
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Сортировка многофазным слиянием.
Рассмотренные выше методы сортировки простым и естественным слиянием достаточно просты, однако не эффективны, так как сортировка выполняется за значительное число проходов. Например, при сортировке М записей простым слиянием требуется: К -проходов.
Естественный путь повышения эффективности сортировки заключается в предварительной внутренней сортировке записей, формирование из них серий возможно большей длинны и распределение этих серий по нескольким файлам. При Р-путевом сбалансированным слияний число проходов
Где R-начальное число серий. Поскольку на каждом проходе обрабатывается N записей, то эффективность всего процесса сортировки будет пропорциональна
А с учётом внутренней сортировки
Из этой формулы виден второй путь повышения эффективности сортировки, а именно увеличивать число файлов P. Однако при сбалансированном многофазном слиянии одновременно используются лишь чуть больше половины имеющихся файлов, а остальные простаивают. Возникает вопрос, можно ли ещё лучше использовать имеющиеся файлы? Да, это возможно, если распределить начальные серии не поровну между всеми файлами, а более хитрым способом, так чтобы на каждой фазе слияния, кроме самой последней, только один файл оказывался пустым. Такой метод называется многофазным слиянием. Вернёмся к предыдущему примеру сортировки 1700 записей, предварительно отсортированных в серии по 100 записей. Однако на первом этапе распределим эти серии на 3 файла следующим образом: в файл 1-7 серий, в файл 2-6 серий, в файл 3-4 серии. Далее будем сливать эти серии в файл 4. В результате в файле 4 мы получим 4 серии длиною 300 записей, в файле 1 останется 3 серии, в файле 2 будет 2 серии, а файл 3 станет пустой. Далее сливаем серии в файл 3 и так далее, пока не получим отсортированный файл, состоящий из одной серии длиною 1700 записей. Процесс сортировки показан на рисунке.
7(100) 6(100) 4(100)
1(100) 2(500) 2(300)
1(1700) Рисунок. Сортировка 1700 записей с использованием 4 файлов методом многофазного слияния.
Например, для 4 файлов имели следующую последовательность Фибоначчи 2-го порядка 0, 0, 1, 1, 2, 4, 7, 13, 24, 44, 81.
Возможные начальные распределения серий показаны в таблице.
Таблица. Начальное распределение серий для 4 лент.
Из сказанного выше следует, что алгоритм многофазного слияния применим только к таким входным данным, в которых число начальных серий имеет волне определённое значение. А что же делать, если число начальных серий отличается от требуемого? В этом случае поступают следующим образом: вводится соответствующее число фиктивных пустых серий, так, чтобы сумма реальных и фиктивных серий давала нужное значение. Однако возникает сразу следующий вопрос: как распределить фиктивные серии между файлами? Давайте посмотрим, как сливаются реальные и фиктивные серии. Понятно, что выбор фиктивной серии с i-ый файла означает, что i-ый файл не участвует в слиянии; в результате слияние происходит с менее чем N-1 файлами. Слияние фиктивных серий со всех N-1 входных файлов не предполагает никакой действительной операции слияния, а означает просто запись фиктивных серий на входной файл. Из этого можно сделать вывод, что фиктивные серии нужно распределить на N-1 файлов как можно более равномерно, так как мы заинтересованы в слиянии с возможно большего числа файлов. Можно также показать, что фиктивные серии лучше располагать в начале файлов. Пример программы Сортировка многофазным слиянием: Программа использует уже готовый файл содержащий не отсортированные данные и не распечатывает отсортированный файл (программа только сортирует файл file0). program Многофазное слияние; uses crt; const n=10; type item=record key: integer; {описания других полей} end; filetype=file of item; var f0, f1, f2, f3, a, b, c, d: filetype; ser0, ser1, ser2, ser3, kolser, disk0, disk1, disk2, disk3, z, l, all, zero0, zero1, zero2, zero3: integer; eora, eorb, eorc, per, eor: boolean; mas: array[1..n]of integer; data: item; procedure fibonachi; procedure