|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Структуры данных и диаграммы отношений компонентов данных
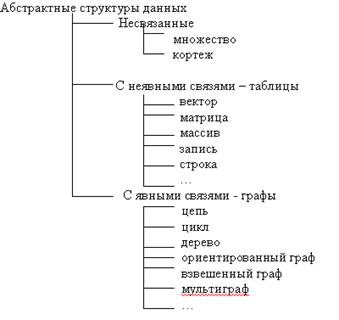
Структурой данных называют данные и совокупность правил и ограничений, которые отражают связи, существующие между данными. Другое определение звучит так: Структуры данных – это объекты определенного уровня абстракции, для представления которых в памяти компьютера можно использовать различные структуры хранения данных (таблицы, стек, граф, списки, дерево и т.п.). Различают абстрактные структуры данных, используемые для уточнения связей между элементами, и конкретные структуры, используемые для представления данных в программах. Все абстрактные структуры данных можно разделить на три группы (рис.3.12): структуры, элементы которых никак не связаны между собой, структуры с неявными связями элементов – таблицы, и структуры, связь элементов которых указывается явно – графы.
Рис. 3.12. Классификация абстрактных структур данных
В первую группу входят множества и кортежи, характеристикой элемента которых, является принадлежность его некоторому набору, т.е. отношение вхождения. Данные абстрактные структуры используют, если никакие другие отношения элементов не являются существенными для описываемых объектов. Ко второй группе относят векторы, матрицы, массивы (многомерные), записи, строки, а также таблицы, включающие перечисленные структуры в качестве частей. Существенным моментом этих структур, кроме вхождения элемента данных в структуру, является их порядок, а также отношения иерархии структур, т.е. вхождение структуры в структуру более высокой степени общности (рис. 3.13). В тех случаях, когда существенны связи элементов данных между собой, в качестве модели структур данных используют графы. На рис. 3.14 показаны различные варианты графовых моделей. Очень существенно, что на практике часты случаи вложения структур данных, в том числе и разных типов, а потому для их описания могут потребоваться специальные модели, как композиции указанных. В зависимости от описываемых типов отношений модели структур данных принято делить на иерархические и сетевые. Иерархические модели позволяют описывать упорядоченные или неупорядоченные отношения вхождения элементов данных в компонент более высокого уровня, т.е. множества, таблицы и их комбинации. К иерархическим моделям относят модель Джексона-Орра, для графического представления которой можно использовать: · диаграммы Джексона, как методику проектирования ПО (1975г.); · скобочные диаграммы Орра, также как методику проектирования ПО (1974г.). Сетевые модели основаны на графах, а потому позволяют описывать связность элементов данных независимо от вида отношения, в том числе комбинации множеств, таблиц и графов. К сетевым моделям, например, относят модель «сущность – связь» (ER – Entity – Relationship), обычно используемую при разработке баз данных. Диаграммы Джексона. В основе диаграмм Джексона лежит предположение о том, что структуры данных, также как и программ, можно строить из элементов с использованием всего трех основных конструкций: последовательность, выбора и повторения.
Рис. 3.13. Таблицы: а – числовой вектор; б – матрица; в – трехмерный массив; г – строка; д – запись; е – массив однотипных таблиц с вложенными структурами.
Каждая конструкция представляется в виде двухуровневой иерархии, на верхнем уровне которой расположен блок конструкций, а на нижнем – блоки элементов. Нотации конструкций различаются специальными символами в правом углу блоков элементов. В изображении конструкции последовательности дополнительный символ «о» (латинское) – сокращение английского «или» (or). Обе эти конструкции должны содержать по два или более элементов второго уровня. В изображении конструкции повторения в блоке единственного (повторяющегося) элемента ставится символ «*», означающий отсутствие, либо повторение более одного раза какого-либо элемента. Так схема, показанная на рис. 3.15, а, означает, что конструкция последовательности А состоит элементов В, С, и Д, следующих в указанном порядке. Схема на рис. 3.15, б означает, что конструкция выбора S состоит либо из элемента Р, либо из элемента Q, либо из элемента R. Схема, изображенная на рис. 3.15, в, показывает, что конструкция повторения W может либо не содержать один или более элементов Х
Рис. 3.14. Графы: а – цепь; б – цикл; в – дерево; г – ориентированный граф; д – взвешенный смешанный граф; е – мультиграф.
Рис.3.15. Нотация Джексона для представления конструкций: а – последовательности; б – выбора; в – повторение.
