|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
РАЗРАБОТКА МОДУЛЯ ТРАНСЛЯТОРАСтр 1 из 11Следующая ⇒
РАЗРАБОТКА МОДУЛЯ ТРАНСЛЯТОРА
Методические указания
для выполнения курсового проекта по дисциплине «Системное программное обеспечение» для студентов дневной формы обучения
Севастополь 2012 УДК 519.6 Разработка модуля учебной операционной системы: Методические указания по дисциплине «Операционные системы» для студентов дневной формы обучения / Сост. Г.Г.Сергеев, С.Н. Фисун. – Севастополь: Изд-во СевНТУ, 2012. – 46с.
Целью методических указаний является оказание помощи студентам в выполнении курсового проекта по дисциплине «Операционные системы».
Методические указания рассмотрены и утверждены на заседании кафедры КиВТ (протокол № 12 от 26.06.2011 г.).
Допущено учебно-методическим центром СевНТУ в качестве методических указаний.
Рецензенты:
Овчинников А.Л. – старший преподаватель кафедры информационных систем СевНТУ. СОДЕЖАНИЕ ВВЕДЕНИЕ.. 4 1 Теоретический раздел. 4 1.1 Проектирование лексического анализатора. 4 1.2 Синтаксический анализ. 10 1.2.1 Распознавание цепочек КС-языков. 10 1.2.2 Грамматики предшествования. 11 1.2.3 Cинтаксический анализ для LL(1)-грамматики. 18 1.3 Генерация и оптимизация кода. 21 1.3.1 Алгоритм генерации объектного кода по дереву вывода. 22 1.3.2 Оптимизация объектного кода методом свертки. 25 2 Порядок выполнения курсового проекта. 29 3 Варианты заданий. 30 4 Содержание отчета. 36 Библиография. 37
ВВЕДЕНИЕ
Цель курсового проекта: изучить теоретические основы построения модулей транслятора. Получить практические навыки разработки системного программного обеспечения.
Теоретический раздел
Begin for i:=1 to N do fg := fg * 0.5 ... Таблица 1. Таблица лексем программы
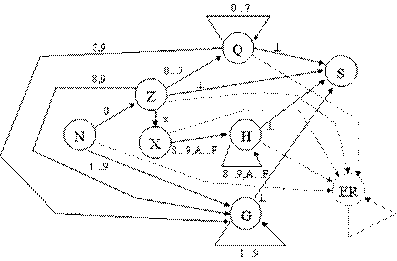
Вид представления информации после выполнения лексического анализа целиком зависит конструкции компилятора. Но в общем виде ее можно представить как таблицу лексем, которая в каждой строчке должна содержать информацию о виде лексемы, ее типе и, возможно, значении. Обычно такая таблица имеет два столбца: первый - строка лексемы, второй - указатель на информацию о лексеме, может быть включен и третий столбец - тип лексем. Лексический анализатор имеет дело с таким объектами, как различного рода константы и идентификаторы (к последним относятся и ключевые слова). Язык констант и идентификаторов в большинстве случаев является регулярным - то есть, может быть описан с помощью регулярных (праволинейных или леволинейных) грамматик [1,3,4]. Распознавателями для регулярных языков являются конечные автоматы. Существуют правила, с помощью которых для любой регулярной грамматики может быть построен недетерминированный конечный автомат, распознающий цепочки языка, заданного этой грамматикой. Недетерминированный конечный автомат задается пятеркой: M=(Q,S ,d ,q0,F), где: Q - конечное множество состояний автомата; S - конечное множество допустимых входных символов; d - заданное отображение множества Q*S во множество подмножеств P(Q) d: Q*S ® P(Q) (иногда d называют функцией переходов автомата); q0Î Q - начальное состояние автомата; F Í Q - множество заключительных состояний автомата. Работа автомата выполняется по тактам. На каждом очередном такте i автомат, находясь в некотором состоянии qiÎ Q, считывает очередной символ wÎ S из входной цепочки символов и изменяет свое состояние на qi+1=d (qi,w), после чего указатель в цепочке входных символов передвигается на следующий символ и начинается такт i+1. Так продолжается до тех пор, пока цепочка входных символов не закончится. Конец цепочки символов часто помечают особым символом ^. Считается также, что перед тактом 1 автомат находится в начальном состоянии q0. Говорят, что автомат допускает цепочку a Î S *, если в результате выполнения всех тактов работы над этой цепочкой он окажется в состоянии qÎ F. Язык, определяемый автоматом, является множеством всех цепочек, допускаемых автоматом. Для анализа цепочки с помощью конечного автомата достаточно подать ее на вход автомата, выполнить все такты его работы и определить, перешел ли автомат в результате работы в одно из заданных конечных состояний. Графически автомат отображается нагруженным однонаправленным графом, в котором вершины представляют состояния, дуги отображают переходы из одного состояния в другое, а символы нагрузки (пометки) дуг соответствуют функции перехода. Если функция перехода предусматривает переход из состояния q в q" по нескольким символам, то между ними строится одна дуга, которая помечается всеми символами, по которым происходит переход из q в q". Недетерминированный автомат неудобен для анализа цепочек, так как в нем могут встречаться состояния, допускающие неоднозначность, т.е. такие, из которых выходит две или более дуги, помеченных одним и тем же символом. Очевидно, что программирование работы такого автомата - нетривиальная задача. Доказано, что любой недетерминированный автомат может быть преобразован в детерминированный так, чтобы их языки совпадали [1,2,3] (говорят, что автоматы эквивалентны). Детерминированный конечный автомат задается пятеркой: M"=(Q",S ,d ",q0",F"), где: Q" - конечное множество состояний автомата; S - конечное множество допустимых входных символов автомата; q0"Î Q" - начальное состояние автомата; d " - заданное отображение множества Q"*S во множество Q" d : Q"*S ® Q"; F Í Q" - множество заключительных состояний автомата. После построения конечный детерминированный автомат может быть минимизирован, т.