
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Физическая организация данных вСтр 1 из 5Следующая ⇒
Физическая организация данных в Информационных системах
Методические указания по выполнению лабораторных работ
Дисциплина – «Базы данных» Специальность – 080801.62 «Прикладная информатика»
Допущено ФГБОУ ВПО «Госуниверситет-УНПК» Для использования в учебном процессе в качестве методических указаний для высшего профессионального образования
Орел 2011
Авторы: доцент кафедры «ИС», к.т.н. Д.В. Рыженков доцент кафедры «ИС», к.т.н. С.В. Новиков доцент кафедры «ИС», к.т.н. А.В. Артемов
Рецензент: к.т.н. доцент кафедры «ИС» А.И. Фролов
Данные методические указания содержат справочный материал о способах организации файлов. В процессе выполнения лабораторных работ обучаемые получают практический опыт по работе с файлами, организованными различными способами. Методические указания предназначены для студентов очной (дневной) формы обучения по специальности 0800801.62 «Прикладная информатика».
Редактор _________________ Технический редактор _________________
Федеральное государственное бюджетное образовательное учреждение высшего профессионального образования «Государственный университет – учебно-научно- производственный комплекс» Лицензия ИД 00670 от 5.01.2000
Подписано к печати ___________г. Формат 60 Усл. печ. л. ___. Тираж __ экз. Заказ №____
Отпечатано с готового оригинал-макета
© ФГБОУ ВПО «Госуниверситет-УНПК», 2011 © Рыженков Д.В., Новиков С.В., Артемов А.В., 2011
Введение 4 1. Теоретические сведения 5 1.1 Физическая организация данных. Основные понятия 5 1.2 Эффективность организации блоков в файле 8 1.3 Организация файлов в виде кучи 9 1.4 Эффективность организации файлов в виде кучи 10 1.5 Организация хешированных файлов 11 1.5.1 Статическое хеширование 11 Динамическое хеширование 12 1.6 Операции над хешированными файлами 13 1.7 Эффективность хешированных файлов 14 Индексированные файлы 15 1.9 Операции над индексированными файлами 17 1.10 Эффективность индексированных файлов 21 1.11 Плотное индексирование 21 1.12 B-деревья 21 1. 13 Операции на В-деревьях. 22 1.14 Эффективность В-дерева. 24 Задания на лабораторные работы 25 Задание 1. Организация файла в виде кучи 25 Задание 2. Организация хешированного файла 26 Задание 3. Организация индексного файла 27 Задание 4. Организация файла в виде В-дерева 28 Рекомендуемая литература 31 Введение
Физические модели баз данных определяют способы размещения данных в среде хранения и способы доступа к этим данным, которые поддерживаются на физическом уровне. Исторически первыми системами хранения и доступа были файловые структуры и системы управления файлами, которые фактически являлись частью операционных систем. СУБД создавала над этими файловыми моделями свою надстройку, которая позволяла организовать всю совокупность файлов таким образом, чтобы она работала как единое целое и получала централизованное управление от СУБД. Однако непосредственный доступ осуществлялся на уровне файловых команд, которые СУБД использовала при манипулировании всеми файлами, составляющими хранимые данные одной или нескольких баз данных. Однако механизмы буферизации и управления файловыми структурами не приспособлены для решения задач собственно СУБД, эти механизмы разрабатывались просто для традиционной обработки файлов, и с ростом объемов хранимых данных они стали неэффективными для использования СУБД. Тогда постепенно произошел переход от базовых файловых структур к непосредственному управлению размещением данных на внешних носителях самой СУБД. И пространство внешней памяти уже выходило из-под владения операционных систем и управлялось непосредственно СУБД. Поэтому в данных методических указаниях, посвященных физическим моделям данных, рассмотрим основные файловые структуры, используемые для организации данных во внешней памяти, применяемых в базах данных. Теоретические сведения Физическая организация данных. Основные понятия База данных (БД) – это совместно используемый набор логически связанных данных и описание этих данных, предназначенное для удовлетворения информационных потребностей организации. От того, каким образом физически храниться информация на диске, в большой степени зависит скорость работы с базой данных. Физически база хранится как набор записей, каждая из которых состоит из одного или более полей. В реляционной базе данных каждая такая запись соответствует кортежу отношения, поля записи соответствую атрибутам отношения. Соответственно у записи столько полей и такого типа, сколько полей и какого типа атрибуты отношения.