В случае, если необходимо показать, что конструкция повторения должна включать, по крайней мере, один или более элементов, используют комбинацию из двух структур: последовательности и повторения (рис. 3.16).
Рис. 3.16. Пример описания конструкции, в которой повторение встречается один или более раз.
Скобочные диаграммы Орра. Диаграмма Орра базируется на том же предположении о сходстве структур программ и данных, что и диаграмма Джексона. Отличие состоит лишь в нотации, т.е. в использовании фигурных скобок (рис. 3.17).
Рис. 3.17. Скобочная нотация для представления структур данных Орра: а – последовательность; б – выбор; в – повторение. Рассмотрим пример описания структуры данных файла «Электронная ведомость», содержащего сведения о сдаче экзаменов студентами. Файл состоит из записей о результатах сдачи сессии студентами одной группы. Файл имеет следующую структуру: номер группы, записи об успеваемости студентов (Ф.И.О. студента, название предмета и оценка, полученная студентом, в завершении записи специальный символ «конец записи») и специальный символ «конец файла». На рис. 3.18 показано, как выглядит описание данной структуры с использованием диаграммы Джексона, а на рис.3.19 – с использованием скобочной нотации Орра.
Рис. 3.18. Описание структуры файла «Электронная ведомость» в виде диаграммы Джексона
Рис. 3.19. Описание структуры файла «Электронная ведомость» в виде скобочной диаграммы Орра
Сетевая модель данных Сетевые модели данных используют в тех случаях, если отношение между компонентами данных не исчерпываются включением. Для графического представления разновидностей этой модели используют несколько нотаций. Наиболее известны из них следующие: · нотация П. Чена; · нотация Р. Баркера; · нотация IDEF1. Наиболее распространенной из них является нотация Р.Баркера, которой мы и будем придерживаться далее. Базовыми понятиями сетевой модели данных являются: сущность, атрибут и связь. Сущность – реальный или воображаемый объект, имеющий существенное значение для рассматриваемой предметной области. Каждая сущность должна: · иметь уникальное имя; · обладать одним или более атрибутами, которые либо принадлежат сущности, либо наследуются через связь; · обладать одним или более атрибутами, которые однозначно идентифицируют каждый экземпляр сущности. Сущность, таким образом, представляет собой множество экземпляров реальных или абстрактных объектов (людей, событий, состояний, предметов и т.п.). Имя сущности должно отражать тип или класс объектов, а не его конкретный экземпляр. Атрибут – любая характеристика сущности, значимая для рассматриваемой предметной области и предназначенная для квалификации, идентификации, классификации, количественной характеристики или выражения состояния сущности. Экземпляр сущности – набор конкретных значений атрибутов сущности. Атрибуты делятся на ключевые, т.е. входящие в состав уникального идентификатора сущности, который называют первичным ключом (Primary Key), и описательные – прочие. Ключевые атрибуты помечают символом “#”. Описательные атрибуты бывают обязательными или необязательными и помечаются символами “*” и “0” соответственно. Для сущностей, как и для классов в объектном программировании, определено понятие супертип и подтип. Например, супертип «учащийся» обобщает подтипы «школьник» и «студент».
Рис. 3.20. Обозначение супертипов и подтипов в нотации Баркера
Связь – поименованная ассоциация между двумя или более сущностями, значимая для рассматриваемой предметной области. Связь означает, что каждый экземпляр одной сущности ассоциирован с произвольным (в том числе и нулевым) количеством экземпляров второй сущности и набором. Если любой экземпляр одной сущности связан хотя бы с одним экземпляром другой сущности, то связь является обязательной. Необязательная связь представляет собой условное отношение между сущностями.
Рис. 3.21. Обозначение связи в нотации Баркера: а – обязательная; б – необязательная (пунктир показывают до середины линии связи)
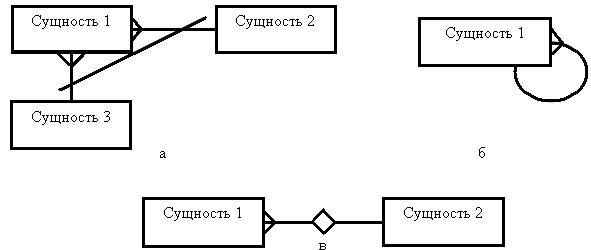
Каждая сущность может быть связана любым количеством связей с другими сущностями модели. В этом случае связь характеризуется количеством экземпляров сущностей, участвующих в связи с каждой стороны. Различают три типа отношений (рис.3.22): 1*1 – «один к одному» - одному экземпляру первой сущности соответствует один экземпляр второй; 1*n – «один- ко -многим» - одному экземпляру первой сущности соответствует несколько экземпляров второй; n*m – «многие –ко -многим» - каждому экземпляру первой сущности может соответствовать несколько экземпляров второй и, наоборот. Зависимые, независимые и ассоциированные сущности. Зависимая сущность представляет данные, зависящие от других сущностей системы, поэтому такая сущность должна быть всегда связана с другими. Независимая – представляет независимые данные, которые всегда присутствуют в системе. Они могут быть связаны или не связаны с другими сущностями той же системы. Ассоциированная сущность представляет данные, которые ассоциируются с отношениями между двумя и более сущностями. Обычно ассоциированная сущность используется в модели для разрешения отношения «многие – ко -многим» между Сущностью 1 и Сущностью 2 (рис. 3.22).
