
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
ПОСТРОЕНИЕ КОРРЕЛЯЦИОННЫХ ПЛЕЯД
Цель работы – выработать навыки сокращения размерности исходного факторного пространства путем разбиения его не группы тесно коррелированных факторов (плеяд) и слабой связью между плеядами. Общие положения 1.1. Построение таблицы исходных данных и ее первичная обработка В практике научных работ нередки случаи, когда объект исследования характеризуется множеством показателей, которые можно измерить и зафиксировать, но нельзя произвольно изменять. Такие задачи встречаются при исследовании технологических процессов производства изделий, показателей состояния организма людей, химических и физико-механических показателей сельскохозяйственной продукции и т.п. Для фиксации цифровых значений таких показателей и упорядочения первичной собранной информации удобно использовать форму таблицы, которую будем называть таблицей исходных данных. Таблица исходных данных представляет собой матрицу размером N*M, где М факторов (столбцы) соединены в многомерную выборку объемом N (строки). Такая матрица может содержать значительный объем информации, извлечь которую является сложной статистической задачей. Практика работы с таблицами исходных данных такого пассивного эксперимента показала, что если число столбцов М ограничивается только списком факторов (который может достигать нескольких сотен наименований), то объем многомерной выборки N (длина таблицы, количество строк матрицы) не может быть произвольным. Интуитивно ясно, что чем больше факторов, тем длинее должна быть таблица. Экспериментально установлено, что таблица результатов пассивного эксперимента является достаточно длинной, если на каждый исследуемый независимый фактор в ней приходится 10-15 строк. Однако теми же исследованиями установлено, что не все факторы воздействуют на целевую функцию (выходной показатель качества изделия, вообще, показатель – цель исследования), то есть, в большинстве случаев исследователь имеет дело со сверхнасыщеным планом, влияние части факторов которого переходит в шум эксперимента. Это означает, что размерность матрицы по количеству факторов может быть существенно уменьшена. Кроме того, новейшие теоретические исследования показали, что для измерений массовой однотипной продукции, изготовленной в едином (или подобном) технологическом процессе, не соблюдается одно из фундаментальных свойств теории вероятности – требование состоятельности оценок выборочных распределений, суть которого заключается в том, что оценка сходится по вероятности к истинному значению (а ошибка оценки к нулю) при неограниченном возрастании числа измерений. На практике определяющим становится влияние всегда присутствующих малых корреляций между ошибками измерений, особенно для групповых или иных связных технологических операций, которое и приводит к нарушению теоретического свойства состоятельности. Другими словами, обработка нескольких тысяч однотипных измерений не уменьшает, а увеличивает ошибку оценки. Следовательно, существует конечное, не слишком большое число измерений, сверх которого уточнение оценки при тех же исходных условиях становится бессмысленным. Эмпирически установлено, что такое число лежит в пределах 250-300 измерений. Таким образом, размерность таблицы исходных данных может меняться от двух до нескольких десятков, сотен и даже тысяч столбцов при длине таблицы до 300 строк. Такая длинная таблица с множеством чисел может содержать и ошибочные данные, поэтому перед дальнейшей работой все столбцы должны быть проверены на грубые промахи любым из известных способов, а выявленные промахи удалены, иначе статистический анализ может дать неверные выводы. Так как каждый столбец таблицы исходных данных есть выборка соответствующего фактора объемом N, то проверку на отсутствие в числовых данных грубых промахов можно совместить с проверкой соответствия распределения факторов с нормальным законом. Проверка соответствия каждого фактора нормальному закону распределения чрезвычайно важна, так как большинство методов математической статистики основаны на использовании этого закона. Особенно важно такое соответствие для целевых функций, так как практически все методы теории планирования эксперимента основаны на предпосылке, что целевая функция распределена именно по нормальному закону. Несоответствие целевой функции нормальному закону заставляет исследователя искать ее преобразование, согласующееся с нормальным законом (см. лабораторную работу №1). Это требование основано на том, что конечной целью обработки таблицы многомерных данных является математическая модель, которая представляет собой наиболее компактное представление содержащейся в таблице в неявном виде конкретной информации. 