Пример, Отношение Сотрудник (табельный номер, номер отдела, имя): record num: integer; depNum: integer; name: string [20]; end;
Часто при обсуждении физического хранения БД используется термин файл. В данном случае под файлом понимают набор записей одинакового формата. Под форматом записи понимают список полей с указанием их типов. То есть термин «файл» применяют для обозначения физического представления отношения БД. На самом деле БД может хранится в одном файле операционной системы (СУБД Interbase), во многих файлах, причем для каждого отношения существует свой файл (СУБД Paradox), или независимо от количества файлов, то есть БД может быть размещена в нескольких файлах, одновременно файл может включать несколько баз (СУБД MSSQL 6.5). Рассмотрим организацию записи на диске. Запись включает столько байт, сколько требуется для хранения каждого поля в зависимости от его типа. Кроме того, запись может включать дополнительные байты, не относящиеся к полям. Это необходимо в следующих случаях: 1. Некоторые байты могут свидетельствовать о формате записи. Это необходимо, если совместно могут храниться записи различных форматов. 2. Один или несколько байт могут хранить информацию о длине записи. Это необходимо, если записи могут иметь переменную длину. В записях с постоянной длиной такая информация не храниться, а вычисляется исходя из типов полей. 3. Один бит может отводиться под информацию о том является ли запись удаленной или нет. В некоторых БД записи физически не удаляются, а соответствующий бит переводится в состояние «запись удалена». Такие записи продолжают храниться, но не рассматриваются при построении запросов. В этом случае СУБД должна иметь функцию сборки мусора. Этот процесс запускается в некоторый момент времени и перераспределяет записи, физически удаляя помеченные записи. 4. Бит использования. Он хранит информацию о наличии свободного места. 5. Неиспользуемое пространство. Байты, не хранящие никакой информации. Такие байты необходимы для более удобного чтения записей. Например, для достижения кратности разрядности процессора. Если запись подразумевает такие типы данных как text, image, blob (двоичная информация), то такие данные не хранятся вместе с записью, а хранятся в отдельном блоке. В записи же хранится адрес.
Пример, Пусть храним вышеописанную запись. В файле хранятся записи только одного формата. СУБД обеспечивает сборку мусора. Отношение Сотрудник (табельный номер: integer, номер отдела: integer, фамилия: char(20), фото: image)
Рисунок 1 – Схема записи отношения сотрудник (в байтах)
1 - служебная информация; 2 - 5 – табел. номер; 6 - 9 – номер отдела; 10 - 29 – фамилия; 30 - 33 – ссылка на фото.
Если записи имеют переменную длину: Сотрудник (табельный номер: integer, номер отдела integer, адрес varchar(100)) и СУБД имеет ограничение на длину строки с переменной длиной равной 255 символам (рисунок 2).
Рисунок 2 – Схема записи отношения сотрудник с переменной длинной (в байтах)
1 - служебная информация; 2-5 - табельный номер; 6-9 - номер отдела; 10 - фактическая длина фамилии; 11-109 – байты для хранения фамилии;
Чем больше байт отводится под хранение информации о фактической длине строкового поля, тем длиннее оно может быть. Наиболее быстрая обработка данных была бы возможна, если размещать БД целиком в оперативной памяти. Однако практически размеры БД гораздо больше, поэтому возникает необходимость переноса фрагментов данных с диска (внешней памяти) в оперативную (первичную) память. Поэтому можно говорить, что данные на диске хранятся разделенными на части. Такие части называются блоками или страницами. Размер блока зависит от количества байт, которые считываются с диска за один раз. Чаще всего запись по размеру намного меньше, чем блок (исключения составляют поля типа рисунок и текст, то есть строка неограниченной длины). Поэтому в блоке храниться множество записей. Кроме записей блок включает специальное пространство для указателя. Это связано с тем, что блоки в файле хранятся в виде списка, и каждый блок должен содержать указатель на связанный блок. Таким образом, блок графически можно представить в следующем виде – рисунок 3.
