
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Адресация памяти в реальном режиме. Сегментация памяти, сегментные регистры.Стр 1 из 15Следующая ⇒
Клавиатура. Клавиатурный буфер. Клава включает в себя сложную топологию проводников, и даже собственный микропроцессор - контроллер. Буфер устроен как циклическая очередь (FIFO - "первым записан - первым считан"). Он занимает непрерывную область адресов памяти с адреса 0040:001Е. Указатели на голову и хвост расположены по адресам 0040:001А и 0040:001С соответственно. Имеет длину 32 байта. Полученный в резул-те преобразований в контроллере двухбайтовый код посылается в кольцевой буфер ввода, который служит для синхронизации ввода данных с клавиатуры и приёма их выполняемой программой. При переполнении буфера новые коды в него не поступают, а нажатие на клавиши вызывает предупреждающие сигналы.
Когда оба указателя равны, буфер пуст. 001Eh и 003Eh адреса начала и конца буфера. Указателями на начало и конец клавиатурного буфера обычно управляют обработчики прерываний INT 09h и INT 16h. Программа извлекает из буфера коды нажатых клавиш, используя различные функции прерывания INT 16h.
Видеосистемы Одной из наиболее важных составных частей любого персонального компьютера является его видеосистема. Под этим понятием обычно подразумевают монитор (дисплей), видеоадаптер и набор соответствующих программ-драйверов, поставляемых в комплекте с видеоадаптером или в составе прикладных пакетов. Самая заметная, крупная дорогая часть видеосистемы – дисплей или монитор. Он характер-ся несколькими св-вами: · Цвет, Размер, Зерно, Максим-ое разреш-е, Вертикал.развёртка(частота смены изобр-ий (85Гц)) Основное назначение видеоадаптера – формирование сигналов, в соответствии с которыми монитор может отображать ту или иную информацию на экране. С помощью видеоадаптера формир-ся изобр-я с различными разреше-ми: от 640 ´ 480 до 1600 ´ 1280 точек. Не меньшее знач-е имеет и глубина цвета, то есть кол-во битов, выдел-ых для кодиров-я инфо о цвете одного пикселя. В настоящ.время распространены след.стандарты на это кол-во: 8 бит (256 цветов),16 бит (65 536 цветов — так называемый High Color),24 бит (16 777 216 цветов — True Color). Видеоадаптер состоит главным образом из 1. набора микросхем (chipset) (в настоящее время, как правило, одной интегрированной схемы). 2. цифро-аналогового преобразователя (нередко также выполняется встроенным в основную микросхему), 3. ПЗУ (так называемый BIOS видеоадаптера) и 4. самой платы с закрепленными на ней клеммами и разъемами. На каждой видеоплате размещ-ся ОП, как правило, обладающая более высокими хар-ми, чем та, что исп-ся в составе ОП компьютера. Блок схема видеоадаптеров EGA/VGA
Существует несколько стандартных режимов работы видеоадаптеров, определенных фирмой IBM. Любой из этих режимов можно инициировать конструкцией типа: mov ah,00h mov al,Mode ;Номер видеорежима int 10h Некот-ые режимы работы видеоадаптеров
При изменении 11 и 12 строки может получить такое: Все видеосистемы ПК, кроме MDA, могут работать в любом из двух режимов: текстовом или графическом. Главное их различие – в способе интерпретации содержимого видеобуфера.
Графический. При этом имеется доступ к каждой элементарной точке экрана – пикселю. Пользователь может установить её в нужный ему цвет, но даже вывод букв или знаков, а тем более графических изображений, достаточно сложен. Каждая точка имеет свою координату. При этом каждая точка может быть установлена в любой цвет из числа допустимых, например, из 256 цветов (разрешение 320´200, 256 цветов – видеорежим 13h). В компенсацию своей сложности и медлительности графический режим позволяет изображать на экране всё, что ни пожелает пользователь. Текстовый. В текстовых режимах (режимы 0,1,2,3) на экране могут отображаться текстовые символы, а также символы псевдографики. Для кодирования каждого символа используется два байта. Первый из них содержит ASCII-код отображаемого символа, который находится в нулевом цветовом слое, а второй - атрибуты символа, которые находятся в первом цветовом слое. Коды символов имеют четные адреса, а атрибуты - нечетные. Атрибуты определяют цвет символа и цвет фона. Благодаря такому режиму хранения информации достигается значительная экономия памяти по сравнению с графическим режимом При отображении символа на экране происходит преобразование его из формата ASCII в двумерный массив пикселей, выводимых на экран. Для этого преобразования используется таблица трансляции символов (таблица знакогенератора).
Текстовый режим прост и быстр, однако он сильно ограничивает возмож-ти польз-ля по выводу инфо. Всякий цвет на экране является композицией трёх основных цветов – красного (red), зелёного (green) и синего (blue). В простейшем случае кодировка заключается в установке или сбросе соответствующего бита. Таким образом формируются восемь цветов. К используемым в этом случае трём битам добавляется четвёртый – яркость (brightness) или интенсивность (intensity). Эта комб-ция наз-ся IRGB-цветом. Простейшие вар-ты кодиров-я цветов сведены в таблицу. Для хранения цветовых атрибутов символа в памяти компьютера отводится один байт: · старшие четыре бита (с 7-го по 4-й) заняты под кодирование фона символа (7-й бит – атрибут мерцания); биты 6–4 – стандартные цвета; · младшие четыре бита (с 3-го по 0-й) заняты под кодирование переднего плана символа.
