
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
На основе теоретико-графовых моделейСтр 1 из 6Следующая ⇒
МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ УКРАИНЫ ТАВРИЧЕСКИЙ НАЦИОНАЛЬНЫЙ УНИВЕРСИТЕТ Им. В.И.Вернандского МАТЕМАТИЧЕСКИЙ ФАКУЛЬТЕТ КАФЕДРА ИНФОРМАТИКИ ДИПЛОМНАЯ РАБОТА Проектирование и разработка Сетевых броузеров На основе теоретико-графовых моделей
Выполнил студент 5 курса Специальности «информатика» _________________Поляков Т.И.
Симферополь Г.
Введение Актуальность
В связи с расширением глобальной сети Internet возрастает необходимость внедрения новых оптимизационных алгоритмов, связанных со скоростью обмена данных между компьютерами в единой сети. Компьютерные сети завоевывают мир. Системы из маленьких компьютеров превращаются в огромные хранилища данных, доступные всему миру. Любая современная фирма, любой офис оснащен хотя бы простейшей сетью. Не выходя из дома, сотни тысяч людей работают на персональных компьютерах, принося пользу всему миру. В основном для работы в Internet используются программы-броузеры. Эти программы позволяют легко обмениваться текстовой, графической и звуковой информацией, используя популярную, простую в обращении мультемедийную службу ИНТЕРНЕТ World Wide Web. Цель
Цель данной работы заключается в следующем: - разработка математической модели сетевого броузера и корпоративной среды; - создание имитационной модели распределении информации в глобальных сетях. Для достижения данной цели были решены следующие задачи: 1.) Проведен анализ существующих броузеров; 2.) Рассмотрены основные топологии существующих корпоративных сетей; 3.) Разработан алгоритм определения оптимального маршрута передачи информации по глобальной сети.
1.Теоретико – графовые модели организации сетевых структур Основные понятия теории графов Определение. Множество Х= Пусть Определение. Система ребер графа Г Определение.Путь Определение. Граф Г называется связным, если для любых двух различных
вершин
Рис. 1 Легко видеть, что граф из примера 1 является конечным, несвязным и содержащим петли.
Определение. графы Г и Г` называются изоморфными, если существует взаимно однозначное соответствие между их вершинами и ребрами такое, что соответствующие ребра соединяют соответствующие вершины. Определение. Граф Г` называется подграфом Г, если его вершины и ребра принадлежат графу Г. Длиной пути в графе называют сумму длин входящих в этот путь ребер. Определение. Деревом называется конечный связный граф с выделенной вершиной, именуемой корнем, не содержащий циклов.
Если в графе можно выделить более одного дерева, которые не связны между собой, то такой граф называют лесом.
Рис 2. Лес, имеющий две компоненты связности (2 дерева).
Будем далее обозначать через Х – множество вершин и U – множество ребер графа, а сам граф, определяемый этой парой объектов, будем обозначать < X, U>; x X, u U. Обозначим длину дуги u=(x, y) через d(u). Кратчайшую длину пути из х в
z обозначим D(x, z).
Очевидно, если кратчайший путь из x в z существует и проходит через промежуточную вершину w, то D(x, z) = D(x, w) + D(w, z). Эта формула справедлива для любой промежуточной вершины w рассматриваемого пути, в том числе и для последней, смежной с конечной вершиной w. Поэтому кратчайший путь можно отыскать, последовательно переходя от конечной вершины z в ближайшую смежную и запоминая цепочку построенных вершин (конечно, при условии, что хотя бы один путь между вершинами x и z существует и граф не содержит циклов. Эта идея и является в сущности принципом Р.Беллмана. Графовые алгоритмы Алгоритм Беллмана поиска кратчайшего пути между двумя вершинами связного графа, не имеющего циклов с неотрицательными длинами ребер. Его описание приводится ниже при помощи алгоритмической схемы.
