
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Формальные языки и грамматикиСтр 1 из 24Следующая ⇒
Содержание 1 Формальные языки и грамматики..................................................................... 1.1 Операции над цепочками символов............................................................... 1.2 Способы задания языков................................................................................ 1.2.1 Определение языков посредством множеств.............................................. 1.2.2 Формы Бэкуса-Наура................................................................................... 1.2.3 Диаграммы Вирта........................................................................................ 1.2.4 Формальные грамматики............................................................................. 1.2.4.1 Определение формальной грамматики.................................................... 1.2.4.2 Классификация языков и грамматик........................................................ 1.2.4.3 Эквивалентность грамматик..................................................................... 1.2.5 Механизмы распознавания языков............................................................. 1.2.5.1 Определение распознавателя.................................................................... 1.2.5.2 Схема работы распознавателя................................................................. 1.2.5.3 Классификация распознавателей.............................................................. 2 Регулярные языки.............................................................................................. 2.1 Регулярные выражения................................................................................... 2.2 Лемма о разрастании для регулярных языков.............................................. 2.2 Конечные автоматы......................................................................................... 2.2.1 Определение конечного автомата............................................................... 2.2.2 Распознавание строк конечным автоматом................................................ 2.2.3 Преобразование конечных автоматов........................................................ 2.2.3.1 Преобразование конечного автомата к детерминированному виду...... 2.2.3.2 Минимизация конечного автомата........................................................... 2.2.3.2.1 Устранение недостижимых состояний автомата................................... 2.2.3.2.2 Объединение эквивалентных состояний автомата................................ 2.4 Взаимосвязь способов определения регулярных языков............................. 2.4.1 Построение конечного автомата по регулярной грамматике.................... 2.4.2 Построение регулярной грамматики по конечному автомату................. 3 Контекстно-свободные языки............................................................................ 3.1 Задача разбора................................................................................................ 3.1.1 Вывод цепочек.............................................................................................. 3.1.2 Дерево разбора............................................................................................ 3.1.2.1 Нисходящее дерево разбора.................................................................... 3.1.2.2 Восходящее дерево разбора..................................................................... 3.1.3 Однозначность грамматик........................................................................... 3.2 Преобразование КС-грамматик.................................................................... 3.2.1 Проверка существования языка.................................................................. 3.2.2 Устранение недостижимых символов.......................................................... 3.2.3 Устранение e-правил.................................................................................... 3.2.4 Устранение цепных правил.......................................................................... 3.2.5 Левая факторизация правил........................................................................ 3.2.6 Устранение прямой левой рекурсии........................................................... 3.3 Автомат с магазинной памятью...................................................................... 3.3.1 Определение МП-автомата.......................................................................... 3.3.2 Разновидности МП-автоматов..................................................................... 3.3.3 Взаимосвязь МП-автоматов и КС-грамматик............................................ 3.3.3.1 Построение МП-автомата по КС-грамматике......................................... 3.3.3.2 Построение расширенного МП-автомата по КС-грамматике................ 3.4 Нисходящие распознаватели языков............................................................. 3.4.1 Рекурсивный спуск....................................................................................... 3.4.1.1 Сущность метода....................................................................................... 