|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Введение. Виды параллелизмаСтр 1 из 6Следующая ⇒
Введение. Виды параллелизма Параллельное программирование используется для создания программ, которые эффективнее используют вычислительные ресурсы за счет одновременного исполнения кода на нескольких вычислительных узлах. Для создания таких приложений используют параллельные языки программирования, а также специальные системы, поддерживающие их, например, MPI и OpenMP. Параллельное программирование более сложное в написании кода и его отладке, чем последовательное. Для облегчения процесса существуют специализированные инструменты, такие как отладчик TotalView или статический анализатор кода VivaMP. В отличие от последовательного программирования, в концептуальной основе которого лежит понятие алгоритма, с шагами строго последовательными во времени, в ПП программа порождает параллельно протекающие процессы обработки информации, которые полностью независимы и не связаны между собой любыми отношениями. Можно выделить несколько видов параллелизма: 1. Естественный параллелизм независимых задач. Он заключается в том, что в систему поступает непрерывный поток не связанных между собой задач, т.е. решение любой задачи не зависит от результатов решения других задач. В этом случае использование нескольких процессоров однозначно повышает производительность. 2. Параллелизм независимых ветвей. Имеет очень широкое реальное распространение. Заключается в том, что при решении большой задачи могут быть выделены отдельные независимые части - ветви программы, которые при наличии нескольких процессоров могут выполняться параллельно и независимо друг от друга. Двумя независимыми ветвями будем считать части, для которых выполняются следующие условия: · ни одна из входных величин для ветви не является выходной для другой ветви (отсутствие функциональных связей); · обе ветви не производят запись в одни и те же ячейки памяти (отсутствие связи по использованию ОП); · условия выполнения одной ветви не зависят от результатов, полученных при выполнении другой ветви (независимость по управлению); · обе ветви должны выполняться по разным блокам программы (программная независимость). На самом деле задача обнаружения и реализации параллелизма независимых ветвей - очень сложная и объёмная. Фактически - это математическая задача сетевого планирования. С ней вы столкнётесь в курсе "ОПУП" на классическом примере "Утро на даче". Особенная сложность - неизвестность длительности исполнения каждой из множества ветвей. На практике невозможно избежать простоев в работе процессоров, мы лишь минимизируем их. 3. Параллелизм объектов или данных. Имеет место тогда, когда по одной и той же программе обрабатывается некая совокупность данных, поступающая в систему одновременно. Примеры: данные от РЛС - все сигналы обрабатываются по одной и той же программе, задачи векторной алгебры, в которых выполняются одинаковые операции над парами чисел двух аналогичных объектов. Можно сказать, что этот вид параллелизма служит базой для построения матричных систем. Третий путь параллельной обработки - конвейерная обработка информации. Его реализация возможна даже в системе с одним процессором, разделённым на несколько последовательно включенных операционных блоков, каждый из которых ориентирован на некоторые строго определённые части операции. Параллелизм данных Основная идея подхода, основанного на параллелизме данных, заключается в том, что одна операция выполняется сразу над всеми элементами массива данных. Различные фрагменты такого массива обрабатываются на векторном процессоре или на разных процессорах параллельной машины. Распределением данных между процессорами занимается программа. Векторизация или распараллеливание в этом случае чаще всего выполняется уже на этапе компиляции - перевода исходного текста программы в машинные команды. Роль программиста в этом случае обычно сводится к заданию опций векторной или параллельной оптимизации компилятору, директив параллельной компиляции, использованию специализированных языков для параллельных вычислений. Подход, основанный на параллелизме данных, базируется на использовании при разработке программ базового набора операций: 1. операции управления данными; 2. операции над массивами в целом и их фрагментами; 3. условные операции; 4. операции приведения; 5. операции сдвига; 6. операции сканирования; 7. операции, связанные с пересылкой данных. Параллелизм задач характеризуется следующими особенностями: · одна операция применяется сразу к нескольким элементам массива данных. Различные фрагменты такого массива обрабатываются на векторном процессоре или на разных процессорах параллельной машины; · обработкой данных управляет одна программа; · пространство