|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Многопроцессорный вычислительный комплекс на основе коммутационной матрицы с симметричной обработкой заданий всеми процессорамиСтр 1 из 5Следующая ⇒
Московский государственный институт радиотехники, электроники и автоматики (Технический Университет)
Проект по курсу “Вычислительные комплексы, системы и сети ЭВМ”
Многопроцессорный вычислительный комплекс на основе коммутационной матрицы с симметричной обработкой заданий всеми процессорами
Группа: АВ-33-93 Студент: Липин В.В.
Москва 1998 Общая часть
Содержание
1. Общая часть 1.1. Содержание 1.2. Задание 1.3. Введение 2. Аппаратная организация МПВК 2.1. Структурная схема МПВК 2.2. Функциональная схема элемента коммутационной матрицы 2.3. Организация оперативной памяти 2.3.1. Память с расслоением 2.3.2. Применение кода Хэмминга в модулях памяти 2.4. Организация резервирования и восстановления при отказе любого компонента МПВК 3. Организация функционирования ОС на МПВК 3.1. Симметричная многопроцессорная обработка (SMP) 3.2. Нити 3.2.1. Подходы к организации нитей и управлению ими в разных вариантах ОС UNIX 3.3. Семафоры 3.3.1. Определение семафоров 3.3.2. Реализация семафоров 3.4. Тупиковые ситуации 3.5. Предотвращение тупиковых ситуаций Линейное упорядочение ресурсов Иерархическое упорядочение ресурсов Алгоритм банкира 3.6. Защита информации 4. Литература Задание (вариант №16)
Разработать многопроцессорный вычислительный комплекс по следующим исходным данным: · использовать матрицу с перекрестной коммутацией; · количество процессоров – 8; · количество блоков ОЗУ – 4; · количество каналов ввода-вывода – 4; Требуется разработать структурную схему коммутационной матрицы и функциональную схему элемента коммутационной матрицы. Описать функционирование ОС для организации многопроцессорной обработки. Описать организацию резервирования и восстановления вычислительного процесса при отказе любого компонента многопроцессорного вычислительного комплекса. Введение Разработка многопроцессорных (МПВК) и многомашинных (ММВК) вычислительных комплексов, как правило, имеет свой целью повышение либо уровня надежности, либо уровня производительности комплекса до значений недоступных или труднореализуемых (реализуемых с большими экономическими затратами) в традиционных ЭВМ. На большинстве классов решаемых задач для достижения высокой производительности наиболее эффективны МПВК. Это связано с большой интенсивностью информационных обменов между подзадачами, которая приводит к слишком высоким накладным расходам в ММВК. ММВК, в принципе, позволяют достичь много большей производительности благодаря лучшей масштабируемости, однако это преимущество проявляется только при соответствия решаемых задач условию максимального удлинения независимых ветвей программы, что не всегда возможно. Указанный в задании МПВК с матрицей перекрестной коммутации позволяет достичь наибольшей производительности, что связано с минимизацией вероятности конфликтов при доступе к компонентам комплекса. При построении МПВК на основе доступа с использованием одной или нескольких общих шин конфликты доступа намного более вероятны, что приводит к заметному снижению производительности по сравнению с МПВК на основе матрицы перекрестной коммутации. Исходя из этих соображений было решено проектировать МПВК по критерию максимальной производительности, меньше уделяя внимания высокой отказоустойчивости комплекса. Это решение также обосновывается и тем, что современные микроэлектронные изделия обладают вполне достаточной надежностью для подавляющего большинства коммерческих применений, что делает экономически необоснованным существенное усложнение комплекса с целью достижения высокой отказоустойчивости. Аппаратная организация МПВК
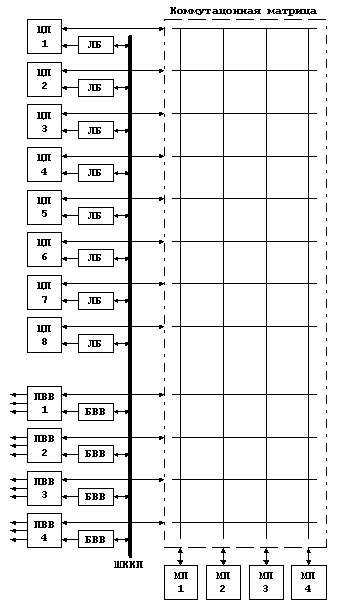
2.1 Структурная схема МПВК В МПВК с перекрестной коммутацией все связи осуществляются с помощью специального устройства – коммутационной матрицы. Коммутационная матрица позволяет связывать друг с другом любую пару устройств, причем таких пар может быть сколько угодно – связи не зависят друг от друга. Структурная схема МПВК приведена на рисунке:
