|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Передумови виникнення програмної інженерії.Стр 1 из 13Следующая ⇒
Класичний життєвий цикл Найстарішою парадигмою процесу розробки ПЗ є класичний життєвий цикл (Уїнстон Ройс, 1970). Класична модель ЖЦПЗ застосовується як для розробки програм для індивідуального використання, так і для складних програмних виробів промислового і комерційного призначення. Дуже часто класичний життєвий цикл називають каскадною або водоспадною моделлю, підкреслюючи, що розробка розглядається як послідовність етапів, причому перехід на наступний, ієрархічно нижчий етап відбувається тільки після завершення робіт на поточному етапі. На практиці виконання робіт за такою жорсткою схемою можна реалізувати тільки для досить простих програмних продуктів, вимоги користувача до яких можна на самому початку сформулювати в повному обсязі. У загальному випадку процес розробки є ітеративним (двосторонні стрілки на рисунку). На кожній фазі життєвого циклу можуть вноситися зміни в прийняті рішення, що приводить до необхідності повернення до попередніх етапів. Охарактеризуємо зміст основних етапів. Вважається, що розробка починається на системному рівні і проходить через аналіз, проектування, кодування, тестування і супровід. При цьому моделюються дії стандартного інженерного циклу. Системний аналіз (проектування системи) задає роль кожного елемента в комп’ютерній системі і їх взаємодію. Оскільки ПЗ є лише частиною великої системи, то аналіз починається саме з визначення вимог до всіх системних елементів і призначення підмножини цих вимог програмному „елементу”. Необхідність системного підходу явно проявляється, коли формують інтерфейс ПЗ з іншими елементами (апаратурою, людьми, базами даних). На цьому ж етапі починається вирішення задачі планування проекту ПЗ. У ході планування проекту визначаються обсяг проектних робіт і їх ризик, необхідні трудові затрати, формуються робочі завдання і план-графік робіт. Результатом роботи даного етапу є визначення вимог користувача. Аналіз вимог відноситься до програмного елементу – ПЗ. Уточнюються і деталізуються його функції, характеристики та інтерфейс. Усі визначення документуються в специфікації аналізу. На цьому ж етапі завершується вирішення задачі планування проекту. Результатом роботи є визначення вимог до ПЗ. Проектування полягає у створенні рішень: − Архітектури ПЗ; − Модульної структури ПЗ; − Алгоритмічної структури ПЗ; − Структури даних; − Вхідного і вихідного інтерфейсів (вхідних і вихідних форм даних). Вихідні дані для проектування містяться в специфікації аналізу, тобто в ході проектування виконується трансляція вимог до ПЗ в множину проектних рішень. При вирішенні задач проектування основна увага приділяється якості майбутнього програмного продукту. Результатом проектування є архітектура програмного виробу. Кодування полягає в перекладі результатів проектування на текст мовою програмування. Тестування – виконання програми для виявлення дефектів в функціях, логіці і формі реалізації програмного продукту. Супровід – це внесення змін в працююче ПЗ. Мета внесення змін: − Виправлення помилок; − Адаптація до змін зовнішнього для ПЗ середовища; − Удосконалення ПЗ на вимогу замовника. Супровід ПЗ полягає в повторному застосуванні кожного з попередніх кроків (етапів) життєвого циклу до існуючої програми, але не в розробці нової програми. Найважливішим видом діяльності на всіх етапах життєвого циклу є критичний і всебічний огляд і оцінка матеріалів, підготовлених на відповідній фазі ЖЦПЗ. Схвалення цих матеріалів визначає момент закінчення однієї фази і момент початку наступної фази. Відповідно до структури ЖЦПЗ при плануванні робіт і при контролі за термінами їх виконання є, принаймні, шість подій, які характеризують перехід до наступної фази: − Розгляд і схвалення вимог користувача. − Розгляд і схвалення вимог до програмного виробу. − Розгляд і схвалення архітектурного проекту програмного виробу. − Розгляд і схвалення детального проекту програмного виробу, керівництва користувача, програм і затвердження акту про готовність їх до приймального тестування. − Затвердження акту про попереднє приймання програмного виробу, розгляд і схвалення документа про передачу програмного виробу в експлуатацію. − Затвердження акту про остаточне приймання і передачу в експлуатацію програмного виробу і прийняття документу про результати всіх робіт по створенню ПЗ. Як і будь-яка інженерна система, класичний життєвий цикл має переваги й недоліки. До переваг класичного життєвого циклу можна віднести: − Дає можливість планувати в часі всі етапи проекту; − Впорядковує хід конструювання. Недоліками класичного життєвого циклу є: − Реальні проекти часто вимагають відхилення від стандартної послідовності кроків; − Цикл базується на точному формулюванні вихідних вимог до ПЗ; − Результати проекту доступні замовнику лише після завершення роботи.
