
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
КЛАССИФИКАЦИЯ ЗАДАЧ математического программированияСтр 1 из 7Следующая ⇒
НЕОБХОДИМЫЙ МАТЕМАТИЧЕСКИЙ АППАРАТ Для удобства изучения дальнейшего материала ниже приводятся некоторые математические сведения, широко используемые в данном учебном пособии. Матрицы и векторы Под матрицей A размерности ( m ´ n) понимается прямоугольная таблица, состоящая из элементов aij и записанная в виде m строк и n столбцов.
Если m = n, то матрица A – квадратичная матрица порядка n. Две матрицы считаются равными, если aij = bij, Суммой матриц A и B размерности ( m ´ n) называется матрица C размерности ( m ´ n) с элементами cij = aij + bij. Сложение матриц подчиняется ассоциативному и коммутативному законам:
Произведением матрицы A на число l называется матрица
Вычитание матриц определяется так: A – B = A + (-1) B. Произведением матриц A( m ´ r) и B( r ´ n) называется матрица С( m ´ n) с элементами
Произведение матриц ассоциативно:
но не коммутативно:
Матрица A называется нулевой, если все её элементы равны нулю aij = 0. Очевидно, что имеют место равенства
Замечание. Если произведение матриц равно нулю, то это еще не значит, что одна из них или обе нулевые. Квадратная матрица называется диагональной, если aij = 0 при i ¹ j. Квадратная матрица In порядка n называется единичной, если In = ||d ij||, где d ij – символ Кронекера.
Матрица AT называется транспонированной по отношению к A, если aijT = aji. Очевидно, имеют место соотношения
Квадратная матрица называется симметричной, если A = AT. Иногда матрицу удобно разбить на подматрицы, проведя условные прямые между строками и столбцами.
где Если мы имеем две матрицы, разбитые на подматрицы
и, если произведения определены, то
Если матрица состоит из одного столбца, то это – вектор-столбец:
Вектор ej называется единичным, если все элементы его равны нулю, кроме j-го, который равен единице {??? } Единичный вектор такой что его норма = 1.
Скалярное произведение двух n-мерных векторов определяется так
Говорят, что квадратная матрица имеет обратную матрицу A-1, если
Если обратная матрица существует, то матрица A называется неособенной, в противном случае – особенной. Если A и B – неособенные матрицы, то имеют место равенства
Следом квадратной матрицы называют сумму её диагональных элементов
Квадратичные формы Квадратичной формой n переменных x1, x2, …, xn называется функция z, равная
Квадратичную форму можно представить в виде
где Считается, что в квадратичной форме матрица A симметричная. Квадратичная форма z = xTAx, а вместе с ней матрица A, называется положительно- определённой, если z > 0 для любых x не равных нулю. Квадратичная форма z = xTAx, а вместе с ней матрица A, называется отрицательно-определённой, если z < 0 для любых x не равных нулю. Квадратичная форма z = xTAx, а вместе с ней матрица A, называется положительно-полуопределенной, если z ³ 0 для любых x и существует x ¹ 0, для которого z = 0. Квадратичная форма z = xTAx, а вместе с ней матрица A, называется отрицательно- полуопределенной, если z £ 0 для любых x и существует x ¹ 0, для которого z = 0. Нетрудно видеть, что в случае двух переменных для положительной определенности квадратичной формы
необходимо и достаточно выполнение условий
В случае n переменных справедлива следующая теорема (критерий Сильвестра): А. Квадратичная форма z = xTAx будет положительно-определенной тогда и только тогда, когда все определители Dk ,
Б. Квадратичная форма z = xTAx будет отрицательно-определенной тогда и только тогда, когда Dk < 0, если k – нечётное, Dk > 0, если k – чётное.
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ МАТЕМАТИЧЕСКОГО ПРОГРАММИРОВАНИЯ В данном разделе приводятся минимальные сведения по теоретическому обоснованию методов оптимизации, излагаемых в учебном пособии. По существу речь идет о необходимых и достаточных условиях оптимальности.
Определения минимума и максимума Говорят, что функция f( x), определённая на множестве X, достигает в точке x абсолютного (глобального) минимума, если f( x*) £ f( x) для любого x Î X. Функция f( x) достигает в точке x относительного (локального) минимума, если неравенство f( x*) £ f( x) имеет место для любого допустимого x из e-окрестности точки x*, то есть для x, удовлетворяющего условиям