е. для него может быть построен эквивалентный ему автомат с минимальным числом состояний. Можно написать функцию, отражающую функционирование любого детерминированного конечного автомата. Чтобы запрограммировать такую функцию, достаточно иметь переменную, которая бы отображала текущее состояние автомата, а переходы автомата из одного состояния в другое на основе символов входной цепочки могут быть построены с помощью операторов выбора. Работа функции должна продолжаться до тех пор, пока не будет достигнут конец входной цепочки. Для вычисления результата функции необходимо по ее завершению проанализировать состояние автомата. Если это одно из конечных состояний, то функция выполнена успешно, и входная цепочка принимается, если нет - то входная цепочка не принадлежит заданному языку. Рассмотрим пример анализа лексем, представляющих собой целочисленные константы без знака в формате языка Си. В соответствии с требованиями языка, такие константы могут быть десятичными, восьмеричными, либо шестнадцатеричными. Восьмеричной константой считается число, начинающееся с 0 и содержащее цифры от 0 до 7; шестнадцатеричная константа должна начинаться с последовательности символов 0x и может содержать цифры и буквы от A до F (будем рассматривать только прописные буквы). Остальные числа считаются десятичными (правила их записи напоминать, наверное, не стоит). Будем считать, что всякое число завершается символом конца строки ^. Рассмотренные выше правила могут быть записаны в форме Бэкуса-Наура в грамматике целочисленных констант без знака языка Си (для избежания путаницы терминальные символы грамматики выделены жирным шрифтом). G({S,G,X,H,Q,Z},{0...9,A...F, ^ },P,S) P: S® G^ |Z^ |H^ |Q^ G® 1|2|3|4|5|6|7|8|9|G0|G1|G2|G3|G4|G5|G6|G7|G8|G9|Z8|Z9|Q8|Q9 H® X0|X1|X2|X3|X4|X5|X6|X7|X8|X9|XA|XB|XC|XD|XE|XF| H0|H1|H2|H3|H4|H5|H6|H7|H8|H9|HA|HB|HC|HD|HE|HF X® Zx Q® Z0|Z1|Z2|Z3|Z4|Z5|Z6|Z7|Q0|Q1|Q2|Q3|Q4|Q5|Q6|Q7 Z® 0 Хорошо видно, что данная грамматика является регулярной грамматикой (леволинейной). Конечный детерминированный автомат M"({N,Z,X,H,Q,G,S,ER},{0...9,A...F,^ },d ,N,{S}), который распознает язык, заданный этой грамматикой, изображен на рис. 3. Начальным состоянием автомата является состояние N. В автомат дополнительно введено особое состояние ER, обозначающее ошибку в распознавании цепочки символов. На графе автомата дуги, идущие в это состояние, не нагружены символами. По принятому соглашению они обозначают функцию перехода по любому символу, кроме тех символов, которыми уже помечены другие дуги, выходящие из той же вершины графа. Такое соглашение принято, чтобы не загромождать обозначениями граф автомата (на рис. 3 такие дуги и состояние ER выделены пунктиром). Можно написать программу, моделирующую работу указанного автомата. Ниже приводится текст функции на языке Паскаль, его реализующей. Результат функции истинный (True), если входная цепочка символов принадлежит входному языку автомата. Границей цепочки считается символ с кодом 0 (#0), в функции он искусственно добавляется в конец цепочки. В программе переменная iState отображает текущее состояние автомата, переменная i является счетчиком символов входной строки. Конечно, рассмотренная программа может быть оптимизирована (например, можно сразу же прекращать разбор по обнаружению ошибки), но в данном примере оптимизация не выполнялась, чтобы можно было четко отследить соответствие между программой и построенным автоматом. type TAutoState = ( AUTO_N, AUTO_Z, AUTO_X,
f unction RunAuto (sInput: string): Boolean; var iState : TAutoState; i : integer; begin sInput := sInput + #0; iState := AUTO_N; i := 0; repeat i := i + 1; case iState of AUTO_N: case sInput[i] of "0": iState := AUTO_Z; "1".."9": iState := AUTO_G; else iState := AUTO_ER; end; AUTO_Z: case sInput[i] of "0".."7": iState := AUTO_Q; "8","9": iState := AUTO_G; "x": iState := AUTO_X; #0: iState := AUTO_S; else iState := AUTO_ER; end; AUTO_X: case sInput[i] of "0".."9": iState := AUTO_H; "A".."F": iState := AUTO_H; else iState := AUTO_ER; end; AUTO_Q: case sInput[i] of "0".."7": iState := AUTO_Q; "8","9": iState := AUTO_G; #0: iState := AUTO_S; else iState := AUTO_ER; end; AUTO_H: case sInput[i] of "0".."9": iState := AUTO_H; "A".."F": iState := AUTO_H; #0: iState := AUTO_S; else iState := AUTO_ER; end; AUTO_G: case sInput[i] of "0".."9": iState := AUTO_G; #0: iState := AUTO_S; else iState := AUTO_ER; end; AUTO_ER: iState := AUTO_ER; end {case}; until (sInput[i] = #0); RunAuto := (iState = AUTO_S); end; { RunAuto } Однако в общем случае задача сканера несколько шире, чем просто проверка цепочки символов лексемы на соответствие ее входному языку. Сканер должен выполнить те или иные действия по запоминанию распознанной лексемы (занесение ее в таблицу лексем). Набор действий определяется реализацией компилятора. Обычно эти действия выполняются сразу же по обнаружению конца распознаваемой лексемы, поэтому их несложно вставить в соответствующие места рассмотренной выше программы-сканера (в те операторы, где обнаруживается символ #0). Вторая проблема, которая уже обсуждалась выше, это выделение границ лексем. Ведь во входном тексте лексемы не ограничены специальными символами. Если говорить в терминах программы-сканера, то определение границ лексем - это выделение тех строк в общем потоке входных символов, для которых надо выполнять распознавание. В общем случае эта задача может быть сложной, но для простейших входных языков границы лексем распознаются по заданным терминальным символам. Эти символы - пробелы, знаки операций, символы комментариев, а также разделители (запятые, точки с запятой и др.). Набор таких терминальных символов может варьироваться в зависимости от входного языка. Важно отметить, что знаки операций сами также являются лексемами, и необходимо не пропустить их при распознавании текста. Таким образом, алгоритм работы простейшего сканера можно описать так: - просматривается входной поток символов программы на исходном языке до обнаружения очередного символа, ограничивающего лексему; - для выбранной части входного потока выполняется функция распознавания лексемы; - при успешном распознавании информация о выделенной лексеме заносится в таблицу лексем, и алгоритм возвращается к первому этапу; - при неуспешном распознавании выдается сообщение об ошибке, а дальнейшие действия зависят от реализации сканера - либо его выполнение прекращается, либо делается попытка распознать следующую лексему (идет возврат к первому этапу алгоритма). Работа программы-сканера продолжается до тех пор, пока не будут просмотрены все символы программы на исходном языке из входного потока.
