П ОСЛЕДНИ Й DUP Х ВОСТ Н ОЛЬ N OT
IF ХВОСТ РЕКУРСИЯ
THEN
9;
10 \ ИТЕРАТИВНЫЙ ВАРИАНТ СЛОВА ПОСЛЕДНИЙ
ПОСЛЕДНИЙ
BEGIN DUP ХВОСТ НОЛЬ NOT
WHILE ХВОСТ
14 REPEAT
15
48
0 \ ЛИСПОПОДОБНЫЕ СЛОВА ПОСТРОЕНИЯ СПИСКОВ
1 \ НА ФОРТЕ-83
2 ( ©СПИСОК -> N) \ ВОЗВРАЩАЕТ ЧИСЛО ЭЛЕМЕНТОВ В СПИСКЕ
3: ДЛИНА DUP НОЛЬ
4 IF DROP 0
5 ELSE ХВОСТ РЕКУРСИЯ 1+
THEN
7;
8
UNNEST
10 \ ДЛИНА. ИТЕРАТИВНЫЙ ВАРИАНТ
ДЛИНА О
BEGIN OVER НОЛЬ NOT
13 WHILE 1+ SWAP ХВОСТ SWAP
14 REPEAT NIP
15
52
0 \ ЛИСПОПОДОБНЫЕ СЛОВА ПОСТРОЕНИЯ СПИСКОВ
1 \ НА ФОРТЕ-83
2 ( СП1 N -> СП2)
3: NHb^ DU P1 <
I F 2DR0P НУЛЬ
ELSE
BEGIN 1- D UP
WHILE SWAP Х ВОСТ SWAP
REPEAT DROP
9 THEN
10
11
12
13
14
15
 Экраны 47, 48, 52. Слова построения списков: ПОСЛЕДНИЙ, ДЛИНА
Экраны 47, 48, 52. Слова построения списков: ПОСЛЕДНИЙ, ДЛИНА
И Ы НЫЙ
174
175
 cm cn2 чл
cm cn2 чл
(В Лиспе для слова ЧЛ есть синоним ЧЛРАВ - MEMQ.) ЧЛ воз-
вращает остаток от СП2, начинающийся с первого встретившегося
элемента, равного (РАВ) СП1. В противном случае на стек поме-
щается НУЛЬ. Слово ЧЛЕН аналогично слову ЧЛ, за исключени-
ем того, что оно для сравнения элементов списка СП1 с элемента-
ми списка СП2 использует не РАВ, а РАВНО (см. разд. " Функции
РАВНО и РАВ" ).
Наконец, фрагмент
С1 С2 СЗ ПОДСТ
 49
49
| 0 \
1 \
2 (
3
4
5:
6
7
8
9
10
11
12;
13
14
15
|
ЛИСПОПОДОБНЫЕ СЛОВА ПОСТРОЕНИЯ СПИСКОВ
НА ФОРТЕ-83
ЭЛЕМЕНТ ©СПИСОК -> @ХВОСТ) \ ЕСЛИ ЭЛЕМЕНТ В СПИСКЕ
\ ПРИСУТСТВ. ТО @ХВОСТ БУДЕТ ОСТАТКОМ СПИСКА,
\ НАЧИНАЮЩЕГОСЯ С ЭЛЕМЕНТА; ИНАЧЕ НУЛЬ
ЧЛ SWAP OVER НОЛЬ
IF2DR0P НУЛЬ
ELSE OVER ПЕРВЫЙ OVER =
IF DROP
ELSE SWAP ХВОСТ РЕКУРСИЯ
THEN
THEN
 Экран 49. Слово ЧЛ работы со списками
Экран 49. Слово ЧЛ работы со списками
осуществляет подстановку С-выражения С1 вместо всех вхождений
С2 в С-выражении СЗ и возвращает СЗ. ПОДСТ сравнивает эле-
менты списка СЗ с элементами списка С2 с помощью функции
РАВНО. Атомы возвращаются неизмененными.
Слова ПОДСТ (SUBST), УДАЛИТЬ и ОБРАТНЫЙ в Лиспе
имеются, но здесь они не реализованы.
а) ХВОСТ
б) ХВОСТ ПЕРВЫЙ
в) ПЕРВЫЙ ПЕРВЫЙ
г) ХВОСТ ХВОСТ ПЕРВЫЙ ХВОСТ
д) ХВОСТ ХВОСТ ХВОСТ ПЕРВЫЙ
е) ХВОСТ ХВОСТ ПЕРВЫЙ ХВОСТ ХВОСТ ПЕРВЫЙ
ж) ХВОСТ ХВОСТ ПЕРВЫЙ ХВОСТ ХВОСТ ПЕРВЫЙ ХВОСТ
ХВОСТ ПЕРВЫЙ
з) ХВОСТ ХВОСТ ХВОСТ ПЕРВЫЙ
2. Объясните, почему в слове ХВОСТ (экран 40) мы не уменьшаем
@СПИСОК безусловно. Что случится, если мы это сделаем?
3. Постройте схему, аналогичную приведенной на рис. 7.5, для списка из
упр.1, давая подспискам имена.
4. Для всех приведенных ниже списков:
СП1: (С1 (С2 СЗ) С4)
СП2: НУЛЬ
СПЗ: (С2 СЗ)
определите результат применения каждого из следующих выражений:
а) С1 СПп ЧЛ ВЫДАТЬ
б) СПп ДЛИНА
в) СПп АТОМ?
г) СПЗ @ ЧЛ
д) СПЗ ЧЛ
5. Напишите определение слова ОБРАТНЫЙ, располагающего элементы
списка в обратном порядке.
6. Напишите определение слова СГЛАЖИВАНИЕ, которое выбирает
элементы подсписков и помещает их в список верхнего уровня, например:
(А (В C)(D (E F) G)) --> (А В С D E F G)
7. Напишите определения функций доступа к спискам свойств ПОЛУЧСВ '
(GETPROP) и ПОМЕСТСВ (PUTPROP).
УПРАЖНЕНИЯ
1. Для следующего списка:
(А В(С D (E F (G) Н) О)
определите результат выполнения следующих операций:
176
Глава 8
МЕТОДЫ ПРОГРАММИРОВАНИЯ
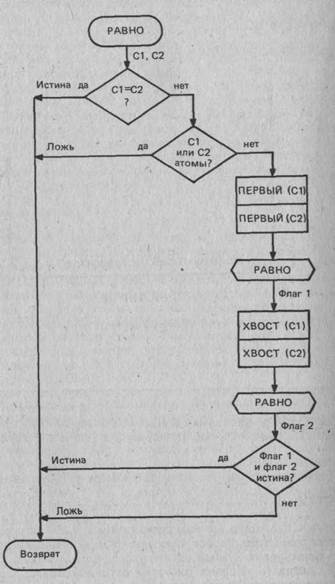
: ПОСЛЕДНИЙ DUP ХВОСТ НОЛЬ NOT
IF ХВОСТ РЕКУРСИЯ
THEN;
Слово ПОСЛЕДНИЙ берет с вершины стека указатель списка и
осуществляет проверку на завершение. При этом проверяется, не
пуст ли хвост списка. Если хвост - НУЛЬ, выполнение слова
заканчивается. В противном случае выбирается хвост списка и
вновь вызывается слово ПОСЛЕДНИЙ. Для этого применяется
слово РЕКУРСИЯ, так как в Форте не предусмотрено нахождение
в словаре слова, определяемого в данный момент. Для иллюстра-
ции выполнения рекурсивных слов предположим, что слово ПОС-
ЛЕДНИЙ было вызвано с указателем в вершине стека, ссылаю-
щимся на список: (А В). Последовательность выполнения слов по-
казана стрелками на рис. 8.1.
