|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Назначение компьютерных сетейСтр 1 из 24Следующая ⇒
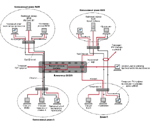
Назначение компьютерных сетей Компьютерные сети включают в себя вычислительные сети, предназначенные для распределенной обработки данных (совместное использование вычислительных мощностей), и информационные сети, предназначенные для совместного использования информационных ресурсов. Компьютерная сеть позволят коллективно решать различные прикладные задачи, увеличивает степень использования имеющихся в сети ресурсов (информационных, вычислительных, коммуникационных) и обеспечивает удаленный доступ к ним. Компьютерная сеть - система взаимосвязанных аппаратных и программных компонентов, осуществляющая обработку информации и взаимодействующая с другими подобными системами. Аппаратные компоненты сети включают в себя компьютеры и коммуникационное оборудование, программные компоненты - сетевые операционные системы и сетевые приложения. Возможности компьютерной сети определяются характеристиками компьютеров, включенных в сеть. Однако и коммуникационное оборудование (кабельные системы, повторители, мосты, маршрутизаторы и др.) играет не менее важную роль. Некоторые из этих устройств представляют собой компьютеры, которые решают сугубо специфические задачи по обслуживанию работы сети. Для эффективной работы сетей используются специальные операционные системы, которые, в отличие от персональных операционных систем, предназначены для решения специальных задач по управлению работой сети компьютеров. Это сетевые ОС. Сетевые ОС устанавливаются на специально выделенные компьютеры. Сетевые приложения - это прикладные программные комплексы, которые расширяют возможности сетевых ОС. Среди них можно выделить почтовые программы, системы коллективной работы, сетевые базы данных и др.
Лекция 2. Физические и логические аспекты эксплуатации сети. Этапы проектирования компьютерной сети
10.
Под инфраструктурой сети понимают множество взаимосвязанных технологий и систем, которые администраторы должны досконально знать, чтобы успешно поддерживать работу сета и устранять неполадки. Инфраструктура определяется:
Определение инфраструктуры сети Инфраструктура сети — это набор физических и логических компонентов, которые обеспечивают связь, безопасность, маршрутизацию, управление, доступ и другие обязательные свойства сети. Чаше всего инфраструктура сета определяется проектом, но многое определяют внешние обстоятельства и * наследственность*. Например, подключение к Интернету требует обеспечить поддержку соответствующих технологий, в частности протокола TCP/IP. Другие же параметры сети, например физическая компоновка основных элементов, определяются при проектировании, а затем уже наследуются позднейшими версиями сети. Физическая инфраструктура Под физической инфраструктурой сети подразумевают ее топологию, то есть физическое строение сети со всем ее оборудованием: кабелями, маршрутизаторами, коммутаторами, мостами, концентраторами, серверами и узлами. К физической инфраструктуре также относятся транспортные технологии: Ethernet. 802.11b, коммутируемая телефонная сеть обшего пользования (PSTN), ATM — в совокупности они определяют, как осуществляется связь на уровне физических подключений. Предполагается, что вы знакомы с основами физической инфраструктуры сети, и эта тема в настоящей статье не рассматривается.
рис. 1-1 Логическая инфраструктура Логическая инфраструктура сети состоит из всего множества программных элементов, служащих для связи, управления и безопасности узлов сети, и обеспечивает связь между компьютерами с использованием коммуникационных каналов, определенных в физической топологии. Примеры элементов логической инфраструктуры сети: система доменных имен (Domain Name System. DNS), сетевые протоколы, например TCP/IP. сетевые клиенты, например Клиент для сетей NetWare (Client Service for NetWare), а также сетевые службы, например Планировщик пакетов качества службы (QoS) |Quality of Service (QoS) Packet Scheduler]. Сопровождение, администрирование и управление логической инфраструктурой существующей сети требует глубокого знания многих сетевых технологий. Администратор сети лаже в небольшой организации должен уметь создавать различные типы сетевых подключений, устанавливать и конфигурировать необходимые сетевые протоколы, знать методы ручной и автоматической адресации и методы разрешения имен и, наконец, устранять неполадки связи, адресации, доступа, безопасности и разрешения имен. В средних и крупных сетях у администраторов более сложные задачи: настройка удаленного доступа по телефонной линии и виртуальных частных сетей (VPN), создание, настройка и устранение неполадок интерфейсов и таблиц маршрутизации, создание, поддержка и устранение неполадок подсистемы безопасности на основе открытых ключей, обслуживание смешанных сетей с разными ОС. в том числе Microsoft Windows. UNIX и Nowell NetWare. Рекомендации по эксплуатации ЛВС: Физические аспекты ЛВС: Для обеспечения правильной работы ЛВС недопустимо несанкционированное ИСПОЛНИТЕЛЕМ физическое вмешательство в инфраструктуру сети (активное и пассивное сетевое оборудование - кабельные каналы, кабель, патч-панели, розетки, и т.п.).
Логические (информационные) аспекты работы ЛВС: Недопустимость использования несанкционированного ПО (в том числе сетевого). Пользователи не должны использовать ЛВС для передачи другим компьютерам или оборудованию сети бессмысленной или бесполезной информации, создающей паразитную нагрузку на эти компьютеры или оборудование, в объемах, превышающих минимально необходимые для проверки работоспособности сети и доступности отдельных ее элементов.
Производительность Определяется такими показателями: время реакции системы - время между моментом возникновения запроса и моментом получения ответа. Пропускная способность сети определяется количеством информации, переданной через сеть или ее сегмент в единицу времени. Определяется в битах в секунду. Надежность Определяется надежностью работы всех ее компонентов. Для повышения надежности работы аппаратных компонентов обычно используют дублирование, когда при отказе одного из элементов функционирование сети обеспечат другие. При работе компьютерной сети должна обеспечиваться сохранность информации и защита ее от искажений. Как правило, важная информация в сети хранится в нескольких экземплярах. В этом случае необходимо обеспечить согласованность данных (например, идентичность копий при изменении информации). Одной из функций компьютерной сети является передача информации, во время которой возможны ее потери и искажения. Для оценки надежности исполнения этой функции используются показатели вероятности потери пакета при его передаче, либо вероятности доставки пакета (передача осуществляется порциями, которые называются пакетами). В современных компьютерных сетях важное значение имеет другая сторона надежности - безопасность. Это способность сети обеспечить защиту информации от несанкционированного доступа. Задачи обеспечения безопасности решаются применением как специального программного обеспечения, так и соответствующих аппаратных средств. Управляемость При работе компьютерной сети, которая объединяет отдельные компьютеры в единое целое, необходимы средства не только для наблюдения за работой сети, сбора разнообразной информации о функционировании сети, но и средства управления сетью. В общем случае система управления сетью должна предоставлять возможность воздействовать на работу любого элемента сети. Должна быть обеспечена возможность осуществлять мероприятия по управлению с любого элемента сети. Управлением сетью занимается администратор сети или пользователь, которому поручены эти функции. Обычный пользователь, как правило, не имеет административных прав. Другими характеристиками управляемости являются возможность определения проблем в работе компьютерной сети или отдельных ее сегментов, выработка управленческих действий для решения выявленных проблем и возможность автоматизации этих процессов при решении похожих проблем в будущем. Прозрачность Прозрачность компьютерной сети является ее характеристикой с точки зрения пользователя. Эта важная характеристика должна оцениваться с разных сторон. Прозрачность сети предполагает скрытие (невидимость) особенностей сети от конечного пользователя. Пользователь обращается к ресурсам сети как к обычным локальным ресурсам компьютероа, на котором он работает. Компьютерная сеть объединяет компьютеры разных типов с разными операционными системами. Пользователю, у которого установлена, например, Windows, прозрачная сеть должна обеспечивать доступ к необходимым ему при работе ресурсам компьютеров, на которых установлена, например, UNIX. Другой важной стороной прозрачности сети является возможность распараллеливания работы между разными элементами сети. Вопросы назначения отдельных параллельных заданий отдельным устройствам сети также должны быть скрытыми от пользователя и решаться в автоматическом режиме.
