AUTHOR (#PCDATA)> ] > <BOOK> <TITLE>The Scarlet Letter</TITLE> <AUTHOR>NathanielHawthorne</AUTHOR> </BOOK>
В этом документе тип элемента BOOK объявлен как имеющий содержимое элемента. (TITLE, AUTHOR), следующие за именем элемента в объявлении, составляют модель содержимого. Модель содержимого указывает на разрешенные типы дочерних элементов и их порядок. В этом примере модель содержимого указывает на то, что элемент BOOK должен иметь ровно один дочерний элемент TITLE, за которым следует ровно один дочерний элемент AUTHOR.
Задание содержимого элемента (мы это проходили с теми ребятами с ФКНа) Если элемент имеет содержимое, он может непосредственно содержать только определенные дочерние элементы, но не символьные данные. Рассмотрим следующий пример XML-документа, описывающий одну книгу: <!DOCTYPE BOOK [ <!ELEMENT BOOK (TITLE, AUTHOR)> <!ELEMENT TITLE (#PCDATA}> <!ELEMENT AUTHOR (#PCDATA)> ] > <BOOK> <TITLE>The Scarlet Letter</TITLE> <AUTHOR>NathanielHawthorne</AUTHOR> </BOOK> В этом документе тип элемента BOOK объявлен как имеющий содержимое элемента. (TITLE, AUTHOR), следующие за именем элемента в объявлении, составляют модель содержимого. Модель содержимого указывает на разрешенные типы дочерних элементов и их порядок. В этом примере модель содержимого указывает на то, что элемент BOOK должен иметь ровно один дочерний элемент TITLE, за которым следует ровно один дочерний элемент AUTHOR.
<!DOCTYPE MOUNTAIN [ <!ELEMENT MOUNTAIN (NAME, HEIGHT, STATE)> <!ELEMENT NAME (#PCDATA)> <!ELEMENT HEIGHT (#PCDATA)> <!ELEMENT STATE (#PCDATA)> ] > Следовательно, следующий элемент Документ будет валидным: <MOUNTAIN> <NAME>Wheeler</NAME> <HEIGHT>13161</HEIGHT> <STATE>New Mexico</STATE> </MOUNTAIN> Следующий элемент Документ, однако, не будет валидным, поскольку порядок дочерних элементов не соответствует объявленному Пропуск дочернего элемента или использование одного и того же типа дочернего элемента более одного раза также недопустимо.
<!DOCTYPEFILM [ <!ELEMENT FILM (STAR | NARRATOR | INSTRUCTOR)> <!ELEMENT STAR (#PCDATA)> <!ELEMENT NARRATOR (#PCDATA)> <!ELEMENT INSTRUCTOR (#PCDATA)> ] > Следовательно, следующий элемент Документ будет валидным: <FILM> <STAR>Robert Redford</STAR> </FILM> как и элемент: <FILM> <NARRATOR>Sir Gregory Parsloe</NARRATOR> </FILM> а также элемент: <FILM> <INSTRUCTOR>GalahadThreepwood</INSTRUCTOR> </FILM> Мы можем изменить любую из этих форм модели содержимого, используя знак вопроса (?), знак плюс (+) и звездочку (*), значения которых описаны в следующей таблице:
Например, следующее объявление означает, что вы можете включить один или более дочерних элементов NAME, и что дочерний элемент HEIGHT является не обязательным: <!ELEMENT MOUNTAIN (NAME+, HEIGHT?, STATE)> Вы также можете воспользоваться символами ?, + или * для модификации всей модели содержимого, помещая символы непосредственно после закрывающих скобок. Например, <!ELEMENT FILM (STAR | NARRATOR | INSTRUCTOR)+> Задание смешанного содержимого Если элемент имеет смешанное содержимое, он может включать символьные данные. Если же мы зададим в объявлении один или несколько типов дочерних элементов, он может содержать любые из этих дочерних элементов в любом порядке и с любым количеством вхождений (нуль и более). Другими словами, при смешанном содержимом вы можете задавать типы дочерних элементов, но не можете задавать порядок или количество вхождений дочерних элементов, а также задавать обязательность включения для определенных типов дочерних элементов. Чтобы объявить тип элемента смешанного содержимого, мы можем воспользоваться одной из ... одной (!) форм модели содержимого.
<!ELEMENT SUBTITLE (#PCDATA)> Следующие два элемента в соответствии с данной декларацией являются корректными: <SUBTITLE>A New Approach</SUBTITLE> <SUBTITLE></SUBTITLE> Заметим, что элемент, который в соответствии с объявлением должен содержать символьные данные, может и не иметь никаких символов, т.е. быть пустым.
Набором всех элементов, содержащихся в документе, задается его структура и определяются все иерархическое соотношения. Плоская модель данных превращается с использованием элементов в сложную иерархическую систему со множеством возможных связей между элементами. Например, опишем месторасположение Новосибирских университетов (указываем, что Новосибирский Университет расположен в городе Новосибирске, который, в свою очередь, находится в России), используя для этого вложенность элементов XML:
<country id="Russia"> <cities-list> <city> <title>Новосибирск</title> <state>Siberia</state> <universities-list> <university id="2"> <title>Новосибирский Государственный Технический Университет</title> <noprivate/> <address URL="www.nstu.ru"/> <description>очень хороший институт</description> </university> <university id="2"> <title>Новосибирский Государственный Университет</title> <noprivate/> <address URL="www.nsu.ru"/> <description>тоже не плохой</description> </university> </universities-list> </city> </cities-list> </country>
Производя в последствии поиск в этом документе, программа клиента будет опираться на информацию, заложенную в его структуру - используя элементы документа. Т.е. если, например, требуется найти нужный университет в нужном городе, используя приведенный фрагмент документа, то необходимо будет просмотреть содержимое конкретного элемента <university>, находящегося внутри конкретного элемента <city>. Поиск при этом, естественно, будет гораздо более эффективен, чем нахождение нужной последовательности по всему документу.
