|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Использование фильтров в сводной таблице
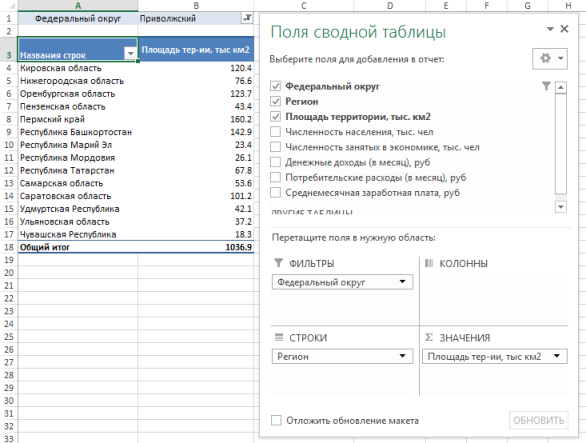
Часто нам необходимо создать отчет для разных типов данных, к примеру, проанализировать только конкретные округи. Вместо того, чтобы тратить время на изменения исходных данных, воспользуемся областью фильтры. Перетащите поле Федеральный округ в область Фильтры. Теперь вы можете менять внешний вид сводной таблицы, задав фильтр на нужном округе.
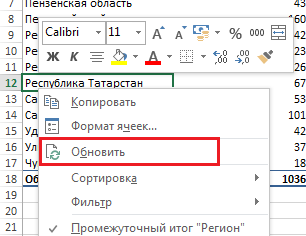
Обновление сводной таблицы Со временем исходные данные изменяются, к ним добавляются новые строки и колонки. Для обновления сводной таблицы выпользуйте командой Обновить, для этого щёлкните правой кнопкой мыши на любом месте таблицы и выберите Обновить.
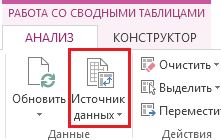
Бывают ситуации, когда структура исходных данных меняется, к примеру, вам необходимо добавить новые строки в таблицу с данными. Этот тип изменений повлияет на диапазон источника данных, и об этом необходимо сообщить сводной таблице. Простое обновление не сработает, в данном случае необходимо расширить диапазон источника данных. Щелкаем левой кнопкой мыши в любом месте сводной таблицы. Идем во вкладку Работа со сводными таблицами -> Анализ –> Источник данных.
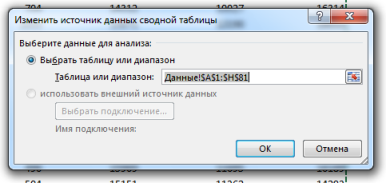
В появившемся диалоговом окне Изменить источник данных сводной таблицы задаем изменившийся диапазон данных.
Функции MS EXCEL: логические, статистические временные, текстовые математические. Логические функции Excel одобного рода функциями служат такие, которые возвращают результат после проверки данных, который всегда представляет «ИСТИНА» либо «ЛОЖЬ», что означает – результат удовлетворяет заданному условию либо не удовлетворяет, соответственно. Прежде чем перейти к рассмотрению описанных функций, ознакомьтесь со статьей нашего сайтаУсловия сравнения чисел и строк в Excel. В описаниях синтаксиса функций их аргументы, которые заключены в квадратные скобки «[]», являются необязательными. Будут рассмотрены следующие функции:
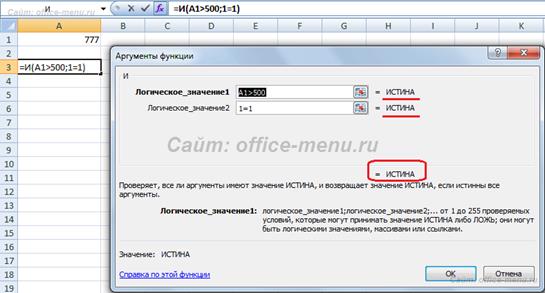
Функция ИСТИНА Не принимает никаких аргументов и просто возвращает логическое значение «ИСТИНА». Синтаксис: =ИСТИНА() Функция ЛОЖЬ Аналогична функции ИСТИНА, за исключением то, что возвращает противоположный результат ЛОЖЬ. Синтаксис: =ЛОЖЬ() Функция И Возвращает логическое значение ИСТИНА, если все аргументы функции вернули истинное значение. Если хотя бы один аргумент возвращает значение ЛОЖЬ, то вся функция вернет данное значение. В виде аргументов должны приниматься условия либо ссылки на ячейки, возвращающие логические значения. Количество аргументов не может превышать 255. Первый аргумент является обязательным. Рассмотрим таблицу истинности данной функции:
Синтаксис: =И(Логическое_значение1; [Логическое_значение1]; …) Пример использования: В первом примере видно, что все аргументы возвращают истинное значение, следовательно, и сама функция вернет истинный результат.