Дані Найбільш важливий компонент СУБД для кінцевих користувачів. У системному каталозі містяться: • імена, типи і розміри елементів даних; • імена зв'язків; • обмеження цілісності даних; • імена зареєстрованих користувачів, яким надані деякі права доступу до даних; • використовувані індекси і структури зберігання. Процедури До процедур відносяться інструкції і правила, які повинні враховуватися при проектуванні і використання бази даних. Опис процедур — інструкції про правила виконання: • реєстрація в СУБД; • використання окремого інструменту СУБД або програми; • запуск і зупинка СУБД; • створення резервних копій СУБД; • обробка збоїв апаратного і програмного забезпечення, • зміна структури таблиці, реорганізація бази даних, Користувачі Обслуговування інформаційних потреб користувачів — мета проектування, створення і підтримки бази даних. За способом використання користувачами системи
6. Вимоги до баз даних. 1. Структурованість. Головна вимога - вона повинна бути сформована за єдиним принципом: за організаціями, співробітниками, по галузях. Багатоцільова клієнтська база даних має бути розбита за темами або розділами. 2. Зручність у користуванні. Базою даних буде зручно користуватися, якщо вона складена у вигляді таблиці. Візуальне сприйняття таблиці полегшить роботу. Список клієнтів або організацій-партнерів повинен бути за абеткою. Це заощадить час на пошуки потрібної людини або організації. 3. Максимальна повнота інформації. Інформація, що міститься в базі даних, повинна обов'язково включати такі інформаційні елементи: ПІБ, місце роботи, посада, телефон, факс, електронна пошта, засоби мобільного зв'язку. З базою буде зручно працювати, якщо робити примітки по кожній організації або клієнту. Приміром, зазначати окремими пунктами в таблиці основний напрямок діяльності, загальний настрій стосовно вашої організації, реагування на ваші пропозиції та інше. - 4. Регулярне поновлення. Базу даних необхідно час від часу поновлювати. Люди змінюють місце роботи й посади, у них може змінитися телефон або з'явитися електронна адреса, якої раніше не було. Оновлення баз даних рекоменовано провадити у півтора-два місяця. 5. Регулярне поповнення. На відміну від обновлення баз даних, конкретних нормативів щодо цього процесу просто не існує. У залежності від обставин до бази даних можна вносити нові записи практично щодня. Слід лише зберігати її початкову структуру, або й розробляти нову, якщо цього вимагатимуть нововнесені доповнення.
Системи управління базами даних (СУБД).
Система управління базами даних - програмне забезпечення, за допомогою якого користувачі можуть визначати, створювати і підтримувати базу даних, а також здійснювати до неї контрольований доступ. Альтернативне визначення: Система управління базами даних — спеціалізована програма (частіше комплекс програм), яка призначена для організації і ведення бази даних. Реляційна модель даних В деяких випадках при ієрархічному і мережному представлені зростання бази даних може привести до порушення логічної організації даних. Такі ситуації виникають при появі нових користувачів, нових застосувань та видів запитів, при обліку інших логічних зв'язків між елементами даних. Недоліки ієрархічної і мережної моделей привели до появи нової, реляційної моделі даних, створеної Коддом у 1970 році .Реляційна модель була спробою спростити структуру бази даних. У ній були відсутні явні покажчики на предків і нащадків, а всі дані були представлені у виді простих таблиць, розбитих на рядки і стовпці. Реляційною називається база даних, у якій усі дані, доступні користувачу, організовані у виді таблиць, а всі операції над даними зводяться до операцій над цими таблицями. Для представлення реляційних баз даних розроблена формальна теорія баз даних, теоретичну основу якої складає алгебра та математична логіка. У реляційної базі даних інформація організована у виді таблиць, розділених на рядки і стовпці, на перетині яких містяться значення даних. У кожної таблиці є унікальне ім'я, що описує її вміст. Масив значень, що можуть міститися в стовпці, називається доменом цього стовпця. Двохвимірні таблиць в математиці отримали назву відношення . У кожного стовпця в таблиці є своє ім'я, що звичайно служить заголовком стовпця. Усі стовпці в одній таблиці повинні мати унікальні імена, однак дозволяється привласнювати однакові імена стовпцям, розташованим в різних таблицях. Стовпці таблиці упорядковані зліва направо, і їхній порядок визначається при формуванні таблиці. У будь-якій таблиці завжди є як мінімум один стовпець. Як правило, не вказується максимально допустиме число стовпців у таблиці, однак майже у всіх комерційних СКБД ця межа існує і , як правило, складає приблизно 255 стовпців. На відміну від стовпців, рядки таблиці не мають визначеного порядку. Це значить, що якщо послідовно виконати два однакових запити для відображення вмісту таблиці, то немає гарантії, що обидва рази рядка будуть перераховані в тому самому порядку. Рядки таблиці утворюють данні різного формату і різного типу, тобто можна стверджувати, що рядки таблиці є кортежами. У таблиці може міститися будь-як кількість рядків. Цілком припустиме існування таблиці з нульовою кількістю рядків. Така таблиця називається порожньою. Порожня таблиця зберігає структуру, визначену її стовпцями, просто в ній не містяться дані. Стандарти реляційних баз даних не накладають обмежень на кількість рядків у таблиці, і в багатьох СКБД розмір таблиць обмежений лише вільним дисковим простором комп'ютера. Як правило, в сучасних реляційних БД допускається збереження символьних, числових даних, бітових рядків, спеціалізованих числових даних (таких як "гроші"), а також спеціальних "темпоральных" даних (дата, час, часовий інтервал). Найменша одиниця даних реляційної моделі - це окреме атомарне (неподільне) для даної моделі значення даних. Так, в одній предметній області прізвище, ім'я і по-батькові можуть розглядатися як єдине значення, а в інший - як три різноманітних значення. Опис кожного відношення складається з імені відношення (підмет), за яким в круглих дужках перечисляться список атрибутів(присудок). Цей опис називають інтенсіоналом або схемою відношення. Під описом слідує деяке заповнення кортежів відношення, яке називають екстенсіоналом. Відношення називаються еквівалентними, якщо вони відрізняються тільки порядком чергування атрибутів. Кодд у 1985 році сформулював 12 правил, яким повинна задовольняти будь-як база даних, що претендує на тип реляційної. З того часу дванадцять правил Кодда вважаються визначенням реляційної СУБД. Дванадцять правил Кодда, яким повинна відповідати реляційна СКБД. 1. Правило інформації. Вся інформація в базі даних повинна бути надана винятково на логічному рівні і тільки одним способом - у виді значень, що містяться в таблицях. 