1.2. Сокращение размерности факторного пространства Перед проведением работ по получению математической модели во всех случаях рекомендуется сократить первоначальный список факторов до возможного минимума, так как с ростом числа факторов трудоемкость моделирования растет как степенная функция. Отсев факторов можно производить по двум критериям: факторы незначимые, то есть не влияющие на целевую функцию и внесенные в первоначальный список факторов ошибочно, и факторы коррелированные, то есть имеющие сильную внутреннюю связь. Естественно, что каждая пара таких факторов должна быть разбита, то есть один из факторов отброшен как не дающий дополнительной информации в будущей математической модели, а другой оставлен для дальнейшей работы. К сожалению, нет никаких формальных критериев, по которым можно судить, какой именно фактор должен быть отброшен, а какой оставлен – это в большей мере вопрос удобства дальнейшей работы, интуиции и опыта исследователя, возможностей измерительного оборудования и т.п. Одним из способов понижения размерности факторного пространства из-за сокращения сильно коррелированных факторов являются корреляционные плеяды, основанные на анализе корреляционной матрицы. Корреляционная матрица представляет собой симметричную квадратную матрицу размером M*M, где М – число исследуемых факторов, главная диагональ которой заполнена единицами (или нулями для удобства дальнейшего анализа), а недиагональные элементы представляют собой меру тесноты связи между парой факторов (коэффициент корреляции, корреляционное отношение, модифицированный индекс Фехнера и т.д.). Другими словами, для заполнения корреляционной матрицы необходимо найти меру тесноты связи для каждой пары факторов, то есть, провести корреляционный анализ таблицы исходных данных по принципу «каждый с каждым» любым известным способом (например, по методу Чебышева). На практике часто встречаются случаи грубых промахов парных выборок, выявить которые очень сложно, а также заметные отклонения факторов от нормального закона распределения. Применение в этих условиях классического корреляционного анализа с мерой тесноты связи в виде коэффициента корреляции требует известной осторожности, так как на фоне большого рассеивания исходных данных нелегко решить, принадлежит ли конкретная пара чисел исследуемой двумерной совокупности или представляет собой грубый промах. В сомнительных случаях (обе случайные величины не распределены по нормальному закону распределения; есть подозрение, что парная выборка может содержать грубые промахи) рекомендуется в качестве меры тесноты связи использовать модифицированный индекс Фехнера. Модифицированный индекс Фехнера, конечно, менее точен, чем коэффициент корреляции, но только в отсутствие грубых промахов и искажения закона распределения. Даже при одном грубом промахе коэффициент корреляции значительно меняется, давая неправильный результат, в то же время как модифицированный индекс Фехнера, основанный на одной из самых робастных (устойчивых к изменению исходных условий) оценок математической статистики – на средней арифметической – дает результат значительно ближе к истинному. Безусловно, если одна или обе случайные величины являются дискретными или варьируются на большом числе уровней, то следует в качестве меры тесноты корреляционной связи выбрать подходящую из богатого арсенала мер. Непосредственный анализ корреляционной матрицы представляет значительную трудность, так как корреляционные связи между факторами образуют деревья, цепи, циклы и другие фигуры графов. Для выделения главных зависимостей следует прибегнуть к одному из методов анализа таких матриц, простейшим из которых является метод корреляционных плеяд. Метод заключается в том, что в корреляционной матрице находится недиагональный элемент с максимальной по модулю величиной |rij|=max. Из матрицы вычеркиваются столбцы с номерами i и j, а из строк с номерами i и j выбирается следующий максимальный по модулю элемент, например |ril|. Столбец с номером l вычеркивается, а из строк с номерами i, j и l выбирается следующий максимальный по модулю элемент, и так далее до исчерпания данных. Результат такой работы удобно представить на рисунке в виде графа, вершинами которого являются факторы, ребрами – максимальные связи, причем длины ребер обратно пропорционально величине соответствующих коэффициентов корреляции. Выбрав некоторое пороговое значение коэффициента корреляции, например |rпор|=0, 5, можно отделить по этому признаку плеяды друг от друга. Внутри каждой плеяды связь между факторами признается тесной, а между плеядами – слабой. Это означает, что если от каждой плеяды выбрать по одному представителю, то новое общее количество факторов, сокращенное до количества плеяд, будет нести об исследуемом объекте практически ту же информацию, что и раньше. При этом факторы новой таблицы данных будут слабо коррелированными между собой, что является одним из главных условий перехода к математическому моделированию. Задача выбора одного фактора из плеяды – неформальная задача и решать ее надо всеми возможными методами с учетом мнения