Рисунок 3 – Схема блока
Блок также как и запись может иметь неиспользуемое пространство и служебные байты. Кроме того, может храниться специальный нулевой блок, который содержит служебную информацию. Например, в случае записей одного формата он может включать названия полей (схему отношения) и типы полей. Таким образом, первый блок может иметь формат, отличный от формата остальных блоков.
Поиск. Поиск осуществляется следующим образом. Задается значение ключа и находится запись (или записи), у которой значение ключевого поля совпадает с заданным значением. Понятие ключ здесь не обязательно подразумевает уникальность поля, то есть это не первичный ключ. Если о ключе известно, что он уникален, то поиск прекращается после первой же найденной записи. Вставка. Вставка представляет собой добавление записи в конец файла. Если данные подразумевают наличие первичного ключа, а это должно быть в подавляющем числе случаев, то перед выполнением вставки выполняют операцию поиска. Удаление. При удалении предполагается, что неизвестно, есть ли удаляемая запись в файле, поэтому также необходимо предварительно выполнить операцию поиска. Модификация. Модификация подразумевает изменение одного или нескольких полей определенной записи (записей), а следовательно также требует выполнения операции поиска.
Динамическое хеширование
Перечисленные выше методы хеширования являются статическими, в том смысле, что пространство хеш-адресов задается непосредственно при создании файла. Считается, что пространство файла уже насыщено, когда оно уже почти полностью заполнено и администратор базы данных вынужден реорганизовать его хеш-структуру. Для этого может потребоваться создать новый файл большего размера, выбрать новую хеш-функцию и переписать старый файл во вновь отведенное место. В альтернативном подходе, получившем название динамического хеширования, допускается динамическое изменение размера файла с целью его постоянной модификации в соответствии с уменьшением или увеличением размеров базы данных. Основной принцип динамического хеширования заключается в обработке числа, выработанного хеш-функцией в виде последовательности битов, и распределении записей по сегментам на основе так называемой прогрессирующей оцифровки этой последовательности. Динамическая хеш-функция вырабатывает значения в широком диапазоне, а именно b -битовые двоичные целые числа, где b обычно равно 32. Такой способ организации показан на рисунке 6.
Рисунок 6 – Динамическое хеширование
Индексированные файлы
Еще одним распространенным способом организации файла записей является поддержание файла в отсортированном (по значениям ключей) порядке. Поля целого или десятичного типа сортируются обычным образом. Если поле имеет строковый тип, то используется лексикографическая сортировка. Пример, пусть существуют две последовательности символов X1X2…Xk и Y1Y2…Ym. Где каждый X и Y – отдельный символ. Можно утверждать, что X1X2…Xk < Y1Y2…Ym в двух случаях: 1) k< m и X1X2…Xk = Y1Y2…Yk 2) для некоторого i£ min(k, m) будет иметь место X1=Y1, X2=Y2, …, Xi-1=Yi-1 и код Xi меньше кода Yi. При этом в качестве кода может быть взят ASCII код символов. Согласно этому принципу «свет» < «светлый» или «луг» < «лук». Часто ключ состоит более чем из одного поля. В этом случае сортировка выполняется следующим образом. Производится упорядочивание по первому полю ключа. В результате получиться последовательность, состоящую из групп с одинаковыми значениями начала ключа. Затем внутри каждой группы производится упорядочивание по следующему полю ключа. При этом получаются большее количество более мелких групп. Процесс продолжается до тех пор, пока не образуются группы, включающие по одной записи. В этом случае файл можно просматривать как обычный словарь или телефонный справочник, когда просматриваются лишь заглавные слова или фамилии на каждой странице. Чтобы облегчить процедуру поиска, можно создать второй файл, называемый разреженным индексом, который состоит из пар (x, b), где x - значение ключа, а b - физический адрес блока, в котором значение ключа первой записи равняется х. Разреженный индекс должен быть отсортирован по значениям ключей.
Пример, на рисунке 7 показан основной файл, а так же соответствующий ему файл разреженного индекса. Предполагается, что три записи основного файла (или три пары индексного файла) умещаются в один блок. Записи основного файла представлены только значениями ключей, которые в данном случае является целочисленными величинами.