2. Правило гарантованого доступу. Логічний доступ до всіх і кожного елементу даних (атомарному значенню) у реляційній базіданих повинний забезпечуватися шляхом використання комбінації імені таблиці, первинного ключа та імені стовпця. 3. Правило підтримки недійсних значень. У реляційній базі даних повинна бути реалізована підтримка недійсних значень, що відрізняються від рядка символів нульової довжини, рядка символів пробілів чи нуля будь-якого іншого числа і використовуватися для представлення відсутніх даних незалежно від типу цих даних. 4. Правило динамічного каталогу, заснованого на реляційній моделі. Опис бази даних на логічному рівні необхідно представити в тому ж виді, що й основні дані, щоб користувачі, які володіють відповідними правами, могли працювати з ним за допомогою тієї ж реляційної мови, яку вони застосовують для роботи з основними даними. 5.Правило вичерпної підмови даних. Реляційна система може підтримувати різні мови і режими взаємодії з користувачем (наприклад, режим питань і відповідей). Однак повинна існувати принаймні одна мова, оператори якої підтримують наступні елементи: визначення даних; визначення представлень; обробку даних (інтерактивну і програмну); умови цілісності; ідентифікацію прав доступу; границі транзакцій (початок, завершення і скасування). 6. Правило відновлення представлень. Усі представлення, які теоретично можна обновити, повинні бути доступні для відновлення. 7. Правило додавання, відновлення і вилучення. Можливість працювати з відношенням як з одним операндом повинна існувати не тільки при читанні даних, але і при додаванні, відновленні вилученні даних. 8. Правило незалежності фізи данихчних. Прикладні програми й утиліти для роботи з даними повинні на логічному рівні залишатися недоторканими при будь-яких змінах методів збереження даних чи методів доступу до них. 9. Правило незалежності логічних даних. Прикладні програми й утиліти для роботи з даними повинні на логічному рівні залишатися недоторканими при внесенні в базові таблиці будь-яких змін, які теоретично дозволяють зберегти недоторканими дані, що містяться в цих таблицях. 10. Правило незалежностіумов цілісності. Повинна існувати можливість визначати умови цілісності, специфічні для конкретної реляційної бази даних, на підмові реляційної бази даних і зберігати їх у каталозі, а не в прикладній програмі. 11. Правило незалежності поширення. Реляційна СКБД не повинна залежати від потреб конкретного клієнта. 12. Правило одиничності.
Інші мови Незважаючи на те що реляційне числення є досить складним з точки зору освоєння та використання, проте його непроцедурна природа вважається досить перспективною і це стимулює пошук інших, більш простих у використанні непроцедурного методів. Подібні дослідження викликали появу двох інших категорій реляційних мовами: трансформаційних і графічних. Трансформаційні мови є класом непроцедурних мов, які використовують відношення для перетворення вихідних даних до необхідного виду. Ці мови надають прості в роботі структури для формулювання вимог до результатів наявними засобами. Прикладами трансформаційних мов є SQUARE, SEQUEL і його версією, а також мова SQL. Графічні мови надають користувачеві схему або інше графічне відображення структури відношень. Користувач створює якийсь зразок бажаного результату, і система повертає затребувані дані в зазначеному форматі. Прикладом подібного мови є мова QBE (Query-By-Example). Ще однією категорією мов є мови четвертого покоління (Fourth-Generation Language - 4GL), які дозволяють створювати повністю готове і відповідне вимогам замовника програму за допомогою обмеженого набору команд і в той же час надають дружнє по відношенню до користувачасередовище розробки, найчастіше побудовану на використанні команд меню. У деяких системах використовуються так само певні різновиди природної мови, тобто обмеженою версією звичайної англійської мови, яку іноді називають мовою п'ятого покоління (Fifth-Generation Language - 5GL). Однак розробки проектів подібних ов здебільшого все ще знаходяться на ранній стадії розвитку
Моделлю даних. Умови і обмеження, які накладаються на відношення реляційних баз даних на табличному рівні представлення, можна сформулювати наступним чином: не може бути однакових первинних ключів, тобто всі рядки (записи) повинні бути унікальними; всі рядки повинні мати однакову типову структуру; імена стовпців в таблиці повинні бути різними, а значення стовпців повинні бути однотиповими; значення стовпців повинні бути атомарними, тобто не можуть бути компонентами інших відношень; повинна зберігатися цілісність для зовнішніх ключів; порядок розміщення рядків у таблиці неістотний - він впливає лише на швидкість доступу до потрібного рядка. Основні вимоги до створення реляційних баз даних:
Нормалізація даних є вирішальною умовою нормально функціонування вашої реляційної бази даних, є такі основні форми нормалізації: 1. Перша форма нормалізації. Таблиця знаходиться в першій нормальній формі, якщо значення всіх її полів атомарні, і в ній відсутні групи полів, що повторюються. Атомарність це коли кожен атрибут має лише одне значення, а не множину значень. 2. Друга форма номалізації. Таблиця знаходиться в другій нормальній формі, якщо вона задовольняє умовам першої нормальної форми, і дані, що повторно з'являються в декількох колонках виносяться в окремі таблиці. 3. Третя форма нормалізації. Таблиця знаходиться в третій нормальній формі, якщо вона задовольняє умовам другої нормальної форми і жодне з неключових полів таблиці не ідентифікується за допомогою іншого неключового поля.