fib; begin disk0: =disk1+disk2+disk3; while disk0< kolser do begin disk3: =disk2; disk2: =disk1; disk1: =disk0; disk0: =disk1+disk2+disk3; end; end; begin disk1: =1; disk2: =1; disk3: =1; fib; kolser: =disk0; disk1: =0; disk2: =0; disk3: =1; fib; disk1: =disk2; disk2: =kolser-(disk1+disk3); end; procedure readfile; begin l: =0; while not eof(f0)and not(l=n) do begin l: =l+1; read(f0, data); mas[l]: =data.key; end; all: =l; end; procedure massort; var buf, units: integer; m: boolean; begin units: =all; repeat m: =true;; units: =units-1; for l: =1 to units do begin if mas[l]> mas[l+1] then begin buf: =mas[l]; mas[l]: =mas[l+1]; mas[l+1]: =buf; m: =false; end; end; until m or (units=1); end; procedure sort(var x: filetype); begin readfile; massort; for l: =1 to all do begin data.key: =mas[l]; write(x, data); end; end; procedure sortrun; begin reset(f0); rewrite(f1); rewrite(f2); rewrite(f3); kolser: =1; zero0: =0; zero1: =0; zero2: =0; zero3: =0; ser0: =0; ser1: =0; ser2: =0; ser3: =0; repeat fibonachi; if disk1< > ser1 then begin if not eof(f0) then sort(f1) else zero1: =zero1+1; ser1: =ser1+1; end; if disk2< > ser2 then begin if not eof(f0) then sort(f2) else zero2: =zero2+1; ser2: =ser2+1; end; if disk3< > ser3 then begin if not eof(f0) then sort(f3) else zero3: =zero3+1; ser3: =ser3+1; end; if (not eof(f0))and(kolser=(ser1+ser2+ser3)) then kolser: =kolser+1; until eof(f0)and(kolser=(ser1+ser2+ser3)); close(f0); close(f1); close(f2); close(f3); end; procedure copy(var x, y: filetype); var buf, buf1: item; begin read(x, buf); write(y, buf); if eof(x) then eor: =true else begin {заглядываем вперед} read(x, buf1); {возвращаемся на исходную запись} seek(x, filepos(x)-1); eor: =buf1.key< buf.key end; end; procedure mergerun(var d, a, b, c: filetype; var serd, sera, serb, serc, zerod, zeroa, zerob, zeroc: integer); {слияние серий из А и В и С в D} var bufa, bufb, bufc: item; zapis: boolean; begin repeat eora: =true; eorb: =true; eorc: =true; serd: =serd+1; sera: =sera-1; serb: =serb-1; serc: =serc-1; if zeroa< > 0 then begin eora: =false; zeroa: =zeroa-1; end; if zerob< > 0 then begin eorb: =false; zerob: =zerob-1; end; if zeroc< > 0 then begin eorc: =false; zeroc: =zeroc-1; end; if (not eora)and(not eorb)and(not eorc) then zerod: =zerod+1; while (eora or eorb or eorc) do begin bufa.key: =1999; bufb.key: =1999; bufc.key: =1999; if eora then begin read(a, bufa); seek(a, filepos(a)-1); end; if eorb then begin read(b, bufb); seek(b, filepos(b)-1); end; if eorc then begin read(c, bufc); seek(c, filepos(c)-1); end; if bufa.key< bufb.key then if bufa.key< bufc.key then begin copy(a, d); if eor then eora: =false; end else begin copy(c, d); if eor then eorc: =false; end else if bufb.key< bufc.key then begin copy(b, d); if eor then eorb: =false; end else begin copy(c, d); if eor then eorc: =false; end; end; until (sera=0)or(serb=0)or(serc=0); end; procedure merge; begin reset(f0); reset(f1); reset(f2); reset(f3); while (ser0+ser1+ser2+ser3)< > 1 do begin if (ser0=0) then begin rewrite(f0); mergerun(f0, f1, f2, f3, ser0, ser1, ser2, ser3, zero0, zero1, zero2, zero3); reset(f0); end; if (ser1=0)and((ser0+ser1+ser2+ser3)< > 1) then begin rewrite(f1); mergerun(f1, f2, f3, f0, ser1, ser2, ser3, ser0, zero1, zero2, zero3, zero0); reset(f1); end; if (ser2=0)and((ser0+ser1+ser2+ser3)< > 1) then begin rewrite(f2); mergerun(f2, f3, f0, f1, ser2, ser3, ser0, ser1, zero2, zero3, zero0, zero1); reset(f2); end; if (ser3=0)and((ser0+ser1+ser2+ser3)< > 1) then begin rewrite(f3); mergerun(f3, f0, f1, f2, ser3, ser0, ser1, ser2, zero3, zero0, zero1, zero2); reset(f3); end; end; close(f0); close(f1); close(f2); close(f3); end; begin clrscr; assign(f0, 'c: \tp\file0'); assign(f1, 'c: \tp\file1'); assign(f2, 'c: \tp\file2'); assign(f3, 'c: \tp\file3'); sortrun; merge; end. Результат работы:
Файл в котором будут отсортированные данные в зависимости от количества данных будут будет меняться(file0 или file1 или file2 или file3). Итак, мы рассмотрели основные методы внешней сортировки.