Коммутационная матрица выполняет передачу данных между процессорами и памятью, а также между процессорами ввода-вывода и памятью. Коммутируются только внутренние шины МПВК, основное назначение которых – высокоскоростная передача данных, для этих шин нет смысла добиваться высокой протяженности проводников или стандартизации с целью упрощения подключения дополнительных устройств. Высокоскоростной обмен с периферийными устройствами осуществляется посредством процессоров ввода-вывода, которые являются контроллерами периферийных высокоскоростных шин, к которым, в свою очередь и подключаются контроллеры соответствующих устройств. На роль таких периферийных шин подходят, например, VME (применяется в МПВК фирмы Digital Equipment Company), SBus (применяется в МПВК фирмы Sun Microsystems) или PCI (применяется в МПВК, построенных на процессорах фирмы Intel семейства x86). В SMP совместимой системе прерывания управляются контроллерами APIC (Advanced Programmable Interrupt Controller), БИС которых серийно выпускаются многими производителями микроэлектронных изделий (например DEC, Sun, IBM, Texas Instruments). Данные контроллеры обладают распределенной архитектурой, в которой функции управления прерываниями распределены между двумя функциональными блоками: локальным (ЛБ) и ввода-вывода (БВВ). Эти блоки обмениваются информацией через шину, называемую шиной коммуникаций контроллера прерываний (ШККП). Устройство ввода-вывода определяет появление прерывания, адресует его локальному блоку и посылает по шине ШККП. Блоки APIC совместно отвечают за доставку прерывания от источника прерываний до получателей по всей системе. Использование такой организации дополнительно увеличивает расширяемость за счет разгрузки разделения между процессорами нагрузки по обработке прерываний. Благодаря распределенной архитектуре, локальные блоки или блоки ввода-вывода могут быть реализованы в отдельной микросхеме или интегрированы с другими компонентами системы. В МПВК подобной структуры нет конфликтов из-за связей, остаются только конфликты из-за ресурсов. Возможность одновременной связи нескольких пар устройств позволяет добиваться очень высокой производительности комплекса. Важно отметить и такое обстоятельство, как возможность установления связи между устройствами на любое, даже длительное время, так как это совершенно не мешает работе других устройств, зато позволяет передавать любые массивы информации с высокой скоростью, что также способствует повышению производительности комплекса. Кроме того, к достоинствам структуры с перекрестной коммутацией можно отнести простоту и унифицированность интерфейсов всех устройств, а также возможность разрешения всех конфликтов в коммутационной матрице. Важно отметить и то, что нарушение какой-то связи приводит не к выходу из строя всего устройств, т.е. надежность таких комплексов достаточно высока. Однако и организация МПВК с перекрестной коммутацией не свободна от недостатков. Прежде всего - сложность наращивания ВК. Если в коммутационной матрице заранее не предусмотреть большого числа входов, то введение дополнительных устройств в комплекс потребует установки новой коммутационной матрицы. Существенным недостатком является и то, что коммутационная матрица при большом числе устройств в комплексе становится сложной, громоздкой и достаточно дорогостоящей. Надо учесть то обстоятельство, что коммутационные матрицы строятся обычно на схемах, быстродействие которых существенно выше быстродействия схем и элементов основных устройств – только при этом условии реализуются все преимущества коммутационной матрицы. Это обстоятельство в значительной степени усложняет и удорожает комплексы. Память с расслоением Наличие в системе множества микросхем памяти позволяет использовать потенциальный параллелизм, заложенный в такой организации. Для этого микросхемы памяти часто объединяются