Мета і задачі проектування В даний час ключова роль в досягненні успіху більшості комп'ютеризованих систем належить не використовуваному устаткуванню, а програмному забезпеченню. Проте існуючі історичні свідчення про розробку програмного забезпечення систем не виробляють такого глибокого враження, як хронологічні огляди стрімкого прогресу в області апаратних засобів обчислювальної техніки. В останні десятиліття прикладні програми пройшли шлях від маленьких і порівняно простих додатків з декількох рядків коду до дуже великих і складних програм, що складаються з декількох мільйонів рядків. Багато з цих додатків вимагали постійного супроводу, включаючи виправлення виявлених помилок, реалізацію нових вимог користувачів, а також перенесення програмного забезпечення на нові або модернізовані обчислювальні платформи. Зусилля та ресурси, що витрачаються на супровід програмного забезпечення, зростали загрозливими темпами. В результаті розробка та реалізація багатьох великих проектів затягувалася, їх вартість перевищувала заплановану, а остаточний продукт виходив ненадійним, складним в супроводі і володів недостатньою продуктивністю. Все це призвело до ситуації, яка відома під назвою "криза програмного забезпечення". Хоча перші згадки про кризу були зроблені ще наприкінці 1960-х років, навіть через більш ніж 50 років його все ще не вдалося подолати. В даний час багато авторів навіть називають цю кризу "депресією програмного забезпечення". У Великобританії спеціальна Група з вивчення організаційних аспектів інформатики (Organizational Aspects Special Interest Group - OASIG) досліджувала цю проблему і сформулювала наступні висновки: • Приблизно 80-90% комп'ютеризованих систем не мають необхідної продуктивністі. • При розробці близько 80% систем були перевищені встановлені для цього часові і бюджетні рамки. • Розробка близько 40% систем закінчилася невдало або була припинена до завершення роботи. • Менш ніж 40% систем передбачали професійне навчання та підвищення кваліфікації користувачів у всьому необхідному обсязі. • Гармонійно інтегрувати інтереси бізнесу і використовуваної технології вдалося не більш ніж в 25% систем. • Тільки 10-20% систем відповідають всім критеріям досягнення успіху. Невдачі при створенні програмного забезпечення були викликані наступними причинами: • відсутністю повної специфікації усіх вимог; • відсутністю прийнятної методології розробки; • недостатнім ступенем поділу загального глобального проекту на окремі компоненти, які піддаються ефективному контролю та управління. Для вирішення цих проблем був запропонований структурний підхід до розробки програмного забезпечення, званий життєвим циклом інформаційних систем (Information Systems Lifecycle), або життєвим циклом розробки програмного забезпечення (Software Development LifeCycle - SDLC). Концептуальне проектування. Концептуальне проектування бази даних - це процес створення моделі використовуваної на підприємстві інформації, що не залежить від будь-яких фізичних аспектів її подання. Перший етап процесу проектування бази даних називається концептуальним проектуванням бази даних. Він полягає у створенні концептуальної моделі даних для аналізованої частини підприємства. Ця модель даних створюється на основі інформації, записаної в специфікаціях вимог користувачів. Концептуальне проектування бази даних абсолютно не залежить від таких подробиць її реалізації, як тип обраної цільової СУБД, набір створюваних прикладних програм, які використовуються мови програмування, тип обраної обчислювальної платформи, а також від будь-яких інших особливостей фізичної реалізації. При розробці концептуальна модель даних постійно піддається тестуванню та перевірці на відповідність вимогам користувачів. Створена концептуальна модель даних підприємства є джерелом інформації для етапу логічного проектування бази даних. 17.Модель "сутність-зв'язок". В даний час існує декілька сотень різних реляційних СУБД хоча в багатьох з них визначення реляційної моделі трактується дуже широко. Прикладами реляційних СУБД для персональних комп'ютерів є Access і FoxPro фірми Microsoft і інші. Реляційні СУБД відносяться до СУБД другого покоління. Однак реляційна модель має також деякі недоліки - зокрема, обмеженими можливостями моделювання. Для вирішення цієї проблеми був виконаний великий обсяг дослідницької роботи. У 1976 році Чен (Chen) запропонував модель "сутність-зв'язок" (Entity-Relationship model - ER-модель), яка в даний час стала найпоширенішою технологією проектування баз даних. Модель "сутність-зв'язок" ґрунтується на якійсь важливій семантичній інформації про реальний світ і призначена для логічного представлення даних. Вона визначає значення даних в контексті їх взаємозв'язку з іншими даними. Важливим є той факт, що з моделі "сутність-зв'язок" можуть бути породжені всі існуючі моделі даних (ієрархічна, мережева, реляційна, об'єктна), тому вона є найбільш загальною. Будь-який фрагмент наочної області може бути представлений як безліч сутностей, між якими існує безліч зв'язків. Топто, ER-модепювання являє сооою низхідний підхід до проектування БД, який починається з визначення найбільш важливих даних, які називаються сутностями (entities), і зв'язків (relationships) між даними, які повинні бути представлені в моделі. Потім в модель заноситься інформація про властивості сутностей і зв'язків називається атрибутами (attributes), а також всі обмеження, які відносяться до сутностей, зв'язків і атрибутів. ER-модепь дає графічне представлення логічних об'єктів і їх відношень в структурі БД. Підхід П.Чена дозволив концептуальне моделювання перевести в практичну площину проектування БД. У подальшому діаграми Чена набули розвитку у багатьох роботах з ER- моделювання. До них належать такі моделі: - "пташина папка", розроблена КМ. Бахманом; - IDEF1X, розроблена Т.Ремеєм; - на основі UML; - модель Баркера і багато інших моделей.