Рисунок 7 – Основной файл и его разреженный индекс
Чтобы отыскать запись с заданным ключом х, надо сначала просмотреть индексный файл, отыскивая в нем пару (x, b). В действительности отыскивается наибольшее z, такое, что z
Пример, Пусть в блок вмещается по пять записей, тогда схема организации основного файла будет иметь вид представленный на рисунке 8.
Рисунок 8 – Организация основного файла 2. Создание индексного файла. При этом берутся первые записи каждого блока и составляются пары (< значение ключа первой записи блока>, < адрес блока> ). Исключение – первый блок. Для него в индексный файл записывается пара (-¥, адрес первого блока). Это необходимо, чтобы не описывать отдельные алгоритмы для работы со значениями ключа, меньшими, чем все существующие в файле на данный момент. Схема организации индексного файла представлена на рисунке 9.
Рисунок 9 – Организация индексного файла
3. Организация блоков индексного файла. Так как индекс может потребовать пространство большее, чем один блок, то необходимо выбрать организацию этого файла. Будем считать, что индексный файл организован в виде кучи. Поиск. Пусть v1 значение ключа искомой записи. Тогда в индексе необходимо найти запись (v2, b), такую что, v2£ v1. И либо v2 – последняя запись в индексе, либо следующие записи имеют вид (v3, b), причем v1< v3. В этом случае говорят, v2 покрывает v1. Таким образом, находится блок, в котором может находиться запись со значение ключа v1. Согласно адресу в записи (v2, b) извлекается блок основного файла. Искомая запись находится либо в этом блоке, либо она вовсе отсутствует в файле. Таким образом, в целом скорость поиска зависит от скорости поиска в индексном файле записи, покрывающей ключ. Существует три основных вида поиска: 1. Линейный поиск. При данном виде поиска, последовательно перебираются все блоки и все записи индекса. Даже при такой организации поиска в индексе получается выигрыш в скорости доступа по сравнению с остальными видами файлов. Так, если в главном файле содержится R записей в блоке, то по сравнению с организацией его в виде кучи, поиск будет происходить в R раз быстрее. 2. Двоичный поиск. Основой для применения этого метода служит никогда не нарушаемое упорядочивание записей не только в основном файле, но и в индексе. Пусть В1, В2, …, Вm – блоки индексного файла. Первые записи в этих блоках (индекса) V1, V2, …, Vm. Необходимо найти запись с ключом V. Сначала извлекается блок Bm/2. Необходимо сравнить значение Vm/2 со значением V. Если V< Vm/2, то продолжается поиск, в блоках В1-Вm.2-1, если V³ Vm/2, то поиск необходимо провести в блоках Bm/2…Bm. Процесс деления продолжается пока не останется один блок. Далее в этом блоке ищется запись, покрывающая V, с использованием линейного поиска. В результате потребуется Log2M обращений к индексному файлу. 3. Интерполирующий поиск. В этом случае кроме упорядочивания записей в индексе важную роль играет знание статистики распределения значений ключей. При работе этого метода должна существовать функция f(V1, V2, V3). Эта функция возвращает в качестве результата блок, в котором может находиться запись со значением ключа равной V1, если известно, что V1 находится между значениями V2 и V3. Поиск продолжается пока не останется один блок, затем в нем перебором ищется покрывающая V1 запись. Потребуется 1+ Log2Log2M доступов к индексу. Модификация. Если изменяется не ключевое поле записи основного файла, то выполняется операция поиска, в результате которой буден считан блок основного файла, в котором должна располагаться искомая запись, в случай ее наличия производиться ее модификация, и блок основного файла перезаписывается на диск. Если необходимо произвести модификацию ключевого поля, то необходимо выполнить операции, характерные для операций вставки и удаления, так как операция модификации не должна нарушать сортировки ни в основном, ни в индексном файле. Вставка. Для вставки записи с ключом V1 в индексированный файл выполняется операция поиска блока Bi, в который должна быть помещена новая запись. После чего, необходимо определить позицию записи в нутрии найденного блока. Это выражается в сохранении сортировки после выполнения операции вставки. Поэтому все записи блока, имеющие ключи больше V1 сдвигаются вправо. При этом освобождается место под V1. Если в блоке Bi нет свободного места, то необходимо проверить блок Bi+1. Найти этот блок можно, используя запись в индексном файле (она следует за записью, покрывающую v1 ). Если в Bi+1 блоке есть свободное место, то последняя запись