3.4.1.2 Достаточные условия применимости метода........................................... 3.4.2 Распознаватели LL(k)-грамматик................................................................ 3.4.2.1 Определение LL(k)-грамматики................................................................ 3.4.2.2 Необходимое и достаточное условие LL(1)-грамматики........................ 3.4.2.3 Построение множеств FIRST(1, A)........................................................... 3.4.2.4 Построение множеств FOLLOW(1, A)...................................................... 3.4.2.5 Алгоритм «сдвиг-свертка» для LL(1)-грамматик.................................... 3.5 Восходящие распознаватели языков.............................................................. 3.5.1 Грамматики предшествования..................................................................... 3.5.1.1 Грамматики просторного предшествования........................................... 3.5.1.1.1 Определение грамматики простого предшествования......................... 3.5.1.1.2 Поиск основы сентенции........................................................................ 3.5.1.1.3 Построение множеств L(A) и R(A)........................................................ 3.5.1.1.4 Матрица предшествования.................................................................... 3.5.1.1.5 Алгоритм «сдвиг-свертка» для грамматик простого предшествования 3.5.1.2 Грамматики операторного предшествования.......................................... 3.5.1.2.1 Определение грамматики операторного предшествования................. 3.5.1.2.2 Построение множеств Lt(A) и Rt(A)....................................................... 3.5.1.2.3 Матрица операторного предшествования............................................ 3.5.1.2.4 Алгоритм «сдвиг-свертка» для грамматик простого предшествования 3.5.2 Распознаватели LR(k)-грамматик................................................................ 3.6 Соотношение классов КС-грамматик............................................................. 4 Принципы построения трансляторов................................................................ 4.1 Лексика, синтаксис и семантика языка........................................................... 4.2 Определение транслятора, компилятора, интерпретатора и ассемблера.... 4.3 Общая схема работы транслятора................................................................. 4.5 Лексический анализ......................................................................................... 4.5.1 Задачи лексического анализа...................................................................... 4.5.2 Диаграмма состояний с действиями............................................................ 4.5.3 Функция scanner........................................................................................... 4.6 Синтаксический анализ.................................................................................. 4.6.1 Задачи синтаксического анализа................................................................. 4.6.2 Нисходящий синтаксический анализ........................................................... 4.7 Семантический анализ.................................................................................... 4.8 Генерация кода................................................................................................ 4.8.1 Формы внутреннего представления программы........................................ 4.8.1.1 Тетрады..................................................................................................... 4.8.1.2 Триады....................................................................................................... 4.8.1.3 Синтаксические деревья............................................................................ 4.8.1.4 Польская инверсная запись...................................................................... 4.8.1.5 Ассемблерный код и машинные команды............................................... 4.8.2 Преобразование дерева операций в код на языке ассемблера.................. 4.9 Оптимизация кода........................................................................................... 4.9.1 Сущность оптимизации кода....................................................................... 4.9.2 Критерии эффективности результирующей объектной программы......... 4.9.3 Методы оптимизации кода.......................................................................... 4.9.4 Оптимизация линейных участков программ.............................................. 4.9.4.1 Свертка объектного кода.......................................................................... 4.9.4.2 Исключение лишних операций................................................................. 4.9.5 Оптимизация циклов.................................................................................... 4.9.6 Оптимизация логических выражений......................................................... 4.9.7 Оптимизация вызовов процедур и функций............................................... 