БАЙТ АТРИБУТА СИМВОЛА Каждый символ, отображаемый на экране в текстовом режиме, определяется не только своим кодом ASCII, но и байтом атрибутов. Атрибуты задают цвет символа, цвет фона а также некоторые другие параметры
D2-D0 - Цвет символа. D3 - Интенсивность символа и выбор таблицы знакогенератора. D6-D4 - Цвет фона символа. D7 - Мигание символа или интенсивность фона символа. Регистры видеоадаптеров EGA и VGA Программирование видеоадаптеров на уровне регистров позволяет увеличить скорость работы программ и решить некоторые задачи, которые нельзя решить только при помощи функций BIOS По признаку выполняемых функций можно выделить следующие группы регистров: Внешние рег-ры, рег-ры контроллера ЭЛТ , рег-ры синхрониз-ра, рег-ры графич.контроллера, рег-ры контроллера атриб-ов, рег-ры цифро-аналогового преобраз-ляVGA,Нестанд-ые режимы видеоадаптера VGA Видеопамять – область оперативной памяти, предназначенная для хранения текста или графической информации, выводимой на экран. В различных режимах работы монитора эта область имеет различный начальный адрес и разную длину, например: *MDA – с адресаB000:0000 до B000:0FFF длиной 4К; *CGA – от B800:0000 до B800:3FFF длиной 16К;
Измен-е какого-либо байта в этой области приводит к измен-ю изображ-я на экране. Того же резул-та можно достичь при выводе нужной инфо на экран, но если скорость записи напрямую в видеобуфер составляет сотни тысяч байт в секунду, то дисплей воспринимает новые данные со скоростью около 1000 байт в секунду (при этом содержимое экрана меняется за 2 секунды) Видеостраницы Как уже упоминалось ранее, всякий экран содержит 2000 символов (например, пустой – 2000 пробелов), каждый из кот-ых характ-ся кодом в таблице ASCII (один байт), цветом фона (1/2 байта) и цветом переднего плана (1/2 байта). Т.о., для хранения всего содержимого экрана необходим V памяти в 4000 байт; именно такая часть (точнее, 4096 байт) видеопамяти называется видеостраницей. Поскольку объём видеопамяти обычно больше этого числа (например, 32К для видеоадаптеров VGA), то имеется возмож-ть организ-ть хранение данных сразу в неск-ких видеостраницах (до 8), по-прежнему демонстрируя на экране только одну из них. В памяти компа это выглядит так:
Нек-ые области между страницами окрашены в серый цвет – это те самые 96 байт, коты-е не исп-ся для вывода информации, а нужны только для получения более "круглых" адресов начал видеостр-ц. Содержимое этих 96 байт не испол-ся комп-ом, и польз-ль может распоряжаться ими по своему усмотрению. Несмотря на то, что хранить и формировать можно все 8 страниц, на экран выводится только одна из них (она получает название активной). Этим можно воспользоваться для создания простых эффектов мультипликации в текстовом режиме – переключаясь между страницами (а это происходит моментально), можно "оживить" какие-нибудь изображения. При помощи функций BIOS или непосредственного программирования регистров видеоадаптера можно переключать активные страницы видеопамяти. Вывод информации можно производить как в активную, так и в неактивные страницы памяти. Т.о. можно подготовить несколько страниц памяти (несколько экранов), а затем быстро сменять их на экране дисплея. Внутри самой видеостраницы запись характеристик символа происходит следующим образом: · первым байтом записывается код символа; · во втором байте хранится информация и цветах: · 4 бита – описание цвета фона для символа; · 4 бита – описание цвета переднего плана символа. Таким образом, связь между адресами видеопамяти, характеристиками символа и его экранными координатами выглядит следующим образом (здесь, как обычно, первая координата экрана – х (столбец), число в промежутке от 0 до 79; вторая координата – у (строка), число от 0 до 24):
Функции блокировки диска Поскольку виндос многозадачная ОС к одному и тому же диску одновременно могут обращаться несколько приложений. Программы, изменяющие стр-ру файловой системы, могут подтвердить данные хранящиеся на диске. Чтобы предотвратить потери данных, система берет на себя управление всеми запросами на прямую доступом к диску. Дисковые утилиты и другие проги, напрямую изменяющие системные области диска должны перед внесением каких либо измен-ий в файловую систему применять монопольную блокировку тома. Это предотвращает случ.запись на диск др. приложениями в момент, когда дисковая утилита модифицирует файловую систему. Обычно виндос не разрешает примен-ие операций записи если диск не заблокирован данным приложением. Ф-ии и прерыв-я с помощью кот-ых прога пытается напрямую записать данные на незаблокированный том возвращает код ошибки errorwriteprotect. Если прилож-е попыт-ся напрямую считать данные с тома, система может вернуть данные из внутр.кеша а не с самого носителя. Система также перехватывает все попытки прямого доступа к портам вв дискового контроллера. Чтобы изменить стандартн.повед-е системы прога запрашивает монопольное исполн-е тома через inpu output ф-ции блок-ки и разблок-ки. Поскольку система сбрасывает внутр. кеша на диск инфо на нем отражает фактическое состояние тома. Блок-ка тома обеспечения непротиворечивости данных т.к. др.процессы не могут что-л. модиф-ть на таком томе. Виндос обеспечивает 4 уровня монопольной блокировки тома.
12) Правила блокировки диска
Нулевой уровень. Блокировка данного уровня невозможна для диска, на котором открыты файлы или описатели. Поэтому приложение никогда не получит блокировку нулевого уровня на томе с системными файлами Шаг 1. Необходимо получить блокировку нулевого уровня Шаг 2. Вызов функции блокировки тома Шаг 3. Сброс данных из КЭШа на диск Шаг 4. Получение блокировки нулевого уровня Шаг 5. Выполнение операций файлового ввода-вывода Шаг 6. Вызов функции блокировки тома. Ужесточение блокировки нулевого уровня Шаг 7. Форматирование диска Первый уровень. Блокир-ка данного уровня устанавл-ся, чтобы не позволить др.процессам заблокир-ть тот же диск. Так же на этом уровне для приложений устанавл-тся права доступа.Второй уровень. Блокир-ка данного уровня запрещает другим процессам запись на диск, но разрешает чтение с диска.Третий уровень. Блокир-ка данного уровня запрещает другим процессам как чтение, так и запись на диск. Правила блокировки дисков • Если на диске нет открытых файлов, то прямая запись выполняется при установленной блокировке нулевого уровня. В противном случае используется иерархия блокировок 1-3 уровня. • Приложение не должно перемещать файл подкачки • Для уменьшения времени блокировки уровня 3 приложение на этом уровне должно выполнять только дисковый ввод-вывод. • Приложение должно обращаться к диску через низкоуровневые функции.