блока Bi переносится в качестве первой в блок Bi+1, после чего в обоих блоках записи сдвигаются вправо, и запись V1 помещается в требуемую позицию в блоке Bi. Также в этом случае необходимо произвести изменение в блоке индексного файла, так как изменилось значение ключа первой записи блока Bi+1 . Если в блоке Bi+1 много свободного места, то все записи (вместе с новой) двух блоков, делятся пополам и размещаются в них поровну. При этом также необходимо перезаписать оба блока и внести изменения в файл индекса. Если блок Bi+1 заполнен, или не существует (то есть Bi – последний), то аналогичную последовательность действий производят с блоком Bi-1. Если Bi – первый, или Bi-1 также заполнен, то к файлу добавляют новый блок. После чего записи Bi распределяют поровну между Bi и новым блоком и в индексный файл добавляют новую запись для нового блока, при этом не нарушается сортировка в индексном файле. Таким же производится сдвиг всех записей индекса и на освободившееся место записывается новое значение. Если индекс занимает более чем один блок, то также могут потребоваться операции перемещения записей индекса между блоками и присоединения нового блока к файлу. При организации вставки в индексированный файл можно принять единую стратегию, когда при заполнении блока i, не проверяется ни i+1, ни i-1 блоки, а сразу захватывается новый блок. Это упрощает и несколько ускоряет процедуру вставки. Однако такая стратегия увеличивает общее число блоков и нарушает их порядок. Удаление. При удалении производится процедура поиска записи, в результате которого искомая запись удаляется, и все записи блока смещаются влево. Если после удаления блок остается пустым, то его возвращают файловой системе. Если удаляется первая запись блока, то необходимо модифицировать соответствующую запись индекса. Если операция удаления записи завершилась удалением блока основного файла, то соответствующую запись в индексе также необходимо удалить, сдвинув все записи индекса влево.
Плотное индексирование
Индексирование, рассмотренное выше, называется разреженным индексированием. Существует другой вид индексирования широко распространенный в реальных СУБД – плотное индексирование. В этом случае индексные файлы содержат пары вида (v, p), где первый элемент – значение ключа, а второй – адрес записи в основном файле с этим ключом. Такой подход не требует обязательного упорядочивания записей по индексируемому полю, а так же не обязательна уникальность ключа. Поэтому подход плотного индекса применим для ускорения поиска по любым полям, позволяя построить несколько независимых индексов. При организации таких файлов скорость доступа будет 2+время поиска в файле индекса.
B-деревья При увеличении числа блоков, занятых индексом в разреженных индексированных файлах, снижается эффективность работы. Структура, называемая В–деревом, позволяет избежать такого снижения путем построения индекса для индекса, и при необходимости далее, пока верхний индекс не будет помещаться в один блок. Таким образом, получается иерархическая структура индексов - рисунок 10.
Рисунок 10 – В-дерево степени 5
В В-дереве узел может иметь много сыновей (на практике до тысячи). Количество сыновей (максимальное) определяет степень В-дерева. Узел х, хранящий n[x] ключей, имеет n[x]+1 сыновей. Хранящиеся в х ключи служат границами, разделяющими всех потомков узла на n[x]+1 групп. За каждую группу отвечает один из сыновей х. При организации В–деревьев не должно быть узлов, заполненных меньше, чем наполовину. Структура В–дерева отличается от простой иерархии индексов следующим соглашением: в индексных блоках В–деревьев значения ключей в первой записи пропускаются. При поиске полагают, что все значения, меньшие второго значения в индексе, покрываются отсутствующим первым значением ключа. Операции на В-деревьях. Поиск. Пусть необходимо найти запись со значением ключа V. При этом нужно найти путь от корня дерева до конкретного листа, в котором должна находиться запись v, если она существует в файле. Поиск начинается с корня дерева и продолжается по иерархии индексов, выстраивая путь. Пример. Текущий узел=корень. While текущий узел не лист Begin Путь=Путь + Текущий узел Адрес = адрес из записи, покрывающей значение v. Текущий узел=извлечь блок(адрес) end; Путь=Путь + Текущий узел