в банки или модули, содержащие фиксированное число слов, причем только к одному из этих слов банка возможно обращение в каждый момент времени. Как уже отмечалось, в реальных системах имеющаяся скорость доступа к таким банкам памяти редко оказывается достаточной. Следовательно, чтобы получить большую скорость доступа, нужно осуществлять одновременный доступ ко многим банкам памяти. Одна из общих методик, используемых для этого, называется расслоением памяти. При расслоении банки памяти обычно упорядочиваются так, чтобы N последовательных адресов памяти i, i+1, i+2, ..., i+N-1 приходились на N различных банков. В i-том банке памяти находятся только слова, адреса которых имеют вид k*N + i (где 0 < k < M-1, а M число слов в одном банке). Можно достичь в N раз большей скорости доступа к памяти в целом, чем у отдельного ее банка, если обеспечить при каждом доступе обращение к данным в каждом из банков. Имеются разные способы реализации таких расслоенных структур. Большинство из них напоминают конвейеры, обеспечивающие рассылку адресов в различные банки и мультиплексирующие поступающие из банков данные. Таким образом, степень или коэффициент расслоения определяют распределение адресов по банкам памяти. Такие системы оптимизируют обращения по последовательным адресам памяти, что является характерным при подкачке информации в кэш-память при чтении, а также при записи, в случае использования кэш-памятью механизмов обратного копирования. Однако, если требуется доступ к непоследовательно расположенным словам памяти, производительность расслоенной памяти может значительно снижаться. Обобщением идеи расслоения памяти является возможность реализации нескольких независимых обращений, когда несколько контроллеров памяти позволяют банкам памяти (или группам расслоенных банков памяти) работать независимо. Если система памяти разработана для поддержки множества независимых запросов (как это имеет место при работе с кэш-памятью, при реализации многопроцессорной и векторной обработки), эффективность системы будет в значительной степени зависеть от частоты поступления независимых запросов к разным банкам. Обращения по последовательным адресам, или, в более общем случае, обращения по адресам, отличающимся на нечетное число, хорошо обрабатываются традиционными схемами расслоенной памяти. Проблемы возникают, если разница в адресах последовательных обращений четная. Одно из решений, используемое в больших компьютерах, заключается в том, чтобы статистически уменьшить вероятность подобных обращений путем значительного увеличения количества банков памяти. Например, в суперкомпьютере NEC SX/3 используются 128 банков памяти. Подобные проблемы могут быть решены как программными, так и аппаратными средствами.
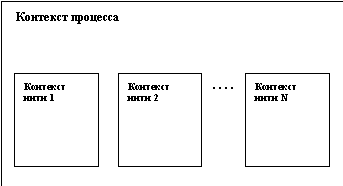
Также стоит подчеркнуть, что, несмотря на возможности организации отказоустойчивости МПВК, все наиболее серьезные реализации отказоустойчивых вычислительных систем представляют собой ММВК. Это объясняется большей изолированностью, а следовательно и к меньшему воздействию отказавших модулей на другие модули в ММВК. Нити (threads) Понятие " легковесного процесса" (light-weight process), или, как принято называть его в современных вариантах ОС, " thread" (нить, поток управления) давно известно в области операционных систем. Интуитивно понятно, что концепции виртуальной памяти и потока команд, выполняющегося в этой виртуальной памяти, в принципе, ортогональны. Ни из чего не следует, что одной виртуальной памяти должен соответствовать один и только один поток управления. Поэтому, например, в ОС Multics допускалось (и являлось принятой практикой) иметь произвольное количество процессов, выполняемых в общей (разделяемой) виртуальной памяти. Понятно, что если несколько процессов совместно пользуются некоторыми ресурсами, то при доступе к этим ресурсам они должны синхронизироваться (например, с использованием семафоров, см. раздел “Семафоры”). Многолетний опыт программирования с использованием явных