Логічне проектування. Логічне проектування бази даних - це процес створення моделі використовуваної на підприємстві інформації на основі обраної моделі організації даних, але без врахування типу цільової СУБД і інших фізичних аспектів реалізації. Другий етап проектування бази даних називається логічним проектуванням бази даних. Його мета полягає у створенні логічної моделі даних для досліджуваної частини підприємства. Концептуальна модель даних, створена на попередньому етапі, уточнюється і перетвориться в логічну модель даних. Логічна модель даних враховує особливості обраної моделі організації даних в цільової СУБД (наприклад, реляційна модель). Якщо концептуальна модель даних не залежить від будь-яких фізичних аспектів реалізації, то логічна модель даних створюється на основі обраної моделі організації даних цільової СУБД. Інакше кажучи, на цьому етапі вже має бути відомо, яка СУБД буде використовуватися в якості цільової - реляційна, мережева, ієрархічна чи об'єктно-орієнтована. Однак на цьому етапі ігноруються всі інші характеристики вибраної СУБД, наприклад, будь-які особливості фізичної організації її структур зберігання даних і побудови індексів. У процесі розробки логічна модель даних постійно тестується і перевіряється на відповідність вимогам користувачів. Для перевірки правильності логічної моделі даних використовується метод нормалізації. Нормалізація гарантує, що відношення, виведені з існуючої моделі даних, не будуть мати надмірності даних, здатної викликати порушення в процесі оновлення даних після їх фізичної реалізації. Крім усього іншого, логічна модель даних повинна забезпечувати підтримку всіх необхідних користувачам транзакцій. Індексація в базах даних. Індекс ( англ. index ) - об'єкт бази даних, який створюється з метою підвищення продуктивності пошуку даних. Таблиці в базі даних можуть мати велику кількість рядків, які зберігаються в довільному порядку, і їх пошук за заданим критерієм шляхом послідовного перегляду таблиці рядок за рядком може займати багато часу. Індекс формується зі значень одного або декількох стовпців таблиці і покажчиків на відповідні рядки таблиці і, таким чином, дозволяє шукати рядки, що задовольняють критерію пошуку. Прискорення роботи з використанням індексів досягається в першу чергу за рахунок того, що індекс має структуру, оптимізовану під пошук - наприклад, збалансованого дерева. Деякі СУБД розширюють можливості індексів введенням можливості створення індексів по стовпцях уявлень або індексів за виразами. Наприклад, індекс може бути створений за висловом upper(last_name) і відповідно буде зберігати посилання, ключем до яких буде значення поля last_name у верхньому регістрі. Крім того, індекси можуть бути оголошені як унікальні і як не унікальні. Унікальний індекс реалізує обмеження цілісності на таблиці, виключаючи можливість вставки повторюваних значень. 1. Архітектура Існує два типи індексів: кластерні і некластерние. При наявності кластерного індексу рядки таблиці впорядковані за значенням ключа цього індексу. Некластерного індекс, створений для такої таблиці, містить тільки покажчики на записи таблиці. Кластерний індекс може бути тільки одним для кожної таблиці, але кожна таблиця може мати декілька різних некластерного індексів, кожний з яких визначає свій власний порядок проходження записів.
Для оптимальної продуктивності запитів індекси зазвичай створюються на тих стовпцях таблиці, які часто використовуються в запитах. Для однієї таблиці може бути створено кілька індексів. Однак збільшення числа індексів уповільнює операції додавання, оновлення, видалення рядків таблиці, оскільки при цьому доводиться оновлювати самі індекси. Крім того, індекси займають додатковий обсяг пам'яті, тому перед створенням індексу слід переконатися, що планований виграш в продуктивності запитів перевищить додаткову витрату ресурсів комп'ютера на супроводження індексу.
Рідкісний індекс ( англ. sparse index ) В базах даних - це файл з послідовністю пар ключів і покажчиків. Кожен ключ в рідкісному індексі, на відміну від щільного індексу, асоціюється з певним дороговказом на блок в сортувати файли даних. Ідея використання індексів прийшла через те, що сучасні бази даних занадто масивні і не поміщаються в основну пам'ять. Ми зазвичай ділимо дані на блоки і розміщуємо дані в пам'яті поблочно. Проте пошук запису в БД може зайняти багато часу. З іншого боку, файл індексів або блок індексів набагато менше блоку даних і може поміститися в буфері основної пам'яті що збільшує швидкість пошуку запису. Оскільки ключі відсортовані, можна скористатися бінарним пошуком. У кластерних індексах з дубльованими ключами рідкісний індекс вказує на найменший ключ в кожному блоці. Привілеї в базах даних. Привілеї – це права користувача на проведення тих чи інших дій над певним об'єктом бази даних. Для введення елементів системи безпеки застосовується інструкція GRANT, за допомогою якої тим чи іншим користувачам надаються певні привілеї на використання тих чи інших об'єктів бази даних. В інструкції GRANT задається комбінація ідентифікатора користувача, об'єкта і привілеїв. Надані привілеї можна пізніше анулювати за допомогою інструкції REVOKE. Кожному користувачеві реляційної бази даних присвоюється ідентифікатор – коротке ім'я, що однозначно визначає користувача для СУБД. Ці ідентифікатори є основою системи безпеки. Кожна інструкція SQL виконується в СУБД від імені конкретного користувача. Від його ідентифікатора залежить, чи буде дозволено або заборонено виконання інструкції. У більшості комерційних реляційних СУБД код користувача створюється для кожного сеансу зв'язку з базою даних. В інтерактивному режимі сеанс починається, коли користувач запускає інтерактивну програму формування запитів, і продовжується до тих пір, поки користувач не вийде з програми. Пароль служить для підтвердження того, що користувач дійсно має право працювати під введеним