
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
КОНЦЕПЦИЯ ИНФОРМАЦИОННЫХ СИСТЕМСтр 1 из 14Следующая ⇒
ВВЕДЕНИЕ Современные мобильные стремительно развивающиеся, носящие глобальные масштабы процессы в производственной и хозяйственной, научно-технической и научно-организационной, общественно-политической и социальной областях человеческой деятельности сложны прежде всего тем, что требуют перманентного изменения их участников. Открывая новые перспективы, эти процессы одновременно вскрывают и различные проблемы, к которым относятся: 1) интенсификация освоения новых знаний, 2) форсирование процессов получения и обработки информации, 3) овладение эффективными технологиями, современными инструментариями. Возможно ли сегодня в условиях научно-технической революции при скоротечных жизненных процессах оперативно осваивать, воспринимать нарастающие потоки новых знаний, лавинообразно увеличивающиеся объемы информации, успешно их использовать в решении практических задач? Существует ли какой-либо катализатор для ускорения адаптации в перестроечных процессах? Где его найти, как применить для достижения своих целей? Практика ведущих мировых государств уверенно дает утвердительный ответ на все перечисленные вопросы. Рецепт - освоение и повсеместное применение современных компьютерных и информационных технологий на базе ЭВМ, персональной компьютерной техники, локальных и глобальных вычислительных информационных сетей, рабочих станций. Сегодня информатизация общества - это свершившийся факт. Стало очевидным, что информация - это не просто научная категория, а коммерческая, являющаяся таким же принципиальным фактором развития, как сырье, энергия. Теперь для восполнения уменьшающихся запасов сырья и энергии человечество остро нуждается в информации. Информация открывает новые пути более рационального и экономного получения средств для дальнейшего научно-технического прогресса, развития всех сфер человеческой деятельности. Любая серьезная проблема неразрешима без переработки значительных объемов информации и налаженных коммуникационных процессов. Исследования американских специалистов, отраженные в табл.В1, наглядно иллюстрируют эффективность качественного информационного обеспечения при проведении исследовательских и проектных работ. Из таблицы видно, что даже у высококвалифицированных специалистов временные затраты по выполнению работ можно сократить более чем в 1, 5 раза лишь за счет своевременного и полного информационного обеспечения. Для серьезных разработок это дает выигрыш в несколько лет.
Таблица В1
Дальнейший рост объема информации в еще большей степени повышает эффективность и актуальность систем информационного обеспечения. По данным ЮНЕСКО, около половины занятого населения наиболее развитых стран непосредственно участвует в процессах производства и распространения информации. В ряде стран до половины национального продукта связано с информационной деятельностью общества. Информатизация превратилась в важнейший ресурс общества, стала фактором производственной деятельности на всех уровнях. В наше время информатика - это основа успеха в науке, технике, коммерции, бизнесе, менеджменте, политике, в любой духовной, культурной, производственной деятельности человека. Информационные ресурсы - продукт интеллектуальной деятельности наиболее квалифицированной и творчески активной части трудоспособного населения. В последней четверти ХХ века информационные ресурсы достигли столь рекордных объемов, что были введены понятия " информационного взрыва", " информационной революции". Подтверждением тому является увеличение информационного потока с начала текущего столетия более чем в 30 раз. Ежегодно в мире выпускается более 100 тыс. журналов на различных языках, 5 млн. научных статей, книг, брошюр. Всемирный фонд описаний патентов содержит около 500 млн. страниц текста, его ежегодный прирост - 1 млн. документов. В мире ежеминутно печатается примерно 2 тыс. страниц научных текстов, каждый час регистрируется 15-20 изобретений или открытий. Современный специалист должен ежедневно прочитывать примерно 1.5 тыс. страниц информации. В США около 50% рабочих и служащих заняты информационным обслуживанием. Однако практически вследствие невозможности оперативно проанализировать все научно-технические публикации немало разработок дублируется. Например, Американское химическое общество информирует, что каждое десятое проводимое в США исследование излишне, так как ранее подобная работа уже была проделана и результаты опубликованы. Сегодня информационное невежество - прямой путь к банкротству. Вместе с тем информационный поток уже опережает возможности человека по его обработке и использованию, так как мозг человека не беспределен. Необходимо изыскание и применение принципиально новых методов и средств восприятия, передачи, обработки, хранения и распространения информации, способных оперировать с большими массивами информации в реальном времени. В настоящее время это реализовано - на базе компьютеров создана информационная индустрия, определившая переход к безбумажным технологиям обмена информацией на основе видеотелефонов, факсимильной передачи документов, видеотекстных систем, электронной почты, телеконференций, локальных и глобальных сетей передачи данных, спутниковой связи, баз и банков данных, информационно-поисковых систем, автоматизированных рабочих мест. В мире работает несколько сотен информационных центров, имеющих около 3 000 баз данных, обеспечивающих удаленный диалоговый режим пользования. Информационная индустрия весьма доходна. В 1990 г. прибыль американских компаний, вовлеченных в информационную индустрию, составила 1 триллион долларов. Феномен информации инициировал новую науку - науку об информации. Ее задачами являются: изучение свойств информации, методов управления информационными потоками и их использования, методов обработки информации для оптимального хранения, поиска и распространения. Можно сказать, что в настоящее время мировое сообщество все более превращается в гигантскую информационную систему. При этом в общем случае информационной системой называется функциональная система, предназначенная для записи, хранения, обработки и выдачи информации по запросам пользователей. В соответствии с документами ЮНЕСКО для информатики введено следующее определение: ИНРФОРМАТИКА - это крупное научное направление, которое включает методы и средства сбора, анализа и обработки информации на основе достижений микропроцессорной, компьютерной техники и технологий, средств и систем коммуникаций в целях научно-технического прогресса и социального развития мирового сообщества. Методы и средства информатики, материализуясь, доходят до потребителя в виде новых информационных технологий, т. е. современных видов информационного обслуживания на базе компьютерных средств и коммуникаций. Компьютер открыл эру безбумажной технологии. По мнению академика Н.Н. Моисеева, создание компьютера столь же крупная веха в становлении человечества, как и использование огня. Контрольные вопросы 1. В чем сложность перестроечных процессов? 2. Что является катализатором ускорения адаптации в перестроечных процессах? 3. Определите понятие " информационный взрыв", приведите иллюстрирующие примеры. 4. Определите понятие " информационные ресурсы" и обоснуйте их значимость. 5. Что вкладывается в понятие информатика? 6. Приведите характеристики, иллюстрирующие динамику развития технических и экономических факторов средств хранения информации. 7. Укажите основные направления, в которых актуально применение ПЭВМ. 8. Каковы основные аспекты решения различных прикладных задач на ПЭВМ? База данных База данных (БД) - это объект управления в БнД. БД описывает состояние объектов предметной области на определенный момент времени совокупностью предложений на некотором формализованном языке. При этом определяются значения всех факторов на данный момент в виде совокупности взаимосвязанных, хранящихся вместе данных. Более подробное рассмотрение БД - предмет дальнейшего изучения.
Словарь данных Словарь данных (СД) - это специальная система для хранения единообразной и централизованной информации о всех ресурсах и данных. Он должен обеспечивать пользователей единой терминологией при обслуживании запросов по данной ПО. СД централизованно накапливает и описывает суммарные ресурсы данных БнД как при его проектировании, так и на стадии функционирования. СД содержит информацию: · об объектах, их свойствах и отношениях для данной ПО; · о данных, хранимых в БД: наименованиях данных, их структурах; связях с другими данными; возможных значениях, форматах представления; источниках возникновения; кодах защиты и разграничениях доступа к данным со стороны пользователей. СД должен: · способствовать уменьшению избыточности и противоречивости данных; · хранить централизованное описание данных, обеспечивающее централизованный ввод новых данных, изменение существующих либо удаление устаревших данных из системы. В БнД в зависимости от типа СУБД могут использоваться два вида СД: · СД, интегрированный с СУБД; · независимый СД. В первом случае в СУБД имеются программные средства ведения словаря. Описания данных хранятся в СД в единственном экземпляре и используются при работе системы. СД может выполнять и контролирующие функции. Во втором случае для СУБД должен разрабатываться специальный пакет программ для ведения СД. Недостаток этого вида СД в том, что имеет место избыточность описания данных - в библиотеке СУБД и в СД. При этом под избыточностью БД понимается дублирование экземпляров данных в БД. Избыточность вызывает: дополнительные ресурсы для хранения копий данных; при модификации данного необходимо обновление всех его копий; увеличение вероятности противоречивости информации из-за ошибок при обновлении копий данных.
