|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Односвязанные (однонаправленные) списки
Для повышения надежности список делают кольцевым. Для работы со списком требуется следующий минимальный набор функций: 1. Формирование первого узла списка 2. Добавление в конец списка 3. Вставка узла после узла с заданным ключом, в качестве ключа может использоваться какой либо элемент поля данных или совокупность полей данных 4. Поиск узла с заданным ключом 5. Удаление узла с заданным ключом 6. Сортировка списка по ключу 7. Уничтожение списка
Двунаправленные Кроме поля данных есть 2 поля указателей – prev (указывает на адрес предыдущего элемента) и next (следующего). Для повышения надежности список делают кольцевым. Если все узлы списка имеют один и тот же тип, то такие списки называются однородными. Неоднородные (гетерогенные) списки Части списка – подсписки. В пределах подсписка узлы однотипные. 4. Двунаправленный линейный однородный список В main pbeg и pend, в функции пользователя pg, pd. Программа формирует список из 5 целых чисел, добавляя элементы в конец списка, вставляет узел после узла с заданным ключом, находит по ключу узел и удаляет его.
На практике списки обычно сортируют по ключу, в качестве ключа обычно используют одно из полей данных, но может вводиться и специальный ключ, например в одно из полей данных записывается целое число, список сортируют, например, в порядке возрастания ключа, отсортирован будет новый список, который образуется из исходного переназначением указателей, однако часто сразу формируют отсортированный список. Поиск хэшированием В любом линейном списке возможен только линейный поиск, тогда эффективность поиска О(n). Для ускорения поиска в списках преобразуют ключ узла (например, целое число) в индекс, это преобразование в хэш-функции, чаще всего используют функцию, которая находит остаток от деления нацело.
Бинарные деревья Виды деревьев: 1. Просто бинарные деревья 2. Упорядоченные бинарные деревья (деревья поиска) 3. AVL-деревья (балансируемые) деревья 4. Идеально-сбалансированные деревья
● Упорядоченные бинарные деревья 17, 18, 6, 5, 9, 23, 12, 7, 8 17 корень (0-ой уровень) 6 18 уровень 1 (слой 1) 5 9 23 уровень 2 7 12 уровень 3 8 11 уровень 4 Глубина – 5 Левое поддерево и правое. Если правое и левое деревья заполнены полностью, то такое дерево – полное. Эффективность поиска на дерево O (log2n). Если дерево вырожденное (неполное) - поиск линейный, неэффективный. Дерево балансируют (AVL), выполняя требования – высота левого и правого дерева не должна отличаться более чем на 1. Если узел не имеет потомка – лист, если имеет – ветвь.
● Идеально-сбалансированное дерево Чтобы его построить, нужно знать количество узлов, т.к. алгоритм требует знания количества узлов. 1. Взять одну вершину (узел) в качестве корня 2. Построить тем же способом левое поддерево с nl=n/2 узлами. 3. Построить тем же способом правое поддерево с nr=n-nl-1 узлами. В данном дерево количество узлов в левом и правом поддеревьях не отличается больше, чем на 1.
Бинарные деревья п.1 не являются упорядоченными, они строятся для различных целей, например для пирамидальной сортировки.
