|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХСтр 1 из 7Следующая ⇒
СИСТЕМЫ УПРАВЛЕНИЯ БАЗАМИ ДАННЫХ Лабораторный практикум для студентов специальностей 1-08 01 01 «Профессиональное обучение» В двух частях ЧАСТЬ 2
МИНСК 2011 Предисловие
Современный специалист в области разработки СУБД и клиент-серверных приложений должен уметь пользоваться различными технологиями получения данных из СУБД, а также различными методами и средствами разработки клиент-серверных приложений различного уровня сложности. Целью дисциплины «Системы управления базами данных» является изучение основ реляционной модели баз данных, принципам их создания и обработки данных, для получение необходимой информации. Лабораторный практикум по данной дисциплине предполагает выполнение 24 лаб раб. Данный практикум является продолжением первой части. В первой части содержаться задания по разделам «Разработка БД в среде MSAccess», «Администрирование БД Interbase». Вторая часть практикума включает задания по разделам «Создание БД MySQL», «Создание БД Oracle», «Создание клиент-серверных приложений», «Работа с транзакциями». Описание каждой лабораторной работы содержит теоретические сведения, необходимые для её выполнения, порядок выполнение работы, задания и контрольные вопросы При защите лабораторной работы необходимо предоставить отчет выполненной работы, продемонстрировать результат выполнения работы и ответить на контрольные вопросы
Указания по выполнению лабораторных работ
Перед выполнением лабораторной работы студенты должны ознакомиться с предлагаемыми теоретическими сведениями, необходимыми для успешного выполнения конкретной работы. Следует внимательно ознакомиться с заданием, обдумать действия по выполнению работы, изучить при необходимости дополнительный теоретический материал, а затем приступить к выполнению задания. Результаты выполнения всех лабораторных работ необходимо сохранить на магнитном носителе, так как они будут использоваться для выполнения последующих работ. Отчет по лабораторной работе включает: - тему лабораторной работы; - цели работы; - пошаговое описание, выполненных заданий; - ответы на контрольные вопросы по лабораторной работе; - выводы по итогам лабораторной работы. К выполнению следующей работы студенты допускаются только после сдачи отчета по предыдущей лабораторной работе.
Лабораторная работа 1 УСТАНОВКА SQL-СЕРВЕРА, ПОДКЛЮЧЕНИЕ КЛИЕНТСКОЙ ПРОГРАММЫ
Цель работы: формирование умений установки на персональный компьютер и конфигурировать сервер баз данных MySQL и закрепление знаний, умений и навыков создания объектов БД.
Создание таблиц базы данных Следующий этап настройки базы данных связан с созданием таблиц. В СУБД MySQL существует несколько типов таблиц. Основные из них: MyISAM для быстрого чтения, InnoDB для транзакций и ссылочной целостности. Это делается с помощью SQL-команды CREATE TABLE tablename(columns) Columns – разделяемый запятыми список столбцов в таблице. Каждый столбец должен иметь имя, за которым следует тип данных. create table student ( idStudent int unsigned not null auto_increment primary key, name char(50) not null, address char(100) not null, city char(30) not null, date date not null ) ENGINE=InnoDB; Каждая таблица создается с помощью отдельного оператора create table. Определение столбца содержит его имя, за которым следует тип данных. В определениях некоторых столбцов присутствуют и другие спецификаторы. Например составной ключ можно создать путем написания строки primary key(fiel1, field2.. fieldN) в конструкции create table. Просмотр таблицы базы данных осуществляется с помощью команды describe dbname;
Практическая часть Порядок выполнения работы 1) Установить сервер баз данных MySQL на компьютер. 2) Выполнить первичную настройку программы. 3) Проверить работоспособность сервера MySQL. 4) Запустить программу-клиент mysql.exe и подключиться к серверу. 5) Вывести и записать список существующих БД. 6) В зависимости от варианта создать требуемые таблицы. 7) Найти на диске в директории баз данных MySQL каталог, содержащий созданную БД.
3. Контрольные вопросы 1) Пояснить термин «реляционная база данных». 2) Где хранятся настройки программы СУБД MySQL? 3) Как можно проверить работоспособность СУБД MySQL? 4) Где хранятся данные СУБД MySQL?
ЛАБОРАТОРНАЯ РАБОТА 2 УПРАВЛЕНИЕ ДОСТУПОМ К ДАННЫМ. КОПИРОВАНИЕ И ВОССТАНОВЛЕНИЕ БД Цель работы: формирование умений и навыков управления доступом к данным; формирование умений копирования и восстановления БД.
