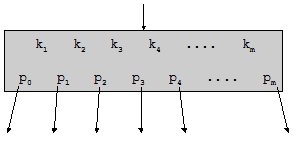|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
|
|
Архитектура Аудит Военная наука Иностранные языки Медицина Металлургия Метрология Образование Политология Производство Психология Стандартизация Технологии |
Сортировка и поиск с использованием деревьев
Задача поиска со вставкой До сих пор мы предполагали, что сортировка массива является предварительно выполняемой операцией, после которой многократно выполняется поиск по сортированному массиву. Однако на практике едва ли не чаще встречается несколько иная ситуация, когда операции поиска чередуются с операциями модификации массива, т.е. со вставками и удалениями элементов массива, изменениями значений элементов. В качестве примера можно рассмотреть информационную подсистему по контингенту студентов. Запросы типа «найти такого-то студента» могут перемежаться корректировками контингента: одного студента отчислить, другого зачислить в порядке перевода из другого вуза, у такой-то студентки изменить фамилию. Другой пример связан с работой компилятора, использующего таблицы имен переменных. При появлении имени в тексте компилируемой программы компилятор должен выяснить, встречалось ли это имя ранее (чтобы определить, была ли переменная описана до ее употребления, нет ли повторного описания и т.п.), и если обнаружится, что имя встречается впервые, его следует занести в таблицу имен. Как организовать эффективный поиск в подобной ситуации? Конечно, можно при каждой корректировке массива предпринимать действия для сохранения его сортированности. Но это потребует времени порядка O(n) на каждую корректировку. Например, при вставке нового элемента потребуется сначала определить, на какое место он должен быть вставлен (это бинарный поиск, т.е. O(log(n))), а потом сдвинуть последующие элементы на одну позицию, чтобы освободить выбранное место. В среднем придется сдвигать половину элементов массива, что и дает оценку O(n). А если не заботиться о сохранении сортированности? Тогда корректировки могут быть выполнены очень быстро, за время порядка O(1) (например, можно вставлять новые элементы всегда в конец массива), но поиск при этом замедляется до O(n) (линейный, а не бинарный поиск). Возможно ли такое решение проблемы, чтобы оценка времени как для поиска, так и для вставки/удаления элементов не превышала «хорошего» O(log(n))? Да, возможно, но для этого придется отказаться от использования такой структуры данных, как массив, и воспользоваться более гибкими сцепленными структурами. В связи с вышесказанным, в данном разделе мы будем рассматривать не чистую задачу поиска, а задачу поиска со вставкой, которую можно сформулировать следующим образом. Дана таблица A, представленная некоторой структурой данных. Дано также значение ключа x. Требуется проверить наличие в таблице записи с данным ключом, в случае отсутствия такой записи вставить ее в таблицу и в любом случае предоставить доступ к найденной или вставленной записи. Обратная операция, а именно удаление записи с заданным ключом, не будет подробно рассматриваться в данном пособии. Как правило, если известно, как добавляется новая запись, то нетрудно понять и как она должна удаляться. В некоторых случаях будут отмечены особенности операции удаления записей. Заметим еще, что алгоритмы поиска со вставкой делают фактически ненужной отдельную процедуру сортировки таблицы. Вместо того, чтобы сначала вводить данные в несортированную таблицу и затем выполнять их сортировку, можно начать с пустой таблицы и заполнить ее с помощью последовательной вставки всех необходимых элементов. Если время поиска и вставки одного элемента будет иметь оценку O(log(n)), то заполнение таблицы из n элементов займет время порядка O(n·log(n)), что сопоставимо с лучшими алгоритмами сортировки. Бинарные деревья поиска Напомним, что под бинарным деревом понимается такая структура данных, которая либо является пустой, либо состоит из вершины, называемой корнем дерева и связанной с двумя другими бинарными деревьями, называемыми левым и правым сыновьями корня. Мы будем рассматривать такие бинарные деревья, у которых с каждой вершиной связано значение этой вершины. Это значение может в общем случае состоять из поля ключа и поля данных, т.е. бинарное дерево можно рассматривать как иное представление таблицы, отличное от более привычного ее представления в виде массива. Как и раньше, мы для простоты будем считать, что значение вершины содержит только ключ. Бинарным деревом поиска называется такое бинарное дерево, у которого для каждой вершины A все значения вершин левого поддерева A не превышают значения A, а все значения вершин правого поддерева A не меньше, чем значение A. По-другому можно сказать, что бинарное дерево поиска – это такое дерево, при обходе которого слева направо значения вершин будут перечисляться в порядке возрастания. Поиск ключа по бинарному дереву имеет много общего с процедурой бинарного поиска в массиве. В том и другом случае после проверки на совпадение с искомым ключом одного из значений (раньше это было значение из середины массива, теперь – значение корня дерева) выполняется переход либо к меньшим, либо к большим значениям ключей. Разница в том, что вместо вычисления индекса следующего проверяемого элемента здесь просто выполняется переход либо к левому, либо к правому сыну проверенной вершины. Опишем структуры данных для представления таблицы в виде бинарного дерева.