Аналогичные определения можно дать для абсолютного и относительного максимума. Отличие состоит лишь в знаке неравенства, которое для максимума имеет вид f( x*) ³ f( x). Минимум и максимум называются экстремумами функции. Различают сильные и слабыеэкстремумы. Если в соответствии с определением соответствующее неравенство определяется строго
то экстремум называют сильным (строгим), в противном случае – слабым (нестрогим). Если в точке x* функция f( x) достигает минимума, то функция – f( x) в этой точке x* достигает максимума. Учитывая это обстоятельство, в дальнейшем всюду за основу принимается рассмотрение задача минимизации функции.
Иллюстрация приведенных определений представлена на рис. 3.1, где показано, что функция f( x) имеет следующие экстремумы: - сильный относительный минимум в точке 1, - сильные относительные максимумы в точках 2 и 4, - абсолютный минимум в точке 3, - слабый относительный минимум в точке 5, - точка 6 является точкой перегиба. Упражнение 1. Показать, что ряд Тейлора функции f( x), полученный разложением в окрестности точки x* с точностью до членов второго порядка малости, имеет вид
Упражнение 2. Показать, что
Методы первого порядка С методической точки зрения анализ методов целесообразно начать с методов первого порядка. Основу этих методов составляют так называемые градиентные методы, сущность, которых заключается в том, что каждое новое приближение х k+1 к минимуму функции f( x) формируется на основе текущего приближения xk по схеме
где через h k обозначена величина шага поиска в направлении антиградиента -Ñ f(xk) на k-й итерации. По существу, данная схема основана на линейной аппроксимации функции f(x) в окрестности точки xk. Обоснованием схемы может служить тот факт, что направление антиградиента -Ñ f(xk) в точке xk определяет (задает) локально наилучшее направление спуска, так как оно совпадает с направлением наискорейшего уменьшения значения функции f(x). В зависимости от способа задания шага поиска различают различные градиентные методы. Некоторые из них рассматриваются ниже.
Метод градиентного спуска Сущность градиентного метода спуска заключается в задании шага поиска h k на каждой итерации достаточно малым. Если предположить, что шаг поиска бесконечно мал, то траектория поиска описывается дифференциальным уравнением
Метод является локально-оптимальным, так как в каждой точке траектории поиска используется наилучшее направление спуска, определяемое антиградиентом (см. рис.5.1). Реализовать такую траекторию можно лишь приближённо, полагая шаг поиска достаточно малым, но конечным.
Реализация метода требует большого количества шагов или итераций, что может привести к неприемлемым затратам машинного времени. Поэтому на практике стремятся использовать простейшую модификацию метода, используя постоянный достаточно большой (по сравнению с градиентным методом) шаг поиска.
Метод наискорейшего спуска К числу методов с переменным шагом относится и метод наискорейшего спуска. Однако теперь шаг поиска hk определяется наилучшим образом на каждой итерации из условия обращения в минимум функции f( x) в направлении антиградиента (рис.5.2),
Таким образом, реализация метода предполагает на каждой итерации решение вспомогательной задачи одномерной оптимизации. Несмотря на это, как правило, метод наискорейшего спуска оказывается более экономным не только по числу машинных операций, но и по затратам машинного времени. При практической реализации градиентных методов процесс поиска заканчивается, если для всех компонент вектора градиента выполняются условия
где d - некоторое заданное число, характеризующее точность нахождения минимума. Методы второго порядка Квазиньютоновские методы Рассмотрим теперь группу методов, называемых квазиньютоновскими, сущность которых состоит в воспроизведении квадратичной аппроксимации функции f( x) по значениям ее градиентов в ряде точек. Тем самым эти методы объединяют достоинства градиентных методов (т.е. не требуется вычисление вторых производных) и методов Ньютона (быстрая сходимость вследствие использования квадратичной аппроксимации). Структура методов этой группы такова:
Здесь, как и ранее, шаг поиска предполагается выбирать из условия