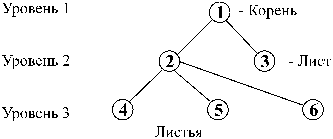
Иерархическая модель данных Иерархическая модель данных – это модель, имеющая древовидную графовую структуру (Рис. 0.13), представляющую собой иерархию элементов, называемых вершинами (или узлами), соединенных между собой дугами (или ветвями). На верхнем уровне иерархии, называемом первым, находится единственный узел, называемый корнем. Узлы следующего более низкого уровня порождаются предыдущими узлами. Каждый узел более высокого уровня может породить один или несколько узлов следующего уровня. Узлы, не имеющие порожденных, называются листьями. Иерархическая структура используется как для логического, так и для физического описания данных. Файлы с записями, связанными древовидной структурой, называются иерархическими.
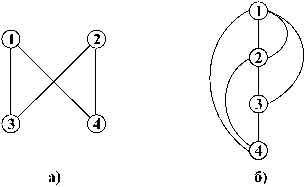
Рис. 0.13 Сетевая модель данных Сетевой моделью данных называется структура, в которой порожденный элемент может иметь больше одного исходного элемента. На Рис. 0.14, а каждый порожденный элемент 3 и 4 имеет по два исходных: элементы 1 и 2. На Рис. 0.14, б нижний элемент 4 имеет три исходных: элементы 1, 2, 3.
Рис. 0.14
Для сетевых моделей данных, как и для иерархических, рассматривается уровневость. Так, структура на рис.2.14, а является двухуровневой, а на Рис. 0.14, б - четырехуровневая. В зависимости от уровней связи сетевые модели разделяются на два вида структур: · сетевые модели простой структуры - при наличии связей типа 1: 1 и 1: М; · сетевые модели сложной структуры - при наличии связей типа М: М. Реляционная модель данных Реляционная модель данных основана на теоретико-множественном подходе. Ее базу составляют методология и язык, разработанные Коддом в 1972 г. Реляционной моделью данных называется модель, представляемая в виде двухмерной таблицы (Рис. 0.15), информационными единицами которой являются поля, домены и кортежи. Для реляционной модели данных используется также термин " отношение". Доменом называется совокупность значений какого-либо типа поля. Из домена извлекаются требуемые конкретные значения этого поля. Кортежем называется запись, или строка, реляционной таблицы. По количеству столбцов в кортеже определяется размерность реляционной модели данных, или отношения. Так, при размерности n реляционная модель будет степени n или n-мерной. Для различных пользователей из БД интересны различные наборы данных и связи между ними. Для одних пользователей требуется извлекать подмножества полей таблицы с целью создания таблиц меньшей размерности, а для других пользователей, наоборот, объединять поля в таблицы большей размерности. Следовательно, с логической точки зрения, реляционная модель данных ПО - это множество двухмерных таблиц, называемых также отношениями с операторами извлечения и объединения полей. Для представления структур реляционных моделей данных, или отношений, можно вместо таблиц использовать рассмотренные ранее строковые записи. В этих записях указывается тип отношения, затем в круглых скобках размещаются через запятую имена доменов, или атрибутов. При этом атрибуты ключей размещаются на первых позициях и подчеркиваются: (4.1) Тип отношения(Атрибут1, Атрибут2, …, АтрибутN).
Домен Рис. 0.15
В отношении (4.1) имена атрибутов, состоящих из нескольких слов, как отмечалось ранее, записываются без пробелов между словами, но каждое новое слово записывается с большой буквы. Пример. (4.2) Сотрудник(NТабСотрудника, ФИО, Задание, ВремяВыполненияЗадания).
Рассмотрим реляционную таблицу - БД " Временные трудовые коллективы (ВТК)", приведенную на Рис. 0.16.
Рис. 0.16 Здесь первичными ключами-кандидатами могут быть: · атрибут №ВТК · сцепленный ключ №Комнаты + ФИО Руководителя. Используя для представления реляционной модели данных вместо таблицы строковую запись, и принимая простой первичный ключ, структуру таблицы на Рис. 0.16можно записать в виде: ВТК(№ВТК, НазваниеВТК, №Комн, ФИОРук-ля).
Контрольные вопросы 1. Что понимается под информационным моделированием? 2. Какие аспекты рассматриваются при инфологическом подходе к построению информационных систем? 3. Что называется инфологической моделью БД? 4. Какими свойствами характеризуются объекты? 5. Что называется атрибутом? 6. Какова элементная база моделирования объектов предметной области? 7. Определите понятие сущность. 8. Что называется моделью " сущность-связь"? 9. Что понимается под схемой и экземпляром схемы структуры данных? 10. Какие используются формы представления данных? 11. Перечислите виды отношений и их характеристики. 12. Каким требованиям должна удовлетворять БД? 13. Какие используются средства поддержки и взаимодействия с БД? 14. Какова цель объединения полей в записи? 15. Каковы правила группировки атрибутов в отношения? 16. Перечислите модели данных. 17. Что называется иерархической моделью данных? 18. Какие элементы используются в структурах иерархических моделей данных? 19. Что называется сетевой моделью данных? 20. В чем отличия сетевой модели данных от иерархической? 21. Что называется реляционной моделью данных? Селекция данных Для селекции, т.е. выбора данных из БД возможно использование различных критериев: по логической позиции данных; по значениям данных; по взаимосвязям данных. Первый способ базируется на упорядочении данных в памяти системы. Это позволяет селектировать данное, находящееся на первой, следующей, предыдущей, n-й или последней позиции. Этот тип селекции называется еще селекцией посредством “текущей”. В качестве текущих используются специальные дополнительные объекты - “индикаторы текущего состояния”. СУБД при выполнении каждой ПП автоматически контролирует индикаторы текущего состояния. Количество и состав индикаторов определяется подсхемой, используемой ПП. Таким образом, функция индикатора - указание некоторого экземпляра записи в БД. При селекции по значениям данных критерий селекции может формироваться на основе условий отбора или на основе операторов алгебры логики. Если в МД имеются взаимосвязи данных, то возможна реализация селекции данных по этим связям. Например, в БД “Отдел” с записями:
(3.1) Отдел(№Отдела, Корпус, НачальникОтдела) (3.2) Служащий(№Таб, ФИО, ГодРождения, Образование) (3.3) РаботаетВ(№Таб, №Отдела)
между сущностями Отдел и Служащий реализована связь РаботаетВ. Тогда допускается селекция с использованием этой связи. В результате можно, например, селектировать места расположения тех отделов, в которых работают служащие, возраст которых не более 27 лет. При этом, естественно, используются имеющиеся в структурах записей соответствующие атрибуты. Обработка данных Обработка данных осуществляется на основе процедур БД. Процедурой БД называется последовательность операций, позволяющая реализовать определенный алгоритм обработки данных для получения искомого результата. Процедура является единой, т.е. неделимой, макрооперацией. Возможность применения процедур существенно расширяет динамические свойства моделей данных. Пример. В БД (3.1)-(3.3) определить количество служащих в возрасте не более 27 лет. Для решения этой задачи необходимо сначала выбрать требуемый контингент, а затем выполнить операцию сравнения.
Во многих процедурах алгоритмы обработки данных зависят от значений данных и управляются этими значениями. Запросы к БД Запросы бывают двух видов: простые; комбинированные (или сложные). Простые запросы определяются формулой:
(3.4) А(Е) qi V,
где А - атрибут; Е - объект предметной области; V - значение атрибута, qi – оператор отношения между А и V. Оператор отношения qi может принимать значения из множества: Q = {=, < >, < =, > =, <, > }.
В соответствии с формулой (3.4) возможны шесть типов простых запросов. Рассмотрим их на примере для БД из предметной области “Поставки комплектующих изделий ( КИ )”. Формулировки запросов приведены на Рис. 0.2. БД “Поставки комплектующих изделий (КИ)” содержит объемы поставок на автопредпрятие по каждому КИ за каждый месяц года, т.е. ее атрибутами являются месячные поставки различных КИ.
Рис. 0.2
Комбинированные или сложные запросы - это запросы, в которых используется несколько различных условий, сформированных из совокупностей простых запросов, соединенных логическими операторами из множества LO: (3.5) LO = {OR (или); AND (и); NOT (нет)}.