● Удаление узла из упорядоченного дерева Возможны 3 случая: 1. Удаляемый узел – лист Удалить ссылку на элемент, освободить память 2. Из удаляемого узла выходит только 1 ветвь Переназначают указатель, освобождают память 3. Из удаляемого узла выходят 2 ветви Чтобы сохранить упорядоченность дерева, удаляемый узел заменяют либо крайним правым узлом левой ветви, либо крайним левым узлом правой ветви
● Способы обхода дерева В общем виде дерево выглядит R A B Способы обхода: 1. Слева направо – A R B 2. Сверху вниз – R A B 3. Снизу вверх – A B R 4. Справа налево – B R A (a+b/c)*(d-e*f)
● Применим запись ARB (a+b/c)*(d-e*f) Сортировка массива по возрастанию (BRA – по убыванию) ● ABR abc/+def*-* постфиксная запись ● RAB – префиксная запись *+a/bc-d*ef
Набор функций для работы с деревом Дерево является рекурсивной структурой данных, поэтому естественно использовать рекурсивные функции, но это не всегда удобно. 1. Формирование первого узла дерева – корня 2. Включение узла в дерево 3. Функция поиск по дереву 4. Функция обхода дерева 5. Удаление узла 6. Уничтожение дерева
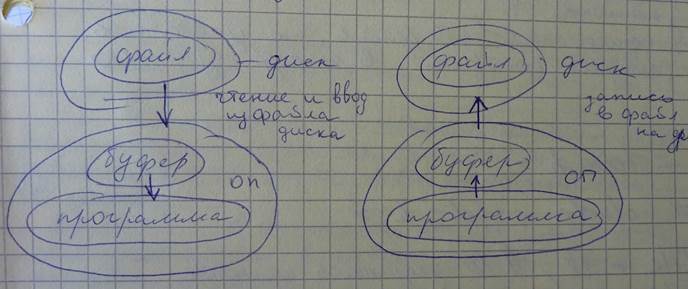
8.Файлы в СИ Все файлы рассматриваются как неструктурированная последовательность байтов. Операции ввода-вывода, связанные с файлами, осуществляются библиотечными функциями. Существует 2 уровня ввода-вывода: 1. Верхний – потоковый 2. Нижний ● Функции верхнего уровня потокового ввода-вывода
При чтении из файла данные помещаются в буфер (под него выделена динамическая память), затем данные побайтно или определенными порциями передаются в программу. При опустошении буфера в него передается следующая порция данных. При выводе или записи в файл данные из программы передаются в буфер, когда буфер будет заполнен – они одним блоком выводятся в файл (за одно обращение к диску). Буфер сокращает временные затраты на взаимодействие программы с диском. Файл вместе со средствами буферизации называют потоком, но обычно вместо слова поток используют слово файл, подразумевая поток. Обмен данными программы с файлами осуществляется функциями библиотеки ввода-вывода. Они могут: 1. Открывать и закрывать потоки (файл) 2. Вводить и выводить символы, строки, форматированные данные, определенную порцию данных 3. Анализировать ошибки и в соответствии с ошибкой выводить сообщение 4. Управлять размером буфера и буферизацией потока 5. Позиционировать файл, т.е. указатель файла ставить в определенную позицию Все функции находятся в файле <stdio.h> #include <stdio.h> FILE*fp; // fp – указатель на поток (файл), FILE - структурный тип, он предопределен, там находится: 1. Указатель на буфер 2. Указатель текущей позиции в файле
Fp=fopen (имя_файла (можно указатель на строку), режим_открытия (можно указатель на строку)); Fp=fopen (“t.txt”, “w”); // при выполнении функции fopen выделяется динамическая память под буфер, буфер связывается с файлом на диске, т.е. образуется поток, адрес буфера помещается в указатель fp, физически существующему файлу на диске t.txt в программе будет соответствовать имя fp. Fp=fopen (“z:\\h\data” , “rb+”);
Файл может быть открыт в одном из 6 режимов: 1. “w” – новый текстовый файл открывается для записи, если он уже существует, то его содержимое стирается, т.е. файл создается заново 2. “r” – уже существующий файл открывается только для чтения 3. “w+” – в отличие от “w” можно делать исправления в файле, файл может увеличиваться в размерах, т.е. «расти» 4. “r+” – в отличие от “r” в файле можно делать изменения (редактировать), но «расти» он не может 5. “a” – (append) – текстовый файл открывается (или создается, если его нет) для добавления в него новой информации в конец 6. “a+” – в отличие от “a” можно его изменять в любом месте, файл может «расти» Файл можно открыть в 2-х режимах: 1. В текстовом (читальный) – отличается тем, что последовательность символов CR (возврат каретки, код 13) и перевод строки LF (код 10) при чтении из файла преобразуются в символ перевода строки ‘\n’ (код 10, в ОП). При выводе в файл – обратное преобразование. Режим по умолчанию - “wt” / “w” 2. В бинарном (прочитать нельзя) – обмен данными осуществляется побайтно, поэтому преобразований нет, открывается – “wb” / “rb”. Режимы с плюсом: - в этом случае переход от записи к чтению можно делать после того, как указатель файла поставлен в соответствующую позицию, т.е. выполнено позиционирование файла
