
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Статистическая мера информации.Стр 1 из 2Следующая ⇒
В статистической теории информации вводится более общая мера количества информации, в соответствии с которой рассматривается не само событие, а информация о нем. Этот вопрос глубоко проработан К. Шенноном в работе «Избранные труды по теории информации». Если появляется сообщение о часто встречающемся событии, вероятность появления которого близка к единице, то такое сообщение для получателя малоинформативное. Столь же мало информативны сообщения о событиях, вероятность появления которых близка к нулю. События можно рассматривать как возможные исходы некоторого опыта, причем все исходы этого опыта составляют ансамбль, или полную группу событий. К. Шеннон ввел понятие неопределенности ситуации, возникающей в процессе опыта, назвав ее энтропией. Энтропия ансамбля есть количественная мера его неопределенности и, следовательно, информативности, количественно выражаемая как средняя функция множества вероятностей каждого из возможных исходов опыта. Поясним содержание статистической меры на следующем частном случае. Пусть выполняется посимвольная передаче текста, состоящего из символов алфавита А. Текст составлен из K символов алфавита. Опыт состоит в передаче очередного символа текста. Так как в один момент времени может быть передан любой символ алфавита, всего возможно А исходов опыта. Очевидно, что одни символы в тексте будут появляться часто, а другие — реже. Различные символы несут разную информацию. Обозначим через ki количество появления символа в тексте, а количество вносимой этим символом информации как Ii. Будем полагать, что передаваемые символы независимы, т.е. передача i –того символа происходит с вероятностью, независящей от того, какой символ был передан ранее. Это означает, информация, вносимая символом постоянна для любых сочетаний символов. Тогда средняя информация, доставляемая одним опытом, Iср = (k1I1+ k 2I2+…+ k AIA)/K. (9) Но количество информации в каждом исходе связано с его вероятностью рi , и выражается в двоичных единицах (битах) как Ii = log2 (1/pi) = -log2 pi. Тогда Iср =[ k 1 (-log2 p1)+...+ k A (-log2 pA)]/K. (10) Выражение (10) можно записать также в виде Iср =k1/K (-log2 p1)+...+kA/K (-log2 pA). (11) Но отношения n/K представляют собой частоты повторения исходов, а, следовательно, могут быть заменены их вероятностями: pi =ki/K , Тогда средняя информация в битах Iср = p1 (-log2 p1)+...+pA (-log2 pA), или Iср =∑ pi (-log2 pi) = H (12)
Полученную величину H называют энтропией. Энтропия обладает следующими свойствами: 1. Энтропия всегда неотрицательна, так как значения вероятностей выражаются величинами, не превосходящими единицу, а их логарифмы — отрицательными числами или нулем, так что члены суммы (12) — неотрицательны. 2. Энтропия равна нулю в том крайнем случае, когда одно из рi, равно единице, а все остальные — нулю. Это тот случай, когда об опыте или величине все известно заранее и результат не дает новую информацию. 3. Энтропия имеет наибольшее значение, когда все вероятности равны между собой: р1 = р2 =... = pi =1/A. При этом H=- log2(1/A)=log2 A=Hmax. 4. Энтропия объекта BC, состояния которого образуются совместной реализацией состояний B и C, равна сумме энтропии исходных объектов B и C, т. е. Н(BC) = Н(B) + Н(C). Если все события равновероятны и статистически независимы, то оценки количества информации, по Хартли и Шеннону, совпадают. Это свидетельствует о полном использовании информационной емкости системы. В случае неравных вероятностей количество информации, по Шеннону, меньше информационной емкости системы. Максимальное значение энтропии достигается при р=0, 5, когда два состояния равновероятны. При вероятностях р=0 или р=1, что соответствует полной невозможности или полной достоверности события, энтропия равна нулю. Наибольшее количество информации получается тогда, когда полностью снимается неопределенность, причем эта неопределенность была наибольшей — вероятности всех событий были одинаковы. Это соответствует максимально возможному количеству информации, оцениваемому мерой Хартли: Ix = log2 N = log2 (1/p) = - log2 p =Hmax, где N — число событий; р — вероятность их реализации в условиях равной вероятности событий, Hmax — максимальное значение неопределенности, равное энтропии равновероятностных событий. Абсолютная избыточность информации Dавс представляет собой разность между максимально возможным количеством информации и энтропией: Dавс = Ix - Н, или Dавс = Нmax -Н. (13) Пользуются также понятием относительной избыточности D = (Нmax -Н )/Hmax. (14) Рассмотренные информационные меры в полной мере применимы для оценки количества информации при передаче и хранении информации в вычислительных системах и цифровых системах связи. Если информация передается с использованием некоторого алфавита A то передачу каждого символа можно рассматривать как опыт, имеющий A возможных исходов. В длинном сообщении, например, при передаче текста размером K символов, различные символы алфавита могут появляться различное число раз. Мы можем говорить о частоте появления символов в сообщении, которая с увеличением K стремится к вероятности появления конкретного символа в сообщении. Информационные меры имеют важное значение при определении характеристик памяти ЭВМ, пропускной способности каналов связи и во многих других приложениях информатики.