В XML документе, как правило, определяется хотя бы один элемент, называемый корневым и с него программы-анализаторы начинают просмотр документа. В приведенном примере этим элементом является <country>
В некоторых случаях тэги могут изменять и уточнять семантику тех или иных фрагментов документа, по разному определяя одну и ту же информацию и тем самым предоставляя приложению-анализатору этого документа сведения о контексте использования описываемых данных. Например, прочитав фрагмент <city>Holliwood</city> мы можем догадаться, что речь в этой части документа идет о городе, а вот во фрагменте <restaurant>Holliwood</restaurant> - о забегаловке.
В случае, если элемент не имеет содержимого, т.е. нет данных, которые он должен определять, он называется пустым. Примером пустых элементов в HTML могут служить такие тэги HTML, как <br>, <hr>, <img>;. Необходимо только помнить, что начальный и конечные тэги пустого элемента как бы объединяется в один, и надо обязательно ставить косую черту перед закрывающей угловой скобкой (например, <empty/>;)
Элементы данных Элемент - это структурная единица XML- документа. Заключая слово rose в в тэги <flower> </flower> , мы определяем непустой элемент, называемый <flower>, содержимым которого является rose. В общем случае в качестве содержимого элементов могут выступать как просто какой-то текст, так и другие, вложенные, элементы документа, секции CDATA, инструкции по обработке, комментарии, - т.е. практически любые части XML- документа. Набором всех элементов, содержащихся в документе, задается его структура и определяются все иерархическое соотношения. Плоская модель данных превращается с использованием элементов в сложную иерархическую систему со множеством возможных связей между элементами. В XML документе, как правило, определяется хотя бы один элемент, называемый корневым и с него программы-анализаторы начинают просмотр документа. В приведенном примере этим элементом является <country> Атрибуты Если при определении элементов необходимо задать какие-либо параметры, уточняющие его характеристики, то имеется возможность использовать атрибуты эдлемента. Атрибут - это пара "название" = "значение", которую надо задавать при определении элемента в начальном тэге. Пример: <color RGB="true">#ff08ff</color> <color RGB="false">white</color> или <author id=0>Ivan Petrov</author> Примером использования атрибутов в HTML является описание элемента <font>: <font color=¦white¦ name=¦Arial¦>Black</font> ТИПЫ АТРИБУТОВ: Строковый тип . Строковый тип атрибута может быть назначен любой строке в кавычках (литералу) <!ATTUST FILM Class CDATA "fictional"> Маркерный тип . Значения, которые вы можете присваивать атрибуту маркерного типа. Нумерованный тип. Для нумерованного типа атрибута вы можете присваивать одно значение или список определенных значений.
Строковый тип. Строковый тип атрибута может быть назначен любой строке в кавычках (литералу) <!ATTUST FILM Class CDATA "fictional"> Маркерный тип. Значения, которые вы можете присваивать атрибуту маркерного типа. Нумерованный тип. Для нумерованного типа атрибута вы можете присваивать одно значение или список определенных значений. Маркерный тип: Существует несколько типов маркерных атрибутов. Наиболее важными являются ID и IDREF. Атрибуты типа ID используются для однозначной идентификации элементов. Атрибут ID должен однозначно идентифицировать тот элемент, в котором он содержится. Например, в следующем объявлении задается обязательный атрибут ID, используемый для идентификации товара: <iATTLIST product id ID #REQUIRED> Атрибуты ID и IDREF можно использовать почти так же, как теги якоря А в HTML Значением атрибута IDREF должно быть значение атрибута ID какого-либо другого элемента (то есть они задают перекрестную ссылку). Например, в следующем фрагменте DTD объявляется элемент с атрибутом ID и элемент с атрибутом IDREF, который ссылается на первый элемент [Featured_products — ключевые товары, product_reference — ссылка на товар]: <!ELEMENT product (name.description,price)> <!ATTLIST product id ID #REQUIRED> <!ELEMENT featured_products (product_reference)*> <!ELEMENT product_ref (#PCDATA)> <!ATTLIST product_ref link IDREF #IMPLIED> В файле XML, который использует это DTD, может содержаться фрагмент, подобный следующему: <product id= "X4343"> <name>rock</name> </product> <featured_products> <product_ref link = "X4343">a rock</product_ref> </featured_products> В атрибутах перечислимых типов приводится список всех возможных значений этого атрибута. Например, если вы хотите объявить атрибут с именем angle_type для элемента, названного triangle, можно указать возможные значения следующим образом [Triangle — треугольник, angle_type — тип угла, obtuse|acute|nght — тупои|острыи|прямой]: <!ATLIST triangle angle_type (obtuse | acute | right)? #REQUIRED> Существует несколько ключевых слов, которые можно использовать, чтобы указать, должен ли этот атрибут обязательно содержаться в элементе и должен ли он принимать какое-то фиксированное значение. В следующей небольшой таблице приведены эти ключевые слова и указано их значение. Если вы не включите в объявление атрибута ни одно из этих ключевых слов, то по умолчанию будет подразумеваться слово IMPLIED: • #REQUIRED. Обязательно задается значение атрибута для каждого элемента ассоциированного типа. <!ATTLJST FILM Class CDATA #REQUIRED> • #IMPLIED можно либо включить, либо опустить атрибут для элемента ассоциированного типа, при этом никакое значение по умолчанию процессору не передается. <!ATTUSTFILM Class CDATA #IMPLIED> • #FIXED AttValue, где AttValue - значение атрибута по умолчанию. <!ATTLIST FILM Class CDATA #FIXED "documentary"> <FILM>The Making of XML</FILM> <FILM Class="documentary">The Making of XML</FILM>