type Tree = ^Node; {Дерево есть указатель на его корень} Node = record {Вершина дерева} key: KeyType; {Ключ} left, right: Tree; {Два сына (поддерева)} end;
Функция поиска по дереву со вставкой может в рекурсивном варианте выглядеть, как показано ниже.
function TreeSearch( var t: Tree; {Корень дерева} x: KeyType; {Искомый ключ} var found: Boolean {Найдено или вставлено? } ): Tree; {Возвращает указатель на вершину} begin if t = nil then begin {Вставка новой вершины} found: = false; {Не найдено, будет вставлено} New(t); t^.left: = nil; t^.right: = nil; t^.key: = x; TreeSearch: = t; end else if t^.key < x then TreeSearch: = TreeSearch(t^.right, x, found) else if t^.key > x then TreeSearch: = TreeSearch(t^.left, x, found) else begin {t^.key = x} found: = true; {Найдено! } TreeSearch: = t; end; end; {TreeSearch}
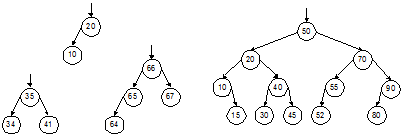
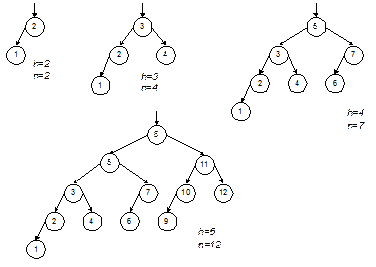
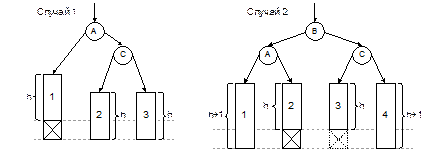
Пока значение ключа текущей вершины не равно искомому, функция выполняет спуск по дереву, переходя к левому или правому сыну вершины. Спуск заканчивается либо когда будет найден искомый ключ, либо когда очередное поддерево оказывается пустым. Это означает, что искомый ключ отсутствует в дереве и должен быть вставлен в соответствующем месте. Значением функции будет указатель на найденную либо вставленную вершину. Если функция выполнит вставку новой вершины, то исходное дерево изменится, однако оно сохранит свойства дерева поиска. Время работы функции определяется числом шагов спуска по дереву выполненных при поиске. Время выполнения вставки не зависит от размеров дерева, поэтому оно не повлияет на оценку в смысле O-большое. Максимальное число шагов спуска ограничено высотой дерева поиска. Как связана высота h с числом вершин дерева n? Это зависит от распределения вершин в дереве. Наиболее предпочтительным для поиска видом деревьев являются идеально сбалансированные деревья (ИС-деревья). Это такие бинарные деревья, у которых для каждой вершины количества вершин в ее левом и правом поддеревьях различаются не больше, чем на 1. Легко доказать, что длины всех ветвей ИС-дерева также различаются не более, чем на 1. Примеры ИС-деревьев поиска с разным числом вершин показаны на рис. 4.1.