4.9.8 Машинно-зависимые методы оптимизации................................................ 5 Формальные методы описания перевода.......................................................... 5.1 Синтаксически управляемый перевод............................................................ 5.1.1 Схемы компиляции...................................................................................... 5.1.2 СУ-схемы...................................................................................................... 5.1.3 МП-преобразователи................................................................................... 5.1.4 Практическое применение СУ-схем............................................................ 5.2 Транслирующие грамматики......................................................................... 5.2.1 Понятие Т-грамматики................................................................................. 5.2.2 Т-грамматика с подпрограммами............................................................... 5.2.3 МП-преобразователь для Т-грамматики.................................................... 5.3 Атрибутные транслирующие грамматики..................................................... 5.3.1 Синтезируемые и наследуемые атрибуты................................................... 5.3.2 Определение и свойства АТ-грамматики.................................................... 5.3.3 ФормированиеАТ-грамматики................................................................... Формальные языки и грамматики Основные понятия теории формальных языков В основе каждого языка лежит алфавит. Определение Алфавитом V называется конечное множество символов. Определение Цепочкой a в алфавите V называется любая конечная последовательность символов этого алфавита. Определение Цепочка, которая не содержит ни одного символа, называется пустой цепочкой и обозначается e. Определение Формальное определение цепочки символов в алфавите V: 1) e - цепочка в алфавите V; 2) если a - цепочка в алфавите V и а – символ этого алфавита, то a а – цепочка в алфавите V; 3) b - цепочка в алфавите V тогда и только тогда, когда она является таковой в силу утверждений 1) и 2). Определение Длиной цепочки a называется число составляющих ее символов (обозначается |a|). Определение Конкатенацией (сцеплением) цепочек a и b называется цепочка g=ab, в которой символы данных цепочек записаны друг за другом. Для любой цепочки a справедливо утверждение ae=ea. Определение Степенью n цепочки a называется конкатенация n цепочек a. (обозначается an). Для любой цепочки a справедливы утверждения a0=e и an=an-1a=aan-1 для n³ 1. Определение Реверсом (обращением) цепочки a называется цепочка aR, составленная из символов цепочки a, записанных в обратном порядке. Пример Пусть алфавит V={a, b, c, d}, тогда для цепочек этого алфавита a=ab и b=bcd будет справедливо |a|=2, |b|=3, ab= abbcd, a2=abab, bR=dcb. Обозначим через V* множество, содержащее все цепочки в алфавите V, включая пустую цепочку e, а через V+ - множество, содержащее все цепочки в алфавите V, исключая пустую цепочку e. Определение Формальным языком L в алфавите V называют произвольное подмножество множества V*. Пример Пусть алфавит двоичных цифр Задать язык L в алфавите V можно тремя способами: 1) перечислением всех допустимых цепочек языка (на языке множеств); 2) указанием способа порождения (генерации) цепочек языка (грамматики, формы Бэкуса-Наура и диаграммы Вирта; 3) определением метода распознавания цепочек языка (распознаватели). Пример Язык L в алфавите
1.2 Способы задания языков Формальные грамматики Рисунок 1.1 – Соотношение типов формальных языков и грамматик
Тип 3. Грамматика Грамматика Определение Язык L(G) называется языком типа k, если его можно описать грамматикой типа k, где k – максимально возможный номер типа грамматики. Пример Примеры различных типов формальных языков и грамматик по классификации Хомского. Терминалы будем обозначать строчными символами, нетерминалы – прописными буквами, начальный символ грамматики – S. а) Язык типа 0 L(G)= 1) S ® aaCFD; 2) AD ® D; 3) F ® AFB | AB; 4) Cb ® bC; 5) AB ® bBA; 6) CB ® C; 7) Ab ® bA; 8) bCD ® e.
б) Контекстно-зависимый язык L(G)={anbncn | n³ 1} определяется грамматикой с правилами вывода: 1) S ® aSBC | abc ; 2) bC ® bc; 3) CB ® BC; 4) cC ® cc; 5) BB ® bb.
в) Контекстно-свободный язык L(G)={(ab)n(cb)n | n> 0 } определяется грамматикой с правилами вывода: 1) S ® aQb | accb; 2) Q ® cSc.
г) Регулярный язык L(G)={w^ | wÎ {a, b}+, где нет двух рядом стоящих а} определяется грамматикой с правилами вывода: 1) S ® A^ | B^; 2) A ® a | Ba; 3) B ® b | Bb | Ab.
Эквивалентность грамматик
Определение Грамматики G1 и G2 называются эквивалентными, если они определяют один и тот же язык, т.е. Определение Грамматики G1 и G2 называются почти эквивалентными, если заданные ими языки различаются не более чем на пустую цепочку символов т.е. Пример Для грамматики G1 эквивалентной будет грамматика G2 = ({0, 1}, {S}, P2, S), где множество правил вывода P2 содержит правила вида S ® 0S1| e. Почти эквивалентной для грамматики G1 будет грамматика G3 = ({0, 1}, {S}, P3, S), где множество правил вывода P3 содержит правила вида S ® 0S1|01.