имен является глобальным; · параллельные операции над элементами массива выполняются одновременно на всех доступных данной программе процессорах. При этом, от программиста требуется: · задание опций векторной или параллельной оптимизации транслятору; · задание директив параллельной компиляции; · использование специализированных языков параллельных вычислений, а также библиотек подпрограмм, специально разработанных с учетом конкретной архитектуры компьютера и оптимизированных для этой архитектуры. Параллелизм задач Стиль программирования, основанный на параллелизме задач, подразумевает, что вычислительная задача разбивается на несколько относительно самостоятельных подзадач и каждый процессор загружается своей собственной подзадачей. Компьютер при этом представляет собой MIMD - машину. Аббревиатура MIMD обозначает в известной классификации архитектур ЭВМ компьютер, выполняющий одновременно множество различных операций над множеством, вообще говоря, различных и разнотипных данных. Для каждой подзадачи пишется своя собственная программа на обычном языке программирования, обычно это ФОРТРАН или С. Чем больше подзадач, тем большее число процессоров можно использовать, тем большей эффективности можно добиться. Важно то, что все эти программы должны обмениваться результатами своей работы, практически такой обмен осуществляется вызовом процедур специализированной библиотеки. Программист при этом может контролировать распределение данных между процессорами и подзадачами и обмен данными. Очевидно, что в этом случае требуется определенная работа для того, чтобы обеспечить эффективное совместное выполнение различных программ. По сравнению с подходом, основанным на параллелизме данных, данный подход более трудоемкий, с ним связаны следующие проблемы: 1. повышенная трудоемкость разработки программы и ее отладки; 2. на программиста ложится вся ответственность за равномерную загрузку процессоров параллельного компьютера; 3. программисту приходится минимизировать обмен данными между задачами, так как пересылка данных - наиболее "времяемкий" процесс; 4. повышенная опасность возникновения тупиковых ситуаций, когда отправленная одной программой посылка с данными не приходит к месту назначения. Параллелизм задач характеризуется следующими особенностями: · вычислительная задача разбивается на несколько относительно самостоятельных подзадач. Каждая подзадача выполняется на своем процессоре (ориентация на архитектуру MIMD); · для каждой подзадачи пишется своя собственная программа на обычном языке программирования (чаще всего это Fortran или С); · подзадачи должны обмениваться результатами своей работы, получать исходные данные. Практически такой обмен осуществляется вызовом процедур специализированной библиотеки. Программист при этом может контролировать распределение данных между различными процессорами и различными подзадачами, а также обмен данными. Привлекательными особенностями данного подхода являются большая гибкость и большая свобода, предоставляемая программисту в разработке программы, эффективно использующей ресурсы параллельного компьютера и, как следствие, возможность достижения максимального быстродействия. Примерами специализированных библиотек являются библиотеки MPI (Message Passing Interface) [61] и PVM (Parallel Virtual Machines) [62]. Параллелизм уровня программ О параллелизме на уровне программы имеет смысл говорить в двух случаях. Во-первых, когда в программе могут быть выделены независимые участки, которые допустимо выполнять параллельно. Примером такого вида параллелизма можег служить программа робота. Пусть имеется робот, запрограммированный на обнаружение электрических розеток, когда уровень напряжения в его аккумуляторах падает. Когда робот находит одну из розеток, он включается в нее на подзарядку В процесс вовлечены три подсистемы робота: зрение, манипуляция и движение Каждая подсистема управляется своим процессором, то есть подсистемы при выполнении разных действий способны работать параллельно. Подсистемы достаточно независимы при ведущей роли системы зрения. Возможен также и центральный процессор — «мозг». Это пример параллелизма программ, в котором разные задачи выполняются единовременно для достижения общей цели. Второй тип параллелизма программ возможен в пределах отдельного программного цикла, если в нем отдельные итерации не зависят друг от друга. Программный параллелизм может быть реализован за счет большого количества процессоров или множества функциональных блоков. В качестве примера рассмотрим следующий фрагмент кода: For I:=1 to N do A(I):=B(I) + C(I) Все суммы независимы, то есть вычисление Вi + Сi не зависит от Bj + Сj для любого j < i. Это означает, что вычисления могут производиться в любой