Идентификаторы: D[w] – рабочий массив, при вычислениях интерпретируется как кратчайшая длина из вершины w в вершину z. w X. d[s, t] – массив длин ребер графа для каждой пары вершин s, t X. Если некоторое ребро отсутствует, то в элементе этого массива полагается записанным некоторое достаточно большое число, превышающее сумму длин всех ребер графа. Stack – последовательность вершин, определяющая кратчайший путь из x в z. Begin Stack: =’’; // Очистить Stack. Stack < =z; // Поместить в стек конечную вершину z. w: =z; // Запомнить первую пройденную вершину. D[z]: =0; // Обнуление длины пути из вершины z в нее же. While w=/=x do // Пока не будет достигнута начальная вершина, выполнять // перебор вершин графа p: = вершина, для которой величина D[p] = d[p, w]+D[w] минимальна. Если таких вершин несколько и среди них имеется вершина x, то p: =x, если же среди них нет вершины x – взять любую из доставляющих минимум сумме. Stack < =p; // Записать выбранную вершину в стек. w: =p; // и взять ее для построения следующего шага. End; End. Пусть число вершин графа |X|=n, а число ребер |U|=m. Оценим сложность этого алгоритма как число шагов выполнения алгоритмической схемы, считая одним шагом выполнение ровно одного выполнимого оператора, каковые представлены только строками 2, 3, 4, 5, 6, 8, 9. В худшем случае выбор вершины в строке 8 (по минимуму расстояния) произойдет в результате просмотра всех n вершин, а цикл с заголовком в строке 6 повторится для всех вершин, поэтому сложность алгоритма можно оценить как C*n^2, где С – некоторая константа, учитывающая реализацию алгоритма в произвольной вычислительной среде. Следующий алгоритм обеспечивает нахождение кратчайших расстояний от фиксированной вершины х, называемой источником, до всех остальных вершин графа с ограничением, предполагающим отсутствие в графе контуров отрицательной длины (сумма длин ребер, входящих в любой контур, неотрицательна). Алгоритм Форда-Беллмана Идентификаторы: d[s, t] – массив длин ребер графа для каждой пары вершин s, t X. Если ребра нет, то соответствующий элемент этого массива содержит достаточно большое число. х – вершина-источник графа < X, U>. n=|X| - число вершин графа. u, w, k – рабочие переменные. D[w] – массив, в котором к концу работы алгоритма будут содержаться кратчайшие длины путей из х в w для всех вершин w X.
Begin D[x]: =0; // Длина пути из источника x. For w X do D[w]: =d[x, w]; // Инициализация матрицы расстояний For k: =1 to n-2 do // Повторять n-2 раз For w {X\{x}} do // Цикл по всем вершинам, кроме источника. For u X do D[w]: =min(D[w], D[u]+d[u, w]); // выбор минимума. End. Этот алгоритм также основан на соотношении (принципе оптимальности) Беллмана. Всякий раз, когда находится путь через транзитную вершину u, который короче найденного пути из х в w, он заменяется на более короткий путь. Это соотношение должно проверяться для любой возможной из n-2 транзитных вершин при оценке пути в каждую вершину, поэтому в алгоритме имеется цикл, определенный в строке 4. Алгоритм Дейкстры нахождения кратчайших расстояний от источника до всех остальных вершин применим только тогда, когда граф не имеет контуров или когда веса всех ребер неотрицательны. Идентификаторы: d[s, t] – массив длин ребер графа для каждой пары вершин s, t X. Если ребра нет, то соответствующий элемент этого массива содержит достаточно большое число. х – вершина-источник графа < X, U>. n=|X| - число вершин графа. u, w – рабочие переменные. D[w] – массив, в котором к концу работы алгоритма будут содержаться кратчайшие длины путей из x в w для всех вершин w X.