примитивов синхронизации показал, что этот стиль " параллельного" программирования порождает серьезные проблемы при написании, отладке и сопровождении программ (наиболее трудно обнаруживаемые ошибки в программах обычно связаны с синхронизацией). Это явилось одной из причин того, что в традиционных вариантах ОС понятие процесса жестко связывалось с понятием отдельной и недоступной для других процессов виртуальной памяти. Каждый процесс был защищен ядром операционной системы от неконтролируемого вмешательства других процессов. Многие годы это считалось одним из основных достоинств системы (впрочем, это мнение существует и сегодня). Однако связывание процесса с виртуальной памятью порождает, по крайней мере, две проблемы. Первая проблема связана с так называемыми системами реального времени. Такие системы, как правило, предназначены для одновременного управления несколькими внешними объектами и наиболее естественно представляются в виде совокупности " параллельно" (или " квазипараллельно" ) выполняемых потоков команд (т. е. взаимодействующих процессов). Однако если с каждым процессом связана отдельная виртуальная память, то смена контекста процессора (т. е. его переключение с выполнения одного процесса на выполнение другого процесса) является относительно дорогостоящей операцией. Поэтому традиционный подход препятствовал использованию системы в приложениях реального времени. Второй (и может быть более существенной) проблемой явилось появление так называемых симметричных мультипроцессорных компьютерных архитектур (SMP - Symmetric Multiprocessor Processing). В таких компьютерах физически присутствуют несколько процессоров, которые имеют одинаковые по скорости возможности доступа к совместно используемой основной памяти. Появление подобных машин на мировом рынке, естественно, вывело на первый план проблему их эффективного использования. Понятно, что при применении традиционного подхода к организации процессов от наличия общей памяти не очень много толка (хотя при наличии возможностей разделяемой памяти об этом можно спорить). К моменту появления SMP выяснилось, что технология программирования все еще не может предложить эффективного и безопасного способа реального параллельного программирования. Поэтому пришлось вернуться к явному параллельному программированию с использованием параллельных процессов в общей виртуальной (а тем самым, и основной) памяти с явной синхронизацией. Что же понимается под " нитью" (thread)? Это независимый поток управления, выполняемый в контексте некоторого процесса. Фактически, понятие контекста процесса изменяется следующим образом. Все, что не относится к потоку управления (виртуальная память, дескрипторы открытых файлов и т. д.), остается в общем контексте процесса. Вещи, которые характерны для потока управления (регистровый контекст, стеки разного уровня и т. д.), переходят из контекста процесса в контекст нити. Общая картина показана на рисунке:
Как видно из этого рисунка, все нити процесса выполняются в его контексте, но каждая нить имеет свой собственный контекст. Контекст нити, как и контекст процесса, состоит из пользовательской и ядерной составляющих. Пользовательская составляющая контекста нити включает индивидуальный стек нити. Поскольку нити одного процесса выполняются в общей виртуальной памяти, все нити процесса имеют равные права доступа к любым частям виртуальной памяти процесса, стек (сегмент стека) любой нити процесса в принципе не защищен от произвольного (например, по причине ошибки) доступа со стороны других нитей. Ядерная составляющая контекста нити включает ее регистровый контекст (в частности, содержимое регистра счетчика команд) и динамически создаваемые ядерные стеки. Приведенное краткое обсуждение понятия нити кажется достаточным для того, чтобы понять, что внедрение в ОС механизма легковесных процессов требует существенных переделок ядра системы. (Всегда трудно внедрить в программу средства, для поддержки которых она не была изначально приспособлена.)