последовательности и в вычислительной системе с N процессорами все суммы могут быть вычислены одновременно. Общая форма параллелизма на уровне программ проистекает из разбиения программируемых данных на подмножества. Это разделение называют декомпозицией области (domain decomposition), а параллелизм, возникающий при этом, носит название параллелизма данных. Подмножества данных назначаются разным вычислительным процессам, и называется этот процесс распределением данных (data distribution). Процессоры выделяются определенным процессам либо по инициативе программы, либо в процессе работы операционной системой. На каждом процессоре может выполняться более чем один процесс. Параллелизм уровня команд Параллелизм на уровне команд имеет место, когда обработка нескольких команд или выполнение различных этапов одной и той же команды может перекрываться во времени. Разработчики вычислительной техники издавна прибегали к методам, известным под общим названием «совмещения операций», при котором аппаратура ВМ в любой момент времени выполняет одновременно более одной операции. Этот общий принцип включает в себя два понятия: параллелизм и конвейеризацию. Хотя у них много общего и их зачастую трудно различать на практике, термины эти отражают два принципиально различных подхода. В первом варианте совмещение операций достигается за счет того, что в составе вычислительной системы отдельные устройства присутствуют в нескольких копиях. Так, в состав процессора может входить несколько АЛУ, и высокая производительность обеспечивается за счет одновременной работы всех этих АЛУ. Второй подход был описан ранее. Методы решения проблем Т.к. транзакции не мешают друг другу, если они обращаются к разным данным или выполняются в разное время, то имеется два способа разрешить конкуренцию между поступающими в произвольные моменты транзакциями: 1. "Притормаживать" некоторые из поступающих транзакций настолько, насколько это необходимо для обеспечения правильности смеси транзакций в каждый момент времени (т.е. обеспечить, чтобы конкурирующие транзакции выполнялись в разное время). 2. Предоставить конкурирующим транзакциям "разные" экземпляры данных (т.е. обеспечить, чтобы конкурирующие транзакции работали с разными версиями данными). Первый метод - "притормаживание" транзакций - реализуется путем использованием блокировок различных видов или метода временных меток. Второй метод - предоставление разных версий данных - реализуется путем использованием данных из журнала транзакций. Внутренний параллелизм Алгоритм обладает внутренним параллелизмом, если его можно разбить на параллельно (но не обязательно независимо) выполняемые части. Использование внутреннего параллелизма имеет очевидное достоинство, т.к. не нужно тратить дополнительные усилия на изучение вычислительных свойств вновь создаваемых алгоритмов. В тех случаях, когда внутреннего параллелизма какого-либо алгоритма недостаточно для эффективного использования конкретного параллельного компьютера, приходится заменять его другим алгоритмом, имеющим лучшие свойства параллелизма. Рассмотрим пример: пусть решается система линейных алгебраический уравнений Ax= b с невырожденной треугольной матрицей А порядка n методом обратной подстановки. Обозначим через aij, bi, xj элементы матрицы, правой части и вектор-решения. Предположим для определенности, что матрица A левая треугольная с диагональными элементами, равными 1. Тогда имеем:
Эта запись также не определяет алгоритм однозначно, т.к. не определен порядок суммирования. Рассмотрим, например, последовательное суммирование по возрастанию индекса j. Соответствующий алгоритм можно записать следующим образом:
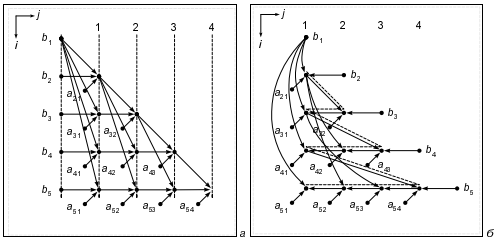
Основная операция алгоритма имеет вид a - bc. Выполняется она для всех допустимых значений индексов i, j. Все остальные операции осуществляют присваивание. Опять неэффективна простая перенумерация операций при построении графа алгоритма. В декартовой системе координат с осями i, j построим прямоугольную координатную сетку с шагом 1 и поместим в узлы сетки при 2 ≤ i ≤ n, 1 ≤ j ≤ i-1 вершины графа, соответствующие операциям a - bc. Анализируя связи между операциями, построим граф алгоритма, включив в него также вершины, символизирующие вход входных данных aij и bj. Этот граф для случая n = 5 представлен на рисунке 1.а. Верхняя угловая вершина находится в точке с координатами i = 1, j = 0. На этом рисунке показана одна из максимальных параллельных форм. Ее ярусы отмечены пунктирными линиями. Параллельная форма становится канонической, если вершины, соответствующие вводу элементов aij, поместить в первый ярус. Общее число ярусов, содержащих операции типа a – bc, равно n – 1. Операции ввода элементов вектора b расположены в первом ярусе.