Формы Бэкуса - Наура Цепочки языка могут содержать метасимволы, имеющие особое назначение. Метаязык, предложенный Бэкусом и Науром (БНФ) использует следующие обозначения: - символ «:: =» отделяет левую часть правила от правой (читается: «определяется как»); - нетерминалы обозначаются произвольной символьной строкой, заключенной в угловые скобки «< » и «> »; - терминалы - это символы, используемые в описываемом языке; - правило может определять порождение нескольких альтернативных цепочек, отделяемых друг от друга символом вертикальной черты «|» (читается: «или». Для повышения удобства и компактности описаний, в расширенных БНФ вводятся следующие дополнительные конструкции (метасимволы): - квадратные скобки «[» и «]» означают, что заключенная в них синтаксическая конструкция может отсутствовать; - фигурные скобки «{» и «}» означают повторение заключенной в них синтаксической конструкции ноль или более раз; - сочетание фигурных скобок и косой черты «{/» и «/}» используется для обозначения повторения один и более раз; - круглые скобки «(» и «)» используются для ограничения альтернативных конструкций; - кавычки используются в тех случаях, когда один из метасимволов нужно включить в цепочку обычным образом. Пример Правила, определяющие понятие «идентификатор» некоторого языка программирования, будут выглядеть следующим образом:
< буква> :: = a | b | c | d | e | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z < цифра> :: = 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 < идентификатор> :: = < буква> { (< буква> | < цифра> ) }
Диаграммы Вирта
В метаязыке диаграмм Вирта используются графические примитивы, представленные на рисунке 1.4.1. При построении диаграмм учитывают следующие правила: - каждый графический элемент, соответствующий терминалу или нетерминалу, имеет по одному входу и выходу, которые обычно изображаются на противоположных сторонах; - каждому правилу соответствует своя графическая диаграмма, на которой терминалы и нетерминалы соединяются посредством дуг; - альтернативы в правилах задаются ветвлением дуг, а итерации - их слиянием; - должна быть одна входная дуга (располагается обычно слева или сверху), задающая начало правила и помеченная именем определяемого нетерминала, и одна выходная, задающая его конец (обычно располагается справа и снизу); - стрелки на дугах диаграмм обычно не ставятся, а направления связей отслеживаются движением от начальной дуги в соответствии с плавными изгибами промежуточных дуг и ветвлений.
Пример 1.4.1. Правила, определяющие понятие «идентификатор» некоторого языка программирования, показаны на рисунке 1.3. Цифра
Буква
Идентификатор
Рисунок 1.3 – Диаграмма Вирта понятия «идентификатор»
Определение распознавателя Обратной к задаче генерации строк языка является задача проверки принадлежности исходной строки заданному языку. Для решения этой проблемы создается механизм распознавания, или распознаватель. Определение Распознаватель – это специальный алгоритм, который позволяет определить принадлежность цепочки символов некоторому языку. Распознаватель схематично можно представить в виде совокупности входной ленты, управляющего устройства и вспомогательной памяти (рисунок 1.4). Схема работы распознавателя Входная лента представляет собой последовательность ячеек, каждая из которых содержит один символ некоторого конечного алфавита. Входная головка в каждый момент обозревает одну ячейку. За один шаг работы распознавателя головка сдвигается на одну ячейку влево (вправо) или остается неподвижной. Распознаватель, не перемещающий входную головку влево, называется односторонним. Управляющее устройство – это программа управления распознавателем. Она задает конечное множество состояний распознавателя и определяет переходы из состояния в состояние в зависимости от прочитанного символа входной ленты и содержимого вспомогательной памяти. Вспомогательная память служит для хранения информации, которая зависит от состояния распознавателя. У некоторых типов распознавателей она может отсутствовать.