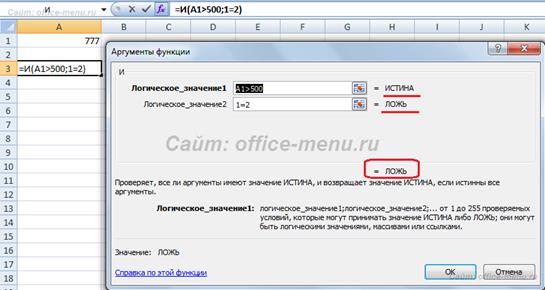
Во втором примере функция никогда не вернет значение ИСТИНА, т.к. условие ее второго аргумента заранее неравно.
Функция ИЛИ Возвращает логическое значение ИСТИНА, если хотя бы один аргумент функции вернет истинное значение. В виде аргументов принимаются условия либо ссылки на ячейки, возвращающие логические значения. Количество аргументов не может превышать 255. Первый аргумент является обязательным. Таблица истинности функции ИЛИ:
Синтаксис: =ИЛИ(Логическое_значение1; [Логическое_значение2]; …) В качестве примера, рассмотрите примеры функции И, все они вернут результат ИСТИНА, т.к. первый аргумент является истинным. Функция НЕ Принимает в виде аргумента всего одно логическое значение и меняет его на противоположное, т.е. значение ИСТИНА она изменит на ЛОЖЬ и наоборот. Таблица истинности функции И с применением функции НЕ:
Таблица истинности функции ИЛИ с применением функции НЕ:
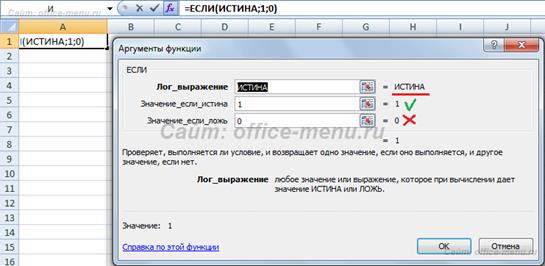
Синтаксис: =НЕ(логическое_значение) Функция ЕСЛИ Является одной из самых полезных, имеющихся в Excel, функций. Она проверяет результат переданного ей логического выражения и возвращает результаты в зависимости от того истинно он или ложно. Синтаксис: =ЕСЛИ(Логическое_выражение; [Значение_если_истина]; [Значение_если_ложь]) Примеры использования функции: Рассмотрим первый простой пример, чтобы понять, как функция работает. Умышлено в первый аргумент функции вставить функцию ИСТИНА. В результате проверки, будет возвращен 2 аргумент (значение_если_истина), 3 аргумент будет опущен.
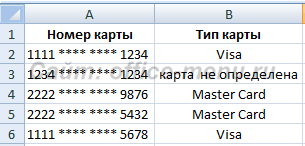
Теперь приведем пример использования вложенности одной функции ЕСЛИ в другую. Такой подход может понадобиться, когда при выполнении (или невыполнении) одного условия требуется дополнительная проверка. Условия примера: Имеются банковские карточки с номерами, начинающимися с первых четырех цифр, которые являются идентификатором вида карты:
Используем нашу функцию для определения типа карты.