а матрица Hk формируется и пересчитывается на основе k-й итерации так, чтобы в пределе она переходила в матрицу, обратную гессиану Обсудим возможные способы формирования матриц Hk, аппроксимирующих матрицу
После введения обозначения
нетрудно установить, что
Учитывая последнее равенство, потребуем, чтобы оно выполнялось и для нового приближения H k+1, т.е.
Последнее условие принято называть квазиньютоновским. Кроме того, потребуем, чтобы Hn = A-1. Оказывается можно предложить различные алгоритмы пересчета матриц Hk, удовлетворяющих сформулированным условиям. Приведем лишь некоторые из них […] а) алгоритм Давидона — Флетчера — Пауэлла
б) алгоритм Бройдена
в) алгоритм Бройдена — Флетчера — Шенно
Можно показать, что все представленные алгоритмы для квадратичных функций f( x) совпадают. Для неквадратичных функций эффективность этих алгоритмов зависит от их вида.
Методы одномерного поиска Как мы видели, большинство методов оптимизации предусматривает поиск минимума функции одной переменной — шага поиска. Этот поиск является составной частью общей процедуры минимизации. От того, насколько хорошо организован Ограничимся рассмотрением
Величину интервала [a, b ], называемого также начальным интервалом неопределенности, обозначим через L0. Будем по-прежнему для минимизируемой функции использовать обозначение f( x), считая, однако, теперь, что х — скаляр. В частном случае под х понимается шаг поиска h, который должен быть выбран в рассмотренных выше алгоритмах. Обычный перебор Простейшим методом одномерного поиска является обычный перебор значений f( xj) минимизируемой функции f( x) в конечном числе точек
Совершенно очевидно, что равномерное распределение всех экспериментов на интервале поиска [а, b] не является наилучшим. Метод дихотомии Эффективность поиска можно существенно повысить, если эксперименты проводить попарно, анализируя результаты после каждой пары экспериментов. Наиболее эффективным проведением экспериментов каждой пары является такое, при котором интервал неопределенности сокращался бы Если перед проведением первой пары экспериментов величина интервала неопределённости, на которой находится искомый минимум, равна L0, то интервал неопределённости L2 после проведения двух экспериментов Если требуется провести ещё пару экспериментов, то наилучшее распределение их будет
Нетрудно сообразить, что при использовании метода дихотомии интервал неопределенности после проведения n/2 пар экспериментов практически будет равен
Отсюда видно, что с ростом n эффективность метода дихотомии по сравнению с простым перебором растет. Например, при n=12 эффективность метода дихотомии примерно в 10 раз выше метода перебора. Тем не менее, метод дихотомии Метод Фибоначчи Оптимальную стратегию последовательного поиска дает метод Фибоначчи. Сущность его состоит в том, что каждые два соседних эксперимента, кроме двух последних, располагаются на текущем интервале неопределенности на одинаковом расстоянии от левого и правого его концов, т.е. симметрично. Что касается проведения двух последних экспериментов, то они проводятся в соответствии с методом дихотомии.
Схема Для последних двух экспериментов согласно методу дихотомии имеем
Введем в рассмотрение последовательность чисел Фибоначчи
Нетрудно установить, что для любого ( n- k)-го эксперимента интервал неопределенности определяется формулой
Так как проведение первого эксперимента не изменяет интервала неопределенности, т.е.
Эффективность метода оказывается наибольшей среди рассмотренных ранее. Например, при n= 12 она превышает эффективность метода дихотомии более, чем в 3, 5 раза. Недостаток метода Фибоначчи состоит в том, что количество экспериментов n должно быть задано заранее. Если же поиск методом Фибоначчи начат, то на любом шаге Указанного недостатка лишен метод золотого сечения, который, уступая несколько методу Фибоначчи, все же существенно превосходит по эффективности метод дихотомии. Метод золотого сечения Метод золотого сечения, как и метод Фибоначчи, основан на симметрии экспериметов относительно текущего интервала неопределенности. Дополнительно он предполагает
Последнее соотношение и обусловило название метода. «Золотым сечением» принято называть деление отрезка на две части так, чтобы отношение всего отрезка к большей части равнялось отношению большей части к меньшей