Синтаксический анализ По иерархии грамматик Хомского выделяют 4 основные группы языков (и описывающих их грамматик). При этом наибольший интерес представляют регулярные и контексно-свободные (КС) грамматики и языки. Они используются при описании синтаксиса языков программирования. С помощью регулярных грамматик можно описать лексемы языка - идентификаторы, константы, служебные слова и прочие. На основе КС-грамматик строятся более крупные синтаксические конструкции - описания типов и переменных, арифметические и логические выражения, управляющие операторы, и, наконец, полностью вся программа на исходном языке. Входные цепочки регулярных языков распознаются с помощью конечных автоматов (КА). Они лежат в основе сканеров, выполняющих лексический анализ и выделение слов в тексте программы на входном языке. Результатом работы сканера является преобразование исходной программы в список или таблицу лексем. Дальнейшую ее обработку выполняет другая часть компилятора - синтаксический анализатор. Его работа основана на использовании правил КС-грамматики, описывающих конструкции исходного языка. Взаимодействие лексического и синтаксического анализатора рассматривалось в предыдущей лабораторной работе, здесь же будем изучать алгоритмы, лежащие в основе синтаксического анализа. Перед синтаксическим анализатором стоят две основные задачи: проверить правильность конструкций программы, которая представляется в виде уже выделенных слов входного языка, и преобразовать ее в вид, удобный для дальнейшей семантической (смысловой) обработки и генерации кода. Одним из таких способов представления является дерево синтаксического разбора. Грамматики предшествования Программирование работы недетерминированного МП-автомата - это сложная задача. Разработан алгоритм, позволяющий для произвольной КС-грамматики определить, принадлежит ли ей заданная входная цепочка (алгоритм Кока-Янгера-Касами)[4,5]. Доказано, что время работы этого алгоритма пропорционально n3, где n - длина входной цепочки. Для однозначной КС-грамматики при использовании другого алгоритма (алгоритм Эрли) это время пропорционально n2. Подобная зависимость делает эти алгоритмы требовательными к вычислительным ресурсам, а потому мало пригодными для практических целей. Но на практике и не требуется анализ цепочки произвольного КС-языка - большинство конструкций языков программирования может быть отнесено в один из классов КС-языков, для которых разработаны алгоритмы разбора, линейно зависящие от длины входной цепочки. КС-языки делятся на классы в соответствии со структурой правил их грамматик. В каждом из классов налагаются дополнительные ограничения на допустимые правила грамматики. Грамматикой простого предшествования называют такую КС-грамматику G(VN,VT,P,S), V=VT VN в которой: Для каждой упорядоченной пары терминальных и нетерминальных символов выполняется не более чем одно из трех отношений предшествования : Si = Sj (" Si,SjÎ V), если и только если $ правило U® xSiSjy Î P, где UÎ VN, x,yÎ V*; Si < Sj (" Si,SjÎ V), если и только если $ правило U® xSiDy Î P и вывод DÞ *Sjz, где U,DÎ VN, x,y,zÎ V*; Si > Sj (" Si,SjÎ V) , если и только если $ правило U® xCSjy Î P и вы вод CÞ *zSi или $ правило U® xCDy Î P и выводы CÞ *zSi и DÞ *Sjw, где U,C,DÎ VN, x,y,z,wÎ V*. Различные порождающие правила имеют разные правые части. Отношения =, < и > называют отношениями предшествования для символов. Отношение предшествования единственно для каждой упорядоченной пары символов. При этом между какими-либо двумя символами может и не быть отношения предшествования - это значит, что они не могут находиться рядом ни в одном элементе разбора синтаксически правильной цепочки. Отношения предшествования зависят от порядка, в котором стоят символы, и в этом смысле их нельзя путать со знаками математических операций - например, если Si > Sj, то не обязательно, что Sj < Si (поэтому знаки предшествования иногда помечают специальной точкой: = , < , >) Метод предшествования основан на том факте, что отношения предшествования между двумя соседними символами распознаваемой строки соответствуют трем следующим вариантам: Si < Si+1, если символ Si+1 - крайний левый символ некоторой основы; Si > Si+1 , если символ Si - крайний правый символ некоторой основы; Si = Si+1 , если символы Si и Si+1 принадлежат одной основе. Исходя из этих соотношений выполняется разбор строки для грамматики предшествования. На основании отношений предшествования строят матрицу предшествования грамматики. Строки матрицы предшествования помечаются первыми символами, столбцы - вторыми символами отношений предшествования, а в клетки матрицы на пересечении соответствующих столбца и строки помещаются знаки отношений. При этом пустые клетки матрицы говорят о том, что между данными символами нет ни одного отношения предшествования. Матрицу предшествования грамматики можно построить, опираясь непосредственно на определения отношений предшествования, но удобнее воспользоваться двумя дополнительными множествами - множеством крайних левых и множеством крайних правых символов относительно нетерминалов грамматики. Эти множества определяются следующим образом: L(U) = {T | $ UÞ *Tz}, U,TÎ V, zÎ V* - множество крайних левых символов относительно нетерминального символа U (цепочка z может быть и пустой цепочкой); R(U) = {T | $ UÞ *zT}, U,TÎ V, zÎ V* - множество крайних правых символов относительно нетерминального символа U. Тогда отношения предшествования можно определить так:Si = Sj (" Si,SjÎ V), если $ правило U® xSiSjy Î P, где UÎ VN, x,yÎ V*; Si < Sj (" Si,SjÎ V), если $ правило U® xSiDy Î P и SjÎ L(D), где U,DÎ VN, x,yÎ V*; Si > Sj (" Si,SjÎ V) , если $ правило U® xCSjy Î P и SiÎ R(C) или $ правило U® xCDy Î P и SiÎ R(C), SjÎ L(D), где U,C,DÎ VN, x,yÎ V*. Такое определение отношений удобнее на практике, так как не требует построения выводов, а множества L(U) и R(U) могут быть построены для каждого нетерминального символа UÎ VN по очень простому алгоритму: Шаг 1. Для каждого нетерминального символа U ищем все правила, содержащие U в левой части. Во множество L(U) включаем самый левый символ из правой части правил, а во множество R(U) - самый крайний символ правой части. Переходи к шагу 2. Шаг 2. Для каждого нетерминального символа U: если множество L(U) содержит нетерминальные символы грамматики U",U",..., то его надо дополнить символами, входящими в соответствующие множества L(U"), L(U"), ... и не входящими в L(U). Ту же операцию надо выполнить для R(U). Шаг 3. Если на предыдущем шаге хотя бы одно множество L(U) или R(U) для некоторого символа грамматики изменилось, то надо вернуться к шагу 2, иначе построение закончено. После построения множеств L(U) и R(U) по правилам грамматики создается матрица предшествования. Матрицу предшествования дополняют символами ^ н и ^ к (начало и конец цепочки). Для них определены следующие отношения предшествования : ^ н < a, " aÎ V, если $ SÞ *ax, где SÎ VN, xÎ V* или (с другой стороны) если aÎ L(S); ^ к > a, " aÎ V, если $ SÞ *xa, где SÎ VN, xÎ V* или (с другой стороны) если aÎ R(S). Грамматикой операторного предшествования называется приведенная КС-грамматика без -правил (e-правил), в которой правые части продукций не содержат смежных нетерминальных символов. Для грамматики операторного предшествования отношения предшествования можно задать на множестве терминальных символов (включая символы ^ н и ^ к). Отношения предшествования для грамматики операторного предшествования G(VN,VT,P,S) задаются следующим образом: a = b, если и только если существует правило U® xaby Î P или правило U® xaCby, где a,bÎ VT, U,CÎ VN, x,yÎ V*; a < b, если и только если существует правило U® xaCy Î P и вывод CÞ *bz или вывод CÞ *Dbz, где a,bÎ VT, U,C,DÎ VN, x,y,zÎ V*; a > b, если и только если существует правило U® xCby Î P и вывод CÞ *za или вывод CÞ *zaD, где a,bÎ VT, U,C,DÎ VN, x,y,zÎ V*. В грамматике операторного предшествования различные порождающие правила имеют разные правые части. Для грамматики операторного предшествования тоже строится матрица предшествования, но она содержит только терминальные символы грамматики. Для построения этой матрицы удобно ввести множества крайних левых и крайних правых терминальных символов относительно нетерминального символа U - Lt(U) или Rt(U): Lt(U) = {t | $ UÞ *tz или $ UÞ *Ctz }, где tÎ VT, U,CÎ VN, zÎ V*; Rt(U) = {t | $ UÞ *zt или $ UÞ *ztC }, где tÎ VT, U,CÎ VN, zÎ V*. Тогда определения отношений операторного предшествования будут выглядеть так: a = b, если $ правило U® xaby Î P или правило U® xaCby, где a,bÎ VT, U,CÎ VN, x,yÎ V*; a < b, если $ правило U® xaCy Î P и bÎ Lt(C), где a,bÎ VT, U,CÎ VN, x,yÎ V*; a > b, если $ правило U® xCby Î P и aÎ Rt(C), где a,bÎ VT, U,CÎ VN, x,yÎ V*. В данных определениях цепочки символов x,y,z могут быть и пустыми цепочками. Для нахождения множеств Lt(U) и Rt(U) используется следующий алгоритм: Шаг 1. Для каждого нетерминального символа грамматики U строятся множества L(U) и R(U). Шаг 2. Для каждого нетерминального символа грамматики U ищутся правила вида U® tz и U® Ctz, где tÎ VT, CÎ VN, zÎ V*; терминальные символы t включаются во множество Lt(U). Аналогично для множества Rt(U) ищутся правила вида U® zt и U® ztC. Шаг 3. Просматривается множество L(U), в которое входят символы U",U",... Множество Lt(U) дополняется символами, входящими в Lt(U"), Lt(U"), ... и не входящими в Lt(U). Аналогичная операция выполняется и для множества Rt(U) на основе множества R(U). Для практического использования матрицу предшествования дополняют символами ^ н и ^ к (начало и конец цепочки). Для них определены следующие отношения предшествования: ^ н < a, " aÎ VT, если $ SÞ *ax или $ SÞ *Cax, где S,CÎ VN, xÎ V* или если aÎ Lt(S); ^ к > a, " aÎ VT, если $ SÞ *xa или $ SÞ *xaC, где S,CÎ VN, xÎ V* или если aÎ Rt(S). Алгоритм "сдвиг-свертка" для грамматик простого и операторного предшествования Алгоритм "сдвиг-свертка" для грамматики простого предшествования. Данный алгоритм выполняется МП-автоматом с одним состоянием. Отношения предшествования служат для того, чтобы определить в процессе выполнения алгоритма, какое действие - сдвиг или свертка - должно выполняться на данном шаге и однозначно выбрать правило при свертке. В начальном состоянии автомата считывающая головка обозревает первый символ, в конец цепочки помещен символ ^ к. Разбор считается законченным (алгоритм завершается), если считы вающая головка автомата обозревает символ ^ н и при этом больше не может быть выполнена свертка. Решение о принятии цепочки зависит от содержимого стека. Автомат принимает цепочку, если в результате завершения алгоритма он находится в конечном состоянии, когда в стеке находятся начальный символ грамматики S и символ ^ н. Выполнение алгоритма может быть прервано, если на одном из его шагов возникнет ошибка. Тогда входная цепочка не принимается. Алгоритм состоит из следующих шагов: Шаг 1. Поместить в верхушку стека символ ^ н. Шаг 2. Сравнить символ, находящийся на вершине стека, с текущим символом ленты. Шаг 3. Если имеет место отношение < или =, то произвести перенос и вернуться к шагу 2. Шаг 4. Если имеет место отношение >, то произвести свертку, то есть найти на вершине стека все символы, связанные отношением = (основу) и заменить их на левую часть соответствующего правила грамматики (если символов, связанных отношением =, на верхушке стека нет, то для правила используется один, верхний символ). Если разбор не закончен, то вернуться к шагу 2. Ошибка в процессе выполнения алгоритма возникает, когда невозможно выполнить очередной шаг - например, если не установлено отношение предшествования между двумя сравниваемыми символами (на шагах 2 и 4) или если не удается найти нужное правило в грамматике (на шаге 4). Тогда выполнение алгоритма немедленно прерывается. Алгоритм "сдвиг-свертка" для грамматики операторного предшествования в целом похож на алгоритм для грамматик простого предшествования. Он выполняется тем же МП-автоматом и имеет те же условия завершения и обнаружения ошибок. Основное отличие состоит в том, что при работе со стеком в этом алгоритме не принимаются во внимание находящиеся в нем нетерминальные символы, и при сравнении ищется ближайший к верхушке стека терминальный символ. Однако после выполнения сравнения и определения границ основы при поиске правила в грамматике нетерминальные символы следует, безусловно, принимать во внимание. Шаг 1. Поместить в верхушку стека символ ^ н. Шаг 2. Сравнить символ, находящийся на вершине стека, игнорируя все нетерминальные символы, с текущим символом ленты. Шаг 3. Если имеет место отношение < или =, то произвести перенос и вернуться к шагу 2. Шаг 4. Если имеет место отношение >, то произвести свертку, то есть найти на вершине стека (опять же игнорируя нетерминальные символы) все символы, связанные отношением = (основу) и заменить их на левую часть соответствующего правила грамматики (при выборе правила нетерминальные символы должны учитываться). Если разбор не закончен, то вернуться к шагу 2. Конечная конфигурация автомата совпадает с конфигурацией при распознавании цепочек грамматик простого предшествования. Пример построения распознавателя для грамматики операторного предшествования. Рассмотрим в качестве примера грамматику G({S,B,T,J},{-,&,^,(,),p},P,S) (терминальные символы выделены жирным шрифтом): P: S ® -B (правило 1) Видно, что эта грамматика является грамматикой операторного предшествования. Построим множества крайних левых и крайних правых символов L(U), R(U) относительно всех нетерминальных символов грамматики. Результат построения приведен в табл. 2. На основе полученных множеств построим множества крайних левых и крайних правых терминальных символов Lt(U), Rt(U) относительно всех нетерминальных символов грамматики. Результат (второй и третий шаги построения) приведен в табл. 3.