Интегрируемость Интегрируемость означает возможность подключения к вычислительной сети разнообразного и разнотипного оборудования, программного обеспечения от разных производителей. Если такая неоднородная вычислительная сеть успешно выполняет свои функции, то можно говорить о том, что она обладает хорошей интегрируемостью. Современная компьютерная сеть имеет дело с разнообразной информацией, процесс передачи которой сильно зависит от типа информации. Передача традиционных компьютерных данных характеризуется неравномерной интенсивностью. При этом нет жестких требований к синхронности передачи. При передаче мультимедийных данных качество передаваемой информации в существенной степени зависит от синхронизации передачи. Сосуществование двух типов данных с противоположными требованиями к процессу передачи является сложной задачей, решение которой является необходимым условием вычислительной сети с хорошей интегрируемостью. Основным направлением развития интегрируемости вычислительных сетей является стандартизация сетей, их элементов и компонентов. Среди стандартов различных видов можно выделить стандарты отдельных фирм, стандарты специальных комитетов, создаваемых несколькими фирмами, стандарты национальных организаций по стандартизации, международные стандарты. Термины расширяемость и масштабируемость иногда используют как синонимы, но это неверно — каждый из них имеет четко определенное самостоятельное значение. Расширяемость (extensibility) означает возможность сравнительно легкого добавления отдельных элементов сети (пользователей, компьютеров, приложений служб), наращивания длины сегментов сети и замены существующей аппаратуры более мощной. При этом принципиально важно, что легкость расширения системы иногда может обеспечиваться в некоторых весьма ограниченных пределах. Например, локальная сеть Ethernet, построенная на основе одного сегмента толстого коаксиального кабеля, обладает хорошей расширяемостью, в том смысле, что позволяем легко подключать новые станции. Однако такая сеть имеет ограничение на число станций — их число не должно превышать 30-40. Хотя сеть допускает физическое подключение к сегменту и большего числа станций (до 100), но при этом чаще всего резко снижается производительность сети. Наличие такого ограничения и является признаком плохой масштабируемости системы при хорошей расширяемости. Масштабируемость (scalability) означает, что сеть позволяет наращивать количество узлов и протяженность связей в очень широких пределах, при этом производительность сети не ухудшается. Для обеспечения масштабируемости сети приходится применять дополнительное коммуникационное оборудование и специальным образом структурировать сеть. Например, хорошей масштабируемостью обладает многосегментная сеть, построенная с использованием коммутаторов и маршрутизаторов и имеющая иерархическую структуру связей. Такая сеть может включать несколько тысяч компьютеров и при этом обеспечивать каждому пользователю сети нужное качество обслуживания.
Выполнение аудита После того, как сеть установлена и начала нормально работать, не расслабляйтесь. Теперь самое время упорядочивать документацию. Познакомьтесь с вашей сетью поближе именно сейчас, пока все работает так, как надо. Это не слишком благодарная работа, и не всегда она кажется приятным времяпрепровождением, но окупается при возникновении неисправностей. Во-первых, если вы будете знать, что собой представляет сеть во время нормальной работы, вам будет легче обнаружить неисправность, когда она не работает. " Не работает" не обязательно из-за неисправностей в результате каких-то изменений в сети. Может быть, например, что часть сети работает, но с пониженной производительностью. Так будет продолжаться до тех пор, пока не будет определена и устранена причина. Во-вторых, для поддержания работоспособности больших и протяженных сетей знание схемы физической компоновки вашей сети может быть весьма важным при установлении причины возникновения нарушений или при определении неисправной части сети. Можно выделить две основные разновидности аудита локальных сетей: физический и нематериальный (intangible). Аудит имущества и оборудования чаще всего является физическим — используйте его для определения того, что имеется в наличии, и локализации местонахождения оборудования. Аудит производительности, эффективности и безопасности в большинстве случаев имеет нематериальную природу. Создание карты сети Часть данных по аудиту можно не только записывать в базу данных, но и хранить в форме карты, позволяющей легко определить связь частей сети друг с другом. Карта может быть выполнена в виде твердой копии или храниться в электронном виде и содержать описание сети на физическом уровне вместе с ее логической организацией. Аппаратное резервирование Если метод резервного копирования широко известен и в той или иной степени применяется сейчас повсеместно, то аппаратное резервирование, к сожалению, менее распространено, хотя этот метод обеспечивает более высокий уровень готовности данных. Вообще аппаратное резервирование — это довольно емкое понятие. Оно может подразумевать разные решения, начиная от резервирования внутрисерверных компонентов и заканчивая созданием кластеризованных систем с удаленной репликацией данных на десятки километров, созданием резервных офисов. Кластеризация дает ряд преимуществ, основные из которых — это:
В ИС применяются кластеры как с центральной точкой отказа, так и без нее. Пока наиболее распространены кластеры с центральной точкой отказа. Устранение единой точки отказа обычно выполняется уже на втором этапе, в ходе усовершенствования существующей системы. В целом комплект оборудования для устранения центральной точки отказа обходится примерно в 10 тыс. долл. (для кластера Microsoft на Intel-серверах Compaq). В последнее время все чаще обращают на себя внимание проекты с возможностью организации удаленного зеркалирования дисковых подсистем, находящихся на большом расстоянии друг от друга (до 40 км), например, в разных зданиях в пределах города. На этот счет существует катастрофоустойчивое решение без центральной точки отказа. Под вторым зданием иногда подразумевают резервный офис. Стоимость такого решения достаточно высока — порядка полумиллиона долларов без учета стоимости кабельной системы и работ по ее прокладке. Сетевое копирование Если необходимо хранить резервные копии информации с нескольких серверов в сети организации, применяется так называемое сетевое копирование. Как правило, выделяется сервер, отвечающий за проведение копирования по сети, и непосредственно к нему подключается устройство копирования. Метод также хорошо известен; стоимость решения сильно зависит от типа ленточного накопителя (ориентировочно до 20 тыс. долл.). Схема сетевого копирования может включать соединения с серверами для копирования через активное сетевое оборудование. В качестве устройств резервного копирования могут использоваться несколько ленточных библиотек. В последнее время популярно выделять для резервного копирования отдельный сегмент в сети организации. Протоколы управления В своей работе системы управления опираются на стандартизованные протоколы управления, такие как: · SNMP — один из первых и наиболее простой протокол управления, в настоящий момент актуальной является третья версия протокола, поддерживается в очень большом количестве устройств; · CMIP — протокол управления, рекомендованный ISO в качестве базового, не получил широкого распространения вследствие своей сложности; · TMN — концепция сетевого управления, включающая в себя множество протоколов управления и вводящая понятие уровней управления; · LNMP — протокол управления для ЛВС; · ANMP — протокол управления для сетей специального назначения. SNMP (англ. Simple Network Management Protocol — простой протокол сетевого управления) — стандартный интернет-протокол для управления устройствами в IP-сетях на основе архитектур TCP/UDP. К поддерживающим SNMP устройствам относятся маршрутизаторы, коммутаторы, серверы, рабочие станции, принтеры, модемные стойки и другие. Протокол обычно используется в системах сетевого управления для контроля подключенных к сети устройств на предмет условий, которые требуют внимания администратора. SNMP определен Инженерным советом интернета (IETF) как компонент TCP/IP. Он состоит из набора стандартов для сетевого управления, включая протокол прикладного уровня, схему баз данных и набор объектов данных. SNMP предоставляет данные для управления в виде переменных, описывающих конфигурацию управляемой системы. Эти переменные могут быть запрошены (а иногда и заданы) управляющими приложениями. Обзор и основные понятия
Principle of SNMP Communication При использовании SNMP один или более административных компьютеров (где функционируют программные средства, называемые менеджерами) выполняют отслеживание или управление группой хостов или устройств в компьютерной сети. На каждой управляемой системе есть постоянно запущенная программа, называемая агент, которая через SNMP передаёт информацию менеджеру. Менеджеры SNMP обрабатывают данные о конфигурации и функционировании управляемых систем и преобразуют их во внутренний формат, удобный для поддержания протокола SNMP. Протокол также разрешает активные задачи управления, например, изменение и применение новой конфигурации через удаленное изменение этих переменных. Доступные через SNMP переменные организованы в иерархии. Эти иерархии, как и другие метаданные (например, тип и описание переменной), описываются базами управляющей информации (базы MIB, от англ. Management information base). Управляемые протоколом SNMP сети состоят из трех ключевых компонентов: · Управляемое устройство; · Агент — программное обеспечение, запускаемое на управляемом устройстве, либо на устройстве, подключенном к интерфейсу управления управляемого устройства; · Система сетевого управления (Network Management System, NMS) — программное обеспечение, взаимодействующее с менеджерами для поддержки комплексной структуры данных, отражающей состояние сети[1]. Управляемое устройство — элемент сети (оборудование или программное средство), реализующий интерфейс управления (не обязательно SNMP), который разрешает однонаправленный (только для чтения) или двунаправленный доступ к конкретной информации об элементе. Управляемые устройства обмениваются этой информацией с менеджером. Управляемые устройства могут относиться к любому виду устройств: маршрутизаторы, серверы доступа, коммутаторы, мосты, концентраторы, IP-телефоны, IP-видеокамеры, компьютеры-хосты, принтеры и т.п. Агентом называется программный модуль сетевого управления, располагающийся на управляемом устройстве, либо на устройстве, подключенном к интерфейсу управления управляемого устройства. Агент обладает локальным знанием управляющей информации и переводит эту информацию в специфичную для SNMP форму или из неё (медиация данных). В состав Системы сетевого управления (NMS) входит приложение, отслеживающее и контролирующее управляемые устройства. NMS обеспечивают основную часть обработки данных, необходимых для сетевого управления. В любой управляемой сети может быть одна и более NMS. CMIP (англ. Common Management Information Protocol - протокол общей управляющей информации) — стандарт управления сетью OSI. CMIP оперирует управляющей информацией в виде управляемых объектов. Управляемые объекты описываются на основе GDMO (англ. Guidelines for Definition of Managed Objects - стандарт описания управляемых объектов). CMIP определяет некоторые функции, отсутствующие в SNMP и SNMPv2. В силу своей сложности данный протокол имеет гораздо меньшее распространение и привлекает меньший интерес, нежели SNMP, но иногда его использование необходимо.