Разделим первое соотношение на Lj, получим
откуда находим единственное положительное решение для параметра
Эффективность метода характеризуется величиной
Сравнивая величины F n и c n-1, можно установить, что при больших n эффективность метода золотого сечения приближается к эффективности метода Фибоначчи. Это обстоятельство и обусловило широкое распространение метода золотого сечения.
Упражнение. Сравнить эффективность методов одномерного поиска, построив зависимости ln( L0/ Ln) от числа n для каждого из рассмотренных методов.
Методы нулевого порядка Перейдем теперь к рассмотрению методов нулевого порядка, требующих для своей реализации лишь значения целевой функции f( x) и не использующих никаких частных производных. Эти методы иногда называют также прямыми. В тех случаях, когда градиенты и гессианы могут быть легко вычислены, прямые методы могут, конечно, оказаться менее эффективными, чем методы первого или второго порядка. Однако в целом ряде случаев прямые методы оказываются единственными практически применимыми методами. Это относится, в частности, к случаям, когда целевая функция имеет разрывы или целевая функция задана не в явном виде, а косвенно через какие-либо уравнения, относящиеся к различным подсистемам некоторой сложной системы и т.д. В настоящее время предложено много различных прямых методов поиска. Характерным для этих методов является их эвристичность. В связи с этим сходимость и эффективность методов может быть подтверждена лишь экспериментально на примерах решения конкретных задач. Метод конфигураций Метод конфигураций является более перспективным для задач большой размерности. В соответствии с этим методом вначале происходит обследование окрестности некоторой точки х0 (например, путем изменения значений одной или нескольких компонент вектора х0). После отыскания приемлемого направления производятся вычисления целевой функции при постепенно увеличивающемся шаге (тем самым устанавливается конфигурация поиска). Увеличение шага продолжается до тех пор, пока поиск в этом направлении приводит к уменьшению функции. Если уменьшения функции не происходит, то шаг уменьшают. После нескольких неудач при сокращении шага от принятой конфигурации отказываются и переходят к новому обследованию окрестности. Таким образом, согласно этому методу делаются попытки найти наилучшее направление поиска с тем, чтобы двигаться вдоль него. Метод прост в реализации. (Где она? пробовали – не вышло )Но и для этого метода характерна возможность (хотя и в меньшей степени) заедания вблизи локального минимума или явно выраженного оврага. По своей сути метод конфигураций является достаточно общим методом прямого поиска. Большинство методов этой группы может рассматриваться как его конкретизация. Методы случайного поиска Большую группу методов прямого поиска, требующих знания лишь значений целевой функции, составляют, так называемые, методы случайного поиска. В отличие от детерминированных Метод наилучшей пробы Смысл данного метода заключается в следующем. Из точки x k делается т реализаций xkj единичных случайных независимых векторов, равномерно распределенных по всем направлениям (см. рис.5.13). С их помощью формируется т проб: {hпрxkj },
Выбирается наилучшее направление из условия
Именно в этом направлении производится рабочий шаг поиска
В данном алгоритме в отличие от предыдущего алгоритма выбору подлежат два параметра hраб и т. Очевидно, что с увеличением числа проб т наилучшее направление приближается к направлению, обратному градиенту, и в пределе при т®¥ совпадает с ним. Преимущество метода по сравнению с градиентными методами состоит, однако, в том, что здесь может иметь место неравенство т < п, где п — размерность вектора x, Другими словами, количество проб может быть существенно меньше размерности задачи. А это важно, особенно при больших размерностях задачи. Кроме того, алгоритм, как и другие методы случайного поиска, обладает возможностью определения глобального экстремума. К недостаткам метода следует отнести возможность неудачного шага, т.е. шага в направлении возрастания целевой функции, и малую эффективность накопления информации. Первый недостаток можно устранить, если использовать, например, следующую модификацию алгоритма