● Ошибки При открытии файла могут возникнуть следующие ошибки: 1. Указанный файл не найден (при чтении) 2. Нет места на диске (при записи) 3. Диск защищен от записи Всего больше 10 ошибок, они нумеруются. Чтобыузнать ошибку используют последовательность операторов ● функция закрытия файла Функция закрытия файла – int fclose(fp); , выполнение функции: данные в буфере, не выведенные на диск, выводятся на диск, данные в буфере, не использованные программой, теряются, динамическая память, выделенная под буфер, освобождается, связь программы с файлом прекращается. Если нет функции – произойдет ошибка. Чтобы не было потери данных при выводе в файл, файл нужно закрывать явно функцией fclose.
Функции библиотеки для работы с файлом в текстовом режиме: 1. Fgetc() – прочитать один символ из файла 2. Fputc() – вывести в файл один символ 3. Fprintf() – форматированный вывод в файл 4. Fgets() – чтение строки из файла 5. Fscanf() – форматированный ввод (чтение) из файла 6. Fputs() – запись строки в файл 7. Int feof (fp) – проверяет состояние индикатора конца файла, если индикатор показывает конец файла, то функция возвращает не нуль Примеры функций: 1. Fgets (str, 50, fp); 50 – количество считываемых символов + ‘\0’, считать можно только 49 символов, если до 49-ого символа прочитали ‘\n’, то он переносится в строку str. Из файла fp прочитывается 49 символов. Функция возвращает или адрес прочитанной строки, или NULL при достижении конца файла или в случае ошибки 2. Fputs (str, fp); Строка str выводится в файл fp, возвращает код последнего символа в случае успеха и NULL в случае ошибки. Строку в файле автоматически не переводит. В файл может вывести только строку, ограниченную ‘\0’, если нуля нет – может быть зацикливание. Символ ‘\0’ – в файл не переносим, перевод строки ‘\n’ – не записывают.
● Функции в бинарном режиме: Int c; C=gets (fp); Puts(c, fp); Из переменой c выводится в файл fp, обмен побайтно, но может происходить и порциями данными определенной длины, тогда используются функции: 1. Fread (ptr, size, N, fp); - для чтения из файла 2. Fwrite (ptr, size, N, fp); - для записи в файл Выполнение функции fread – из файла fp выводится N элементов по size байт каждый в область памяти, адресуемую ptr. Выполнение фукнции fwrite – из области памяти, адресуемую ptr, в файл fp выводится N элементов по size байт каждый. Эти функции особенно удобны при работе с файлами структур. В этом случае N – размер массива структур. Size – объем памяти, занимаемой структурой.
● Позиционирование файла (работа с файлом, как с массивом) – произвольный доступ к файлу Используют функции: 1. Int fseek (указатель, смещение, начало отсчета); Указатель – указатель на файл, fp Смещение – тип long, может быть >0 (если смещаемся к концу файла) или <0 (к началу файла) Начало отсчета – параметр кодируется, если 0, то начало отсчета – начало файла, если 1 – текущая позиция файла, 2 – конец файла В случае успеха возвращает NULL, а в случае неуспеха возвращает -1 (при попытке сместиться на пределы файла). Примеры использования: a. Fseek (fp, 0L, 0); - перемещение к началу файла из произвольной позиции b. Fseek (fp, 0L, 2); - к концу файла из произвольной позиции c. Struct {…} st; Fseek (fp, -(long)sizeof(st), 1); - указатель текущей позиции в файле перемещается к началу файла на 1 структуру.