BEGIN D[x]: =0; For w X do D[w]: =d[x, w]; T: ={X\{x}};
While T=\= do Begin w: =вершина r из T такая, что D[r]=min{D[p]: p из T}; T: ={T\{w}}; For u T do D[w]: =min[D[w], D[u]+d[u, w]]; End END Алгоритм Форда-Фалкерсона нахождения максимального потока в сети. Многие задачи исследования операций сводятся к анализу потоков, маршрутов, последовательностей событий, протекающих со времени, и других процессов, которые можно представить в виде множества взаимосвязанных элементов. Для математического представления таких процессов удобно их задание в виде графов. Рассмотрим конечный ориентированный граф Г=(X, u), в котором Х={x1,..., xn}-множество вершин, U – множество дуг. Пусть x X. Обозначим E+(x) – множество дуг графа, входящих в х, E-(x) – выходящих из х.
Множества начальных вершин дуг из Е+(х) и множество конечных вершин дуг из Е-(х) обозначим соответственно S+(x) и S-(x).

y x y
S+(x) S-(x) Рис. 3. Окрестность вершины графа.
Е-(z)=. Вершина х0 называется истоком, z-стоком, c(u) – пропускной способностью дуги. Потоком в транспортной сети называют целочисленную функцию ф(u), удовлетворяющую следующим условиям: 1) 0< =ф(u)< =с(u)
u Е+(х) u Е-(х)
При этом поток не может «накапливаться» ни в одной вершине транспортной сети, кроме истока х0 и стока z, поэтому
u Е+(х) u Е-(х) Величину Ф называют потоком транспортной сети. Дуга u называется насыщенной, если ф(u)=c(u). Поток Ф называется полным, если каждый путь из х0 в z содержит хотя бы одну насыщенную дугу. Рассмотрим разбиение R множества вершин сети Х = Х1UX2, X1 X2 X1 X2=, x0 X1, z X2, называемое разрезом сети.
u {(xi, xj): xi X1, xj X2} Поскольку для любой дуги u выполняется неравенство ф(u)< =c(u), то Ф< =r(R). Теорема Форда-Фалкерсона : максимальный поток в сети равен минимальной величине разрезов в этой сети. Алгоритм нахождения максимального потока, предложенный Фордом и Фалкерсоном, состоит в постепенном увеличении допустимого потока Ф до максимальной величины Ф*. Начальное значение потоков полагается равным нулю. Процесс увеличения потока состоит в поиске путей, на которых возможно увеличение потока, с соответствующей разметкой вершин сети. Алгоритм Форда-Фалкерсона Предполагается, что путь из истока в сток с ненулевыми пропускными способностями входящих в него дуг существует.
2. Взять некоторую вершину xi с пометкой, которая в общем случае имеет вид (+ или – xk, d(xi)), где xk – обозначение вершины, d(xi) – некоторое число. Каждой непомеченной вершине xj из S-(xi), для которой ф(xi, xj)< с(xi, xj), присвоить пометку (+xi, min[d(xi), c(xi, xj)-ф(xi, xj)]). Это означает, что поток в дуге (xi, xj) может быть увеличен (знак плюс) на величину, определяемую минимумом. Каждой непомеченной вершине xj из S+(xi), такой, что ф(xj, xi)> 0 присвоить пометку (-xi, min[d(xi), ф(xj, xi)]), что означает возможность уменьшения потока на величину, определяемую минимумом. 3. Если сток не помечен и можно пометить какую-либо вершину, кроме стока, то перейти к п.2. 4. Если оказался помеченным сток z, и в его пометку входит число d(z), то между вершинами x0 и z найдется цепь, все вершины которой помечены номерами предыдущих вершин. Для каждой помеченной вершины х в этой цепи изменить величину потока: ф'(y, x)=ф(y, x)+d(z), если х имеет пометку (+y, d(x)) или ф'(y, x)=ф(y, x)-d(z), если х имеет пометку (-y, d(x)). Пометка вершины х стирается, назначенные потоки запоминаются. При достижении (в процессе стирания пометок вершин цепи) истока х0 перейти к п.1; если же ни одну вершину пометить не удается и сток z не помечен, то перейти к построению разреза. II.Построение разреза. Искомый минимальный размер R определяется двумя множествами Х1 и Х2, где Х1 – все помеченные вершины, Х2 – вершины, которые не удается пометить. При этом полный поток Ф=Ф* должен быть равен величине полученного минимального разреза.