Пример. ZS = (Z1) LO1 (Z2) LO2 (Z3) LO3 …,
где ZS – сложный запрос; Z1, Z2, Z3, … - простые запросы, определяемые формулой (3.4), LO1, LO2, LO3… - логические операторы из множества (3.5) При реализации сложных запросов порядок выполнения операторов можно изменять круглыми скобками. В заключение отметим, что сложные запросы могут формулироваться и по нескольким объектам. 3.5. Схема реализации запроса в БнД В БнД посредством СУБД несколько пользователей могут одновременно обращаться с запросами к БД в соответствии со своими ПП. Допустим, некоторая ПП1 ( Рис. 0.3) посредством ЯМД делает, например, запрос (1) к СУБД на чтение записи. При этом одновременно сообщается имя программиста, затребовавшего эту запись, а также значение ключа записи. Для реализации этого запроса СУБД вызывает в свое распоряжение (2) подсхему ПП1 из БД подсхем (БД ПС) и ищет в ней описания данных, на которые выдан запрос. Затем СУБД вызывает (3) из БД схем (БД С) в свое распоряжение схему БД и определяет по ней типы необходимых логических данных. После этого СУБД просматривает (6) описание физического размещения - схему хранения данных (БД СХ), определяет, какую физическую запись считать. В результате СУБД дополняет запрос от ПП1 соответствующей информацией из БД ПС, БД С и БД СХ. Далее СУБД выдает ОС ПК команду чтения (5) требуемой записи. ОС обеспечивает (6) чтение записи из физической памяти ПК (БД) и передачу (7) искомых данных (8) в системный буфер (СБ) блока данных пользователей (БлДП). СБ используется одновременно несколькими ПП, обслуживаемыми СУБД, причем размер СБ определяет АБД. После этого СУБД сравнивает (9) подсхему ПП1 и схему БД, выделяя ту логическую запись, которая запрошена ПП1. При необходимости реализуется преобразование данных. Затем инициируется (9) пересылка данных (10) из СБ в рабочую область ПП1 (РОПП1). Здесь СУБД формирует (11) данные результата выполнения запроса ПП1 (ДРВЗПП1). При этом полученные из БД данные обрабатываются средствами включающего или базового языка и используются (12) ПП1. Под управлением (13) СУБД информация о результатах выполнения запроса (ИРВЗ) вместе с сообщениями об ошибках через ячейку связи (ЯС) передается (14) в ПП1. Данные, наряду с извлечением из БД, могут также и помещаться в нее. Этот процесс аналогичен рассмотренному, но информационные потоки (8) и (10) будут иметь обратные направления. При необходимости реализовать операцию модификации записи СУБД считывает и модифицирует ее в рабочей области РО, а затем модифицированные данные записывает обратно в БД.
Рис. 0.3
3.6. Способы обработки данных В информационных системах используется три варианта обработки данных: Централизованная распределенная комбинированная. Рассмотрим их особенности. РЕЛЯЦИОННЫЕ БД 4.1. Свойства реляционных таблиц В реляционных БД при формировании реляционных таблиц необходимо выполнение следующих условий, определяемых свойствами этих таблиц: · домены, должны иметь индивидуальные уникальные имена; · каждое значение поля таблицы должно представляет собой один элемент данных; · в каждом домене все значения полей однородны; · недопустимы идентичные кортежи; · каждый кортеж должен иметь первичный ключ. 4.2. Назначение первичных и вторичных ключей реляционных таблиц Первичный ключ В реляционных таблицах в общем случае может быть несколько вариантов возможных первичных ключей, или ключей-кандидатов. Ключом-кандидатом называется минимальный набор полей, однозначно идентифицирующих кортеж, или запись, в БД. Минимальность набора понимается в том смысле, что при исключении из набора какого-либо поля он теряет свойства ключа-кандидата. Поля, входящие в ключи-кандитаты, называются первичными атрибутами. Остальные поля, т.е. не входящие в ключи-кандитаты, называются непервичными атрибутами.
Пример. Рассмотрим БД " Адреса клиентов", приведенную на Рис. 0.1.Здесь можно выделить два ключа-кандидата: а) ШифрКлиента; б) ФИО + Адрес. Для пользователя удобнее принять в качестве первичного несцепленный ключ - ШифрКлиента, который и подчеркнут в таблице на рисунке.
Вторичный ключ Вторичным ключом, как отмечалось выше, называется идентификатор, выбираемый в качестве ключа и неоднозначно идентифицирующий кортеж, или запись, в БД. Вторичный ключ применяется для выбора множества записей, имеющих одинаковые значения полей, определенных в качестве вторичного ключа.
Пример. Рассмотрим БД Сотрудники, имеющую структуру: Сотрудники(№Таб, ФИО, ПаспортныеДанные, Должность). Здесь вторичным ключом может быть тип поля Должность. Тогда по нему будет выбираться множество сотрудников, занимающих одну и ту же должность на предприятии. 4.3. Функциональные и многозначные зависимости Понятия функциональной и многозначной зависимостей широко используются при разработке моделей данных различных приложений. Выявление функциональных зависимостей важно для выявления ключей-кандидатов, назначения первичных и вторичных ключей в реляционных таблицах, для нормализации баз данных. Они являются одними из основных понятий в реляционной алгебре, являющейся основным математическим аппаратом реляционных моделей данных. Функциональные зависимости В отношении R атрибут типа Y функционально зависит от атрибута типа Х, если каждому значению атрибута X соответствует единственное значение атрибута типа Y. Синтаксис X ® Y (X влечет Y). Пример 1. В отношении Двигатель(МаркаДвигателя, Мощность, Масса) значение атрибута Мощность функционально зависит от значения атрибута МаркаДвигателя. Кроме того, значение атрибута Масса также функционально зависит от значения атрибута МаркаДвигателя. При определении функциональных зависимостей используется также термин «детерминант»: в отношении R атрибут или комбинация атрибутов называется детерминантом, если от него функционально зависит какой-либо другой атрибут. Графически функциональные зависимости представляются диаграммами. На Рис. 0.2 приведена диаграмма функциональных зависимостей для рассмотренного выше примера в двух вариантах исполнения: а) с вертикальным размещением атрибутов; б) с горизонтальным размещением атрибутов.
На рисунке звездочкой помечен ключ-кандидат, который и принят в качестве ключа, что отображается его подчеркиванием. Пример 2. При отсутствии однофамильцев представим отношение Служащий в виде: (4.1) Служащий(№Служащего, ФИО, ЗПлата, №Проекта, ДатаОкончания), а1 а2 а3 а4 а5
где аi (i=1,..., 5) - символьные имена атрибутов, вводимые для упрощения построения схем отношений и анализа функциональных зависимостей в них. Выявим в отношении (4.1) функциональные зависимости и определим ключ. С этой целью изобразим функциональные зависимости отношения " Служащий" в виде схемы на рис.4.2. Здесь линии со стрелками определяют зависимости полей-функций аj, находящихся возле концов линий, отмеченных стрелками, от аргументов аi, находящихся возле начал этих линий. Из схемы, например, видно, что атрибут а1 не является функционально зависимым от атрибута а3 . Действительно, одинаковая зарплата может быть у нескольких служащих. Аналогично а1 не зависит от а4. Рассмотрим возможные ключи отношения, т.е. ключи-кандидаты. Атрибут а4 не может быть ключом-кандидатом, так как от него зависит лишь атрибут а5. Вместе с тем ключами-кандидатами, обычно помечаемыми в схемах символом " звездочка" (*), могут быть а1 и а2 , так
как от любого из них зависят все атрибуты отношения. Удобнее в качестве ключа принять атрибут а1 - №Служащего, который подчеркнут в исходной записи.
Пример 3. Рассмотрим отношение Программисты (с зависимостями между группами атрибутов), в котором неповторимы атрибуты ФИО и НазваниеПрограммы (Назв-еПр-мы): (4.2) Программисты(№Прогр-та, №Программы, ФИО, Назв-еПр-мы, Ресурсы), а1 a 2 а 3 а 4 а5
где под ресурсами понимаются средства на разработку, которые зависят от программы и от программиста; аi (i=1,..., 5) - символьные имена атрибутов. Схема отношения Программисты с обозначенными функциональными зависимостями приведена на Рис. 0.4. Здесь линиями с промежуточными черточками обозначены функциональные зависимости от совокупностей атрибутов. Из рассмотрения функциональных зависимостей видно, что в отношении нет простого ключа. Однако имеется четыре составных (или сцепленных) ключа-кандидата, состоящих из пар атрибутов (а1, а2), (а1, а4), (а2, а3), или (а3, а4), которые помечены звездочками. Так, атрибут а5 функционально зависит от любого из приведенных возможных составных ключей. По соображениям удобства для пользователей ключом принята пара атрибутов (а1, а2), т.е. (№Прогр-та, №Пр-мы), которые в формуле (4.2) и на рисуке подчеркнуты.