Синтаксис и семантика языка Синтаксис языка - это набор правил, определяющий допустимые конструкции языка. Синтаксис определяет «форму языка» - задает набор цепочек символов, которые принадлежат языку. Чаще всего синтаксис языка можно задать в виде строгого набора правил, но полностью это утверждение справедливо только для чисто формальных языков. Например, строка «3+2» является арифметическим выражением, «3 2 +» - не является. Семантика языка - это раздел языка, определяющий значение предложений языка. Семантика определяет «содержание языка» - задает значение для всех допустимых цепочек языка. Например, используя семантику алгебры мы можем сказать, что строка «3+2» есть сумма чисел 3 и 2, а также то, что «3+2 = 5» - это истинное выражение Лексика - это совокупность слов (словарный запас) языка. Слово или лексическая единица (лексема) языка - это конструкция, которая состоит из элементов алфавита языка и не содержит в себе других конструкций. Грамматика - это описание способа построения предложений некоторого языка. Иными словами, грамматика - это математическая система, определяющая язык. Формально порождающая грамматика G - это четверка G (VT, VN, P, S), где VT - множество терминальных символов (терминалов), VN - множество нетерминальных символов (нетерминалов), не пересекающееся с VT, P - множество правил (продукций) грамматики вида a ® b, где aÎV+, bÎV*, S - целевой (начальный) символ грамматики, S Î VN. Для записи правил вывода с одинаковыми левыми частями a ® b1 a ® b2 ... a ® bn будем пользоваться сокращенной записью a ® b1 | b2 |...| bn. Каждое bi , i = 1, 2, ... ,n , будем называть альтернативой правила вывода из цепочки a. Такую форму записи правил грамматики называют формой Бэкуса-Наура. Она предусматривает также, что все нетерминальные символы берутся в <> скобки. Пример: <число>::= <цифра>|<цифра><число> <цифра>::= 0|1|2|3|4|5|6|7|8|9 Грамматики G1 и G2 называются эквивалентными, если L(G1) = L(G2). Например, G1 = ({0,1}, {A,S}, P1, S) и G2 = ({0,1}, {S}, P2, S) P1: S ® 0A1 P2: S ® 0S1 | 01 0A ® 00A1 A ® e эквивалентны, т.к. обе порождают язык L(G1) = L(G2) = {0n1n | n>0}. Грамматики G1 и G2 называются почти эквивалентными, если L(G1) = L(G2) È {e}. Другими словами, грамматики почти эквивалентны, если языки, ими порождаемые, отличаются не более, чем на e. Например, G1 = ({0,1}, {A,S}, P1, S) и G2 = ({0,1}, {S}, P2, S) P1: S ® 0A1 P2: S ® 0S1 | e 0A ® 00A1 A ® e почти эквивалентны, т.к. L(G1)={0n1n | n>0}, а L(G2)={0n1n | n>=0}, т.е. L(G2) состоит из всех цепочек языка L(G1) и пустой цепочки, которая в L(G1) не входит. Контекстно-свободная грамматика G называется неоднозначной, если существует хотя бы одна цепочка a Î L(G), для которой может быть построено два или более различных деревьев вывода. Это утверждение эквивалентно тому, что цепочка a имеет два или более разных левосторонних (или правосторонних) выводов. В противном случае грамматика называется однозначной. Язык, порождаемый грамматикой, называется неоднозначным, если он не может быть порожден никакой однозначной грамматикой. Пример неоднозначной грамматики: G = ({if, then, else, a, b}, {S}, P, S), где P = {S ® if b then S else S | if b then S | a}. В этой грамматике для цепочки if b then if b then a else a можно построить два различных дерева вывода. Однако это не означает, что язык L(G) обязательно неоднозначный. Определенная нами неоднозначность - это свойство грамматики, а не языка, т.е. для некоторых неоднозначных грамматик существуют эквивалентные им однозначные грамматики. Если грамматика используется для определения языка программирования, то она должна быть однозначной. В приведенном выше примере разные деревья вывода предполагают соответствие else разным then. Если договориться, что else должно соответствовать ближайшему к нему then, и подправить грамматику G, то неоднозначность будет устранена: S ® if b then S | if b then S’ else S | a S’ ® if b then S’ else S’ | a Проблема, порождает ли данная контекстно-свободная грамматика однозначный язык (т.е. существует ли эквивалентная ей однозначная грамматика), является алгоритмически неразрешимой ТИП 0: Грамматика G = (VT, VN, P, S), V = VN È VT называется грамматикой типа 0, если на ее правила вывода не накладывается никаких ограничений, т.е. правила имеют вид a ® b, где a Î V+, b Î V*. ТИП 1: Грамматику типа 1 можно определить как контекстно-зависимую либо как неукорачивающую. Грамматика G = (VT, VN, P, S), V = VN È VT называется контекстно-зависимой, если каждое правило из P имеет вид a1Aa2 ® a1ba2, где a1, a2 Î V*, A Î VN, b Î V+. Грамматика G = (VT, VN, P, S), V = VN È VT называется неукорачивающей грамматикой, если каждое правило из P имеет вид a ® b, где a, b Î V+ и | b | ³ | a |. Выбор определения не влияет на множество языков, порождаемых грамматиками этого класса, поскольку доказано, что множество языков, порождаемых неукорачивающими грамматиками, совпадает с множеством языков, порождаемых контекстно-зависимыми грамматиками. ТИП 2: Грамматику типа 2 можно определить как контекстно-свободную либо как укорачивающую контекстно-свободную. Грамматика G = (VT, VN, P, S), V = VN È VT называется контекстно-свободной, если каждое правило из Р имеет вид A ® b, где A Î VN, b Î V+. Грамматика G = (VT, VN, P, S), V = VN È VT называется укорачивающей контекстно-свободной, если каждое правило из Р имеет вид A ® b, где A Î VN, b Î V*. Возможность выбора обусловлена тем, что для каждой укорачивающей контекстно-свободной грамматики существует почти эквивалентная ей контекстно-свободная грамматика. ТИП 3: Грамматику типа 3 можно определить либо как праволинейную, либо как леволинейную. Грамматика G = (VT, VN, P, S), V = VN È VT называется праволинейной, если каждое правило из Р имеет вид A ® gB либо A ® g, где A, B Î VN, g Î VT*. Грамматика G = (VT, VN, P, S), V = VN È VT называется леволинейной, если каждое правило из Р имеет вид A ® Bg либо A ® g, где A, B Î VN, g Î VT*. Выбор определения не влияет на множество языков, порождаемых грамматиками этого класса, поскольку доказано, что множество языков, порождаемых праволинейными грамматиками, совпадает с множеством языков, порождаемых леволинейными грамматиками. Определение: язык L(G) является языком типа k, если его можно описать грамматикой типа k. Языки классифицируются в соответствии с типами грамматик, с помощью которых они заданы. ТИП 3: регулярные языки Это самый простой тип языков. Время на распознавание предлож-ий регулярного языка линейно зависит от длины исход.цепочки символов. Данные языки лежат в основе простейших конструкций языков программир-я, на их основе строятся многие мнемокоды команд, а также командные ПР, символьные управляю. команды и др.подобные стр-ры. Регул. языки - очень удобное средство. Для работы с ними можно использ-ть регулярные множ-ва и выраж-я, конечные автоматы. Распознаватели Для каждого языка программирования важно не только уметь построить текст программы на этом языке, но и определить принадлежность имеющегося текста к данному языку. Именно эту задачу решают компиляторы в числе прочих задач. В отношении исходной программы компилятор выступает как распознаватель, а человек, создавший программу на некотором языке, выступает в роли генератора цепочек этого языка. Распознаватель - это специальный алгоритм, который позволяет определить принадлежность цепочки символов некоторому языку. Задача распознавателя заключается в том, чтобы на основании исходной цепочки дать ответ, принадлежит ли она заданному языку или нет. В общем виде распознаватель можно отобразить в виде условной схемы, отображающей работу алгоритма распознавателя, представленной на рисунке.