 В Лиспе как данные, так и команды выражаются в форме спи-
В Лиспе как данные, так и команды выражаются в форме спи-
сков и взаимозаменяемы. Мы же будем использовать списки толь-
ко в качестве данных (в прямом их смысле), поскольку интерпре-
татор Форта не интерпретирует списки - он интерпретирует шитые
код. Управляющая логика программы отрабатывается соответству-
ющими традиционными словами на Форте. Форт на самом деле
имеет более обширный набор управляющих слов, чем Лисп. Уни-
версальный оператор Форта CASE аналогичен функции COND Ли-
спа. Но в Лиспе отсутствуют такие конструкции, имеющиеся
Форте, как IF-THEN-ELSE, BEGIN-UNTIL, BEGIN-WHILE-
REPEAT. Последние две конструкции являются примитивами пос-
троения циклов. Они заставляют последовательность команд по-
вторяться неоднократно за счет передачи управления назад, на
начало последовательности.
РЕКУРСИЯ
Несмотря на то что Форт предоставляет удобные средства для
программирования рекурсивных процессов, к ним очень редко об-
ращаются. Программирование, основанное на списках, составляет
исключение. Рекурсия имеет место в тех случаях, когда какое-то |
слово вызывает само себя. Если параметры, используемые данным
словом, при этом находятся в стеке, то они во время вызова оче-
редного экземпляра этого слова остаются неизменными. Рекурсию
можно представить как вызов копии исходного слова. Рекурсивный
вызов может выполняться несколько раз и всякий раз параметры
предыдущего вызова будут проталкиваться в глубь стека. В конце
концов некоторое условие должно завершить последовательность
| : ПОСЛЕДНИЙ DUP ХВОСТ НОЛЬ NOT IF ХВОСТ РЕКУРСИЯ
|
| ■: ПОСЛЕДНИЙ DUP ХВОСТ НОЛЬ NOT IF THEN;
|
THEN
Рис. 8.1. Схема передачи управления в рекурсивном слове
ПОСЛЕДНИЙ. РЕКУРСИЯ вызывает копию слова ПОСЛЕДНИЙ (вторая
строка), которая завершает рекурсию
Обратите внимание на то, что здесь две строки содержат опре-
деление слова ПОСЛЕДНИЙ. Верхняя строка соответствует исход-
ному вызову со списком (А В) в стеке. Поскольку хвостом (А В)
является (В), т.е. хвост не пустой, то выполняется ветвь, следую-
щая за IF. ХВОСТ от (А В) помещает в стек (В), а затем выполня-
ется слово РЕКУРСИЯ. Оно вновь вызывает слово ПОСЛЕДНИЙ,
при этом стрелка ведет ко второй строке. Это слово начинает вы-
полняться, на сей раз с (В) в стеке. Хвост (В) является НУЛЕМ,
поэтому ветвь за IF пропускается до THEN и; , что приводит к
выходу из данной копии слова ПОСЛЕДНИЙ и переходу к той,
которая представлена верхней строкой, а именно к варианту, выз-
вавшему копию. Выполнение продолжается с того места, откуда
вызывалась РЕКУРСИЯ. Выход из этого варианта осуществляется
обычным образом и в стеке остается (В) - последний элемент
из (А В).
178
 Если бы список был длиннее, то последовательность списков,
Если бы список был длиннее, то последовательность списков,
остававшаяся в стеке после каждого вызова слова ПОСЛЕДНИЙ,
была бы следующей:
(А В С D)
(BCD)
(CD)
(D)
Поскольку всякий раз, когда рекурсивно вызывается слово
ПОСЛЕДНИЙ, в стек возвращается хвост заданного списка, у это-
го списка последовательно отсекаются головы до тех пор, пока не
останется один элемент. Такая рекурсия называется хвостовой,
так как слово последовательно обрабатывает хвост списка. Кроме
рассмотренных, хвостовую рекурсию осуществляют слова ДЛИНА
и ЧЛ. При использовании ЧЛ ему передаются два параметра, но
при каждом рекурсивном вызове ЧЛ ЭЛЕМЕНТ остается прежним,
а от списка ©СПИСОК - только хвост.
При первом знакомстве рекурсия, как правило, вызывает не-
доумение. Однако она так же естественна, как любой циклический
процесс. Недоумение зачастую происходит от того, что одна и та
же процедура обращается сама к себе несколько раз. Однако пред-
ставьте себе, что всякий раз вызываются отдельные копии, а если
это необходимо, то можно называть каждую копию (скажем слова
ПОСЛЕДНИЙ) своим именем, например: ПОСЛЕДНИЙ 1, ПОС-
ЛЕДНИЙ2 и т.д. Напоминаем, что управление в любую копию пе-
редается дважды: первый раз при ее вызове, а второй - при
возврате в нее после рекурсивного вызова. В определении слова
ПОСЛЕДНИЙ выполняется проверка словом НОЛЬ, а затем сло-
вом ХВОСТ из оператора IF-THEN, после чего РЕКУРСИЯ вызы-
вает слово ПОСЛЕДНИЙ в очередной раз. Управление снова воз-
вращается в данную копию, причем в то место определения, от-
куда произошел рекурсивный вызов, т.е. происходит выход из
оператора IF-THEN и из самого определения этой копии слова
ПОСЛЕДНИЙ.
Для того чтобы понять, что происходит между рекурсивными
вызовами, нужно проследить за изменением содержимого стека
(рис. 8.2). Начиная с верхнего левого угла, мы имеем в стеке
список (А В С). Каждый последующий вызов слова ПОСЛЕДНИЙ
спускает нас на один уровень ниже по левой стороне рисунка. При
первом вызове слова ПОСЛЕДНИЙ в момент рекурсии в стеке ос-
танется (В С).
После второго рекурсивного вызова в стеке останется (С).
Заметьте, что управление все время " крутится" вокруг первой
части слова ПОСЛЕДНИЙ - от его начала до слова РЕКУРСИЯ.
При рекурсии повторяется одно и то же действие. Список как бы
обрезается всякий раз на один элемент. Останавливает такой
рекурсивный спуск выполнение условия завершения: если хвост
180
списка, переданного очередной копии слова ПОСЛЕДНИЙ
НУЛЬ, то рекурсия завершается.
 : ПОСЛЕДНИЙ DUP ХВОСТ НОЛЬ NOT
: ПОСЛЕДНИЙ DUP ХВОСТ НОЛЬ NOT
IF ХВОСТ РЕКУРСИЯ
(А В С)
Вызов
слова
| Результат
после первого •
вызова
|
 ПОСЛЕДНИЙ
ПОСЛЕДНИЙ
(С)
Завершающий вызов: ПОСЛЕДНИЙ DUP ХВОСТ NOT
IF THEN
 Рис. 8.2. Состояние стека при рекурсивном вызове слова
Рис. 8.2. Состояние стека при рекурсивном вызове слова
ПОСЛЕДНИЙ и исходном списке в стеке (А В С). Выполнение
фрагментов Форт-программы, помещенных над вертикальными
линиями, для каждого уровня отмечается стрелкой. Фрагмент,
выполняемый по финальному вызову (который завершает рекурсию),
показан внизу
Когда в третий раз слову ПОСЛЕДНИЙ передается (С), хвост
этого списка оказывается НУЛЕМ, что означает пустой список и
та часть оператора IF-THEN, которая вызывает рекурсию будет
обойдена. Третий вызов слова ПОСЛЕДНИЙ (показан в нижней
части рис. 8.2) осуществляет возврат. Управление передается фраг-менту следующему за словом РЕКУРСИЯ, в копии слова ПОСЛЕДНИЙ, из которой был произведен рекурсивный вызов. На схеме рассматриваемая копия находится на следующем относи-
тельно дна уровне. Здесь выполняется фрагмент THEN; и проис-
ходит очередной выход из определения. Множественный выход из
181
| : ДЛИНА DUP НОЛЬ
IF ELSE ХВОСТ РЕКУРСИЯ
(ABC)
|
копий слова ПОСЛЕДНИЙ продолжается до тех пор, пока не за-
вершится выход из копии самого верхнего уровня.
