|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Describe the process of setting the number of parallel streams in OpenMP.
omp_get_thread_num() - get the thread rank in a parallel region (0 -omp_get_num_threads() -1) The number of threads in a parallel region is determined by the following factors, in order of precedence: 1. Evaluation of the if clause. 2. Setting of the num_threads() clause. 3. Use of the omp_set_num_threads() library function. 4. Setting of the OMP_NUM_THREAD environment variable. 5. Implementation default – usually the number of cores on a node. Threads are numbered from 0 (master thread) to N-1. int nthreads, tid; #pragma omp parallel num_threads(4) private(tid) { The call to find the maximum number of threads that are available to do work is omp_get_max_threads() (from omp.h). This should not be confused with the similarly named omp_get_num_threads(). The 'max' call returns the maximum number of threads that can be put to use in a parallel region. There's a big difference between the two. In a serial region omp_get_num_threads will return 1; in a parallel region it will return the number of threads that are being used.
1.6. Define the race flows and mutexes 11 in C ++. Race condition is a kind of a bug that occurs in multithreaded applications. When two or more threads perform a set of operations in parallel, that access the same memory location. Also, one or more thread out of them modifies the data in that memory location, then this can lead to an unexpected results some times. This is called race condition. Race conditions are usually hard to find and reproduce because they don’t occur every time. They will occur only when relative order of execution of operations by two or more threads leads to an unexpected result. class Wallet{ int mMoney; public: Wallet() :mMoney(0){} int getMoney() { return mMoney; } void addMoney(int money){ for(int i = 0; i < money; ++i){ mMoney++; }}}; Now Let’s create 5 threads and all these threads will share a same object of class Wallet and add 1000 to internal money using it’s addMoney() member function in parallel. So, if initially money in wallet is 0. Then after completion of all thread’s execution money in Wallet should be 5000. But, as all threads are modifying the shared data at same time, it might be possible that in some scenarios money in wallet at end will be much lesser than 5000. A mutex is a lockable object that is designed to signal when critical sections of code need exclusive access, preventing other threads with the same protection from executing concurrently and access the same memory locations. The new concurrency library of C++11 comes with two different classes for managing mutex locks: namely std::lock_guard and std::unique_lock. 1.7. Describe barrier synchronization C ++ 11, OpenMP, MPI Barrier: Each thread waits until all threads arrive. A barrier defines a point in the code where all active threads will stop until all threads have arrived at that point. With this, you can guarantee that certain calculations are finished. For instance, in this code snippet, computation of y can not proceed until another thread has computed its value of x . #pragma omp parallel { int mytid = omp_get_thread_num(); x[mytid] = some_calculation(); y[mytid] = x[mytid]+x[mytid+1]; } This can be guaranteed with a barrier pragma: #pragma omp parallel { int mytid = omp_get_thread_num(); x[mytid] = some_calculation(); #pragma omp barrier y[mytid] = x[mytid]+x[mytid+1]; }
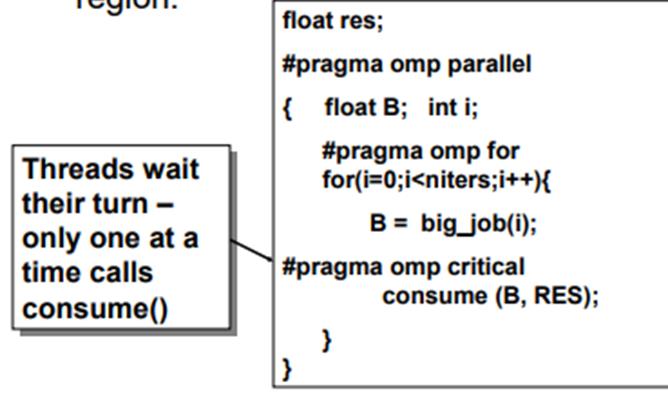
Critically evaluate Synchronization in OpenMP. Only one thread at a time can enter a critical region. It is high level synch. There are two pragmas for critical sections: critical and atomic . The second one is more limited but has performance advantages. The typical application of a critical section is to update a variable: #pragma omp parallel{ int mytid = omp_get_thread_num(); double tmp = some_function(mytid);#pragma omp critical sum += tmp;}
|
Последнее изменение этой страницы: 2019-04-01; Просмотров: 252; Нарушение авторского права страницы