Как видно из рисунка, распознаватель состоит из следующих основных компонентов: · ленты, содержащей исходную цепочку входных символов, и считывающей головки, обозревающей очередной символ в этой цепочке; · устройства управления (УУ), которое координирует работу распознавателя, имеет некоторый набор состояний и конечную память (для хранения своего состояния и некорой промежуточной информации); · внешней (рабочей) памяти, которая может хранить некоторую информацию в процессе работы распознавателя и в отличие от памяти УУ может иметь неограниченный объем. Распознаватель работает по шагам или тактам. В начале такта, как правило, считывается очередной символ из входной цепочки, и в зависимости от этого символа УУ определяет, какие действия необходимо выполнить. Вся работа распознавателя состоит из последовательности тактов. В начале каждого такта состояние распознавателя определяется его конфигурацией. В процессе работы конфигурация меняется. Конфигурация распознавателя определяется следующими параметрами: - содержимое входной цепочки символов и положение считывающей головки в ней; - состояние УУ; - содержимое внешней памяти. Для распозн-ля всегда задается определ.конфиг-ция, кот-ая считается нач.конфиг-цией. В нач.конфигурации считывающая головка обозревает первый символ входной цепочки, УУ находится в заданном нач. состоянии, а внешняя память либо пуста, либо содержит строго определенную инфо. Кроме нач.состояния для распозн-ля задается 1 или неск-ко конечных конфигураций. В конечной конфигурации считывающая головка, как правило, находится за концом исход.цепочки. Распозн-ль допускает входную цепочку символов a, если, находясь в нач.конфигурации и получив на вход эту цепочку, он может проделать последов-ть шагов, заканчивающуюся одной из его конечных конфигураций. Распознаватели можно классифицировать в зависимости от вида составляющих их компонентов: считывающего устройства, устройства управления (УУ) и внешней памяти. По видам считывающего устройства распознаватели могут быть двусторонние и односторонние. Односторонние распознаватели допускают перемещение считывающей головки по ленте входных символов только в одном направлении. А двусторонние распознаватели допускают, что считывающая головка может перемещаться относительно ленты входных символов в обоих направлениях. По видам устройства управления распознаватели бывают детерминированные и недетерминированные. Распознаватель называется детерминированным в том случае, если для каждой допустимой конфигурации распознавателя, которая возникла на некотором шаге его работы, существует единственно возможная конфигурация, в которую распознаватель перейдет на следующем шаге работы. В противном случае распознаватель называется недетерминированным. По видам внешней памяти распознаватели бывают следующих типов: - распознаватели без внешней памяти; - распознаватели с ограниченной внешней памятью; - распознаватели с неограниченной внешней памятью. Вместе эти три составляющих позволяют организовать общую классификацию распознавателей. Тип распознавателя в классификации определяет сложность создания такого распознавателя, а следовательно сложность разработки соответствующего программного обеспечения для компилятора. Классификация распознавателей по видам составляющих их компонентов определяет сложность алгоритма работы распознавателя. Но сложность распознавателя также напрямую связана с типом языка, входные цепочки которого может принимать распознаватель. Для каждого из четырех типов языков существует свой тип распознавателя с определенным составом компонентов и, следовательно, с заданной сложностью алгоритма работы. Для языков с фразовой структурой (тип 0) необходим распознаватель, равномощный машине Тьюринга - недетерминированный двусторонний автомат, имеющий неограниченную внешнюю память. Для контекстно-зависимых языков (тип 1) распознавателями являются двусторонние недетерминированные автоматы с линейно ограниченной внешней памятью. Для контекстно-свободных языков (тип 2) распознавателями являются односторонние недетерминированные автоматы с магазинной (стековой) внешней памятью. Для регулярных языков (тип 3) распознавателями являются односторонние недетерминированные автоматы без внешней памяти - конечные автоматы. Грамм-ки и распозн-ли - 2 независимых метода, кот-ые идеально м.б. использованы для определ-я какого-л. языка. Однако при разработке компил-ра для нек-го языка программ-я возникает задача, кот-ая требует связать между собой эти методы задания языков. Разработчики компил-ра всегда имеют дело с уже определенным языком программ-я. Грамматика для синтаксич.конструкций этого языка известна. Она, как правило, четко описана в стандарте языка. Задача разработчиков заключ. в том, чтобы построить распозн-ль для заданного языка, кот-ый затем будет основой синтаксич.анализатора в компил-ре. Т.о., задача разбора в общем виде заключ-ся в следующем: на основе имеющейся грамм-ки нек-го языка построить расп-ль для этого языка. Заданная грамм-ка и распозн-ль д.б. эквива-ны, то есть определять один и тот же язык.
Цепочки вывода Цепочка b Î V* непосредственно выводима из цепочки a Î V+ в грамматике G = (VT, VN, P, S) (обозначим a ® b), если a = x1gx2, b = x1dx2, где x1, x2, d Î V*, g Î V+ и правило вывода g ® d содержится в P. Цепочка b Î V* выводима из цепочки a Î V+ в грамматике G = (VT, VN, P, S) (обозначим a Þ b), если существуют цепочки g0, g1, ... , gn (n >= 0), такие, что a = g0 ® g1 ® ... ® gn= b. Последовательность g0, g1, ... , gn называется выводом длины n. Тогда языком, порождаемым грамматикой G = (VT, VN, P, S), называется множество L(G) = {a Î VT* | S Þ a}. Другими словами, L(G) - это все цепочки в алфавите VT, которые выводимы из S с помощью P. Цепочка a Î V*, для которой S Þ a, называется сентенциальной формой в грамматике G = (VT, VN, P, S). Таким образом, язык, порождаемый грамматикой, можно определить как множество терминальных сентенциальных форм. Цепочка принадлежит языку, порождаемому грамматикой, только в том случае, если существует ее вывод из цели этой грамматики. Процесс построения такого вывода (а, следовательно, и определения принадлежности цепочки языку) называется разбором. Вывод цепочки b Î (VT)* из S Î VN в контекстно-свободной грамматике G = (VT, VN, P, S), называется левым (левосторонним), если в этом выводе каждая очередная сентенциальная форма получается из предыдущей заменой самого левого нетерминала. Вывод цепочки b Î (VT)* из S Î VN в контекстно-свободной грамматике G = (VT, VN, P, S), называется правым (правосторонним), если в этом выводе каждая очередная сентенциальная форма получается из предыдущей заменой самого правого нетерминала. В грамматике для одной и той же цепочки может быть несколько выводов, эквивалентных в том смысле, что в них в одних и тех же местах применяются одни и те же правила вывода, но в различном порядке. Например, для цепочки a+b+a в грамматике G = ({a,b,+}, {S,T}, {S ® T | T+S; T ® a | b}, S) можно построить выводы: (1) S®T+S®T+T+S®T+T+T®a+T+T®a+b+T®a+b+a (2) S®T+S®a+S®a+T+S®a+b+S®a+b+T®a+b+a (3) S®T+S®T+T+S®T+T+T®T+T+a®T+b+a®a+b+a Здесь (2) - левосторонний вывод, (3) - правосторонний, а (1) не является ни левосторонним, ни правосторонним, но все эти выводы являются эквивалентными в указанном выше смысле. Для контекстно-свободных грамматик можно ввести удобное графическое представление вывода, называемое деревом вывода, причем для всех эквивалентных выводов деревья вывода совпадают. Дерево называется деревом вывода (или деревом разбора) в контекстно-свободной грамматике G = {VT, VN, P, S), если выполнены следующие условия: (1) каждая вершина дерева помечена символом из множества (VN È VT È e ) , при этом корень дерева помечен символом S; листья - символами из (VT È e); (2) если вершина дерева помечена символом A Î VN, а ее непосредственные потомки - символами a1, a2, ... , an, где каждое ai Î (VT È VN), то A ® a1a2...an - правило вывода в этой грамматике; (3) если вершина дерева помечена символом A Î VN, а ее единственный непосредственный потомок помечен символом e, то A ® e - правило вывода в этой грамматике. Пример дерева вывода для цепочки a+b+a в грамматике G:
При нисходящем разборе дерево вывода формируется от корня к листьям; на каждом шаге для вершины, помеченной нетерминальным символом, пытаются найти такое правило вывода, чтобы имеющиеся в нем терминальные символы “проектировались” на символы исходной цепочки. Метод восходящего разбора заключается в том, что исходную цепочку пытаются “свернуть” к начальному символу S; на каждом шаге ищут подцепочку, которая совпадает с правой частью какого-либо правила вывода; если такая подцепочка находится, то она заменяется нетерминалом из левой части этого правила. Если грамматика однозначная, то при любом способе построения будет получено одно и то же дерево разбора.