XSL-таблица стилей (eXtensible Stylesheet Language - расширяемый язык таблиц стилей) связывается с XML-документом и сообщает браузеру, как отображать данные XML. XSL позволяет открывать XML-документ непосредственно в браузере без посредничества HTML-страницы. XSL позволяет осуществлять отбор и сортировку данных XML при их отображении, предоставляет доступ ко всем компонентам XML (элементам, атрибутам, комментариям и инструкциям по обработке), даёт возможность включать в таблицу стилей сценарии. Существуют два основных шага для отображения XML-документа при использовании XSL-таблицы стилей:
<?xml-stylesheet type="text/xsl" href=xslFileURL?> Здесь "xslFileURL" - URL файла XSL-таблицы стилей. Если вы используете полный (не относительный) URL, таблица стилей должна размещаться в том же домене, что и сам XML-документ. Инструкция по обработке xml-stylesheet добавляется в пролог XML-документа вслед за объявлением XML. Если вы связываете с XML-документом более одной XSL-таблицы стилей, браузер использует первую таблицу и игнорирует все остальные. Если вы связываете с XML-документом одновременно CSS-таблицу и XSL-таблицу стилей, браузер использует только XSL-таблицу стилей. Если XML-документ не связан ни с CSS-таблицей, ни с XSL-таблицей стилей, Internet Explorer отобразит документ с помощью встроенной XSL-таблицы, которая используется по умолчанию. Вы можете открыть XML-документ непосредственно через Internet Explorer 5, точно так же, как вы бы открыли HTML Web-страницу. Если XML-документ не содержит связи с таблицей стилей, Internet Explorer 5 помечает различные составные части документа различным цветом, чтобы облегчить их распознавание, а также представляет элемент Документ в виде иерархического дерева с возможностью свертывания и развертывания структуры и просмотра с меньшей или большей степенью детализации. Если же XML-документ имеет связь с таблицей стиля, Internet Explorer 5 отобразит только символьные данные из элементов документа, отформатировав их в соответствии с правилами, установленными в таблице стиля. Вы можете использовать либо таблицу каскадных стилей (CSS-таблицу, аналогичную той, которая используется для HTML-страниц), либо XSL-таблицу стилей (Extensible Stylesheet Language), которая является более мощным инструментом и строится в соответствии с синтаксисом, принятым для XML. Такие таблицы могут использоваться исключительно для XML-документов. Пример: <!-- File Name: Inventory.xml --> <INVENTORY> <BOOK> <TITLE>The Adventures of Huckleberry Finn</TITLE> <AUTHOR>Mark Twain</AUTHOR> <BINDING>mass market paperback</BINDING> <PAGES>298</PAGES> <PRICE>$5.49</PRICE> </BOOK> <BOOK> <TITLE>Leaves of Grass</TITLE> <AUTHOR>Walt Whitman</AUTHOR> <BINDING>hardcover</BINDING> <PAGES>462</PAGES> <PRICE>$7.75</PRICE> </BOOK> <BOOK> <TITLE>The Legend of Sleepy Hollow</TITLE> <AUTHOR>Washington Irving</AUTHOR> <BINDING>mass market paperback</BINDING> <PAGES>98</PAGES> <PRICE>$2.95</PRICE> </BOOK> <BOOK> <TITLE>The Marble Faun</TITLE> <AUTHOR>Nathaniel Hawthorne</AUTHOR> <BINDING>trade paperback</BINDING> <PAGES>473</PAGES> <PRICE>$10.95</PRICE> </BOOK> <BOOK> <TITLE>Moby-Dick</TITLE> <AUTHOR>Herman Melville</AUTHOR> <BINDING>hardcover</BINDING> <PAGES>724</PAGES> <PRICE>$9.95</PRICE> </BOOK> <BOOK> <TITLE>The Portrait of a Lady</TITLE> <AUTHOR>Henry James</AUTHOR> <BINDING>mass market paperback</BINDING> <PAGES>256</PAGES> <PRICE>$4.95</PRICE> </BOOK> <BOOK> <TITLE>The Scarlet Letter</TITLE> <AUTHOR>Nathaniel Hawthorne</AUTHOR> <BINDING>trade paperback</BINDING> <PAGES>253</PAGES> <PRICE>$4.25</PRICE> </BOOK> <BOOK> <TITLE>The Turn of the Screw</TITLE> <AUTHOR>Henry James</AUTHOR> <BINDING>trade paperback</BINDING> <PAGES>384</PAGES> <PRICE>$3.35</PRICE> </BOOK> </INVENTORY> Отображение XML-документа без таблицы стиля
1. В Windows Explorer (Проводник) или в окне папки дважды щелкните на имени файла Inventory.xml. Internet Explorer 5 отобразит документ, как показано на верхнем рисунке на следующей странице.
2. Попробуйте изменить степень детализации представления элементов документа. Щелкните на символе знака минус (-) слева от начального тега, чтобы свернуть элемент, либо на знаке плюс (+) рядом со свернутым элементом, чтобы развернуть его. Например, щелкнув на знаке минус (-) рядом с элементом INVENTORY, вы получите то же, что представлено на нижнем рисунке на следующей странице.
Каскадные (многоуровневые) таблицы стилей - cascading style sheets (CSS) - это мощный стандарт на основе текстового формата, определяющий представление данных в броузере. CSS предполагает 3 типа таблиц стилей - встроенные, внедренные (внутренние) и связанные (внешние). Впервые идея форматирования HTML-документов с помощью CSS была рекомендована Консорциумом W3C в 1996 году. Эта рекомендация, которая была обновлена в 1998 году, используется Web-разработчиками и по сей день. Что значит слово "каскадный"? Поддержка шрифтов в таблицах стилей Один из наиболее привлекательных аспектов таблиц стиля - это возможность применения различных шрифтов к определенной странице без необходимости использовать многочисленные теги <font>. Таблицы стилей позволяют выбирать ряд шрифтов и применять их к конкретным разделам страницы типа номера заголовка, абзаца или другого фрагмента. Однако вместо стандартного тега HTML <font> используется атрибут таблицы стилей font-family. Вы можете добавлять в этот тег многие атрибуты либо использовать классы и группировку, чтобы реализовать всю мощь средств работы со шрифтами с помощью таблиц стилей.