Во время рекурсивного подъема по стрелкам в правой части
рис. 8.2 список не изменяется. Он просто передается с самого
нижнего уровня наверх. Изменяется только стек возвратов, из
которого при выходе из очередной копии слова ПОСЛЕДНИЙ пос-
ледовательно убираются адреса возвратов.
В качестве второго, чуть более сложного, примера рассмотрим
определения слова ДЛИНА (экран 48). Для сравнения здесь приве-
дены оба варианта - и итерационный, и рекурсивный. В реализа-
ции итерационного алгоритма цикл BEGIN-WHILE неоднократно
исполняется до тех пор, пока список не будет усечен до НУЛЯ. На
каждом шаге выполнения цикла счетчик, значение которого внача-
ле было равно нулю, увеличивается. Состояние стека перед выпол-
нением BEGIN следующее:
(список счетчик)
Рекурсивный вариант действует по аналогичной схеме, но
вместо цикла внутри одной и той же копии слова ДЛИНА в нем
вызываются последовательные копии, как показано на рис. 8.3.
Части определения слова ДЛИНА, соответствующие рекурсивному
спуску и подъему, расположены над вертикальными стрелками. Во
время спуска выполняется начальный фрагмент определения слова
ДЛИНА до слова РЕКУРСИЯ. Результатом выполнения этого фра-
гмента является усечение списка посредством слова ХВОСТ. При
каждом последующем вызове слова ДЛИНА ему передается спи-
сок, укороченный на один элемент. В конце спуска условие завер-
шения истинно, а список пуст.
В этом последнем вызове слова ДЛИНА (ему соответствует
текст в нижней части рисунка) последовательность команд уже
иная, так как здесь выбирается ветвь IF, а не ELSE. Операторы
данной ветви удаляют из стека пустой список и вместо него поме-
щают начальное значение счетчика, равное нулю, после чего осу-
ществляется возврат из нашей копии слова ДЛИНА в вызываю-
щую копию, которая на рис.8.3 расположена уровнем выше. По-
скольку управление возвращается фрагменту, следующему за
словом РЕКУРСИЯ, происходит увеличение числа на стеке и воз-
врат. Количество таких увеличений равно количеству уровней.
Так как каждый уровень соответствует рекурсивному вызову, во
время которого при рекурсивном спуске из списка удаляется один
элемент, число прибавлений на обратном пути будет совпадать с
числом вызовов.
Другой вид рекурсии - так называемая двойная рекурсия, В
этом случае слово РЕКУРСИЯ вызывается дважды. Обычно при
одном вызове передается голова списка, а при втором - хвост.
Примером тому может служить определение слова РАВНО. Его
алгоритм показан на рис. 8.4, а исходный текст приведен на экра-
182

| Выбирается НУЛЬ, заносится О
|
Выбирается НУЛЬ, заносится О
: ДЛИНА DUP НОЛЬ
IF DROPOTHEN
 Рис. 8.3. Схема рекурсивных обращений к слову ДЛИНА. При завер-
Рис. 8.3. Схема рекурсивных обращений к слову ДЛИНА. При завер-
шающем вызове стек очищается от списка, а счетчик обнуляется
не 53. Стековая нотация данного определения следующая:
( С1 С2 -> F)
Если С1 и С2 - атомы, то они сравниваются, на стек помещается
соответствующий флаг и рекурсия при этом не выполняется. Если
же они представляют собой списки, то головы и хвосты С1 и С2
Должны совпадать. Первая рекурсия осуществляется по головам
всех С-выражений. Она продолжается до тех пор, пока не будут
получены атомы, при условии, что сравниваемые головы сами
являются списками, после чего исходный вариант слова РАВНО
начинает рекурсивное выполнение по хвостам всех списков. Зна-
чения флагов от двух рекурсий логически умножаются (операция
Рис. 8.4. Алгоритм выполнения слова РАВНО (пример двойной
Рекурсии)

Рис. 8.5. Рекурсивная схема слова 2СОЕД. При каждом рекурсивном
вызове передаются два элемента (оба списка). Списки (А В С) и ( D )
после соединения образуют (А В С D ). Список ( D ) обозначен буквой L
AND), так как для равенства списковых структур оба они должны
быть истинными. Общее действие в данном случае заключается в
том, что рекурсивно сравниваются головы; затем этот процесс по-
вторяется в виде рекурсии по хвостам.
Последнии пример рекурсии, несомненно, сложнее двух пре-
дыдущих. На рис. 8.5 показана схема рекурсии, аналогичная схе-
мам из первых двух примеров, но для слова 2СОЕД. Здесь при
каждом рекурсивном вызове в стеке находится не один элемент, а
несколько. 2СОЕД (текст приводится на экране 42) берет со стека список (@СПИСОК) и присоединяет его к началу другого списка с именем I. Главная идея алгоритма состоит в усечении @СПИСОК и одновременно передачи копии СПЙСОК2. Эти копии пригодятся
185
184
во время рекурсивного подъема. Когда @СПИСОК становится
НУЛЕМ, завершающий вызов 2СОЕД удаляет из стека пустой
@СПИСОК, а также соответствующий ему список I и осуществля-
ет возврат, как показано в нижней части рис. 8.5.
При рекурсивном подъеме на стек воздействует фрагмент
2СОЕД, находящийся непосредственно за словом РЕКУРСИЯ. Го-
лова каждого варианта @СПИСОК связывается в I. Таким обра-
зом, всякий раз один элемент из исходного варианта @СПИСОК
начиная с конечного хвоста ©СПИСОК, последовательно присое-
диняется к I.
Эти три примера помогут вам детально изучить рекурсивный
вызов отдельной функции, и лишь после того, как вы окончатель-
но разберетесь в нем, можно приступить к более абстрактному
представлению проблемы. Если для понимания происходящего до-
статочно следить за ходом рекурсии по диаграмме, то для написа-
ния рекурсивных процедур требуются уже определенные знания.
Попытаемся проиллюстрировать функционирование слова 2СОЕД
на некотором абстрактом уровне мышления. Так как при рекурсии
вызываются копии какого-либо слова, они должны выполнять в
точности ту же функцию, что и исходное слово при его первона-
чальном вызове.
В функциональной записи обращение к 2СОЕД выглядит так:
2СОЕД(Х, У)
Слово 2СОЕД берет два аргумента, X и Y, и присоединяет X к Y
путем присоединения хвоста списка @СПИСОК к I, или:
2СОЕД(ХВОСТ ©СПИСОК, I)
Затем к результату добавляется голова списка ©СПИСОК:
2СОЕД(ПЕРВЫЙ ©СПИСОК, 2СОЕД (ХВОСТ
©СПИСОК, I))
Обратите внимание на то, что слово 2СОЕД рекурсивно, поскольку
используется в качестве аргумента к самому себе. Второй аргумент
2СОЕД можно развернуть следующим образом:
2СОЕД(ПЕРВЫЙ ©СПИСОК, 2СОЕД(ПЕРВЫЙ ХВОСТ
©СПИСОК, I), I)
Слово 2СОЕД внутри последнего выражения также может быть i
свою очередь развернуто. Эти последовательные расширения могут
продолжаться до тех пор, пока не встретится некоторое условие
завершения.