специалистов (например технологов исследуемого процесса) лучше всего экспертными методами. Это значит, что в обязательном порядке надо сопоставлять корреляционные плеяды, полученные на основе анализа корреляционных матриц, составленных не только из коэффициентов корреляции, но и корреляционных отношений, и МИФ. Этим самым уменьшается ошибка от неучета нелинейного характера связи между факторами, а также влияние хоть и принадлежащих к данной двумерной совокупности, но нетипичных пар данных. При невозможности использовать другие методы можно выделять факторы по максимальным коэффициентам корреляции с выходным показателем качества (целевой функцией). После выделения по одному представителю от каждой плеяды можно из таблицы исходных данных построить таблицу некоррелированных (фактически слабо коррелированных) данных, информационная емкость которой практически не изменяется, а размерность факторного пространства сокращается в несколько раз. Однако в силу того, что плеяды учитывают не все связи, а только максимальные, следует полученную таблицу предполагаемых некоррелированных данных заново проверить на наличие парных корреляционных зависимостей, вновь составить корреляционную матрицу и проанализировать её с помощью новых плеяд. В случае обнаружения достаточно сильной корреляционной зависимости ее следует уничтожить (уменьшить до приемлемого уровня) путем замены прежнего фактора на другого представителя из соответствующей первоначальной плеяды. Работа должна быть продолжена до тех пор, пока очередная проверка не подтвердит создание таблицы действительно некоррелированных (фактически слабо коррелированных) данных, которая на самом деле и является исходной для нахождения математических моделей. 1.3. Построение таблицы независимых (слабокоррелированных) факторов Конечной целью статистического моделирования является нахождение оптимальных условий работы исследуемого объекта, что в большинстве случаев невозможно без получения математической модели этого объекта. Сложность вычислений адекватной модели по пассивным многомерным данным существенно зависит от размерности факторного пространства, а информационная емкость модели самым тесным образом зависит от качества выбранных для моделирования параметров (факторов) исследуемого объекта. Именно стремление сравнительно легко получить модель не только адекватную исходным экспериментальным данным, но и имеющую возможно большую информационную ёмкость заставляет исследователя стремиться сократить размерность факторного пространства до возможного минимума, а среди выбранных значимых факторов иметь наиболее информационно ёмкие. Первым этапом на пути сокращения размерности факторного пространства является уменьшение количества столбцов таблицы исходных экспериментальных данных до числа плеяд, что можно сделать без существенной потери информации. С этой целью из каждой плеяды выделяется один представитель-фактор, который будем называть существенным, значимым, контролепригодным, в зависимости от решаемой задачи. Остальные факторы плеяды могут быть отброшены как несущественные (второстепенные) или, если они вызывают какой-либо дополнительный интерес, то исследователь легко может найти их уравнения парной корреляции с выделенным существенным фактором. К сожалению, нет формальных правил для выделения из плеяд значимых факторов, это задача творческая, однако можно порекомендовать следующие приемы. 1. В первую очередь из плеяды надо выделить тот фактор, который имеет самую сильную корреляционную связь с выходным показателем (целевой функцией), поэтому при построении плеяды желательно включать в нее и целевую функцию на правах фактора. 2. Если есть возможность оценить факторы на однородность, то при прочих равных условиях следует отдать предпочтение однородному фактору, то есть фактору, имеющему возможно большую корреляционную зависимость между его значениями, измеренными в разных условиях (по площади пластин, в разное время и т.п.). Можно также отдать предпочтение фактору, имеющему минимальную дисперсию (разброс). 3. Предпочтение следует также отдавать фактору, коэффициент точности которого, максимален. 4. Если не удается явно выделить один из факторов, то для каждой плеяды можно применить один из экспертных методов ранжирования, которые позволяют выделить объективную информацию из субъективных высказываний специалистов. 5. При прочих равных условиях предпочтение следует отдавать фактору с лучшими метрологическими характеристиками (легко измерить с высокой точностью). 6. Если речь идет о технологическом процессе, следует отдавать предпочтение факторам, измеряемым на более ранней стадии этого процесса. 