Однако следует иметь в виду, что выигрыш, полученный за счет исключения возможности неудачного шага, может и не покрыть дополнительных потерь, необходимых для этого исключения, а неудачные шаги как раз являются теми шагами, которые позволяют отыскивать глобальный экстремум (точнее, преодолевать локальные экстремумы). Малую эффективность накопления информации следует понимать так. Из всех пробных шагов выбирается лишь лучший, все остальные отбрасываются, несмотря на то, что в них содержится информация о поведении целевой функции в районе текущей точки. Очевидно, алгоритм можно улучшить, если принимать решение о направлении рабочего шага не только по результату наилучшей пробы. В простейшем варианте, кроме наилучшей, можно учесть и наихудшую пробу
Если окажется, что модуль приращения целевой функции при наихудшей пробе больше модуля приращения целевой функции при наилучшей пробе, то рабочий шаг целесообразно сделать в направлении
Комбинированные методы Эти методы применяются для улучшения сходимости методов случайного поиска, а также для ликвидации ряда недостатков детерминированных методов. Стохастический вариант метода Гаусса-Зейделя. Основной недостаток метода Гаусса-Зейделя состоит в слабой эффективности при оптимизации овражных функций и при наличии ограничений. Этот недостаток может быть устранён, если движение вдоль координатной оси заменить движением в случайном направлении. Метод оврагов. В случае многомерных оврагов полезно в начале поиска взять несколько случайных точек x01, x02, …, x0 n и произвести спуск на дно оврага в точки x11, x12, …, x1 n. Далее по этим точкам выбрать направление оврага, например, с помощью метода статистического градиента. Алгоритм случайного перебора локальных экстремумов. Для поиска глобального экстремума можно использовать любой детерминированный метод поиска локального экстремума, комбинируя его со случайным подбором начальных условий поиска. Такой алгоритм поиска является по сути дела алгоритмом случайного перебора локальных экстремумов и применим при большом их числе. Блуждающий глобальный поиск. Этот метод является статистическим обобщением метода градиентного спуска. Чтобы придать поиску глобальный характер, на траекторию градиентного спуска накладываются случайные отклонения x( t), которые создают режим случайного блуждания. Движение точки x(t) в процессе поиска описывается уравнением
где h – параметр, играющий роль шага поиска при численной реализации данного уравнения, а x( t) - n-мерный случайный процесс типа белого шума с нулевым математическим ожиданием и спектральной плотностью s2. Процесс, описываемый этим выражением, является Марковским случайным процессом диффузионного типа. Плотность распределения вероятности p( x, t) удовлетворяет уравнению Фоккера-Планка-Колмогорова
У этого уравнения есть стационарное решение
где c – формирующий множитель. Максимальное значение p( x) соответствует точке глобального минимума функции f( x), следовательно, наиболее вероятное положение точки x в результате достаточно длительного поиска – это положение глобального минимума. Упражнение 1. Сравнить качественно траектории поиска минимума функции f( x)=4( x1-5)2 + ( x2- s)2 различными методами случайного поиска. (Как это предполагается делать? ) Упражнение 2. Показать, каким образом происходит изменение траекторий поиска минимума функции f( x) = x12 + x22 – cos18 x1 – cos18 x2 методом случайного поиска с направляющим конусом при изменении параметров y, hраб, считая, что m достаточно велико. ( Как это сделать? )
Похоже, разд.5.5 это запись конспекта лекций, прочитанного кем-то (Заниным? ). Нуждается в кардинальной редакции. В, В,!! У нас же есть пособие «Решение задач матпрограммирования в среде Delphi», в котором приведены как реализации алгоритмов, так и сведения о вычислении производных, оценках точности и т.п. Этим пособием пользуются наши студенты при выполнении курсовых работ. Как предплогается выполнять упраженеия по построению линий уровня? – Матлаб? |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-10-24; Просмотров: 304; Нарушение авторского права страницы
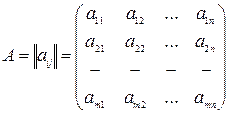 .
.
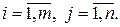
 .
.