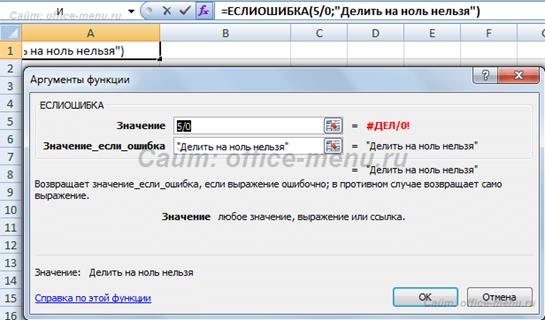
Функция, применяемая в данном примере, выглядит так: = ЕСЛИ ( ЛЕВСИМВ(A2; 4)=" 1111"; " Visa"; ЕСЛИ ( ЛЕВСИМВ(A2; 4)=" 2222" ; " Master Card"; " карта не определена" )) Помимо самой рассматриваем функции, в примере используется текстовая функция ЛЕВСИМВ, которая возвращает часть текста из строки, начиная с левого края, в количестве символов, заданном вторым ее аргументом. С ее помощью мы проверяем, являются ли они равными строке «1111», если да, возвращаем результат «Visa», если нет, то выполняем вложенную функцию ЕСЛИ. Подобным образом можно достичь значительной вложенности и организовывать сложные проверки. Функция ЕСЛИОШИБКА Предназначена для проверки возврата выражением ошибки. Если ошибка обнаружена, то она возвращает значение второго аргумента, иначе первого. Функция принимает 2 аргумента, все они являются обязательными. Синтаксис: =ЕСЛИОШИБКА(значение; значение_если_ошибка) Пример использования функции: В приведенном примере видно, что выражение в первом аргументе возвращает ошибку деления на ноль, но так как оно вложено в нашу функцию, то ошибка перехватывается и подменяется вторым аргументов, а именно строкой «Делить на ноль нельзя», которую мы ввели самостоятельно. Вместо данной строки могли бы быть другие функции, все зависит от поставленной перед Вами задачи.
Статистические функции Применение статистических функций облегчает пользователю статистический анализ данных. Количество доступных статистических функций в седьмой версии программы увеличилось, и можно утверждать, что по спектру доступных функций Excel сегодня почти не уступает специальным программам обработки статистических данных. Для того чтобы иметь возможность использовать все статистические функции, следует загрузить надстройку Пакет анализа. Основу статистического анализа составляет исследование совокупностей и выборок. Выборка представляет собой подмножество совокупности. В качестве примера выборки можно привести опросы общественного мнения. Исследуя выборки с помощью вычисления отклонений и отслеживания взаимосвязей с генеральной совокупностью, можно проследить, насколько репрезентативна выборка. Целый ряд статистических функций Excel предназначен для анализа вероятностей. Ниже приведено описание некоторых наиболее распространенных функций. Информацию о других функциях пользователь может найти в справочной подсистеме.
FРАСП Синтаксис: FРАСП(х, степени_свободы1, степени_свободы2) Результат: F-распределение вероятности. Эту функцию можно использовать, чтобы определить, имеют ли два множества данных различные степени плотности. Например, можно исследовать результаты тестирования мужчин и женщин, окончивших высшую школу, и определить, зависит ли разброс результатов от пола. Аргументы: · х - значение, для которого вычисляется функция; · степени_свободы1 - числитель степеней свободы; · степени_свободы2 - знаменатель степеней свободы.
ВЕРОЯТНОСТЬ Синтаксис: ВЕРОЯТНОСТЬ(х_интервал, интервал_вероятностей, нижний_предел, верхний_предел) Результат: Значение вероятности того, что значение из интервала находится внутри заданных пределов. Вели аргумент верхний_предел не задан, то возвращается значение вероятности того, что значения в аргументе х_интервал равны значению аргумента нижний_предел. Аргументы: · х_интервал- интервал числовых значений х; · интервал_вероятностей- множество вероятностей возникновения значений, входящих в аргумент х_интервал; · нижний_предел- нижняя граница значения, для которого вычисляется вероятность; · верхний_предел- необязательная верхняя граница значения, для которого требуется вычислить вероятность.
ДИСП Синтаксис: ДИСП(число1, число2, ...) Результат: Дисперсия выборки. Аргументы рассматриваются как выборка из генеральной совокупности. Аргументы: · число1, число2,... - не более 30 аргументов; текстовые, логические и пустые поля приводят к ошибке.