Таблица 2. Множества крайних правых и крайних левых символов грамматики (по шагам построения)
Таблица 3. Множества крайних правых и левых терминальных символов грамматики (по шагам построения)
На основе этих множеств и правил грамматики G построим матрицу предшествования грамматики (табл. 4). Таблица 4. Матрица предшествования грамматики
Посмотрим, как заполняется матрица предшествования в табл. 4 на примере символа &. В правиле грамматики B ® B&T (правило 3) этот символ стоит слева от нетерминального символа T. В множество Lt(T) входят символы: ^ (p. Ставим знак < в клетках матрицы, соответствующих этим символам, в строке для символа &. В то же время в этом же правиле символ & стоит справа от нетерминального символа B. В множество Rt(B) входят символы: & ^) p. Ставим знак > в клетках матрицы, соответствующим этим символам, в столбце для символа &. Больше символ & ни в каком правиле не встречается, значит заполнение матрицы для него закончено, берем следующий символ и продолжаем заполнять матрицу таким же методом. Алгоритм разбора цепочек грамматики операторного предшествования игнорирует нетерминальные символы. Поэтому имеет смысл преобразовать исходную грамматику таким образом, чтобы оставить в ней только один нетерминальный символ. Тогда получим следующий вид правил: P: E ® -E (правило 1) E ® E | E&E (правила 2 и 3) E ® E | E^E (правила 4 и 5) E ® (E) | p (правила 6 и 7) Это преобразование не ведет к созданию эквивалентной грамматики и выполняется только после построения всех множеств и матрицы предшествования. Само преобразование выполняется только с целью более эффективного выполнения алгоритма разбора, в который уже заложены необходимые данные о порядке применения правил при создании матрицы предшествования . Рассмотрим работу алгоритма распознавания на примерах. Последовательность разбора будем записывать в виде последовательности конфигураций МП-автомата из трех составляющих: не просмотренная автоматом часть входной цепочки, содержимое стека и последовательность правил грамматики. Так как автомат имеет только одно состояние, то для определения его конфигурации достаточно двух составляющих - положения считывающей головки во входной цепочке и содержимого стека, - но последовательность номеров правил несет дополнительную полезную информацию, которая должна быть затем использована компилятором на последующих этапах для семантической обработки и для генерации кода объектной программы. (Кроме того, последовательность примененных правил делает пример более наглядным). Будем обозначать такт автомата символом ¸. Введем также дополнительное обозначение ¸ п, если на данном такте выполнялся перенос, и ¸ с, если выполнялась свертка. Последовательности разбора цепочек входных символов будут, таким образом, иметь вид: Пример 1. Входная цепочка -p&p^(p). {-p&p^(p)^ к; ^ н; Æ } ¸ п {p&p^(p)^ к; ^ н-; Æ } ¸ п {&p^(p)^ к; ^ н-p; Æ } ¸ с {&p^(p)^ к; ^ н-E; 7} ¸ п {p^(p)^ к; ^ н-E&; 7} ¸ п {^(p)^ к; ^ н-E&p; 7} ¸ с {^(p)^ к; ^ н-E&E; 7,7} ¸ п {(p)^ к; ^ н-E&E^; 7,7} ¸ п {p)^ к; ^ н-E&E^(; 7,7} ¸ п {)^ к; ^ н-E&E^(p; 7,7} ¸ с {)^ к; ^ н-E&E^(E; 7,7,7} ¸ п Пример 2. Входная цепочка -p^p(p). {-p^p(p)^ к; ^ н; Æ } ¸ п {p^p(p)^ к; ^ н-; Æ } ¸ п {^p(p)^ к; ^ н-p; Æ } ¸ с {^p(p)^ к; ^ н-E; 7} ¸ п Пример 3. Входная цепочка -p^p&p. {-p^p&p^ к; ^ н; Æ } ¸ п {p^p&p^ к; ^ н-; Æ } ¸ п {^p&p^ к; ^ н-p; Æ } ¸ с {^p&p^ к; ^ н-E; 7} ¸ п Пример 4. Входная цепочка -p&p^p. {-p&p^p^ к; ^ н; Æ } ¸ п {p&p^p^ к; ^ н-; Æ } ¸ п {&p^p^ к; ^ н-p; Æ } ¸ с {&p^p^ к; ^ н-E; 7} ¸ п Два последних примера наглядно демонстрируют, что приоритет операций, установленный в грамматике, влияет на последовательность разбора и последовательность применения правил. Общий алгоритм работы синтаксического анализатора Синтаксический анализатор работает, опираясь на построенную матрицу предшествования. На его вход поступает обработанный сканером текст исходной программы. Каждый идентификатор или константа представляются для него некоторым терминальным символом (в примере он обозначен как p, в задании - a). Тогда первым шагом общего алгоритма анализа должно являться построение таблицы лексем (что уже выполнялось в предыдущей работе). По таблице лексем и матрице предшествования выполняется разбор цепочки. Результатом разбора является проверка цепочки на синтаксическую правильность и для правильных цепочек - построение последовательности правил вывода (для неправильных цепочек выдается сообщение об ошибке). Получение последовательности правил - второй шаг общего алгоритма анализа. По последовательности правил легко строится цепочка вывода и дерево синтаксического разбора. Дерево строится сверху вниз путем последовательного применения правил. При построении дерева следует учитывать, что алгоритм разбора порождает правосторонний вывод, поэтому на каждом шаге на основе правила в цепочке следует заменять крайний правый нетерминальный символ (нижний правый в дереве). Это третий шаг общего алгоритма анализа. Цепочки вывода для двух из рассмотренных выше примеров будут иметь следующий вид: Пример 3. Входная цепочка -p^p&p. E ® -E ® -E&E ® -E&p ® -E^E&p ® -E^p&p ® -p^p&p Пример 4. Входная цепочка -p&p^p. E ® -E ® -E&E ® -E&E^E ® -E&E^p ® -E&p^p ® -p&p^p Деревья вывода для этих двух примеров приведены на рис. 4. После построения дерева остается заменить терминальные символы (p или a) грамматики на соответствующие константы и идентификаторы из таблицы лексем. Для этого достаточно просматривать таблицу от начала к концу и, обходя построенное дерево от корня сверху вниз слева направо, последовательно заменить все листья, помеченные искомым символом, на лексемы из таблицы. Это последний шаг общего алгоритма работы синтаксического анализатора. Построенное дерево и будет деревом синтаксического разбора предложения грамматики. Содержание отчета
Введение 1 Постановка задачи 2 Описание программы 3 Руководство оператора 4 Программа и методика испытаний Заключение Библиография Приложения (текст программы)