Краткие теоретические сведения Копирование и восстановление БД Утилита mysqldump позволяет получить дамп содержимого базы данных или совокупности баз для создания резервной копии или пересылки данных на другой SQL-сервер (не обязательно MySQL-сервер). Дамп будет содержать набор команд SQL для создания и/или заполнения таблиц. Так же mysqldump имеет возможность развертывания баз данных из созданного sql-файла. Пример использования mysqldump для создания дампа базы данных «database» при помощи перенаправления потока в файл «database.sql»: mysqldump -uroot -hlocalhost -p database > database.sql
-u или -- user=... — имя пользователя -h или --host=... — удаленный хост (для локального хоста можно опустить этот параметр) -p или --password — запросить пароль database — имя базы данных database.sql — файл для дампа
Для того чтобы сделать дамп несколько баз данных, необходимо использовать параметр --databases (или сокращенно -B ), пример: mysqldump -uroot -hlocalhost -p -B database1 database2 database3 > databases.sql
А для того чтобы сделать дамп всех баз данных, необходимо использовать параметр --all-databases (или сокращенно -A ), пример: mysqldump -uroot -hlocalhost -p -A > all-databases.sql
Для того, чтобы развернуть дамп, перенаправляем поток в обратную сторону и развертываем базу данных: mysql -uroot -hlocalhost -p database < database.sql Или через mysql-console:
mysql> use database; mysql> source database.sql
Практическая часть Порядок выполнения работы 1) Создать несколько пользователей. Делегировать пользователям следующие права: - права системного администратора с возможностью передавать эти права другим пользователям; - права системного администратора без права передавать эти права другим пользователям; - права на добавление и выборку записей из всех таблиц; - права на удаление, добавление и выборку данных из нескольких таблиц, с указанием полей, которые разрешено изменять. 2) Научиться пользоваться командой, которая ликвидирует права. 3) Сохранить резервную копию БД на съемном носителе для дальнейшего использования.
3.Контрольные вопросы 1) Каким образом можно ограничить доступ пользователям к БД? 2) Какие виды ограничений бывают? 3) Каким образом можно ликвидировать права пользователей?
Лабораторная работа 3 Индексы и обзоры.
Цель работы: получить практические навыки работы с индексами, оптимизации работы запросов. Научиться создавать обзоры.
Создание индекса Общий вид создания индекса: CREATE [UNIQUE|FULLTEXT] INDEX index_name ON tbl_name (col_name[(length)],... ) Обычно все индексы создаются в таблице во время создания самой таблицы командой CREATE TABLE. CREATE INDEX дает возможность добавить индексы к существующим таблицам. Также индекс можно создать следующей командой: ALTER TABLE tbl_name ADD INDEX (field)
где field – наименование поля. Рассмотрим пример. Пусть имеется таблица Student с полями idStudent (PK) и name.
Из описание видно, что в таблице уже имеется индекс типа PRIMARY, созданный автоматически при создании таблицы. Предположим, что необходим частый поиск по имени студента, для чего следует создать индекс: ALTER TABLE student ADD INDEX (name(5)); В данном примере 5 – длина индекса. Здесь не следует пренебрегать данным параметром во избежание экономии памяти, т.к. чем больше длина индекса, тем больше места занимает таблица на жестком диске. Тем более меньшая длина индекса гораздо повысит скорость операции INSERT. Проверяем созданный индекс:
SHOW INDEX FROM student;
После этого поиск, сортировка по имени студента будут происходить гораздо быстрее.
В СУБД MySQL удаление индексов производится операторами DROP INDEX или ALTER TABLE. Удаление первичных ключей (индексов PRIMARY KEY) осуществляется только с помощью оператора ALTER TABLE. Операторы удаления индексов имеют следующий синтаксис: DROP INDEX < index_name> ON < bl_name>; ALTER TABLE < tbl_name> DROP INDEX < index_name>; Оператор для удаления индекса PRIMARY KEY имеет синтаксис: ALTER TABLE < tbl_name> DROP PRIMARY KEY; Если такой индекс с именем PRIMARY KEY создан не был, а таблица имеет один или несколько индексов UNIQUE, будет удален первый из них. Удаление столбцов из таблицы влияет на индексы. Удаляя столбец из таблицы, вы тем самым удаляете этот столбец из индекса. Удаляя все индексируемые столбцы из таблицы, вы удаляете весь индекс. Оператор EXPLAIN EXPLAIN может в точности рассказать вам, что происходит, когда вы выполняете запрос. Эта информация позволит вам обнаружить медленные запросы и сократить время, затрачиваемое на обработку запроса, что впоследствии может значительно ускорить работу вашего приложения. Оператор EXPLAIN можно применять двумя способами:
1) EXPLAIN tbl_name; (идентично describe tbl_name; )
2) Применение оператора EXPLAIN перед SELECT запросами.