В результате текущий блок является блоком основного файла, поэтому искомая запись со значением v ищется в нем. Модификация. Если модификация затрагивает первичный ключ, то необходимо выполнить операции удаления и вставки. Если модифицируются не ключевые атрибуты, то выполняется операция поиска, после чего вносятся изменения в поля записи, и блок перезаписывается на диск. Вставка. Изначально необходимо найти блок В, в котором должна располагаться новая запись. Если В содержит меньше, чем 2е-1 записей, то запись размещается в блоке так, чтобы не нарушить сортировку. Очевидно, что новая запись не будет первой записью блока, кроме случая самого левого блока. Следовательно, нет необходимости изменять значения ключей в индексных блоках по иерархии. Если в блоке уже 2е-1 записей, то в файле выделяется новый блок В1 и все записи блока В делятся поровну между блоками В и В1 (первые е записей остаются в блоке В, остальные переносятся в В1 ). При начальном поиске уже был найден путь от корня до блока В1. Теперь необходимо повторить процедуру вставки для всех блоков в обратном направлении к корню для регистрации блока В1 в индексах. В результате на определенном уровне индексный блок также может разделиться, если до вставки в нем уже было 2d-1 записей. Процесс разделения блоков может затронуть и корневой блок, в этом случае увеличивается количество уровней иерархии, так как в корне дерева должен лежать только один блок. Удаление. При удалении необходимо найти блок В, в котором содержится запись v. Если после удаления в блоке осталось е или более записей, то после удаления найденной записи и сдвига всех остальных операция закончена. Если удаляемая запись является первой в блоке, то необходимо изменить значения в блоках в направлении обратном найденному пути. При этом необходимо учитывать следующее. Если В первый потомок своего предка, то предок не включает значения для ключа первой записи блока В. В этом случае нужно проверить предка предка и так далее, пока не найдется блок-предок А1 для В, такой что, А1 – не первый потомок своего предка А2. Тогда новое меньшее значение ключа блока В записывают в блок А2 вместе с адресом блока А1. Если после удаления блок В содержит е-1 запись, то необходимо найти блок В1, имеющий того же родителя, что и В и расположенный непосредственно слева или справа от В. Если блок В1 содержит более е записей, то необходимо перераспределить записи блоков В и В1 поровну с сохранением порядка. Далее необходимо внести изменения в записи общего предка. Если в блоке В1 содержится только е записей, то блоки В и В1 должны быть объединены. После этого в общем предке В и В1 при необходимости изменяется информация о блоке В1 и удаляется информация о блоке В. Если в предке В1 оказывается d записей, то необходимо повторить ту же операцию, но уже на индексных блоках. В результате выполнения таких действий с блоками пути, построенного в результате поиска, возможно уменьшение числа уровней индексов.
Эффективность В-дерева.
Пусть главный файл содержит n записей, а e и d – параметры организации В–дерева. Тогда листьев в дереве будет не больше чем n/e, так как е – наименьшее число записей в одном блоке. Предков листьев будет n/de, предков предков листьев n/d2e, и так далее. Если путь от корня до листьев содержит i узлов, то для количества блоков последнего уровня будет ровняться n/di-1e. Так как известно, что в В–дереве только один блок является корнем, то следовательно n/di-1e равняется 1, из этого следует что, n равняется di-1e, и i равняется 1+Logd(n/e), так как d и e по определению минимальны, то i меньше или равно 1+Logd(n/e). То есть, максимальное число обращений к диску при поиске будет 1+Logd(n/e). При вставке данное значение увеличивается на 1 (для записи блока).
Задания на лабораторные работы Задание 1. Организация файла в виде кучи
Написать программу, которая работает с организованным в виде кучи файлом, хранящем информацию об отношении «студент». В программе должны быть реализованы следующие функции: · добавление информации о студент; · изменение информации о студенте; · удаление информации о студенте; · осуществление поиска информации о студенте. Отношение студент должно содержать следующие атрибуты: номер зачетки (тип integer), фамилия (тип string(30)), имя (тип string(20)), отчество (тип string(30)), номер группы (тип integer). Для организации хранения информации о записи в файле необходимо использовать тип Zap. Type Zap = record Id_zachet, id_gr: integer; Surname, Name: string (20); Patronymic: string(30); End; Блок файла должен включать 5 записей. Type Block = record Zap_block: array[1..5] of zap; End; Для хранения схемы отношения в файле должен использоваться нулевой блок. Программа должна работать с любым файлом, организованным по данной схеме.