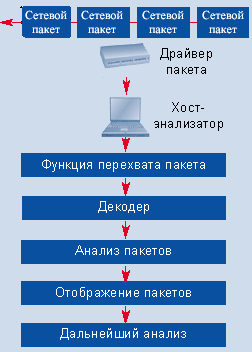
Типичные функции Большинство анализаторов сетевых протоколов работают по схеме, представленной на рис. 1, и отображают, по крайней мере в некотором начальном виде, одинаковую базовую информацию. Анализатор работает на станции хоста. Когда анализатор запускается в беспорядочном режиме (promiscuous mode), драйвер сетевого адаптера, NIC, перехватывает весь проходящий через него трафик. Анализатор протоколов передает перехваченный трафик декодеру пакетов анализатора (packet-decoder engine), который идентифицирует и расщепляет пакеты по соответствующим уровням иерархии. Программное обеспечение протокольного анализатора изучает пакеты и отображает информацию о них на экране хоста в окне анализатора. В зависимости от возможностей конкретного продукта, представленная информация может впоследствии дополнительно анализироваться и отфильтровываться.
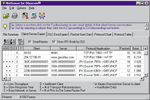
Обычно окно протокольного анализатора состоит их трех областей, как, например, показано на экране 1, демонстрирующем продукт Ethereal. Верхняя область отображает итоговые данные перехваченных пакетов. Обычно в этой области отображается минимум полей, а именно: дата; время (в миллисекундах), когда пакеты были перехвачены; исходные и целевые IP-адреса; исходные и целевые адреса портов; тип протокола (сетевой, транспортный или прикладного уровня); некоторая суммарная информация о перехваченных данных. В средней области показаны логические врезки пакетов, выбранных оператором. И наконец, в нижней области пакет представлен в шестнадцатеричном виде или в символьной форме — ASCII. Общая проблема, которую я наблюдал, работая со многими анализаторами протоколов, включая и те, что рассматриваются в данной статье, — невозможность аккуратной идентификации (а следовательно, и декодирования) протокола, использующего порт, отличный от порта по умолчанию. Сегодня все хорошо осознают важность проблем безопасности, и запуск известных приложений на редко используемых портах является общепринятой практикой защиты от хакеров. Некоторые декодеры умеют распознавать трафик независимо от того, через какой порт он проходит, тогда как другие — нет, и поэтому просто будут определять протокол по его нижнему уровню (т. е. TCP или UDP), а это означает, что декодер не представит более полезной информации о полях. Некоторые анализаторы позволяют модифицировать декодер, чтобы научиться распознавать больше, чем просто порт по умолчанию для определенных протоколов. Обзор анализаторов На рынке программного обеспечения и программных продуктов среди анализаторов сетевых протоколов я, к своему удивлению, обнаружил большое количество сильных программ, вполне достойных друг друга. Оценивая анализатор протоколов, рекомендую особое внимание обратить на такие его свойства, как точность перехвата пакетов, диапазон декодируемых протоколов (с учетом условий работы конкретной сети), степень детализации декодеров, наличие экспертного анализа, модель размещения (распределенная или нет), цена и техническая поддержка. Далее мы рассмотрим шесть анализаторов сетевых протоколов общего назначения: Ethereal, OptiView Protocol Expert 4.0 (производитель — Fluke Networks), Netasyst Network Analyzer WLX (производитель — Network Associates), Observer 9.0 (производитель — Network Instruments), LanHound 1.1 (производитель — Sunbelt Software) и EtherPeek NX 2.1 (производитель — WildPackets).
Тестеры (омметры) Тестеры кабельных систем- наиболее простые и дешевые приборы для диагностики кабеля. Они позволяют определить непрерывность кабеля, однако, в отличие от кабельных сканеров, не обозначают, где произошел сбой. Кабельные сканеры Приборы позволяют определить длину кабеля, NEXT, затухание, импеданс, схему разводки, уровень электрических шумов и оценить полученные результаты. Цена на них варьируется от $1.000 до $3.000. Существует достаточно много устройств данного класса, например, сканеры компаний Microtest Inc., Fluke Corp., Datacom Technologies Inc., Scope Communication Inc. В отличие от сетевых анализаторов сканеры могут быть использованы не только специалистами, но даже администраторами-новичками. Для определения местоположения неисправности кабельной системы (обрыва, короткого замыкания и т.д.) используется метод кабельного радара, или Time Domain Reflectometry (TDR). Суть эго состоит в том, что сканер излучает в кабель короткий электрический импульс и измеряет время задержки до прихода отраженного сигнала. По полярности отраженного импульса определяется характер повреждения кабеля (короткое замыкание или обрыв). В правильно установленном и подключенном кабеле отраженный импульс отсутствует. Наиболее известными производителями компактных (их размеры обычно не превышают размеры видеокассеты стандарта VHS) кабельных сканеров являются компании Microtest Inc., WaveTek Corp., Scope Communication Inc. Рассмотрим подробнее технические воз-можности приборов для сертификации кабельных систем (так в более общем случае называют современные многофункциональные сканеры) на примере семейства моделей PentaScanner компании Microtest. Модель кабельного сканера PentaScanner Cable Admin обеспечивает сертификацию кабельных систем категории 5 уровней точности I. Он предназначен для поиска неисправностей кабельной системы и представляет собой сравнительно дешевый и простой в использовании прибор, позволяющий быстро определить неисправность кабельной системы.
PentaScanner+ проводит все необходимые тесты для сертификации кабельных сетей, включая определение NEXT, затухания, отношения сигнал-шум, импеданса, емкости и активного сопротивления. PentaScanner+ содержит несколько частотных генераторов и узкополосных приемников, графический дисплей на жидких кристаллах и флэш-память для записи результатов тестирования и новых версий программного обеспечения. Как элемент питания PentaScanner использует аккумуляторные батареи, работающие без подзарядки до 10 часов. Прибор содержит разъемы для прямого присоединения к кабелю. Для измерения перекрестных наводок между витыми парами (NEXT) источник сигналов - Super Injector+ (прибор поставляемый в комплекте с PentaScanner+) (подсоединяется к передающей паре и начинает передавать в нее сигналы различной частоты. Приемник сигналов подключается к приемной паре и измеряет сигнал, наведенный в ней, сравнивая его со стандартными величинами. Преимуществом узкополосного приемника в PentaScanner+ является измерение чистого NEXT, с отфильтровыванием всех наводок и электрического шума. Для измерения затухания PentaScanner+ использует Super Injector+ в качестве удаленного источника сигналов, генерирующего серию сигналов различной частоты. PentaScanner+ в этот момент измеряет амплитуду этих сигналов на другом конце кабеля. И, наконец, последняя модель семейства PentaScanner - PentaScanner 350 - являет-ся сканером нового поколения, предназначенного для тестирования кабельных систем категории 5 на частоте до 350 Мгц. Penta-Scanner 350 представляет собой наиболее прецизионный на сегодняшний день кабельный сканер, полностью соответствующий Уровню точности II стандарта TSB-67. В памяти сканера PentaScanner 350 могут сохраняться результаты до 500 различных тестов. Описаные нами устройства предназначены для тестирования кабельных систем на основе медного кабеля. У читателя может возникнуть вопрос: А как же быть с системами на основе волоконно-оптического кабеля?. Действительно, сегодня волоконно-оптические сети находят в мире все большее применение. В пользу еще более широкого распространения их в ближайшем будущем говорит, во-первых, снижение стоимости на сам волоконно-оптический кабель, а также на оборудование для сварки и инсталляции. В скором времени, по мнению зарубежных аналитиков, стоимость медного кабеля категории 5 и волоконно-оптического кабеля сравняются. Во-вторых, именно на волоконно-оптический кабель ориентируются ведущие производители сетевого оборудования при разработке новых стандартов передачи данных, в частности, так называемого, гигабитного Ethernet.