2.Сетевые структуры на базе теоретико-графовых моделей Типы кабелей Тип кабеля, выбранного для соединения сетевых компонентов между собой, определяет максимальную скорость передачи данных в сети и возможную удаленность компьютеров друг от друга. Это связано с частотными свойствами процессов распространения сигналов. Основными и наиболее распространенными являются следующие типы кабелей: - Коаксиальный (coaxial), подразделяющийся на толстый и тонкий; - Витая пара (twisted pair), имеющая два типа: неэкранированная (10 Base-T) и экранированная. - оптоволоконный (fiber optic).
Толстый кабель обеспечивает передачу сигналов на большие расстояния, чем тонкий, -до 500 метров, и часто используется в качестве основного магистрального кабеля (backbone). Для подключения к толстому коаксиальному кабелю применяют специальное устройство – трансивер ( TRANSmitter/reCEIVER – передатчик.приемник), устройство, преобразующее поток параллельных данных, который использует шина компьютера, в поток последовательных данных, направляемых по кабелю к другому компьютеру. Трансивер, используемый для подключения к толстому кабелю, снабжен специальным коннектором, который называют «зуб вампира» или «пронзающий ответвитель». Чтобы подключить трансивер к сетевому адаптеру, нужно подключить кабель трансивера к коннектору AUI- порта сетевой платы. Этот коннектор известен как DB-15 (15-ти контактный). Витая пара дешевле коаксиального кабеля и менее надежна. Использование неэкранированной витой пары позволяет реализовать длину сегментов соединения до 100 метров. Для подключения витой пары используются восьмиконтактные коннекторы RG-45. Оптоволоконный кабель имеет высокую стоимость и обладает рядом преимуществ: слабое затухание сигнала, практическая невозможность вскрытия оптоволокна с целью перехвата данных. Такой кабель передает данные только в одном направлении и поэтому состоит из двух волокон с отдельными коннекторами. Использование оптоволоконного кабеля теоретически может позволить осуществлять передачу данных со скоростью 200000 Мб/сек. Платы сетевого адаптера Платы сетевого адаптера принимают параллельные данные с шины компьютера и преобразуют их в последовательный битовый код, используемый при передаче по кабелю. Плата сетевого адаптера должна указать свое местонахождение или сетевой адрес, чтобы ее можно было отличить от остальных плат. Сетевые адреса определены комитетом IEEE, закрепившим за каждым производителем таких плат некоторые интервалы адресов. Эти адреса «зашиты» в микросхемы. Благодаря этому каждая плата и каждый компьютер имеют уникальный адрес в сети. Плата сетевого адаптера запрашивает у компьютера данные из памяти по шине, и если они поступают быстрее, чем может передать плата, то данные временно помещаются в буфер. Перед передачей данных передающая плата проводит диалог с принимающей платой, осуществляя согласование информации о следующих параметрах передачи: - максимальном размере блока передаваемых данных; - объеме данных, передаваемых без подтверждения о получении; - интервалах между передачами блоков данных; - интервале, в течение которого необходимо послать подтверждение; - объеме данных, которые может принять каждая плата без возникновения ситуации переполнения; - скорости передачи данных.