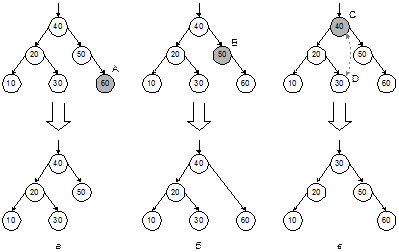
Рис. 4.1. Примеры идеально сбалансированных деревьев поиска Нетрудно доказать, что ИС-дерево высоты h может иметь от 2h–1 до 2h – 1 вершин. Отсюда можно получить и обратную зависимость – оценку высоты для данного числа вершин: h £ log2n + 1. Получается, что время поиска по ИС-дереву имеет логарифмическую оценку: T(n) = O(log(n)), аналогично бинарному поиску в сортированном массиве. Проблема заключается в том, что сбалансированность дерева обеспечить трудно. Предположим, что на вход программы, строящей бинарное дерево поиска с помощью функции TreeSearch, поступает монотонно возрастающая последовательность ключей. Нетрудно видеть, что в этом случае каждая новая вершина будет включаться в дерево как правый сын предыдущей вершины, а левых сыновей в этом дереве не будет вовсе. Результатом будет крайне несбалансированное вырожденное дерево, по сути представляющее собой линейный список. Для вырожденного дерева его высота равна числу вершин, а стало быть, T(n) = O(n). С другой стороны, пусть нам удалось каким-то образом построить ИС-дерево из n вершин. Если затем в это дерево будет добавлено еще хотя бы 1-2 вершины, то его балансировка может быть нарушена и для ее восстановления придется заново строить все дерево, затратив на это время порядка O(n). Таким образом, для несбалансированного дерева время порядка O(n) может тратиться на каждый поиск ключа, а для идеально сбалансированного аналогичное время будет затрачиваться на процедуру перебалансировки после добавления вершины. Разумеется, вырожденное дерево – это заведомо худший случай. В среднем дело обстоит не так плохо. Доказано, что если вершины добавляются в случайном порядке, то математическое ожидание высоты получившегося дерева будет иметь логарифмическую оценку и лишь примерно на 40 % превысит высоту ИС-дерева с тем же количеством вершин. Ситуация напоминает ту, которая характерна для алгоритма QuickSort: в среднем все очень хорошо, но не исключен и худший случай, когда все становится плохо. До сих пор мы говорили только о добавлении вершин (записей) в бинарное дерево поиска. Выполнение удаления вершин несколько сложнее, поскольку нужно уметь удалять не только листья, но и внутренние вершины дерева, и при этом нужно обеспечить сохранение целостности дерева. Не вдаваясь в подробности, покажем на рис. 4.2, как выполняется удаление на примере разных вершин одного и того же дерева.
Рис. 4.2. Удаление вершин из дерева поиска На рис. 4.2, а показано удаление вершины A, не имеющей сыновей. Здесь проблем не возникает. На рис. 4.2, б иллюстрируется удаление вершины B, имеющей одного сына. При этом у отца удаляемой вершины освобождается одна связь, к которой и присоединяется «осиротевший внук». Очевидно, что сортированность дерева поиска при этом сохраняется. На рис. 4.2, в показан самый сложный случай – удаление вершины C, имеющей двух сыновей. Чтобы при этом не развалить дерево и сохранить его сортированность, поступают следующим образом. Для удаляемой вершины ищется ближайшая к ней слева вершина. Для этого нужно сначала перейти от C к ее левому сыну, а затем спускаться направо, пока не попадем в вершину, не имеющую правого сына. В данном примере это вершина D. Далее следует поменять местами удаляемую вершину C и ее левого соседа D (это можно сделать либо путем манипуляций указателями, либо просто обменяв записи таблицы, связанные с вершинами). На новом месте вершина C имеет не более одного сына (ибо правого сына она не имеет), а потому может быть удалена, как в случае а или б. Легко видеть, что сортированность дерева не будет нарушена после этих операций. Удаление вершин, как и их добавление, может нарушить сбалансированность дерева и в худшем случае привести к его вырожденности. АВЛ-деревья Можно ли при работе с бинарными деревьями поиска гарантировать оценку T(n) = O(log(n)) для поиска и вставки