Рассмотрим второй способ. Простейший пример использования:
EXPLAIN SELECT * FROM student WHERE idStudent = 2;
В этом примере производится выборка данных студента на основе его идентификатора (idStudent). Вот то, что мы имеем в результате выполнения запроса EXPLAIN:
Id: Идентификатор (ID) таблицы в запросе. EXPLAIN создает по одной записи для каждой таблицы в запросе. Select_type: simple. Возможные значения: SIMPLE, PRIMARY, UNION, DEPENDENT UNION, SUBSELECT, и DERIVED. Это тип запроса. · SIMPLE – обычный тип запроса SELECT. · PRIMARY – внешний (первый) запрос, в котором используются подзапросы и соединения. · UNION – второй или последний запрос в соединении · DEPENDENT UNION - второй или последний запрос в соединении, зависящий от первичного запроса · SUBQUERY – внутренний подзапрос. · DEPENDENT SUBQUERY – внутренний подзапрос, зависящий от первичного запроса · DERIVED – подзапрос, использованный в выражении FROM.
Table. Имя таблицы, из которой MySQL читает данные. Type. Тип объединения, которое использует MySQL. Возможные значения: eq_ref, ref, range, index, или all. (const – таблица в запросе считывается только однажды) Possible_keys. Список индексов (или NULL, если индексов нет), которые MySQL может использовать для выборки рядов в таблице. Key. Название индекса, который использует MySQL (после проверки всех возможных индексов). Key_len. Размер ключа в байтах. Ref. Колонки или значения, которые используются для сравнения с ключем. Rows. Количество рядов, которые MySQL необходимо проверить, для обработки запроса(! ) Extra. Дополнительная информация о запросе.
Этот пример достаточно прост. Мы производим поиск по первичному ключу (idStudent) и может быть только одна запись, которая подойдет нашим условиям (переменная rows равна 1).
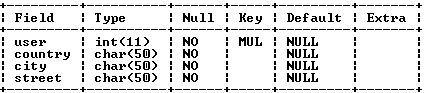
Рассмотрим более расширенный пример. Создадим еще одну таблицу address, содержащую место проживания студентов.
EXPLAIN SELECT * FROM student INNER JOIN ADDRESS ON student.idStudent = address.user WHERE student.idStudent = 1;
Наблюдаем результат, и видим, что во второй таблице не используется индекс, и она просматривается вся при соединении. При большом количестве данных это очень критично.
Добавим индекс во вторую таблицу для поля user.
ALTER TABLE address ADD INDEX (user);
Наблюдаем результат:
Теперь поле проиндексировано и просматривается всего лишь 1 запись из присоединяемой таблицы.
Представления (обзоры) Представление (VIEW) — объект базы данных, являющийся результатом выполнения запроса к базы данных, определенного с помощью оператора SELECT, в момент обращения к представлению. Представление доступно для пользователя как таблица, но само оно не содержит данных, а извлекает их из таблиц в момент обращения к нему. Если данные изменены в базовой таблице, то пользователь получит актуальные данные при обращении к представлению, использующему данную таблицу. Для создания представления используется оператор CREATE VIEW, имеющий следующий синтаксис: CREATE [OR REPLACE]
где view_name - имя создаваемого представления. select_statement - оператор SELECT, выбирающий данные из таблиц и/или других представлений, которые будут содержаться в представлении
Оператор CREATE VIEW содержит 4 необязательные конструкции: 1) OR REPLACE - при использовании данной конструкции в случае существования представления с таким именем старое будет удалено, а новое создано. 2) ALGORITM - определяет алгоритм, используемый при обращении к представлению. UNDEFINED – автоматический выбор (по умолчанию). 3) column_list - задает имена полей представления., 4) WITH CHECK OPTION - при использовании данной конструкции все добавляемые или изменяемые строки будут проверяться на соответствие определению представления. В случае несоответствия данное изменение не будет выполнено. Обратите внимание, что при указании данной конструкции для необновляемого представления возникнет ошибка и представление не будет создано.