Глобальная сеть Internet Концепция сокетов Сетевой сокет (network socket) во многом напоминает электрическую розетку. В сети имеется множество сокетов, причем каждый из них выполняет стандартные функции. Все, что поддерживает стандартный протокол, можно «подключить» к сокету и использовать для коммуникаций. Для электрической розетки не имеет значения, что именно вы подключаете – лампу или тостер, поскольку оба прибора рассчитаны на напряжение 220 Вольт и частоту 50 Герц. Несмотря на то, что электричество свободно распространяется по сети, все розетки в доме имеют определенное место. Подобным образом работают и сетевые сокеты, за исключением того, что электроны и почтовые адреса заменены на пакеты TCP/IP и IP-адреса. Internet Protocol (IP) является низкоуровневым протоколом маршрутизации, который разбивает данные на небольшие пакеты и рассылает их по различным сетевым адресам, что не гарантирует доставку вышеупомянутого пакета адресату. Transmission Control Protocol (TCP) является протоколом более высокого уровня, собирающим пакеты в одну строку, сортирующим и перетранслирующим их по мере необходимости, поддерживая надежную рассылку данных. Третий протокол, UNIX Domain Protocol (UDP), используется вместе с TCP и может применяться для быстрой, но ненадежной передачи пакетов. Клиент/сервер Под термином сервер подразумевается любой объект с общедоступными ресурсами. Клиентом называется любой другой объект, желающий получить доступ к определенному серверу. Взаимодействие между клиентом и сервером во многом подобно взаимодействию лампы и розетки. Электрическая сеть является сервером, а лампа является клиентом напряжения. Сервер постоянно предлагает свои «услуги», в то время как клиент волен в любое время отключиться от обслуживания. В сокетах Berkley понятие сокета позволяет одному компьютеру обслуживать несколько различных клиентов одновременно, а также одновременно обрабатывать информацию различных типов. Это стало возможным после введения понятия порта, который является нумерованным сокетом на определенном компьютере. Серверу разрешено обслуживать несколько клиентов, подсоединенных к одному порту, но не одновременно. Для управления соединением нескольких клиентов процесс сервера должен быть многопоточным или иметь другие средства мультиплексирования одновременных операций ввода-вывода. Зарезервированные сокеты После физического подключения выбирается протокол высокого уровня, который зависит от используемого порта. Согласно спецификации протокола TCP/IP, первые 1024 порта резервируются для определенных задач. Порт номер 21 предназначен для протокола FTP, 23 – для Telnet, 25 – для электронной почты, 79 – для протокола finger, 80 – для HTTP, и т.д. Каждый протокол определяет, каким образом клиент должен взаимодействовать с портом. Например, протокол HTTP используется Web-броузерами и серверами для передачи гипертекстовых страниц и изображений. Работает он следующим образом. Когда клиент запрашивает файл от сервера HTTP (это действие известно под названием попадание – hit), он просто записывает имя файла в специальном формате в определенный порт и получает обратно содержимое файла. Сервер также возвращает код состояния, сообщающий клиенту о возможности удовлетворения запроса, и причину отказа.. Вот пример запроса клиентом файла /index.html, в ответ на который сервер передает содержимое файла. СЕРВЕР КЛИЕНТ Опрашивает порт 80 Подключается к порту 80 Определяет подключение Записывает «GET /index.html к серверу HTTP/1.0\n\n» Считывает до второго символа новой строки (\n) Определяет команду GET как известную команду и протокол HTTP/1.0. Считывает файл /index.html Записывает «HTTP/1.0 200 OK\n\n» («200» означает «дальше идет содержимое файла») Копирует содержимое файла в сокет Считывает файл и выводит его Отключается Отключается Транслирующие серверы Транслирующие серверы (proxy servers) передают часть протокола клиента другому серверу. Это необходимо в случаях, когда клиенты имеют определенные ограничения при подключении к серверу. Таким образом, клиент может быть подключен к другому серверу, не имеющему подобных ограничений, а тот, в свою очередь, будет осуществлять все операции клиента. Транслирующий сервер имеет возможность фильтровать определенные запросы или накапливать (кэшировать) результаты этих запросов для дальнейшего использования. Транслирующий HTTP сервер, поддерживающий кэширование, в состоянии уменьшить количество запросов связи локальных сетей с Internet. Если популярная web-страница затребована сотнями пользователей, транслирующий сервер может, считав ее содержимое с web-сервера только один раз, сохранить ее в буфере и обеспечить более быстрый доступ к ней клиентов. Адресация Internet Каждый компьютер в Internet имеет адрес. Им является число, однозначно определяющее компьютер в сети. На IP-адрес отводится 32 бита и мы часто представляем подобные адреса в виде последовательности чисел в интервале от 0 до 255, разделенных точками. Это облегчает их запоминание, поскольку адреса присваиваются отнюдь не беспорядочно – прослеживается определенная иерархия. Служба доменных имен (DNS) Internet не была бы столь дружественной сетью, если бы существовала необходимость задавать адреса только числами. Например, сложно себе представить появление ссылки на адрес «http: //192.9.9.1/» в рекламном объявлении. К счастью, существует служба, обеспечивающая поиск информации в Internet с помощью имен, - служба доменных имен (Domain Name Service - DNS). Точно так же, как четыре числа IP-адреса описывают сетевую иерархию слева направо, имя адреса Internet, называемое именем его домена, описывает положение машины в пространстве имен Internet справа налево. Например, www.starwave.com означает, что адресат находится в домене com (зарезервированном для коммерческих сетей США) и называется starwave (название компании), а www является именем определенного компьютера – в данном случае web-сервера компании starwave. www соответствует крайнему правому числу в эквивалентном IP-адресе.