7. В обязательном порядке необходимо после выделения значимых факторов вновь составить корреляционную матрицу, введя в нее только выделенные факторы, с целью проверки их некоррелированности (слабой, незначимой коррелированности). Это необходимо потому, что плеяды составляются по самым сильным связям, но при этом возможны случаи, когда в разные плеяды попадают факторы, связанные меньшими, но все же достаточно сильными корреляционными зависимостями. В этих случаях один из факторов следует заменить на другой из той же плеяды и заново проверить вновь образованную матрицу на уровень корреляционных связей между параметрами. 8. Еще одним способом сокращения размерности факторного пространства может служить ранжировка отобранных факторов, проведенная каким-либо способом, например, экспертным методом весовых коэффициентов важности. Практика показала, что факторы, находящиеся в «хвосте» гистограммы, можно исключить из рассмотрения как несущественные начиная с того, чей вес примерно на порядок меньше веса первого по рангу фактора. 1.4. Производственный пример В таблице 6.1 приведен фрагмент таблицы исходных данных для 13 факторов и 130 объектов исследования. Построить корреляционные плеяды и сократить, если возможно, размерность факторного пространства. Р е ш е н и е: Для построения корреляционных плеяд предварительно необходимо найти корреляционную матрицу. Поскольку большинство факторов распределены по нормальному закону, то корреляционная матрица, представленная в таблице 6.2, построена на основе коэффициентов корреляции как мер тесноты связи. Анализ корреляционной матрицы по правилам построения корреляционных плеяд привёл к графу, представленному на рисунке 6.1, из которого ясно, что без изменения информационной емкости размерность факторного пространства можно уменьшить с 13 до 7, что существенно облегчит в дальнейшем поиск математической модели. Таблица 6.1 - Фрагмент таблицы исходных данных
Таблица 6.2 - Корреляционная матрица данных таблицы 6.1
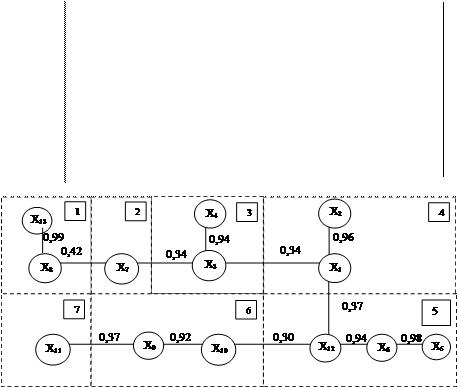
Рисунок 6.1 – Граф корреляционных плеяд Примечание: в кружочках обозначены факторы, в квадратах - номера плеяд, цифры между карточками – коэффициенты корреляции между факторами. Таким образом, в будущую таблицу для математического моделирования отобраны Для уверенности в правильном выборе произведем повторную проверку отобранных факторов на минимум коэффициентов корреляции (таблица 6.3). Таблица 6.3 – Корреляционная матрица отобранных факторов
Таким образом подтверждается, что выбор был сделан правильно. Ранжировка отобранных факторов, например, экспертным методом ВКВ, возможно позволила бы сократить размерность факторного пространства еще до начала процедуры моделирования. Порядок проведения работы 2.1. Одним из способов, изученных при проведении лабораторной работы №3, рассчитать коэффициенты корреляции факторов и целевой функции исходной таблицы данных по принципу «каждый с каждым» и построить корреляционную матрицу. 2.2. Используя только часть корреляционной матрицы, относящуюся к факторам, построить корреляционные плеяды, используя в качестве порогового значения величину 2.3. Из каждой плеяды выделить по одному фактору, имеющему максимально тесную связь с целевой функцией, и расположить их в порядке убывания (по модулю) величин коэффициентов корреляции фактора и целевой функции. Содержание отчета Отчет по лабораторной работе должен содержать ответы на все пункты задания с привидением необходимых формул и расчетов. При подготовке к защите работы необходимо ознакомиться с контрольными вопросами и продумать результаты лабораторной работы. 4. Контрольные вопросы 4.1. Почему нужно сокращать размерность факторного пространства? 4.2. Почему нельзя по таблице исходных данных сразу приступить к поиску математической модели? 4.3. Зачем нужна корреляционная матрица? 4.4. Почему важны именно меры тесноты линейной связи? 4.5. Что такое корреляционные плеяды? 4.6. По каким признакам исходные факторы разделяются на плеяды? 4.7. Каким образом определяются границы плеяд? 4.8. Каким образом можно выделить из плеяды один (главный) фактор? 4.9. Как перейти от таблицы исходных к таблице слабокоррелированных данных? 4.10. Как доказать, что найденная новая таблица данных пригодна для целей моделирования? 4.11. Что делать, если новая таблица оказалась непригодной для моделировния. 4.12. Во сколько раз сокращается размерность факторного пространства с помощью метода плеяд? 5. Рекомендуемая литература 5.1. Дружинин Г.В. Методы оценки и прогнозирования качества. – М.: Радио и связь, 1982. – 160 с. 5.2. Долгов Ю.А. Статистическое моделирование. – 2-е изд., доп. - Тирасполь: Полиграфист, 2011. – 352 с. (с. 75-83; 94-96). Лабораторная работа № 7 |
Последнее изменение этой страницы: 2017-04-12; Просмотров: 2716; Нарушение авторского права страницы
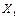 ,
, 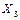 ,
, 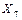 ,
, 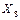 ,
, 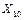 ,
, 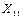 ,
,  .
.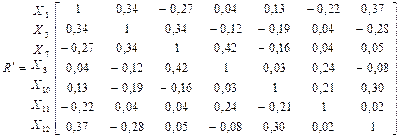
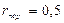 .
.