Лабораторная работа №4 «Кодирование дискретных источников информации методом Шеннона-Фано» Цель работы Освоить метод построения кодов дискретного источника информации используя конструктивный метод, предложенный К.Шенноном и Н.Фано. На примере показать однозначность раскодирования имеющегося сообщения. Порядок выполнения лабораторной работы Исходными данными для данной лабораторной работы являются результаты статистической обработки текста, выполненной в предыдущей лабораторной работе. Из лабораторной работы «Определение количества информации, содержащегося в сообщении» для данной работы необходимо взять: 1) список символов данного текста; 2) оценку вероятностей появления символов в тексте; 3) значение энтропии источника. Расчеты рекомендуется выполнять в табличной форме, используя MS Excel. 1. Отсортировать символы в порядке убывания их вероятности появления в тексте. 2. Построить один из возможных вариантов по правилу Шеннона-Фано для посимвольного кодирования заданного текста. 3. Определить энтропию и среднее количество двоичных разрядов, необходимых для передачи текста при использовании эффективных кодов. 4. Проверить возможность однозначного декодирования полученных кодов, рассмотрев пример передачи слова, состоящего из не менее 10 символов. Содержание отчёта 1. Название и цель работы. 2. Заполненная таблица для 50-ти символов, содержащая: Ø список символов; Ø значения вероятностей; Ø кодовые комбинации; Ø ступени деления. 3. Значение средней информации в битах. 4. Описание применяемых формул. 5. Составленное сообщение, содержащее не менее 10 символов и кодовая строка. 6. Описание декодирования данного сообщения любым способом. 7. Выводы по работе соответственно цели лабораторной работы. Приложение к лабораторной работе «Кодирование дискретных источников информации методом Шеннона-Фано» Основные положения При кодировании дискретных источников информации часто решается задача уменьшения избыточности, т.е. уменьшения количества символов, используемых для передачи сообщения по каналу связи. Это позволяет повысить скорость передачи за счет уменьшения количества передаваемой информации, а точнее, за счет отсутствия необходимости передачи избыточной информации. В системах хранения уменьшение избыточности позволяет снизить требования к информационной емкости используемой памяти. Для передачи и хранения информации, как правило, используется двоичное кодирование. Любое сообщение передается в виде различных комбинаций двух элементарных сигналов. Эти сигналы удобно обозначать символами 0 и 1. Тогда кодовое слово будет состоять из последовательностей нулей и единиц. Если алфавит A состоит из N символов, то для их двоичного кодирования необходимо слово разрядностью n, которая определяется n = é log2 Nù . Это справедливо при использовании стандартных кодовых таблиц, например, ASCII, KOI-8 и т.п., обеспечивающих кодирование до 256 символов. Если в используемом алфавите символов меньше, чем используется в стандартной кодовой таблице, то возможно использование некоторой другой таблицы кодирования, позволяющей уменьшить количество двоичных разрядов, используемых для кодирования любого символа. Это, в определенном смысле, обеспечивает сжатие информации. Например, если необходимо передавать или хранить сообщение, состоящее из символов кириллицы, цифр и семи символов разделителей {«.», «, », «: », «; », «! », « кавычки », «? »} ( всего 50 символов), мы можем воспользоваться способами кодирования: Ø Кодировать каждый символ в соответствии со стандартной кодовой таблицей, например, KOI-8R. По этой таблице каждый символ будет представляться 8 битовым (байт) кодовым словом, n1 = 8; Ø Составить и использовать отдельную кодовую таблицу, это может быть некоторый усеченный вариант стандартной таблицы, не учитывающую возможность кодирования символов, не входящих в передаваемое сообщение, тогда необходимый размер кодового слова n2 =é log2 Nù == é log2 50ù =6. Очевидно, передача сообщения с помощью такого кода будет более эффективной, т.