не только в среднем, но и в худшем случае? Ответ положительный. Однако для этого следует выбрать подходящий класс деревьев. Для произвольных бинарных деревьев операция вставки выполняется просто и быстро, но поиск может быть долгим в случае вырождения. ИС-деревья гарантируют быстрый поиск, но много времени уходит на поддержание баланса при вставке и удалении. Желательно найти какой-то «средний» тип деревьев, чтобы они были не намного хуже, чем идеально сбалансированные, но вставка выполнялась значительно быстрее. Было предложено несколько подобных типов деревьев. Среди них АВЛ-деревья [1, 5], 2-3-деревья [3, 5], красно-черные деревья [4]. Мы рассмотрим только АВЛ-деревья, которые были названы в честь предложивших их советских математиков Г.М.Адельсона-Вельского и Е.М.Ландиса и которые до настоящего времени остаются одним из лучших средств решения задачи поиска со вставкой. АВЛ-деревом [3] называется такое бинарное дерево поиска, для каждой вершины которого высота ее левого и правого поддеревьев отличаются не более, чем на единицу. Легко видеть, что всякое ИС-дерево поиска является АВЛ-деревом. Обратное, вообще говоря, неверно. На рис. 4.3 показаны примеры самых худших (т.е. наиболее разбалансированных, «перекошенных») АВЛ-деревьев для различных значений высоты. Как видно из рисунка, даже в худшем случае АВЛ-деревья далеки от вырожденности. Это становится все более заметно при увеличении высоты. Можно доказать, что высота АВЛ-дерева превышает высоту ИС-дерева с тем же количеством вершин не более, чем на 45 %. Таким образом, логарифмическая зависимость высоты от числа вершин сохраняется даже в худшем случае. Таким образом, качество АВЛ-деревьев вполне приемлемо для быстрого поиска. Покажем, что поддержание сбалансированности при вставке новой вершины для этого типа деревьев требует лишь нескольких операций с указателями.
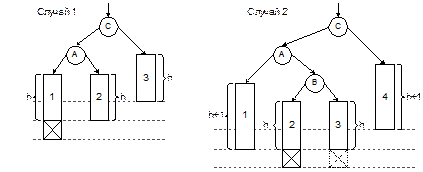
Рис. 4.3. Наихудшие АВЛ-деревья разной высоты Прежде всего, надо выяснить, каким образом вообще обнаруживается нарушение сбалансированности при вставке. Наиболее удобное решение – хранить в каждой вершине АВЛ-дерева дополнительное поле bal (баланс), которое может принимать одно из трех значений: t^.bal = –1, если левое поддерево вершины t выше, чем правое; t^.bal = 0, если оба поддерева одинаковы по высоте; t^.bal = +1, если правое поддерево t выше, чем левое. При выполнении вставки сначала происходит рекурсивный спуск по дереву, затем новая вершина добавляется как лист (и для нее, естественно, устанавливается начальное значение bal = 0), а затем, в процессе возврата вверх, для всех вершин соответствующей ветви дерева выполняется корректировка значений поля bal, если вставка новой вершины вызвала увеличение высоты левого или правого поддерева. Пусть при возврате вверх после вставки выяснилось, что для некоторой вершины C баланс нарушен: левое поддерево C теперь оказалось на 2 единицы выше, чем правое (случай перекоса вправо рассматривается аналогично). При этом для вершин, лежащих ниже C, баланс остается в пределах нормы (от –1 до +1). В этой ситуации возможны два существенно разных случая, проиллюстрированных на рис. 4.4.
Рис. 4.4. Нарушение баланса при вставке в АВЛ-дерево Буквой A обозначен левый сын вершины C. Высота поддерева A могла увеличиться либо при вставке в левое поддерево A (случай 1), либо при вставке в правое поддерево (случай 2). Прямоугольники 1, 2, 3, 4 обозначают поддеревья произвольной сложности, а перечеркнутый квадрат – добавленную вершину. Во втором случае показаны два возможных положения добавленной вершины, одно из них – пунктиром. Можно доказать, что в случае 1 высоты поддеревьев 1, 2 и 3 равны одной и той же величине h, а в случае 2 высоты поддеревьев 1 и 4 на единицу больше, чем 2 и 3. Для восстановления баланса изображенные части дерева должны быть переставлены так, как показано на рис. 4.5.