Рассматриваемое слово 2СОЕД является реализацией такок
функционального подхода. В подобном представлении остается
186
неясным, что же процедура завершения передает самой вложенной
копии слова 2СОЕД. На нижнем уровне рекурсивной схемы пос-
ледний вызов должен выполнить подготовку к подъему, поскольку
условие завершения инициирует переход только один раз. Напри-
мер в случае 2СОЕД при подготовке к подъему необходимо уда-
лить из стека два верхних элемента, оставшихся в нем после
спуска.
Возможен и другой путь представления процесса рекурсии -
как пары последовательных итерационных процедур с процедурой
завершения, разделяющей их в нижней части рекурсивной схемы.
Если вы следите за состоянием стека по ходу рекурсивного
выполнения какого-то слова, то, подходя к слову РЕКУРСИЯ,
нужно учитывать, что состояние стека должно в точности соответ-
ствовать его состоянию перед исходным выполнением этого слова
(как это определено стековой нотацией для данного слова).
При выполнении слова 2СОЕД РЕКУРСИЯ выбирает из стека
два элемента, но не помещает в стек ни одного. Два списка,
переданные слову 2СОЕД при исходном обращении, остаются в
стеке, а затем копируются посредством OVER ХВОСТ OVER для
передачи слову РЕКУРСИЯ. После возврата из слова РЕКУРСИЯ
очевидно, что завершилось выполнение
2СОЕД(ХВОСТ ©СПИСОК, I)
Далее последовательность SWAP ПЕРВЫЙ SWAP СВЯЗЬ вычисля-
ет ПЕРВЫЙ ©СПИСОК, а СВЯЗЬ осуществляет присоединение.
То, что РЕКУРСИЯ оставляет в стеке, определяет характер
выполнения процедуры завершения. В нашем случае по крайней
мере два элемента должны быть удалены из стека. Никаких иных
действий не требуется, следовательно, ветвь IF содержит 2DROP.
В предыдущем примере со словом ДЛИНА все необходимое для
процедуры завершения можно было выяснить путем анализа содер-
жимого стека до и после выполнения слова РЕКУРСИЯ. Список
следовало вывести из стека, а число внести, что ветвь IF слова
ДЛИНА и делала. Она удаляла посредством DROP из стека указа-
тель списка и помещала в него начальное значение (0).
Двойную рекурсию можно организовать так же, как и обыч-
ную хвостовую рекурсию, которая использовалась в приведенных
выше примерах. Стандартная схема действий такова: проверка ус-
ловия завершения, затем выбор головы и хвоста списка, рекурсия
по каждому из них и затем объединение результата по какому-ни-
будь принципу. Для слова РАВНО (рис. 8.4) условием завершения
Рекурсии является проверка на атомы, а значения флагов, оставля-
емые в стеке после двух рекурсивных вызовов, логически умножа-
ется посредством AND.
Тщательно изучите приведенные выше примеры рекурсии, постарайтесь выработать свои приемы и понятие рекурсии станет для вас таким же привычным, как и понятие цикла. Слова Лиспа на
187
экранах с 40 по 49 (см. гл. 7 или листинга исходных текстов) тоже
могут служить примерами слов, реализованных с помощью
рекурсии.
СБОРКА МУСОРА
Важной составляющей общей реализации Лиспа является уп-
равление списковой памятью - областью памяти, выделенной под
списки. В нашей несколько упрощенной реализации память под
списки выделяется статически (во время компиляции), а не дина-
мически. Но в силу того, что управление списковой памятью, как
уже отмечалось, играет не последнюю роль для Лиспа в частности
и для языков ИИ вообще, мы рассмотрим ее здесь.
Так как ячейки связи, из которых строятся списки, могут ос-
вобождаться, требуется некоторый механизм, позволяющий опре-
делить, какие ячейки свободны для использования их словом
СВЯЗЬ, а какие из них уже заняты. Существуют различные схе-
мы управления списковой памятью, обеспечивающие решение за-
дачи динамического распределения памяти. Основная проблема за-
ключается в распознавании свободных ячеек связи. Этот процесс
называется сборкой мусора. В большинстве реализаций Лиспа
применяется техника отметить и удалить ( mark and sweep ).
Другая схема, описываемая ниже более подробно, называется
учетом ссылок ( reference counting ).
Прежде чем объяснить различие между этими методами, мы
должны упомянуть о двух нежелательных эффектах при работе с
памятью - висячих ссылках и мусоре, причем первый из них пред-
ставляет наибольшую опасность. Висячие ссылки появляются в тех
случаях, когда некоторая ячейка считается свободной, хотя факти-
чески остается все еще занятой. Если ячейки, входящие как сос-
тавные части в активные (используемые) списки, ссылаются на
ячейку, которая стала считаться свободной, то это не мешает слову
СВЯЗЬ данную ячейку задействовать вновь и сделать ее частью
нового списка. В результате появляются " висячие" указатели из
активных ячеек, так как их значения фактически не определены.
Отсюда следует, что нельзя активную ячейку связи делать свобод-
ной. Второй эффект противоположен первому. Мы полагаем, что
ячейка активна, а она на самом деле свободна. Такая ячейка на-
зывается мусором, поскольку не может быть повторно использова-
на, и нет способа узнать, что она не занята.
При отметке и удалении мы можем избежать неприятностей
так как разрешаем использовать всю свободную память, а затем
собираем мусор. Специальная программа просматривает списки, на
которые есть ссылки от идентификаторов, и, поскольку такие
списки являются активными, в " бите сборки мусора" каждой а
тивной ячейки делается отметка, показывающая, что данна
ячейка не может быть освобождена. Далее просматривается вся
списковая память и непомеченные ячейки собираются в отдельный
свободный список, откуда будут вновь выделяться словом СВЯЗЬ.
Но для задач реального времени схема отметки и удаления не сов-
сем подходит, так как сборка мусора занимает очень много време-
ни, а задача при этом не может выполняться. На больших компью-
терах пауза для сборки мусора может занимать секунды. Не дай
бог связываться с длительными циклами по непрерывному обнов-
лению памяти!
Учет ссылок не требует длительных пауз для подчистки спис-
ковой памяти. Однако такой подход имеет недостаток: програм-
мисту приходится вести точный учет использования ячеек памяти,
а потому каждая ячейка связи должна иметь дополнительную па-
мять для счетчика ссылок. Последний содержит число активных
указателей, ссылающихся на данную ячейку. Всякий раз, когда
указатель удаляется, счетчик ссылок ячейки, на которую ссыла-
ется указатель, уменьшается (посредством RC- ), а когда активный
указатель начинает ссылаться на эту ячейку, - увеличивается (по-
средством RC+ ). Нулевое значение счетчика ссылок свидетель-
ствует о том, что ячейка свободна. Если над списками
выполняются неразрушительные операции, то они в процессе
выполнения производят копии исходных списков с помощью слова
СВЯЗЬ. Счетчики ссылок ячеек таких списков не увеличиваются,
так как эти ячейки не приписываются идентификатору и по
определению не активны.
Управление счетчиками ссылок осуществляется операторами
RC+ и RC-. Они различаются только тем, что RC+ увеличивает
значение счетчиков, a RC- их уменьшает. Эти операторы прос-
матривают всю структуру некоторого списка целиком и модифи-
цируют счетчики ячеек каждой ячейки связи данного списка.