При создании представления основанного на нескольких таблицах возможна ситуация повторения представления. Например:
CREATE VIEW v AS SELECT a.id, b.id FROM a, b;
Поэтому необходимо использовать псевдонимы имен: CREATE VIEW v AS SELECT a.id a_id, b.id b_id FROM a, b;
Для просмотра содержимого представления используется оператор SELECT (полностью аналогично как в случае простой таблицы).
SELECT * FROM v;
Практическая часть 1) Составить сложные запросы для 3 или более таблиц с использованием INNER JOIN. 2) Проанализировать запросы с помощью оператора EXPLAIN. 3) Оптимизировать запросы добавлением индексов. 4) Зафиксировать результаты. 5) Создать обзоры по БД вашего варианта
3. Контрольные вопросы 1) Для чего необходимо обеспечивать уникальность значений ключевых полей? 2) Перечислите виды индексов. 3) Для чего используется оператор EXPLAIN? 4) Что такое обзор? 5) Почему рекомендуется создавать псевдонимы имен в обзорах?
ЛАБОРАТОРНАЯ РАБОТА 4 Синтаксис хранимого кода Для использования множественных инструкций необходимо, чтобы была возможность посылать строки запросов, содержащие разделитель операторов;. Добиться этого можно путем применения команды DELIMITER в командной строке клиента mysql. Замена завершающего запрос разделителя; (например, на разделитель $$) позволяет использовать; в теле процедуры. Хранимый код может включать множественные инструкции, благодаря составному оператору BEGIN…END, который и определяет блок инструкций. [< метка начала>: ] BEGIN [< блок инструкций> ] END [< метка конца> ] Значения < метка начала> и < метка конца>, если оба заданы, должны быть одинаковыми. Метка позволяет не путать операторы, если они вложены. Конструкция DECLARE используется для объявления внутренних переменных, создания курсоров и конструкций исключений. DECLARE < имя переменной> [,...] type [DEFAULT < значение> ] Эта инструкция используется, чтобы объявить внутренние переменные, переменные, которые определяются для процедур, функций, триггеров. Чтобы задать значение по умолчанию для переменной, надо указать DEFAULT. Значение может быть определено как выражение, оно не обязательно должно быть константой. Если DEFAULT отсутствует, начальное значение NULL, type, здесь, подобен стандартным типам данных. Пример: DECLARE a INT DEFAULT 5; Курсоры – это указатели на ресурс выборки. Курсоры существуют только в хранимой процедуре или функции. Курсоры довольно медленные, поэтому использовать их стоит по необходимости. Создаются курсоры при помощи оператора DECLARE: DECLARE < имя курсора> CURSOR FOR < select выражение> Эта инструкция объявляет курсор. Каждый курсор должен иметь уникальное имя. < select выражение> – SELECT, не может иметь оператор INTO. Инструкция OPEN открывает предварительно объявленный курсор: OPEN < имя курсора> Инструкция FETCH выбирает следующую строку (если строка существует), используя определенный открытый курсор, и продвигает указатель курсора: FETCH < имя курсора> INTO < имя переменной> [, < имя переменной> ]... Если больше нет доступных строк, происходит условие No Data. Чтобы обнаружить это условие, можно установить обработчик для этого: CLOSE < имя курсора> CLOSE Закрывает предварительно открытый курсор. Если курсор не закрыт, он все равно закроется в конце составной инструкции (обычно по наступлению END), в которой он был объявлен. Следует обратить внимание: сначала объявляются переменные, потом курсоры: CREATE PROCEDURE curdemo() BEGIN DECLARE done INT DEFAULT 0; DECLARE a CHAR(16); DECLARE b, c INT; DECLARE cur1 CURSOR FOR SELECT id, data FROM test.t1; DECLARE cur2 CURSOR FOR SELECT i FROM test.t2; OPEN cur1; OPEN cur2; < блок инструкций> CLOSE cur1; CLOSE cur2; END Констукция SELECT … INTO так же позволяет «заполнить» переменную, прямо из таблицы: SELECT < имя столбца> [,...] INTO < имя переменной> [,...] < sql выражение> Этот синтаксис SELECT сохраняет выбранные столбцы непосредственно в переменные. Следовательно, количество выбранных столбцов слева от INTO должно быть равно количеству переменных справа от INTO. Пример: SELECT id, data INTO x, y FROM test.t1 WHERE id_tm = 5; Названия переменных не чувствительны к регистру. Важно: имена