|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Кодирование сложных описаний ⇐ ПредыдущаяСтр 7 из 7
Вернемся к памяти и попробуем систематизировать, с какими типами информации, и, соответственно, типами описаний умеет оперировать наш мозг. Первый тип – это простое описание, которое соответствует картине мгновенной активности коры. Это сочетание тех понятий, что детектированы мозгом именно сейчас. Второй тип – это пакет простых описаний, соответствующих одному событию, одной мысли. В пакете несущественен порядок следования описаний. Перестановка слоев пакета не меняет общего смысла высказывания. Вспоминание пакета – это восстановление серии следующих друг за другом простых описаний. Третий тип – это позиционное описание. В таком описании сохраняется связь одних объектов с другими, находящимися с ними в определенной системе отношений. Например, разновидность такого описания – это пространственное описание. Когда мы не просто фиксируем свое положение в пространстве, а увязываем его определенными описаниями с расположением других объектов. Четвертый тип – это процедурное описание. Такое описание, в котором важна последовательность смены образов и сопутствующие этому интервалы. Например, восприятие речи определяется последовательностью звуков, при этом соотношение интервалов формирует интонацию, от которой сильно зависит общий смысл услышанной фразы. Вспоминание процедуры – это воспроизведение соответствующей последовательности образов. И пятый тип – это хронологическое описание. Фиксация на продолжительных отрезках времени того в какой последовательности и с какими временными интервалами происходили те или иные события. Возможность вспомнить для хронологической памяти – это не воспроизведение сразу всего, относящегося к одной хронологии, а возможность перейти от одного описания к другому, связанному с ним общей временной последовательностью. Несложно заметить, что многие описания так или иначе завязаны на время. Пакетное описание – это серия следующих друг за другом образов. Процедурное описание учитывает последовательность событий. Хронологическое описание требует учета позиционирования событий во времени. Такая зависимость описаний от времени послужила поводом к возникновению соответствующих моделей. Наиболее известная из них – это пропагандируемая Джефом Хокинсом концепция иерархической темпоральной памяти (HTM) (Хокинс, 2011). Он и его коллеги исходят из того, что темпоральная смена событий – это единственное, что позволяет связать между собой отдельные информационные образы. Из этого делается вывод, что базовый информационный элемент коры должен работать не со статичными образами, а с временной последовательностью. В концепции HTM элемент хранения информации – это развернутая во времени последовательность сигналов. Узнавание – это определение совпадения двух последовательностей. При этом особый акцент делается на способность HTM к предсказанию. Как только нейрон узнает начало знакомой ему последовательности, он становится способен по своему опыту предсказать запомненное им продолжение. Описание текущей картины в HTM – это активность тех нейронов, которые откликнулись на текущую смену событий. Сложности такого подхода достаточно очевидны. Во-первых, требование соблюдения временных масштабов. Небольшое ускорение или задержка в поступлении данных могут нарушить алгоритм узнавания. Во-вторых, необходимость переводить все статичные образы во временные последовательности перед тем, как кора сможет с ними оперировать. И тому подобное. В нашей модели система идентификаторов дает нам универсальный инструмент, который одинаково хорошо подходит для описания всех возможных типов памяти. Основная идея проста – каждое простое описание представляет собой составной идентификатор, содержащий в себе все необходимое для указания всего набора, как ассоциативных, так и временных взаимосвязей. На рисунке ниже приведено условное изображение такого простого описания. Простое описание – это волна, несущая в себе несколько наборов идентификаторов разных типов. Основное содержание кодируется набором идентификаторов понятий, описывающих суть происходящего. Идентификатор слоя помечает основное содержание, отделяя его от остальных простых описаний. Идентификатор пакета объединяет несколько слоев, относящихся к одному сложному описанию. Идентификаторы места, времени и последовательности создают систему соответствующих связей между сложными описаниями.
Формат простого описания Возьмем предыдущий пример и обозначим волны идентификаторов, соответствующие используемым понятиям (concepts), как C1…C7 (рисунок ниже).
Понятия, используемые для описания Тогда описание того, что «красный объект A лежит на синем объекте B» будет выглядеть, как показано на рисунке ниже.
