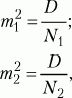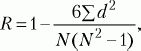|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Вторичная статистическая обработка.
К вторичным относят такие методы статистической обработки, с помощью которых на базе первичных данных выявляют скрытые в них статистические закономерности. Вторичные методы можно подразделить на способы оценки значимости различий и способы установления статистических взаимосвязей. Способы оценки значимости различий. Для сравнения выборочных средних величин, принадлежащих к двум совокупностям данных, и для решения вопроса о том, отличаются ли средние значения статистически достоверно друг от друга, используют t-критерий Стьюдента. Его формула выглядит следующим образом:
где М1, М2 – выборочные средние значения сравниваемых выборок, m1, m2 – интегрированные показатели отклонений частных значений из двух сравниваемых выборок, вычисляются по следующим формулам:
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках. После вычисления значения показателя t по таблице критических значений, заданного числа степеней свободы (N1 + N2 – 2) и избранной вероятности допустимой ошибки (0, 05, 0, 01, 0, 02, 0, 001 и т.д.) находят табличное значение t. Если вычисленное значение t больше или равно табличному, делают вывод о том, что сравниваемые средние значения двух выборок статистически достоверно различаются с вероятностью допустимой ошибки, меньшей или равной избранной. Если в процессе исследования встает задача сравнить не абсолютные средние величины, а частотные распределения данных, то используется χ 2-критерий. Его формула выглядит следующим образом:
где Pk – частоты распределения в первом замере, Vk – частоты распределения во втором замере, m – общее число групп, на которые разделились результаты замеров. После вычисления значения показателя χ 2по таблице критических значений, заданного числа степеней свободы (m – 1) и избранной вероятности допустимой ошибки, делают вывод о том, что сравниваемые распределения данных в двух выборках статистически достоверно различаются с вероятностью допустимой ошибки, меньшей или равной избранной. Для сравнения дисперсий двух выборок используется F-критерий Фишера. Его формула выглядит следующим образом:
где D1, D2 – дисперсии первой и второй выборок, N1, N2 – число значений в первой и второй выборках. После вычисления значения показателя F по таблице критических значений, заданного числа степеней свободы (N1 – 1, N2 – 1) находится Fкр. Если вычисленное значение F больше или равно табличному, делают вывод о том, что различие дисперсий в двух выборках статистически достоверно. Способы установления статистических взаимосвязей. Предыдущие показатели характеризуют совокупность данных по какому-либо одному признаку. Этот изменяющийся признак называют переменной величиной или просто переменной. Меры связи выявляют соотношения между двумя переменными или между двумя выборками. Эти связи, или корреляции, определяют через вычисление коэффициентов корреляции. Однако наличие корреляции не означает, что между переменными существует причинная (или функциональная) связь. Функциональная зависимость – это частный случай корреляции. Даже если связь причинна, корреляционные показатели не могут указать, какая из двух переменных является причиной, а какая – следствием. Кроме того, любая обнаруженная в психологических исследованиях связь, как правило, существует благодаря и другим переменным, а не только двум рассматриваемым. К тому же взаимосвязи психологических признаков столь сложны, что их обусловленность одной причиной вряд ли состоятельна, они детерминированы множеством причин. По тесноте связи можно выделить следующие виды корреляции: полная, высокая, выраженная, частичная; отсутствие корреляции. Эти виды корреляций определяют в зависимости от значения коэффициента корреляции. При полной корреляции его абсолютные значения равны или очень близки к 1. В этом случае устанавливается обязательная взаимозависимость между переменными. Здесь вероятна функциональная зависимость. Высокая корреляция устанавливается при абсолютном значении коэффициента 0, 8–0, 9. Выраженная корреляция считается при абсолютном значении коэффициента 0, 6–0, 7. Частичная корреляция существует при абсолютном значении коэффициента 0, 4–0, 5. Абсолютные значения коэффициента корреляции менее 0, 4 свидетельствуют об очень слабой корреляционной связи и, как правило, в расчет не принимаются. Отсутствие корреляции констатируется при значении коэффициента 0. Кроме того, в психологии при оценке тесноты связи используют так называемую «частную» классификацию корреляционных связей. Она ориентирована не на абсолютную величину коэффициентов корреляции, а на уровень значимости этой величины при определенном объеме выборки. Эта классификация применяется при статистической оценке гипотез. При данном подходе предполагается, что чем больше выборка, тем меньшее значение коэффициента корреляции может быть принято для признания достоверности связей, а для малых выборок даже абсолютно большое значение коэффициента может оказаться недостоверным. По направленности выделяют следующие виды корреляционных связей: положительная (прямая) и отрицательная (обратная). Положительная (прямая) корреляционная связь регистрируется при коэффициенте со знаком «плюс»: при увеличении значения одной переменной наблюдается увеличение другой. Отрицательная (обратная) корреляция имеет место при значении коэффициента со знаком «минус». Это означает обратную зависимость: увеличение значения одной переменной влечет за собой уменьшение другой. По форме различают следующие виды корреляционных связей: прямолинейную и криволинейную. При прямолинейной связи равномерным изменениям одной переменной соответствуют равномерные изменения другой. Если говорить не только о корреляциях, но и о функциональных зависимостях, то такие формы зависимости называют пропорциональными. В психологии строго прямолинейные связи – явление редкое. При криволинейной связи равномерное изменение одного признака сочетается с неравномерным изменением другого. Эта ситуация для психологии типична. Коэффициент линейной корреляции по К. Пирсону (r) вычисляется c помощью следующей формулы:
где х – отклонение отдельного значения X от среднего выборки (Мх), у – отклонение отдельного значения Y от среднего выборки (Му), ϭ х – стандартное отклонение для X, ϭ y – стандартное отклонение для Y, N – число пар значений X и Y. Оценка значимости коэффициента корреляции проводится по таблице критических значений. При сравнении порядковых данных применяется коэффициент ранговой корреляции по Ч. Спирмену (R):
где d – разность рангов (порядковых мест) двух величин, N – число сравниваемых пар величин двух переменных (X и Y). Оценка значимости коэффициента корреляции проводится по таблице критических значений. Внедрение в научные исследования автоматизированных средств обработки данных позволяет быстро и точно определять любые количественные характеристики любых массивов данных. Разработаны различные программы для компьютеров, по которым можно проводить соответствующий статистический анализ практически любых выборок. Из массы статистических приемов в психологии наибольшее распространение получили следующие: 1) комплексное вычисление статистик; 2) корреляционный анализ; 3) дисперсионный анализ; 4) регрессионный анализ; 5) факторный анализ; 6) таксономический (кластерный) анализ; 7) шкалирование. Познакомиться с характеристиками этих методов можно в специальной литературе («Статистические методы в педагогике и психологии» Стенли Дж., Гласса Дж. (М., 1976), «Математическая психология» Г.В. Суходольского (СПб., 1997), «Математические методы психологического исследования» А.Д. Наследова (СПб., 2005) и «Методы математической обработки в психологии» Е.В. Сидоренко (СПБ., 2001) и др.). |
Последнее изменение этой страницы: 2017-04-12; Просмотров: 494; Нарушение авторского права страницы