Форма записи раздела CDATA
Чтобы задать область документа, которую при разборе анализатор будет рассматривать как простой текст, игнорируя любые инструкции и специальные символы, но, в отличии от комментариев, иметь возможность использовать их в приложении, необходимо использовать тэги <![CDATA] и ]]>. Внутри этого блока можно помещать любую информацию, которая может понадобится программе- клиенту для выполнения каких-либо действий (в область CDATA, можно помещать, например, инструкции JavaScript).
Раздел CDATA начинается с символов <![CDATA[ и заканчивается символами ]]>.
Между этими двумя ограничителями вы можете поместить любые символы (включая < или &), за исключением ]]>. Все символы внутри раздела CDATA трактуются как литеральная часть символьных данных элемента, а не как XML-разметка.
Ниже приведен пример правильно записанного раздела CDATA:
<![CDATA[ Здесь вы можете разместить любые символы, за исключением двух правых квадратных скобок с последующим знаком «больше». ]]>
Ключевое слово CDATA (как и другие ключевые слова XML) должно быть набрано прописными буквами.
Если вы хотите включить в состав имеющихся символьных данных блок исходного кода или разметку, которые будут отображаться браузером, то можете воспользоваться разделом CDATA с целью предотвратить интерпретацию синтаксическим анализатором символов < или & как XML-разметку. Например:
<A-SECTION>
Вот пример очень простой HTML-страницы:
<![CDATA[ <HTML> <HEAD> <TITLE>R. Jones & Sons</TITLE> </HEAD> <BODY> <Р>Добро пожаловать на нашу домашнюю страницу! </Р> </BODY> </HTML> ]]> </A-SECTION>
Внутри раздела CDATA процессор будет предполагать, что <HTML>, например, есть начало вложенного элемента, но не часть символьных данных элемента A-SECTION.
Где разместить раздел CDATA
Раздел CDATA можно поместить в любое место, занимаемое символьными данными - т.е. внутри содержимого элемента, но не внутри XML-разметки. Вот правильно записанный раздел CDATA:
<?xmlversion="1.0"?> <MUSICAL> <TITLE PAGE> <![CDATA[ <0klahoma!> By Rogers & Hammerstein ]]> </TITLE_PAGE> <!-- Здесь расположены другие элементы... -> </MUSICAL>
Ошибочно сформированный XML-документ, представленный ниже, содержит два неправильно записанных раздела CDATA. Первый из них не находится внутри содержимого элемента. Второй находится внутри содержимого элемента, но также и внутри начального тега разметки.
<?xmlversion="1.0"?> <![CDATA[ ОШИБКА: не внутри содержимого элемента! ]]> <DOC ELEMENT> <SUB_ELEMENT <![CDATA[ ОШИБКА: внутри разметки! ]]> > содержимое подэлемента... </SUB ELEMENT> </DOC_ELEMENT>
Примечание . Разделы CDАТА не являются вложениями. Вы не можете поместить один раздел СDАТА внутрь другого.
Валидным (valid) называется корректно сформированный (well-formed) документ, отвечающий двум дополнительным требованиям:
Требования валидности представляют собой дополнительный набор правил в спецификации XML. Поскольку валидность является не обязательной для XML-документа, отклонение от требований валидноcти считается лишь ошибкой (error), но не фатальным сбоем. Если XML- процессор встречает ошибку, он может просто выдать сообщение о ней и продолжить обработку. Область схемы данных
Создавая схемы данных, мы определяем в документе специальный элемент, <schema>;, внутри которого содержатся описания правил:
<schema id="OurSchema"> <!-- последовательность инструкций --> </schema> Если использовать отдельное пространство имен, то полный XML-документ, содержащий в себе схему данных, будет выглядеть следующим образом:
<?XML version='1.0' ?> <?xml:namespace href="http://www.mrcpk.nstu.ru/schemas/" as="s"/?> <s:schema id="OurSchema"> <!-- последовательность инструкций --> </s:schema> Описание элементов
Для определения класса элемента, к которому в дальнейшем будут применяться инструкции, описывающие его содержимое и структуру, предназначен специальный элемент схемы elementType, <elementType id="issue"> <descript>Элемент содержит информацию об очередном выпуске журнала</descript> </elementType> Название элемента задается атрибутом id . Все дальнейшие инструкции, которые относятся к описываемому классу, определяют его внутреннюю структуру и набор допустимых данных, содержатся внутри блока, заданного тэгами <elementType> и </elementType>. Мы рассмотрим эти инструкции чуть позже. Как видно из примера, при определении класса элемента, можно также использовать комментарии к нему, которые заключаются в тэги <descript></descript>
Атрибуты элемента Для того, чтобы в описании элемента определить его атрибуты и описать свойства этих атрибутов мы должны использовать элемент attribute: <elementType id="photo"> <attribute name="src"/> <empty/> </elementType> В данном примере элементу <photo> определяется атрибут src, значением которого может быть любая последовательность разрешенных символов: <photo src="0"/> <photo src="some text"> Подобно DTD, схемы данных позволяют устанавливать ограничения на значения и способ использования атрибутов. Для этого в дескрипторе <attribute> необходимо использовать параметр atttype. Например, если мы хотим указать, что значение атрибута должно использоваться программой-анализатором как уникальный идентификатор, то нам необходимо создать следующее правило: <elementType id="bouquet"> <attribute name="id" atttype="ID"> </elementType> Если же требуется задать список возможных значений атрибута, то пример будет выглядеть следующим образом: <attribute name="flower" atttype="ENUMERATION" values="red green blue" default="red"> Для приведенных примеров корректным будет являться следующий фрагмент XML-документа: <bouquet id="0"> <flower color="red">rose</flower> <flower color="green">leaf</flower> <flower color="blue">bluet</flower> </bouquet> Модель содержимого элемента Под моделью содержимого в схеме данных понимают