Аксиома транзитивности
Введем обозначения: X, Y, Z – атрибуты (А); R - отношение; QА - множество атрибутов отношения R; QF - множество функциональных зависимостей из R. Аксиома. Если атрибуты X, Y и Z принадлежат множеству QA и заданы зависимости F1: X ® Y, F2: Y ® Z, которые принадлежат множеству функциональных зависимостей QF либо получены из него на основе правил вывода, то имеет место функциональная зависимость X ®Z или ( x ® y ) & ( y ® z ) x ® z.
Пример. В отношении Служащие(ФИО, ЗПлата, Задание Задание, ВремяВыполнения)
атрибут ВремяВыполнения зависит от атрибута Задание, который в свою очередь зависит от атрибута ФИО. Следовательно, атрибут ВремяВыполнения транзитивно зависит от атрибута ФИО. Это можно представить схемой:
Задание à ВремяВыполнения, ФИО à Задание ФИО à ВремяВыполнения Многозначные зависимости В отношении R имеет место многозначная зависимость, если при заданном значении атрибута типа X существует множество взаимосвязанных значений атрибута типа Y. Для обозначения многозначной зависимости обычно используется символика: X ®® Y. Пример. В отношении Поставки(Завод, Изделие, Цена)
между атрибутами типов Завод и Изделие имеет место многозначная зависимость, т.к. одному значению атрибута типа Завод соответствует множество значений атрибута типа Изделие:
Завод à à Изделие
4.4. Уровни автоматизации манипулирования данными в реляционных БД В соответствии с лингвистическим обеспечением, используемым пользователями при работе с БД, предусмотрено три уровня манипулирования данными: · низший уровень - это уровень, при котором пользователь БД оперирует непосредственно с записями; · средний уровень, основанный на использовании реляционной алгебры. Пользователь для манипулирования данными использует наборы высокоуровневых операций над отношениями; · высшим уровнем автоматизации в БД является применение исчисления отношений. При этом пользователь непосредственно обращается к СУБД на ПЭВМ, используя объектный язык. В результате решение сформулированной задачи по манипулированию данными осуществляется самостоятельно программой СУБД. При таком методе пользователь не интересуется, как ЭВМ получает результат, и она, в свою очередь, имеет свободу для оптимизации запросов. В подобных системах удобнее и проще реализуется засекречивание данных. Контрольные вопросы 1. Перечислите свойства реляционных таблиц. 2. Что называется первичным ключом? 3. Что называется вторичным ключом? 4. Приведите пример функциональной зависимости. 5. Что понимается под многозначной зависимостью?
РЕЛЯЦИОННАЯ АЛГЕБРА 5.1. Операции над отношениями Для получения информации по запросам пользователей из отношений в СУБД используется язык манипулирования данными, разработанный Коддом. С его помощью выполняются необходимые операции над отношениями. Язык Кодда содержит требуемые операторы манипулирования данными. Важной функцией языка является формулирование запросов, представляющих собой произвольные функции над отношениями. Для реализации операций над отношениями Коддом было предложено три абстрактных теоретических языка: · реляционная алгебра; · реляционное исчисление с переменными - кортежами; · реляционное исчисление с переменными - доменами. Эти языки по своей выразительности эквивалентны. Языки запросов, построенные на первом типе, являются алгебраическими языками. Они выражают запросы пользователей средствами специализированных операторов, применяемых к отношениям. Языки второго и третьего типов являются языками исчисления. Они выражают запросы на основе спецификации предикатов. Предикаты - это логические высказывания, принимающие значения «истинно» или «ложно», в результате чего выделяются требуемые кортежи или домены. Современные языки манипулирования данными SEQUEL (SQL), QBE, ISBL и др., используемые в СУБД, реализуют широкий набор операций: · операции с данными: включение, модификация, удаление данных; · операции обработки данных: · арифметические выражения (вычисления, сравнения); · команды присваивания и печати; · агрегатные функции. Агрегатными функциями называются функции, применяемые к доменам отношений для вычисления единственной величины. Пример. · определение максимального или минимального значения домена · определение суммы домена · определение среднего домена и т.п. Гибкость реляционных БД определяется легкостью манипулирования, т.е. простотой модификации реляционных таблиц (РТ). Это означает, что исходя из РТ, сформированных при разработке концептуальной схемы БД, пользователь или прикладной программист могут легко создавать и далее использовать свои РТ. Для этих целей используются процедурные и непроцедурные языки. К процедурным относится язык реляционной алгебры. Его операторы в выражениях специфицируют конкретный порядок выполнения операций: различные действия по преобразованию реляционных таблиц, типов полей, их значениях, т.е. операндов. В результате применения этих операторов получается искомая реляционная таблица. При формулировке каждого запроса пользователь должен сам выполнять его оптимизацию, т.е. формировать структуру запроса с обеспечением минимальности последующей вычислительной работы при его реализации. К непроцедурным относятся языки исчисления. Их средствами выражается результат, который требуется получить, без раскрытия алгоритма получения этого результата. В них наиболее эффективный порядок вычислений для реализации запроса, т.е. оптимизация запроса выполняется интерпретатором или транслятором. Настоящая глава посвящена рассмотрению средств реляционной алгебры. Для удобства изучения операторов реляционной алгебры будем рассматривать БД “Разработчики ПП”, представленную шестью таблицами на Рис. 0.1. 5.2. Оператор " объединение" (union) Функция: для двух РТ R1 и R2 одинаковой арности и с совпадающими типами полей формируется РТ R с записями, входящими хотя бы в одну исходную РТ. Синтаксис: R = R1 union R2 Пример. Объединить две РТ: R1 и R2 в одну РТ R.
5.3. Оператор " вычитание" (difference) Функция: для двух РТ R1 и R2 одинаковой арности и с совпадающими типами полей формируется РТ R c записями, содержащимися " Разработчики ПП" в уменьшаемом - таблице R1, но отсутствующими в вычитаемом - таблице R2. Синтаксис: R = R1 difference R2.
Рис. 0.1 Пример. Вычесть из РТ R1 таблицу R2, результат записать в РТ R.
5.4. Оператор " пересечение" (intersection) Функция: для двух РТ R1 и R2 одинаковой арности и с совпадающими типами полей формируется РТ R с записями, входящими в обе РТ. Синтаксис: R = R1 intersection R2. Пример. Выполнить пересечение таблиц R1 и R2, результат записать в таблицу R.
5.5. Оператор " проектирование" (proj) Функция: из РТ R1 оператор выбирает заданные типы полей и размещает в указанном порядке в таблице R. Синтаксис: R = proj a1,..., ar(R1) Пример. Из РТ " Разработчики" (R1 на рис.5.1) выбрать поле ФИО и поле ГодРождения.
R = proj ФИО, ГодРожд-я(Разработчики)
5.6. Оператор " выбор" (sel) Функция: из РТ R1 по заданному критерию выбирается требуемая совокупность записей. В частном случае результатом выборки может быть и пустое множество. Синтаксис: R= sel < F> (R1), где F - критерий выбора. Критерии выбора могут формулироваться на основе операторов двух типов: · операторы сравнения: =, < >, <, < =, >, > =; · логические операторы: И (AND), ИЛИ (OR), НЕ (NOT). Пример 1. В БД на Рис. 0.1 выбрать данные разработчика Белова А. Для решения надо использовать РТ " Разработчики" и выбрать данные Белова А.:
R= sel < ФИО = 'Белов А.'> (Разработчики)
Пример 2. В БД на Рис. 0.1 выбрать программистов выше третьей категории, работающих на Pascal'e. Для решения воспользуемся РТ " Программисты" и критерием выбора:
< F> = < (ЯзыкПрогр-я = 'Pas') and (Катег-яПрогр-та < 3)>.
Тогда оператор примет вид:
R=sel< (ЯзыкПр-я='Pas')and(Катег-яПр-та< 3)> (Программисты).
Алгоритм реализации 1) Выделим названия РТ, задействованных в реализации запроса. Это РТ: " Разработанные ПП" (R3) и " Разработчики" (R1). 2) Из К3 выберем записи по условию в запросе:
RT1 = sel < (ГодСозд-я > = 1970) and (ГодСозд-я < = 1985)> (R3).