19) Преобразование грамматик 1. Если при описании грамматики указаны только правила вывода Р, то будем считать, что большие латинские буквы обозначают нетерминальные символы, S - цель грамматики, все остальные символы - терминальные. 2. Предположим, что анализируемая цепочка заканчивается специальным символом # - признаком конца цепочки. Рассмотрим методы и средства, которые обычно используются при построении лексических анализаторов. В основе таких анализаторов обычно лежат регулярные грамматики. Для грамматик, например, леволинейного типа существует алгоритм определения того, принадлежит ли анализируемая цепочка языку, порождаемому этой грамматикой или нет (алгоритм разбора): (1) первый символ исходной цепочки a1a2...an# заменяем нетерминалом A, для которого в грамматике есть правило вывода A ® a1 (другими словами, производим "свертку" терминала a1 к нетерминалу A); (2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: полученный на предыдущем шаге нетерминал A и расположенный непосредственно справа от него очередной терминал ai исходной цепочки заменяем нетерминалом B, для которого в грамматике есть правило вывода B ® Aai (i = 2, 3,.., n) и т.д. Это эквивалентно построению дерева разбора методом "снизу-вверх": на каждом шаге алгоритма строим один из уровней в дереве разбора, "поднимаясь" от листьев к корню. При работе этого алгоритма возможны следующие ситуации: (1) прочитана вся цепочка; на каждом шаге находилась единственная нужная "свертка"; на последнем шаге свертка произошла к символу S. Это означает, что исходная цепочка принадлежит языку (a1a2...an# Î L(G)). (2) прочитана вся цепочка; на каждом шаге находилась единственная нужная "свертка"; на последнем шаге свертка произошла к символу, отличному от S. Это означает, что исходная цепочка не принадлежит языку (a1a2...an# Ï L(G)). (3) на некотором шаге не нашлось нужной свертки, т.е. для полученного на предыдущем шаге нетерминала A и расположенного непосредственно справа от него очередного терминала ai исходной цепочки не нашлось нетерминала B, для которого в грамматике было бы правило вывода B ® Aai. Это означает, что исходная цепочка не принадлежит языку (a1a2...an# Ï L(G)). (4) на некотором шаге работы алгоритма оказалось, что есть более одной подходящей свертки, т.е. в грамматике разные нетерминалы имеют правила вывода с одинаковыми правыми частями, и поэтому непонятно, к какому из них производить свертку. Это говорит о недетерминированности разбора. Анализ этой ситуации будет приведен далее. Таблица свёрток и диаграмма состояний Для того, чтобы при лексическом разборе быстрее находить правило с подходящей правой частью, фиксируют все возможные свертки в описании грамматики (это определяется только грамматикой и не зависит от вида анализируемой цепочки). Это можно сделать в виде таблицы, строки которой помечены нетерминальными символами грамматики, столбцы - терминальными. Значение каждого элемента таблицы - это нетерминальный символ, к которому можно свернуть пару "нетерминал-терминал", которыми помечены соответствующие строка и столбец. Например, для грамматики G = ({a, b, #}, {S, A, B, C}, P, S), такая таблица будет выглядеть следующим образом: P: S ® C# C ® Ab | Ba A ® a | Ca B ® b | Cb
Чаще информацию о возможных свертках представляют в виде диаграммы состояний - неупорядоченного ориентированного помеченного графа, который строится следующим образом: (1) строят вершины графа, помеченные нетерминалами грамматики (для каждого нетерминала - одну вершину), и еще одну вершину, помеченную символом, отличным от нетерминальных, - H. Эти вершины будем называть состояниями. H - начальное состояние. (2) соединяем эти состояния дугами по следующим правилам: a) для каждого правила грамматики вида W ® t соединяем дугой состояния H и W (от H к W) и помечаем дугу символом t; б) для каждого правила W ® Vt соединяем дугой состояния V и W (от V к W) и помечаем дугу символом t. Диаграмма состояний для грамматики G (см. пример выше):
(1) объявляем текущим состояние H; (2) затем многократно (до тех пор, пока не считаем признак конца цепочки) выполняем следующие шаги: считываем очередной символ исходной цепочки и переходим из текущего состояния в другое состояние по дуге, помеченной этим символом. Состояние, в которое мы при этом попадаем, становится текущим.
При работе этого алгоритма возможны следующие ситуации (аналогичные ситуациям, которые возникают при разборе непосредственно по регулярной грамматике): (1) прочитана вся цепочка; на каждом шаге находилась единственная дуга, помеченная очередным символом анализируемой цепочки; в результате последнего перехода оказались в состоянии S. Это означает, что исходная цепочка принадлежит L(G). (2) прочитана вся цепочка; на каждом шаге находилась единственная "нужная" дуга; в результате последнего шага оказались в состоянии, отличном от S. Это означает, что исходная цепочка не принадлежит L(G). (3) на некотором шаге не нашлось дуги, выходящей из текущего состояния и помеченной очередным анализируемым символом. Это означает, что исходная цепочка не принадлежит L(G). (4) на некотором шаге работы алгоритма оказалось, что есть несколько дуг, выходящих из текущего состояния, помеченных очередным анализируемым символом, но ведущих в разные состояния. Это говорит о недетерминированности разбора. Анализ этой ситуации будет приведен далее.