ДИСПР Синтаксис: ДИСПР(число1, число2, ...) Результат: Дисперсия генеральной совокупности. Аргументы представляют всю генеральную совокупность. Аргументы: · число1, число2,... - не более 30 аргументов; текстовые, логические и пустые поля приводят к ошибке.
ДИСПА Синтаксис: ДИСПА(значение1, значение2, ...) Результат: Дисперсия выборки. Аргументы рассматриваются как выборка из генеральной совокупности, содержащей наряду с числовыми и логические значения, а также текст. Аргументы: См. описание функции СТАНДОТКЛОНА. ПРИМЕЧАНИЕ Вычисления производятся по той же формуле, что и в функции ДИСП, однако учитываются ячейки с текстовыми и логическими значениями.
ДИСПРА Синтаксис: ДИСПРА(значение1, значение2,...) Результат: Дисперсия генеральной совокупности. Аргументы представляют всю генеральную совокупность. Аргументы: См. описание функции СТАНДОТКЛОНА. ПРИМЕЧАНИЕ Вычисления производятся по той же формуле, что и в функции ДИСПР, однако учитываются ячейки с текстовыми и логическими значениями.
ДОВЕРИТ Синтаксис: ДОВЕРИТ(альфа, станд_откл, размер) Результат: Доверительный интервал для среднего генеральной совокупности. Доверительный интервал - окрестность среднего выборки (интервал, содержащий значение среднего выборки, равноудаленное от концов интервала). Например, заказав товар по почте, вы можете определить с конкретным уровнем надежности самую раннюю и самую позднюю даты его прибытия. Аргументы: · альфа - уровень значимости, используемый для вычисления уровня надежности (уровень надежности равен 100*(1 - альфа)%\ другими словами, значение альфа, равное 0, 05, означает уровень надежности, равный 95%); · станд_откл - стандартное отклонение генеральной совокупности для интервала данных (предполагается известным); · размер - размер выборки.
КВАДРОТКЛ Синтаксис: КВАДРОТКЛ(число1, число2, ...) Результат: Сумма квадратов отклонений точек данных от их среднего. Аргументы: · число1, число2, ... - от 1 до 30 аргументов, для которых вычисляется сумма квадратов отклонений; в функции КВАДРОТКЛ вместо аргументов можно использовать массив или ссылку на массив.
КВПИРСОН Синтаксис: КВПИРСОН(известные_значения_у, известные_значения_х) Результат: Квадрат коэффициента корреляции Пирсона для точек данных в аргументах известные_значения_у и известные_значения_х. Значение r-квадрат можно интерпретировать как отношение дисперсии для у к дисперсии для х. Аргументы: · известные_значения_у - массив или интервал точек данных; · известные_значения_х - массив или интервал точек данных.
КОВАР Синтаксис: КОВАР(массив1, массив2) Результат: Ковариация (среднее произведений отклонений для каждой пары точек данных). Ковариация используется для определения связи между двумя множествами данных. Например, можно проверить, соответствует ли более высокому уровню доходов более высокий уровень образования. Аргументы: · массив1 - первый массив или интервал данных; · массив2 - второй массив или интервал данных.
КОРЕЛ Синтаксис: КОРЕЛ(массив1, массив2) Результат: Коэффициент корреляции между интервалами ячеек аргументов массив1 и массив2. Коэффициент корреляции используется для определения наличия взаимосвязи между двумя свойствами. Например, можно установить зависимость между средней температурой в помещении и наличием кондиционера. Аргументы: · массив1 - первый массив интервала данных; · массив2 - второй массив интервала данных.
