
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Наличие экспертных оценок
В Веб содержится огромное количество экспертных оценок, как явных, так и неявных, которые могут быть использованы для обучения и настройки методов поиска. Например, явная информация о тематической направленности ресурсов содержится в тематических каталогах -- как в глобальных типа Yahoo! или List.Ru, так и в небольших персональных подборках ссылок на ресурсы по определенной теме. Важным источником экспертных оценок в Веб являются гипертекстовые ссылки. Поскольку большинство ссылок создается вручную, то гипертекстовая ссылка часто отражает мнение создателя о цитируемом ресурсе. Пытаться характеризовать это мнение можно разными способами -- например, путем анализа текста ссылки или в ее окружении. Особенности структуры Естественной моделью представления Веб является ориентированный граф, в котором вершины соответствуют страницам, а ребра - соединяющим страницы гиперссылкам. В рамках этой модели задача анализа структуры связей между страницами -- это задача анализа структуры графа. Информацию о структуре графа Веб можно использовать при решении многих связанных с Веб задач: при теоретическом анализе поведения алгоритмов, использующих информацию о ссылках; для оптимизации вычислительной эффективности методов работы с графом - например, сжатие графа Веб; при исследовании развития Веб с социологической точки зрения и т.д. [26]. Отметим лишь некоторые известные свойства Веб, которые активно используются в методах информационного поиска:
Другой часто встречающийся вид подграфов -- полные двудольные подграфы Эти наблюдения очень важны для использующих структуру графа Веб алгоритмов, которые обсуждаются далее (см. раздел 4.1).
Очень важное наблюдение о том, что ``Веб -- это фрактал'', т.е. структура Веб обладает свойством самоподобия, был сделан в работе [106]. Другими словами, свойства структуры Веб также верны и для его ``характерных'' подграфов. Таким подграфом является относительно большое подмножество (от Этот факт позволяет надеяться, что алгоритмы, использующие информацию о структуре Веб, будут работать не только на том наборе данных, на котором они тестировались.
Интуитивно кажется естественным предположение о том, что ссылки со страниц в Веб в основном ведут на страницы близкой тематики. Эмпирическое подтверждение согласованности между тематической и пространственной (в смысле расстояний в графе Веб) локальностью было дано в работе [44]. Более формально эмпирически показана справедливость следующих предположений: Ссылки в большинстве случаев соединяют страницы с близким содержанием Текст ссылки и, возможно, вокруг нее описывает содержание страницы, на которую ведет ссылка. В работе [55] был предложен эффективный алгоритм выделения ``сообществ'' в Веб, т.е. множеств страниц близкой тематики, где с любой из страниц большая часть ссылок ведет на другие страницы этого же ``сообщества'', на основе анализа только гипертекстовой структуры сети. Этот результат важен, поскольку демонстрирует осмысленность структуры ссылок Веб, процесс создания которой централизовано не контролируется 2. Особенности информационного поиска в WEB по сравнению с информационно-справочными системами. Модель поведения типичного пользователя. Методы поиска, используемые в классических ИПС, разрабатывались и тестировались на относительно небольших и однородных коллекциях, таких как библиотечные каталоги или коллекции газетных статей. Веб как набор данных имеет ряд важных особенностей:
Отметим, что эти оценки касаются только той ``поверхностной'' части Веб, которая не скрыта за поисковыми формами, и доступ к которой не требует предварительной регистрации или авторизации. Другую, ``скрытую'' часть Веб (hidden web), поисковые системы обычно не рассматривают, а ведь к ней относится множество крупных баз данных, опубликованных в Интернет. Поэтому неудивительно, что оценка объема ``скрытого'' Веб в 500 раз больше, чем объем ``поверхностного'' Веб [17,84].
Около 30% информации в Веб составляют точные или приблизительные копии других документов [104].
В Веб изменяется и понятие ``типичного пользователя''. Отметим следующие отличия [72]:
Более того, типичные запросы очень коротки -- более 60% поисковых запросов в Веб состоят из 1-2 слов, что сильно отличается от 7-9 слов в классических ИПС [15,72].