Мы приходим к довольно сложным алгоритмам сортировки файлов, поскольку более простые методы внутренней сортировки требуют достаточно большой оперативной памяти, чтобы хранить все сортируемые данные. Внутренняя сортировка, как мы видим, используется на этапе распределения начальных серий так, чтобы в результате эти серии имели как можно большую длину. Очевидно, что на последних проходах никакой внутренней сортировки не дадут какого-либо улучшения, так как длинна участвующих в них серий постоянно растёт и, следовательно, всегда будет больше имеющейся оперативной памяти. Поэтому следует сосредоточить внимание на оптимизацию алгоритма, который формирует начальные серии. Наиболее подходящим является логарифмические методы сортировки массивов и среди них сортировка с помощью дерева или пирамидальная сортировка.
Программа, представляющая собой комбинацию многофазной и пирамидальной сортировки достаточно сложна, хотя, по существу, она выполняет туже самую легко определимую задачу переупорядочения множества элементов, что и любая из коротких программ простых методов сортировки массивов. Из всего сказанного можно следующий выводы:
1.Между алгоритмом и структурой данных существует тесная связь: структура данных оказывает большое влияние на вид программы.
2.При помощи усложнения программы можно значительно повысить её эффективность, даже когда структура данных, с которой она работает, плохо соответствует поставленной задаче. Лабораторная работа №12. Сортировка файлов. Цель работы: 1. Ознакомление с возможностями сортировки файлов на внешних носителях в ЭВМ. 2. Получение навыков работы с внешними файлами. Постановка задачи: Подготовить данные об абитуриентах, поступающих в институт. Информацию о каждом абитуриенте оформить в виде записи, содержащей следующие поля: 1. ФИО. 2. Год рождения. 3. Год окончания школы. 4. Оценки в аттестате. 5. Признак - нуждается ли в общежитии. 6. Оценки вступительных экзаменов. Разработать программу сортировки подготовленных данных во внешнем файле, методом заданном в варианте, и распечатать записи в файле. Содержание отчёта: 1. Постановка задачи. 2. Анкетные данные абитуриентов. 3. Тексты программ. 4. Распечатка результатов выполнения программы. Методические указания. При подготовке исходных данных необходимо учесть, что выходная информация программы обработки внешнего файла должна составлять не менее одной четверти от входной. Образец выполнения задания. Лабораторная работа №12. Сортировка файлов. Постановка задачи: Подготовить данные об абитуриентах, поступающих в институт. Информацию о каждом абитуриенте оформить в виде записи, содержащей следующие поля: 1. ФИО. 2. Год рождения. 3. Год окончания школы. 4. Оценки в аттестате. 5. Признак - нуждается ли в общежитии. 6. Оценки вступительных экзаменов. Разработать программу сортировки подготовленных данных во внешнем файле по фамилии, методом сортировки естественным слиянием, и распечатать фамилии и даты рождения и даты окончания школы, до сортировки и после. Методические указания. При подготовке исходных данных необходимо учесть, что выходная информация программы обработки внешнего файла должна составлять не менее одной четверти от входной. Популярное:
|
Последнее изменение этой страницы: 2016-03-15; Просмотров: 1859; Нарушение авторского права страницы

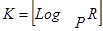









 3(100) 2(100) 4(300)
3(100) 2(100) 4(300)







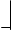


 1(900) 1(500) 1(300)
1(900) 1(500) 1(300)