ЛГРФПРИБЛ Синтаксис: ЛГРФПРИБЛ(известные_значения_у, известные_значения_х, конст, статистика) Результат: Возвращает матрицу, описывающую экспоненциальную кривую (у = bm/\х), которая была рассчитана из заданных значений: первое значение результирующей матрицы есть основание экспоненты (т), второе значение - коэффициент (Ь). Аргументы: · известные_значения_у - множество значений у (если массив известные_значения_у имеет один столбец, то каждый столбец массива известные_значения_х интерпретируется как отдельная переменная; если массив извест-ные_значения_у имеет одну строку, то каждая строка массива известные_значения_х интерпретируется как отдельная переменная); · известные_значения_х - необязательное множество значений х, которые уже известны для соотношения у = mх + b (массив известиые_знанения_х может содержать одно или несколько множеств переменных; если используется только одна переменная, то аргументы известные_значения_у известные_значения_х могут быть массивами любой формы при условии, что они имеют одинаковую размерность; если используется более одной переменной, то аргумент извест-ные_значения_у должен быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец); если аргумент известные_значения_х опущен, то предполагается, что это массив {1; 2; 3;...} такого же размера, как и массив известные_значе-ния_у); · конст - логическое значение; если аргумент отсутствует или имеет значение ИСТИНА, то b вычисляется обычным способом; если аргумент имеет значение ЛОЖЬ, то Ь полагается равным 1 и знамения т подбираются так, чтобы выполнялось соотношение у = m/\х; · статистика - логическое значение, которое указывает, требуется ли возвращать дополнительную статистику по регрессии (если аргумент имеет значение ИСТИНА, то функция ЛГРФПРИБЛ возвращает дополнительную регрессионную статистику, так что возвращаемый массив будет иметь вид: {mn; mn-1;...; m1; b: sen; sen-1;...; se1; seb: r2; sey: F; df: ssreg; ssresid}; если аргумент имеет значение ЛОЖЬ или опущен, то функция ЛГРФПРИБЛ возвращает только коэффициенты т и постоянную Ь).
ЛИНЕЙН Синтаксис: ЛИНЕЙН(известные_значения_у, известные_значения_х, конст, статистика) Результат: Эта функция использует метод наименьших квадратов, чтобы найти уравнение прямой линии, которая наилучшим образом аппроксимирует имеющиеся данные. Функция возвращает массив, который описывает полученную прямую. Уравнение прямой линии имеет следующий вид: у = m1*1+m2*2+...+b или у=mх+b где зависимое значение у является функцией независимого значения х, т - матрица значений углового коэффициента результирующей прямой, а Ь - абсцисса точки пересечения прямой с Y-осью. Аргумент ЛИНЕЙН может также возвращать дополнительную регрессионную статистику. Аргументы: См. функцию ЛГРФПИБЛ. ЛОГНОРМОБР Синтаксис: ЛОГНОРМОБР(вероятность, среднее, стандартное_отклонение) Результат: Обратная функция логарифмического нормального распределения х, где 1/\(х) имеет нормальное распределение с параметрами среднее и стандартное> _отклотние. Если р = ЛОГНОРМОБР(х,...), то ЛОГНОРМОБР(p,...)= х, Логарифмическое нормальное распределение используется для анализа логарифмически преобразованных данных. Аргументы: · вероятность - вероятность, связанная с нормальным логарифмическим распределением; · среднее - среднее ln(x); · стандартное_отклонение - стандартное отклонение ln(х).
МАКС Синтаксис: МАКС(число1, число2, ...) Результат: Наибольшее значение в списке аргументов. Аргументы: · число1, число2, ... - от 1 до 30 чисел, среди которых ищется максимальное значение. Можно задавать аргументы, которые являют -ся числами, пустыми ячейками, логическими значениями или текстовыми представлениями чисел; аргументы, которые являются значениями ошибки или текстами, не преобразуемыми в числа, приводят к появлению значений ошибки. Если аргумент является массивом или ссылкой, то в нем учитываются только числа. Пустые ячейки, логические значения, тексты или значения ошибок в массиве или ссылке игнорируются. Если аргументы не содержат чисел, то функция МАКС возвращает 0.
МЕДИАНА Синтаксис: МEДИАНА(число1, число2, ...) Результат: Медиана заданного множества чисел (число, которое является серединой множества чисел: половина чисел больше, чем медиана, а половина чисел меньше, чем медиана). Аргументы: · число1, число2, ... - числа или имена, массивы или адресные ссылки на диапазон ячеек, содержащий ссылки.