Как следствие, меняется представление о критериях эффективности поиска. Например, традиционно популярный критерий полноты, т.е. процента обнаруженных релевантных документов, малополезен для оценки эффективности систем поиска для Веб [39]. 3. Архитектура поисковой системы для WEB. Понятия: хранилище документов, модуль индексирования, индекс, сетевой робот, поисковая машина, формат запроса.
Хранилище Хранилище содержит большое количество объектов данных (страниц Веб) и в этом смысле очень похоже на СУБД или файловую систему. Однако многие возможности этих систем в данном случае совершенно не нужны (например, транзакции или иерархия директорий), зато очень важны другие: масштабируемость, эффективная поддержка двух режимов доступа: произвольного -- для того, чтобы быстро найти конкретную страницу по ее идентификатору (например, для создания копии страницы из кэша ИПС), и потокового -- для того, чтобы вынуть значительную часть всей коллекции (например, для индексирования или анализа), эффективная поддержка обновлений, сборка ``мусора'' (устаревших страниц) [14]. Естественно, что для достижения необходимой масштабируемости Хранилище должно быть распределенным и должно храниться на множестве отдельных узлов. Эффективность реализации требуемых операций зависит от способов решения трех основных проблем:
Модуль индексирования Задачей этого модуля является построение необходимых структур данных, ускоряющих поиск - индексов. Кроме текстовых индексов, часто используются индексы, описывающие структуру графа Веб, а также прочие вспомогательные индексы (например, индекс для доступа к страницам по их длине или по количеству используемых графических изображений). Существует много подходов к индексированию текстовой информации -- например, инвертированные файлы, хэширование, файлы сигнатур, различные виды деревьев для многомерного индексирования и т.п. Специфика Веб определяет свои особенности построения текстового индекса для ИПС. В дополнение к традиционным целям -- минимизации времени доступа и размера индекса -- здесь также важно минимизировать время создания индекса и обеспечивать возможность эффективного обновления. Один из возможных подходов -- распределенное построение инвертированных файлов на основе техники программных каналов. Идея состоит в параллельном выполнении трех процессов: загрузки документов в оперативную память, построения инвертированных списков по документам и их окончательной записи на жесткий диск. Поскольку эти процессы требуют разных аппаратных ресурсов, то такой подход позволяет сократить время создания индекса на 30-40%. Очень важной проблемой является создание индексов для хранения информации о структуре графа Веб. Для поддержки эффективного выполнения алгоритмов на графах необходимо применение специализированных методов индексирования. Например, в последней версии системы Connectivity Server для хранения информации о ссылке требуется менее 6 бит, что позволяет хранить графы в несколько сот миллионов страниц в оперативной памяти и, как следствие, обеспечивать эффективный доступ к этой информации. Поисковая машина Расширенные возможности поиска пользуются малым спросом у пользователей ИПС для Веб. Как следствие, за исключением предикатов, позволяющих наложить условия на входящие/исходящие ссылки, в языках запросов, применяемых в системах в Веб, нет существенных нововведений по сравнению с языками запросов классических ИПС. Однако простота запросов влечет их низкую селективность, и поэтому очень важной задачей является упорядочивание результатов так, чтобы первыми оказались те результаты, которые вероятнее всего интересны пользователю. Классические подходы к ранжированию опираются на меру схожести текста запроса и текста документа, но ``расплывчатые'' запросы пользователей и огромное количество документов значительно понижают эффективность таких подходов в контексте Веб. Новые подходы к задаче ранжирования результатов поиска обсуждаются в разделе 4. 4. Стратегии сканирования пространства WEB сетевыми роботами. Особенности сканирования скрытого Web. Стратегии сканирования Используемая сетевым роботом стратегия сканирования определяет множество посещенных им страниц. Например, возможные стратегии выбора следующей ссылки из множества уже известных, но еще не посещенных ссылок -- обход ``в глубину'', т.е. посещение последней обнаруженной ссылки, или обход в ``ширину'', т.е. посещение ссылок в порядке их обнаружения. Обобщенной задачей робота является максимизация ``качества'' построенного приближения
Сетевые роботы обычно сканируют только ``поверхностный'' Веб и не могут сканировать информацию, скрытую за поисковыми формами или требующую предварительной регистрации. Мы обсудим некоторые подходы к задаче сканирования ``скрытого'' Веб в разделе 3.3. Большинство сетевых роботов осуществляет сканирование сетевых ресурсов за счет перекачивания их содержимого на тот сервер, где они работают, тем самым создавая значительный сетевой трафик.