Для того чтобы сохранить только ячейки связи, являющиеся
частью списка, на который ссылается идентификатор списка, при-
меняется слово УСТАНОВИТЬ (или SETQ в Лиспе). Оно выполня-
ет большую часть работы счетчиков ссылок по обновлению. Слово
УСТАНОВИТЬ запускает RC+ на список, когда на тот начинает
ссылаться идентификатор списка, и RC-, когда тот же самый
идентификатор прекращает ссылки. Таким образом, управление
ячейками осуществляется просто словом УСТАНОВИТЬ. Применя-
емые в настоящее время методы сборки мусора, конечно, более
сложны, чем две предложенные вам здесь схемы, и, как правило,
представляют их комбинации. Кроме того, современные языки ИИ
для эффективного хранения массивов, символьных строк и чисел
используют структуры данных, отличные от ячеек связи.
189
РЕАЛИЗАЦИЯ ФУНКЦИЙ
ПРЕОБРАЗОВАНИЯ СПИСКОВ
В Лиспе функции преобразования применяются не для соз
дания модифицированных копий списков, а для модификации
структуры самих списков. Ниже будут описаны некоторые таки
функции из числа наиболее часто употребляемых.
ЗАМЕНЕ инициирует RC- для конкретного списка, а затем
вызывает слово ЗАМЕНГ*, которое фактически осуществляет его
изменение. Оно замещает заголовок списка заданным С-выражени
ем. ЗАМЕНХ же замещает хвост. Остальные слова преобразования
списков используют ЗАМЕНГ* и ЗАМЕНХ*, поскольку каждое
слово для того, чтобы привести в соответствие счетчики ссылок
обращается к RC-. Слова ЗАМЕНГ* и ЗАМЕНХ* являются прими
тивами преобразования списков, поскольку они, в отличие от
ЗАМЕНГ и ЗАМЕНХ, -не затрагивают счетчики ссылок.
НОБРАТНЫЙ циклически просматривает заданный список
СП1 и замещает прежние значения хвостов ячеек связи указателя
ми на предыдущие ячейки, как показано на рис. 8.6. Хвост первого
элемента СП1 устанавливается в НУЛЬ, чтобы обозначить конец
преобразованного списка. СП2 является указателем обратного спи-
ска, поскольку ссылается на его заголовок.

Рис. 8.6. Список СП2, реорганизованный в обратном порядке. Хво-
стовые значения ячеек связи исходного списка СП1 (вариант А)
заменены указателями на предыдущие ячейки (вариант В)
*НКОНК (*NCONC), а также слово НКОНК (NCONC) осу-
ществляет конкатенацию списков СШ и СП2, замещая НУЛЬ пос-
леднего элемента СШ указателем на СП2. Слово ПРИСОЕД
(ATTACH) выбирает из стека аргументы С - С-выражение и СП-
список. Если С представляет собой атом, то с помощью слова
СВЯЗЬ оно присоединяет С к СП, а если - список, то так же, как
и слово *НКОНК, замещает хвост С указателем на СП. С стано-
вится начальной частью нового списка.
НУДАЛИТЬ (DREMOVE) использует слово НУДАЛИТЫ, ко-
торое, подобно НУДАЛИТЬ, выбирает С и СП как аргументы и
удаляет из СП все ячейки с головами, равными (РАВ) С. Ре-
зультат выполнения НУДАЛИТЬ показан на рис. 8.7. Хвост ячей-
ки, указывающий на ячейку, голова которой РАВ С, модифициру-
ется таким образом, что указываемая ячейка обходится, ее место
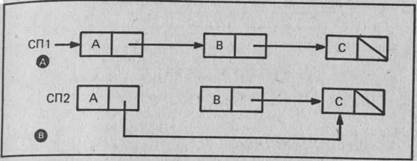
Рис. 8.7. Удаление элемента из списка с помощью слова
НУДАЛИТЫ. Элемент В удаляется из исходного списка СП1 (вариант
А), в результате получается список СП2 (вариант В)
занимает следующая-и тем самым средняя ячейка исключается из
списка. НУДАЛИТЬ проверяет голову первой ячейки СП на равен-
ство (РАВ) С. Если равенство не обнаруживается, то вызывается
слово НУДАЛИТЫ, которое перемещается дальше по СП, обходя
ячейки с головами, равными (РАВ) С, путем изменения хвостовых
указателей. Однако если должен быть удален первый элемент СП,
то его голова и хвост замещаются содержимым этих полей из
второго элемента - таким образом осуществляется эффективный
обход второго элемента, поскольку хвост первой ячейки теперь
указывает на третью ячейку, так как вторую ячейку мы предвари-
тельно удалили. Затем для преобразования этого списка можно
вызвать слово НУДАЛИТЫ. Схема выполнения слова НУДА-
ЛИТЬ показана на рис. 8.8.
Функции преобразования списков нужно применять с осто-
рожностью по следующим причинам:
1. Если на некоторый список ранее ссылался идентификатор
списка, то после выполнения функции преобразования он может
не ссылаться на гол ову этого списка, так как списки реорганизуют-
ся- Например, слово НОБРАТНЫЙ возвратит указатель на голову
обратного списка, но идентификатор списка, который указывал на
исходный список, теперь ссылается на последний элемент вновь
полученного списка. После выполнения функций непосредственно-
го преобразования списков все ссылающиеся на них идентификато-
ры должны быть переназначены.
190
191
2. Поскольку происходит переупорядочение элементов списка
сведения о том, какие ячейки связи освободились, не получаются
автоматически. Должно быть выполнено динамическое перераспре-
деление списковой памяти.
| О
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
 54
54
\ ПРИМЕР РЕКУРСИИ: ВЫЧИСЛЕНИЕ ФАКТОРИАЛА
( N М -> )
: ФАКТОРИАЛ OVER 0=
IF NIP
ELSE OVER * SWAP 1- SWAP РЕКУРСИЯ
THEN
( M -> M! )
: ФАКТОРИАЛ 1 " ФАКТОРИАЛ;
 Экран 54. Определение рекурсивных слов ФАКТОРИАЛ и
Экран 54. Определение рекурсивных слов ФАКТОРИАЛ и
•ФАКТОРИАЛ
3. С помощью функций преобразования легко создать непра-
вильные списки. Часто случайно образуются зацикленные списки.
Как правило, они обнаруживаются при печати, инициируемой сло-
вом ВЫДАТЬ, одного из них. Вывод таких списков продолжается
бесконечно и требует аппаратного переключения или какого-ни-
будь иного принудительного выхода из системы.
ФУНКЦИИ НЕПОСРЕДСТВЕННОГО
ПРЕОБРАЗОВАНИЯ СПИСКОВ И УЧЕТ ССЫЛОК
Функции непосредственного преобразования списков усложня-
ют управление памятью, так как изменяют структуру самого спис-
ка, а не возвращают его видоизмененную копию. Если существует
идентификатор, ссылающийся на список, который подвергался пре
образованиям посредством слова НОБРАТНЫЙ или НУДАЛЕ-
НИЕ, то неясно, что делать со счетчиками ссылок. Не известно
вошли ли ячейки исходного списка в полученный список (в случае
НУДАЛИТЬ) или добавлены новые ячейки (в случае ЗАМЕНГ
ЗАМЕНХ). К счастью, есть простой способ справиться с этой проб

Рис. 8.8. Алгоритм слова НУДАЛЕНИЕ. Если из списка СП1, изобра-
женного на рис. 8.7, должна быть удалена первая ячейка, то проис-
ходит замещение головы и хвоста первой ячейки содержимым вто-.