Эти приборы тестируют сети стандартов Ethernet, Token Ring и Fiber Distributed Data Interface (FDDI). FiberEye измеряет мощность светового пучка, входящего или выходящего из волоконно-оптической линии. Точное измерение опической мощности и потери оптического сигнала необходимы при инсталляции, техническом обслуживании и поиске неисправностей в волоконно-оптических сетях. С помощью FiberEye можно также проверить правильность работы различных волоконно-оптических компонентов, волоконно-оптических концентраторов, повторителей и сетевых адаптеров. Данные о потере сигнала помогают определить дефектные участки кабеля, неисправные разъемы и коннекторы. FiberLight - калиброванный световой источник, можно использовать с FiberEye для обеспечения эффективности диагностики волоконно-оптической сети. FiberLight состоит из двух источников световых импульсов, каждый из которых имеет свой внешний разъем для подключения к кабелю. Один источник используется для сетей Ethernet и Token Ring, a другой для сетей FDDI.
Режимы функционирования ЭС может функционировать в 2-х режимах. 1. Режим ввода знаний — в этом режиме эксперт с помощью инженера по знаниям посредством редактора базы знаний вводит известные ему сведения о предметной области в базу знаний ЭС. 2. Режим консультации — пользователь ведет диалог с ЭС, сообщая ей сведения о текущей задаче и получая рекомендации ЭС. Например, на основе сведений о физическом состоянии больного ЭС ставит диагноз в виде перечня заболеваний, наиболее вероятных при данных симптомах. Режимы функционирования ЭС может функционировать в 2-х режимах. 3. Режим ввода знаний — в этом режиме эксперт с помощью инженера по знаниям посредством редактора базы знаний вводит известные ему сведения о предметной области в базу знаний ЭС. 4. Режим консультации — пользователь ведет диалог с ЭС, сообщая ей сведения о текущей задаче и получая рекомендации ЭС. Например, на основе сведений о физическом состоянии больного ЭС ставит диагноз в виде перечня заболеваний, наиболее вероятных при данных симптомах. · Статические ЭС — это ЭС, решающие задачи в условиях не изменяющихся во времени исходных данных и знаний. · Квазидинамические ЭС интерпретируют ситуацию, которая меняется с некоторым фиксированным интервалом времени. · Динамические ЭС — это ЭС, решающие задачи в условиях изменяющихся во времени исходных данных и знаний. Этапы разработки ЭС · Этап идентификации проблем — определяются задачи, которые подлежат решению, выявляются цели разработки, определяются эксперты и типы пользователей. · Этап извлечения знаний — проводится содержательный анализ проблемной области, выявляются используемые понятия и их взаимосвязи, определяются методы решения задач. · Этап структурирования знаний — выбираются ИС и определяются способы представления всех видов знаний, формализуются основные понятия, определяются способы интерпретации знаний, моделируется работа системы, оценивается адекватность целям системы зафиксированных понятий, методов решений, средств представления и манипулирования знаниями. · Этап формализации — осуществляется наполнение экспертом базы знаний. В связи с тем, что основой ЭС являются знания, данный этап является наиболее важным и наиболее трудоемким этапом разработки ЭС. Процесс приобретения знаний разделяют на извлечение знаний из эксперта, организацию знаний, обеспечивающую эффективную работу системы, и представление знаний в виде, понятном ЭС. Процесс приобретения знаний осуществляется инженером по знаниям на основе анализа деятельности эксперта по решению реальных задач. · Реализация ЭС — создается один или несколько прототипов ЭС, решающие требуемые задачи. · Этап тестирования — производится оценка выбранного способа представления знаний в ЭС в целом. Наиболее известные/распространённые ЭС[править | править вики-текст] · Simptomus — сервис онлайн-диагностики заболеваний. Пациенты указывают симптомы, а Simptomus на основе экспертной системы выводит список возможных диагнозов. · CLIPS — весьма популярная оболочка для построения ЭС (public domain) · OpenCyc — мощная динамическая ЭС с глобальной онтологической моделью и поддержкой независимых контекстов · WolframAlpha — база знаний и набор вычислительных алгоритмов, интеллектуальный «вычислительный движок знаний» · MYCIN — наиболее известная диагностическая система, которая предназначена для диагностики и наблюдения за состоянием больного при менингите и бактериальных инфекциях. · HASP/SIAP — интерпретирующая система, которая определяет местоположение и типы судов в Тихом океане по данным акустических систем слежения. · Акинатор — интернет-игра. Игрок должен загадать любого персонажа, а Акинатор должен его отгадать, задавая вопросы. База знаний автоматически пополняется, поэтому программа может отгадать практически любого известного персонажа. · IBM Watson — суперкомпьютер фирмы IBM, способный понимать вопросы, сформулированные на естественном языке, и находить на них ответы в базе данных.
Сетевой монитор. Использование сетевого монитора позволяет собирать сведения, обеспечивающие бесперебойную работу, начиная от определения шаблона до предотвращения и устранения неполадок. Сетевой монитор предоставляет сведения о трафике сетевого адаптера того компьютера, на котором он установлен. Сбор и анализ этих сведений позволяет предотвращать, диагностировать и устранять сетевые неполадки различных типов. Можно настроить сетевой монитор для предоставления конкретных наиболее важных сведений. Например, можно так установить триггеры, что сетевой монитор будет начинать и завершать сбор сведений при соблюдении определенного условия или набора условий. Также можно установить фильтры для контроля за типом собираемых и отображаемых сетевым монитором сведений. Для облегчения анализа сведений можно изменить способ отображения данных на экране, а также сохранить или распечатать данные, чтобы просмотреть их позднее. С помощью компонента Сетевой монитор, включенного в операционные системы Microsoft Windows Server 2003, можно собирать данные, отправленные или полученные с компьютера, на котором установлен сетевой монитор. Для сбора данных, посылаемых или получаемых с удаленного компьютера, необходимо использовать компонент Сетевой монитор, входящий в Microsoft Systems Management Server (SMS), с помощью которого можно собирать данные, посылаемые или получаемые с любого компьютера, на котором установлен драйвер сетевого монитора. Дополнительные сведения о сервере Systems Management Server см. на веб-узле корпорации Майкрософт(http: //www.microsoft.com/smsmgmt). Сведения, предоставляемые сетевым монитором, получены из сетевого трафика и разделены на кадры. Эти кадры содержат такие сведения как адрес компьютера, пославшего кадр, адрес компьютера, которому кадр был послан, и протоколы, существующие в кадре. Запись данных. Процесс копирования пакетов сетевым монитором называется записью. Можно записывать как весь сетевой трафик локального сетевого адаптера, так и отдельные наборы пакетов с помощью фильтров записи. Можно также задать набор условий для триггеров событий. После создания триггеров сетевой монитор может отвечать на события в сети. Например, операционная система может запустить исполняемый файл, если сетевой монитор обнаруживает в сети выполнение определенного набора условий. После записи данных их можно просмотреть. Сетевой монитор преобразует исходные данные в соответствии с логической структурой пакета. При записи кадров сетевым монитором сведения о кадрах отображаются в окне записи данных, разделенном на четыре панели.