ідентифікатором. Ідентифікатори і паролі застосовуються в більшості реляційних СУБД, однак спосіб, яким користувач вводить свій ідентифікатор та пароль, змінюється залежно від СУБД. Наприклад, коли СУБД Oracle працює з інтерактивним SQL-модулем, який називається SQLPLUS, необхідно ввести ім'я користувача і відповідний пароль у командному рядку: SQLPLUS ідентифікатор/пароль. У багатьох інших СУБД, включаючи Informix, у ролі ідентифікаторів користувачів використовуються імена користувачів, що реєструються в операційній системі мейнфрейму. У великих виробничих базах даних часто є групи користувачів зі схожими завданнями. У межах кожної групи всі користувачі працюють з однаковими даними і повинні мати ідентичні привілеї. Згідно стандарту ANSI/ISO, з групами користувачів можна вчинити одним з двох способів: 1. Кожному члену групи можна присвоїти один і той же код користувача. 2. Усім членам групи можна присвоїти різні ідентифікатори користувача. Ті дії, які користувач має право виконувати над об'єктом бази даних, називаються привілеями користувача по відношенню до даного об'єкту. У стандарті SQL для таблиць визначені чотири привілеї: 1. Привілей SELECT дозволяє отримувати дані з таблиці. 2. Привілей INSERT дозволяє додавати нові записи в таблицю. 3. Привілей DELETE дозволяє видаляти записи з таблиці. 4. Привілей UPDATE дозволяє модифікувати записи у таблиці або псевдотаблиці. Коли користувач створюєте таблицю за допомогою інструкції CREATE TABLE, він стаєте її власником і отримуєте всі привілеї для цієї таблиці (SELECT, INSERT, DELETE, UPDATE та інші привілеї, які є в СУБД). Інші користувачі спочатку не мають ніяких привілеїв на щойно створену таблицю. Щоб вони отримали доступ до таблиці, власник повинен явно надати їм відповідні привілеї за допомогою інструкції GRANT [5]. У багатьох комерційних СУБД крім привілеїв SELECT, INSERT, DELETE і UPDATE, встановлених стандартом SQL, по відношенню до таблиць можуть бути видані додаткові привілеї. Наприклад, в Oracle та Informix передбачені привілеї ALTER та INDEX. Маючи привілей ALTER для якої-небудь таблиці, користувач може за допомогою інструкції ALTER TABLE модифікувати структуру даної таблиці; маючи привілей INDEX, користувач може за допомогою інструкції CREATE INDEX створити індекс для таблиці За допомогою механізму прав на рівні таблиці можна управляти доступом різних користувачів на рівні таблиці цілком або на рівні полів у таблиці. Але іноді виникає ситуація, коли необхідно управляти доступом до окремих записів у таблиці. Наприклад, в деякій фірмі треба забезпечити такий доступ до інформації про співробітників, щоб кожен користувач міг бачити записи тільки про тих співробітників, які працюють в одному з ним відділі. Як вирішити це завдання? Якщо користуватися правами на рівні таблиць, то буде потрібно створювати стільки таблиць з однаковою структурою, скільки відділів у фірмі. Очевидно, це переобтяжить структуру бази даних, зробить її негнучкої і зробить важчою розробку прикладних програм. У SQL дана проблема може бути вирішена за допомогою VIEW – псевдотаблиці. Ієрархічна модель даних. Ієрархічна модель даних Деревоподібна (ієрархічна) структура, або дерево, - це зв'язний неорієнтований граф, що не містить циклів, тобто петель з замкнутих шляхів.
Як правило, при роботі з деревом виділяють яку-небудь конкретну верхівку (початок), визначають її як коріння дерева і розглядають особливо - в цю верхівку не заходить жодне ребро. В цьому випадку дерево стає орієнтованим. Орієнтація на кореневому дереві визначається або від коріння, або до коріння. Кореневе дерево можна визначити наступним чином: 1) є єдиний особливий вузол , який називається корінням, в який не заходить жодне ребро; 2) в всі інші вузли заходить тільки одне ребро, а виходить довільна (0, 1, 2,..., п) кількість ребер; 3) не існує циклів. В програмуванні використовується інше визначення дерева, яке дозволяє розглядати дерево як рекурсивну структуру. Рекурсивне дерево визначається як кінцева множина Т, яка складається з одного або більш вузлів, таких, що: 1) існує один спеціально виділений вузол, який називається корінням дерева; 2) інші вузли розбиті на m>0 неперетинаючихся підмножини T1,T2, …, Tm, кожна з яких в свою чергу є деревом. T1,T2, …, Tm, називаються піддеревами. З визначення слідує, що будь-який вузол дерева є корінням деякого піддерева, що міститься в повному дереві. Число піддерев вузла називають ступенем вузла. Вузол називається кінцевим, якщо він має нульову степінь. Інколи кінцеві вузли називають листками, а ребра -гілками . Кожний вузол, крім кореневого , зв'язаний з одним вузлом на більш високому рівні ієрархії і називається вихідним. Кожний вузол може бути зв'язаний з одним або декількома вузлами на більш низькому рівні і називається породженим. Якщо кожний вузол має однакову кількість гілок, причому процес включення нових гілок іде зверху вниз , а на кожному рівні дерева - зліва направо, то таке дерево називається збалансованим. Для збалансованих дерев фізична організація даних суттєво спрощується. До особливої категорії дерев відносять двійкове (бінарне) дерево. Це дерево має не більш як дві гілки, які виходять з одного вузла. Двійкові дерева можуть бути як збалансованими, так і незбалансованими. . Прикладом простого ієрархічного представлення може служити адміністративна структура вищого учбового закладу: університет - відділення - факультет - група (студентська).
Пошук даних у ієрархічній структурі виконується завжди по одній із гілок, починаючи з кореневого елемента, тобто повинний бути зазначений повний шлях руху по гілкам. Так, для пошуку і вибірки одного або декількох екземплярів запису типу СТУДЕНТ необхідно вказати кореневий елемент ФАКУЛЬТЕТ і елементи КУРС, ГРУПА. У операційній системі для пошуку файла використовується такий же принцип - вказуються послідовно ім'я диска, ім'я каталогу, ім'я підкаталогів, ім'я файла.
