
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Операции над множествами и их свойства ⇐ ПредыдущаяСтр 2 из 2
Множество-совокупность некоторых обьектов, объединённых по одному признаку. Множество не содержащее ни одного элемента называют пустым множеством. Операции над множествами: а) Пересечением множеств М и N называют множество тех объектов, которые принадлежат множествам М и N одновременно. Обозначение: М б) Объединением множеств М и N называют множество тех элементов, которые содержатся по крайней мере в одном из множеств М или N. Обозначение: M в) Разностью множеств М и N называют множество тех элементов, которые принадлежат множеству М и не принадлежат множеству N. Обозначение: М \ N. = {х | х г) Симметрической разностью множеств М и N называют множество тех элементов, которые принадлежат только множеству М - или только множеству N. Обозначение: M д) В конкретных математических областях бывает полезно ввести в рассмотрение столь обширное множество U, что все рассматриваемые множества окажутся его подмножествами. Такое множество U принято называть универсальным множеством или универсумом.
Множественный тип данных Множество — тип и структура данных в информатике, является реализацией математического объекта множество. Данные типа множество позволяют хранить ограниченное число значений определённого типа без определённого порядка. Повторение значений, как правило, недопустимо. За исключением того, что множество в программировании конечно, оно в общем соответствует концепции математического множества. Для этого типа в языках программирования обычно предусмотрены стандартные операции над множествами. пример: (type {определяем базовые для множеств перечислимый тип и тип-диапазон} colors = (red, green, blue); smallnumbers = 0..10; {определяем множества из наших типов} colorset = set of colors; numberset = set of smallnumbers; {можно и не задавать тип отдельно} anothernumberset = setof 0..20; {объявляем переменные типа множеств} var nset1, nset2, nset3: numberset; cset: colorset; begin nset1: = [0, 2, 4, 6, 8, 10]; {задаем в виде конструктора множества} cset: = [reb, blue]; {простым перечислением элементов} nset2: = [1, 3, 9, 7, 5]; {порядок перечисления неважен} nset3: = []; {пустое множество} nset1: = [0..5]; {возможно задавать элементы диапазоном} nset3: = nset1 + nset2; {объединение} nset3: = nset1 * nset2; {пересечение} nset3: = nset1 - nset2; {разность} if (5 in nset2) or {проверка на вхождение элемента} (green in cset) then ... end; ) Функции и процедуры над строковыми данными 1) Функция Length(Str: String) - возвращает длину строки (количество символов). 2) Функция SetLength(Str: String; NewLength: Integer) позволяет изменить длину строки. Если строка содержала большее количество символов, чем задано в функции, то " лишние" символы обрезаются. 3) Функция Pos(SubStr, Str: String) - возвращает позицию подстроки в строке. Нумерация символов начинается с единицы (1). В случае отсутствия подстроки в строке возращается 0. 4) Функция Copy(Str: String; Start, Length: Integer) - возвращает часть строки Str, начиная с символа Start длиной Length. Ограничений на Length нет - если оно превышает количество символов от Start до конца строки, то строка будет скопирована до конца. 5) Процедура Delete(Str: String; Start, Length: Integer) - удаляет из строки Str символы, начиная с позиции Start длиной Length. 6) Процедура Insert(SubStr: String; Str: String; Pos: Integer) - вставляет в строку Str подстроку SubStr в позицию Pos. 7) Функции UpperCase(Str: String) и LowerCase(Str: String) преобразуют строку соответственно в верхний и нижний регистры Строки можно сравнивать друг с другом стандартным способом.
Математическая модель комбинированного типа данных TYPE < имя типа> = RECORD < имя поля 1>: тип; < имя поля 2>: тип; ... < имя поля n>: тип END;
Записи. Вариантные записи Запись – это множество разнотипных элементов. Каждый элемент (поле) записи имеет свое собственное имя и тип. Запись может иметь вариантную часть, которая должна следовать после обычных полей. Запись также может иметь только вариантную часть. В языке Pascal был введен вариантный тип данных ( Variant ), тип которых не известен на этапе компиляции и может изменяться на этапе выполнения программы. Однако этот тип данных поглощает больше памяти по сравнению с соответствующими переменными и операции над данными типа Variant выполняются медленнее. Более того, недопустимые операции над данными этого типа чаще приводят к ошибкам на этапе выполнения программы, в то время как подобные ошибки над данными другого типа были бы выявлены еще на этапе компиляции. Вариантные переменные могут принимать различные значения (целые, строковые, булевские, Currency, OLE-строки), быть массивами элементов этих же типов и массивом значений вариантного типа, а также содержать COM и CORBA объекты, чьи методы и свойства могут быть доступны посредством этого типа. Однако Variant не может содержать: данные структурных типов, указатели, Int64 (начиная с Delphi 6 – может).