описание всех допустимых объектов XML- документа, использование которых внутри данного элемента является корректным. Модель содержимого определяется инструкциями, расположенными внутри блока <elementType>. <elementType id="article"> <attribute name="id" atttype="ID"> <element type="#title"> <string/> </elementType> Для этого правила корректным будет являться следующий фрагмент документа: <article id="0"> <title>Психи и маньяки в Интернет</title> </article> Вложенные элементы описываются при помощи инструкции element, в которой параметром type указывается класс объекта - ссылка на его определение: <elementType id="article"> <element type="#title"/> <element type="#author"/> </elementType> Если требуется указать режим использования вложенного элемента, то надо определить параметр occurs: <elementType id="article"> <element type="#title" occurs="REQUIRED"/> <element type="#author" occurs="OPTIONAL"/> <element type="#subject" occurs="ONEORMORE"/> </elementType> Возможные значения этого параметра таковы:
Примеры правильных XML-документа, использующих приведенную выше схему: <article> <title>Зачем он нужен, XML?</title> <author>Иван Петров</author> <subject>Что такое XML</subject> <subject>нужен ли он нам</subject> </article> или <article> <title>Зачем он нужен, XML?</title> <subject>Что такое XML</subject> </article> Кроме элементов, содержимым XML-документа могут также является обычный текст и области CDATA. Для обозначения типов содержимого текущего элемента в схемах используются следующие инструкции:
· <elementType id="flower"> · <string/> · </elementType>
· <elementType id="issue"> · <any/> · </elementType>
· <elementType id="contacts"> · <mixed/> · </elementType>
Пример: <elementType id="title"> <string/> </elementType> <elementType id="chapter"> <string/> </elementType> <elementType id="chapters-list"> <any/> </elementType> <elementType id="content"> <element type="#chapters-list" occurs="OPTIONAL"> </elementType> <elementType id="article"> <mixed><element type="#title"></mixed> <element type="#content" occurs="OPTIONAL"> </elementType>
Элемент group используется для того, чтобы задать некоторую последовательность вложенных объектов: <elementType id="contacts"> <element type="#tel" occurs="ONEORMORE"> <group occurs="OPTIONAL"> <element type="#email"> <element type="#url"> </group> </elementType> Группировка объектов позволяет определять сразу группу объектов различных типов, которые могут находится внутри данного объекта. В приведенном примере мы указали, что внутри объекта типа contacts могут быть включены элементы tel, email, и url, причем атрибутом occurs мы указали, что элементы в группе являются необязательными. Корректным для таких схем будут являться следующие фрагменты документов: <contacts> <tel>12-12-12</tel> <email>[email protected]</email> <url>http://www.j.com</url> </contacts> ... <contacts> <tel>12-12-12</tel> </contacts> ... <contacts> <tel>12-12-12</tel> <email>[email protected]</email> </contacts> При помощи атрибута groupOrder можно также задавать режим использования группированных элементов При установленном значении OR возможно использование не всех элементов группы, а лишь некоторых из них. Если задано значение AND, то оба элемента должны быть включены в обязательном порядке. Например, для следующей группы правил: <elementType id="contacts"> <element type="#tel" occurs="ONEORMORE"> <group groupOrder="AND" occurs="OPTIONAL"> <element type="#email"> <element type="#url"> </group> </elementType> будут считаться правильными только следующие варианты: <contacts> <tel>12-12-12</tel> <email>[email protected]</email> <url>http://www.j.com</url> </contacts> или <contacts> <tel>12-12-12</tel> </contacts> Пример диалога Human: I am Mahesh Robot: Hello Mahesh! Human: Good Night Robot: Good Night Mahesh! Thanks for the conversation!
Тег <that>
Данный тег используется в AIML для реагирования внутри контекста
<category> <pattern>WHAT ABOUT MOVIES</pattern> <template>Do you like comedy movies</template> </category> <category> <pattern>YES</pattern> <that>Do you like comedy movies</that> <template>Nice, I like comedy movies too.</template> </category> <category> <pattern>NO</pattern> <that>Do you like comedy movies</that> <template>Ok! But I like comedy movies.</template> </category>
Human: Hi Alice! What about movies? Robot: Do you like comedy movies? Human: No Robot: Ok! But I like comedy movies.
Тег < topic > Данный тег используется в AIML для хранение контекста, на основе которого будет базироваться дальнейший диалог с ботом. Как правило, тег <topic> используется в общении типа ДА/НЕТ Human: let discuss movies Robot: Yes movies Human: Comedy movies are nice to watch Robot: Watching good movie refreshes our minds. Human: I like watching comedy Robot: I too like watching comedy.
<category> <pattern>LET DISCUSS MOVIES</pattern> <template>Yes <set name="topic">movies</set></template> </category> <topic name="movies"> <category> <pattern> * </pattern> <template>Watching good movie refreshes our minds.</template> </category> <category> <pattern> I LIKE WATCHING COMEDY! </pattern> <template>I like comedy movies too.</template> </category> </ topic > Тег < think > Данный тег используется в AIML для хранения значения переменной без уведомления пользователя об этом.
Human: My name is Mahesh Robot: Hello! Human: Byeee Robot: Hi Mahesh Thanks for the conversation!
<category> <pattern>My name is *</pattern> <template> Hello!<think><set name="username"> <star/></set></think> </template> </category> <category> <pattern>Byeee</pattern> <template> Hi <get name="username"/> Thanks for the conversation! </template> </category> Тег < condition > Данный тег похож на переключатель темы Human: How are you feeling today Robot: I am happy!