Метод восходящего разбора Синтаксис - совокупность правил некоторого языка, определяющих формирование его элементов. Иначе говоря, это совокупность правил образования семантически значимых последовательностей символов в данном языке. Синтаксис задается с помощью правил, которые описывают понятия некоторого языка. Примерами понятий являются: переменная, выражение, оператор, процедура. Последовательность понятий и их допустимое использование в правилах определяет синтаксически правильные структуры, образующие программы. Одной из наиболее простых и широко используемых форм записи грамматик является нормальная форма Бэкуса-Наура (БНФ). Метаязык, предложенный Бэкусом и Науром, впервые использ-ся для описания синтаксиса реального языка программирования Алгол 60. Наряду с обозначениями метасимволов, в нем использовались содержательные обозначения нетерминалов. Это сделало описание языка нагляднее и позволило в дальнейшем широко исп-ть данную нотацию для описания реальных языков программирования. Были использованы следующие обозначения: - символ "::=" отделяет левую часть правила от правой (символ "::=" можно читать как “является по определению”, иногда вместо "::=" используется символ "®"); - нетерминалы обозначаются произвольной символьной строкой, заключенной в угловые скобки "<" и ">" (нетерминалы являются именами конструкций, определенными внутри грамматики); - терминалы - это символы, используемые в описываемом языке; - каждое правило определяет порождение нескольких альтернативных цепочек, отделяемых друг от друга символом вертикальной черты "|". Метод восходящего разбора заключается в том, что исходную цепочку пытаются “свернуть” к начальному символу S; на каждом шаге ищут подцепочку, которая совпадает с правой частью какого-либо правила вывода; если такая подцепочка находится, то она заменяется нетерминалом из левой части этого правила. При восходящем разборе построение дерева начинается с терминальных листьев путем подстановки правил, применимых к входной цепочке в произвольном порядке. На следующем шаге новые узлы полученных поддеревьев используются как листья во вновь применяемых правилах. Процесс построения дерева разбора завершается, когда все символы входной цепочки будут являться листьями дерева, корнем которого окажется начальный нетерминал. Если в результате полного перебора всех возможных правил невозможно построить требуемое дерево разбора, то рассматриваемая входная цепочка не принадлежит данному языку. При использовании восходящего метода на множестве терминальных и нетерминальных символов необходимо ввести три отношения, называемые «отношения предшествования» и обозначаемые как Отношения <, >, =. Отношение и не обязательно транзитивны, т. е. для отношения предшествования не выполняются некоторые правила, привычные для отношения арифметического порядка. Например, Отношения предшествования удобно занести в матрицу, в которой строки и столбцы помечены терминалами грамматики. Отношение предшествования и должны рассматриваться грамматическим процессором в качестве одной конструкции языка. Если для пар отношения предшествования не существует, это означает, что они не могут находиться рядом ни в одном грамматически правильном предложении. Если подобная комбинация лексем встретится в процессе грамматического разбора, то она должна рассматриваться как синтаксическая ошибка. Существуют алгоритмы автоматического построения матриц предшествования на основе формального описания грамматики (рис 2.6). Применение метода операторного предшествования возможно в случае, когда отношения предшествования заданы однозначно. Например, не должно быть одновременно отношений
однако некоторые из отношений грамматики Паскаля не являются однозначными и метод оперативного предшествования к ним не применим. На рис. 2.7 изображен пошаговый процесс грамматического разбора предложения присваивания в строке 14 Процесс сканирования слева направо продолжается на каждом шаге грамматического разбора лишь до тех пор, пока не определится очередной фрагмент предложения для грамматического распознавания, т. е. первый фрагмент, ограниченный отношениями фрагмент выделен, он интерпретируется как некоторый очередной нетерминальный символ в соответствии с каким-либо правилом грамматики. Этот процесс продолжается до тех пор, пока предложение не будет распознано целиком. Следует обратить внимание на то, что каждый фрагмент дерева грамматического разбора строится, начиная с оконечных узлов вверх, в сторону корня дерева. Отсюда и возник термин «восходящий разбор». Для метода операторного предшествования имена нетерминальных символов несущественны. Таким образом, вся информация о грамматике и синтаксических правилах языка содержится в матрице операторного предшествования
Нисходящий метод Другой метод грамматического разбора – нисходящий метод, называемый рекурсивным спуском. Это один из методов грамматического анализа, где правила формальной грамматики раскрываются, начиная со стартового символа, до получения требуемой последовательности токенов. Процессор грамматического разбора, основанный на этом методе, состоит из отдельных процедур для каждого нетерминального символа, определенного в грамматике. Каждая такая процедура носит имя нетерминала и ищет во входном потоке подстроку, начинающуюся с текущей лексемы, которая может быть интерпретирована как нетерминальный символ, связанный с данной процедурой. В процессе своей работы она может вызывать другие подобные процедуры или даже рекурсивно саму себя для поиска других нетерминальных символов. Если эта процедура находит соответствующий нетерминальный символ, то она заканчивает свою работу, передает в вызвавшую ее программу признак успешного завершения и устанавливает указатель текущей лексемы на первую лексему после распознанной подстроки. Если же процедура не может найти подстроку, которая могла бы быть интерпретирована как требуемый нетерминальный символ, она заканчивается с признаком ошибки или вызывает процедуру выдачи диагностического сообщения и процедуру восстановления. Тело каждой такой процедуры пишется непосредственно по правилам вывода соответствующего нетерминала: для правой части каждого правила осуществляется поиск подцепочки, выводимой их этой правой части. При этом терминалы распознаются самой процедурой, а нетерминалы соответствуют вызовам процедур, носящих их имена. На рис. 2.8 представлен разбор методом рекурсивного спуска оператора присваивания в строке 14
Компоновщик Компон-к – это прога, преодоставляемая проектировщиком системы, которая связывает независ. лог. обл-ти кажд. подр-мы и кажд. модуля в одну единств. лог. обл-ть. Компоновка включает по крайней мере следующие этапы: 1.Сбор всех модулей из библиотек пользователей и системных библиотек. 2.Установка всех внешних ссылок м/д модулями. 3.Собщение о неопределенных ссылках. 4.Конструирование структуры оверлея. 5.Определение и построение загрузочного модуля Главная задача программы компоновщика создать комплекс объект. модулей, полученных от компиляторов с различных языков в какой-нибудь из разновидностей исполняемых модулей и заменить неопределенные ссылки на внешние имена с соответствующими адресами или информацией доступной для загрузчиков. Классификация типов связей разграничивает 2 класса: управляющие и информационные. Для реализации которых используется единый технический подход, опирающийся на глобально-доступные имена элементов программных модулей. Управляющие связи в современных системах программирования определяются способами передачи управления и действиями, выполняемыми для решения частей общей задачи и представленные в одной из шести форм: 1.Вызов подпрограммы того же загрузочного модуля в процессе его выполнения, реализуемого простыми средствами модульного программирования. 2.Макровызов, как подготовка действий по решению части задачи на этапе компиляции или создания программы, которая реализуется с помощью встроенных макросредств системы программирования. 3.Вызов подпрограммы, копия которой имеется в основной программе и который обычно реализуется в форме обращения к общей системной программе ОС или управляющей надстройке пользователя. 4.