к. будет требовать меньшего количества бинарных сигналов при кодировании. Можно говорить о том, что при таком кодировании мы не передаем избыточную информацию, которая была бы в восьмибитовом кодировании; Ø Использовать специальный код со словом переменной длины, в котором символы, появляющиеся в сообщении с наибольшей вероятностью, будут закодированы короткими словами, а наименее вероятным символам сопоставлять длинные кодовые комбинации. Такое кодирование называется эффективным. Эффективное кодирование базируется на основной теореме Шеннона для каналов без шума, в которой доказано, что сообщения, составленные из букв некоторого алфавита, можно закодировать так, что среднее число двоичных символов на букву будет сколь угодно близко к энтропии источника этих сообщений, но не меньше этой величины. Теорема не указывает конкретного способа кодирования, но из нее следует, что при выборе каждого символа кодовой комбинации необходимо стараться, чтобы он нес максимальную информацию. Следовательно, каждый элементарный сигнал должен принимать значения 0 и 1 по возможности с равными вероятностями и каждый выбор должен быть независим от значений предыдущих символов. При отсутствии статистической взаимосвязи между кодируемыми символами конструктивные методы построения эффективных кодов были даны впервые К.Шенноном и Н.Фано. Их методики существенно не различаются, поэтому соответствующий код получил название кода Шеннона-Фано. Код строится следующим образом: буквы алфавита сообщений выписываются в таблицу в порядке убывания вероятностей. Затем они разделяются на две группы так, чтобы суммы вероятностей в каждой из групп были по возможности одинаковы. Всем буквам верхней половины в качестве первого символа приписывается 1, а всем нижним — 0. Каждая из полученных групп, в свою очередь, разбивается на две подгруппы с одинаковыми суммарными вероятностями и т. д. Процесс повторяется до тех пор, пока в каждой подгруппе останется по одной букве. Рассмотрим алфавит из восьми букв (табл. 1). Ясно, что при обычном (не учитывающем статистических характеристик) кодировании для представления каждой буквы требуется n2 =3 символа. В табл.1 приведен один из возможных вариантов кодирования по сформулированному выше правилу.
Очевидно, для указанных вероятностей можно выбрать другое разбиение на подмножества не нарушая алгоритма Шеннона-Фано. Такой пример приведен в табл.2.
Сравнивая приведенные таблицы, обратим внимание на то, что по эффективности полученные коды различны. Действительно, в табл.2 менее вероятный символ a4 будет закодирован двухразрядным двоичным числом, в то время как a2 , вероятность появления которого в сообщении выше, кодируется трехразрядным числом. Таким образом, рассмотренный алгоритм Шеннона-Фано не всегда приводит к однозначному построению кода. Ведь при разбиении на подгруппы можно сделать большей по вероятности как верхнюю, так и нижнюю подгруппу. Энтропия набора символов в рассматриваемом случае определяется как
Напомним, что смысл энтропии в данном случае, как следует из теоремы Шеннона, — наименьшее возможное среднее количество двоичных разрядов, необходимых для кодирования символов алфавита размера восемь с известными вероятностями появления символов в сообщении. Мы можем вычислить среднее количество двоичных разрядов, используемых при кодировании символов по алгоритму Шеннона-Фано
где: A — размер (или объем) алфавита, используемого для передачи сообщения; n(ai) — число двоичных разрядов в кодовой комбинации, соответствующей символу ai. Таким образом, мы получим для табл.1 Пример декодирования сообщения Рассмотрим пример сообщения, созданного из имеющихся символов. Пусть передано сообщение a1, a5, a3, a7, a2, a3. При кодировании, используя табл.1 получим следующую последовательность: 1100101100001101011 Получив сообщение подобного вида, необходимо её декодировать, чтобы прочитать сообщение. Считаем, что получатель имеет таблицу кодировки символов, идентичную с отправителем. Возможный способ декодирования представлен на таблице 3: Таблица 3
Декодирование производиться с наименьшей длины кодового слова — в нашем случае — 2, — получается таблица (см.выше), с итоговым результатом, аналогичным закодированному:
|
Последнее изменение этой страницы: 2017-03-14; Просмотров: 92; Нарушение авторского права страницы
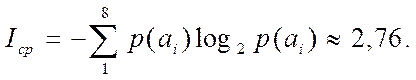
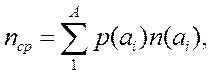
 =2, 84, а для табл.2
=2, 84, а для табл.2 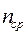 =2, 80. Построенный код весьма близок к наилучшему эффективному коду по Шеннону, но не является оптимальным. Должен существовать некоторый алгоритм позволяющий выполнить большее сжатие сообщения.
=2, 80. Построенный код весьма близок к наилучшему эффективному коду по Шеннону, но не является оптимальным. Должен существовать некоторый алгоритм позволяющий выполнить большее сжатие сообщения.