МИН Синтаксис: МИН(число1, число2, ...) Результат: Наименьшее значение в списке аргументов. Аргументы: · число1, число2, ... - не более 30 аргументов; игнорируются только значения ошибки и текст, который не может быть преобразован в числа; если ни один аргумент не содержит чисел, функция МИН возвращает 0.
МОДА Синтаксис: МОДА(число1, число2, ...) Результат: Наиболее часто встречающееся значение в массиве или интервале данных. Так же, как и функция МЕДИАНА, функция МОДА является мерой взаимного расположения значений. Аргументы: · число1, число2, ... - от 1 до 30 аргументов, для которых вычисляется функция МОДА; в функции МОДА можно использовать вместо аргументов массив или ссылку на массив.
НОРМАЛИЗАЦИЯ Синтаксис: НОРМАЛИЗАЦИЯ(х, среднее, стандартное_откл) Результат: Нормализованное значение для распределения, характеризуемого средним и стандартным отклонением. Аргументы: · х - нормализуемое значение; · среднее - среднее арифметическое распределения; · стандартное_откл стандартное отклонение распределения. ПРИМЕЧАНИЕ Аргументы должны быть числами или именами, массивами или ссылками, содержащими числа. Microsoft Excel проверяет все числа, содержащиеся в аргументах, которые являются массивами или ссылками. Если аргумент, который является ссылкой, содержит пустые ячейки, текстовые или логические значения, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются.
НОРМРАСП Синтаксис: НОРМРАСП(х, среднее, стандартное_откл, интегральная) Результат: Нормальная функция распределения для указанного среднего и стандартного отклонения. Эта функция имеет очень широкий диапазон применения в статистике, включая проверку гипотез. Аргументы: · х - значение, для которого строится распределение; · среднее - среднее арифметическое распределения; · стандартное_откл - стандартное отклонение распределения; · интегральная - логическое значение, определяющее форму функции (если аргумент интегральная имеет значение ИСТИНА, то функция НОРМРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, то возвращается функция плотности распределения).
ПРЕДСКАЗ Синтаксис: ПРЕДСКАЗ(х, известные_значения_у, известные_значения_х) Результат: Значение функции в точке х, предсказанное на основе линейной регрессии, для массивов известных значений х и у или интервалов данных. Эту функцию можно использовать для прогнозирования будущих продаж, потребностей в оборудовании или тенденций потребления. Аргументы: · х - точка данных, для которой прогнозируется значение; · известные_значения_у - зависимый массив или интервал данных; · известные_значения_х - независимый массив или интервал данных.
РАНГ Синтаксис: РАНГ(число, ссылка, порядок) Результат: Ранг числа в списке чисел. Ранг числа - это показатель его величины относительно других значений в списке. (Если список отсортировать, то ранг числа будет его позицией.) Аргументы: · число - число, для которого определяется ранг; · ссылка - массив или ссылка на список чисел (нечисловые значения в ссылке игнорируются); · порядок - число, определяющее способ упорядочения (если порядок равен 0 или опущен, то Excel определяет ранг числа так, как если бы ссылка была списком, отсортированным в порядке убывания; если порядок - это любое ненулевое число, то Excel определяет ранг числа так, как если бы ссылка была списком, отсортированным в порядке возрастания). ПРИМЕЧАНИЕ Одинаковые числа получают одинаковый ранг в списке.