1. Графы для треугольных систем Если при вычислении суммы по формуле (1) мы останавливаемся по каким-либо соображениям на последовательном способе суммирования, то выбор суммирования именно по возрастанию индекса j был сделан, вообще говоря, случайно. Так как в этом выборе пока не видно каких-либо преимуществ, то можно построить алгоритм обратной подстановки с суммированием по убыванию индекса j. Соответствующий алгоритм таков:
Его граф для случая n = 5 представлен на рисунке 1.б. Теперь угловая вершина находится в точке с координатами i =1, j = 1. Пытаясь размещать вершины, соответствующие операциям a – bc, по ярусам хотя бы какой-нибудь параллельной формы, мы обнаруживаем что теперь в каждом ярусе всегда может находится только одна вершина. Объясняется это тем, что все вершины графа 1.б лежат на одном пути. Этот путь показан пунктирными стрелками. Поэтому общее число ярусов в графе алгоритма (3), содержащих операции a – bc, всегда равно ( n2 – n + 2)/2, что намного больше, чем n – 1 ярус в графе алгоритма (2). Оба алгоритма (2) и (3) предназначены для решения одной задачи. Они построены на одних и тех же формулах (1) и в отношении точных вычислений эквивалентны. Оба алгоритма совершенно одинаковы с точки зрения их реализации на однопроцессорных компьютерах, т.к. требуют выполнения одинакового числа операций умножения и вычитания одинакового объема памяти. На классе треугольных систем оба алгоритма даже эквивалентны с точки зрения влияния ошибок округления. Тем не менее, графы алгоритмов принципиально отличаются друг от друга. Если эти алгоритмы реализовать на параллельной вычислительной системе, имеющей n процессоров, то алгоритм (2) можно реализовать за время, пропорциональное n, а алгоритм (3) только за время пропорциональное n2. В первом случае средняя загруженность процессоров близка 0,5, во втором она близка к 0. Таким образом, алгоритмы, совершенно одинаковые с точки зрения реализации на обычных компьютерах могут быть принципиально разными с точки зрения реализации на параллельных компьютерах. Создание параллельных вычислительных систем дополнительно потребовало от алгоритмов принципиально других свойств и характеристик, знание которых для последовательных компьютеров было не нужным. Вот почему важно исследовать алгоритмы более глубоко и основательно. Особенно необходимо создавать конструктивную методологию для выявления и изучения параллельных свойств алгоритмов. Рассмотренный выше пример показал, что в алгоритмах действительно имеется хороший запас параллелизма. Ключевым моментом в его выявлении или установлении факта, что он отсутствует, является знание графов алгоритмов и параллельных форм.
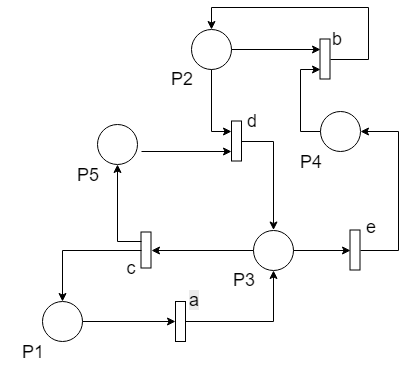
Задача по сетям Петри Для двух таблиц Hi и Fi, выбранных в соответствии с номером варианта (Nвар=Nсп.гр.mod12) выполнить следующее: · построить сеть Петри (без пересечения линий!!!); · найти особые места в сети, в которых фишки могут исчерпаться либо накопиться; проанализировать возможные тупики (зависания сети) с учётом особых мест и блокировок переходов; · выбрать начальную разметку (достаточно в нескольких позициях иметь по одной-две фишки) и записать сценарий функционирования сети (для каждого момента времени указать сработавшие переходы и полученную в результате новую разметку сети), приведший к тупику. В случае отсутствия тупика записать сценарий для 8-10 срабатываний переходов. Вариант N = 8 mod6 = 2.