а1 а2 … аn Входная лента
Рисунок 1.4 – Схема распознавателя Поведение распознавателя можно представить с помощью его конфигураций. Определение Конфигурация распознавателя есть совокупность следующих элементов: - состояние управляющего устройства; - содержимое входной ленты и положение входной головки; - содержимое вспомогательной памяти. Определение Управляющее устройство называется детерминированным, если для каждой конфигурации распознавателя существует не более одного возможного следующего шага, в противном случае управляющее устройство называется недетерминированным. Определение Конфигурация распознавателя называется начальной, если управляющее устройство находится в заданном начальном состоянии, входная головка обозревает самый левый символ на входной ленте и вспомогательная память имеет заранее установленное начальное состояние. Определение Конфигурация распознавателя называется заключительной, если управляющее устройство находится в одном из заранее выделенных заключительных состояний, а входная головка сошла с правого конца входной ленты. Содержимое вспомогательной памяти удовлетворяет некоторому установленному условию. Определение Входная строка w допускается распознавателем, если от начальной конфигурации, в которой цепочка w записана на входной ленте, распознаватель может выполнить последовательность шагов, заканчивающуюся заключительной конфигурацией. Определение Множество всех строк, допускаемых распознавателем, называется языком распознавателя. Регулярные выражения
Регулярный язык L в некотором алфавите V представляет собой регулярное множество строк. Определение Регулярное множество есть Æ, либо {e}, либо {а} для некоторого а Î V, либо множество, которое можно получить из указанных множеств путем применения конечного числа операций сцепления, объединения и итерации. В основе метода определения регулярности заданного языка лежит лемма о разрастании языка.
Лемма о разрастании языка
В достаточно длинной строке регулярного языка всегда можно найти непустую подстроку, повторение которой произвольное количество раз порождает новые строки того же самого языка. Пример Язык L1 = {ambn | m, n ³ 0} – регулярный, т.к., например, в строке aabbb повторение любой подстроки, образованной только из нулей или единиц, порождает строки (aaaabbb, aaabbb, aabbbb, aabbbbbb и т.д.) языка L1. Язык L2 = {anbn | n ³ 1} – не регулярный, т.к. Действительно, любая итерация подстроки, состоящей только из нулей или единиц, нарушает баланс нулей и единиц. Подобные действия со смешанными подстроками, содержащими нули и единицы, приводят к нарушению порядка следования нулей и единиц. Таким образом, для языка L2 не строк, удовлетворяющих условиям леммы. Удобным средством формального определения регулярных языков являются регулярные выражения. Определение Регулярные выражения над алфавитом S определяются следующим образом: 1) Æ - регулярное выражение (обозначает пустоте регулярное множество Æ ); 2) e - регулярное выражение (обозначает регулярное множество {e}, состоящее из пустой строки); 3) а Î S - регулярное выражение (обозначает множество {а}); 4) если p и q – регулярные выражения, обозначающие множества P и Q, то посредством операций над выражениями определяются выражения следующих трех типов: а) p|q или p+q – регулярное выражение (обозначает объединение PÈ Q), где символ | или + называют операцией или (альтернативы); б) pq или p× q – регулярное выражение (обозначает множество PQ = {xy | x Î P, y Î Q}), где символ «точка» (возможно умалчиваемый) называют операцией сцепления (конкатенации); в) p* - регулярное выражение (обозначает множество P*), где символ «*» называют операцией итерации. Соотношение между регулярными языками и регулярными выражениями устанавливает теорема Клини.
Теорема Клини. Каждому регулярному языку из S* соответствует регулярное выражение над множеством S.
Пример Примеры регулярных выражений и их значений представлены в таблице 2.1.
Таблица 2.1 – Примеры регулярных выражений
В практических приложениях вводятся дополнительные соглашения относительно записи регулярных выражений, например, запись вида р+ используется для обозначения выражения рр*.