Сетевой монитор копирует передаваемые по сети пакеты с требуемыми характеристиками в буфер записи с помощью спецификации NDIS. Фильтры записи. Фильтр записи работает как запрос базы данных, который используется для указания типов пакетов, передаваемых по сети, которые планируется записывать для последующего анализа. Например, для сбора данных, относящихся к определенному подмножеству компьютеров или протоколов, следует подготовить базу данных адресов, использовать эту базу для создания фильтра записи, а затем сохранить этот фильтр в файле. В дальнейшем при необходимости этот файл можно загружать для работы с фильтром. Использование фильтра позволяет сэкономить время и память буфера записи. Создание фильтров записи Чтобы создать фильтр записи, следует выбрать критерии фильтрации в диалоговом окне Фильтр записи. В этом диалоговом окне отображается дерево критериев, которое является графическим представлением логики фильтра. При каждом добавлении или исключении компонентов спецификации записи эти изменения отражаются в дереве критериев. Триггеры записи. После создания триггеров записи сетевой монитор может отвечать на события в сети. По умолчанию условия включения триггера не установлены. Типы триггеров С помощью сетевого монитора можно определить степень заполнения буфера записи и наличие определенного шаблона данных в записанном кадре. Можно создавать триггеры записи на основе одного из этих условий или на основе обоих условий. Если триггер задан на основе определенного шаблона данных в записанном кадре, то сетевой монитор выполнит определенное действие при обнаружении кадра с нужным шаблоном. Шаблон может быть задан шестнадцатеричной строкой или строкой ASCII. Можно задать триггер на основе определенного шаблона данных в записанном кадре и определенного процента заполнения буфера записи. Также можно задать начало поиска для сетевого монитора: с начала каждого кадра, после заголовка каждого кадра или через несколько байт после любого из этих положений. По умолчанию сетевой монитор выполняет поиск по шаблону для всего кадра. Действия триггера Можно выбрать одно из следующих действий триггера, которое будет исполняться при выполнении условий триггера.
Чтобы задать команду, которая запускает программу, введите имя и путь к файлу программы, или нажмите кнопку Обзор и найдите файл программы. Для использования команды MS-DOS, такой как copy, введите CMD /K и затем введите команду. Дизайн хранилищ данных Существуют два архитектурных направления – нормализованные хранилища данных и хранилища с измерениями. В нормализованных хранилищах, данные находятся в предметно ориентированных таблицах третьей нормальной формы. Нормализованные хранилища характеризуются как простые в создании и управлении, недостатки нормализованных хранилищ – большое количество таблиц как следствие нормализации, из-за чего для получения какой-либо информации нужно делать выборку из многих таблиц одновременно, что приводит к ухудшению производительности системы. Для решения этой проблемы используются денормализованные таблицы - витрины данных, на основе которых уже выводятся отчетные формы. При громадных объемах данных могут использовать несколько уровней «витрин»/«хранилищ». Хранилища с измерениями используют схему «звезда» или схему «снежинка». При этом в центре «звезды» находятся данные (Таблица фактов), а измерения образуют лучи звезды. Различные таблицы фактов совместно используют таблицы измерений, что значительно облегчает операции объединения данных из нескольких предметных таблиц фактов (Пример – факты продаж и поставок товара). Таблицы данных и соответствующие измерениями образуют архитектуру «шина». Измерения часто создаются в третьей нормальной форме, в том числе, для протоколирования изменения в измерениях. Основным достоинством хранилищ с измерениями является простота и понятность для разработчиков и пользователей, также, благодаря более эффективному хранению данных и формализованным измерениям, облегчается и ускоряется доступ к данным, особенно при сложных анализах. Основным недостатком является более сложные процедуры подготовки и загрузки данных, а также управление и изменение измерений данных. При достаточно большом объеме данных схемы «звезда» и «снежинка» также дают снижение производительности при соединениях с измерениями. Процессы работы с данными Источниками данных могут быть: 1. Традиционные системы регистрации операций 2. Отдельные документы 3. Наборы данных Операции с данными: 1. Извлечение – перемещение информации от источников данных в отдельную БД, приведение их к единому формату. 2. Преобразование – подготовка информации к хранению в оптимальной форме для реализации запроса, необходимого для принятия решений. 3. Загрузка – помещение данных в хранилище, производится атомарно, путем добавления новых фактов или корректировкой существующих. 4. Анализ – OLAP, Data Mining, сводные отчёты. 5. Представление результатов анализа. Вся эта информация используется в словаре метаданных. В словарь метаданных автоматически включаются словари источников данных. Здесь же описаны форматы данных для их последующего согласования, периодичность пополнения данных, согласованность во времени. Задача словаря метаданных состоит в том, чтобы освободить разработчика от необходимости стандартизировать источники данных. Создание хранилищ данных не должно противоречить действующим системам сбора и обработки информации. Специальные компоненты словарей должны обеспечивать своевременное извлечение данных из них и обеспечить преобразование данных к единому формату на основе словаря метаданных. Логическая структура данных хранилища данных существенно отличается от структуры данных источников данных. Для разработки эффективного процесса преобразования необходима хорошо проработанная модель корпоративных данных и модель технологии принятия решений. Данные для пользователя удобно представлять в многоразмерных БД, где в качестве измерений могут выступать время, цена или географический регион. Кроме извлечения данных из БД, для принятия решений важен процесс извлечения знаний, в соответствии с информационными потребностями пользователя. С точки зрения пользователя в процессе извлечения знаний из БД должны решаться следующие преобразования: данные → информация → знания → полученные решения.
Основные функции СУБД · управление данными во внешней памяти (на дисках); · управление данными в оперативной памяти с использованием дискового кэша; · журнализация изменений, резервное копирование и восстановление базы данных после сбоев; · поддержка языков БД (язык определения данных, язык манипулирования данными). Обычно современная СУБД содержит следующие компоненты: · ядро, которое отвечает за управление данными во внешней и оперативной памяти и журнализацию, · процессор языка базы данных, обеспечивающий оптимизацию запросов на извлечение и изменение данных и создание, как правило, машинно-независимого исполняемого внутреннего кода, · подсистему поддержки времени исполнения, которая интерпретирует программы манипуляции данными, создающие пользовательский интерфейс с СУБД · а также сервисные программы (внешние утилиты), обеспечивающие ряд дополнительных возможностей по обслуживанию информационной системы. Классификации СУБД По модели данных Примеры: · Иерархические · Сетевые · Реляционные · Объектно-ориентированные · Объектно-реляционные По степени распределённости · Локальные СУБД (все части локальной СУБД размещаются на одном компьютере) · Распределённые СУБД (части СУБД могут размещаться на двух и более компьютерах). По способу доступа к БД · Файл-серверные В файл-серверных СУБД файлы данных располагаются централизованно на файл-сервере. СУБД располагается на каждом клиентском компьютере (рабочей станции). Доступ СУБД к данным осуществляется через локальную сеть. Синхронизация чтений и обновлений осуществляется посредством файловых блокировок. Преимуществом этой архитектуры является низкая нагрузка на процессор файлового сервера. Недостатки: потенциально высокая загрузка локальной сети; затруднённость или невозможность централизованного управления; затруднённость или невозможность обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Применяются чаще всего в локальных приложениях, которые используют функции управления БД; в системах с низкой интенсивностью обработки данных и низкими пиковыми нагрузками на БД. На данный момент файл-серверная технология считается устаревшей, а её использование в крупных информационных системах — недостатком[2]. Примеры: Microsoft Access, Paradox, dBase, FoxPro, Visual FoxPro. · Клиент-серверные Клиент-серверная СУБД располагается на сервере вместе с БД и осуществляет доступ к БД непосредственно, в монопольном режиме. Все клиентские запросы на обработку данных обрабатываются клиент-серверной СУБД централизованно. Недостаток клиент-серверных СУБД состоит в повышенных требованиях к серверу. Достоинства: потенциально более низкая загрузка локальной сети; удобство централизованного управления; удобство обеспечения таких важных характеристик как высокая надёжность, высокая доступность и высокая безопасность. Примеры: Oracle, Firebird, Interbase, IBM DB2, Informix, MS SQL Server, Sybase Adaptive Server Enterprise, PostgreSQL, MySQL, Caché, ЛИНТЕР. · Встраиваемые Встраиваемая СУБД — СУБД, которая может поставляться как составная часть некоторого программного продукта, не требуя процедуры самостоятельной установки. Встраиваемая СУБД предназначена для локального хранения данных своего приложения и не рассчитана на коллективное использование в сети. Физически встраиваемая СУБД чаще всего реализована в виде подключаемой библиотеки. Доступ к данным со стороны приложения может происходить через SQL либо через специальные программные интерфейсы. Примеры: OpenEdge, SQLite, BerkeleyDB, Firebird Embedded, Microsoft SQL Server Compact, ЛИНТЕР. Стратегии работы с внешней памятью[править | править вики-текст] СУБД с непосредственной записью — это СУБД, в которых все измененные блоки данных незамедлительно записываются во внешнюю память при поступлении сигнала подтверждения любой транзакции. Такая стратегия используется только при высокой эффективности внешней памяти. СУБД с отложенной записью — это СУБД, в которых изменения аккумулируются в буферах внешней памяти до наступления любого из следующих событий: · контрольной точки; · конец пространства во внешней памяти, отведенное под журнал. СУБД выполняет контрольную точку и начинает писать журнал сначала, затирая предыдущую информацию; · останов. СУБД ждёт, когда всё содержимое всех буферов внешней памяти будет перенесено во внешнюю память, после чего делает отметки, что останов базы данных выполнен корректно; · При нехватке оперативной памяти для буферов внешней памяти. Такая стратегия позволяет избежать частого обмена с внешней памятью и значительно увеличить эффективность работы СУБД.