Пример сложного описания В этом примере каждый из слоев пакета является простым описанием со своим идентификатором слоя. Все слои пакета имеют общий идентификатор пакета p1. Когда заканчивается одно сложное описание, другое, следующее за ним имеет отличный от него идентификатор пакета p2 (понятия второго описания на рисунке не показаны). Чтобы такая конструкция была работоспособной, мозгу необходима достаточно сложная система, создающая идентификаторы, формирующие пакеты. Причем для каждой из зон коры может потребоваться свой набор таких идентификаторов, уместный именно для нее. Например, возьмем последовательность зрительного восприятия. Скачкообразные микродвижения глаз, называемые микросаккадами, заставляют глаз сканировать малый фрагмент изображения, приходящийся на центр сетчатки. Все образы, которые получаются в процессе такого сканирования, предположительно могут объединяться общим идентификатором. Микродвижениями глаз управляют верхние бугорки четверохолмия. Можно предположить, что именно они кодируют такой идентификатор. После нескольких микросаккад происходит сильный прыжок, называемый саккадой (выше на рисунке с головой Нефертити показаны именно саккады). Каждая саккада вызывают смену идентификатора микросаккад. Можно предположить, что микросаккады принципиально важны для первичной зрительной коры. Общий идентификатор сообщает коре, что сери подряд идущих образов описывает один и тот же объект, но в разных его позициях на сетчатке, что позволяет объединить их в единое описание и реализовать инвариантное к положению на сетчатке узнавание. Более продолжительное событие — серия саккад. Так как серия относится к разглядыванию единой картины, то получаемые описания тоже можно связать между собой еще одним общим идентификатором – идентификаторам саккад. Но этот идентификатор существенен уже не для первичной, а для вторичной и более глубоких уровней зрительной коры, где происходит последующая обработка информации. Идентификатор, сообщающий коре, что все, что мы видим во время серии саккад – это одна и та же картина, позволяет соотнести между собой одни и те же образы, видимые разными местами сетчатки. Смена идентификатора саккад должна происходить, когда существенно меняется разглядываемая картина. Например, при сильном повороте головы, переключении внимания, смене плана или сцены в кино. Переключение внимания может кодироваться элементами лимбической системы мозга и распространяться на множество, завязанных на это, зон коры. Одновременно с этим в системе описаний присутствуют идентификаторы гиппокампа, кодирующие пространственно-временные описания событий. Короче, система идентификаторов, определяющих пакет, может быть достаточно сложна, и определяться особенностями той информации, с которой имеет дело каждая конкретная зона коры. Используя идентификаторы несложно организовать фиксацию последовательности событий. Например, если взять идентификатор, состоящий из двух фрагментов, то поочередно меняя по одному из них, можно получить ассоциативную связанность соседних описаний (рисунок ниже).
Кодирование последовательности Каждый такой идентификатор будет содержать элемент от предыдущего и последующего идентификатора. Запомнив временную последовательность образов с такими идентификаторами, мы для каждого образа сможем найти его двух соседей по временной шкале. Несложно усложнив идентификатор можно закодировать не только общую связанность, но и направление течения времени. Надо отметить, что в нашей модели каждое воспоминание имеет богатую систему идентификаторов. Это позволяет получить доступ к воспоминанию через множество совершенно различных ассоциаций. Можно вспомнить что-либо, исходя из совпадения смыла описаний. Можно проассоциировать информационные картины по месту или времени описываемых событий. Можно воспроизвести последовательность образов, относящихся к одному событию. Нетрудно заметить, что такой доступ к воспоминаниям имеет много общего с подходами, которые используются при создании традиционных реляционных баз данных. Реляционная модель данных В 1970 году Эдгар Кодд опубликовал статью (Codd, 1970), в которой описал основы реляционной модели хранения данных. Практической реализацией этой модели стали все современные реляционные базы данных. Формализация модели привела к созданию реляционного исчисления и реляционной алгебры. Основное элемент реляционной модели – это кортеж. Кортеж – это упорядоченный набор элементов, каждый из которых принадлежит определенному множеству или, иначе говоря, имеет свой тип. Совокупность однородных по структуре кортежей образует отношение. Несколько более наглядно все это выглядит в терминах, используемых в базах данных (рисунок ниже). Отношение – это таблица с данными. Кортеж — строка таблицы. Какого типа кортежи содержатся в отношении, или, что то же самое, каков формат строк в таблице, определяется заголовком отношения или таблицы. Каждый из столбцов таблицы образует домен. Значения, которое могут принимать элементы домена, называются атрибутами. Строки таблицы – это совокупность атрибутов, соответствующих доменам.