2. Long ftell (fp); - возвращает текущую позицию в файле 3. Void rewind (fp); - устанавливает указатель на начало файла
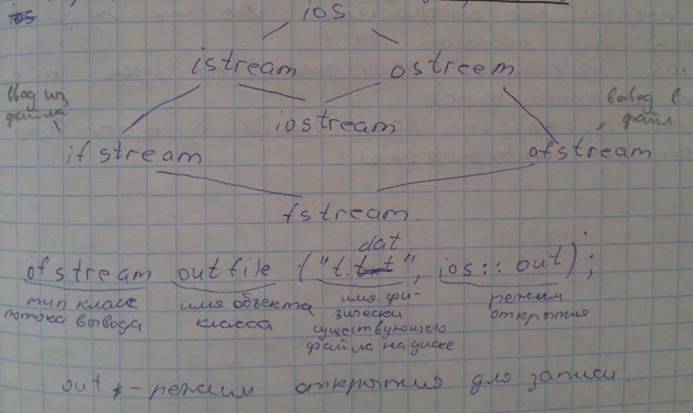
9.Файлы в Си++ Для ввода-вывода используются объекты классов. Буфер в Си заменяется здесь на объект существующего класса. ● Иерархия классов ввода-вывода:
● Режимы открытия файлов в Си++ 1. ios::in – открыть файл для чтения или ввода 2. ios::out – открыть файл для записи или вывода 3. ios::app – записывать все данные в конец файла 4. ios::ate – переместиться в конец исходного открытого файла, но данные могут быть записаны в любом месте файла 5. ios::trunс – если файл существует, то его содержимое – отбросить, тоже по умолчанию для режима out 6. ios::nocreate – если файл не существует, то он и не открывается 7. ios::norlace – если файл существует – то он не открывается
● Реализация динамических структур с помощью массивов Это возможно когда заранее известен полный объем данных Стек Для реализации стека кроме массива данных нужна одна вспомогательная переменная, куда заносится индекс вершины стека. Очередь Для реализации очереди кроме массива данных нужны 2 вспомогательные переменные, в а – заносится индекс начала очереди, в b – индекс конца, с течением времени они возрастают. Линейный список Вывод: Недостаток реализации: 1. динамических структур с помощью массива – необходимо до выполнения программы знать объем данных (на практике – не часто). Достоинства: 1. Используются непрерывные участки памяти (под массивы), 2. Можно сортировать, в общем случае, упорядочивать большие объемы данных без физического их перемещения в памяти
● Неформатированный ввод-вывод в файлах СИ++ Infile.read ((char*)&s, sizeof(s)); // чтение Outfile.write ((char*)&s, sizeof(s)) // запись
● Позиционирование в файлах Си++ 1. Infile.seekg (n); // позиционирование на n-ый байт от начала файла Infile.seekg (n, ios::beg); // это же самое 2. Infile.seekg (n, ios::cur); // позиционирование на n-ый байт вперед от текущей позиции 3. Infile.seekg (n, ios::end); // … от конца файла 4. Infile.seekg (0, ios::end); // указатель на конец файла 5. Outfile.seekp (…); // для файла открытого на запись
● Функции, позволяющие получить текущую позицию указателя файла 1. Long l=infile.tellg (); // возвращает текущую позицию указателя в файле открытого для чтения 2. Long l=outfile.tellp (); // возвращает текущую позицию указателя в файле открытого на запись
Файлы в СИ++ подразделяются на: 1. Файлы с последовательным доступом 2. Файлы с произвольным доступом (записи имеют одинаковую длину), самый быстрый доступ, поэтому такие файлы используются в системах по обработке запросов
|
Последнее изменение этой страницы: 2019-05-08; Просмотров: 227; Нарушение авторского права страницы