Лекция 23. Принципы планирования восстановления работоспособности сети при аварийной ситуации. Если пришла беда... Последние несколько лет характеризуются динамичной перестройкой восприятия окружающего мира не только у специалистов, занятых в области информационных технологий, но и у тысяч простых пользователей этих самых информационных технологий. Поскольку чрезвычайные ситуации различной природы стали практически нормой сегодняшнего дня, то, соответственно, возникла и необходимость по формализации деятельности персонала информационных и телекоммуникационных систем в условиях таких ситуаций. В комплекте нормативной документации появился документ – " План восстановления функционирования системы в условиях чрезвычайных ситуаций". Что же он собой представляет? Как его разработать? Какая информация должна быть в нем отражена? Ответы на эти и другие вопросы мы постарались дать в статье. Общие положения Один из наиболее полных и логичных образцов подобного документа был разработан Национальным институтом стандартов США (NIST) в 2001 году (http: //www.anykeynow.com/services/white_papers/bcp1.htm). План восстановления функционирования системы (далее План) устанавливает перечень и последовательность процедур, необходимых для восстановления нормального функционирования системы после наступлении чрезвычайных обстоятельств, повлекших отказ в доступности ресурсов системы в результате выхода из строя отдельных элементов системы, физического разрушения помещений, пожара, наводнения, террористических атак и др. Основная цель реализации Плана заключается в обеспечении быстрого и полного восстановления устойчивого функционирования информационной системы. Поставленная цель достигается решением следующих задач:
Согласно исследованию компании McKinseyQuarterly, за последний год в США значительно возросло число компьютерных атак на корпоративные IT-системы. В исследовании McKinseyQuarterly сообщается, что число компьютерных атак (действия хакеров, вирусов, червей, недобросовестных работников и др.) возросло на 150% по сравнению с 2000 годом, составив в общей сложности 53000 случаев взлома систем информационной безопасности компаний. Такой рост произошел в первую очередь из-за отношения к IT-безопасности как к области сугубо технологической. Это означает, что многими организационными и стратегическими решениями в компаниях попросту пренебрегали. Принципы планирования восстановления Реализуемость Плана основана на двух предположениях:
Допущения при разработке Плана При разработке Плана восстановления, как правило, применяются следующие основные допущения и посылки:
Целью хакерской атаки обычно является хищение коммерческой информации и финансовое мошенничество, однако в Москве, по опросам специалистов, эти позиции составляют лишь 3% и 6% от общего числа хакерских атак. Эксперты Ernst & Young полагают, что масштабы проблемы намного существеннее, а низкий процент объясняется тем, что современные хакеры искусно скрывают следы. Только в Москве ущерб от электронных мошенников оценивается столичными правоохранительными органами в 12 - 15 млн долларов в месяц. Основные требования к политике организации Эффективная реализация Плана требует учета основных его положений при планировании политики развития организации. Прежде всего, организация должна развивать свои способности по восстановлению нормального функционирования информационной системы в случае ее недоступности в течение не более 12 часов. При недоступности аппаратно-программных средств системы, расположенных в центральном офисе организации, более 6 часов должно быть предусмотрено наличие резервного офиса, обладающего соответствующей инфраструктурой и ресурсами для восстановления нормального функционирования системы по резервному варианту. Все процедуры, необходимые для выполнения Плана, должны быть изложены в соответствующих инструкциях в структурных подразделениях организации, привлекаемых к реализации Плана. Документы должны пересматриваться не реже одного раза в год и модифицироваться по мере необходимости. Персонал, ответственный за систему, должен быть обучен выполнять процедуры Плана восстановления. Принятие решения на активацию Плана Решение о необходимости активизации Плана восстановления системы принимает координатор лично, на основании результатов анализа, проведенного группой анализа повреждений, а также выводов и рекомендаций членов оперативного штаба. С этой целью каждый член штаба дает ситуации оценку, в которой приводит свое видение проблемы (активировать или нет в складывающейся обстановке План восстановления) и кратко его аргументирует. В докладах членов штаба и руководителя группы анализа повреждений должна быть отражена следующая информация:
На принятие решения накладываются некоторые серьезные ограничения. Так, решение координатором об активизации Плана восстановления должно быть принято в течение не более 30 минут с момента получения им информации об инциденте. Принятое решение не обсуждается. План восстановления системы должен быть активизирован в обязательном порядке, если анализ повреждений говорит о том, что на восстановление ее работоспособности необходимо более 6 часов, при этом существует опасность физического разрушения инфраструктуры и аппаратно-программных средств системы или реальная угроза жизни и здоровью персонала. Если нанесенный системе ущерб может быть устранен за время не более 6 часов, то координатор вправе не активировать План восстановления, а поручить устранение неисправностей соответствующим специалистам в рабочем порядке. Координатор также может принять решение о привлечении аварийно-спасательных служб города для локализации и ликвидации последствий чрезвычайного происшествия. Как при положительном (активировать План), так и отрицательном (отбой) решении оно доводится до руководства и всех привлекаемых к реализации Плана восстановления структур. Мероприятия по восстановлению работоспособности системы в резервном варианте размещения оборудования и персонала Обеспечение готовности резервного помещения заключается в заблаговременном оснащении резервного центра необходимым количеством средств вычислительной техники, которые образуют автономную подсеть и имеют выход на резервный сервер, а также расходных материалов и канцтоваров. К каждому средству вычислительной техники прилагается инструкция, в которой излагаются действия оператора данного средства при получении сигнала оповещения о чрезвычайной ситуации и команды на переход на резервный режим функционирования системы. Для получения резервных копий программ и данных организуется процесс дублирования и актуализации баз данных, необходимых для работы клиентов системы. Резервные копии программ хранятся как в центральном помещении организации, так и в резервном центре. Актуализация копий программ производится немедленно после их замены или модернизации в системе. Лекция 26. План восстановления системы. В понедельник в два часа ночи вам звонят и сообщают о том, что в результате разрыва водопроводной трубы прямо над вашим офисом серверы и маршрутизаторы, а также большинство рабочих станций стоят в воде. Офис открывается в 8 часов утра. Бен Смит
В понедельник в два часа ночи вам звонят и сообщают о том, что в результате разрыва водопроводной трубы прямо над вашим офисом серверы и маршрутизаторы, а также большинство рабочих станций стоят в воде. Офис открывается в 8 часов утра. Что делать? В подобных ситуациях становится очевидным отличие ИТ-отделов, предусматривающих планирование действий в чрезвычайных ситуациях, от ИТ-отделов, в которых аварийные мероприятия не планируются. Для второй группы описанная выше ситуация - не просто авария, а настоящая катастрофа. Возможность полной потери данных при отсутствии программы послеаварийного восстановления ставит под угрозу деятельность организаций, особенно представителей малого и среднего бизнеса, часто не располагающих средствами для восстановления работоспособности после катастрофических событий. Во многих компаниях планирование чрезвычайных мероприятий фокусируется уже в первую очередь на ИТ. Программа сохранения непрерывности бизнес-операций и послеаварийного восстановления может стать одним из наиболее ценных вкладов отдела ИТ в успешную деятельность организации. Шесть этапов планирования В терминологии планирования действий в аварийных ситуациях фигурируют два общих понятия: планирование сохранения непрерывности бизнеса (Business Continuity Planning, BCP) и планирование послеаварийного восстановления (Disaster Recovery Planning, DRP). Эти понятия, часто используемые как равноценные, представляют различные концепции. ВСР традиционно предусматривает планирование мероприятий, обеспечивающих сохранение деловой активности организации в чрезвычайных ситуациях. Сфера ответственности DRP, по сути, представляет подмножество ВСР и касается восстановления информации и работоспособности систем в случае аварии. Например, выход из строя жесткого диска на сервере базы данных потенциально угрожает целостности бизнеса, но не является результатом катастрофических событий. Разрыв же водопроводной трубы с затоплением серверного помещения и погружением сервера базы данных в воду представляет угрозу целостности бизнеса, рассматриваемую в рамках плана послеаварийного восстановления (DRP). Планирование мероприятий ВСР и DRP - дело непростое, и в крупных организациях этим часто занимаются специальные группы. Однако даже без детального анализа степеней риска и решения прочих сложных вопросов в рамках ВСР и DRP в крупных компаниях можно создать программу сохранения целостности бизнеса и послеаварийного восстановления, если двигаться по шести перечисленным ниже этапам. Шаг 2. Сбор статистики. Опрос узлов сети на предмет получения log-файлов, диагностические команды узла сети, нарушающего общее функционирование (при условии его доступности) Шаг 3. Локализация причины Базируясь на полученных сведениях, отброс некоторых потенциальных проблем. В зависимости от полученных данных, стоит определить характер проблемы – аппаратная ли она или программная. Шаг 4. Устранение проблемы. Представляя вероятные причины неисправности, пошагово осуществлять ряд операций, ведущий к ее устранению, параллельно проверяя результат своих действий. Нужно четко понимать, какое конкретное действие приводит к правильному пути для устранения неисправности, чтобы, во-первых, всегда была возможность вернуться на шаг назад, а во-вторых, иметь представление о том, как решить подобную проблему в будущем используя уже выверенный план действий. Шаг 5. Анализ результатов. Если проблема решена, значит примененный инструментарий для ее решения был верен. Процесс завершен. Если разработанный алгоритм не принес успеха, необходимо вернуться на Шаг 3 и пересмотреть ход действий, осуществив процесс устранения заново.