<category> <pattern>ARE YOU FEELING TODAY *</pattern> <template> <think><set name="state"> <star/> </set></think> <condition name="state" value="happy"> I am happy! </condition> <condition name="state" value="sad"> I am sad! </condition> </template> </category> 23. Программный бот, его программирование, регистрация в WWW, сообщества ботов. Области использования ботов. Ро́бот, или бот, а также интернет-бот, www-бот и т. п. (англ. bot, сокр. от чеш. robot) — специальная программа, выполняющая автоматически и/или по заданному расписанию какие-либо действия через те же интерфейсы, что и обычный пользователь. Обычно боты предназначаются для выполнения работы, однообразной и повторяемой, с максимально возможной скоростью (очевидно, намного выше возможностей человека). Лицо, обслуживающее серверы, может поместить на сервере файл robots.txt, содержащий ограничения, которым обязаны подчиняться боты. Боты находят также применение в условиях, когда требуется лучшая реакция по сравнению с возможностями человека (например, игровые боты, боты для интернет-аукционов и т. п.) или, реже, для имитации действий человека (например, боты для чатов и т. п.). Чат-бот может выдать достаточно адекватный ответ на вопрос, сформулированный на правильном русском языке (или любом другом, работа с которым поддерживается). Такие боты часто применяются для сообщения прогноза погоды, результатов спортивных соревнований, курсов валют, биржевых котировок и т. п. Они находят применение, например, в системе SmarterChild в AOL Instant Messenger и MSN messenger. (наплетите фигню, как мы создавали чат-бота на сайте Pandora). Также бывают боты для коммерческого использования, такие используются на eBay, а также для вредоносного использования. У каждого бота должна бать своя учетная запись. Все боты, которые осуществляют какие-либо протоколируемые действия (например, редактирование страниц, загрузка файлов или создание аккаунтов), должны быть одобрены до начала работы. Операторы могут осуществлять ограниченное тестирование ещё не одобренного бота при условии, что испытания малы и немногочисленны, а также ограничены в области проведения тестовыми страницами. Подобные тестовые правки могут быть выполнены из-под любой учётной записи. Кроме того, любой бот или автоматизированный процесс, затрагивающий лишь собственные личные страницы и подстраницы либо личные страницы ботовладельца, может быть запущен без предварительного одобрения. 24. Понятие онтологии, элементы онтологии : экземпляры (примеры), понятия (концепты), атрибуты, отношения.
Термин «онтология» был предложен Рудольфом Гоклениусом в 1613, имеет два значения: • «Философская дисциплина, которая изучает наиболее общие характеристики бытия и сущностей» • «Онтология – артефакт, структура, описывающая значения элементов некоторой системы» Онтология - это точная спецификация некоторой предметной области. Формальное и декларативное представление, которое включает словарь (или имена) указателей на термины предметной области и логические выражения, которые описывают, что эти термины означают, как они соотносятся друг с другом, и как они могут или не могут быть связаны друг с другом. Самое короткое определение. Онтология - это спецификация концептуализации (Том Грубер, 1993 ) • Тезаурусы -особая разновидность словарей, в которых указаны семантические отношения (синонимы, антонимы, паронимы, и т. п.) между лексическими единицами. • Словари, таксономии • Идея системы ссылок (пример нелинейного описания предметной области - Библия). Элементы онтологий Современные онтологии строятся по большей части одинаково, независимо от языка написания. Обычно они состоят из экземпляров, понятий, атрибутов и отношений. Экземпляры (англ. instances) или индивиды (англ. individuals) — это основные, нижнеуровневые компоненты онтологии. Экземпляры могут представлять собой как физические объекты (люди, дома, планеты), так и абстрактные (числа, слова). Строго говоря, онтология может обойтись и без конкретных объектов. Однако, одной из главных целей онтологии является классификация таких объектов, поэтому они также включаются. Понятия (англ. concepts) или классы (англ. classes) — абстрактные группы, коллекции или наборы объектов. Они могут включать в себя экземпляры, другие классы, либо же сочетания и того, и другого. Пример: · Понятие «люди», вложенное понятие «человек». Чем является «человек» — вложенным понятием, или экземпляром (индивидом) — зависит от онтологии. · Понятие «индивиды», экземпляр «индивид». Классы онтологии составляют таксономию — иерархию понятий по отношению вложения[1]. Объекты в онтологии могут иметь атрибуты. Каждый атрибут имеет по крайней мере имя и значение и используется для хранения информации, которая специфична для объекта и привязана к нему. Например, объект Автомобиль-модели-А имеет такие атрибуты, как: · Название: Автомобиль-модели-А · Число-дверей: 4 · Двигатель: {4.0Л, 4.6Л} · Коробка-передач: 6-ступенчатая Значение атрибута может быть сложным типом данных. В данном примере значение атрибута, который называется Двигатель, является списком значений простых типов данных. Важная роль атрибутов заключается в том, чтобы определять отношения (зависимости) между объектами онтологии. Обычно отношением является атрибут, значением которого является другой объект. Предположим, что в онтологии автомобилей присутствует два объекта — автомобиль Автомобиль-модели-А и Автомобиль-модели-Б. Пусть Автомобиль-модели-Б это модель-наследник Автомобиль-модели-А, тогда отношение между Автомобиль-модели-А и Автомобиль-модели-Б определим как атрибут «isSuccessorOf» со значением «Автомобиль-модели-А» для объекта Автомобиль-модели-Б (следует заметить, что в языках описания онтологий существуют предопределенные отношения наследования).