переменных SQL не должны совпадать с именами столбцов. В конструкции управления потоком входят IF, CASE, LOOP, WHILE, REPLACE ITERATE и LEAVE. Многие из этих конструкций могут содержат другие инструкции. Такие конструкции могут быть вложены. Например, IF мог бы содержать цикл, который непосредственно содержит WHILE, который в свою очередь включает в себя оператор CASE. Инструкция IF: IF < условие> THEN < блок операторов> [ELSEIF < условие> THEN < блок операторов> ]... [ELSE < блок операторов> ] END IF Инструкция CASE: CASE < выражение> WHEN < значение> THEN < блок операторов> [WHEN < значение> THEN < блок операторов> ]... [ELSE < блок операторов> ] END CASE или CASE WHEN < условие> THEN < блок операторов> [WHEN < условие> THEN < блок операторов> ]... [ELSE < блок операторов> ] END CASE В первом варианте обрабатывается < блок операторов> , если < выражение> =< значение> . Во втором – результат для первого указанного условия < условие> , если оно истинно. Если соответствующая величина результата не определена, то обрабатывается < блок операторов> , указанное после оператора ELSE. Если часть ELSE в выражении отсутствует, возвращается NULL. Пример: SELECT CASE 1 WHEN 1 THEN " one" WHEN 2 THEN " two" ELSE " more" END; SELECT CASE WHEN 1> 0 THEN " true" ELSE " false" END; SELECT CASE BINARY " B" WHEN " a" THEN 1 WHEN " b" THEN 2 END; Инструкция WHILE: [< метка начала>: ] WHILE < условие> DO < блок операторов> END WHILE [< метка конца> ] Операторный список < блок операторов> внутри инструкции WHILE будет повторятся до тех пор пока < условие> равно true. Инструкция LEAVE: LEAVE label Эта инструкция используется, чтобы из выйти любой указаной конструкции управления потоком данных. Может использоваться внутри BEGIN … END или же конструкций цикла (LOOP, REPEAT, WHILE). Можно сравнить c инструкцией break из С++. Инструкция REPEAT: [< метка начала> : ] REPEAT < блок операторов> UNTIL < условие> END REPEAT [< метка конца> ] Пример с использование различных конструкций: CREATE PROCEDURE curdemo() BEGIN DECLARE done INT DEFAULT 0; # переменная, определяющая условие выполнения нашего цикла DECLARE a CHAR(16); DECLARE b, c INT; DECLARE cur1 CURSOR FOR SELECT id, data FROM test.t1; # создаём курсоры DECLARE cur2 CURSOR FOR SELECT id FROM test.t2; DECLARE CONTINUE HANDLER FOR SQLSTATE '02000' SET done = 1; # статус, когда курсор истощатся OPEN cur1; # открываем курсор OPEN cur2; REPEAT FETCH cur1 INTO a, b; # забираем циклом данные из курсоров, пока не кончатся данные FETCH cur2 INTO c; IF NOT done THEN # пока done 0 IF b < c THEN INSERT INTO test.t3 VALUES (a, b); # записываем в таблицу наименьшее из b и c ELSE INSERT INTO test.t3 VALUES (a, c); END IF; END IF; UNTIL done END REPEAT; CLOSE cur1; CLOSE cur2; END
Практическая часть Порядок выполнения работы 1) В зависимости от варианта создать несколько триггеров для различных таблиц (возможные ситуации включения триггеров предусмотреть по собственному усмотрению). 2) Научиться использовать команду удаления триггеров. 3) В зависимости от варианта создать несколько процедур для различных таблиц (возможные ситуации использования процедур предусмотреть по собственному усмотрению).
3. Контрольные вопросы 1) С какими объектами БД связываются триггеры? 2) Какие виды инструкций активизируют триггер? 3) Каким образом можно удалить триггер? 4) В чем отличие хранимой процедуры от функции 5) Какие конструкции управления потоками данных вы знаете?
ЛАБОРАТОРНАЯ РАБОТА № 5 Практическая часть Порядок выполнения работы 1) Спроектируйте базу данных, состоящую из нескольких таблиц таким образом, чтобы в многотабличной системе были таблицы со связью 1: 1, 1: N 2)Отредактируете несколько записей в базе данных. 3)Отсортируйте данные в базе данных по какому-либо признаку или полю, записав результаты сортировки. 4)Составьте вторичный индекс из одного, двух или более полей. 3. Контрольные вопросы 1)Каким образом, используя компоненты IBX визуализировать содержимое таблиц 2)Как отключить отображения окна ввода имени пользователя и пароля каждый раз, когда происходит соединение с базой данных 3)Какие компоненты осуществляют навигацию по записям БД.