Как уже было сказано выше, фокусированное сканирование применяется для повышения общей ``полезности'' посещенных ресурсов. ``Полезность'' ресурса определяется той целью, которая поставлена роботу:
Отметим также, что наибольшее превосходство фокусированные стратегии сканирования демонстрируют при относительно небольшой продолжительности сканирования, т. е. до Сканирование ``скрытого'' Веб Робот, сканирующий ``скрытые'' ресурсы, должен уметь не только автоматически взаимодействовать с основанными на формах поисковыми интерфейсами, которые ориентированы на пользователя-человека, но также и подставлять осмысленные значения при заполнении этих форм. Фундаментальное отличие робота, сканирующего ``скрытую'' часть Веб, относится только к работе со страницами, которые содержат поисковые формы. Модель робота содержит 4 компонента:
5. Понятие релевантного и нерелевантного документа. Методы ранжирования результатов поиска. Модели PageRank, “голосования”, HITS. Ранжирование результатов Локальные методы В подходах этой группы для оценки качества страницы используется информация о ее локальном контексте и учитывается специфика текущего запроса. Наиболее известным подходом этого вида является HITS (Hyperlink-Induced Topic Search) [74]. В рамках модели HITS выделяются две разных роли документа -- ``первоисточника'' (authority) и ``посредника'' (hubs). Хороший ``первоисточник'' -- это документ, на который часто ссылаются в контексте некоторой тематики, а хороший ``посредник'' ссылается на много хороших ``первоисточников''. Алгоритм HITS состоит из двух шагов: выбор подмножества Веб на основе запроса и определение лучших ``авторитетов'' и ``посредников'' по результатам анализа этого подмножества [56]. Подмножество строится путем расширения множества найденных по запросу пользователя страниц за счет добавления всех страниц, связанных с ними путем, состоящим из одной (иногда двух) ссылок. Далее, для каждого документа рекурсивно вычисляется его значимость как ``авторитета''
Однако в некоторых ситуациях последнее предположение оказывается неверным, и, как следствие, доминирующее сообщество относится к другой тематике. Так, например, по запросу ``jaguar'' доминирующее сообщество посвящено городу ``Цинциннати'', местная газета которого уделяет много внимания давнему сопернику их футбольной команды - команде ``Jaguars''. Теоретический анализ стабильности метода вычисления HITS по отношению к небольшим изменениям в графе показал, что стабильность сильно зависит от разницы между наибольшими собственными числами матрицы В основе одного из расширений модели HITS лежит предположение, что ссылка Для вычисления рангов необходимо задать количество факторов Глобальные методы Подходы этой группы оценивают качество страницы, используя только информацию о Веб, и получаемые оценки не зависят от текущего запроса. Типичным примером является индекс цитирования, т.е. количество ссылок на данную страницу, аналог которого давно используется в библиометрическом анализе. Наиболее известным расширением индекса цитирования в Веб является PageRank, который определяет важность страницы
где d -- это некоторый параметр (обычно порядка 0.85), а В основе PageRank лежит модель случайного пользователя, который, начав с какой-то страницы, переходит на новые страницы по ссылкам с текущих и никогда не нажимает кнопку ``Вернуться'', а когда ему надоедает (что происходит с вероятностью Формально, модель PageRank не учитывает динамику развития Веб и анализирует граф с некоторой статической структурой. Однако теоретический анализ стабильности PageRank относительно изменений в графе показал устойчивость получаемых рангов по отношению к изменениям, касающимся ресурсов с невысоким рангом [96]. Этот результат очень важен, поскольку на практике PageRank всегда вычисляется на основе некоторого приблизительного представления о содержимом Веб. Еще одна интересная модель -- модель ``голосования'' (voting model), в которой ранг ресурса определяется на основе оценок качества от некоторого множества экспертов и структуры графа Веб [86]. Отметим, что здесь в качестве экспертов могут быть использованы разнообразные источники информации -- тематические каталоги, поведение других пользователей, явная метаинформация на странице, и т.п. Формально, эта модель расширяет PageRank, но отсутствие результатов апробирования не позволяет оценить практическую полезность этого расширения.