3) Соединим RT1 и R1 по общему полю №Разр-ка:
RT2 = RT1 join R1.
Таблица RT2 будет иметь вид:
RT2:
4) Выбрать из RT2 Название ПП, ФИО и стаж разработчиков:
R = proj НазваниеПП, ФИОРазр-ка, Стаж (RT2) Результирующая таблица R как ответ на запрос примет вид:
Общий алгоритм реализации запроса можно представить в виде:
proj Назв-еПП, ФИОРазр-ка, Стаж (sel < ГодСозд-я > = 1970 and ГодСозд-я < = 1984> (Разработанные ПП) join Разработчики).
Алгоритм реализации 1) Выделим названия РТ, задействованных в реализации запроса. Это РТ: " Разработанные ПП" (R3), " Разработчики" (R1), " Временные трудовые коллективы (ВТК)" (R4), " Составы ВТК" (R5), " Программисты" (R2). 2) Для выявления разработчиков ПП, выступающих одновременно и как руководители ВТК, объединим таблицы R3 и R4. Здесь общим полем является №Разр-ка - №Разр-каРук-ляВТК:
RT1 = R3 join R4:
RT1:
3) Для экономии памяти ПК и увеличения быстродействия выберем из RT1 лишь участвующие в запросе поля:
RT2 = proj Назв-еПП, №Разр-ка-Рук-ляВТК, №ВТК(RT1):
4) Для определения Разработчиков-Руководителей ВТК, являющихся одновременно и программистами, соединим RT2 и R2 по одному общему полю: №Разр-каРук-ляВТК - №Разр-ка-Прогр-та:
RT3 = RT2 join R2:
RT3:
5) Выберем из RT3 лишь участвующие в запросе поля:
RT4=projНазв-еПП, №Разр-ка-Рук-ляВТК, №ВТК, №Пр-та(RT3): RT4:
6) Для определения разработчиков-руководителей ВТК, являющихся программистами именно в своих ВТК, сделаем соединение таблиц RT4 и R5 по двум полям: №ВТК и №Прогр-та:
RT5 = RT4 join R5: RT5:
7) Выберем из RT5 участвующие в запросе поля:
RT6 = proj Назв-еПП, №Разр-ка-Рук-ляВТК (RT5):
8) Для полного ответа на запрос объединим таблицы RT6 и R1 с последующим выделением полей, указанных в запросе: RT7 = RT6 join R1: RT7:
RT8 = proj Назв-еПП, №Разр-ка, ФИОРазр-ка (RT7):
Таким образом, алгоритм ответа на запрос можно записать в виде: proj Назв-еПП, №Разр-ка-Рук-ляВТК(proj Назв-еПП, 6 4 №Разр-ка-Рук-ляВТК, №ВТК, №Прогр-та(proj Назв-еПП, 2 №Разр-ка-Рук-ляВТК(Разр-ыеПП joinВТК) join Прогр-ты) 1 3 join СоставыВТК) join Разр-ки 5 7 Примечание: Цифры под операторами обозначают порядковые номера их выполнения. 6.1.6. Оператор " соединение по условию" Функция: из двух РТ R1 и R2 формируется результирующая R оператором join (см. п.5.6), если выполняется заданное условие V: V = P1i G P2j, где G - арифметический оператор сравнения, выбираемый из множества: {=, >, <, > =, < =, < > }; P1i, P2j - типы полей в реляционных таблицах R1 и R2 соответственно. Для оператора G типа равенство оператор join называется эквисоединением. Синтаксис: R = R1 join R2 P1i G P2j Пример. Соединить таблицы R1 и R2 по условию B=D:
R = R1 join R2. B=D
5.8. Оператор " умножение" (product) Функция: для двух РТ R1 и R2 соответственно арности К1 и К2 формируется результирующая R арности (К1 + К2), записи которой представляют собой конкатенацию каждой записи из таблицы R1 с каждой записью из таблицы R2. В таблице R имена полей формируются из двух частей, разделенных точкой. Префиксом имени поля принимается имя таблицы R1 или R2, в зависимости от того, из какой таблицы взято значение поля, а афиксом - соответствующие имена полей из этой таблицы. Синтаксис: R = R1 product R2. Пример.
Запросы с оператором умножения используются в ответах на запросы, требующие сравнения значений полей различных файлов. Алгоритм реализации Для решения поставленной задачи в целях демонстрации примем среди различных возможных алгоритм с использованием оператора умножения. 1) Выделим названия РТ, задействованных в реализации запроса. Это РТ: " Разработчики" (R1), " Разработанные ПП" (R3). 2) Сформируем таблицу с годом рождения Фатова Р. Для этого сначала выделим его запись из таблицы R1, а затем выберем поле ГодРождения: RT1 = sel < ФИОРазр-ка = 'Фатов Р.'> (R1)
RT2 = proj ГодРожд-я(RT1)
3) Из R3 выделим поля Назв-еПП и ГодСозд-я: RT3 = proj Назв-еПП, ГодСозд-я(R3)
4) Для реализации сравнения по сути запроса выполним произведение таблиц RT2 и RT3: RT4 = RT2 product RT3
5) Из RT4 выберем запись по критерию запроса:
RT5 = sel < RT3.ГодСозд-я < RT2.ГодРожд-я> (RT4)
6) Из RT5 выберем поля. необходимых и достаточных для ответа на запрос:
RT6 = proj RT3.Назв-е, RT3.ГодСозд-я(RT5)
Таким образом, алгоритм ответа на запрос можно записать в виде: projRT3.Назв-еПП, RT3.ГодСозд-я(sel< RT3.ГодСозд-я< RT2.Год 6 5 Рожд-я> (projГодРожд-я(sel< ФИОРазр-ка='Фатов'> (R1)product 2 1 4 proj Назв-еПП, ГодСозд-я(R3))). 3 Примечание. Цифры под операторами обозначают порядковые номера их выполнения. 5.9. Оператор " деление" (division) Функция: для двух реляционных таблиц соответственно делимого R1 и делителя R2 таких, что: а) каждому типу поля в делителе найдется соответствующий тип поля в делимом; б) в экземплярах записей делимого имеются типы полей, отсутствующих в делителе, отдельные значения которых в этих экземплярах записей последовательно конкатенированы с каждым экземпляром записи в делителе, будет получена таблица-частное R, которая: а) включает типы полей из числа содержащихся в делимом, но отсутствующих в делителе; б) включает значения полей каждого экземпляра записи частного R лишь в том случае, если они в экземплярах записей делимого конкатенированы с каждым экземпляром записи в делителе. Синтаксис: R = R1 division R2. Пример.