Вызов подпрограмм с диска можно подзагрузкой их кодов и управляющих данных, при котором иногда различают оверлейную структуру программ с фиксированным взаимным расположение модулей и фрагментов и динамическую подзагрузку в совершенно произвольном порядке. 5.Динамический вызов параллельных процессов решения подзадач включая выполнение ехе-модули и dll-модули, которые подключаются на этапе выполнения. 6.Передача сообщения и сигналов автономным параллельным процессам и задачам широко применяемым для управления вычислениями в объектно-ориентированных оболочках. Кроме управляющих необходимо установить и информационные связи между модулями для передачи в подчиненные модули операт. данных или аргументов подпрограмм и возврата результатов в вызывающие программы, а также для передачи универсальных управляющих данных в другие программные модули. К основным способам установления информационных связей относят 3 следующих способа: 1.Передача аргументов при вызове подпрограмм и функций унифицированная стандартами обращения к подпрограммам, общая для компоновщиков и специализированными для языков программирования. 2.Возрат результатов при вызове функций, при котором соблюдают стандарт. связанный с ЯП. 3.Использование глобальных областей памяти для обмена данными между подпрограммами и задачами. Комбинирование связи чаще всего возникают, когда управляющая или адресная информация рассматриваются как данные в аргументах функций и процедур или адресов подпрограмм, но с другой стороны точки ветвления могут быть рассмотрены как адреса передачи управления для их реализации достаточно использовать типичные средства связывания с незначительными особенностями во входных языках для определения процедурных типов. Для реализации компоновщика и его эксплуатации необходимо проанализировать форматы его элементов хотя бы на самом общем уровне. При изучении форматов объектных модулей особый интерес представляют такие вопросы: 1. как определяется? Какие внешние подпрограммы и данные нужны объектному модулю и каким образом определяются адреса обращения или точки входа в подпрограммах или данных, которые могут использоваться программами других модулей? 2. как проверить корректность типов данных при обращении к подпрограммам и задачам? 3. как достигается переместимость объект. программы, т.е. возможность размещать ее в любом месте ОП? 4. как и почему компонуются отдельные логические сегменты в единый физический сегмент? Объединение логических сегментов требует корректировки относительного адреса в уже сформированный коде путем добавления относительного смещения смещения начала логического сегмента для переместимых адресов. В случае использования внешних имен условный код указателя заменяется конкретным адресом соответственного объекта. Многообразие объектов переместимости, а иногда и использование разных кодов для внутреннего представления типов переместимости делают несовместимыми объектные коды, получаемые от трансляторов разных фирм или даже разных систем программирования одной фирмы. В модульном программировании различают связи по управлению и по данным, реализуемые с помощью адресных указателей или ссылок на данные и коды. При объедении модулей необходимо определить имена областей памяти и фрагментов программ, используемых в др модулей в списке операндов оператора public, внешние имена из других модулей вместе с их типами описываются в списке операндов оператора extended. Для указателей используются только ключевые слова word и dword, т.е. указатели в ассемблере нетипизированы. При обращении к подпрограммам и функциям по прямым адресам используются типы near и far. Передача параметров в форме непосредственных значений или адресных указателей осуществляются через стек. Необходимость проверки соответствия типов данных, аргументов, процедур и функций, а также числа аргументов в процедурах, существенно усложняет представления словаря внешних ссылокв объектных файлах. Компоновщики используют программные модули, хранящие информацию об именах исходных модулей программы, типе компилятора породившем этот модуль, а иногда и даже и о модели памяти под которую этот модуль оттранслирован.
Связывающие загрузчики
Выполняют связывание и перемещение во время загрузки.
Несмотря на то, что операции связывания и загрузки выполняются загрузчиком, работа загрузчика разделяется на две части. Первая часть вырабатывает загрузочный модуль, состоящий из всех объектных сегментов, связанных и перемещаемых вместе относительно стандартного базового адреса. Другая часть – операция загрузки – загружает модуль в основную память, настраивая адреса в соответствии с распределением памяти для модуля. Редактор связей выполняет часть работы по распределению памяти, но основную работу по распределению памяти выполняет загрузчик. Статический принцип настройки адресов выполняет статический алгоритм распределения памяти. Вся необходимая основная память для пользовательской программы и данных назначается до начала выполнения программы, а все адреса настраиваются так, чтобы отразить это назначение. Если настройка происходит во время выполнения, непосредственно предшествуя каждому обращению к памяти, то адреса настраиваются динамически. При динамической настройке адресов связывающий загрузчик должен быть построен по более сложным алгоритмам. Входящая информация для связывающего загрузчика состоит из набора объектных программ, т.е. управляющих секций, которые должны быть связаны друг с другом. В управляющих секциях могут использоваться внешние ссылки на имена, значения которых во входном потоке еще не были определены. В этом случае требуемое связывание не может быть выполнено до тех пор, пока не будут назначены адреса для всех требующих имен, т.е. до тех пор, пока не будет прочитана требуемая управляющая секция, поэтому связывающий загрузчик обычно выполняет два просмотра входного потока точно так же, как это делает ассемблер. Т.е. во время первого просмотра назначаются адреса для всех внешних ссылок, а во время второго – выполняет фактическая перемещение, связывание и загрузка. Основная структура данных, необходимая для связывающего загрузчика – это таблица внешних имен (ESTAB). Данная таблица используется для хранения имен и адресов всех внешних ссылок для всего набора управляющих секций, загружаемых совместно. Очень часто в этой таблице также запоминается информация о том, какая управляющая секция содержит определение имени. Обычно ESTAB организуется в виде КЭШ-таблицы. Двумя другими важными переменными являются PROGADDR и CSADDR – начальный адрес той управляющей секции, которая обрабатывается загрузчиком в данный момент. Этот адрес добавляется к всем относительным адресам данной управляющей секции для того, чтобы преобразовать их в фактические адреса. Во время первого просмотра загрузчик обрабатывает только запись-заголовок и записи определения управляющих секций. PROGADDDR становится начальным адресом первой управляющей секции входного потока. Имя управляющей секции, полученное из записи-заголовка, записывается в ESTAB и ему присваивается текущее значение CSADDR. Все внешние имена из записей-определений также заносятся в ESTAB. Значения их адресов получается путем сложения значения из записи-определения с CSADDR. После того, как прочитана запись-конец к CSADDR добавляется длина управляющей секции и таким образом получается адрес начала следующей управляющей секции. После завершения первого просмотра ESTAB содержит все внешние имена, определенные в данном наборе управляющих секций вместе с назначенными им адресами. Далее осуществляется связывание, перемещение и загрузка. Переменная CSADDR используется также, как и во время первого просмотра. Она всегда содержит фактический начальный адрес загруженной в данный момент секции. Завершает работу загрузчик обычно передачей управления на загружаемую программу. Запись-конец каждой управляющей секции может содержать адрес первой команды данной секции, с которой должно начинаться ее исполнение. Если адрес передачи управления задан более чем в одной управляющей секции, то загрузчик использует последний встретившийся. Если ни одна из управляющих секций не содержит адрес передачи управления, то используется PROGADDR. Адрес передачи управления должен помещаться только в записи-конце главной программы, но не в подпрограммах, чтобы стартовый адрес не зависел от порядка следования управляющих секций.