Решение: Построим сеть Петри по таблицам:
Проанализировав сеть, я пришла к выводу, что точки могут накапливаться в P1 при срабатывании переходов d, а затем c b, также в P5, при срабатывании переходов a, а затем c. Также точки могут исчерпаться в P2 и P4 и P5, что приведет к зависанию сети. Установим разметку сети, я установила 3 фишки в P2, так как там они могут исчерпаться быстрее всего:
Запишем сценарий работы сети: 1. Начальная разметка {1, 3, 0, 0, 0}, P1. 2. Срабатывает переход a. Разметка: {0, 3, 1, 0, 0}, P3. 3. Возможные переходы e и с: 3.a.: 3.a.1. Срабатывает переход e. Разметка: {0, 3, 0, 1, 0}, P4. 3.a.2. Срабатывает переход b. Разметка: {0, 3, 0, 0, 0}, P2. Литература 1. Л.В. Городняя, ПАРАДИГМЫ ПРОГРАММИРОВАНИЯ. Часть 4. Параллельное программирование – Новосибирск, 2015 2. Воеводин В.В., Воеводин Вл.В. Параллельные вычисления – СПб:БХВ-Петербург, 2002 3. http://umk.portal.kemsu.ru/mps/html/node4_25.htm ОСНОВНЫЕ ПОНЯТИЯ ПАРАЛЛЕЛИЗМА 4. https://www.intuit.ru курс Intel Parallel Programming Professional (Introduction) 5. https://pro-prof.com/forums/topic/parallel-programming-paradigms - Парадигмы параллельного программирования 6. Парадигмы параллельного программирования [Электронный ресурс]: лекционный материал. – Режим доступа: http://staff.mmcs.sfedu.ru/~dubrov/files/sl_parallel_05_paradigm.pdf 7. И.Г.Бурова, Ю. К. Демьянович, АЛГОРИТМЫ ПАРАЛЛЕЛЬНЫХ ВЫЧИСЛЕНИЙ И ПРОГРАММИРОВАНИЕ, Курс лекций 8. https://www.intuit.ru/studies/courses/1047/248/info курс «Вычислительная математика и структура алгоритмов» Введение. Виды параллелизма Параллельное программирование используется для создания программ, которые эффективнее используют вычислительные ресурсы за счет одновременного исполнения кода на нескольких вычислительных узлах. Для создания таких приложений используют параллельные языки программирования, а также специальные системы, поддерживающие их, например, MPI и OpenMP. Параллельное программирование более сложное в написании кода и его отладке, чем последовательное. Для облегчения процесса существуют специализированные инструменты, такие как отладчик TotalView или статический анализатор кода VivaMP. В отличие от последовательного программирования, в концептуальной основе которого лежит понятие алгоритма, с шагами строго последовательными во времени, в ПП программа порождает параллельно протекающие процессы обработки информации, которые полностью независимы и не связаны между собой любыми отношениями. Можно выделить несколько видов параллелизма: 1. Естественный параллелизм независимых задач. Он заключается в том, что в систему поступает непрерывный поток не связанных между собой задач, т.е. решение любой задачи не зависит от результатов решения других задач. В этом случае использование нескольких процессоров однозначно повышает производительность. 2. Параллелизм независимых ветвей. Имеет очень широкое реальное распространение. Заключается в том, что при решении большой задачи могут быть выделены отдельные независимые части - ветви программы, которые при наличии нескольких процессоров могут выполняться параллельно и независимо друг от друга. Двумя независимыми ветвями будем считать части, для которых выполняются следующие условия: · ни одна из входных величин для ветви не является выходной для другой ветви (отсутствие функциональных связей); · обе ветви не производят запись в одни и те же ячейки памяти (отсутствие связи по использованию ОП); · условия выполнения одной ветви не зависят от результатов, полученных при выполнении другой ветви (независимость по управлению); · обе ветви должны выполняться по разным блокам программы (программная независимость). На самом деле задача обнаружения и реализации параллелизма независимых ветвей - очень сложная и объёмная. Фактически - это математическая задача сетевого планирования. С ней вы столкнётесь в курсе "ОПУП" на классическом примере "Утро на даче". Особенная сложность - неизвестность длительности исполнения каждой из множества ветвей. На практике невозможно избежать простоев в работе процессоров, мы лишь минимизируем их. 3. Параллелизм объектов или данных. Имеет место тогда, когда по одной и той же программе обрабатывается некая совокупность данных, поступающая в систему одновременно. Примеры: данные от РЛС - все сигналы обрабатываются по одной и той же программе, задачи векторной алгебры, в которых выполняются одинаковые операции над парами чисел двух аналогичных объектов. Можно сказать, что этот вид параллелизма служит базой для построения матричных систем. Третий путь параллельной обработки - конвейерная обработка информации. Его реализация возможна даже в системе с одним процессором, разделённым на несколько последовательно включенных операционных блоков, каждый из которых ориентирован на некоторые строго определённые части операции. |
Последнее изменение этой страницы: 2019-04-21; Просмотров: 354; Нарушение авторского права страницы