Примечание. 1) В таблице R лишь одно поле D, так как оно входит в делимое и отсутствует в делителе; 2) Значения А и В входят в R, так как в делимом они соответственно конкатенированы с каждой из трех записей делителя (см. в табл.R1 записи №№ 1, 5, 6 для D=А и №№ 3, 4, 7 для D=В); 3) Значение С отсутствует в R, так как в R1 нет записи Ch3. 5.10. Оптимизация алгоритмов реализации запросов Задача оптимизации реализации запросов заключается в выборе такой последовательности операций, при которой минимизируются объемы требуемой памяти и вычислительной работы, а соответственно сокращается время ответа на запросы. Пусть P11 - одно из возможных значений поля P таблицы R1, которая должна быть объединена с таблицей R2 для получения таблицы R с выполнением ниже сформулированного условия: для таблицы R должны быть выбраны из таблицы, полученной объединением R1 и R2, записи со значением поля P, равным P11. Для получения ответа возможно два алгоритма:
(5.1) R = (sel < P = P11> (R1)) join R2 и (5.2) R = sel < P = P11> (R1 join R2),
дающих идентичные результаты. Однако последовательности выполнения операций и затраты будут различны. По формуле (5.1) записи из R1 будут выбираться до операции соединения, а по формуле (5.2) - наоборот после операции соединения. Применение формулы (5.2) в случае результата операции соединения с количеством записей большим, чем в R1, приведет к увеличению времени реализации процедуры sel, что замедлит работу системы. При таком положении предпочтительнее алгоритм (5.1). В обратной ситуации целесообразнее алгоритм (5.2). Стандартные языки СУБД реализуют процедуры оптимизации автоматически. При написании БД и СУБД на алгоритмических языках необходимо специально реализовывать эти процедуры написанием программ оптимизации алгоритмов реализации запросов. Контрольные вопросы 1. Что понимается под реляционной алгеброй, ее операторами и операндами? 2. Приведите характеристику оператора UNION и пример. 3. Приведите характеристику оператора DIFFERENCE и пример его применения. 4. Приведите характеристику оператора INTERSECTION и пример его применения. 5. Приведите характеристику оператора PROJ и пример. 6. Приведите характеристику оператора SEL и пример. 7. Приведите характеристику оператора JOIN и пример его применения. 8. Приведите характеристику оператора PRODUCT и пример его применения. 9. Приведите характеристику оператора DIVISION и пример. 10. Каковы цели и критерии оптимизации реализаций алгоритмов запросов? НОРМАЛИЗАЦИЯ РЕЛЯЦИОННЫХ БД 6.1. Задачи нормализации Бд Нормализацией БД называется процедура декомпозиции или композиции исходных схем отношений проекта БД, назначение ключей для каждого отношения с целью исключения возможных аномалий при манипулировании данными. Правила нормализации разработаны Коддом в 1972 году. В результате нормализации обеспечивается: · регулярность описаний данных; · возможность присоединения новых полей, записей, связей без изменения существующих подсхем (или внешних моделей) и, соответственно, ПП. Это обычно требует больших дополнительных затрат по сопровождению; · максимальная гибкость при обработке произвольных запросов с рабочих мест пользователей. Нормализация базируется на представлении данных двухмерными таблицами, составляющими основу реляционных моделей данных. Важно отметить, что любая иерархическая или сетевая модель данных может быть с некоторой избыточностью разложена в совокупность двухмерных таблиц. Процесс нормализации реализуется поэтапно путем формирования последовательности так называемых нормальных форм (НФ). 6.2. Первая нормальная форма Первым этапом нормализации является группировка атрибутов, заключающаяся в свертывании данных в двухмерные таблицы (или файлы), и выделении ключевых полей. В результате формируется первая нормальная форма. Схема отношения R находится в первой нормальной форме (1НФ), когда все входящие в неё атрибуты являются атомарными, т.е. в любом поле содержится только одно значение, и любое ключевое поле не пусто. Представление БД в 1НФ достаточно для применения языков манипулирования данными (реляционной алгебры, исчисления доменов или кортежей и др.). Однако при этом не исключаются аномалии, возникающие при манипулировании данными. Для их исключения необходима последующая нормализация отношений. Основной операцией для последующей нормализации отношений является их декомпозиция. 6.3. Декомпозиция реляционных таблиц Присоединенные записи Присоединенными записями называются записи, которые не имеют ключевого поля, и, следовательно, не могут храниться в исходной реляционной таблице, так как будет нарушено правило обязательности ключевого значения в каждой записи, но могут храниться в полной декомпозиции реляционной таблицы. Рассмотрим два набора полей S1 и S2 из реляционной таблицы R, причем в S1 содержится ключ, и выполняется условие R = proj S1(R) join proj S2(R). Запись будет присоединенной, если она занесена в проекцию proj S2(R), но не занесена в проекцию proj S1(R) и, следовательно, не войдет в соединение этих проекций. Пример. Рассмотрим для БД " Поставщики КИ" (см. рис.6.5) с проекциями S1 = (№КИ, Фирма) и S2 = (Фирма, Телефон) в качестве присоединенной запись для фирмы РОС с телефоном 2462475: (РОС, 2462475). Фирма РОС еще не приступила к поставке товаров и, следовательно, еще не имеет значения ключевого поля №КИ. Это означает, что ее запись можно хранить в проекции S2, т.е. в полной декомпозиции, но не в исходной реляционной таблице R. В случае когда добавляемая запись содержит значение ключевого поля, но отсутствуют значения каких-либо других полей, эту запись можно разместить в исходной реляционной таблице, так как не будет нарушаться правило ключа. На местах отсутствующих значений полей следует поставить значение " Пусто". Теорема Хита Однако получение рассмотренного результата в общем случае не является столь простой процедурой. При декомпозиции следует учитывать весьма важное обстоятельство, заключающееся в том, что не всякая декомпозиция реляционной таблицы исключает дублирование. Рассмотрим БД Склад(База, Товар, Поставщик), приведенную на Рис. 0.5. Ее декомпозицию можно реализовать двумя способами.
Рис. 0.5
По первому способу получаем проекции: (6.2) R11 = proj База, Товар(Склад); R12 = proj Товар, Поставщик(Склад), приведенные соответственно на Рис. 0.6, а. и Рис. 0.6, б.
а) Рис. 0.6
При объединении, т.е. композиции полученных проекций, образуется исходная БД " Склад". Это означает, что результатом первого способа (6.2) была полная декомпозиция. Однако, как видно из Рис. 0.6, при декомпозиции в записях полученных таблиц не удалось исключить дублирование значений полей М3 и INT. При декомпозиции по второму способу получаем проекции: R21 = proj База, Поставщик(Склад); R22 = proj Товар, Поставщик(Склад),
для которых соответствующие таблицы приведены на Рис. 0.7, а и Рис. 0.7, б.
б) а) Рис. 0.7 При объединении этих полученных проекций формируется результирующая таблица, которая, в отличие от исходной БД " Склад", имеет две лишние записи, как показано на Рис. 0.7. Это означает, что декомпозиция по второму способу не является полной и, следовательно, недопустима для рассмотрения и использования.
Рис. 0.7, в Следовательно, полная декомпозиция возможна лишь по первому способу (6.2), однако в полученных проекциях не исключено дублирование значений полей МЗ и INT, т.е. поставленная задача осталась нерешенной. Из изложенного вытекают следующие основные проблемы теории декомпозиции: · формирование правил выбора одной из альтернатив: либо хранить БД в исходном виде, либо выполнить полную декомпозицию БД и хранить ее проекции; · разработка методов анализа с целью определения совокупности проекций, обеспечивающих полную декомпозицию исходной БД. Теорема Хита для БД, представленной реляционной таблицей, устанавливает взаимосвязь между функциональной зависимостью и полной декомпозицией таблицы. Рассмотрим БД (рис. 6.8) в виде реляционной таблицы R с тремя непересекающимися наборами полей: S1, S2 и S3, т.е. таких, что каждое поле таблицы принадлежит лишь одному из этих типов, причем S3 функционально зависит от S2.
Рис. 6.8
В этом случае справедлива теорема, называемая теоремой Хита. Теорема Хита. Если в реляционной таблице R существуют наборы Si (i = 1, 2, 3), не пересекающиеся между собой, и набор S3 функционально зависит от набора S2, то справедливо тождество: R = proj S1, S2 (R) join proj S2, S3 (R), т.е. имеет место полная декомпозиция реляционной таблицы R. Проанализируем с позиций теоремы Хита функциональные зависимости для рассмотренных выше БД Поставщики (№КИ, Фирма, Телефон) и Склад(База, Товар, Поставщик). Для БД Поставщики функциональные зависимости исходной реляционной таблицы и ее проекций приведены соответственно на Рис. 0.8, а и 6.9, б.