3.2.1 Подходы к организации нитей и управлению ими в разных вариантах ОС UNIX Хотя концептуально реализации механизма нитей в разных современных вариантах практически эквивалентны (да и что особенное можно придумать по поводу легковесных процессов? ), технически и, к сожалению, в отношении интерфейсов эти реализации различаются. Мы не ставим здесь перед собой цели описать в деталях какую-либо реализацию, однако постараемся в общих чертах охарактеризовать разные подходы. Начнем с того, что разнообразие механизмов нитей в современных вариантах ОС UNIX само по себе представляет проблему. Сейчас достаточно трудно говорить о возможности мобильного параллельного программирования в среде UNIX-ориентированных операционных систем. Если программист хочет добиться предельной эффективности (а он должен этого хотеть, если для целей его проекта приобретен дорогостоящий мультипроцессор), то он вынужден использовать все уникальные возможности используемой им операционной системы. Для всех очевидно, что сегодняшняя ситуация далека от идеальной. Однако, по-видимому, ее было невозможно избежать, поскольку поставщики симметричных мультипроцессорных архитектур должны были как можно раньше предоставить своим покупателям возможности эффективного программирования, и времени на согласование решений просто не было (любых поставщиков прежде всего интересует объем продаж, а проблемы будущего оставляются на будущее). Применяемые в настоящее время подходы зависят от того, насколько внимательно разработчики ОС относились к проблемам реального времени. (Возвращаясь к введению этого раздела, еще раз отметим, что здесь мы имеем в виду " мягкое" реальное время, т. е. программно-аппаратные системы, которые обеспечивают быструю реакцию на внешние события, но время реакции не установлено абсолютно строго.) Типичная система реального времени состоит из общего монитора, который отслеживает общее состояние системы и реагирует на внешние и внутренние события, и совокупности обработчиков событий, которые, желательно параллельно, выполняют основные функции системы. Понятно, что от возможностей реального распараллеливания функций обработчиков зависят общие временные показатели системы. Если, например, при проектировании системы замечено, что типичной картиной является " одновременное" поступление в систему N внешних событий, то желательно гарантировать наличие реальных N устройств обработки, на которых могут базироваться обработчики. На этих наблюдениях основан подход компании Sun Microsystems. В системе Solaris (правильнее говорить SunOS 4.x, поскольку Solaris в терминологии Sun представляет собой не операционную систему, а расширенную операционную среду) принят следующий подход. При запуске любого процесса можно потребовать резервирования одного или нескольких процессоров мультипроцессорной системы. Это означает, что операционная система не предоставит никакому другому процессу возможности выполнения на зарезервированном(ых) процессоре(ах). Независимо от того, готова ли к выполнению хотя бы одна нить такого процесса, зарезервированные процессоры не будут использоваться ни для чего другого. Далее, при образовании нити можно закрепить ее за одним или несколькими процессорами из числа зарезервированных. В частности, таким образом, в принципе можно привязать нить к некоторому фиксированному процессору. В общем случае некоторая совокупность потоков управления привязывается к некоторой совокупности процессоров так, чтобы среднее время реакции системы реального времени удовлетворяло внешним критериям. Очевидно, что это " ассемблерный" стиль программирования (слишком много перекладывается на пользователя), но зато он открывает широкие возможности перед разработчиками систем реального времени (которые, правда, после этого зависят не только от особенностей конкретной операционной системы, но и от конкретной конфигурации данной компьютерной установки). Подход Solaris преследует цели удовлетворить разработчиков систем " мягкого" (а, возможно, и " жесткого" ) реального времени, и поэтому фактически дает им в руки средства распределения критических вычислительных ресурсов. В других подходах в большей степени преследуется цель равномерной балансировки загрузки мультипроцессора. В этом случае программисту не предоставляются средства явной привязки процессоров к процессам или нитям. Система допускает явное распараллеливание в пределах общей виртуальной памяти и " обещает", что по мере возможностей все процессоры вычислительной системы будут загружены равномерно. Этот подход обеспечивает наиболее эффективное использование общих вычислительных ресурсов мультипроцессора, но не гарантирует корректность выполнения систем реального времени (если не считать возможности установления специальных приоритетов реального времени). Отметим существование еще одной аппаратно-программной