рой. В противном случае вызывается НУДАЛЕНИЕ1
лемой. Если перед модификацией списка преобразующие слова
уменьшают счетчики ссылок списка, используя RC-, то
впоследствии ни одна ячейка, изъятая из списка, не становится
мусором. Затем выполняется модификация списка.
Здесь необходимо отметить (позднее мы обсудим этот вопрос
подробнее), что любой идентификатор измененного списка сейчас
неверен, поскольку он продолжает ссылаться на ячейку, которая
была заголовком списка, но теперь может им не быть. Должна
быть выполнена последовательность действий, переназначающая
идентификатор новому списку. Сначала выполняется с новым спи-
ском RC+, а затем с помощью функций Форта указатель списка
заносится в переменную идентификатора списка. Второй вопрос
(более тонкий) состоит в определении влияния реорганизации
списка на другие списки, содержащие подсписки вместе с реорга-
низованным списком. Таких ситуаций желательно избегать,
выполняя функции преобразования списков только над теми
словами, которые не имеют общих нодсписков с другими словами.
УПРАЖНЕНИЯ
1. Используя рекурсию, напишите слово ФАКТОРИАЛ, которое вычисляло бы
факториал п. Стековая нотация имеет вид: ( п —> п! )
2. Изобразите схему рекурсии слова ФАКТОРИАЛ из упр. 1.
3. Напишите слово ОБРАТНЫЙ из упр.5 гл.7 как рекурсивное слово.
4. Напишите слова ЗАМЕНГ и ЗАМЕНХ. Примените их для написания
слова НОБРАТНЫЙ.
192
рирует отдельный факт. Программа на Прологе содержит перечень
пред ло ж ений ( clause ), которые суть либо факты, либо правила.
Предложения записываются в форме:
заголовок: - цель,, цель2, ..., цельп
Глава 9
ПРОЛОГ - ЯЗЫК РАЗРАБОТКИ СИСТЕМ,
ОСНОВАННЫХ НА ЗНАНИЯЯ
 Компьютерные программы, интерпретирующие продукции,
Компьютерные программы, интерпретирующие продукции,
или правила вывода и содержащие знания специалистов, называ-
ются экспертными системами, или системами, основанными на
знаниях (или просто системами знаний). В настоящей главе рас-
сматривается построение интерпретатора правил вывода с исполь-
зованием методов, описанных з гл.8. Этот интерпретатор является
упрощенным вариантом интерпретатора правил языка Пролог - ве-
дущего языка логического программирования.
. ЛОГИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
НА ПРОЛОГЕ
В 70-е годы из Франции и Шотландии до нас дошел язык ло-
гического программирования Пролог. Он бал выбран для японского
проекта компьютеров пятого поколения. Пролог ( PROLOG - PRO-
gramming LOGic ) представляет собой простой, но в то же время
мощный язык. Он относится в большей степени к реляционным
или декларативным.( описательным), а не к функциональным
языкам. Функция - это вид процедуры, которая выбирает передан-
ные ей аргументы, обрабатывает их и возвращает результат. При-
мером функционального «зыка может служить Форт. Программа
на реляционном языке состоит из операторов, описывающих отно-
шения между представляемыми объектами, на Прологе - в терми-
нах логики предикатов. Предикаты используются для представле-
ния фактов и могут быть истинными или ложными. Предикаты
млекопитающее (козел)
утверждает, что " козел является млекопитающим". Этот оператор
не предписывает выполнение некоторой процедуры, а лишь декла-
194
заголовок предложения называется заключением правила, в то
время как цели, разделенные запятыми, - посылками или условия-
ми Символ : - может восприниматься как слово " если". Цели, сле-
дующие за символом " если", в совокупности называются телом.
Правило при таких обозначениях может быть прочитано так:
" Если цель1 и цель2 и... и цельn истинны, то заголовок истинен".
Типы данных в Прологе, как это принято в логике, называют-
ся термами. На рис. 9.1 показано, что термами в Прологе могут
быть константы, переменные или структуры. Константы - это либо
атомы, либо целые числа. Атомы должны начинаться со строчной
буквы или заключаться в одинарные кавычки. Переменные обозна-
чаются именами с прописной первой буквой. Структуры состоят из
двух частей: функтора ( functor ) - атома, и компонент - термов,
заключенных в круглые скобки и разделенных запятыми. Структу-
ры могут применяться в качестве логических предикатов, напри-
мер:
отец(Х, 'Билл').
Предлагаемый вам терм читается так: " X отец Билла" и явля-
ется предикатом, поскольку может быть либо истинным, либо лож-
ным. Слово " Билл" заключено в одиночные кавычки, чтобы пока-
зать, что это атом. Без кавычек данное слово интерпретировалось
бы как переменная, например X. Переменная X и " Билл" счита-
ются компонентами структуры.
Функтор, который может быть использован либо в префикс-
ной, либо в инфиксной записи, представляет собой оператор.
Например, ' символ " если" (: - ) может применяться в такой
записи:
-: (а, Ь, с)
или в инфиксной:
а: - b, с
Не все функторы - операторы, но те, которые мы привыкли рас-
сматривать в качестве операторов (например, : - или + ), определе-
ны как операторы.
Факты, а также заголовки и цели правил - термы. Помимо
термов в Прологе имеются списки. (Обратите внимание: правила
195
имеют заголовки, а списки - головы, что не всегда одно и то же.) В
Прологе списки заключаются в квадратные скобки. Например:
[а, Ь, с]
Это список из трех элементов, где а - голова, [b, cj - хвост.
 Термы
Термы
Переменные
Компоненты
(термы)
Операторы
(в префиксной или
инфиксной записи)
 Рис. 9.1. Типы данных в Прологе. Функторы являются атомами, а ко-
Рис. 9.1. Типы данных в Прологе. Функторы являются атомами, а ко-
мпоненты - термами. Логические предикаты и арифметические опе-
рации представляют собой структуры. Такие операторы,
как: -, могут использоваться в инфиксной форме
Пустой список записывается как []. В списке
[Г|Х]
вертикальной чертой разделены голова и хвост.
В Прологе имеются встроенные предикаты, такие, как " если"
(: - ). Ниже приводятся еще несколько встроенных предикатов:
истина ( true )
ложь ( false )
пер(Х) ( var ( X )) Возвращает истину, е сли
X - переменная
атом(Х) ( at o mic ( X )) Возвращает истину, если
X - константа
Комментарий в исходном тексте заключается в парные симмет-
ричные слэжи-звездочки:
/ *... */
Для всех программ б Прологе предусмотрена одна процедура
вывода. Поскольку прикладные области применения Пролога весь-
ма обширны, эта процедура, без сомнения, должна быть мощной и
универсальной. Речь идет о процедуре поиска, дополненной прави-
лом вывода, известным как резолюция. Вместе того чтобы иметь
несколько правил вывода, по которым из существующих предложе-
ний логически выводятся новые факты, вполне достаточно пользо-
ваться лишь резолюцией, что упрощает дело, в частности при вы-
боре применимого правила на каждом шаге процесса рассуждения.
Правила, записываемые программистом как предложения, не
являются правилами вывода Пролога, а представляют собой логи-
ческую импликацию и эквивалентны следующей записи:
заголовок v ⌐ цель1 v ⌐ цель2 v... v⌐ цельп
где v - знак логической операции ИЛИ (дизъюнкции), & - знак
логической операции И (конъюнкции), а ⌐ - операция НЕ (логи-
ческое отрицание). Предложения Пролога связаны между собой-
логической конъюнкцией, т.е. в совокупности они истинны.