а) б) Рис. 0.8 Из Рис. 0.8, а следует, что в БД можно рассматривать три непересекающихся набора Si , соответствующие трем атрибутам аi., причем а3 функционально зависит от а2. Это означает, что декомпозиция, выполненная в соответствии с Рис. 0.8, б, обеспечивает выполнение условий теоремы Хита и, следовательно, будет полной. Для БД Склад функциональные зависимости исходной реляционной таблицы и ее двух вариантов проекций приведены соответственно на Рис. 0.9, а, б и в. а1 а1 а1
а) б) в)
Рис. 0.9
Из Рис. 0.9, а следует, что в БД также можно рассматривать три непересекающихся набора Si , соответствующие трем атрибутам аi.. Отметим однако, что в этой БД нет ключа, т.е. она не в 1НФ, и лишь а3 функционально зависит от а2. Тем не менее, декомпозиция, выполненная в соответствии с Рис. 0.9, б на подмножества (а1, а2 ) и (а2, а3), обеспечивает выполнение условий теоремы Хита, так как а2 входит в оба подмножества, и, следовательно, декомпозиция будет полной. Однако, как видно из Рис. 0.9, б, дублирование значений полей не удалось исключить. Декомпозиция же, выполненная в соответствии с Рис. 0.9, в, не обеспечивает выполнение условий теоремы Хита, т.к. от общего атрибута а3 атрибут а2 функционально не зависит, и, следовательно, полученный результат не является полной декомпозицией. На основании рассмотренного можно заключить, что фактически теорема Хита определяет только необходимое условие исключения дублирования, т.е. лишь возможность полной декомпозиции исходной БД. Четвертая нормальная форма Если в отношении R, находящемся в ЗНФ, имеются многозначные зависимости, то оно для исключения аномалий операций должно быть нормализовано до четвертой нормальной формы. Отношение R представлено в четвертой нормальной форме (ЧНФ) тогда и только тогда, когда каждая его полная декомпозиция из двух проекций такова, что обе проекции не содержат общего ключа-кандидата. Пятая нормальная форма Реляционная таблица, любая полная декомпозиция которой содержит во всех проекциях ключ-кандидат, считается находящейся в пятой нормальной форме (5НФ). Кроме того, реляционная таблица, для которой невозможна ни одна полная декомпозиция, также считается находящейся в 5НФ. В общем случае замена реляционной таблицы в 5НФ на любую ее полную декомпозицию, во-первых, не устраняет дублирования и, во-вторых, не обеспечивает сохранение присоединенных записей. С другой стороны, если реляционная таблица не в 5НФ, то возможна ее полная декомпозиция с устранение дублирования и возможностью сохранения присоединенных записей. Если составляющие полную декомпозицию проекции, в свою очередь, не являются реляционными таблицами в 5НФ, то для каждой из них можно рассмотреть возможность последующей полной декомпозиции. Таким образом, этапы нормализации составляют процесс последовательного перехода к полным декомпозициям. Основные цели нормализации: · исключение дублирования данных; · обеспечение сохранения присоединенных записей. 6.7. Методические аспекты реализации нормализации Проектировщик БД при решении информационных задач должен выявить в предметной области поля, выполнить их объединение реализовать процесс нормализации. Нормализация наиболее часто реализуется за три шага. Это наглядно иллюстрирует Рис. 0.14. При
Рис. 0.14 установлении взаимозависимости данных имеется определенная свобода выбора количества и семантики типов полей в отношениях, а также состава отношений. Разработчик должен выбирать такие атрибуты и отношения, которые наиболее устойчивы к пополнениям и модификациям в БД. Особое внимание должно быть уделено выбору ключей-кандидатов и первичного ключа из их числа. Например, нецелесообразно ключом-кандидатом назначать ФИО, так как в дальнейшем возможно появление однофамильцев. Недопустимо включение в состав ключа типов полей, значения которых в некоторых записях могут отсутствовать, так как это приведет к потере экземпляров записей и соответственно всех значений атрибутов. Таким образом, как это отмечалось ранее, этапы нормализации составляют процесс последовательного перехода к полным декомпозициям. Основные цели нормализации обеспечиваются за счет: · исключения дублирования данных; · обеспечения сохранности присоединенных записей. Контрольные вопросы 1. Что называется нормализацией БД? 2. Приведите определение первой нормальной формы. 3. Как нормализуются иерархические модели данных? 4. Как нормализуются сетевые модели данных? 5. Каково назначение декомпозиции реляционных таблиц? 6. Что устанавливает теорема Хита? 7. Что является критерием полной декомпозиции, исключающей дублирование? 8. Приведите определение пятой нормальной формы. 9. Приведите определение второй нормальной формы. 10. Приведите определение третьей нормальной формы. 11. Приведите определение четвертой нормальной формы. 12. Изложите методику реализации нормализации.
Список литературы
1. Ревунков Г.И. и др. Базы и банки данных и знаний. - М.: Высшая школа, 1992. 2. Вейнеров О.М., Самохвалов Э.Н. Проектирование баз данных САПР. - М.: Высшая школа, 1990. 3. Мейер Д. Теория реляционных баз данных. - М.: Мир, 1987. 4. Ульман Дж. Базы данных на Паскале. - М.: Машиностроение, 1990. 5. Диго С.М. Проектирование баз данных. - М.: Финансы и статистика, 1988. 6. Каратыгин С.А., Тихонов А.Ф. Энциклопедия по СУБД Paradox 4.5: В 2-х томах. - М.: Мир, 1994.
ВВЕДЕНИЕ Современные мобильные стремительно развивающиеся, носящие глобальные масштабы процессы в производственной и хозяйственной, научно-технической и научно-организационной, общественно-политической и социальной областях человеческой деятельности сложны прежде всего тем, что требуют перманентного изменения их участников. Открывая новые перспективы, эти процессы одновременно вскрывают и различные проблемы, к которым относятся: 1) интенсификация освоения новых знаний, 2) форсирование процессов получения и обработки информации, 3) овладение эффективными технологиями, современными инструментариями. Возможно ли сегодня в условиях научно-технической революции при скоротечных жизненных процессах оперативно осваивать, воспринимать нарастающие потоки новых знаний, лавинообразно увеличивающиеся объемы информации, успешно их использовать в решении практических задач? Существует ли какой-либо катализатор для ускорения адаптации в перестроечных процессах? Где его найти, как применить для достижения своих целей? Практика ведущих мировых государств уверенно дает утвердительный ответ на все перечисленные вопросы. Рецепт - освоение и повсеместное применение современных компьютерных и информационных технологий на базе ЭВМ, персональной компьютерной техники, локальных и глобальных вычислительных информационных сетей, рабочих станций. Сегодня информатизация общества - это свершившийся факт. Стало очевидным, что информация - это не просто научная категория, а коммерческая, являющаяся таким же принципиальным фактором развития, как сырье, энергия. Теперь для восполнения уменьшающихся запасов сырья и энергии человечество остро нуждается в информации. Информация открывает новые пути более рационального и экономного получения средств для дальнейшего научно-технического прогресса, развития всех сфер человеческой деятельности. Любая серьезная проблема неразрешима без переработки значительных объемов информации и налаженных коммуникационных процессов. Исследования американских специалистов, отраженные в табл.В1, наглядно иллюстрируют эффективность качественного информационного обеспечения при проведении исследовательских и проектных работ. Из таблицы видно, что даже у высококвалифицированных специалистов временные затраты по выполнению работ можно сократить более чем в 1, 5 раза лишь за счет своевременного и полного информационного обеспечения. Для серьезных разработок это дает выигрыш в несколько лет.