6. Синтаксические диаграммы комбинированного типа данных 7. Селектор записи
Понятие модели данных В классической теории баз данных, модель данных есть формальная теория представления и обработки данных в системе управления базами данных (СУБД), которая включает, по меньшей мере, три аспекта: а) аспект структуры: методы описания типов и логических структур данных в базе данных; б) аспект манипуляции: методы манипулирования данными; в) аспект целостности: методы описания и поддержки целостности базы данных. Аспект структуры определяет, что из себя логически представляет база данных, аспект манипуляции определяет способы перехода между состояниями базы данных (то есть способы модификации данных) и способы извлечения данных из базы данных, аспект целостности определяет средства описаний корректных состояний базы данных. Модель данных — это абстрактное, самодостаточное, логическое определение объектов, операторов и прочих элементов, в совокупности составляющих абстрактную машину доступа к данным, с которой взаимодействует пользователь. Эти объекты позволяют моделировать структуру данных, а операторы — поведение данных. Каждая БД и СУБД строится на основе некоторой явной или неявной модели данных. Все СУБД, построенные на одной и той же модели данных, относят к одному типу. Например, основой реляционных СУБД является реляционная модель данных, сетевых СУБД — сетевая модель данных, иерархических СУБД — иерархическая модель данных и т.д.
Иерархическая модель данных Иерархическая модель данных — логическая модель данных в виде древовидной структуры. Иерархическая модель данных представляет собой совокупность элементов, расположенных в порядке их подчинения от общего к частному и образующих перевернутое дерево (граф). Данная модель характеризуется такими параметрами, как уровни, узлы, связи. Принцип работы модели таков, что несколько узлов более низкого уровня соединяется при помощи связи с одним узлом более высокого уровня. Узел — информационная модель элемента, находящегося на данном уровне иерархии.
Сетевая модель данных Сетевая модель данных — логическая модель данных, являющаяся расширением иерархического подхода, строгая математическая теория, описывающая структурный аспект, аспект целостности и аспект обработки данных в сетевых базах данных. Разница между иерархической моделью данных и сетевой состоит в том, что в иерархических структурах запись-потомок должна иметь в точности одного предка, а в сетевой структуре данных у потомка может иметься любое число предков. Сетевая БД состоит из набора экземпляров определенного типа записи и набора экземпляров определенного типа связей между этими записями. Тип связи определяется для двух типов записи: предка и потомка. Экземпляр типа связи состоит из одного экземпляра типа записи предка и упорядоченного набора экземпляров типа записи потомка. Для данного типа связи L с типом записи предка P и типом записи потомка C должны выполняться следующие два условия: а) каждый экземпляр типа записи P является предком только в одном экземпляре типа связи L; б) каждый экземпляр типа записи C является потомком не более чем в одном экземпляре типа связи L.
Реляционная модель данных Реляционная модель данных — логическая модель данных, прикладная теория построения баз данных, которая является приложением к задачам обработки данных таких разделов математики как теории множеств и логика первого порядка. На реляционной модели данных строятся реляционные базы данных. Реляционная модель данных включает следующие компоненты: а) структурный — данные в базе данных представляют собой набор отношений. б) целостностный — отношения (таблицы) отвечают определенным условиям целостности. РМД поддерживает декларативные ограничения целостности уровня домена (типа данных), уровня отношения и уровня базы данных. в) обработки (манипулирования) — РМД поддерживает операторы манипулирования отношениями (реляционная алгебра, реляционное исчисление). Кроме того, в состав реляционной модели данных включают теорию нормализации. Термин «реляционный» означает, что теория основана на математическом понятии отношение (relation). В качестве неформального синонима термину «отношение» часто встречается слово таблица. Необходимо помнить, что «таблица» есть понятие нестрогое и неформальное и часто означает не «отношение» как абстрактное понятие, а визуальное представление отношения на бумаге или экране. Некорректное и нестрогое использование термина «таблица» вместо термина «отношение» нередко приводит к недопониманию. Наиболее частая ошибка состоит в рассуждениях о том, что РМД имеет дело с «плоскими», или «двумерными» таблицами, тогда как таковыми могут быть только визуальные представления таблиц. Отношения же являются абстракциями, и не могут быть ни «плоскими», ни «неплоскими». Для лучшего понимания РМД следует отметить три важных обстоятельства: а) модель является логической, то есть отношения являются логическими (абстрактными), а не физическими (хранимыми) структурами; б) для реляционных баз данных верен информационный принцип: всё информационное наполнение базы данных представлено одним и только одним способом, а именно — явным заданием значений атрибутов в кортежах отношений; в частности, нет никаких указателей (адресов), связывающих одно значение с другим; в) наличие реляционной алгебры позволяет реализовать декларативное программирование и декларативное описание ограничений целостности, в дополнение к навигационному (процедурному) программированию и процедурной проверке условий.
|
Последнее изменение этой страницы: 2017-03-14; Просмотров: 449; Нарушение авторского права страницы
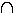 N = {х|х
N = {х|х  М и х
М и х 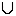 N = {х | х
N = {х | х  N}.
N}. N ={ x | (x
N ={ x | (x 