Теперь рассмотрим два предложения:
цель, заголовок: - цель
Первое предложение - факт, а второе - правило, которое ло-
гически может быть выражено связкой ⌐ цель v заголовок. Поско-
льку предложения объединяются конъюнкцией, такая запись эк-
вивалентна логическому выражению:
цель & (⌐ цель v заголовок)
Так как выражение цель & ⌐ цель всегда ложно, то результи-
рующим выражением должно быть следующее: цель & заголовок.
Резолюция есть правило вывода, объединяющее два выражения -
факт и правило. При этом цель правила сопоставляется с фактом и
выводится новый факт - заголовок правила. В результате цель
продолжает оставаться в числе предложений, а заголовок добавля-
ется к их числу. Как факты, так и правила являются предложени-
ями и имеют одну и ту же форму, поскольку факт это то же пра-
вило, но без целей:
факт: -
196
197
Иными словами, факт можно считать правилом, которое выполня-
ется безусловно, не имея целей. Отрицания фактов могут быть
выражены следующим образом:
: - факт
что эквивалентно выражению ⌐ факт по определению логической
импликации.
Прежде чем описывать процедуру поиска, рассмотрим простой
пример программы на Прологе. В гл.8 вам демонстрировалась ре-
курсия в определении слова 2СОЕД. Эта функция на Прологе
может быть выражена в виде логического предиката (структуры
Пролога):
соед(СП1, СП2, СПЗ)
означающего: " Соединение списков СП1 и СП2 дает в результате
список СПЗ". Например, для СП1 (А В) и СП2 (С D) СПЗ будет
(А В С D). На Прологе функция соед может быть выражена следу-1
ющим образом:
соед([], СП2, СП2)
соед([Г|СП1], СП2, [Г|СПЗ]): -соед(СП1, СП2> СПЗ)
Первое предложение подобно условию завершения слова
2СОЕД. Оно означает, что если к СП2 присоединяется [] (или
НУЛЬ), то в результате получается СП2. Во втором предложении
содержится слово соед как в заголовке, так и в цели, что озна-
чает рекурсию. Если СП1 присоединяется к СП2 для образования
СПЗ, то список с заголовком Г и хвостом СП1, присоединенный к
СП2, даст в результате список с головой Г и хвостом СПЗ.
Чтобы проверить слово соед в действии, присоединим (а Ь) к
(с d). Успешными подстановками в заголовок правила являются
следующие:
| [Г|СП3]
[а|СП3]
[а|СП3] ]
|
Пустой список СП1 в последней строке запускает условие завер-
шения для слова соед. Теперь подбирается не правило, а факт:
соед([ ], СП2, СП2)
Здесь мы выполняем такие подстановки:
СП2 [Г|СПЗ]
(с d) [a|[b|(cd)]]
198
При последнем подборе вместо СПЗ подставляется СП2. В ре-
зультате получаем список:
[a|[b|(cd)]]-> [abcd]
Обратите внимание: в то время как [Г|СП1] обеспечивает
сопоставление с (а Ь), третий аргумент правила, [Г|СПЗ}, кон-
струирует список. Обратное действие состоит в подстановке СПЗ
из цели в СПЗ заголовка. Это ведет к тому, что предыдущая под-
становки, скажем [а|СПЗ] для СПЗ, заменит текущий список
СПЗ в [Ь|СПЗ]:
[а|[b|СПЗ]]
Во время последней итерации СП2 заменит СПЗ, и реоргани-
зация списка будет завершена.
ИНТЕРПРЕТАТОР ПРОЛОГА
Повторяющееся применение фактов к правилам, приводящее
к новым фактам, называется прямым рассуждением ( forward
chaining ). При обратном рассуждении { backward chaining }
осуществляется поиск заключений (заголовков правил), соответст-
вующих цели. Если такое заключение найдено, то в свою очередь
должны быть доказаны цели, входящие в данное правило, В Про-
логе используется обратное рассуждение.
В Прологе поиск осуществляется в глубину. Алгоритм поиска
показан на рис.9.2. Здесь задействованы три списка. Первый,
ПРЕДЛОЖЕНИЯ (CLAUSES), содержит предложения. Во втором,
ЦЕЛИ (GOALS), находятся цели, подлежащие удовлетворению.
Третий список, РЕШЕНИЯ (SOLVED), включает точки возврата
(см. ниже) и хранит следы предложений, применившихся для дос-
тижения целей. Это своего рода трасса нахождения решения про-
цедурой поиска.
Как показано на рис. 9.2, процедура поиска ПОИСК
(SEARCH) просматривает список ЦЕЛИ, Если он пуст, то, значит,
не осталось ни одной цели, которую нужно доказать, и поиск
считается успешным. В противном случае удаляется первая цель
из списка ЦЕЛИ, и сканирование продолжается по списку ПРЕД-
ЛОЖЕНИЯ в поисках подходящего предложения. Если таковое
найдено, то указатель (в списке ПРЕДЛОЖЕНИЯ) на это предло-
жение вместе с целью добавляется к списку РЕШЕНИЯ. Указатель
отмечает, как далеко процедура ПОИСК продвинулась в списке
ПРЕДЛОЖЕНИЯ перед нахождением нужного предложения. За-
тем проверяются цели выбранного предложения. Если хотя бы
одна из них недостижима, указатель продвигается до следующего
подходящего предложения в списке ПРЕДЛОЖЕНИЯ и его цели
199
помещаются в список ЦЕЛИ. Такая реакция на неудачу называет-
ся возвратом. Этот новый указатель замещает прежний в списке
РЕШЕНИЯ, и всякий раз, когда совершается возврат, продвигает-
ся далее по списку ПРЕДЛОЖЕНИЯ. Если указатель достигает
конца списка ПРЕДЛОЖЕНИЯ, то, следовательно, в списке нет
предложений, доказывающих искомые цели, и ПОИСК заверша-
ется неудачей.
Чтобы объяснить действие процедуры поиска, нам потребуется
пример списка предложений и цель. Предложения будут представ-
лены в форме, принятой в данной реализации (см. экраны с 60 по
65 ). Для нашего примера на экране 70 приводится небольшая база
знаний. Список ПРЕДЛОЖЕНИЯ содержит следующие предложе-
ния:
1. (ДАЕТ-МОЛОКО)
2. (ИМЕЕТ-ВОЛОС-ПОКРОВ)
3. (ИМЕЕТ-РОГА)
4. (МЛЕКОПИТАЮЩЕЕ ДАЕТ-МОЛОКО
ИМЕЕТ-ВОЛОС-ПОКРОВ)
5. (КОЗЕЛ БОРЬКА)
6. (КОЗЕЛ МЛЕКОПИТАЮЩЕЕ ИМЕЕТ-РОГА)
Предложения 1, 2, 3 и 5 - факты; предложения 4 и 6 - правила.
Список ЦЕЛИ выглядит как (КОЗЕЛ). Итак, процедура ПОИСК
будет пытаться доказать цель КОЗЕЛ, используя утверждения,
содержащиеся в списке ПРЕДЛОЖЕНИЯ. Список РЕШЕНИЯ
первоначально пуст.
Как показано на рис, 9.2, ПОИСК в первую очередь прове-
ряет, не пуст ли список ЦЕЛИ, а затем удаляет из списка ЦЕЛИ
объект КОЗЕЛ, после чего он становится пустым. Теперь ПОИСК
находит первое предложение с заголовком, сопоставимым с фак-
том КОЗЕЛ (предложение 5), и помещает утверждение КОЗЕЛ,
а также указатель на 5 в список РЕШЕНИЯ. Поскольку предло-
жение (предложение 5) выбрано, так как его заголовок совпал с
фактом КОЗЕЛ, тело данного правила добавляется к списку;
ЦЕЛИ. Теперь в списке ЦЕЛИ появляется содержимое:
(БОРЬКА)
Поиск продолжается. Цель удаляется из списка ЦЕЛИ, и
ищется предложение, удовлетворяющее факту БОРЬКА. Так как
его не существует, поиск заканчивается неудачей и происходит
возврат.