25. Типы онтологий: верхнего уровня, предметных областей, прикладные онтологии. Характеристики онтологий верхнего уровня (ОВУ)
n Набор основных отношений: § Иерархические § класс-подкласс § часть-целое § Ассоциативные n Типичные концепты и принципы разделения: § Сущность § Явление § Объект § Процесс § Роль n Нацеленность на многократное повторное использование онтологии
Характеристики онтологий предметных областей n Существенные отличия от ОВУ: § Охват конкретной области знаний (авиация, медицина, культура), § Круг решаемых задач и вопросов, на которые онтология отвечает, ограничен выбранной областью, § Больший по сравнению с ОВУ объем онтологии, § Наличие отношений специфичных для конкретной области. n Повторное использование только в рамках предметной области
Характеристики прикладных онтологий n Направленность на решение конкретной задачи, обеспечение работы некоторого приложения. n Круг вопросов, на которые онтология отвечает n Задается перед ее созданием n Влияет на процесс концептуализации n Используется для проверки “компетентности” онтологии
26. Языки описания онтологий. Стандарты. Язык описания онтологий — формальный язык, используемый для кодирования онтологии. Существует несколько подобных языков (изначально это был язык XML): · OWL — Web Ontology Language, стандарт W3C, язык для семантических утверждений, разработанный как расширение RDF и RDFS; · KIF (англ.)русск. (англ. Knowledge Interchange Format — формат обмена знаниями) — основанный на S-выражениях синтаксис для логики; · Common Logic (CL) (англ.)русск. — преемник KIF (стандартизован — ISO/IEC 24707:2007). · CycL (англ.)русск. — онтологический язык, использующийся в проекте Cyc. Основан на исчислении предикатов с некоторыми расширениями более высокого порядка. · DAML+OIL (англ.) русск. (FIPA) Для работы с языками онтологий существует несколько видов технологий: редакторы онтологий (для создания онтологий), СУБД онтологий (для хранения и обращения к онтологии) и хранилища онтологий (для работы с несколькими онтологиями).
27. Назначение онтологий. Задачи, решаемые с помощью онтологий. ОНТОЛОГИИ: применение • формирование и фиксация общего разделяемого всеми экспертами знания о предметной области (ПО) • явная концептуализация ПО, позволяющая описывать семантику данных • Возможность многократно использовать формализованные знания • интеграция и возможность совместного использования разнородных данных и знаний в рамках одной системы • обеспечение лучшего понимания предметной области пользователями системы • Использование онтологии при проектировании и разработке ИС (управляемая онтологией разработка ИС). • Использование онтологии в качестве полноценного компонента ИС (в управляемой онтологией ИС) История развития компьютерных сетей передачи данных. Появление Internet .
В 1958 году в ответ на запуск советского спутника США создают ARPA. Усилия организации, направленные на исследования в области компьютерных технологий, возглавил д-р Ликлайдер (J.C.R. Licklider *). Произошло это в октябре 1962 года. Обработка, хранение, передача информации — все эти процессы тогда выполнялись на перфокартах, что существенно усложняло весь процесс исследований и расчетов. Ведь ARPA работало (да и работает) на контрактной основе: заключаются контракты на исполнение какого-то куска работы с неправительственными организациями или университетами, которые располагаются в разных штатах, на разных побережьях. Поэтому первоначальная задача перед Ликлайдером стояла в изменении самого технологического процесса. Весной 1967 года в Университете города Мичигана состоялась ежегодная встреча "исследователей принципа". Ее цель была скоординировать дальнейшие шаги в развитии сетей. Помимо ARPA, на встрече присутствовали организации, вовлеченные в процесс создания "интергалактической сети" (изначальна формулировка Ликлайдера для будущей сети). Активное участие в обсуждении принимали уже упомянутый Паул Бэран и Томас Мэрилл
"Протоколы и построения сети были окончательно обсуждены на встрече в июне 1968 года. После чего ARPANET, как официальный проект, начала свое существование." Программа, получившая название "Распределение ресурсов компьютерных сетей", была принята 3 июня 1968 года и одобрена директором ARPA 21 июня.
В 1973 сеть выросла до международных масштабов, объединив сети, находящиеся в Англии и Норвегии. Десятилетие спустя IP был расширен за счет набора коммуникационных протоколов, поддерживающих как локальные, так и глобальные сети. Так появился TCP/IP. Вскоре после этого, National Science Foundation (NSF) открыла NSFnet с целью связать 5 суперкомпьютерных центров. Одновременно с внедрением протокола TCP/IP новая сеть вскоре заменила ARPAnet в качестве «хребта» (backbone) Интернета.