РОСТ Синтаксис: РОСТ(известные_значения_у, известные_значения_х, новые_значения_х, конст) Результат: Аппроксимирует экспериментальной кривой известные_значения_у и извест-ные_значения_х и возвращает значения этой кривой, соответствующие значениям х, которые определяются аргументом новые_значения_х. Аргументы: · известные_значения_у - множество значений у, которые уже изиестны для соотношения у - b*m/\х (если массив известные_значения_у имеет один столбец, то каждый столбец массива известные_значения_х интерпретируется как отдельная переменная; если массив известные^ значения_у имеет одну строку, то каждая строка массива известные_значения_х интерпретируется как отдельная переменная; если какие-либо числа в массиве известные_значения_у равны 0 или отрицательны, то функция РОСТ возвращает значение ошибки #ЧИСЛО! ); · известные_значения_х - необязательное множество значений х, которые уже известны для соотношения у = b *m/\х (массив известные_значения_х может содержать одно или несколько множеств переменных; если используется только одна переменная, то извест-ные_значения_у и известные_значения_х могут иметь любую форму при условии, что они имеют одинаковую размерность; если используется более одной переменной, то известные: _значения_у должны быть вектором (то есть интервалом высотой в одну строку или шириной в один столбец); если аргумент известные_значения_х опущен, то предполагается, что это массив {1; 2; 3;...} такого же размера, как и известные_значения_у); · новые_значения_х - новые значения х, для которых функция РОСТ возвращает соответствующие значения у (аргумент новые_значения_х должен содержать столбец (или строку) для каждой независимой переменной, как и известные_значения_х\ таким образом, если аргумент известные_значения_у - это один столбец, то аргументы известные_значения_х и но-вые_значения_х должны иметь такое же количество столбцов; если аргумент известные_значения_у - это одна строка, то аргументы известные_зна-чения_х и новые__значения_х должны иметь такое же количество строк; если аргумент новые_значения_х опущен, то предполагается, что он совпадает с аргументом известные_значения_х если оба аргумента известные_значения_х и новые_ значе-ния_х опущены, то предполагается, что это массив {1; 2; 3;...} такого же размера, как и извест-ныезначения_у); · конст - логическое значение; если аргумент конст отсутствует или имеет значение ИСТИНА, то b вычисляется традиционно; если аргумент конст имеет значение ЛОЖЬ, то Ъ полагается равным 1 и значения т подбираются так, чтобы выполнялось соотношение у=m/\х.
СРГЕОМ Синтаксис: СРГЕОМ(число1, число2, ...) Результат: Среднее геометрическое значений массива или интервала положительных чисел. Например, функцию СРГЕОМ можно использовать для вычисления средних темпов роста, если задан составной доход с переменными ставками. Аргументы: · число1, число2, ... - от 1 до 30 аргументов, для которых вычисляется среднее геометрическое; в функции СРГЕОМ вместо аргументов можно использовать массив или ссылку на массив.
СРЗНАЧ Синтаксис: СРЗНАЧ(число1, число2, ...) Результат: Среднее значение (среднее арифметическое) аргументов. Аргументы: · число1, число2, ... - числа или имена, массивы или адресные ссылки на диапазон ячеек, содержащий ссылки. Функция СРЗНАЧ позволяет задавать от 1 до 30 аргументов.
СРОТКЛ Синтаксис: СРОТКЛ(число1, число2, ...) Результат: Среднее абсолютных значений отклонений точек данных от среднего. Функция СРОТКЛ является мерой разброса множества данных. Аргументы: · число1, число2, ... - от 1 до 30 аргументов, для которых определяется среднее абсолютных отклонений; вместо аргументов в функции СРОТКЛ можно использовать массив или ссылку на массив.
СТАНДОТКЛОН Синтаксис: СТАНДОТКЛОН(число1, число2, ...) Результат: Оценка стандартного отклонения по выборке. Стандартное отклонение - это мера того, насколько широко разбросаны точки данных относительно их среднего. Аргументы: · число1, число2, ... - от 1 до 30 числовых аргументов, соответствующих выборке из генеральной совокупности. ПРИМЕЧАНИЕ Используйте эту функцию, чтобы вычислить стандартное отклонение генеральной совокупности на основании выборки.
СТАНДОТКЛОНП Синтаксис: СТАНДОТКЛОНП(число1, число2,...) Результат: Стандартное отклонение по генеральной совокупности. Стандартное отклонение - это мера того, насколько широко разбросаны точки данных относительно их среднего. Аргументы: · число1, число2, ... - от 1 до 30 числовых аргументов, соответствующих генеральной совокупности; можно использовать массив или ссылку на массив вместо аргументов, разделяемых точкой с запятой. ПРИМЕЧАНИЕ Используйте эту функцию, чтобы вычислить стандартное отклонение генеральной совокупности на основе всех данных.