Рис. 4.5. Восстановление баланса АВЛ-дерева Такие преобразования АВЛ-дерева принято называть его поворотами. Прежде всего заметим, что повороты не нарушают упорядоченность дерева поиска (например, в случае 1 и до поворота, и после него ключи в различных частях дерева упорядочены следующим образом: 1 £ A £ 2 £ C £ 3). При этом восстанавливается баланс вершин дерева. Преобразования поворота выполняются с помощью нескольких присваиваний значений указателей. Ниже приведен в качестве примера фрагмент программы, выполняющий поворот для случая 1.
var t: Tree; {Корень поворачиваемой части дерева} p: Tree; {Рабочая переменная} ... p: = t^.left; {p -> A} t^.left: = p^.right; {C -> 2} p^.right: = t; {A -> C} t^.bal: = 0; {Оба поддерева C стали одной высоты} t: = p; {A – новый корень повернутой части} t^.bal: = 0; {Оба поддерева A тоже одной высоты} ...
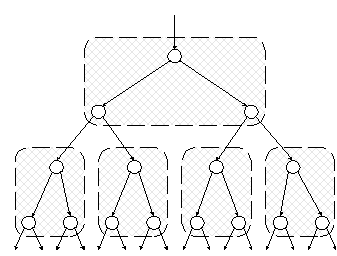
Из сравнения рис. 4.4 и 4.5 можно заметить, что высота рассматриваемой части дерева не увеличивается после вставки и последующего поворота. Это значит, что баланс вышележащих вершин дерева не изменяется и эти вершины не потребуют дополнительных поворотов. Страничные деревья поиска Использование бинарных деревьев поиска – удачный выбор для решения задачи поиска со вставкой, но только при условии, что все дерево может быть размещено в оперативной памяти компьютера. Однако это не всегда возможно, даже в условиях постоянно возрастающих объемов памяти современных компьютеров. Важный класс задач поиска связан с запросами к базам данных, которые хранятся на периферийных устройствах памяти (дисках и т.п.). При этом, как и в задачах внешней сортировки, рассмотренных в подразд. 3.7, высокая эффективность работы может быть достигнута применением таких алгоритмов и структур данных, которые минимизируют количество обращений к внешней памяти. С этой точки зрения бинарные деревья представляются малопригодными. Действительно, если не принять специальных мер, то вершины дерева могут оказаться произвольным образом разбросанными по блокам (секторам) устройства, при этом почти каждый переход от вершины-отца к ее левому или правому сыну потребует выполнения операции чтения блока с устройства. Целесообразно ввести в рассмотрение такие структуры данных (и связанные с ними алгоритмы), которые принимают во внимание блочную структуру хранения данных на устройстве. Действительно, поскольку за одно обращение к диску обязательно читается или записывается сразу блок данных, то алгоритмы поиска должны выполнить максимум полезной работы с этим блоком, прежде чем потребуется перейти к другому блоку. Такие алгоритмы легче конструировать, если физическому понятию «блок» поставить в соответствие некоторую единую структуру данных. Назовем такую структуру страницей. Ясно, что страница должна содержать намного больше данных, чем вершина бинарного дерева. Типичный размер блока (512 байт для большинства компьютеров) позволяет разместить на одной странице данные, соответствующие нескольким десяткам ключей и указателей. Один из наиболее логичных способов перехода от бинарного дерева к набору страниц показан на рис. 4.6.
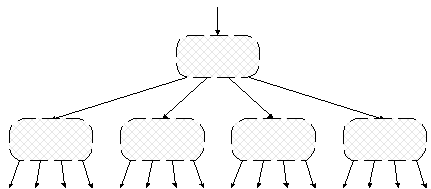
Рис. 4.6. Разбиение бинарного дерева на страницы Изображенный на рисунке фрагмент сбалансированного бинарного дерева разбит на страницы, которые, ради простоты примера, содержат по три вершины. Разумеется, на практике страница содержит значительно больше данных. Рисунок иллюстрирует две важные особенности разбиения. Во-первых, все страницы представляют собой одинаковые структуры данных. Во-вторых, алгоритм поиска выполняет как можно больше работы на одной странице, прежде чем перейти к другой странице. В данном маленьком примере это выражается в том, что на каждой странице выполняется не одно, а два сравнения ключей. Теперь посмотрим, что же получилось. Результат разбиения бинарного дерева на страницы схематически показан на рис. 4.7.