Раздел «Описание программы» должен соответствовать требованиям ГОСТ 19.101-77, «Руководство оператора» - ГОСТ 19.105—78, программа и методика испытаний - ГОСТ 19.105-78 (приложение А). БИБЛИОГРАФИЯ
Группа Т55 МЕЖГОСУДАРСТВЕННЫЙ СТАНДАРТ Единая система программной документации ГОСТ 19.701-90 (ИСО 5807-85) СХЕМЫ АЛГОРИТМОВ, ПРОГРАММ, ДАННЫХ И СИСТЕМ Обозначения условные и правила выполнения
ОКСТУ 5004 Дата введения 01.01.92 Настоящий стандарт распространяется на условные обозначения (символы) в схемах алгоритмов, программ, данных и систем и устанавливает правила выполнения схем, используемых для отображения различных видов задач обработки данных и средств их решения. Стандарт не распространяется на форму записей и обозначений, помещаемых внутри символов или рядом с ними и служащих для уточнения выполняемых ими функций. Требования стандарта являются обязательными. 1. ОБЩИЕ ПОЛОЖЕНИЯ Схемы алгоритмов, программ, данных и систем (далее — схемы) состоят из имеющих заданное значение символов, краткого пояснительного текста и соединяющих линий. Схемы могут использоваться на различных уровнях детализации, причем число уровней зависит от размеров и сложности задачи обработки данных. Уровень детализации должен быть таким, чтобы различные части и взаимосвязь между ними были понятны в целом. В настоящем стандарте определены символы, предназначенные для использования в документации по обработке данных, и приведено руководство по условным обозначениям для применения их в:
схемах данных; схемах программ; схемах работы системы; схемах взаимодействия программ; схемах ресурсов системы.
ГОСТ 19.701—90 1.4. В стандарте используются следующие понятия: 1) основной символ - символ, используемый в тех случаях, когда точный тип (вид) процесса или носителя данных неизвестен или отсутствует необходимость в описании фактического носителя данных; специфический символ — символ, используемый в тех случаях, когда известен точный тип (вид) процесса или носителя данных или когда необходимо описать фактический носитель данных; схема — графическое представление определения, анализа или метода решения задачи, в котором используются символы для отображения операций, данных, потока, оборудования и т. д. 2. ОПИСАНИЕ СХЕМ 2.1. Схема данных Схемы данных отображают путь данных при решении задач и определяют этапы обработки, а также различные применяемые носители данных. Схема данных состоит из: символов данных (символы данных могут также указывать вид носителя данных); символов процесса, который следует выполнить над данными (символы процесса могут также указывать функции, выполняемые вычислительной машиной); символов линий, указывающих потоки данных между процессами и (или) носителями данных; специальных символов, используемых для облегчения написания и чтения схемы. 2.1.3. Символы данных предшествуют и следуют за символами процесса. Схема данных начинается и заканчивается символами данных (за исключением специальных символов, указанных в п. 3.4). 2.2. Схема программы Схемы программ отображают последовательность операций в программе. Схема программы состоит из: 1) символов процесса, указывающих фактические операции обработки данных (включая символы, определяющие путь, которого следует придерживаться с учетом логических условий); линейных символов, указывающих поток управления; специальных символов, используемых для облегчения написания и чтения схемы. 2.3. Схема работы системы 2.3.1. Схемы работы системы отображают управление операциями и поток данных в системе. 2.3.2. Схема работы системы состоит из: 1) символов данных, указывающих на наличие данных (символы данных могут также указывать вид носителя данных); 2) символов процесса, указывающих операции, которые следует выполнить над данными, а также определяющих логический путь, которого следует придерживаться; 3) линейных символов, указывающих потоки данных между процессами и (или) носителями данных, а также поток управления между процессами; 4) специальных символов, используемых для облегчения написания и чтения блок-схемы. 2.4. Схема взаимодействия программ 2.4.1. Схемы взаимодействия программ отображают путь активаций программ и взаимодействий с соответствующими данными. Каждая программа в схеме взаимодействия программ показывается только один раз (в схеме работы системы программа может изображаться более чем в одном потоке управления). 2.4.2. Схема взаимодействия программ состоит из: 1) символов данных, указывающих на наличие данных; 2) символов процесса, указывающих на операции, которые следует выполнить над данными; 3) линейных символов, отображающих поток между процессами и данными, а также инициации процессов; 4) специальных символов, используемых для облегчения написания и чтения схемы. 2.5. Схема ресурсов системы 2.5.1. Схемы ресурсов системы отображают конфигурацию блоков данных и обрабатывающих блоков, которая требуется для решения задачи или набора задач. 2.5.2. Схема ресурсов системы состоит из: 1) символов данных, отображающих входные, выходные и запоминающие устройства вычислительной машины; 2) символов процесса, соображающих процессоры (центральные процессоры, каналы и т. д.); 3) линейных символов, отображающих передачу данных между устройствами ввода-вывода и процессорами, а также передачу управления между процессорами; 4) специальных символов, используемых для облегчения написания и чтения схемы, Примеры выполнения схем приведены в приложении. 3. ОПИСАНИЕ СИМВОЛОВ 3.1. Символы данных 3.1.1. Основные символы данных 3.1.1.1. Данные 3.1.1.2, Запоминаемые данные Символ отображает хранимые данные в виде, пригодном для обработки, носитель данных не определен.
3.1.2. Специфические символы данных 3.1.2.1. Оперативное запоминающее устройство Символ отображает данные, хранящиеся в оперативном запоминающем устройстве.
3.1.2.2. Запоминающее устройство с последовательным доступом Символ отображает данные, хранящиеся в запоминающем устройстве с последовательным доступом (магнитная лента, кассета с магнитной лентой, магнитофонная кассета).