СТАНДОТКЛОНА Синтаксис: СТАНДОТКЛОНА(значение1, значение2, ...) Результат: Оценка стандартного отклонения по выборке, содержащей наряду с числовыми и логические значения, а также текст. Аргументы: · значение1, значение2, ... - От 1 до 30 аргументов, соответствующих выборке из генеральной совокупности. Можно использовать массив или ссылку на массив вместо перечисляемых через запятую аргументов. Для вычисления стандартного отклонения применяется та же формула, которая используется в функции СТАНДОТКЛ. Однако значения аргументов могут быть не только числовыми, но и текстовыми, а также логическими значениями. Аргумент, содержащий значение ИСТИНА, при вычислении заменяется на 1, а аргумент, включающий значение ЛОЖЬ или текст, - на 0.
СТАНДОТКЛОНПА Синтаксис: СТАНДОТКЛОНПА(значение1, значение2, ...) Результат: Оценка стандартного отклонения по генеральной совокупности, содержащей наряду с числовыми и логические значения, а также текст. Аргументы: См. описание функции СТАНДОТКЛОНА. ПРИМЕЧАНИЕ Для выборок большого объема СТАНДОТКЛОНПА и СТАНДОТКЛОНА дают близкие результаты. Функция СТАНДОТКЛОНА возвращает несмещенную оценку стандартного отклонения, а функция СТАНДОТКЛОНПА - смещенную оценку. СЧЕТ Синтаксис: СЧЕТ(значение1, значение2, ...) Результат: Количество чисел в списке аргументов. Функция СЧЕТ используется для получения количества числовых ячеек в интервалах или массивах ячеек. Аргументы: · значение1, значение2, ... - не более 30 аргументов; если аргуменг является матрицей или адресной ссылкой, то в нем при подсчете учитываются только числа, в остальных случаях учитываются пустые поля, числовые поля, логические значения и текстовые представления чисел (но не значения ошибки или не преобразуемы и текст). СЧЕТЗ Синтаксис: СЧЕТЗ(значение1, значение2, ... ) Результат: Количество всех значений (любого типа), приведенных в качестве аргументов. Аргументы: · значение1, значение2, ... - не более 30 аргументов; в матрицах и адресуемых диапазонах пустые поля игнорируются.
ЧАСТОТА Синтаксис: ЧАСТОТА(массив_данных, массив_карманов) Результат: Распределение частот в виде вертикального массива. Для данного множества значений и данного множества карманов (" карман" соответствует понятию интервала в математике) частотное распределение показывает, сколько исходных значений попадает в каждый интервал. Аргументы: · массив_данных - массив или ссылка на множество данных, для которых вычисляются частоты; если аргумент массив_данных не содержит значений, то функция ЧАСТОТА возвращает массив нулей; · массив_карманов - массив или ссылка на множество интервалов, в которые группируются значения аргумента массив_дан-ных\ если аргумент массив_карманов не содержит значений, то функция ЧАСТОТА возвращает количество элементов в аргументе массив_данных. ПРИМЕЧАНИЕ Функция ЧАСТОТА не учитывает ни текст, ни пустые ячейки. ЭКСПРАСП Синтаксис: ЭКСПРАСП(х, лямбда, интегральная) Результат: Экспоненциальное распределение. Функция ЭКСПРАСП используется для моделирования временных задержек между событиями, например для определения того, сколько времени займет денежный перевод в автоматизированном банке. С помощью функции ЭКСПРАСП можно подсчитать вероятность того, что этот процесс займет, предположим, не более минуты. Аргументы: · х - значение функции; · лямбда - значение параметра; · интегральная - логическое значение, которое указывает, какую форму экспоненциальной функции использовать (если аргумент интегральная имеет значение ИСТИНА, то функция ЭКСПРАСП возвращает интегральную функцию распределения; если этот аргумент имеет значение ЛОЖЬ, то возвращается функция плотности распределения). Математические функции В данной статье будет рассмотрена та часть математических функций, которая наиболее часто применяется в решении различных задач. С полным перечнем можно ознакомиться на вкладке «Формулы» => выпадающий список «Математические»:
Какие функции затронет статья: |
Последнее изменение этой страницы: 2017-04-13; Просмотров: 725; Нарушение авторского права страницы