Рис. 4.7. Страничное дерево Безусловно, это дерево. Но теперь уже не бинарное. Каждая вершина дерева представляет собой страницу, т.е. блок данных на диске, и содержит не два, а большее число указателей на нижележащие вершины-страницы (в данном примере – четыре указателя). В действительности, страничные деревья далеко не всегда удается так хорошо сбалансировать, как на рисунке. Приходится до определенных пределов мириться и с неполными страницами, и с разной длиной ветвей в дереве страниц. Рассмотрим подробнее, из чего состоит страница.
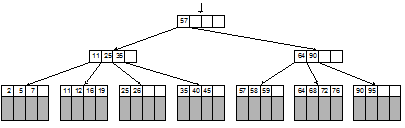
Рис. 4.8. Структура страницы Как показано на рис. 4.8, страница содержит некоторое количество m ключей k1, k2, …, km и m+1 указателей на нижележащие страницы p0, p1, p2, …, pm. Максимальное значение m называется порядком страничного дерева; порядок дерева зависит от размеров страницы, ключа и указателя. Каждый из pi указывает на поддерево, содержащее ключи x из определенного диапазона, а именно: p0 x £ k1; p1 k1 £ x £ k2; … pi ki £ x £ ki+1; … pm km £ x. По аналогии с бинарным деревом поиска, описанным в подразд. 4.2, дерево страниц, удовлетворяющее приведенным выше неравенствам, будем называть страничным деревом поиска. Заметим кстати, что бинарное дерево поиска можно считать частным случаем страничного при m = 1. Поиск по страничному дереву выполняется следующим образом. Сначала искомый ключ x сравнивается с ключами корневой страницы дерева. При этом либо на странице будет найден ключ ki = x, либо будет определен интервал (ki, ki+1), в который попадает значение x. В этом случае происходит переход по указателю pi (т.е. фактически с устройства читается другая страница), после чего поиск продолжается. Если дерево не содержит искомого значения x, то на некотором шаге будет получен пустой указатель pi. Следует заметить, что слово «указатель» в данном случае не обязательно означает адрес оперативной памяти. Если страничное дерево хранится в файле, то «указатель» будет скорее всего представлять собой смещение указываемой страницы от начала файла (в байтах или в секторах). Может возникнуть вопрос, как на самом деле расположены ключи и указатели внутри страницы. Судя по рис. 4.6, они образуют бинарное дерево, но на рис. 4.8 размещение больше похоже на два массива. На самом деле, этот вопрос несуществен. Как уже говорилось в подразд. 3.7, операции обмена данными с устройствами выполняются настолько медленнее, чем любые операции в оперативной памяти, что способ организации поиска внутри страницы не оказывает большого влияния на общую скорость поиска. Внутри страницы можно использовать сортированный массив, бинарное дерево или любую другую удобную структуру. Желательно лишь, чтобы эта структура была как можно более компактной, поскольку это позволит увеличить m – число ключей на странице. Скорость поиска по страничному дереву определяется главным образом числом операций чтения страницы. Поскольку при поиске выполняется спуск от страницы-корня к одной из страниц-листьев, максимальное время поиска определяется высотой дерева. Нетрудно оценить зависимость высоты страничного дерева от общего числа ключей n и порядка дерева m. Введем сначала понятие сбалансированного страничного дерева. Это дерево, все ветви которого по длине различаются не более, чем на 1, и все страницы, кроме, быть может, одной страницы на каждом уровне, содержат ровно m ключей. Можно показать, что высота сбалансированного страничного дерева не превышает logm(n) + 1. Отсюда понятно, что увеличение порядка дерева приводит к уменьшению высоты дерева, т.