Конечные автоматы Задача разбора Вывод цепочек Выводом называется процесс порождения предложения языка на основе правил определяющей язык грамматике. Чтобы дать формальное определение процессу вывода, необходимо ввести еще несколько дополнительных понятий. Определение Цепочка b Î (VTÈ VN)* непосредственно выводима из цепочки Определение Цепочка b Î (VTÈ VN)* выводима из цепочки Такая последовательность непосредственно выводимых цепочек называется выводом или цепочкой вывода. Вывод называется правосторонним (левосторонним), если в нем на каждом шаге вывода правило грамматики применяется всегда к крайнему правому (левому) нетерминальному символу в цепочке. Вывод можно рассматривать также как процесс получения одной строки из другой. С понятием вывода тесно связано понятие разбора строки языка. С одной стороны, разбор— это задача выяснения принадлежности заданной строки языку, порождаемому заданной грамматикой. С другой стороны, разбор — это последовательность правил грамматики, определенным образом соответствующая выводу. Пример Грамматика G1=({0, 1}, {A, S}, P1, S), где множество Р состоит из правил вида: 1) S® 0A1; 2)0A® 00A1; 3) A®e. В грамматике G1 SÞ *000111, т.к. существует вывод Дерево разбора Графическим способом отображения процесса разбора цепочек является дерево разбора (или дерево вывода). Определение дерево разбора грамматики - каждая вершина дерева обозначается символом грамматики - корнем дерева является вершина, обозначенная начальным символом грамматики S; - листьями дерева (концевыми вершинами) являются вершины, обозначенные терминальными символами грамматики или символом пустой строки e; - если некоторый узел дерева обозначен символом Дерево разбора можно построить двумя способами: сверху вниз и снизу вверх.
Нисходящее дерево разбора При построении дерева вывода сверху вниз построение начинается с целевого символа грамматики, который помещается в корень дерева. Затем в грамматике выбирается необходимое правило, и на первом шаге вывода корневой символ раскрывается на несколько символов первого уровня. На втором шаге среди всех концевых вершин дерева выбирается крайняя (крайняя левая — для левостороннего вывода, крайняя правая — для правостороннего) вершина, обозначенная нетерминальным символом, для этой вершины выбирается нужное правило грамматики, и она раскрывается на несколько вершин следующего уровня. Построение дерева заканчивается, когда все концевые вершины обозначены терминальными символами, в противном случае надо вернуться ко второму шагу и продолжить построение. Восходящее дерево разбора Построение дерева вывода снизу вверх начинается с листьев дерева. В качестве листьев выбираются терминальные символы конечной цепочки вывода, которые на первом шаге построения образуют последний уровень (слой) дерева. Построение дерева идет по слоям. На втором шаге построения в грамматике выбирается правило, правая часть которого соответствует крайним символам в слое дерева (крайним правым символам при правостороннем выводе и крайним левым — при левостороннем). Выбранные вершины слоя соединяются с новой вершиной, которая выбирается из левой части правила. Новая вершина попадает в слой де рева вместо выбранных вершин. Построение дерева закончено, если достигнута корневая вершина (обозначенная целевым символом), а иначе надо вернуться ко второму шагу и повторить его над полученным слоем дерева. Поскольку все известные языки программирования имеют нотацию записи «слева — направо», компилятор также всегда читает входную программу слева направо (и сверху вниз, если программа разбита на несколько строк). Поэтому для построения дерева вывода методом «сверху вниз», как правило, используется левосторонний вывод, а для построения «снизу вверх» — правосторонний вывод. На эту особенность компиляторов стоит обратить внимание. Нотация чтения программ «слева направо» влияет не только на порядок разбора программы компилятором (для пользователя это, как правило, не имеет значения), но и ни порядок выполнения операций — при отсутствии скобок большинство равноправных операций выполняются в порядке слева направо, а это уже имеет существенное значение.