проблемы, связанной с нитями (и не только с ними). Проблема связана с тем, что в существующих симметричных мультипроцессорах обычно каждый процессор обладает собственной сверхбыстродействующей буферной памятью (кэшем). Идея кэша, в общих чертах, состоит в том, чтобы обеспечить процессору очень быстрый (без необходимости выхода на шину доступа к общей оперативной памяти) доступ к наиболее актуальным данным. В частности, если программа выполняет запись в память, то это действие не обязательно сразу отображается в соответствующем элементе основной памяти; до поры до времени измененный элемент данных может содержаться только в локальном кэше того процессора, на котором выполняется программа. Конечно, это противоречит идее совместного использования виртуальной памяти нитями одного процесса (а также идее использования памяти, разделяемой между несколькими процессами). Это очень сложная проблема, относящаяся к области проблем " когерентности кэшей". Теоретически имеется много подходов к ее решению (например, аппаратное распознавание необходимости выталкивания записи из кэша с синхронным объявлением недействительным содержания всех кэшей, включающих тот же элемент данных). Однако на практике такие сложные действия не применяются, и обычным приемом является отмена режима кэширования в том случае, когда на разных процессорах мультипроцессорной системы выполняются нити одного процесса или процессы, использующие разделяемую память. После введения понятия нити трансформируется само понятие процесса. Теперь лучше (и правильнее) понимать процесс ОС UNIX как некоторый контекст, включающий виртуальную память и другие системные ресурсы (включая открытые файлы), в котором выполняется, по крайней мере, один поток управления (нить), обладающий своим собственным (более простым) контекстом. Теперь ядро знает о существовании этих двух уровней контекстов и способно сравнительно быстро изменять контекст нити (не изменяя общего контекста процесса) и так же, как и ранее, изменять контекст процесса. Последнее замечание относится к синхронизации выполнения нитей одного процесса (точнее было бы говорить о синхронизации доступа нитей к общим ресурсам процесса - виртуальной памяти, открытым файлам и т. д.). Конечно, можно пользоваться (сравнительно) традиционными средствами синхронизации (например, семафорами). Однако оказывается, что система может предоставить для синхронизации нитей одного процесса более дешевые средства (поскольку все нити работают в общем контексте процесса). Обычно эти средства относятся к классу средств взаимного исключения (т. е. к классу семафороподобных средств). К сожалению, и в этом отношении к настоящему времени отсутствует какая-либо стандартизация. Семафоры Поддержка операционной системы в многопроцессорной конфигурации может включать в себя разбиение ядра системы на критические участки, параллельное выполнение которых на нескольких процессорах не допускается. Нижеследующие рассуждения помогают понять суть данной особенности. При ближайшем рассмотрении сразу же возникают два вопроса: как использовать семафоры и где определить критические участки. Если при выполнении критического участка программы процесс приостанавливается, для защиты участка от посягательств со стороны других процессов алгоритмы работы ядра однопроцессорной операционной системы используют блокировку.
Механизм установления блокировки:
/* операция проверки */ выполнять пока (блокировка установлена) { приостановиться (до снятия блокировки); }; установить блокировку;
Механизм снятия блокировки:
снять блокировку; вывести из состояния приостанова все процессы, приостановленные в результате блокировки;
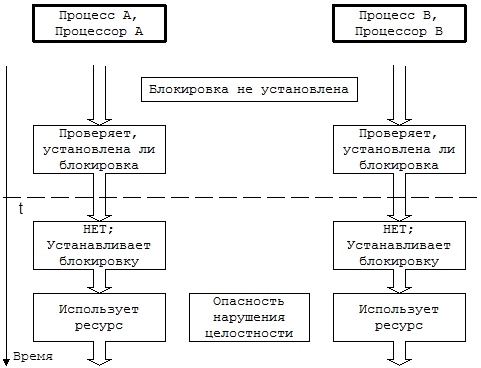
Блокировки такого рода охватывают некоторые критические участки, но не работают в многопроцессорных системах, что видно из приведенного рисунка:
Предположим, что блокировка снята, и что два процесса на разных процессорах одновременно пытаются проверить ее наличие и установить ее. В момент t они обнаруживают снятие блокировки, устанавливают ее вновь, вступают в критический участок и создают опасность нарушения целостности структур данных ядра. В условии одновременности имеется отклонение: механизм не сработает, если перед тем, как процесс выполняет операцию проверки, ни один другой процесс не выполнил операцию установления блокировки. Если, например, после обнаружения снятия блокировки процессор A обрабатывает прерывание и в этот момент процессор B выполняет проверку и устанавливает блокировку, по выходе из прерывания процессор A так же установит блокировку. Чтобы предотвратить возникновение подобной ситуации, нужно сделать так, чтобы процедура блокирования была неделимой: проверку наличия блокировки и ее установку следует объединить в одну операцию, чтобы в каждый момент времени с блокировкой имел дело только один процесс.