е. к ускорению поиска. Как и в случае бинарных деревьев поиска, многократные операции вставки и удаления ключей в страничное дерево могут, если не принять специальных мер, привести к вырождению дерева. Вырождение заключается в том, что число ключей на страницах становится значительно меньше m, при этом ветви дерева могут сильно различаться по длине. Следствием вырождения будет не только увеличение времени поиска, как в бинарном случае, но и излишний расход дисковой памяти на хранение неполных страниц. Здесь пора вспомнить, что, помимо ключа, каждая запись таблицы может еще содержать поле данных. На рис. 4.8 поля данных не показаны. Хранение данных внутри страниц дерева может привести к значительному уменьшению значения m (поскольку в одном секторе диска будет помещаться меньше записей). На практике, чтобы не хранить в страничном дереве объемные данные, вместо этого на странице размещают указатель на эти данные, которые хранятся где-нибудь в другом месте (например, в отдельном файле). B-деревья Подобно тому, как из множества бинарных деревьев поиска оказалось полезным выделить подкласс АВЛ-деревьев, так и из множества страничных деревьев поиска выделяют подкласс B-деревьев, которые позволяют сочетать достаточно хорошую сбалансированность с возможностью эффективно выполнять операции добавления и удаления ключей. B-деревом[4] порядка m называется страничное дерево поиска, удовлетворяющее следующим условиям. 1. Каждая страница дерева содержит не более m ключей, причем m – четное число. 2. Каждая страница, кроме, быть может, корневой страницы дерева, содержит не менее m/2 ключей. 3. Все страницы-листья находятся на одинаковом расстоянии от корня. Условие 1 означает всего лишь, что максимальное число ключей, которые можно разместить на странице, является четным. Условие 2 более существенно: оно означает, что каждая страница дерева (за исключением, может быть, корневой) заполнена по крайней мере наполовину. Условие 3 гарантирует невырожденность дерева. Условия 1 и 2 кажутся на первый взгляд довольно мягкими. Видно, что они допускают двойной перерасход дисковой памяти по сравнению со случаем дерева, все страницы которого максимально заполнены. Высота B-дерева при этом также не будет минимально возможной. Но это неизбежная плата за компромисс. Как и бинарные АВЛ-деревья, страничные B-деревья не являются оптимальными, но они совмещают достаточно приличную сбалансированность с возможностью быстрой вставки и удаления ключей. Насколько высота B-дерева (т.е. время поиска ключа) может превышать минимально возможную высоту страничного дерева? Ясно, что высота будет тем больше, чем меньше ключей на каждой странице. Однако можно показать, что при достаточно большом порядке страницы высота наихудшего B-дерева (с одним ключом на корневой странице и m/2 ключами на каждой из остальных страниц) будет лишь на 1-2 уровня превышать высоту наилучшего дерева (с m ключами на каждой странице). Рассмотрим теперь, как выполняется добавление новых ключей в B-дерево и каким образом при этом достигается соблюдение условий 1 – 3. При поиске ключа в B-дереве происходит спуск от корня до страницы, содержащей искомый ключ. Если ключ не найден, то поиск завершается на той странице-листе, куда следует вставить этот ключ. На рис. 4.9 показано небольшое B-дерево порядка 4, в которое последовательно вставляются три ключа.