Анализ проблемы. Заключает в себе несколько первичных действий, необходимых для грубого установления местоположения неисправности. Как правило, сначала определяется проблемный узел (или навскидку, если нет в распоряжении точной топологии и логического устройства сети, из которых можно быстро и четко понять, какой узел за что отвечает, является ли он простым связующим звеном или это пограничный маршрутизатор, являющий точкой соединения с интернет-провайдером или выходом на резервную линию). После того, как возможно неисправный узел сети детектирован, необходимо проверить его доступность и доступность его интерфейсов. Удаленно произведя такого рода действия, можно определенно выяснить, вышел из строя сам узел или проблема только в соединении между узлами. 2. Сбор статистики. Подразумевает собой опрос проблемного маршрутизатора (если он доступен) или соседних узлов сети на предмет получения статистики, а именно файлов журнала, фиксирующего разного рода ошибки на интерфейсах, протоколах и т.д. Оперируя такими данными, можно с большой точностью узнать время, причины и предпосылки возникновения неисправности узла сети либо напрямую из его системных журналов, либо косвенно, запрашивая информацию о состоянии соседних устройств на время нарушения функционирования сети. Локализация причины Оперируя собранными данными, без труда можно отбросить некоторые варианты возникновения поломки, а вместе с ними и неверные действия на пути решения проблемы. То есть, конкретно определив, что неисправность узла аппаратная (отсутствие питания, физический выход из строя оборудования), не придется удаленно пытаться анализировать составляющие протоколы или найти проблему маршрутизации. И наоборот, заведомо установив, что устройство функционирует нормально в штатном режиме, нужно искать проблему только в настройках и программном обеспечении. Таким образом, заведомо корректная локализация причины неисправности, сокращает количество лишних манипуляций и затрачиваемое на устранение проблемы время. Устранение проблемы. Установив с большой долей вероятности неисправный сетевой узел, зная характер проблемы (аппаратный или программный), а так же, располагая сведениями статистики на время нарушения функционирования сети от проблемного узла или от соседних устройств, можно разработать последовательность действий, необходимых для устранения неисправности. Далее, необходимо выбрать некую конечную задачу, на решение которой будут направлены все последующие действия. Каждый шаг предпринимаемых действий должен сопровождаться мониторингом изменений в работе налаживаемого устройства. Если преследуемые цели и фактические показатели функционирования сети не совпадают, а очередной шаг процедуры устранения неисправности ухудшил ситуацию (например, появились сбои в работе уже соседних устройств или целой ветви сети), следует пересмотреть выбор инструментария для разрешения неполадки. 5. Анализ результатов. Выполнив процедуру наладки неисправного узла, необходимо убедиться, решена ли проблема. Если функционирование сети восстановлено, значит постановка задачи и предпринятые действия были верны. Если неисправность по-прежнему не устранена, необходимо вернуться к пункту 3 и пересмотреть в корне корректность локализации причины неисправности. Процесс поиска и устранения неисправности всегда проще облегчить, имея в своем распоряжении: - наличие полной актуальной топологии сети; - логическую карту адресов устройств, подсетей и соединений; - список протоколов, запущенных внутри сети; - правильно сконфигурированные маршрутизаторы; - информация о внешних точках соединения сети с ISP; - своевременное профилактика и диагностика; Располагая таким инструментарием, неполадки будет устранить гораздо легче. А так же, документируя каждый процесс устранения неисправностей, можно облегчить последующие экстренные работы и профилактические мероприятия, зная слабые места сети.
Диагностические команды ОС Таблица 5.1.
Для того чтобы диагностировать ситуацию в сети, необходимо представлять себе взаимодействие различных ее частей в рамках протоколов TCP/IP и иметь некоторое представление о работе Ethernet [4]. Сети, следующие рекомендациям Интернет, имеют локальный сервер имен (DNS, RFC-1912, -1886, -1713, -1706, -1611-12, -1536-37, -1183, -1101, -1034-35; цифры, напечатанные полужирным шрифтом, соответствуют кодам документов, содержащим описания стандартов), служащий для преобразования символьного имени сетевого объекта в его IP-адрес. Обычно эта машина базируется на ОС UNIX. DNS-сервер обслуживает соответствующую базу данных, которая хранит много другой полезной информации. Многие ЭВМ имеют SNMP-резиденты (RFC-1901-7, -1446-5, -1418-20, -1353, -1270, - 1157, -1098), обслуживающие управляющую базу данных MIB (RFC-1792, -1748-49, -1743, -1697, -1573, -1565-66, -1513-14, -1230, -1227, -1212-13 ), содержимое которой поможет также узнать много интересного о состоянии вашей сети. Сама идеология Интернет предполагает богатую диагностику (протокол ICMP, RFC- 1256, 1885, -1788, -792 ).