Контрольные вопросы 1. Что такое запись? 2. Какие дополнительные байты может содержать запись? 3. Что такое блок? 4. В чем особенности организации файлов в виде кучи? 5. Эффективность рабы с файлом, организованным в виде кучи. Задание 2. Организация хешированного файла
Написать программу, которая работает с хешированным фалом хранящем информацию об отношении «студент». В программе должны быть реализованы следующие функции: · добавление информации о студент; · изменение информации о студенте; · удаление информации о студенте; · осуществление поиска информации о студенте. Отношение студент должно содержать следующие атрибуты: номер зачетки (тип integer), фамилия (тип string(30)), имя (тип string(20)), отчество (тип string(30)), номер группы (тип integer). Атрибут «номер зачетки» выступает в роли первичного ключа. В качестве хеш-функции необходимо использовать остаток от деления первичного ключа на 4. Для организации хранения информации записи в файле необходимо использовать тип Zap. Type Zap = record Id_zachet, id_gr: integer; Surname, Name: string (20); Patronymic: string(30); End; Каждый блок – это запись из массива записей и указателя на следующий блок. Блок файла должен включать 5 записей. Type Block = record Zap_block: array[1..5] of zap; Nextb: integer; End; Для хранения схемы отношения в файле должен использоваться нулевой блок. Информация о каталоге бакетов также должна размещаться в нулевом блоке. Type Block0 = record Relation_scheme: string(255); Catalog: array[0..4]of record nf, nl: integer; End; End; Переменная nf – номер первого блока в бакете, переменная nl – номер последнего блока в бакете. В пределах каждого бакета, блоки записываются как в файле в виде кучи. Программа должна работать с любым файлом, организованным по данной схеме.
Контрольные вопросы 1. Что такое бакет? 2. Что такое каталог бакетов? 3. Что такое хеш-функция? 4. В чем особенности организации хешированных файлов? 5. Причины снижения эффективности хешированных файлов. 6. Что такое динамическое хеширование? 7. Эффективность работы хешированных файлов.
Задание 3. Организация индексного файла
Написать программу, которая организует хранение информации об отношении «студент» в виде разреженного индексируемого файла. В программе должны быть реализованы следующие функции: · добавление информации о студент; · изменение информации о студенте; · удаление информации о студенте; · осуществление поиска информации о студенте. Отношение студент должно содержать следующие атрибуты: номер зачетки (тип integer), фамилия (тип string(30)), имя (тип string(20)), отчество (тип string(30)), номер группы (тип integer). Атрибут «номер зачетки» выступает в роли первичного ключа. Информация о студентах храниться в основном файле, а индексы хранятся в файле индексов (отдельно). Для организации хранения записей основного файла необходимо использовать тип Zap. Type Zap = record Id_zachet, id_gr: integer; Surname, Name: string (20); Patronymic: string(30); End; Каждый блок – это запись из массива записей и указателя на следующий блок. Блок файла содержит 5 записей. Type Block = record Zap_block: array[1..5] of zap; End; Для хранения схемы отношения в файле используется нулевой блок. Записи об индексах хранятся аналогично записям отношения. В индексном блоке помещается по 10 записей. Индексирование производиться по ключевому атрибуту. Программа должна работать с любым файлом, организованным по данной схеме.
Контрольные вопросы 1. В чем суть организации индексированных файлов? 2. В чем суть процесса инициализации? 3. Чем плотное индексирование отличается от разреженного? |
Последнее изменение этой страницы: 2017-04-12; Просмотров: 817; Нарушение авторского права страницы
 84 1/16
84 1/16 Содержание
Содержание 



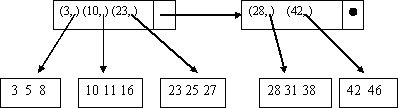
 x и далее находится пара (z, b). В этом случае ключ х оказывается в блоке b (если такой ключ вообще присутствует в данном файле).
x и далее находится пара (z, b). В этом случае ключ х оказывается в блоке b (если такой ключ вообще присутствует в данном файле).