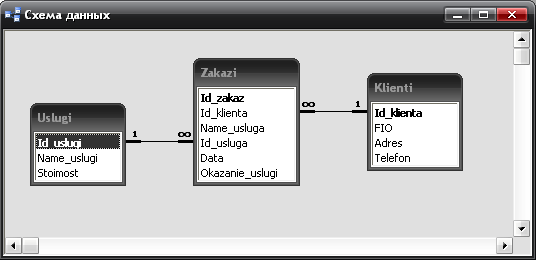
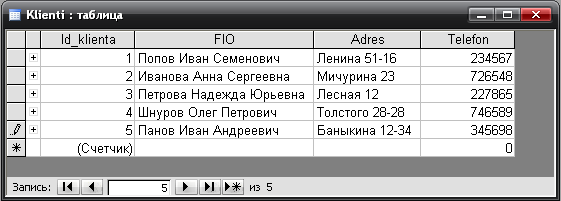
Лабораторная работа № 6 Этап создания БД 1. В соответствии с вариантом «Ателье обуви. Оформление заказов» создаем базу данных в Microsoft Access (Рис.1). Рис.1. Создание таблиц 2. Установливаем связи (Рис.2). Рис.2. Установление связей между таблицами 3. Вносим данные в таблицы (Рис.3).
Рис.3. Заполнение таблиц Этап подключения к БД 1. Создаем меню из нескольких форм. Для этого размещаем на форме приложения компонент Main Menu и отредактируем его (Рис.4).
Рис.4. Создание меню на главной форме 2. Организовываем доступ к БД через ADOConnection, ADOTable, DataSource. Используя объект DataModule. На DataModule (File – New – DataModule) разместим следующие компоненты (Рис.5): · 1 компонент AdoConnection – связывает Delphi с БД · 3 компонента AdoTable – связывает Delphi с таблицами БД · 1 компонент AdoQuery – SQL-запрос · 4 компонента DataSource – связь между набором данных (AdoTable или AdoQuery) и визуальными компонентами (на вкладке DataAccess)
Рис.5. Объект DataModule 3. Настраиваем компоненты: AdoConnection: · свойство ConnectionString – открывается окно, в нем по нажатию кнопки Build выбираем Microsoft Jet 4.0v OLE DB Provider, потом по кнопке Next – выбираем нашу БД · свойство Login Promt: False · свойство Connected: True Настраиваем таблицы (AdoTable1, AdoTable2, AdoTable3, AdoTable4): · свойство Connection = AdoConnection1, · свойство TableName –указать название таблицы, с которыми установлена связь; · свойство Name – имя по таблице БД. · свойство Active –True. Настроиваем запрос AdoQuery: · свойство Connection = AdoConnection1. DataSource1, DataSource2, DataSource3, DataSource4, DataSource5: · свойство DataSet – выбираем соответствующую таблицу; · свойство Name – имя по таблице БД.
Рис.6. Настройка компонентов Этап работы с SQL-запросами 1. Построить SQL-запросы: · На выборку: SELECT Id_uslugi, Name_uslugi, Stoimost FROM Uslugi WHERE (((Uslugi.Stoimost)> 100)) ORDER BY Name_uslugi; SELECT Id_zakaz, Id_klienta, Id_usluga, Data, Okazanie_uslugi FROM Zakazi WHERE (((Zakazi.Id_zakaz)> 2)) ORDER BY Id_zakaz; · На обновление: UPDATE Услуги SET Name_Uslugi = " Стельки" WHERE Id_uslugi=19; UPDATE Klienti SET FIO = " Аношкина Александра Владимировна" WHERE Id_klienta=1; · На добавление: INSERT INTO Услуги ( Name_uslugi, Stoimost ) VALUES (" Шнурки", 200); INSERT INTO Klienti ( FIO, Adres, Telefon ) VALUES (" Потапова Антонина Сергеевна", " Ленинский 12-96", 347091); · На удаление: DELETE * FROM Uslugi WHERE Id_Uslugi=18;
DELETE * FROM Klienti WHERE Id_klienta=7. Построить запрос по трем таблицам с использованием связи между таблицами и сортировки: SELECT Zakazi.Id_zakaz, Klienti.FIO, Uslugi.Name_uslugi, Zakazi.Okazanie_uslugi FROM Uslugi INNER JOIN (Klienti INNER JOIN Zakazi ON Klienti.Id_klienta = Zakazi.Id_klienta) ON Uslugi.Id_uslugi = Zakazi.Id_usluga ORDER BY Klienti.FIO. Скопировать текст SQL-запроса в буфер обмена для дальнейшей вставки в Delphi. Зайти в Delphi и настроить компонент ADOQuery. В ыбрать на DataModule5 компонент AdoQuery1. Настроить свойства: · свойство Connection = AdoConnection1 (было настроено раньше), · свойство SQL – в редакторе SQL текста вставила текст SQL-запроса из буфера обмена, · свойство Active –True. На главную форму вставить DBGrid. Свойство DataSource настроить на компонент DataSource Query. Запустить программу и проверить ее работоспособность (Рис.10).