Компоненты маршрутизации Маршрутизация включает в себя два основных компонента: определение оптимальных трактов маршрутизации и транспортировка информационных групп (обычно называемых пакетами) через объединенную сеть. В настоящей работе последний из этих двух компонентов называется коммутацией. Коммутация относительно проста. С другой стороны, определение маршрута может быть очень сложным процессом.
Определение маршрута Определение маршрута может базироваться на различных показателях (величинах, результирующих из алгоритмических вычислений по отдельной переменной - например, длина маршрута) или комбинациях показателей. Программные реализации алгоритмов маршрутизации высчитывают показатели маршрута для определения оптимальных маршрутов к пункту назначения. Для облегчения процесса определения маршрута, алгоритмы маршрутизации инициализируют и поддерживают таблицы маршрутизации, в которых содержится маршрутная информация. Маршрутная информация изменяется в зависимости от используемого алгоритма маршрутизации. Алгоритмы маршрутизации заполняют маршрутные таблицы неким множеством информации. Ассоциации " Пункт назначения/следующая пересылка" сообщают роутеру, что определенный пункт назначения может быть оптимально достигнут путем отправки пакета в определенный роутер, представляющий " следующую пересылку" на пути к конечному пункту назначения. При приеме поступающего пакета роутер проверяет адрес пункта назначения и пытается ассоциировать этот адрес со следующей пересылкой. В маршрутных таблицах может содержаться также и другая информация. " Показатели" обеспечивают информацию о желательности какого-либо канала или тракта. Роутеры сравнивают показатели, чтобы определить оптимальные маршруты. Показатели отличаются друг oт друга в зависимости от использованной схемы алгоритма маршрутизации. Далее в этой главе будет представлен и описан ряд общих показателей. Роутеры сообщаются друг с другом (и поддерживают свои маршрутные таблицы) путем передачи различных сообщений. Одним из видов таких сообщений является сообщение об " обновлении маршрутизации". Обновления маршрутизации обычно включают всю маршрутную таблицу или ее часть. Анализируя информацию об обновлении маршрутизации, поступающую ото всех роутеров, любой из них может построить детальную картину топологии сети. Другим примером сообщений, которыми обмениваются роутеры, является " объявление о состоянии канала". Объявление о состоянии канала информирует другие роутеры о состоянии каналов отправителя. Канальная информация также может быть использована для построения полной картины топологии сети. После того, как топология сети становится понятной, роутеры могут определить оптимальные маршруты к пунктам назначения. Коммутация Алгоритмы коммутации сравнительно просты и в основном одинаковы для большинства протоколов маршрутизации. В большинстве случаев главная вычислительная машина определяет необходимость отправки пакета в другую главную вычислительную машину. Получив определенным способом адрес роутера, главная вычислительная машина-источник отправляет пакет, адресованный специально в физический адрес роутера (уровень МАС), однако с адресом протокола (сетевой уровень) главной вычислительной машины пункта назначения. После проверки адреса протокола пункта назначения пакета роутер определяет, знает он или нет, как передать этот пакет к следующему роутеру. Во втором случае (когда роутер не знает, как переслать пакет) пакет, как правило, игнорируется. В первом случае роутер отсылает пакет к следующей роутеру путем замены физического адреса пункта назначения на физический адрес следующего роутера и последующей передачи пакета. Следующая пересылка может быть или не быть главной вычислительной машиной окончательного пункта назначения. Если нет, то следующей пересылкой, как правило, является другой роутер, который выполняет такой же процесс