Появление World Wide Web (WWW), понятие гипертекстовой среды работы с документами. Всеми́рная паути́на— распределённая система, предоставляющая доступ к связанным между собой документам, расположенным на различных компьютерах, подключённых к Интернету. Для обозначения Всемирной паутины также используют слово веб и аббревиатуру WWW. Всемирную паутину образуют сотни миллионов веб-серверов. Большинство ресурсов Всемирной паутины основаны на технологии гипертекста. В компьютерной терминологии гипертекст — это текст, сформированный с помощью языка разметки с расчетом на использование гиперссылок. Гипертекстовые документы, размещаемые во Всемирной паутине, называются веб-страницами. Несколько веб-страниц, объединённых общей темой, дизайном, а также связанных между собой ссылками и обычно находящихся на одном и том же веб-сервере, называются веб-сайтом. Для загрузки и просмотра веб-страниц используются специальные программы — браузеры. Всемирная паутина вызвала настоящую революцию в информационных технологиях и взрыв в развитии Интернета. Изобретателями всемирной паутины считаются Тим Бернерс-Ли и, в меньшей степени, Роберт Кайо. Тим Бернерс-Ли является автором технологий HTTP, URI/URL и HTML. В 1980 году он работал в Европейском совете по ядерным исследованиям консультантом по программному обеспечению. Именно там, в Женеве (Швейцария), он для собственных нужд написал программу «Энквайр», которая использовала случайные ассоциации для хранения данных и заложила концептуальную основу для Всемирной паутины. В 1989 году Тим Бернерс-Ли предложил глобальный гипертекстовый проект, теперь известный как «Всемирная паутина». Проект подразумевал публикацию гипертекстовых документов, связанных между собой гиперссылками, что облегчило бы поиск и консолидацию информации для учёных Европейского совета по ядерным исследованиям. Для осуществления проекта Тимом Бернерсом-Ли (совместно с его помощниками) были изобретены идентификаторы URI, протокол HTTP и язык HTML. Это технологии, без которых уже нельзя себе представить современный Интернет. В период с 1991 по 1993 год Бернерс-Ли усовершенствовал технические спецификации этих стандартов и опубликовал их. В рамках проекта Бернерс-Ли написал первый в мире веб-сервер, называвшийся «httpd», и первый в мире гипертекстовыйвеб-браузер, называвшийся «WorldWideWeb». Первый в мире веб-сайт был размещён Бернерсом-Ли 6 августа1991 года. Ресурс определял понятие «Всемирной паутины», содержал инструкции по установке веб-сервера, использования браузера и т. п. Этот сайт также являлся первым в мире интернет-каталогом, потому что позже Тим Бернерс-Ли разместил и поддерживал там список ссылок на другие сайты. И всё же теоретические основы веба были заложены гораздо раньше Бернерса-Ли. Ещё в 1945 годуВанна́вер Буш разработал концепцию Memex — вспомогательных механических средств «расширения человеческой памяти». Memex — это устройство, в котором человек хранит все свои книги и записи (а в идеале — и все свои знания, поддающиеся формальному описанию) и которое выдаёт нужную информацию с достаточной скоростью и гибкостью. Оно является расширением и дополнением памяти человека. Бушем было также предсказано всеобъемлющее индексирование текстов и мультимедийных ресурсов с возможностью быстрого поиска необходимой информации. Следующим значительным шагом на пути ко Всемирной паутине было создание гипертекста (термин введён Тедом Нельсоном в 1965 году). В опубликованном виде он впервые появился в 1965 годув докладе для описания документов (например, представляемых компьютером), которые выражают нелинейную структуру идей, в противоположность линейной структуре традиционных книг, фильмов и речи.
|
Последнее изменение этой страницы: 2019-04-10; Просмотров: 238; Нарушение авторского права страницы
 пропорциональна
пропорциональна  (для входящих ссылок
(для входящих ссылок  , а для исходящих --
, а для исходящих -- 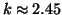 ). Этот факт, например, неявно используется в алгоритмах, использующих информацию о цитировании для оценки ``авторитетности'' ресурсов (см. раздел 4).
). Этот факт, например, неявно используется в алгоритмах, использующих информацию о цитировании для оценки ``авторитетности'' ресурсов (см. раздел 4).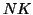 -кланы (
-кланы (  -clans), т.е. графы из
-clans), т.е. графы из  вершин, где между любыми двумя вершинами существует путь длины
вершин, где между любыми двумя вершинами существует путь длины  [51].
[51].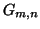 , т.е. графы из
, т.е. графы из 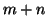 вершин, в которых каждая из множества
вершин, в которых каждая из множества  вершин ссылается на каждую из
вершин ссылается на каждую из 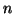 . При разумных значениях
. При разумных значениях 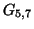 ) можно интерпретировать как ядро некоторого сообщества [77].
) можно интерпретировать как ядро некоторого сообщества [77]. ) страниц Веб, имеющих общую черту -- например, содержимое (общее ключевое слово), местоположение в Веб (интранет), географическое местоположение. Это наблюдение также верно для случайной связной коллекции крупных Веб сайтов и при сужении Веб графа на граф сайтов, т.е. граф, в котором всем страницам с одного сайта соответствует единственная вершина.
) страниц Веб, имеющих общую черту -- например, содержимое (общее ключевое слово), местоположение в Веб (интранет), географическое местоположение. Это наблюдение также верно для случайной связной коллекции крупных Веб сайтов и при сужении Веб графа на граф сайтов, т.е. граф, в котором всем страницам с одного сайта соответствует единственная вершина. при заданных ограничениях (время, пропускная способность сети и т.п.). Однако критерии, определяющие понятие качества, могут быть разными:
при заданных ограничениях (время, пропускная способность сети и т.п.). Однако критерии, определяющие понятие качества, могут быть разными: страниц в зависимости от критерия полезности.
страниц в зависимости от критерия полезности. и как ``посредника''
и как ``посредника''  :
:
 . Если разница невелика, то даже небольшие изменения могут вызвать смену доминирующего сообщества [96]. Две модификации HITS, менее чувствительные к небольшим изменениям в исходном графе, обсуждаются в [95].
. Если разница невелика, то даже небольшие изменения могут вызвать смену доминирующего сообщества [96]. Две модификации HITS, менее чувствительные к небольшим изменениям в исходном графе, обсуждаются в [95].
 на документ
на документ  зависит от скрытого фактора
зависит от скрытого фактора  , характеризующего тематику [38]. Предлагаемый подход PHITS (Probabilistic HITS) использует условные распределения
, характеризующего тематику [38]. Предлагаемый подход PHITS (Probabilistic HITS) использует условные распределения  и
и  для описания зависимостей между наличием ссылки, скрытым фактором и содержимым документа. В терминах этих распределений определяется функция правдоподобия
для описания зависимостей между наличием ссылки, скрытым фактором и содержимым документа. В терминах этих распределений определяется функция правдоподобия 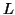 , и неизвестные вероятности подбираются с целью максимизации
, и неизвестные вероятности подбираются с целью максимизации  рекурсивно на основе информации о ссылающихся на
рекурсивно на основе информации о ссылающихся на 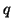 :
:
 обозначает количество ссылок, выходящих со страницы
обозначает количество ссылок, выходящих со страницы 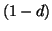 ), он начинает заново со случайно выбранной страницы.
), он начинает заново со случайно выбранной страницы.  -- это вероятность того, что такой пользователь попадет на страницу
-- это вероятность того, что такой пользователь попадет на страницу 