Рис.3.22. Обозначение ассоциированной сущности в нотации Баркера
Если экземпляр сущности полностью идентифицируется своими ключевыми атрибутами, то говорят о полной идентификации сущности. В противном случае идентификация такой сущности осуществляется с использованием атрибутов связанной сущности, что указывается вертикальной черточкой на линии связи у идентифицируемой сущности (рис. 3.23).
Рис.3.23. Обозначение идентификации посредством другой сущности в нотации Баркера
И, наконец, сетевая модель данных включает понятия: взаимно исключающие, рекурсивные и неперемещаемые связи. При наличии взаимно исключающей связи экземпляр сущности участвует только в одной связи из некоторой группы связей. Рекурсивная связь предполагает, что сущность может быть связана сама с собой. Неперемещаемая связь означает, что экземпляр сущности не может быть перенесен из одного экземпляра связи в другой (рис. 3.24).
Рис. 3.24. Обозначение особых видов связи в нотации Баркера: а – взаимно исключающая; б – рекурсивная; в – неперемещаемая.
В заключении рассмотрим структуру базы данных для системы учёта успеваемости студентов. Основными сущностями для решения указанной задачи являются: Студент и Предмет, отношение между которыми относится к типу «многие -ко- многим». Чтобы реализовать это отношение, введём ассоциированную с ними сущность Экзамен/Зачёт, которая должна отражать текущее выполнение предметов учебного плана студентом. Учебный план включает список предметов каждого семестра (Семестр), запланированные кафедрой. Сущности Факультет, Курс, Кафедра и Группа – определяют структуру организации, а также источники и потребители различного рода справок. Сущность ДатаЭкзамена имеет обязанности по хранению даты экзаменов для каждой группы, что даёт возможность определять момент времени, начиная с которого отсутствие положительных результатов сдачи экзамена следует считать задолженностью. На следующем шаге определяем спецификацию сущностей, т.е. атрибуты и их типы. Факультет: #ФакID, *ФакИмя Курс: #КурсID, *ФакID, *ГодПоступления Кафедра: #КафID, *ФакID, *КафИмя Семестр: #СемID, *КурсID, *КафID, *СемИмя Группа: #ГруппаID, *КафID, *КурсID, *ГруппаИмя Дата Экзамена: #ГруппаID, #ПредметID, #СемID, *Дата, *Аудитория Номер Предмет: #ПредметID, *Семестр, *ПредметИмя, оВидОценкиЗнаний (о-необязательный атрибут). Студент: #СтудентID, *Фамилия, *Имя, *Отчество, *ГруппаID, * Год Поступления Экзамен/Зачет: #СтудентID, #ПредметID, *Дата, *ТипЭкзамена, *Оценка Диаграмма «сущность - связь» приведена на рис. 3.25.
Рис.3.25. Диаграмма «сущность – связь» для описания базы данных системы учета успеваемости студентов
3.5. Методы задания спецификаций процессов Спецификация процесса (СП) используется для описания функционирования процесса в случае отсутствия необходимости детализировать его с помощью DFD, то есть, если он достаточно невелик и его описание может занимать до одной страницы текста. Фактически СП представляют собой алгоритмы описания задач, выполняемых процессами: множество всех СП является спецификацией систем. Спецификация процесса содержит номер и/или имя процесса, списки входных и выходных данных и тело (описание) процесса, являющееся спецификацией алгоритма или операции, преобразующей входные потоки в выходные. Известны разнообразные нотации, позволяющие задать тело процесса, от структурированного естественного языка, псевдокода до визуальных языков проектирования и формальных компьютерных языков. |
Последнее изменение этой страницы: 2017-05-11; Просмотров: 668; Нарушение авторского права страницы