Определение семафоров Семафор представляет собой обрабатываемый ядром целочисленный объект, для которого определены следующие элементарные (неделимые) операции:
· Инициализация семафора, в результате которой семафору присваивается неотрицательное значение; · Операция типа P, уменьшающая значение семафора. Если значение семафора опускается ниже нулевой отметки, выполняющий операцию процесс приостанавливает свою работу; · Операция типа V, увеличивающая значение семафора. Если значение семафора в результате операции становится больше или равно 0, один из процессов, приостановленных во время выполнения операции P, выходит из состояния приостанова; · Условная операция типа P, сокращенно CP (conditional P), уменьшающая значение семафора и возвращающая логическое значение " истина" в том случае, когда значение семафора остается положительным. Если в результате операции значение семафора должно стать отрицательным или нулевым, никаких действий над ним не производится и операция возвращает логическое значение " ложь".
Определенные таким образом семафоры, безусловно, никак не связаны с семафорами пользовательского уровня.
Реализация семафоров Дийкстра показал, что семафоры можно реализовать без использования специальных машинных инструкций. Здесь представлены реализующие семафоры функции, написанные на языке Си.
struct semaphore { int val[NUMPROCS]; /* замок - 1 элемент на каждый процессор */ int lastid; /* идентификатор процессора, получившего семафор последним */
}; int procid; /* уникальный идентификатор процессора */ int lastid; /* идентификатор процессора, получившего семафор последним */
Init(semaphore) struct semaphore semaphore; { int i; for (i = 0; i < NUMPROCS; i++) semaphore.val[i] = 0; }
Pprim(semaphore) struct semaphore semaphore; { int i, first; loop: first = lastid; semaphore.val[procid] = 1; forloop: for (i = first; i < NUMPROCS; i++) { if (i == procid) { semaphore.val[i] = 2; for (i = 1; i < NUMPROCS; i++) if (i! = procid & & semaphore.val[i] == 2) goto loop; lastid = procid; return; /* успешное завершение, ресурс можно использовать */ } else if (semaphore.val[i]) goto loop; } first = 1; goto forloop; }
Vprim(semaphore) struct semaphore semaphore; { lastid = (procid + 1) % NUMPROCS; /* на следующий процессор */ semaphore.val[procid] = 0; }
Функция Pprim блокирует семафор по результатам проверки значений, содержащихся в массиве val; каждый процессор в системе управляет значением одного элемента массива. Прежде чем заблокировать семафор, процессор проверяет, не заблокирован ли уже семафор другими процессорами (соответствующие им элементы в массиве val тогда имеют значения, равные 2), а также не предпринимаются ли попытки в данный момент заблокировать семафор со стороны процессоров с более низким кодом идентификации (соответствующие им элементы имеют значения, равные 1). Если любое из условий выполняется, процессор переустанавливает значение своего элемента в 1 и повторяет попытку. Когда функция Pprim открывает внешний цикл, переменная цикла имеет значение, на единицу превышающее код идентификации того процессора, который использовал ресурс последним, тем самым гарантируется, что ни один из процессоров не может монопольно завладеть. Функция Vprim освобождает семафор и открывает для других процессоров возможность получения исключительного доступа к ресурсу путем очистки соответствующего текущему процессору элемента в массиве val и перенастройки значения lastid. Чтобы защитить ресурс, следует выполнить следующий набор команд:
Pprim(семафор); команды использования ресурса; Vprim(семафор);
В большинстве машин имеется набор элементарных (неделимых) инструкций, реализующих операцию блокирования более дешевыми средствами, ибо циклы, входящие в функцию Pprim, работают медленно и снижают производительность системы. Так, например, в машинах серии IBM 370 поддерживается инструкция compare and swap (сравнить и переставить), в машине AT& T 3B20 - инструкция read and clear (прочитать и очистить). При выполнении инструкции read and clear процессор считывает содержимое ячейки памяти, очищает ее (сбрасывает в 0) и по результатам сравнения первоначального содержимого с 0 устанавливает код завершения инструкции. Если ту же инструкцию над той же ячейкой параллельно выполняет еще один процессор, один из двух процессоров прочитает первоначальное содержимое, а другой - 0: неделимость операции гарантируется аппаратным путем. Таким образом, за счет использования данной инструкции функцию Pprim можно было бы реализовать менее сложными средствами:
struct semaphore { int lock; };
Init(semaphore) struct semaphore semaphore; { semaphore.lock = 1; }
Pprim(semaphore) struct semaphore semaphore; { while (read_and_clear(semaphore.lock)); }
Vprim(semaphore) struct semaphore semaphore; { semaphore.lock = 1; }
Процесс повторяет инструкцию read and clear в цикле до тех пор, пока не будет считано значение, отличное от нуля. Начальное значение компоненты семафора, связанной с блокировкой, должно быть равно 1. Как таковую, данную семафорную конструкцию нельзя реализовать в составе ядра операционной системы, поскольку работающий с ней процесс не выходит из цикла, пока не достигнет своей цели. Если семафор используется для блокирования структуры данных, процесс, обнаружив семафор заблокированным, приостанавливает свое выполнение, чтобы ядро имело возможность переключиться на контекст другого процесса и выполнить другую полезную работу. С помощью функций Pprim и Vprim можно реализовать более сложный набор семафорных операций, соответствующий тому составу, который определен в разделе “Определение семафоров”. Для начала дадим определение семафора как структуры, состоящей из поля блокировки (управляющего доступом к семафору), значения семафора и очереди процессов, приостановленных по семафору. Поле блокировки содержит информацию, открывающую во время выполнения операций типа P и V доступ к другим полям структуры только одному процессу. По завершении операции значение поля сбрасывается. Это значение определяет, разрешен ли процессу доступ к критическому участку, защищаемому семафором.
Алгоритм операции P: /* Операция над семафором типа P входная информация: (1) семафор; (2) приоритет; выходная информация: 0 - в случае нормального завершения; 1 - в случае аварийного выхода из состояния приостанова по cигналу, принятому в режиме ядра; */ { Pprim(semaphore.lock); уменьшить (semaphore.value); если (semaphore.value > = 0) { Vprim(semaphore.lock); вернуть (0); } /* следует перейти в состояние приостанова */ если (проверяются сигналы) { если (имеется сигнал, прерывающий нахождение в состоянии приостанова)
увеличить (semaphore.value); если (сигнал принят в режиме ядра) { Vprim(semaphore.lock); вернуть (-1); } в противном случае { Vprim(semaphore.lock); longjmp; } } } поставить процесс в конец списка приостановленных по семафору; Vprim(semaphore.lock); выполнить переключение контекста; проверить сигналы (см. выше); вернуть (0); }
В начале выполнения алгоритма операции P ядро с помощью функции Pprim предоставляет процессу право исключительного доступа к семафору и уменьшает значение семафора. Если семафор имеет неотрицательное значение, текущий процесс получает доступ к критическому участку. По завершении работы процесс сбрасывает блокировку семафора (с помощью функции Vprim), открывая доступ к семафору для других процессов, и возвращает признак успешного завершения. Если же в результате уменьшения значение семафора становится отрицательным, ядро приостанавливает выполнение процесса, используя алгоритм, подобный алгоритму sleep: основываясь на значении приоритета, ядро проверяет поступившие сигналы, включает текущий процесс в список приостановленных процессов, в котором последние представлены в порядке поступления, и выполняет переключение контекста.
Алгоритм V /* Операция над семафором типа V входная информация: адрес семафора выходная информация: отсутствует */ { Pprim(semaphore.lock); увеличить (semaphore.value); если (semaphore.value < = 0) { удалить из списка процессов, приостановленных по семафору, первый по счету процесс; перевести его в состояние готовности к запуску; } Vprim(semaphore.lock); }
|
Последнее изменение этой страницы: 2020-02-17; Просмотров: 70; Нарушение авторского права страницы