Таблица В1
Дальнейший рост объема информации в еще большей степени повышает эффективность и актуальность систем информационного обеспечения. По данным ЮНЕСКО, около половины занятого населения наиболее развитых стран непосредственно участвует в процессах производства и распространения информации. В ряде стран до половины национального продукта связано с информационной деятельностью общества. Информатизация превратилась в важнейший ресурс общества, стала фактором производственной деятельности на всех уровнях. В наше время информатика - это основа успеха в науке, технике, коммерции, бизнесе, менеджменте, политике, в любой духовной, культурной, производственной деятельности человека. Информационные ресурсы - продукт интеллектуальной деятельности наиболее квалифицированной и творчески активной части трудоспособного населения. В последней четверти ХХ века информационные ресурсы достигли столь рекордных объемов, что были введены понятия " информационного взрыва", " информационной революции". Подтверждением тому является увеличение информационного потока с начала текущего столетия более чем в 30 раз. Ежегодно в мире выпускается более 100 тыс. журналов на различных языках, 5 млн. научных статей, книг, брошюр. Всемирный фонд описаний патентов содержит около 500 млн. страниц текста, его ежегодный прирост - 1 млн. документов. В мире ежеминутно печатается примерно 2 тыс. страниц научных текстов, каждый час регистрируется 15-20 изобретений или открытий. Современный специалист должен ежедневно прочитывать примерно 1.5 тыс. страниц информации. В США около 50% рабочих и служащих заняты информационным обслуживанием. Однако практически вследствие невозможности оперативно проанализировать все научно-технические публикации немало разработок дублируется. Например, Американское химическое общество информирует, что каждое десятое проводимое в США исследование излишне, так как ранее подобная работа уже была проделана и результаты опубликованы. Сегодня информационное невежество - прямой путь к банкротству. Вместе с тем информационный поток уже опережает возможности человека по его обработке и использованию, так как мозг человека не беспределен. Необходимо изыскание и применение принципиально новых методов и средств восприятия, передачи, обработки, хранения и распространения информации, способных оперировать с большими массивами информации в реальном времени. В настоящее время это реализовано - на базе компьютеров создана информационная индустрия, определившая переход к безбумажным технологиям обмена информацией на основе видеотелефонов, факсимильной передачи документов, видеотекстных систем, электронной почты, телеконференций, локальных и глобальных сетей передачи данных, спутниковой связи, баз и банков данных, информационно-поисковых систем, автоматизированных рабочих мест. В мире работает несколько сотен информационных центров, имеющих около 3 000 баз данных, обеспечивающих удаленный диалоговый режим пользования. Информационная индустрия весьма доходна. В 1990 г. прибыль американских компаний, вовлеченных в информационную индустрию, составила 1 триллион долларов. Феномен информации инициировал новую науку - науку об информации. Ее задачами являются: изучение свойств информации, методов управления информационными потоками и их использования, методов обработки информации для оптимального хранения, поиска и распространения. Можно сказать, что в настоящее время мировое сообщество все более превращается в гигантскую информационную систему. При этом в общем случае информационной системой называется функциональная система, предназначенная для записи, хранения, обработки и выдачи информации по запросам пользователей. В соответствии с документами ЮНЕСКО для информатики введено следующее определение: ИНРФОРМАТИКА - это крупное научное направление, которое включает методы и средства сбора, анализа и обработки информации на основе достижений микропроцессорной, компьютерной техники и технологий, средств и систем коммуникаций в целях научно-технического прогресса и социального развития мирового сообщества. Методы и средства информатики, материализуясь, доходят до потребителя в виде новых информационных технологий, т. е. современных видов информационного обслуживания на базе компьютерных средств и коммуникаций. Компьютер открыл эру безбумажной технологии. По мнению академика Н.Н. Моисеева, создание компьютера столь же крупная веха в становлении человечества, как и использование огня. Контрольные вопросы 1. В чем сложность перестроечных процессов? 2. Что является катализатором ускорения адаптации в перестроечных процессах? 3. Определите понятие " информационный взрыв", приведите иллюстрирующие примеры. 4. Определите понятие " информационные ресурсы" и обоснуйте их значимость. 5. Что вкладывается в понятие информатика? 6. Приведите характеристики, иллюстрирующие динамику развития технических и экономических факторов средств хранения информации. 7. Укажите основные направления, в которых актуально применение ПЭВМ. 8. Каковы основные аспекты решения различных прикладных задач на ПЭВМ? КОНЦЕПЦИЯ ИНФОРМАЦИОННЫХ СИСТЕМ 1.1. Информация и данные предметных областей Информация – это понятие, подразумевающее знание определенных сведений, используемых в различных областях человеческой деятельности. На основе информации углубляются познания законов развития материального мира, взаимосвязываются и координируются различные виды работ, контролируются процессы и принимаются решения. Информацией называются любые сведения о каких-либо явлениях, событиях, процессах, являющихся объектами восприятия, передачи, преобразования, хранения и использования. Обычно потребителя информации интересует некоторый конкретный вопрос, область знаний или какая-то определенная совокупность объектов. В соответствии с этим в информационной деятельности введено понятие предметной области. Предметной областью (ПО) называется определенная часть реального мира, представляющая интерес для конкретного исследования или планируемых действий и соответственно для использования и отображения в информационной системе. При изучении объекта наблюдатель фиксирует состояние системы в определенной форме без выполнения над ним каких-либо операций. Информация, фиксируемая в определенной форме и пригодная для последующей обработки, хранения и передачи, называется данными. Процесс восприятия состояния системы в виде данных, описывающих состояние системы, называется фиксацией данных. Информация, представляемая в виде зарегистрированных фактов, называется фактографической. При изучении ПО в соответствии с понятиями " информация" и " данные" рассматривается 2 аспекта: инфологический; датологический. Инфологический аспект предусматривает рассмотрение вопросов смыслового содержания информации, независимо от способа формирования и организации данных в памяти ЭВМ. Датологический аспект рассматривает вопросы организации данных для их представления в памяти информационной системы. На этом этапе: · формулируются правила смысловой интерпретации данных; · определяются формы представления информации посредством данных в информационной системе; · определяются модели и методы представления и преобразования данных. Определение смыслового содержания зарегистрированных данных называется семантической информацией (или семантикой ). Она необходима для дальнейшего использования в производственных операциях. Основное средство представления семантики данных - это естественный язык. В общем случае работа с семантикой - это работа со знаниями. Благодаря семантической информации машинные системы способны " понимать" задачу в формулировке пользователя, т.е. реализуются " интеллектуальные" возможности или способности ЭВМ. В результате общение с пользователем становится возможным на естественном языке. При этом в режиме диалога " человек - ЭВМ" возможно использование текстовой, графической, а также речевой форм представления информации и получения результатов ее обработки. В информационных системах сложноорганизованные данные, содержащие одновременно как фактографическую, так и семантическую информацию, необходимую пользователю для машинного преобразования исходных фактов в соответствии с определенными правилами, т.е. для работы с данными, называются знаниями. Специализированные информационные системы, оперирующие со знаниями и называемые системами искусственного интеллекта, используются специальные формализованные языки. Эти языки более эффективно реализуют обработку семантической информации. Для представления знаний в ЭВМ применяются различные модели, среди которых наиболее распространены семантические сети, фреймы, логические модели, системы продукций. Системы искусственного интеллекта, называемые также интеллектуальными системами, используются для принятия решений в задачах менеджмента, в различных областях экономической деятельности, для автоматического перевода текстов на иностранных языках, доказательства теорем, диагностирования ситуаций, распознавания изображений, автоматизации процессов проектирования и т.д. Учитывая лавинообразно нарастающие потоки информации в самых различных областях человеческой деятельности, естественен вопрос, как и какими средствами можно представить в ЭВМ столь многообразную и многочисленную информацию и успешно ее использовать. Наиболее совершенной и прогрессивной формой организации информации и знаний в ЭВМ являются банки данных и банки знаний. Главная их задача - это обеспечение пользователей требуемой информацией, т.е. ответы на информационные запросы пользователей к банку данных или банку знаний с целью получения искомой информации. Банк данных (БнД) - это автоматизированная система, включающая базу данных (БД), лингвистические, программные, технические, организационно-методические средства, обеспечивающие централизованное накопление и коллективное многоцелевое использование информации в различных областях деятельности пользователей. В БнД содержатся совокупности фактов о качественных и количественных характеристиках конкретных объектов предметной области. Банк знаний (БнЗ) - это автоматизированная система, содержащая различные виды знаний (например, концептуальные, понятийные знания) о предметной области. Эти знания обычно выражаются в терминах данной ПО. Хранящиеся в БнЗ знания используются для вывода новых знаний на основании специальных механизмов, имеющихся в БнЗ. С БнД и БнЗ в процессе их создания и эксплуатации взаимодействуют пользователи различных категорий, основными из которых являются конечные пользователи. Ими являются специалисты предметных областей, для удовлетворения информационных потребностей которых и создаются БнД и БнЗ. Конечные пользователи различаются: сферой интересов, информационными потребностями, квалификацией и т.п. Под конечным пользователем понимаются как физические лица, так и различные вычислительные процессы, задачи, а иногда и целые системы, взаимодействующие с БнД и БнЗ. Во всех случаях результатом взаимодействия является информация, данные, знания. 1.2. Структура банка данных Структурная схема БнД приведена на рис. 1.1. Здесь ВС - вычислительная система, включающая технические средства (ЭВМ или персональный компьютер, устройства ввода-вывода), операционную систему, программные средства общего назначения и программы пользователей; БД - база данных; СУБД - система управления базами данных; СД - словарь данных; ОП - обслуживающий персонал, т.е. группа сотрудников, обеспечивающая операции по сопровождению технических и программных средств БнД, по вводу и выводу текущей информации; АБД - администратор базы данных.
Рис.1.1. Структурная схема СУБД
База данных База данных (БД) - это объект управления в БнД. БД описывает состояние объектов предметной области на определенный момент времени совокупностью предложений на некотором формализованном языке. При этом определяются значения всех факторов на данный момент в виде совокупности взаимосвязанных, хранящихся вместе данных. Более подробное рассмотрение БД - предмет дальнейшего изучения.
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-06-08; Просмотров: 209; Нарушение авторского права страницы

 1
1
































 МаркаДвигателя * МаркаДвигателя Мощность Масса
МаркаДвигателя * МаркаДвигателя Мощность Масса
 Мощность
Мощность



 №Служащего*:
№Служащего*:




 а1
а1



 а2
а2





 а2 а2
а2 а2
 Ненормализо-ванная форма БД
Ненормализо-ванная форма БД