Рис.10. SQL-запрос Создать подключение базы данных из текущей папки приложения. Для этого: 1. Отключить свойство Connected компонента AdoConnection. 2. Поместить файл базы данных в папку приложения 3. При настройке компонента AdoConnection: · свойство ConnectionString – открывается окно строки соединения, в нем по нажатию кнопки Build выбираем Microsoft Jet 4.0v OLE DB Provider, потом по кнопке Next – выбираем нашу БД и вместо полного пути с указанием диска и каталогов оставляем только название файла с базой данных.
2. Практические задания Порядок выполнения работы 1) создать БД согласно индивидуального задания в среде MSAccess 2) с использованием ADO компонентов подключить БД в среде Delphi 3) создать полнофункциональное приложение с использованием ADO компонентов
3. Контрольные вопросы 1) Какие компоненты ADO используются для подключения БД 2) Как осуществляется настройка соединения база данных с ADO.
ЛАБОРАТОРНАЯ РАБОТА № 7 Порядок выполнения работы Согласно своей предметной область выполните следующие: 1) Подключите БД с помощью ADO компонентов 2) Создайте простейший редактор таблиц на основе TADODataSet. 3)Используя компоненты TDBNavigator., TDBGrid отобразить содержимое таблиц и навигацию по записям. 4)Для редактирования деталей использовать контейнер TDBCtrlGrid в который поместить TDBLabel, TDBText, TDBComboBox.
Контрольные вопросы: 1) Приведите схему доступа к данным с применением ADO. 2) Какие компоненты Delphi используются для организации доступа к данным по технологии ADO? 3) Как задаются параметры соединения при разработке в Delphi приложения, использующего технологию ADO?
ЛАБОРАТОРНАЯ РАБОТА №8 Порядок выполнения работы 1) Подготовить клиентское приложение, средствами которого необходимо получать информацию следующего плана: - осуществлять выборку данных по параметрам заданным пользователем; - осуществлять выборку данных по определенным признакам (например определенный промежуток времени); - определить основные максимальные и минимальные финансовые или численные показатели; - осуществлять выборку данных по определенным признакам (количество признаков ≥ 3) - определять среднее значение основных показателей;
3. Контрольные вопросы 1) Назовите способы обращения к полю записи. 2) Как ограничить диапазон просматриваемых записей? 3)В каких случаях целесообразно отключать визуальные компоненты от источника данных? 4) Для чего используются процедуры Edit, Post, Insert, Append, Delete? 5) Назовите способы обращения к полю записи.
ЛАБОРАТОРНАЯ РАБОТА №9 Виды форм БД и их создание Формы БД различаются по способу представления информации. Существуют следующие виды форм: Список-форма Она похожа на таблицу, где записи расположены одна под другой. Следует отметить, что для создания такой формы используется компонента DBGrid. Как правило, все поля записи в этой форме размещаются в одну строку. С этой формой очень удобно работать, когда записи короткие Бланк-форма Эта форма похожа на анкету, где все поля одной записи расположены на одном листе. Такая форма используется при отображении больших записей из БД, например анкетной информации о человеке, и позволяет создать очень информативное представление данных за счет дополнительных элементов. Форма с подформой Представляет собой форму, в которой отображаются два или более связанных между собой наборов данных. Эта форма используется для вывода данных из связанных таблиц. В главной форме отображаются записи из одной таблицы, а в подчиненной - записи из другой таблицы, связанные с текущей записью в главной форме. Этот вариант представления данных удобен, когда одной записи в первом наборе данных соответствует несколько записей во втором.
