
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Анализ данных: вычисление числовых характеристик и доверительных интервалов. Построение гистограммы, «ящика с усами» и оценки функции плотности распределения
Когда исследуемая выборка открыта в окне данных, выполнить действия. 6.1 В главном меню выбрать Analyze/Variable Data/One-Variable Analysis. 6.2 В окне One-Variable Analysis в поле Data ввести имя анализируемой переменной (дважды нажать левой клавишей мыши на имени переменной. В нашем примере – N_7_2). Затем нажать OK. 6.3 В открывшемся окне One-Variable Analysis выберем те статистические процедуры, которые нас интересуют. Для этого надо нажать кнопку Tables (см. рисунок В.3) и в окне Tables отметить Summary Statistics и Confidence Intervals (остальные отметки удалить). Нажать OK. 6.4 В окне One-Variable Analysis нажать правую кнопку мыши на поле Summary Statistics. В открывшемся меню выбрать Pane Options и в окне Summary Statistics Options отметить: Average, Median, Mode, Variance, Standard deviation, Coeff. of variation, Minimum, Maximum, Range, Skewness, Stnd. Skewness, Kurtosis, Stnd. kurtosis (остальные отметки удалить). Нажать OK. И мы получим набор нужных нам характеристик: Summary Statistics for N_7_2 Count 100 – объем выборки Average 6, 33721 – математическое ожидание Median 6, 33769 – медиана Mode – мода Variance 3, 91295 – дисперсия Standard deviation 1, 97812 – среднее квадратическое отклонение Coeff. of variation 0, 31214 – коэффициент вариации Minimum 1, 0657 – минимальный элемент выборки Maximum 11, 3348 – максимальный элемент выборки Range 10, 2691 – размах выборки Skewness 0, 06599 – коэффициент асимметрии Stnd. skewness 0, 26940 – стьюдентизированный коэффициент асимметрии Kurtosis 0, 03200 – коэффициент эксцесса Stnd. kurtosis 0, 06532 – стьюдентизированный коэффициент эксцесса Замечание – В пакете Statgraphics Centurion оценка моды равна элементу выборки, который наиболее часто встречается. Если каждый элемент выборки встречается один раз, то оценка моды не определена. В поле Confidence Intervals получим доверительные интервалы. Confidence Intervals for N_7_2 95, 0 % confidence interval for mean: [5, 94471; 6, 72972] – доверительный интервал для математического ожидания случайной величины, 95, 0 % confidence interval for standard deviation: [1, 7368; 2, 29793] – доверительный интервал для среднего квадратического отклонения. 6.5 Нажать кнопку Graphs (см. рисунок В.3) и в открывшемся окне Grafs отметить Box-and-Whisker Plot, Frequency Histogram и Density Trace. Остальные отметки удалить. Нажать OK. В результате мы получим графики: «ящик с усами», гистограмму и график оценки функции плотности распределения вероятностей. На рисунке В.4 изображен график «ящик с усами», который был придуман Дж. Тьюки для компактного и наглядного описания данных. Фактически на рисунке отображены шесть характеристик вариационного ряда: Рисунок В.4 – График «ящик с усами» Абсциссы точек пересечения двух коротких вертикальных линий с горизонтальной осью соответствуют минимальному и максимальному значениям выборки (если отсутствуют наблюдения, подозрительные на аномальность). Если продолжить левую и правую стороны прямоугольника до пересечения с горизонтальной осью, то получим точки (нижнюю и верхнюю выборочные квартили), между которыми находится ровно половина всех значений выборки. Абсцисса точки пересечения вертикальной линии внутри прямоугольника с горизонтальной осью характеризует положение выборочной медианы, а точки, отмеченной знаком «+», – среднее значение выборки. Любое существенное различие между значениями оценок медианы и математического ожидания либо говорит о наличии аномальных наблюдений, либо о несимметричном распределении исследуемой случайной величины. Значения, подозрительные на аномальность, отмечаются точками вне «усов» (рисунок В.5).
Гистограмма частот изображена на рисунке В.6. Рисунок В.6 – Гистограмма частот На рисунке В.7 изображена кривая, сглаживающая гистограмму и являющаяся непараметрической оценкой функции плотности распределения вероятностей. Этот график используется при подборе теоретического закона распределения вероятностей изучаемой случайной величины. Рисунок В.7 – Оценка функции плотности распределения вероятностей 7 Проверка независимости наблюдений (случайности выборки) Результаты анализа статистических данных являются надежными в тех случаях, когда объем выборки достаточно большой (сотни, а то и тысячи наблюдений). На практике часто бывает сложно собрать большое количество данных за короткий промежуток времени. А данные, которые собирались длительное время, могут зависеть от фактора времени. Для таких данных разработаны специальные процедуры статистического анализа, отличные от процедур анализа случайных выборок. Поэтому, применяя статистические процедуры анализа случайных выборок, мы должны быть уверены, что имеющаяся в нашем распоряжении выборка действительно является случайной. Чтобы протестировать выборку на случайность необходимо выполнить следующие действия. 7.1 Открыть файл, содержащий изучаемую выборку данных. 7.2 В главном меню выбрать Forecast/Descriptive Time Series Methods. 7.3 В окне Descriptive Methods ввести в поле Data имя исследуемой переменной (дважды нажать левой клавишей мыши на имени переменной. В нашем примере – N_7_2). Нажать OK. 7.4 Откорректируем результаты анализа, появившиеся на экране: выведем на экран дисплея те статистические процедуры, которые необходимы для проверки случайности выборки. Нажать кнопку Tables (см. рисунок В.3). В появившемся окне Tables отметить Tests for Randomness, остальные отметки убрать. В результате этих действий в поле Descriptive Methods в левой колонке появятся результаты проверки трех тестов: критерия серий, критерия «нисходящих» и «восходящих» серий и критерия автокорреляции. Tests for Randomness of N_7_2 (1) Runs above and below median критерий серий Median = 6, 33769 Number of runs above and below median = 50 Expected number of runs = 51, 0 Large sample test statistic z = 0, 100509 P- value = 0, 919935 (2) Runs up and down критерий «восходящих» и «нисходящих» серий Number of runs up and down = 64 Expected number of runs = 66, 3333 Large sample test statistic z = 0, 438808 P-value = 0, 660797 (3) Box-Pierce Test критерий автокорреляции Test based on first 24 autocorrelations Large sample test statistic = 22, 5724 P-value = 0, 545142 Если для всех критериев значения P-value ≥ α (например, α = 0, 05), то у нас нет оснований для отклонения гипотезы о случайности выборки. Если результаты проверки какого-либо из критериев приводят к противоположному выводу, то, очевидно, требуются дополнительные исследования. |
Последнее изменение этой страницы: 2017-05-05; Просмотров: 540; Нарушение авторского права страницы
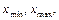 оценка медианы, оценка математического ожидания, нижняя и верхняя выборочные квартили.
оценка медианы, оценка математического ожидания, нижняя и верхняя выборочные квартили.