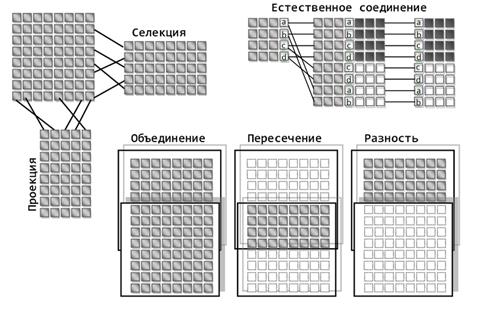
Пример отношения (Заборов) Строки таблицы могут быть идентифицированы по своим атрибутам, то есть по тому, какие значения принимают элементы кортежа. Само содержание кортежа делает его непохожим на остальные. Но может так оказаться, что некоторые строки совпадут по своим атрибутам. Само по себе совпадение не страшно, но оно уже не позволяет использовать такой набор атрибутов, для однозначной идентификации кортежей в отношении. Чтобы идентификация была однозначной, вводят такое ключевое поле, которое для каждой строки принимает уникальное значение. Такой ключ может нести смысловую нагрузку, а может быть просто искусственно сгенерированным числом. Совокупность всех отношений определяет базу данных. Каждое отношение хранит свою логическую часть информации. Чтобы получить определенные сведения может потребоваться сопоставление информации из разных отношений. Кодд описал восемь основных операций реляционной алгебры, позволяющих манипулировать с кортежами: · Объединение; · Пересечение; · Вычитание; · Декартово произведение; · Выборка; · Проекция; · Соединение; · Деление. Замечательное свойство реляционной алгебры – это ее замкнутость, то есть операции над отношениями задаются таким образом, чтобы результат сам был отношением. То есть, имея несколько таблиц и производя соответствующие операции над ними, мы получим результатом тоже таблицу. Смысл многих операций совпадает с соответствующими операциями из теории множеств. Общее представление об их сути дает рисунок ниже.
Пример операций над кортежами (Заборов) Важно, что разные отношения могут содержать домены одного типа. Это значит, что если в двух кортежах встречаются одинаковые домены, внутри них одинаковые атрибуты, то можно говорить об определенной связи кортежей, содержащих эти атрибуты. Иначе говоря, если разные строки одной таблицы в одном из столбцов имеют одинаковые значения, то можно говорить об определенной связи этих строк. Или если в разных таблицах есть столбцы (домены) с одинаковым смыслом, то строки с одинаковыми значениями в этих столбцах оказываются связанными между собой. Операция проекции позволяет получать отношения, состоящие из части элементов исходных отношений, ограничивая набор используемых доменов. Выборка или селекция позволяет получать отношения, содержащие только те кортежи, поля которых удовлетворяют условиям выборки. Например, можно выбрать только те кортежи, указанные домены которых имеют заданные значения атрибутов. Совокупность всех операций над отношениями позволяет извлечь из базы данных любую интересующую информацию и сформировать ее в виде отношения (таблицы) с наперед заданными свойствами (заголовком). Реляционной модель данных возникла не случайно, а явилась следствием необходимости оперировать с большими объемами разнообразных данных. Оказалось, что такая структура хранения данных и определенные в этой структуре операции удобны для решения широкого спектра прикладных задач. Можно предположить, что аналогичное удачное решение могла нащупать и природа в результате естественного отбора. Описываемая нами система идентификаторов, понятий и событийной памяти во многом очень похожа на реляционную модель. Можно провести ряд аналогий: · Нейрон оперирует информацией с нескольких дендритных сегментов, каждый из которых настроен на данные определенного типа. Дендритные сегменты одного типа можно сопоставить с определенным доменом; · Сочетания понятий, которые описывают информацию, характерную для дендритного сегмента, соответствуют атрибутам, встречающимся в домене; · Понятия, используемые зоной коры, и идентификаторы, задающие структуру пакетов, характерную для этой зоны, определяют структуру доменов (заголовок); · Использование общих понятий при проекции информации между зонами соответствует использованию общих доменов в разных отношениях; · Совокупность зон коры, формирующих мозг, соответствует совокупности отношений, формирующих базу данных; · Ассоциативность, между воспоминаниями, соответствует связанности через общие атрибуты различных кортежей; · Распределенность воспоминания по зонам коры соответствует тому, как одно событие может породить несколько кортежей в разных отношениях, объединенных единым уникальным ключом; · Волна, описывающая текущее состояние мозга, может выступать аналогом запроса к базе данных. Так же, как результат операции над отношениями есть отношение, так и ответ мозга может быт совокупностью ассоциативно связанных описаний, совмещенных в одной волновой картине. Конечно, между нашей моделью мозга и реляционными системами нет точного соответствия. Архитектура мозга значительно богаче, так как решает не только задачи хранения и извлечения данных, но и массу других совмещенных с этим функций. Однако даже имеющееся сходство позволяет лучше понять суть информационных процессов, происходящих в коре.
|
Последнее изменение этой страницы: 2017-03-14; Просмотров: 374; Нарушение авторского права страницы