принятия решения о коммутации. По мере того, как пакет продвигается через объединенную сеть, его физический адрес меняется, однако адрес протокола остается неизменным. В изложенном выше описании рассмотрена коммутация между источником и системой конечного пункта назначения. Международная Организация по Стандартизации (ISO) разработала иерархическую терминологию, которая может быть полезной при описании этого процесса. Если пользоваться этой терминологией, то устройства сети, не обладающие способностью пересылать пакеты между подсетями, называются конечными системами (ЕS), в то время как устройства сети, имеющие такую способность, называются промежуточными системами (IS). Промежуточные системы далее подразделяются на системы, которые могут сообщаться в пределах " доменов маршрутизации" (" внутридоменные" IS), и системы, которые могут сообщаться как в пределах домена маршрутизации, так и с другими доменами маршрутизации (" междоменные IS" ). Обычно считается, что " домен маршрутизации" - это часть объединенной сети, находящейся под общим административным управлением и регулируемой определенным набором административных руководящих принципов. Домены маршрутизации называются также " автономными системами" (AS). Для определенных протоколов домены маршрутизации могут быть дополнительно подразделены на " участки маршрутизации", однако для коммутации как внутри участков, так и между ними также используются внутридоменные протоколы маршрутизации.
Алгоритмы маршрутизации Алгоритмы маршрутизации можно дифференцировать, основываясь на нескольких ключевых характеристиках. Во-первых, на работу результирующего протокола маршрутизации влияют конкретные задачи, которые решает разработчик алгоритма. Во-вторых, существуют различные типы алгоритмов маршрутизации, и каждый из них по-разному влияет на сеть и ресурсы маршрутизации. И наконец, алгоритмы маршрутизации используют разнообразные показатели, которые влияют на расчет оптимальных маршрутов. В следующих разделах анализируются эти атрибуты алгоритмов маршрутизации. Оптимальность Оптимальность, вероятно, является самой общей целью разработки. Она характеризует способность алгоритма маршрутизации выбирать " наилучший" маршрут. Наилучший маршрут зависит от показателей и от " веса" этих показателей, используемых при проведении расчета. Например, алгоритм маршрутизации мог бы использовать несколько пересылок с определенной задержкой, но при расчете " вес" задержки может быть им оценен как очень значительный. Естественно, что протоколы маршрутизации должны строгo определять свои алгоритмы расчета показателей.
Живучесть и стабильность |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-10-03; Просмотров: 250; Нарушение авторского права страницы
 и набор U неупорядоченных пар объектов (
и набор U неупорядоченных пар объектов ( 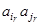 ) из Х называется графом Г. Объекты множества Х называются вершинами графа, а наборы объекта U – ребрами графа. Про ребра
) из Х называется графом Г. Объекты множества Х называются вершинами графа, а наборы объекта U – ребрами графа. Про ребра  будем говорить, что они соединяют вершины
будем говорить, что они соединяют вершины  и
и  .
.  В случае, если множество Х и набор U состоят из конечного числа объектов и пар, то граф Г называется конечным.
В случае, если множество Х и набор U состоят из конечного числа объектов и пар, то граф Г называется конечным. называется путем, соединяющим вершины
называется путем, соединяющим вершины  , не проходящий дважды одно ребро, называется циклом, если
, не проходящий дважды одно ребро, называется циклом, если  . В частности, цикл
. В частности, цикл  будем называть петлей.
будем называть петлей.

















 2) ф(u) - ф(u) = 0 для любой вершины x=/=x0, x=/=z.
2) ф(u) - ф(u) = 0 для любой вершины x=/=x0, x=/=z.  I. Увеличение потока.
I. Увеличение потока.