AnetTest 1.0 --1 Автоматизированное тестирование сетевых устройств и приложений (генератор пакетов и сниффер - sniffer) Net Runner 1.0 Net Runner is an accurate and fast performing analyzer for testing the performance of a network Port Detective 2.0 +1 The Port Detective performs a remote port scan on your IP address. TrafficEmulator 1.4 Stress test servers, routers and firewalls under heavy network load CheckHost 1.5 +5 Network management tool continuously monitors specific host availability. PingMaster 0.9 PingMaster pings computers in its database and monitors their response times Graph-A-Ping 1.0.10 Graph-A-Ping is a free application design to graph a ping to any host
Ускорение работы сети Ещё одна распространенная проблема — медленная работа Windows XP с сетью. Тут особо отличились некоторые антивирусы, например антивирус Касперского, очень сильно затрудняющий работу с сетевыми папками. Для того, чтобы избавиться от этой проблемы, недостаточно выгрузить из памяти антивирусный монитор — нужно ещё остановить службу KAV Monitor Service. Разумеется, риск подцепить вирус при этом повышается. Замечено также, что после установки пакета обновлений Rollback 1 Проводник начинает серьезно «тормозить» при просмотре сетевых папок. Помочь в этом случае может удаление ярлыков в папке My Network Places или возврат к более старой версии файла shell32.dll. Также для ускорения обзора сетевых ресурсов удалите в реестре раздел HKEY_LOCAL_MACHINE\ SOFTWARE\ Microsoft\ Windows\ CurrentVersion\ explorer\ RemoteComputer\ NameSpace\ {D6277990-4C6A-11CF-8D87-00AA0060F5BF} — он отвечает за использование Планировщика Заданий в работе с удалённым ПК и несколько замедляет работу с Проводником в сети (там же могут быть и другие ключи, например, принтера — можно попробовать удалить и их). Попробуйте также отключить поддержку динамической файловой системы, которая тоже может замедлять работу, для чего создайте такой параметр в реестре: HKEY_LOCAL_MACHINE\System\CurrentControlSet\Services\Mup\ Иногда полезно также установить в реестре такой параметр: HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\lanmanserver\parameters (тип DWORD, десятичное значение, возможные значения параметра — 512—65536, оптимально обычно устанавливать 14596). Для некоторого ускорения работы можно попробовать подключать сетевые папки как сетевые диски, а также создать в папке WINDOWS\SYSTEM32\DRIVERS\ETC файл LMHOST (без расширения) с таким примерно содержанием: 192.168.0.101 Computer1 То есть пропишите в нём все IP-адреса вашей сети и соответствующие им имена компьютеров (использование файла LMHOSTS должно быть разрешено в настройках соединения). Кстати, путь к этому файлу можно изменить в разделе реестра HKEY_LOCAL_MACHINE\ SYSTEM\ CurrentControlSet\ Services\ Tcpip\ Parameters — проверьте значение параметра DataBasePath типа REG_EXPAND_SZ. В ряде случаев производители выпускают обновления драйверов сетевых карт, после установки которых работа с сетью улучшается. Правда, иногда помогает только замена сетевой карты (в том числе Wi-Fi) на более современную.
Резервные копии Для сохранения важной информации самым простым способом является создание ее резервных копий и размещение их в безопасном месте. Это могут быть копии на бумаге либо на электронных носителях (например, на магнитных лентах). Резервные копии предотвращают полную потерю информации при случайном или преднамеренном уничтожении файлов. Внимание! Даже наличие резервных копий не гарантирует стопроцентную сохранность информации. Вы можете обнаружить, что случайно уничтожена магнитная лента с важным файлом. Важно вовремя отслеживать создание резервных копий ценных файлов. Безопасным местом для хранения резервных копий являются сейфы или изолированные помещения, в которые ограничен физический доступ лиц. Резервные копии действительно помогают восстановить важную информацию, но не всегда позволяют делать это быстро. Ведь резервные копии нужно сначала забрать из специального хранилища, доставить в нужное место, а затем загрузить в систему. Кроме того, потребуется какое-то время для восстановления каждого приложения или всей системы. Переключение по отказу Переключение по отказу (fail-over) обеспечивает восстановление информации и сохранение производительности. Системы, настроенные подобным образом, способны обнаруживать неисправности и восстанавливать рабочее состояние (выполнение процессов, доступ к информации или соединениям) автоматически с помощью резервных аппаратных средств. Переключение по отказу еще называется прямым восстановлением, поскольку не требует настройки. Резервная система располагается на том же рабочем месте, что и основная, чтобы незамедлительно включиться в работу при возникновении сбоя в исходной системе. Это наименее дорогостоящий вариант для большинства систем переключения по отказу. Примечание Механизмы обеспечения доступности являются самыми дорогими средствами безопасности в организации. Чтобы определить состав необходимых аппаратных средств, важно учесть требования соответствующих процедур управлением риском (см. в " Управление риском" ). Предотвращение атак Механизмы обеспечения доступности используются для восстановления систем после атак на отказ в обслуживании. Надежных и эффективных способов предотвращения атак DoS мало, но данная служба позволит уменьшить последствия атак и вернуть системы и аппаратуру в рабочее состояние
Назначение компьютерных сетей Компьютерные сети включают в себя вычислительные сети, предназначенные для распределенной обработки данных (совместное использование вычислительных мощностей), и информационные сети, предназначенные для совместного использования информационных ресурсов. Компьютерная сеть позволят коллективно решать различные прикладные задачи, увеличивает степень использования имеющихся в сети ресурсов (информационных, вычислительных, коммуникационных) и обеспечивает удаленный доступ к ним. Компьютерная сеть - система взаимосвязанных аппаратных и программных компонентов, осуществляющая обработку информации и взаимодействующая с другими подобными системами. Аппаратные компоненты сети включают в себя компьютеры и коммуникационное оборудование, программные компоненты - сетевые операционные системы и сетевые приложения. Возможности компьютерной сети определяются характеристиками компьютеров, включенных в сеть. Однако и коммуникационное оборудование (кабельные системы, повторители, мосты, маршрутизаторы и др.) играет не менее важную роль. Некоторые из этих устройств представляют собой компьютеры, которые решают сугубо специфические задачи по обслуживанию работы сети. Для эффективной работы сетей используются специальные операционные системы, которые, в отличие от персональных операционных систем, предназначены для решения специальных задач по управлению работой сети компьютеров. Это сетевые ОС. Сетевые ОС устанавливаются на специально выделенные компьютеры. Сетевые приложения - это прикладные программные комплексы, которые расширяют возможности сетевых ОС. Среди них можно выделить почтовые программы, системы коллективной работы, сетевые базы данных и др.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Последнее изменение этой страницы: 2019-06-19; Просмотров: 766; Нарушение авторского права страницы



 Кабельный сканер PentaScanner+ предназначен, главным образом, для специалистов компаний сетевых интеграторов или сотрудников отделов автоматизаций предприятий, которым необходимо устанавливать и сертифицировать кабельные системы категории 5. TSB-67 требует измерение NEXT с обоих концов линии. Используя PentaScanner+ совместно с двунаправленным инжектором - 2-Way Injector+, измерения NEXT можно производить с обоих концов линии одновременно. При использовании PentaScanner+ совместно со стандартным инжектором - Super Injector+, необходимо менять местами PentaScanner+ и Super Injector+ для проведения полной сертификации линии (рис. Кабельный сканер PentaScanner+ с двунаправленным инжектором - 2-Way Injector+).
Кабельный сканер PentaScanner+ предназначен, главным образом, для специалистов компаний сетевых интеграторов или сотрудников отделов автоматизаций предприятий, которым необходимо устанавливать и сертифицировать кабельные системы категории 5. TSB-67 требует измерение NEXT с обоих концов линии. Используя PentaScanner+ совместно с двунаправленным инжектором - 2-Way Injector+, измерения NEXT можно производить с обоих концов линии одновременно. При использовании PentaScanner+ совместно со стандартным инжектором - Super Injector+, необходимо менять местами PentaScanner+ и Super Injector+ для проведения полной сертификации линии (рис. Кабельный сканер PentaScanner+ с двунаправленным инжектором - 2-Way Injector+). Для диагностики волоконно-оптических кабелей компания Microtest предлагает комплект Fiber Solution Kit, который состоит из двух приборов: измерителя оптической мощности FiberEye и калиброванного светового источника FiberLight (рис. Измеритель оптической мощности FiberEye и калиброванный световой источник FiberLight).
Для диагностики волоконно-оптических кабелей компания Microtest предлагает комплект Fiber Solution Kit, который состоит из двух приборов: измерителя оптической мощности FiberEye и калиброванного светового источника FiberLight (рис. Измеритель оптической мощности FiberEye и калиброванный световой источник FiberLight).

 Причина, вследствие которой мы изменили свои планы, заключается в следующем. В ходе проведения выставки Internetcom’98 мы (компания " ПроЛАН" ) решили изучить рынок диагностических средств в России. С этой целью посетителям нашего стенда было предложено письменно ответить на ряд вопросов относительно организации процесса диагностики локальной сети в их компании. Нас, в частности, интересовала актуальность проблемы диагностики сетей и ассортимент применяемых диагностических средств.
Причина, вследствие которой мы изменили свои планы, заключается в следующем. В ходе проведения выставки Internetcom’98 мы (компания " ПроЛАН" ) решили изучить рынок диагностических средств в России. С этой целью посетителям нашего стенда было предложено письменно ответить на ряд вопросов относительно организации процесса диагностики локальной сети в их компании. Нас, в частности, интересовала актуальность проблемы диагностики сетей и ассортимент применяемых диагностических средств.