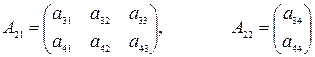 .
.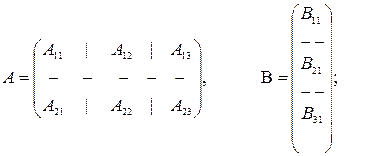




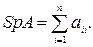

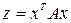 ,
,
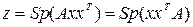 ,
,

 .
.
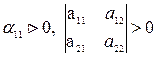 .
.
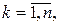 матриц
матриц  положительны, т.е.
положительны, т.е. .
.

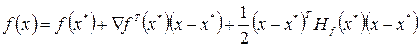 .
.
 .
.
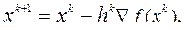




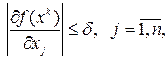


 . Тем самым в пределе методы этой группы переходят в ньютоновские методы.
. Тем самым в пределе методы этой группы переходят в ньютоновские методы. . Можно, конечно, воспользоваться обычной конечно-разностной аппроксимацией гессиана с последующим обращением этой матрицы. Однако такой подход не всегда является наилучшим. Он требует больших вычислительных затрат. Идея квазиньютоновских методов заключается в построении аппроксимации для обратной матрицы
. Можно, конечно, воспользоваться обычной конечно-разностной аппроксимацией гессиана с последующим обращением этой матрицы. Однако такой подход не всегда является наилучшим. Он требует больших вычислительных затрат. Идея квазиньютоновских методов заключается в построении аппроксимации для обратной матрицы 

 ,
,
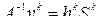 .
.






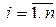 переменной х, равномерно распределенных на интервале [а, b], с последующим выбором наименьшего значения
переменной х, равномерно распределенных на интервале [а, b], с последующим выбором наименьшего значения  Значение
Значение  в силу свойства унимодальности может быть приближенно принято за искомое оптимальное значение. Очевидно, точность такого процесса определяется количеством экспериментов, связанных с
в силу свойства унимодальности может быть приближенно принято за искомое оптимальное значение. Очевидно, точность такого процесса определяется количеством экспериментов, связанных с 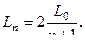 (поправил ф-лу) Таким образом, эффективность процесса поиска можно оценить отношением
(поправил ф-лу) Таким образом, эффективность процесса поиска можно оценить отношением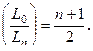 (поправил ф-лу)
(поправил ф-лу)
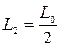 .
. . Общая схема алгоритма метода дихотомии представлена на рис.5.6.
. Общая схема алгоритма метода дихотомии представлена на рис.5.6.
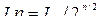 . Следовательно, эффективность метода характеризуется величиной
. Следовательно, эффективность метода характеризуется величиной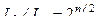 . (поправил ф-лу)
. (поправил ф-лу)

 .
.
 .
Поэтому получаем
.
Поэтому получаем
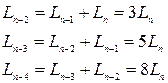


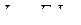
 то
то 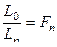 (поправил ф-лу)
(поправил ф-лу)

 ,
,
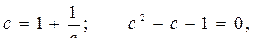
 Поиск минимума по методу золотого сечения (рис. 5.8) производится так же, как и по методу Фибоначчи. Отличие заключается лишь в проведении двух первых экспериментов. В данном случае они располагаются симметрично на интервале [а, b] и на расстоянии L0/с от его концов. После проведения n экспериментов интервал неопределенности будет равным
Поиск минимума по методу золотого сечения (рис. 5.8) производится так же, как и по методу Фибоначчи. Отличие заключается лишь в проведении двух первых экспериментов. В данном случае они располагаются симметрично на интервале [а, b] и на расстоянии L0/с от его концов. После проведения n экспериментов интервал неопределенности будет равным где hпр — величина пробного шага.
где hпр — величина пробного шага.


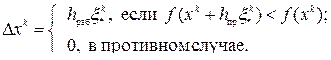
 для которой
для которой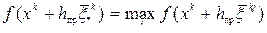 .
.
 , т.е.
, т.е.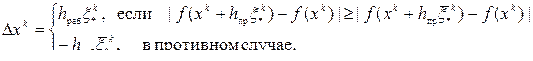


 , при t ® ¥ ,
, при t ® ¥ ,