6. Архитектуры Информационно-поисковых систем(ИПС): распределенные, метапоисковые . Вариации архитектуры ИПС Описанная в разделе 2 архитектура ИПС для Веб не является единственно возможной. Мы остановимся на нескольких альтернативных вариантах, поскольку принципиальные изменения архитектуры часто вызывают появление новых исследовательских проблем. Распределенные ИПС Естественной попыткой решить проблему масштабируемости ИПС является использование распределенной архитектуры. Этот подход активно исследовался как в контексте классических ИПС [15], так и в контексте поисковых систем Веб [99]. В рамках такой архитектуры поиск производится по виртуально единому индексу, который физически распределен по ряду серверов. Эффективная система должна выполнять запросы, не производя поиск во всех частях индекса, стараясь искать только там, где действительно содержится ответ. В распределенной ИПС для Веб пополнение и поддержка разных частей индекса может выполняться разными роботами, и то, насколько они будут эффективны, также зависит от принципов разбиения индекса [10]. Интересным примером является исследовательская система OASIS (http://www.oasis-europe.org), в которой индекс разбивается на тематические части [99]. Такой подход не только позволяет использовать фокусированные стратегии сканирования для обнаружения новых документов (см. раздел 3.1), но также и лучше контролировать качество информации по отдельным тематикам, например, привлекая экспертов по этим темам. Возможно дальнейшее повышение автономности системы. Так, например, для поиска в разных частях индекса могут использоваться разные алгоритмы (например, тематический тезаурус). При этом, поскольку оценки близости запросу пользователя становятся не сравнимы, возникает проблема слияния результатов [58]. Важными также являются вопросы, связанные с интероперабельностью компонент распределенной системы [1].
Метапоисковая система -- это система, которая предоставляет единый доступ к нескольким другим поисковым системам, т.е. обслуживает запросы пользователей за счет опрашивания других поисковых систем, которые полностью независимы и не предоставляют никакой специальной информации о содержимом своих индексов или используемых методах поиска [4,81,92,113]. Такие системы популярны в силу ряда причин:
При создании метапоисковой системы необходимо решать проблемы, похожие на возникающие при создании распределенных систем. Но полная автономность составляющих ИПС вносит свою специфику. Так, языки запросов, используемые в разных ИПС, зачастую сильно отличаются, и поэтому необходим либо сильно упрощенный язык поиска для метапоисковой системы, либо такой подход к интеграции гетерогенных ИПС, который решает задачу по переформулировке запросов. Отметим, модель ADMIRE, которая способна адаптироваться к изменениям в поисковых интерфейсах и к появлению новых ИПС [69]. Непростой задачей является и выбор ИПС, которые будут обрабатывать запрос. Этот шаг напрямую влияет как на вычислительную, так и на качественную эффективность поиска [48,91]. Проблема осложняется отсутствием информации о множестве проиндексированных ИПС документов. Одним из возможных подходов является сбор этой информации в процессе работы. Например, система SavvySearch на основе своего опыта обслуживания запросов учится предсказывать полезность конкретных ИПС по используемым в запросе ключевым словам [68]. В случае поиска по специализированным ИПС полезным может оказаться их предварительная автоматическая классификация на основе тестовых запросов [70]. |
Последнее изменение этой страницы: 2019-04-10; Просмотров: 238; Нарушение авторского права страницы
 пропорциональна
пропорциональна  (для входящих ссылок
(для входящих ссылок  , а для исходящих --
, а для исходящих -- 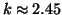 ). Этот факт, например, неявно используется в алгоритмах, использующих информацию о цитировании для оценки ``авторитетности'' ресурсов (см. раздел 4).