3.1,2,3, Запоминающее устройство с прямым доступом Символ отображает данные, хранящиеся в запоминающем устройстве с прямым доступом (магнитный диск, магнитный барабан, гибкий магнитный диск).
3.1.2.4. Документ Символ отображает данные, представленные на носителе в удобочитаемой форме (машинограмма, документ для оптического или магнитного считывания, микрофильм, рулон ленты с итоговыми данными, бланки ввода данных).
3.1.2.5. Ручной ввод Символ отображает данные, вводимые вручную во время обработки с устройств любого типа (клавиатура, переключатели, кнопки, световое перо, полоски со штриховым кодом).
3.1.2.6. Карта Символ отображает данные, представленные на носителе в виде карты (перфокарты, магнитные карты, карты со считываемыми метками, карты с отрывным ярлыком, карты со сканируемыми метками).
3.1.2.7. Бумажная лента Символ отображает данные, представленные на носителе в виде бумажной ленты
3.1.2.8 .Дисплей Символ отображает данные, представленные в человекочитаемой форме на носителе в виде отображающего устройства (экран для визуального наблюдения, индикаторы ввода информации).
3.2. Символы процесса 3.2.1. Основные символы процесса 3.2.1.1. Процесс
Символ отображает функцию обработки данных любого вида (выполнение определенной операции или группы операций, приводящее к изменению значения, формы или размещения информации или к определению, по которому из нескольких направлений потока следует двигаться).
3.2.2. Специфические символы процесса 3.2.2.1. Предопределенный процесс Символ отображает предопределенный процесс, состоящий из одной или нескольких операций или шагов программы, которые определены в другом месте (в подпрограмме, модуле).
3.2.2.2. Ручная операция
Символ отображает любой процесс, выполняемый человеком. 3.2.2.3. Подготовка Символ отображает модификацию команды или группы команд с целью воздействия на некоторую последующую функцию (установка переключателя, модификация индексного регистра или инициализация программы) .
3.2.2.4. Решение Символ отображает решение или функцию переключательного типа, имеющую один вход и ряд альтернативных выходов, один и только один из которых может быть активизирован после вычисления условий, определенных внутри этого символа. Соответствующие результаты вычисления могут быть записаны по соседству с линиями, отображающими эти пути.
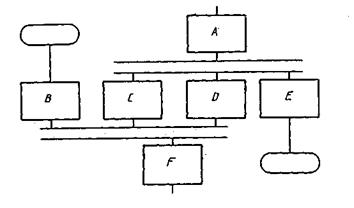
3.2.2.5. Параллельные действия Символ отображает синхронизацию двух или более параллельных операций.
Пример.
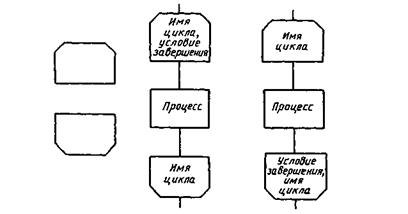
Примечание. Процессы С, D и Е не могут начаться до тех пор, пока не завершится процесс А; аналогично процесс F должен ожидать завершения процессов В, С и D, однако процесс С может начаться и (или) завершиться прежде, чем соответственно начнется и (или) завершится прочей: D. 3.2.2.6. Граница цикла Символ, состоящий из двух частей, отображает начало и конец цикла. Обе части символа имеют один и тот же идентификатор. Условия для инициализации, приращения, завершения и т. д. помещаются/ внутри символа в начале или в конце в зависимости от расположения операции, проверяющей условие.
Пример
3.3, Символы линий 3.3.1. Основной символ линий 3.3,1.1. Линия Символ отображает поток данных или управления.
При необходимости или для повышения удобочитаемости могут быть добавлены стрелки-указатели. 3.3.2. Специфические символы линий 3,3,2.1, Передача управления Символ отображает непосредственную передачу управления от одного процесса к другому, иногда с возможностью прямого возвращения к инициирующему процессу после того, как инициированный процесс завершит свои функции. Тип передачи управления должен быть назван внутри символа (например, запрос, вызов, событие).
3.3.2.2. Канал ев язи Символ отображает передачу данных по каналу связи.
3.3.2 3. Пунктирная линия Символ отображает альтернативную связь между двумя или более символами. Кроме того, символ используют для обведения аннотированного участка. Пример 1. Если один из ряда альтернативных выходов используют в качестве входа в процесс либо когда выход используется в качестве входа в альтернативные процессы, эти символы соединяют пунктирными линиями.
Пример 2. ' ' ' Выход, используемый в качестве входа в следующий процесс, может быть соединен с этим входом с помощью пунктирной линии.
3.4. Специальные символы
3.4.1. Соединитель Символ отображает выход в часть схемы и вход из другой части этой схемы и используется для обрыва линии и продолжения ее в другом месте. Соответствующие символы-соединители должны содержать одно и то же уникальное обозначение.
3.4.2. Терминатор Символ отображает выход во внешнюю среду и вход из внешней среды (начало или конец схемы программы, внешнее использование и источник или пункт назначения данных).
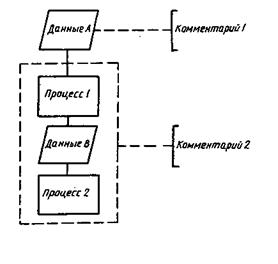
3.4.3. Комментарий Символ используют для добавления описательных комментариев или пояснительных записей в целях объяснения или примечаний. Пунктирные линии в символе комментария связаны с соответствующим символом или могут обводить группу символов. Текст комментариев или примечаний должен быть помещен около ограничивающей фигуры.
3.4 4. Пропуск Символ (три точки) используют в схемах для отображения пропуска символа или группы символов, в которых не определены ни тип, ни число символов. Символ используют только в символах линии или между ними. Он применяется главным образом в схемах, изображающих общие решения с неизвестным числом повторений.
Пример.
Пример.
4.1.6.Если объем текста, помещаемого внутри символа, превышает его размеры, следует использовать символ комментария. 4.1.7.Если использование символов комментария может запутать или разрушить ход схемы, текст следует помещать на отдельном листе и давать перекрестную ссылку на символ. 4.1.8.4.1.5. В схемах может использоваться идентификатор символов. Это связанный с данным символом идентификатор, который определяет символ для использования в справочных целях в других элементах документации (например, в листинге программы). Идентификатор символа должен располагаться слева над символом. Пример.
4.1.9. В схемах может использоваться описание символов — любая другая информация, например для отображения специального применения символа с перекрестной ссылкой или для улучшения понимания функции как части схемы. Описание символа должно быть расположено справа над символом. Пример.