Итак, список ЦЕЛИ пуст, а предыдущая цель (КОЗЕЛ) вмес- j
те с указателем на предложение 5 восстанавливается из списка-
РЕШЕНИЯ. Пара указатель/цель удаляется из списка РЕШЕНИЯ
и предпринимается новая попытка поиска цели, начиная с пред-;
ложения, следующего за предложением 5. Теперь уже предложе-
200
ние 6 в списке ПРЕДЛОЖЕНИЯ сопоставляется с утверждением
КОЗЕЛ. Это новая точка возврата, поэтому и КОЗЕЛ, и предло-.
жение 6 помещаются в список РЕШЕНИЯ. Цели предложения 6
добавляются к списку ЦЕЛИ. Возврат закончился и так как пред-
ложение, совпадающее с фактом КОЗЕЛ найдено (предложение 6)
ПОИСК не завершает аварийно работу, а продолжает выполнение
по описанному выше алгоритму до тех пор, пока не будут достиг-
нуты все цели, или произведен возврат по последнему предложе-
нию из списка ПРЕДЛОЖЕНИЯ. Если поиск завершается успеш-
но, то список РЕШЕНИЯ содержит следы пути поиска, показыва-
ющие, каким образом была доказана истинность цели. В случае
же неудачи в списке РЕШЕНИЯ остается частичное решение, по
которому можно судить о том, как далеко продвинулось выполне-
ние процедуры ПОИСК перед аварийным завершением.
Продемонстрируем работу интерпретатора правил на примере.
Загрузив экран 70, вы скомпилируете в словарь Форта описанную
выше базу знаний и создадите списки. Активируя слово СЛЕД, вы
можете нажатием любой клавиши останавливать выполнение, а за-
тем продолжать его, причем на каждом шаге вывода (т.е. на каж-
дом шаге цикла поиска) на экран будут выводиться списки ЦЕЛИ
и РЕШЕНИЯ. На рис. 9, 3 показаны результаты последовательного
выполнения слова СЛЕД. Каждый фрейм ЦЕЛИ-РЕШЕНИЯ раз-
делен пустой строкой.
Первый напечатанный фрейм характеризует начальное состо-
яние списков перед первым выводом. В каждом после дующем
70
0 \ БАЗА ЗНАНИЙ
1: МАРКЕР;
2 ПРАВИЛО: ДАЕТ-МОЛОКО (ДАЕТ-МОЛОКО )
3 ПРАВИЛО: ИМЕЕТ-ВОЛОС-ПОКРОВ (ИМЕЕТ-ВОЛОС-ЛОКРОВ )
4 ПРАВИЛО: ИМЕЕТ-РОГА (ИМЕЕТ-РОГА )
5 ПРАВИЛО: МЛЕКОПИТАЮЩЕЕ (МЛЕКОПИТАЮЩЕЕ
6 ДАЕТ-МОЛОКО
7 ИМЕЁТ-ВОЛОС-ПОКРОВ )
8 ПРАВИЛО: КОЗЕЛ1 (КОЗЕЛ БОРЬКА )
9 ПРАВИЛО: КОЗЕЯ2 (КОЗЕЛ МЛЕКОПИТАЮЩЕЕ ИМЕЕТ-РОГА )
10 ПРЕДЛОЖЕНИЯ НУЛЬ УСТАНОВИТЬ ПРЕДЛОЖЕНИЯ НТСП
11 (ДАЕТ-МОЛОКО @ ИМЕЕТ-ВОЛОС-ЛОКРОВ @ ИМЕЕТ-РОГА
@ МЛЕКОПИТАЮЩЕЕ @ КОЗЕЛ1 @ КОЗЕЛ2 @ )
13 РЕШЕНИЯ НУЛЬ УСТАНОВИТЬ
Т4 ЦЕЛИ НУЛЬ УСТАНОВИТЬ
15 НУЛЬ КОЗЕЛ ЦЕЛИ СПИСОК
Экран 70. База знаний
202
фрейме из списка ЦЕЛИ удаляется каждая недостигнутая цель и
добавляются цели из вновь выбранного предложения. Это предло- ение также появляется в виде первого элемента в списке РЕШЕ-
НИЯ. При первом выводе (рис. 9.3) цель БОРЬКА не достигается.
Во втором фрейме БОРЬКА удален из списка ЦЕЛИ, а цели пер-
вого предложения из списка РЕШЕНИЯ добавлены. Это предложе-
ние в списке РЕШЕНИЯ было найдено при возврате. Последний
фрейм показывает, что все цели достигнуты, так как список ЦЕЛИ
представляет собой НУЛЬ. Список РЕШЕНИЯ содержит последо-
вательность вывода, примененную для доказательства ЦЕЛИ из
списка РЕШЕНИЯ.
На экране 71 приводится несколько расширенная база знаний,
в которой предложения расположены так, что дважды совершается
возврат для утверждения КОЗЕЛ и один раз для утверждения
ИМЕЕТ-ВОЛОС-ПОКРОВ. Поскольку факты ни БОРЬКА, ни
ГРУБИЯН не могут быть доказаны, а факт ГРУБИЯН оказывался
целью дважды, произошло три возврата.
РЕАЛИЗАЦИЯ ПОИСКА
Реализация алгоритма процедуры ПОИСК представлена на
экранах с 60-го по 63-й, а весь " пакет" - на экранах с 60-го по
65-й. Она построена на использовании лиспоподобных слов, опи-
санных в гл.7, а также программ, приведенных на экранах 70 и 71.
Поскольку сам алгоритм поиска был уже рассмотрен выше, оста-
новимся на деталях реализации.
На экране 63 показано слово ПОИСК, содержащее простой
цикл повторения слова (ПОИСК), приведенного на экране 62.
Слово (ПОИСК) выполняет свои функции и передает слову
ПОИСК флаг успех/неудача, по которому и определяется момент
завершения. В первую очередь (ПОИСК) посредством слова НОЛЬ
проверяет список ЦЕЛИ. Если список не пуст, то с помощью кома-
нды ПОЛУЧИТЬ-ЦЕЛЬ определяется цель из списка ЦЕЛИ. За-
тем (ПОИСК) получает указатель на заголовок списка ПРЕДЛО-
ЖЕНИЯ, чтобы приступить к поиску цели с начала списка.
Слово НАЙТИ-ПРЕДЛОЖЕНИЕ? получает цель и указатель
в список ПРЕДЛОЖЕНИЯ и пытается найти предложение с заго-
ловком, сопоставимым с целью. Если поиск завершается успешно,
то, помимо всего, цель и указатель на выбранное предложение
помещаются в список РЕШЕНИЯ. В стек возвращается флаг, кото-
рый истинен, если предложение было найдено.
В слове (ПОИСК) выбор предложения осуществляет ветвь IF.
В ней активируется слово ДОБАВИТЬ-ЦЕЛИ, которое помещает
в список ЦЕЛИ цели выбранного предложения (указатель на
него находится в списке РЕШЕНИЯ). Если подходящего предложе-
ния не оказалось, требуется возврат: выбирается ветвь ELSE и
вызывается слово ВОЗВРАТ. Какая бы из ветвей ни выполнялась,
203
 71
71
0 \ БАЗА ЗНАНИЙ
1: МАРКЕР; ПРАВИЛО: ДАЕТ-МОЛОКО (ДАЕТ-МОЛОКО )