Однозначность грамматик
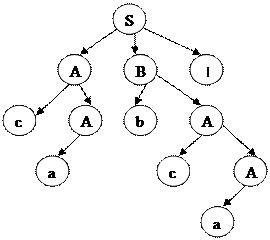
Грамматика называется однозначной, если для каждой цепочки символов языка, заданного этой грамматикой, можно построить единственный левосторонний (и единственный правосторонний) вывод. Или, что то же самое: грамматика называется однозначной, если для каждой цепочки символов языка, заданного этой грамматикой, существует единственное дерево вывода. В противном случае грамматика называется неоднозначной. 3.2 Преобразование КС-грамматик Определение КС-грамматика называется приведенной, если она не имеет циклов, e-правил и бесполезных символов. Рассмотрим основные алгоритмы приведения КС-грамматик. Перед всеми другими исследованиями и преобразованиями КС-грамматик выполняется проверка существования языка грамматики. Устранение e-правил Устранение цепных правил Левая факторизация правил Рекурсивный спуск Сущность метода В основе метода рекурсивного спуска лежит левосторонний разбор строки языка. Исходной сентенциальной формой является начальный символ грамматики, а целевой – заданная строка языка. На каждом шаге разбора правило грамматики применяется к самому левому нетерминалу сентенции. Данный процесс соответствует построению дерева разбора цепочки сверху вниз (от корня к листьям). Пример Дана грамматика Левосторонний вывод цепочки имеет вид:
Нисходящее дерево разбора цепочки представлено на рисунке 3.2.
Рисунок 3.2 – Дерево нисходящего разбора цепочки cabca^
Метод рекурсивного спуска реализует разбор цепочки сверху вниз следующим образом. Для каждого нетерминального символа грамматики создается своя процедура, носящая его имя. Задача этой процедуры – начиная с указанного места исходной цепочки, найти подцепочку, которая выводится из этого нетерминала. Если такую подцепочку считать не удается, то процедура завершает свою работу вызовом процедуры обработки ошибок, которая выдает сообщение о том, что цепочка не принадлежит языку грамматики и останавливает разбор. Если подцепочку удалось найти, то работа процедуры считается нормально завершенной и осуществляется возврат в точку вызова. Тело каждой такой процедуры составляется непосредственно по правилам вывода соответствующего нетерминала, при этом терминалы распознаются самой процедурой, а нетерминалам соответствуют вызовы процедур, носящих их имена. Пример Построим синтаксический анализатор методом рекурсивного спуска для грамматики Введем следующие обозначения: 1) СH – текущий символ исходной строки; 2) gc – процедура считывания очередного символа исходной строки в переменную СH; 3) Err - процедура обработки ошибок, возвращающая по коду соответствующее сообщение об ошибке. С учетом введенных обозначений, процедуры синтаксического разбора будут иметь вид.
procedure S; begin A; B; if CH< > ¢ ^¢ then ERR end; procedure A; begin if CH=¢ a¢ then gc else if CH=¢ c¢ then begin gc; A end else Err end; procedure B; begin if CH= ¢ b¢ then begin gc; B end else Err end; Грамматики предшествования Таблица 3.8 – Матрица предшествования символов грамматики
Шаг 3. Функционирование распознавателя для цепочки (((aa)a)a) показано в таблице 3.9.
Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 1759; Нарушение авторского права страницы
 , тогда
, тогда 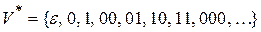 , а
, а  .
.
 называется регулярной грамматикой (Р-грамматикой) выровненной вправо, если ее правила вывода имеют вид
называется регулярной грамматикой (Р-грамматикой) выровненной вправо, если ее правила вывода имеют вид  , где
, где  .
. , где
, где  определяется грамматикой с правилами вывода:
определяется грамматикой с правилами вывода:  .
. .
.




 в грамматике
в грамматике 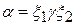 и
и  , где
, где  ,
,  и правило вывода
и правило вывода 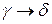 содержится во множестве Р.
содержится во множестве Р. (n³ 0) такая, что
(n³ 0) такая, что  .
.  .
. называется дерево, которое соответствует некоторой цепочке вывода и удовлетворяет следующим условиям:
называется дерево, которое соответствует некоторой цепочке вывода и удовлетворяет следующим условиям: 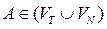 ;
;  , а связанные с ним узлы – символами
, а связанные с ним узлы – символами  , то в грамматике
, то в грамматике 
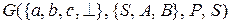 с правилами
с правилами  . Требуется выполнить анализ строки cabca^.
. Требуется выполнить анализ строки cabca^. .
.
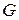 из предыдущего примера.
из предыдущего примера.