4.1.10. В схемах работы системы символы, отображающие носители данных, во многих случаях представляют способы ввода-вывода. Для использования в качестве ссылки на документацию текст на схеме для символов, отображающих способы вывода, должен размещаться справа над символом, а текст для символов, отображающих способы ввода,— справа под символом. 4.1.11.Пример.
4.1.8. В схемах может использоваться подробное представление, которое обозначается с помощью символа с полосой для процесса или данных, Символ с полосой указывает, что в этом же комплекте документации в другом месте имеется более подробное представление. Символ с полосой представляет собой любой символ, внутри которого в верхней части проведена горизонтальная линия. Между этой линией и верхней линией символа помещен идентификатор, указывающий на подробное представление данного символа. В качестве первого и последнего символа подробного представления должен быть использован символ указателя конца. Первый символ указателя конца должен содержать ссылку, которая имеется также в символе с полосой,
4.2. Правила выполнения соединений 4.2.1. Потоки данных или потоки управления в схемах показываются линиями. Направление потока слева направо и сверху вниз считается стандартным. В случаях, когда необходимо внести большую ясность в схему (например, при соединениях), на линиях используются стрелки. Если поток имеет направление, отличное от стандартного, стрелки должны указывать это направление. 4.2.2. В схемах следует избегать пересечения линий. Пересекающиеся линии не имеют логической связи между собой, поэтому изменения направления в точках пересечения не допускаются. Пример.
4.2.3, Две или более входящие линии могут объединяться в одну исходящую линию. Если две или более линии объединяются в одну линию, место объединения должно быть смещено. Пример.
4.2.4.Линии в схемах должны подходить к символу либо слева, либо сверху, а исходить либо справа, либо снизу. Линии должны быть направлены к центру символа. 4.2.5.При необходимости линии в схемах следует разрывать для избежания излишних пересечений или слишком длинных линий, а также, если схема состоит из нескольких страниц. Соединитель в начале разрыва называется "внешним соединителем, а соединитель в конце разрыва — внутренним соединителем. 4.2.6.Ссылки к страницам могут быть приведены совместно с символом комментария для их соединителей. Пример.
4.3. Специальные условные обозначения 4.3.1. Несколько выходов 4.3.1.1. Несколько выходов из символа следует показывать: 1) несколькими линиями от данного символа к другим символам; 2) одной линией от данного символа, которая затем разветвляется в соответствующее число линий. 4.3.1.2. Каждый выход из символа должен сопровождаться соответствующими значениями условий, чтобы показать логический, путь, который он представляет, с тем, чтобы эти условия и соответствующие ссылки были идентифицированы. Примеры.
4.3.2. Повторяющееся представление 4.3.2.1. Вместо одного символа с соответствующим текстом могут быть использованы несколько символов с перекрытием изображения, каждый из которых содержит описательный текст (использование или формирование нескольких носителей данных или файлов, производство множества копий печатных отчетов или форматов перфокарт). 4.3.2.2. Когда несколько символов представляют упорядоченное множество, это упорядочение должно располагаться от переднего (первого) к заднему (последнему), 4.3.2.3. Линии могут входить или исходить из любой точки перекрытых символов, однако требования п. 4.2,4 должны соблюдаться. Приоритет или последовательный порядок нескольких символов не изменяется посредством точки, в которой линия входит или из которой исходит.
ПРИМЕНЕНИЕ СИМВОЛОВ
ПРИМЕРЫ ВЫПОЛНЕНИЯ СХЕМ 1. Схема данных
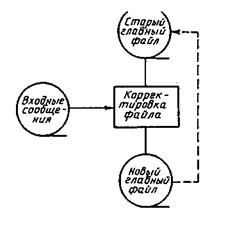
Пример 1.
ИНФОРМАЦИОННЫЕ ДАННЫЕ 1. РАЗРАБОТАН И ВНЕСЕН Государственным комитетом СССР по вычислительной технике и информатике РАЗРАБОТЧИКИ А.А. Мкртумян (руководитель разработки); АЛ. Щерс, д-р техн. наук; А.Н. Сироткин, канд. ист. наук; Л.Д. Райков, канд. техн. наук; А.В. Лобова; межведомственная Рабочая группа по разработке стандартов ЕСПД 2. УТВЕРЖДЕН И ВВЕДЕН В ДЕЙСТВИЕ Постановлением Государственного комитета СССР по управлению качеством продукции и стандартам от 26.12.90 №3294 3. Настоящий стандарт разработан методом прямого применения между народного стандарта ИСО 5807-85 "Обработка информации. Символы и условные обозначения блок-схем данных, программ и систем, схем программных сетей и системных ресурсов" 4. ВЗАМЕН ГОСТ 19.002-80, ГОСТ 19.003-SO 5. Переиздание
РАЗРАБОТКА МОДУЛЯ ТРАНСЛЯТОРА
Методические указания
для выполнения курсового проекта по дисциплине «Системное программное обеспечение» для студентов дневной формы обучения
Севастополь 2012 УДК 519.6 Разработка модуля учебной операционной системы: Методические указания по дисциплине «Операционные системы» для студентов дневной формы обучения / Сост. Г.Г.Сергеев, С.Н. Фисун. – Севастополь: Изд-во СевНТУ, 2012. – 46с.
Целью методических указаний является оказание помощи студентам в выполнении курсового проекта по дисциплине «Операционные системы».
Методические указания рассмотрены и утверждены на заседании кафедры КиВТ (протокол № 12 от 26.06.2011 г.).
Допущено учебно-методическим центром СевНТУ в качестве методических указаний.
Рецензенты:
Овчинников А.Л. – старший преподаватель кафедры информационных систем СевНТУ. СОДЕЖАНИЕ ВВЕДЕНИЕ.. 4 1 Теоретический раздел. 4 1.1 Проектирование лексического анализатора. 4 1.2 Синтаксический анализ. 10 1.2.1 Распознавание цепочек КС-языков. 10 1.2.2 Грамматики предшествования. 11 1.2.3 Cинтаксический анализ для LL(1)-грамматики. 18 1.3 Генерация и оптимизация кода. 21 1.3.1 Алгоритм генерации объектного кода по дереву вывода. 22 1.3.2 Оптимизация объектного кода методом свертки. 25 2 Порядок выполнения курсового проекта. 29 3 Варианты заданий. 30 4 Содержание отчета. 36 Библиография. 37
ВВЕДЕНИЕ
Цель курсового проекта: изучить теоретические основы построения модулей транслятора. Получить практические навыки разработки системного программного обеспечения.
Теоретический раздел
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-05-07; Просмотров: 310; Нарушение авторского права страницы