Адресация памяти в реальном режиме. Сегментация памяти, сегментные регистры. Процессор делит адресное простр-во на произвольное кол-во сегментов, каждый из кот-ых содержит не более 64 Кбайт. Адрес первого байта сегмента всегда кратен 16 и назыв-ся адресом сегмента или параграфом сегмента. Возникает проблема представл-я 20-разр. физич. адреса памяти при помощи содержимого 16-разрядных регистров.
В процессоре имеется неск-ко быстрых элем-ов памяти на интегральных схемах, кот-ые назыв-ся регистрами. Регистры можно рассм-ть, как ЯП, к кот-ым ПР может обращаться быстрее, чем к обычной памяти. Все РОНы могут участвовать в ариф-ко-логических операциях. РОНы делятся условно на 2 части: Low – младшая и High – старшая (например, старшая часть – это AH, а младшая – AL). Так же использ-ся рег-ры EAX, EBX, ECX и EDX (E - Extended(расширенный))
AX – аккумулятор, BX - базовый регистр, CX – счетчик, DX - данные. Явл-ся расширением регистра AX при умножении двойных слов, а также при операциях деления хранит остаток.
1) SI - индекс. Использ-ся в кач-ве индексного рег-ра, 2) DI - индекс. Использ-ся в кач-ве индексного регистра, 3) BP – дополнительный регистр базы. Используется в кач-ве базового регистра, 4) SP - указатель стека.
. Некот-ые флаги устанавл-ся в резул-те выполн-я арифметич.операций или операций сравнения,Напр-р, флаг нуля (бит Z в регистре флагов) устанавл-ся после инструкции вычитания, если рез-т нулевой.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-05-08; Просмотров: 239; Нарушение авторского права страницы
 Чтение, запись в буфер
Чтение, запись в буфер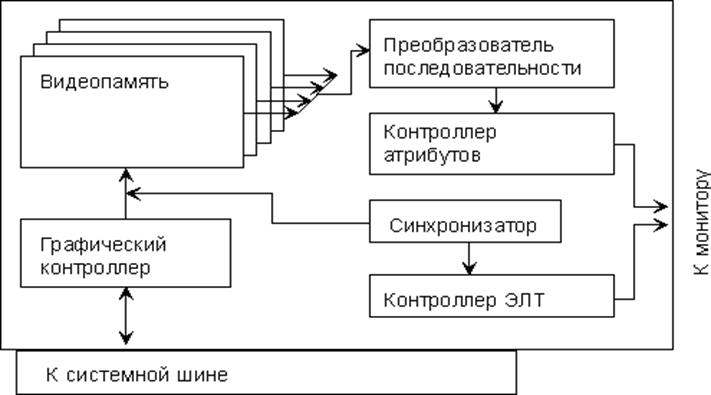
 Структура видеопамяти режима 10 h .
Структура видеопамяти режима 10 h .  Преобразов-е кода ASCII в образ символа на экране
Преобразов-е кода ASCII в образ символа на экране - Байт атрибутов символа
- Байт атрибутов символа * E GA, VGA , sVGA – от B800:0000 до B800:7FFF длиной 32К.
* E GA, VGA , sVGA – от B800:0000 до B800:7FFF длиной 32К. Т.к. видеопамять компа нач-ся с адреса B800:0000, то это – адрес начала страницы № 0. След.страница нач-ся с адреса B800:0000+4096, т.е. B800:1000; страница № 2 – с адреса B800:2000 и т.д.
Т.к. видеопамять компа нач-ся с адреса B800:0000, то это – адрес начала страницы № 0. След.страница нач-ся с адреса B800:0000+4096, т.е. B800:1000; страница № 2 – с адреса B800:2000 и т.д.
 Уровни блокировки
Уровни блокировки
 Дерево вывода можно строить нисходящим либо восходящим способом.
Дерево вывода можно строить нисходящим либо восходящим способом. Знак "-" ставится в том случае, если для пары "терминал-нетерминал" свертки нет.
Знак "-" ставится в том случае, если для пары "терминал-нетерминал" свертки нет. Тогда для диаграммы состояний применим следующий алгоритм разбора:
Тогда для диаграммы состояний применим следующий алгоритм разбора:
 не является отношением эквивалентности, а отношения
не является отношением эквивалентности, а отношения
 означает, что обе лексемы имеют одинаковый уровень
означает, что обе лексемы имеют одинаковый уровень и
и  Это требование выполняется для используемой грамматики,
Это требование выполняется для используемой грамматики, . Как только подобный
. Как только подобный


 Для получения 20-разр.физич.адреса к сегментной компоненте приписываются справа четыре нулевых бита и складывается с компонентой смещения.
Для получения 20-разр.физич.адреса к сегментной компоненте приписываются справа четыре нулевых бита и складывается с компонентой смещения.

 Сегментные регистры
Сегментные регистры Регистр флагов Этот 16-разр-ый (16-битовый) регистр содержит инфо о соотношении между данными, резул-тах операций и состоянии ПР в целом.
Регистр флагов Этот 16-разр-ый (16-битовый) регистр содержит инфо о соотношении между данными, резул-тах операций и состоянии ПР в целом. 3) Стек, вектора прерываний
3) Стек, вектора прерываний


 Система прерыв-ий в реал.режиме работы ПР
Система прерыв-ий в реал.режиме работы ПР