). Этот факт, например, неявно используется в алгоритмах, использующих информацию о цитировании для оценки ``авторитетности'' ресурсов (см. раздел 4). -кланы (
-кланы (  -clans), т.е. графы из
-clans), т.е. графы из  вершин, где между любыми двумя вершинами существует путь длины
вершин, где между любыми двумя вершинами существует путь длины  [51].
[51].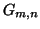 , т.е. графы из
, т.е. графы из 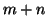 вершин, в которых каждая из множества
вершин, в которых каждая из множества  вершин ссылается на каждую из
вершин ссылается на каждую из 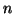 . При разумных значениях
. При разумных значениях 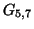 ) можно интерпретировать как ядро некоторого сообщества [77].
) можно интерпретировать как ядро некоторого сообщества [77]. ) страниц Веб, имеющих общую черту -- например, содержимое (общее ключевое слово), местоположение в Веб (интранет), географическое местоположение. Это наблюдение также верно для случайной связной коллекции крупных Веб сайтов и при сужении Веб графа на граф сайтов, т.е. граф, в котором всем страницам с одного сайта соответствует единственная вершина.
) страниц Веб, имеющих общую черту -- например, содержимое (общее ключевое слово), местоположение в Веб (интранет), географическое местоположение. Это наблюдение также верно для случайной связной коллекции крупных Веб сайтов и при сужении Веб графа на граф сайтов, т.е. граф, в котором всем страницам с одного сайта соответствует единственная вершина. при заданных ограничениях (время, пропускная способность сети и т.п.). Однако критерии, определяющие понятие качества, могут быть разными:
при заданных ограничениях (время, пропускная способность сети и т.п.). Однако критерии, определяющие понятие качества, могут быть разными: страниц в зависимости от критерия полезности.
страниц в зависимости от критерия полезности. и как ``посредника''
и как ``посредника''  :
:
 . Если разница невелика, то даже небольшие изменения могут вызвать смену доминирующего сообщества [96]. Две модификации HITS, менее чувствительные к небольшим изменениям в исходном графе, обсуждаются в [95].
. Если разница невелика, то даже небольшие изменения могут вызвать смену доминирующего сообщества [96]. Две модификации HITS, менее чувствительные к небольшим изменениям в исходном графе, обсуждаются в [95].
 на документ
на документ  зависит от скрытого фактора
зависит от скрытого фактора 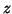 , характеризующего тематику [38]. Предлагаемый подход PHITS (Probabilistic HITS) использует условные распределения
, характеризующего тематику [38]. Предлагаемый подход PHITS (Probabilistic HITS) использует условные распределения 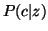 и
и  для описания зависимостей между наличием ссылки, скрытым фактором и содержимым документа. В терминах этих распределений определяется функция правдоподобия
для описания зависимостей между наличием ссылки, скрытым фактором и содержимым документа. В терминах этих распределений определяется функция правдоподобия 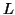 , и неизвестные вероятности подбираются с целью максимизации
, и неизвестные вероятности подбираются с целью максимизации  рекурсивно на основе информации о ссылающихся на
рекурсивно на основе информации о ссылающихся на 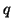 :
:
 обозначает количество ссылок, выходящих со страницы
обозначает количество ссылок, выходящих со страницы 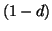 ), он начинает заново со случайно выбранной страницы.
), он начинает заново со случайно выбранной страницы.  -- это вероятность того, что такой пользователь попадет на страницу
-- это вероятность того, что такой пользователь попадет на страницу