Рис. 4.9. Добавление ключей в B-дерево На верхнем рисунке – исходное B-дерево. При вставке на шаге 1 ключа 4 поиск приведет на крайнюю левую страницу-лист и, поскольку на странице есть свободное место, ключ добавляется без проблем. На шаге 2 ключ 6 должен быть вставлен на ту же страницу, но места там уже нет. В этом случае должна быть выполнена операция расщепления страницы. Она заключается в следуюшем. Создается новая страница дерева. Те m ключей, которые были на заполненной странице (2, 4, 5 и 7), плюс вставляемый ключ 6, распределяются так: меньшие m/2 ключей (2 и 4) остаются не прежней странице, большие m/2 (6 и 7) переносятся на новую. Средний по значению ключ 5 переносится на страницу уровнем выше и используется как разделитель двух нижних страниц. Из приведенного описания становится понятно, откуда взялось число m/2 в определении B-дерева. На шаге 3 ключ 18 также должен быть вставлен в заполненную страницу с ключами 11, 12, 16 и 19. При расщеплении на старой странице остаются ключи 11 и 12, на новую переносятся 18 и 19, а ключ 16 переносится на уровень вверх, на корневую страницу, где для него опять нету места. Создаются еще две новые страницы, одна из которых становится новым корнем B-дерева, содержащим всего один ключ. Высота дерева в этом случае увеличивается на 1. В худшем случае при добавлении одного ключа переполнение страниц может приключиться на каждом уровне дерева, что приведет к созданию h+1 новой страницы. Но после этого на всех затронутых расщеплением страницах будет полно свободного места, так что следующее переполнение вряд ли случится скоро. Так или иначе, время вставки пропорционально высоте дерева, т.е. логарифму от числа вершин. Заметим, что на шаге 3 можно было бы избежать расщепления страниц, воспользовавшись операцией переливания ключей на соседнюю неполную страницу. Рядом со страницей, содержащей ключи (11, 12, 16, 19), имелась страница с ключами (25, 26). При добавлении ключа 18 на старой странице можно было бы оставить ключи (11, 12, 16, 18), ключ 19 перешел бы вверх на место ключа 20, который сдвинулся бы вниз: (20, 25, 26). Если использовать переливание, то расщепление страницы будет необходимым только тогда, когда ни слева, ни справа от переполняющейся страницы нет страницы со свободным местом. Удаление ключа из B-дерева можно рассматривать как обратную операцию по отношению к вставке, однако здесь имеются некоторые дополнительные сложности. При удалении ключа надо обязательно сделать попытку переливания с одной из соседних страниц и только в случае невозможности следует объединять две страницы в одну, перенося вниз разделяющий их ключ со страницы верхнего уровня. Переливание выполняется не только для страниц-листьев, но и для внутренних страниц, если число ключей стало меньше m/2. Описанная выше модель B-деревьев допускает многочисленные варианты и улучшения. Вероятно, самое главное уточнение заключается в следующем. Обратим внимание, что структура страниц-листьев отличается от остальных страниц дерева. Из листьев не выходят указатели на нижележащие страницы, значит для указателей не нужно отводить место на странице. Сэкономленная память может быть использована для хранения большего количества ключей и данных на каждой странице-листе. Это приведет к уменьшению общего числа страниц, и как следствие, – к уменьшению высоты дерева. Можно также повысить порядок внутренних страниц B-дерева, если отказаться от хранения данных на всех страницах, кроме листьев. Тогда внутренние страницы будут содержать только ключи и указатели на нижележащие страницы, а листья – ключи и связанные с ними данные. При этом, очевидно, листья будут содержать все записи таблицы, т.е. все ключи и их данные, а внутренние листья тогда должны содержать дубликаты некоторых ключей, позволяющие спуститься к нужному листу. Такая структура данных называется B+-деревом. Пример B+-дерева показан на рис. 4.10.
Рис. 4.10. Структура B+-дерева На рисунке серым заштрихованы области памяти, отведенные для хранения данных, связанных с ключами. Можно отметить, что каждый ключ, расположенный во внутреннем узле дерева, является дубликатом ключа ближайшей к нему справа записи, расположенной в листе дерева[5]. В тех случаях, когда объем внешней памяти ограничен и потому нежелателен двойной перерасход памяти, допускаемый моделью B-деревьев, можно использовать такую модификацию, как B * -деревья. Они отличаются иным алгоритмом вставки (и удаления) ключей. В этом алгоритме при переполнении страницы обязательно используется переливание на одну из соседних страниц. Когда соседние страницы заполнены, выполняется расщепление не одной страницы, а двух соседних страниц. На новую страницу переносится треть ключей с каждой из двух заполненных страниц, так что каждая страница B*-дерева будет заполнена по крайней мере на 2/3, а не на 1/2, как для обычного B-дерева. Корневая страница B*-дерева должна при этом быть большего размера, чем остальные, и она может быть заполнена не более чем на 4/3 от объема обычной страницы. При расщеплении корня он дает две обычные страницы, заполненные на 2/3, а новый корень, как и для B-деревьев, содержит только один ключ. Модель B*-деревьев позволяет сократить расход внешней памяти примерно на 25 %, но при этом добавление и удаление ключей выполняется заметно сложнее, чем для B-деревьев.
Популярное:
|
Последнее изменение этой страницы: 2016-04-11; Просмотров: 1061; Нарушение авторского права страницы