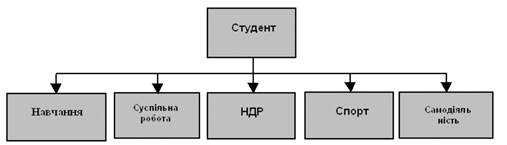
На рисунку приведений приклад типу набору, представленого у виді діаграми Бахмана. Діаграму назвали по імені вченого, який вперше їх застосував для опису відношень між даними при розробці СУБД IDS. На такій діаграмі кожний прямокутник представляє собою тип запису, а стрілка - відношення "один до багатьох" між типами запису.. У прикладі тип запису СТУДЕНТ є записом-власником, а типи записів НАВЧАННЯ, СУСПІЛЬНА РАБОТА, НДР, СПОРТ і САМОДІЯЛЬНІСТЬ -записами - членами. Тип набору названий ім'ям СУОНСС по перших літерах імен усіх типів запису, що беруть участь у наборі (наборові можна було надати і будь-яке інше ім'я). У цілому приведений тип набору призначений для того, щоб відобразити зв'язок між загальними даними про студента, що знаходяться в типі запису СТУДЕНТ, і даними, що характеризують різні сторони діяльності студента у вузі. При традиційному підході всі ці данні можна було б помістити в один загальний запис. Оскільки не кожний студент бере участь, наприклад, у спорті або самодіяльності, то прийшлося б вибрати запис з змінною довжиною або запис із фіксованою довжиною, причому в останньому випадку частина пам'яті витрачалася б даремно. Ієрархічна структура усуває виникаючі при цьому складнощі, тому що в будь-якому екземплярі типу набору з записом-власником можна асоціювати стільки записів-членів, скільки необхідно для конкретного екземпляра. Повна схема бази даних формується в загальному випадку з множини різних типів набору і типів запису. Ієрархічна деревоподібна структура, що орієнтована від коріння, задовольняє наступним умовам: 1) ієрархія завжди починається з кореневого вузла; 2) на першому рівні може знаходитися тільки один вузол- кореневий; 3) на нижніх рівнях знаходяться породжені (залежні) вузли; 4) кожний породжений вузол, який знаходиться на рівні і , зв'язаний тільки з одним вхідним вузлом , який знаходиться на рівні (і-1) ієрархії дерева; 5) кожний вхідний вузол може мати один або декілька породжених вузлів, які називаються подібними; 6) доступ до кожного породженого вузла виконується через йому відповідний вхідний вузол; 7) існує єдиний ієрархічний шлях доступу до будь-якого вузла, починаючи від кореневого вузла дерева. Прикладами типових операторів маніпулювання ієрархічно- організованими даними можуть бути наступні: · Знайти задане дерево БД ; · Перейти від одного дерева до іншого; · Перейти від одного запису до іншого в середині дерева ; · Перейти від одного запису до іншого в порядку обходу ієрархії; · Уставити новий запис у зазначену позицію; · Видалити поточний запис. Перевагами деревовидної моделі є наявність функціональних систем керування базами даних , які підтримують дану модель , простота сприйняття користувачами принципу ієрархії, забезпечення деякого рівня незалежності даних, простота оцінки операційних характеристик системи завдяки апріорно заданим взаємозв'язкам. До недоліків ієрархічних структур відносять : - надлишковість зберігання інформації, так як ієрархічні структури не підтримують взаємозв'язки Б:Б; - строгу ієрархічну впорядоченість , яка ускладнює процедури включення та вилучення записів; - вилучення вихідних вузлів призводить до вилучення відповідних їм породжених , що вимагає особливої обережності; - ускладнюється доступ до даних , які лежать на більш низьких рівнях ієрархії, так як кореневий вузол завжди є головним, а доступ до любого породженого вузла може здійснюватись через вихідний. В ієрархічні базі даних проблеми, пов'язані з операціями включення нових записів і вилучення старих, а також проблеми часткового дублювання інформації виникають в результаті того, що відношення БАГАТО-ДО-БАГАТЬОХ безпосередньо не підтримується, що і є основним недоліком ієрархічних моделей. Мережева модель даних. Більш широкі можливості для користувача забезпечує мережна модельбази даних, яка є узагальненням ієрархічної моделі і дозволяє відображативідношення між типами записів виду "багато до багатьох". У мережній моделікожний тип запису може бути членом більш ніж одного типу набору. Врезультаті можна сформувати модель бази даних із довільними зв'язками міжрізними типами запису. Крім того, окремі типи записів можна не включати ні всякі типи набору, що забезпечує додаткові можливості для ряду задач обробки даних в СКБД. Відзначимо, що СКБД, в основі якої використовується мережна модель бази даних, називається СУБД мережного типу. У 1971 році був опублікований офіційний стандарт мережних баз даних, який відомий як модель CODASYL. Розділення мережних структур на два типи (складні та прості) необхідно хоча б тому, що структури, побудовані з використанням зв'язку БАГАТО-ДО- БАГАТЬОХ, вимагають для їх реалізації використання більш складних методів. Крім того, деякі системи керування базами даних можуть підтримувати прості мережні структури, але не можуть підтримувати складні. Наприклад, СКБД DMS, DBMS, СЕКТОР дозволяють описувати прості мережні структури. Реалізація складних мережних структур можлива і в цих системах керування базами даних шляхом приведення до більш простого вигляду. Любу мережну структуру можливо привести до більш простого вигляду, якщо ввести надлишковість. Якщо надлишковість, яка при цьому виникає, є допустимою, то такий шлях дозволяє підтримувати мережні структури даних СКБД, які орієнтовані на ієрархічну організацію даних. Прикладами типових операторів маніпулювання мережними даними можуть бути наступні: · Знайти конкретний запис у наборі однотипних записів ; · Перейти від предка до першого нащадка по деякому зв'язку ; · Перейти до наступного нащадка в деякому зв'язку ; · Перейти від нащадка до предка по деякому зв'язку ; · Створити новий запис; · Знищити запис; · Модифікувати запис; · Включити в зв'язок; · Виключити зі зв'язку; · Переставити в інший зв'язок і т.