2. Практические задания Порядок выполнения работы 1)Используя исходную БД, спроектируйте экранную форму (приложение), включив в нее все поля и оформив некоторые из них следующим образом:
– комбинированная строка ввода значений поля БД (DBComboBox). - необходимо вывести в формате, например: 15 Апрель 1998 г. – набор варианта значения поля БД (DBRadioGroup). - необходимо вывести в формате, например: 1990 год. – выключатель для полей БД логического типа (DBCheckBox). 2)Создайте и разместите на форме вычисляемое(ые) поле, 3. Контрольные вопросы 1) Компоненты полей. Что это такое? 2) Перечислите основные компоненты полей. 3) Какие поля называют вычисляемыми? 4) Как создать вычисляемое поле? 5) Почему в некоторых случаях вычисляемое поле автоматически не отображается в компоненте DBGrid?
ЛАБОРАТОРНАЯ РАБОТА №10 Проектирование отчетов
Цель работы: получить практические навыки разработки отчетов. Формирование умений и навыков работ ы с компонентом QuickReport 2.0. Получение практических навыков построения отчетов.
Порядок выполнения работы 1) Используя приложение, созданное в лабораторной работе спроектируйте и создайте:
- сводный отчет
- вывод таблиц с использованием группировки
- составление отчета с вычисляемым полем
- составление отчета с использованием агрегатных функций
Контрольные вопросы:
1) Какие компоненты используются при подготовке отчета 2) Изобразите схему, поясняющую состав простого отчета и его взаимосвязи с набором данных 3) Как осуществляется создание вычисляемых полей в отчете
ЛАБОРАТОРНАЯ РАБОТА №11 Приложений
Цель работы: получить практические навыки разработки и подключению запросов. Формирование навыков и умений работы с компонентами TQuery, TStoredProc. ЛАБОРАТОРНАЯ РАБОТА №12 ПРОЕКТИРОВАНИЕ МЕНЮ
Цель работы: Получить практические навыки разработки меню. Формирование навыков и умений работы с компонентами TMainMenu, построения меню. Порядок выполнения работы 1) Используя приложение, созданное ранее, спроектируйте, создайте главное меню, предоставляющее следующие возможности (состав и структуру меню и его подменю определить самостоятельно). - завершение работы - печать отчета, созданного в лабораторной работе - поиск по таблицам - вывод результатов запросов - вывод отсортированных записей по параметру
3. Контрольные вопросы 1) Для чего и как используется свойство Filter компонента Table? 2) Какие используются методы для поиска записи по индексированному (не индексированному) полю? 3) Что такое закладка? 4) Как найти нужную запись? Перечислите разные способы.
ЛАБОРАТОРНАЯ РАБОТА №7 Порядок выполнения работы 1) создать пользователя 2) согласно теме индивидуального задания создать БД 3) заполнить таблицы тестовыми данными 3. Контрольные вопросы 1) Возможности web –интерфейса Oracle Database 10g Express Edition 2) Перечислите некоторые ключевые возможности Oracle Database 10g 3) Какова архитектура сервера базы данных Oracle
Лабораторная работа № 13 Создание пользовательских приложений
Цель работы: Получение практических навыков проектирования и разработки приложений Oracle. Формирования навыков работы в среде Oracle Database 10g Express Edition Порядок выполнения работы - создать на основе индивидуального задания приложения в среде Oracle Database 10g Express Edition 3. Контрольные вопросы Лабораторная работа № 14 Порядок выполнения работы 1)осуществите подсоединение к базе, созданной ранее 2) создайте средствамиSQLplus новую таблицу 3) заполните таблицу данными 4) выполните просмотр данных 5) отсоединетесь от БД 3. Контрольные вопросы 1) Наиболее популярные команды SQL*Plus 2) Использование SQL*Plus для форматированной выдачи 3) Совместное использование команд SPOOL, SAVE и START
ЛАБОРАТОРНАЯ РАБОТА №15 Управление транзакциями Цель работы: Освоение способов управления транзакциями в средах СУБД DB2 и Oracle. Формирование навыков и умений управления транзакциями, Подготовка к работе Подготовить SQL-скрипты для выполнения проверок изолированности транзакций по образцу сценариев, описанных в справке. Ваши скрипты должны работать с таблицами
3. Практические задания 1) Запустить Oracle SQL*Plus. Запустить второй экземпляр Oracle SQL*Plus в отдельном окне. В обоих окнах соединиться с локальной базой данных. |
Последнее изменение этой страницы: 2017-03-14; Просмотров: 557; Нарушение авторского права страницы