д. До переваг мережних структур слід віднести наявність СКБД, які успішно реалізують таку організацію, а також простоту реалізації зв'язків "багато до багатьом", які часто зустрічаються в реальному світі. Недолік таких структур полягає в складності по відношенню до ієрархічних структур. Прикладному програмісту часто необхідно знати логічну структуру бази даних. При реорганізації бази даних не виключається в ряді випадків втрата незалежності даних. Представлення даних ієрархічними та мережними структурами, в загальному випадку, перешкоджає внесенню багатьох змін, пов'язаних з розширенням бази даних. Це може призвести до порушення логічного представлення даних, схем, підсхем, а, отже, до зміни в прикладних програмах. Передумови виникнення програмної інженерії. В кінці 60-х – на початку 70-х років з’явилися перші ознаки кризи в області програмування – колосальні успіхи в галузі розвитку засобів обчислювальної техніки прийшли в протиріччя з низькою продуктивністю праці програмістів. У зв’язку з ускладненням програмних систем стало очевидним, що їх важко проектувати, кодувати, тестувати і особливо важко розуміти, коли виникає необхідність їх модифікації в процесі супроводу. З’явилася життєва потреба в створенні технології розробки програмних засобів і інженерних методів їх проектування для істотного поліпшення продуктивності праці розробників.Кардинальні зміни в галузі створення програмного забезпечення (ПЗ) були обумовлені і швидким зростанням ринкового програмного продукту – тієї частини розроблених програм, яка отримувалася користувачем у вигляді готових до експлуатації пакетів програм різного призначення. Не дивлячись на те, що значна частина створюваного програмного забезпечення не доводиться до комерційного використання, тобто не виходить за межі фірми-розробника,вона представляє велику цінність для подальших розробок і для накопичення досвіду і знань. Вже до початку 80-х років тільки в США було створено ПЗ на сотні мільярдів доларів. Впровадження комп’ютерних технологій в різноманітні сфери людської діяльності привело до виникнення і бурхливого розвитку нової галузі суспільного виробництва – промисловості обробки даних, сумарний обсяг продажів продукції в якій швидко залишив позаду всі традиційні галузі промисловості. Перерозподіл кількості працюючих у сфері матеріального виробництва привів до того, що в найрозвиненіших країнах більше половини працівників виявилися зайнятою обробкою інформації. В США в 90-ті роки цей показник досяг 80%. Основа даної галузі в першу чергу є технічне і програмне забезпечення систем обробки даних. При цьому самою наукомісткою залишається програмна продукція. Природно, що і в наукових дослідженнях, і в практичній діяльності постійно робилися спроби перевести виготовлення програмної продукції на інженерну основу. Так, в 70-х роках виникла нова інженерна дисципліна – програмотехніка, або інженерія ПЗ (Software Engineering). Становленню програмотехніки сприяло розширення ринку ПЗ, поява могутніх фірм, зайнятих виробництвом виключно цієї продукції, і зростання кількості користувачів програмних виробів. Програмна інженерія вивчає теорії, методи й засоби професійної розробки ПЗ. Програмна інженерія – це інженерна дисципліна, яка зв’язана зі всіма аспектами виробництва ПЗ від початкових стадій створення специфікації до підтримки системи після здачі в експлуатацію. У цьому визначенні є дві важливі частини: − „Інженерна дисципліна”. Інженери добиваються результатів. Вони застосовують теорії, методи й засоби, які допустимі для вирішення даної задачі, але вони застосовують їх вибірково і завжди пробують знайти рішення, навіть у тих випадках, коли теорій чи методів, які відповідають даній задачі, ще не існує. Крім того, інженери повинні розуміти значимість часових, фінансових і організаційних обмежень. − „Усі аспекти виробництва програмного забезпечення”. Програмна інженерія займається не тільки технічними питаннями виробництва ПЗ, але й управлінням програмними проектами, а також розробкою засобів, методів і теорій для підтримки процесу виробництва ПЗ. Програмні інженери застосовують систематичні й організовані підходи до роботи для досягнення максимальної ефективності й якості программного забезпечення. Загальноприйнята думка, що неправильно вибраний підхід повинен негативно вплинути на якість і термін здачі системи. Але підхід потрібно вибирати з розумом – в багатьох випадках неформальні, „легкі” процеси можуть виявитися значно ефективнішими. Між програмною інженерією і комп’ютерними науками в цілому існує різниця. Комп’ютерні науки займаються теорією й методами комп’ютерних і програмних систем, в той час, як програмна інженерія займається практичними проблемами створення програмного забезпечення. Природно, інженер-програміст зобов’язаний в деякому обсязі знати інформатику, проте обсяг теоретичних знань у різних спеціалістів сильно відрізняється і може бути дуже невисоким, що тим не менше, не заважає їм вирішувати деякі задачі. В ідеалі, вся програмна інженерія повинна підтримуватися якимось теоріями інформатики, але на практиці все значно складніше. Інженери часто застосовують перші методи, які попадуться, а елегантні теорії інформатики не завжди можна застосувати до реальних великих систем. Програмна інженерія відрізняється від системної інженерії. Системна інженерія, а точніше – комп’ютерна системна інженерія, займається всіма аспектами створення й еволюції комплексних систем, в яких програмне забезпечення відіграє значну роль. Таким чином, програмна інженерія є частиною системної інженерії, поряд зі створенням апаратних платформ, створенням архітектури, системною інтеграцією і т.п. У системній інженерії основний ухил робиться саме на системні питання (специфікація системи, проектування архітектури, інтеграція й впровадження), а не на складові частини системи. Системна інженерія значно старша програмування як дисципліни. Програмна інженерія займається питаннями ефективної розробки програмного забезпечення. Існують всього на всього три основні труднощі програмної інженерії: − Застарілі системи, які необхідно супроводжувати і розвивати; − Робота в гетерогенному середовищі з розподіленими системами, які включають різне програмне і апаратне забезпечення; − Нестача часу, яке відводиться на розробку програмних продуктів. Зрозуміло, що ці проблеми не є абсолютно незалежними і можуть накладатися одна на одну.
|
Последнее изменение этой страницы: 2019-04-19; Просмотров: 378; Нарушение авторского права страницы